开源组件系列(3):非关系型数据导入(Flume)
(一)非关系型数据采集概述
在日常的数据仓库建设过程中,通常会采集各类型的业务日志,包括广告日志、搜索日志、展现日志、点击日志等。当业务达到一定规模时,日志记录系统会产生大量的日志,而如何将这些日志高效及时的收集起来,并存储到Hadoop上,是非关系型数据导入组件设计的动机。总的来说,需要考虑以下四方面的问题:
1.数据来源多:基本上各种类型的业务都会产生日志,这些日志很难保持相同的结构,产生和收集的方式也不同;
2.物理分布广:由于不同类型的业务需要部署在不同的环境下,有一些甚至是跨机房部署,因而天然的需要考虑分布式特征;
3.不间断产生:日志的产生和收集是实时的,如果有实时数据统计,对于延迟的要求会更高;
4.可靠性要高:特殊或者重要日志,例如金融类日志,是不允许丢失情况的。
(二)Flume概述
Flume的设计思想是:插拔式。作为中间件,类似于U盘一样,即插即用,用户可以根据自行的需要定制每种组件。在官方的介绍中,Flume是一个分布式的、可依赖的并且具备高可用性的组件,它具有一种简单便捷的流式数据收集结构。
Flume具备以下的特点:
1.良好的扩展性,Flume的架构是分布式的,没有中心化组件;
2.高度的定制化:各个组件之间是插拔的(Source/Channel/Sink),可以根据实际业务场景进行定制;
3.动态的配置化:Flume提供了一种声明式的参数配置方式,可以自行配置一套数据流拓扑结构。
Flume架构示意如下:

Event在图上并没有标记出来,但Event在Flume中是数据传输的最小单元,负责定制数据的传输任务。Agent是一个Flume的实例,本质上是一个JVM进程,控制Event数据流的走向。Source消费Web服务器传递的Event,并通过Thrift/Avro协议将数据存储到一个或多个Channel中。Channel是被动的存储器,用于保持Event的状态并最终被Sink消费掉。Sink负责从Channel中移除相关的Event,并存储到外部的系统,如HDFS中,或者转发给下一个Flume Agent,以实现自定义的数据拓扑结构。
值得注意的是,Agent中的Source和Sink,在Channel执行存取Event操作时,是异步的。
(三)Flume NG基本架构
Flume NG是相对于原版的Flume OG而言,Flume OG有Master的概念,依赖于Zookeeper,而Flume NG放弃了这些概念,只用了简单的Source、Channel和Sink概念完成了设计,使用更加便捷高效,因此现在Flume基本上都是使用NG架构。从上文得知,Flume的数据流是通过一个又一个的Agent来实现的,一个Agent可以从前一个Agent中接收数据,经过数据过滤后,传递给下一个Agent,直到存储到目标系统中。
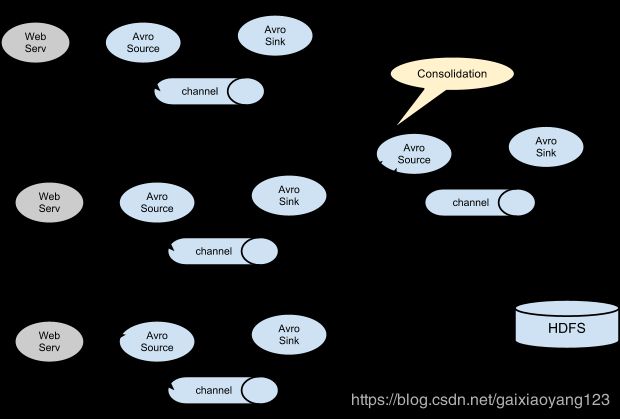
Flume支持多路复用数据流到一个或多个目的地。这是通过Channel Selector来实现的,它可以复制或者选择数据流到一个或多个channel上。如下图所示:
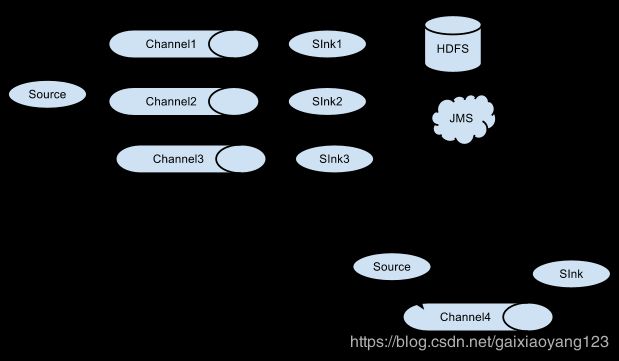
Flume的相关组件说明如下:
【Source组件】
作为数据流中接收Event的组件,Flume提供了很多种实现组件,主要包括:
1.Avro Source:接收Avro客户端数据;
2.Thrift Source:接收Thrift客户端数据;
3.Exec Source:执行Sehll命令;
4.Kafka Source:从Kafka Broker中读取Topic的数据;
5.HTTP Source:接收HTTP数据;
6.自定义Source:用户自行定制。
【Channel组件】
作为Flume中的数据缓冲区,负责暂存Event数据,主要有以下组件:
1.Memory Channel:将数据暂存到内存中,具备极高的性能,但断电会丢失数据;
2.File Channel:将数据暂存到文件中,不会丢失数据,但性能不高;
3.JDBC Channel:将数据写入到数据库中,适用于高可靠性场景;
4.Kafka Channel:将数据写入到Kafka中,使Channel具备了Kafka的高容错和可扩展的特性。
【Sink组件】
Sink负责从Channel中读取数据,并发送给下一个Agent或写入到目标系统,Flume提供了如下实现:
1.HDFS Sink:最常用的Sink,负责写入HDFS;
2.HBase Sink:适用于使用HBase的场景;
3.Avro/Thrift Sink:发送给制定的Avro/Thrift Server;
4.Kafka Sink:将最终数据写入到Kafka中。
【Interceptor】
Interceptor是Flume中的高级组件,允许用户修改或者丢弃Event,常见的组件有:
1.Timestamp Interceptor:根据Event头部的时间戳信息处理Event;
2.Host Interceptor:根据Event头部Host或者Ip信息处理Event;
3.Regex Filtering Interceptor:根据正则表达式处理Event。
【Channel Selector】
Channel Selector允许Source选择一个或多个Channel,并将Event写入到选中的Channel中,常见组件有:
1.Replicating Channel Selector:Flume的默认Channel Selector,将相同的数据导入到多套系统中;
2.Multiplexing Channel Selector:根据Event头部属性,写入对应的Channel。
【Sink Processor】
Flume允许将多个Sink组合在一起形成Sink Group,Sink Processor在Sink Group的基础上提供负载均衡及容错的功能。常见的组件有:
Default Sink Processor:默认的Sink Processor实现,Source -> Channel -> Sink;
Failover Sink Processor:Sink Group中每个Sink均有优先级的设置,优先级高的Sink的优先发送,如果高优先级的Sink失败了,则第二优先级的Sink接替;
Load balancing Sink Processor:Event通过某种负载均衡机制,交给Sink Group中所有的Sink发送,目前支持round_robin和random两种方式,
(四)Flume 示例程序
第一步:配置各个组件。
每个组件(Source,Sink或者Channel)都有Name、Type和一些其他的属性。例如Avro Source需要有Host或者Ip老来接收数据。这些组件属性都需要在Flume配置文件中设置。
以下是一个单节点的 Flume 实例配置:
# 配置Agent a1各个组件的名称
a1.sources = r1 #Agent a1 的source有一个,叫做r1
a1.sinks = k1 #Agent a1 的sink也有一个,叫做k1
a1.channels = c1 #Agent a1 的channel有一个,叫做c1
# 配置Agent a1的source r1的属性
a1.sources.r1.type = netcat #使用的是NetCat TCP Source,这个的是别名,Flume内置的一些组件都是有别名的,没有别名填全限定类名
a1.sources.r1.bind = localhost #NetCat TCP Source监听的hostname,这个是本机
a1.sources.r1.port = 44444 #监听的端口
# 配置Agent a1的sink k1的属性
a1.sinks.k1.type = logger # sink使用的是Logger Sink,这个配的也是别名
# 配置Agent a1的channel c1的属性,channel是用来缓冲Event数据的
a1.channels.c1.type = memory #channel的类型是内存channel,顾名思义这个channel是使用内存来缓冲数据
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 把source和sink绑定到channel上
a1.sources.r1.channels = c1 #与source r1绑定的channel有一个,叫做c1
a1.sinks.k1.channel = c1 #与sink k1绑定的channel有一个,叫做c1第二步:连接各个组件。
Agent需要知道加载什么组件,以及这些组件在流中的连接顺序,这需要通过定义每个sink和source的channel来完成。
例如:
# 列出Agent的所有Source、Channel、Sink
.sources =
.sinks =
.channels =
# 设置Channel和Source的关联
.sources..channels = ...
# 设置Channel和Sink的关联
.sinks..channel =
# 列出Agent的所有source、sink和channel
agent_foo.sources = avro-appserver-src-1
agent_foo.sinks = hdfs-sink-1
agent_foo.channels = mem-channel-1
agent_foo.sources.avro-appserver-src-1.channels = mem-channel-1 # 指定与source avro-appserver-src-1 相连接的channel是mem-channel-1
agent_foo.sinks.hdfs-sink-1.channel = mem-channel-1 # 指定与sink hdfs-sink-1 相连接的channel是mem-channel-1 再例如在Agent中添加一个流:
# 这样列出Agent的所有source、sink和channel,多个用空格分隔
.sources =
.sinks =
.channels =
agent_foo.sources = avro-AppSrv-source1 exec-tail-source2 # 该agent中有2个sourse,分别是:avro-AppSrv-source1 和 exec-tail-source2
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2 # 该agent中有2个sink,分别是:hdfs-Cluster1-sink1 和 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2 # 该agent中有2个channel,分别是:mem-channel-1 file-channel-2
# 这里是第一个流的配置
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 # 与avro-AppSrv-source1相连接的channel是mem-channel-1
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1 # 与hdfs-Cluster1-sink1相连接的channel是mem-channel-1
# 这里是第二个流的配置
agent_foo.sources.exec-tail-source2.channels = file-channel-2 # 与exec-tail-source2相连接的channel是file-channel-2
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2 # 与avro-forward-sink2相连接的channel是file-channel-2 第三步:启动Agent。
bin目录下的flume-ng是Flume的启动脚本,启动时需要指定Agent的名字、配置文件的目录和配置文件的名称。例如:
$bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template