1. 什么是Apache Cassandra?
Apache Cassandra是一个开源,分布式和分散式/分布式存储系统(数据库),用于管理遍布世界各地的大量结构化数据。它提供高可用性的服务,没有单点故障。下面列出了Apache Cassandra的一些值得注意的地方:
- 它是可扩展,容错和一致的。
- Apache Cassandra是一个开源,分布式和分散式/分布式存储系统(数据库),用于管理遍布世界各地的大量结构化数据。它提供高可用性的服务,没有单点故障。
- 它是一个面向列的数据库。
- 它的分布设计基于Amazon的Dynamo及其在Google的Bigtable上的数据模型。
- 创建在Facebook,它与关系数据库管理系统有很大的不同。
- Cassandra实现了一个没有单点故障的Dynamo风格的复制模型,但增加了一个更强大的“列族”数据模型。
- Cassandra被一些最大的公司使用,如Facebook,Twitter,Cisco,Rackspace,ebay,Netflix等。
2. Cassandra的特点
Cassandra因其卓越的技术特性而变得如此受欢迎。下面给出了Cassandra的一些特性:
- 弹性可扩展性 - Cassandra是高度可扩展的; 它允许添加更多的硬件以适应更多的客户和更多的数据根据要求。
- 始终基于架构 - Cassandra没有单点故障,它可以连续用于不能承担故障的关键业务应用程序。
- 快速线性性能 - Cassandra是线性可扩展性的,即它为你增加集群中的节点数量增加你的吞吐量。因此,保持一个快速的响应时间。
- 灵活的数据存储 - Cassandra适应所有可能的数据格式,包括:结构化,半结构化和非结构化。它可以根据您的需要动态地适应变化的数据结构。
- 便捷的数据分发 - Cassandra通过在多个数据中心之间复制数据,可以灵活地在需要时分发数据。
- 事务支持 - Cassandra支持属性,如原子性,一致性,隔离和持久性(ACID)。
- 快速写入 - Cassandra被设计为在廉价的商品硬件上运行。 它执行快速写入,并可以存储数百TB的数据,而不牺牲读取效率。
3. 相关概念
keyspace -> table –> column,对应关系型数据库 database -> table -> column
存储结构:
CREATE TABLE mykeyspace.mytable (
key1 text,
key2 text,
key3 text,
column1 bigint,
column2 int,
column3 timestamp,
PRIMARY KEY (key1, key2, key3);
)
key1: partitionKey,分区主键,用来决定Cassandra会使用集群中的哪个结点来记录该数据,每个Partition Key对应着一个特定的Partition;
4. Cassandra安装
依赖:jdk、python,并且要保证jvm(java命令)和jdk(javac命令)版本一致,python的版本也会根据你下载的Cassandra版本有要求,具体请查看官方文档:http://cassandra.apache.org/doc/latest/,jdk和python的安装我这里就不演示,大家自行安装;这里只说一下Cassandra的安装过程;
- 去官网下载文件,下载最新版本即可,https://cassandra.apache.org/

- 解压到你的的目录下,例如:E:\apache-cassandra-3.11.2\bin
- 运行cmd,cd到你解压的目录下,运行cassandra.bat,如果出现
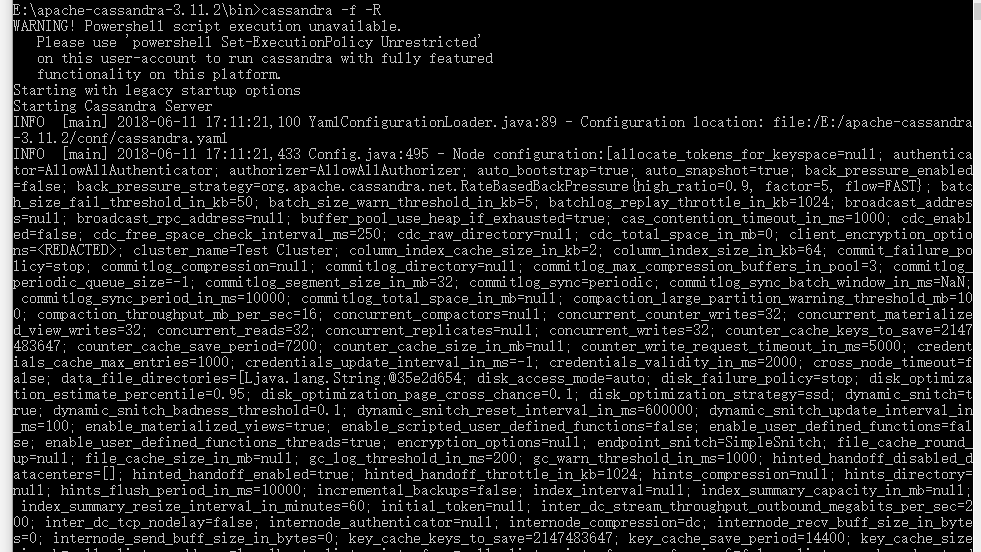
证明运行成功,否则检查错误;
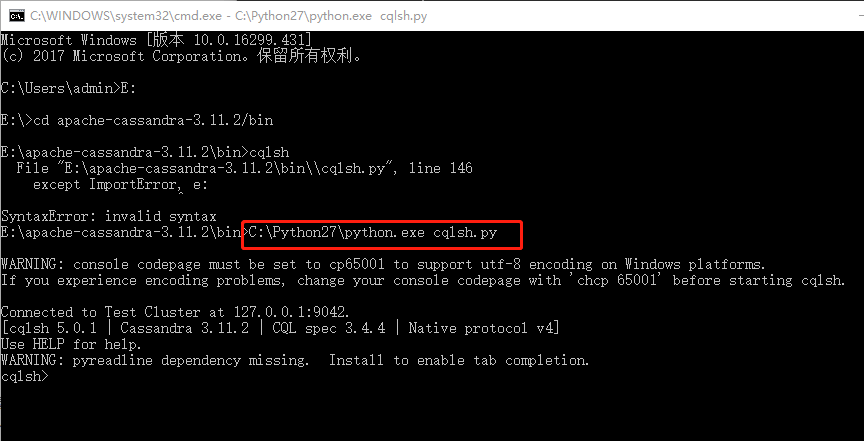
- 如果运行成功,在命令行输入cqlsh,就可以愉快地写cql代码啦~,如果你的电脑中装有两个python版本,如有python35和python27,可以不用修改环境变量,直接在运行cqlsh的时候前面加上python27的路径,如图:
5. 数据类型
下面只是简单介绍了一下,具体用法请查看官方文档:https://cassandra.apache.org/doc/latest/cql/types.html#grammar-token-collection_type。
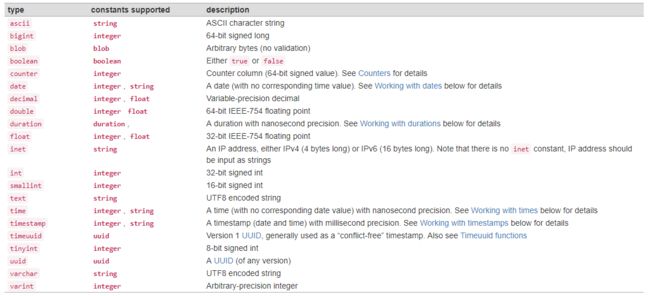
- Native type:
-
Collection
CQL支持3种集合类型:Map、Set和List。这些集合的类型由以下定义:

- User-defined types
例:
CREATE TYPE phone (
country_code int,
number text,
)
CREATE TYPE address (
street text,
city text,
zip text,
phones map
)
CREATE TABLE user (
name text PRIMARY KEY,
addresses map>
)
INSERT INTO user (name, addresses)
VALUES ('z3 Pr3z1den7', {
'home' : {
street: '1600 Pennsylvania Ave NW',
city: 'Washington',
zip: '20500',
phones: { 'cell' : { country_code: 1, number: '202 456-1111' },
'landline' : { country_code: 1, number: '...' } }
},
'work' : {
street: '1600 Pennsylvania Ave NW',
city: 'Washington',
zip: '20500',
phones: { 'fax' : { country_code: 1, number: '...' } }
}
})
- Tuples
例:
CREATE TABLE durations (
event text,
duration tuple,
)
INSERT INTO durations (event, duration) VALUES ('ev1', (3, 'hours'));
- Custom types
这种类型用法比较复杂并且不太友好,可以用user-defined type 替代之。
6. 基本操作
具体教程可以参考w3cshool教程https://www.w3cschool.cn/cassandra/cassandra_create_keyspace.html。这里只介绍几种常用基本命令:
- 创建一个keyspace:CREATE KEYSPACE IF NOT EXISTS myCas WITH REPLICATION = {'class': 'SimpleStrategy','replication_factor':1};
class : 副本配置策略(总共有三种):
Simple Strategy(RackUnaware Strategy):为集群指定简单的复制因子,副本不考虑机架的因素,按照Token放置在连续下几个节点;
OldNetwork Topology Strategy(RackAware Strategy):考虑机架的因素,除了基本的数据外,先找一个处于不同数据中心的点放置一个副本,其余N-2个副本放置在同一数据中心的不同机架中;
Network Topology Strategy(DatacneterShard Strategy):将M个副本放置到其他的数据中心,将N-M-1的副本放置在同一数据中心的不同机架中; - 查询全部的keyspace:describe keyspaces;(或desc keyspaces;)
- 使用某个keyspace:use myCas;
- 查询全部的table:desc tables;
- 创建一张表:CREATE TABLE user (id int, user_name varchar, PRIMARY KEY (id) ); 注意创建表的时候至少指定一个主键;
- 删除表: drop table user;
- 描述一张表:desc user;
- 向表中插入一条记录:INSERT INTO user (id,user_name) VALUES (1,'zhangsan');
- 查询表中全部数据:select * from user;
cassandra查询有很多限制,比如只能单表查询,不支持联表查询和子查询,查询条件只支持key查询和索引列查询,而且key有顺序的限制,等等;更多详情请自行阅读官方文档; - 简单的条件查询:select * from user where id=1;
- 创建索引:create index on user(user_name);
- 索引列查询:select * from user where user_name='zhangsan';
若没有在name上创建索引,那么此查询会报错;索引列只可以用=号查询,不能使用>或<;如果想用>或<查询,可以加上ALLOW FILTERING,例如:select * from teacher where age>35 ALLOW FILTERING;如果查询条件里,有一个是根据索引查询,那其它非索引非主键字段,也可以通过加一个ALLOW FILTERING来过滤实现; - 更新表中数据:update user set user_name='lisi' where id=2;
只支持按主键更新,也就是where后只能跟主键 - 删除表中记录:delete from user where id=1;
删除某条记录中的某个字段,该字段会被设成null:delete user_name from user where id=1;无论是删除某条记录,还是将某个字段置null,都只支持按主键删除,也就是where后只能跟主键; - 删除自定义类型: drop type user_defined;
7. 常见错误解决方法
- “except ImportError, e”这种错误应该是你的python版本是3.0以上的,而对应版本的Cassandra需要2.x的版本,因此你可能需要重新装一个2.x的版本;
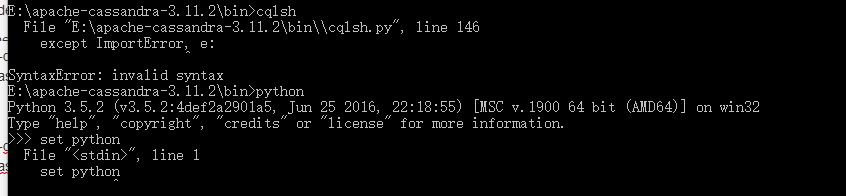
- 另外要保证jdk和jvm版本一致,可以在cmd命令下查看:javac -version 和 java -version;
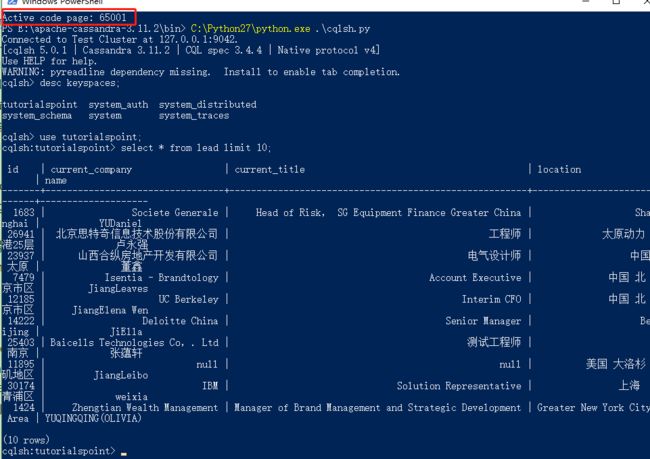
- Cassandra中文查询乱码,可以在命令行输入chcp 65001,即可设为 UTF-8 编码。
- 官网提供的常见问题:http://cassandra.apache.org/doc/latest/faq/index.html;
8. Cassandra-java基本操作
可以参考http://www.cnblogs.com/youzhibing/p/6607082.html。
9. Cassandra高级操作
可以参考: cassandra高级操作之索引、排序以及分页
参考文章:
- Cassandra简介
- cassandra简单介绍与基本操作
- Cassandra-java操作——基本操作
- cassandra高级操作之索引、排序以及分页
非常感谢前辈们的付出,谢谢!