Python编程语言简介
https://www.cnblogs.com/hany-postq473111315/p/12256134.html
Python环境搭建及中文编码
https://www.cnblogs.com/hany-postq473111315/p/12256337.html
Python 基础语法
https://www.cnblogs.com/hany-postq473111315/p/12257287.html
Python 变量类型及变量赋值
https://www.cnblogs.com/hany-postq473111315/p/12258952.html
Python 标准数据类型
https://www.cnblogs.com/hany-postq473111315/p/12259374.html
Python 数字数据类型
https://www.cnblogs.com/hany-postq473111315/p/12259684.html
Python字符串
https://www.cnblogs.com/hany-postq473111315/p/12259859.html
Python列表
https://www.cnblogs.com/hany-postq473111315/p/12259925.html
Python元组
https://www.cnblogs.com/hany-postq473111315/p/12260559.html
Python字典
https://www.cnblogs.com/hany-postq473111315/p/12260671.html
Python数据类型转换
https://www.cnblogs.com/hany-postq473111315/p/12260913.html
Python算术运算符
https://www.cnblogs.com/hany-postq473111315/p/12261418.html
Python比较运算符
https://www.cnblogs.com/hany-postq473111315/p/12262652.html
Python赋值运算符
https://www.cnblogs.com/hany-postq473111315/p/12262791.html
Python位运算符
https://www.cnblogs.com/hany-postq473111315/p/12262990.html
Python逻辑运算符
https://www.cnblogs.com/hany-postq473111315/p/12263166.html
Python成员运算符
https://www.cnblogs.com/hany-postq473111315/p/12263573.html
Python身份运算符
https://www.cnblogs.com/hany-postq473111315/p/12263746.html
Python运算符优先级
https://www.cnblogs.com/hany-postq473111315/p/12263888.html
Python条件语句
https://www.cnblogs.com/hany-postq473111315/p/12264149.html
Python简单的语句组
https://www.cnblogs.com/hany-postq473111315/p/12264240.html
Python循环语句
https://www.cnblogs.com/hany-postq473111315/p/12264329.html
Python循环控制语句
https://www.cnblogs.com/hany-postq473111315/p/12264653.html
Python while循环语句
https://www.cnblogs.com/hany-postq473111315/p/12264768.html
Python无限循环
https://www.cnblogs.com/hany-postq473111315/p/12267695.html
Python while 循环中使用 else 语句
https://www.cnblogs.com/hany-postq473111315/p/12267719.html
Python while 中简单的语句组
https://www.cnblogs.com/hany-postq473111315/p/12267753.html
Python for循环语句
https://www.cnblogs.com/hany-postq473111315/p/12268067.html
Python for循环使用 else 语句
https://www.cnblogs.com/hany-postq473111315/p/12268076.html
Python for循环通过序列索引迭代
https://www.cnblogs.com/hany-postq473111315/p/12268174.html
Python 循环嵌套
https://www.cnblogs.com/hany-postq473111315/p/12268209.html
Python break语句
https://www.cnblogs.com/hany-postq473111315/p/12268271.html
Python continue语句
https://www.cnblogs.com/hany-postq473111315/p/12268306.html
Python pass语句
https://www.cnblogs.com/hany-postq473111315/p/12268565.html
Python 数字类型转换
https://www.cnblogs.com/hany-postq473111315/p/12268709.html
Python数学函数
https://www.cnblogs.com/hany-postq473111315/p/12268737.html
Python随机数函数
https://www.cnblogs.com/hany-postq473111315/p/12269533.html
Python三角函数
https://www.cnblogs.com/hany-postq473111315/p/12269772.html
Python数学常量
https://www.cnblogs.com/hany-postq473111315/p/12269905.html
Python创建字符串
https://www.cnblogs.com/hany-postq473111315/p/12275504.html
Python访问字符串中的值
https://www.cnblogs.com/hany-postq473111315/p/12275513.html
Python字符串更新
https://www.cnblogs.com/hany-postq473111315/p/12275591.html
Python转义字符
https://www.cnblogs.com/hany-postq473111315/p/12275690.html
Python字符串运算符
https://www.cnblogs.com/hany-postq473111315/p/12275891.html
Python字符串格式化
https://www.cnblogs.com/hany-postq473111315/p/12276031.html
Python三引号
https://www.cnblogs.com/hany-postq473111315/p/12283515.html
Python Unicode字符串
https://www.cnblogs.com/hany-postq473111315/p/12283589.html
Python字符串内建函数_上
https://www.cnblogs.com/hany-postq473111315/p/12284044.html
Python字符串内建函数_下
https://www.cnblogs.com/hany-postq473111315/p/12284555.html
Python列表
https://www.cnblogs.com/hany-postq473111315/p/12286383.html
Python访问列表中的值
https://www.cnblogs.com/hany-postq473111315/p/12286568.html
Python更新列表
https://www.cnblogs.com/hany-postq473111315/p/12286660.html
Python删除列表元素
https://www.cnblogs.com/hany-postq473111315/p/12286710.html
Python列表脚本操作符
https://www.cnblogs.com/hany-postq473111315/p/12286755.html
Python列表截取
https://www.cnblogs.com/hany-postq473111315/p/12286809.html
Python列表函数和方法
https://www.cnblogs.com/hany-postq473111315/p/12286964.html
Python元组
https://www.cnblogs.com/hany-postq473111315/p/12287445.html
Python访问元组
https://www.cnblogs.com/hany-postq473111315/p/12287609.html
Python修改元组
https://www.cnblogs.com/hany-postq473111315/p/12287673.html
Python删除元组
https://www.cnblogs.com/hany-postq473111315/p/12287811.html
Python元组运算符
https://www.cnblogs.com/hany-postq473111315/p/12287938.html
Python元组索引、截取
https://www.cnblogs.com/hany-postq473111315/p/12287975.html
Python元组内置函数
https://www.cnblogs.com/hany-postq473111315/p/12288016.html
Python字典
https://www.cnblogs.com/hany-postq473111315/p/12288198.html
Python访问、修改、删除字典中的值
https://www.cnblogs.com/hany-postq473111315/p/12288231.html
Python字典内置函数和方法
https://www.cnblogs.com/hany-postq473111315/p/12288354.html
Python日期和时间_什么是Tick_什么是时间元组_获取当前时间
https://www.cnblogs.com/hany-postq473111315/p/12289960.html
Python获取当前时间_获取格式化时间_格式化日期
https://www.cnblogs.com/hany-postq473111315/p/12290540.html
Python Time模块
https://www.cnblogs.com/hany-postq473111315/p/12290622.html
Python日历模块
https://www.cnblogs.com/hany-postq473111315/p/12290929.html
Python定义一个函数
https://www.cnblogs.com/hany-postq473111315/p/12293310.html
Python函数调用
https://www.cnblogs.com/hany-postq473111315/p/12294753.html
Python按值传递参数和按引用传递参数
https://www.cnblogs.com/hany-postq473111315/p/12294915.html
Python函数参数
https://www.cnblogs.com/hany-postq473111315/p/12295062.html
Python匿名函数_return语句
https://www.cnblogs.com/hany-postq473111315/p/12295925.html
Python变量作用域
https://www.cnblogs.com/hany-postq473111315/p/12296130.html
Python全局变量和局部变量
https://www.cnblogs.com/hany-postq473111315/p/12298147.html
Python模块_import语句_from...import 函数名_from ... import *
https://www.cnblogs.com/hany-postq473111315/p/12298371.html
Python定位模块_PYTHONPATH变量
https://www.cnblogs.com/hany-postq473111315/p/12299402.html
Python命名空间和作用域
https://www.cnblogs.com/hany-postq473111315/p/12299536.html
Python dir( )函数
https://www.cnblogs.com/hany-postq473111315/p/12299640.html
Python globals和locals函数_reload函数
https://www.cnblogs.com/hany-postq473111315/p/12299945.html
Python包
https://www.cnblogs.com/hany-postq473111315/p/12302885.html
Python打印到屏幕_读取键盘输入
https://www.cnblogs.com/hany-postq473111315/p/12303156.html
Python打开和关闭文件
https://www.cnblogs.com/hany-postq473111315/p/12303245.html
Python read和write方法
https://www.cnblogs.com/hany-postq473111315/p/12303304.html
PythonFile对象的属性
https://www.cnblogs.com/hany-postq473111315/p/12303309.html
Python里的目录方法
https://www.cnblogs.com/hany-postq473111315/p/12303318.html
Python重命名和删除文件
https://www.cnblogs.com/hany-postq473111315/p/12303314.html
猜数字游戏
https://www.cnblogs.com/hany-postq473111315/p/12651677.html
实现功能菜单栏
https://www.cnblogs.com/hany-postq473111315/p/12652887.html
pass 出错问题
https://www.cnblogs.com/hany-postq473111315/p/12652896.html
Python 实现分层聚类算法
https://www.cnblogs.com/hany-postq473111315/p/12671890.html
KNN算法基本原理与sklearn实现
https://www.cnblogs.com/hany-postq473111315/p/12672247.html
矩阵常用操作
https://www.cnblogs.com/hany-postq473111315/p/12672549.html
不同复制操作对比(三种)
https://www.cnblogs.com/hany-postq473111315/p/12672623.html
排序和索引的问题
https://www.cnblogs.com/hany-postq473111315/p/12672695.html
正则表达式补充
https://www.cnblogs.com/hany-postq473111315/p/12675139.html
Pandas 复习
https://www.cnblogs.com/hany-postq473111315/p/12675657.html
Pandas 复习2
https://www.cnblogs.com/hany-postq473111315/p/12677896.html
Series结构(常用)
https://www.cnblogs.com/hany-postq473111315/p/12678080.html
部分画图
https://www.cnblogs.com/hany-postq473111315/p/12679161.html
提取txt文本有效内容
https://www.cnblogs.com/hany-postq473111315/p/12680021.html
获取全部 txt 文本中出现次数最多的前N个词汇
https://www.cnblogs.com/hany-postq473111315/p/12680560.html
使用朴素贝叶斯模型对邮件进行分类
https://www.cnblogs.com/hany-postq473111315/p/12680882.html
函数进阶1
https://www.cnblogs.com/hany-postq473111315/p/12681153.html
函数进阶2
https://www.cnblogs.com/hany-postq473111315/p/12681487.html
Python异常及异常处理
https://www.cnblogs.com/hany-postq473111315/p/12303328.html
Python 中 False 和 True 关键字
https://www.cnblogs.com/hany-postq473111315/p/12257604.html
正则表达式补充2
https://www.cnblogs.com/hany-postq473111315/p/12681687.html
正则表达式基础1
https://www.cnblogs.com/hany-postq473111315/p/12682011.html
两数相加(B站看视频总结)
https://www.cnblogs.com/hany-postq473111315/p/12682862.html
函数进阶3
https://www.cnblogs.com/hany-postq473111315/p/12683682.html
函数进阶4
https://www.cnblogs.com/hany-postq473111315/p/12683729.html
列表推导式
https://www.cnblogs.com/hany-postq473111315/p/12683951.html
关于类和异常的笔记
https://www.cnblogs.com/hany-postq473111315/p/12683969.html
类 巩固小结
https://www.cnblogs.com/hany-postq473111315/p/12684207.html
模块小结
https://www.cnblogs.com/hany-postq473111315/p/12684404.html
异常 巩固1
https://www.cnblogs.com/hany-postq473111315/p/12684508.html
异常 巩固2
https://www.cnblogs.com/hany-postq473111315/p/12684638.html
logging日志基础示例
https://www.cnblogs.com/hany-postq473111315/p/12684676.html
异常 巩固3
https://www.cnblogs.com/hany-postq473111315/p/12684747.html
多线程复习1
https://www.cnblogs.com/hany-postq473111315/p/12685980.html
多线程复习2
https://www.cnblogs.com/hany-postq473111315/p/12686171.html
yield 复习
https://www.cnblogs.com/hany-postq473111315/p/12686330.html
协程解决素数
https://www.cnblogs.com/hany-postq473111315/p/12686467.html
爬虫流程复习
https://www.cnblogs.com/hany-postq473111315/p/12686857.html
列表常用方法复习
https://www.cnblogs.com/hany-postq473111315/p/12691570.html
字典常用操作复习
https://www.cnblogs.com/hany-postq473111315/p/12691575.html
单链表复习
https://www.cnblogs.com/hany-postq473111315/p/12695182.html
双链表复习
https://www.cnblogs.com/hany-postq473111315/p/12697287.html
单向循环链表
https://www.cnblogs.com/hany-postq473111315/p/12700855.html
将"089,0760,009"变为 89,760,9
https://www.cnblogs.com/hany-postq473111315/p/12701254.html
Linux最常用的基本操作复习
https://www.cnblogs.com/hany-postq473111315/p/12702144.html
python连接数据库
https://www.cnblogs.com/hany-postq473111315/p/12704539.html
复习实现栈的基本操作
https://www.cnblogs.com/hany-postq473111315/p/12705117.html
显示列表重复值
https://www.cnblogs.com/hany-postq473111315/p/12705591.html
复习 队列的实现
https://www.cnblogs.com/hany-postq473111315/p/12706952.html
扩展 双端队列
https://www.cnblogs.com/hany-postq473111315/p/12707455.html
复习 二叉树的创建
https://www.cnblogs.com/hany-postq473111315/p/12723432.html
复习 广度遍历
https://www.cnblogs.com/hany-postq473111315/p/12725087.html
复习 深度遍历(先序中序后序)
https://www.cnblogs.com/hany-postq473111315/p/12725386.html
应用场景
https://www.cnblogs.com/hany-postq473111315/p/12725748.html
类 扩展
https://www.cnblogs.com/hany-postq473111315/p/12727814.html
复习 装饰器
https://www.cnblogs.com/hany-postq473111315/p/12731157.html
扩展 求奇数和
https://www.cnblogs.com/hany-postq473111315/p/12732794.html
字符串重复出现
https://www.cnblogs.com/hany-postq473111315/p/12732912.html
最基本的Tkinter界面操作
https://www.cnblogs.com/hany-postq473111315/p/12736499.html
Tkinter常用简单操作
https://www.cnblogs.com/hany-postq473111315/p/12736695.html
Tkinter经典写法
https://www.cnblogs.com/hany-postq473111315/p/12736898.html
Label 组件基本写法
https://www.cnblogs.com/hany-postq473111315/p/12739187.html
类实例化的对象调用的方法或属性来自于类的哪个方法中
https://www.cnblogs.com/hany-postq473111315/p/12739493.html
Button基本用语
https://www.cnblogs.com/hany-postq473111315/p/12739711.html
Entry基本用法
https://www.cnblogs.com/hany-postq473111315/p/12739996.html
Text多行文本框基本用法
https://www.cnblogs.com/hany-postq473111315/p/12741482.html
Radiobutton基础语法
https://www.cnblogs.com/hany-postq473111315/p/12742418.html
Checkbutton基本写法
https://www.cnblogs.com/hany-postq473111315/p/12742886.html
扩展写法
https://www.cnblogs.com/hany-postq473111315/p/12748369.html
整理上课内容
https://www.cnblogs.com/hany-postq473111315/p/12758012.html
Seaborn基础1
https://www.cnblogs.com/hany-postq473111315/p/12765835.html
Seaborn基础2
https://www.cnblogs.com/hany-postq473111315/p/12765847.html
Seaborn基础3
https://www.cnblogs.com/hany-postq473111315/p/12765857.html
Seaborn实现单变量分析
https://www.cnblogs.com/hany-postq473111315/p/12766032.html
Seaborn实现回归分析
https://www.cnblogs.com/hany-postq473111315/p/12766396.html
Seaborn实现多变量分析
https://www.cnblogs.com/hany-postq473111315/p/12766576.html
将形如 5D, 30s 的字符串转为秒
https://www.cnblogs.com/hany-postq473111315/p/12770867.html
获得昨天和明天的日期
https://www.cnblogs.com/hany-postq473111315/p/12770871.html
计算两个日期相隔的秒数
https://www.cnblogs.com/hany-postq473111315/p/12770888.html
遍历多个 txt 文件进行获取值
https://www.cnblogs.com/hany-postq473111315/p/12771248.html
Django学习路
https://www.cnblogs.com/hany-postq473111315/p/12774607.html
Django学习路2
https://www.cnblogs.com/hany-postq473111315/p/12775279.html
Django学习路3
https://www.cnblogs.com/hany-postq473111315/p/12778795.html
安装第三方库
https://www.cnblogs.com/hany-postq473111315/p/12785024.html
安装第三方库进阶
https://www.cnblogs.com/hany-postq473111315/p/12785212.html
Python第一次实验
https://www.cnblogs.com/hany-postq473111315/p/12787851.html
打包程序问题
https://www.cnblogs.com/hany-postq473111315/p/12788073.html
pip 国内源
https://www.cnblogs.com/hany-postq473111315/p/12802294.html
format 进阶
https://www.cnblogs.com/hany-postq473111315/p/12806654.html
进阶删除重复元素
https://www.cnblogs.com/hany-postq473111315/p/12819466.html
实现优先级队列
https://www.cnblogs.com/hany-postq473111315/p/12819475.html
爬虫流程复习2
https://www.cnblogs.com/hany-postq473111315/p/12819589.html
numpy第三方库
https://www.cnblogs.com/hany-postq473111315/p/12821506.html
pandas第三方库
https://www.cnblogs.com/hany-postq473111315/p/12821512.html
函数式回文串
https://www.cnblogs.com/hany-postq473111315/p/12821617.html
判断是否包含重复值
https://www.cnblogs.com/hany-postq473111315/p/12821629.html
函数实现 多个数据求平均值
https://www.cnblogs.com/hany-postq473111315/p/12821637.html
对传入的数据进行分类
https://www.cnblogs.com/hany-postq473111315/p/12821665.html
进阶 对传入的数据进行分类
https://www.cnblogs.com/hany-postq473111315/p/12821676.html
二进制字符长度
https://www.cnblogs.com/hany-postq473111315/p/12821692.html
将包含_或-的字符串最开始的字母小写,其余的第一个字母大写
https://www.cnblogs.com/hany-postq473111315/p/12821750.html
将字符串的首字母大写其余字符根据需要,判断是否大写
https://www.cnblogs.com/hany-postq473111315/p/12821780.html
将每一个分隔开的字符的首字母大写
https://www.cnblogs.com/hany-postq473111315/p/12821790.html
无论传入什么数据都转换为列表
https://www.cnblogs.com/hany-postq473111315/p/12821818.html
斐波那契数列进一步讨论性能
https://www.cnblogs.com/hany-postq473111315/p/12827717.html
迭代器和可迭代对象区别
https://www.cnblogs.com/hany-postq473111315/p/12827742.html
map 函数基本写法
https://www.cnblogs.com/hany-postq473111315/p/12827787.html
filter 函数基本写法
https://www.cnblogs.com/hany-postq473111315/p/12827853.html
functools 中的 reduce 函数基本写法
https://www.cnblogs.com/hany-postq473111315/p/12827943.html
三元运算符
https://www.cnblogs.com/hany-postq473111315/p/12827981.html
学装饰器之前必须要了解的四点
https://www.cnblogs.com/hany-postq473111315/p/12828151.html
列表推导式,最基本写法
https://www.cnblogs.com/hany-postq473111315/p/12828176.html
字典推导式,最基本写法
https://www.cnblogs.com/hany-postq473111315/p/12828267.html
集合推导式,最基本写法
https://www.cnblogs.com/hany-postq473111315/p/12828283.html
状态码
https://www.cnblogs.com/hany-postq473111315/p/12835104.html
爬虫流程复习3
https://www.cnblogs.com/hany-postq473111315/p/12836761.html
Django坑_01
https://www.cnblogs.com/hany-postq473111315/p/12837316.html
list 和 [ ] 的功能不相同
https://www.cnblogs.com/hany-postq473111315/p/12838134.html
Django创建简单数据库
https://www.cnblogs.com/hany-postq473111315/p/12840986.html
数据库设计基础知识
https://www.cnblogs.com/hany-postq473111315/p/12841422.html
Django学习路4_数据库添加元素,读取及显示到网页上
https://www.cnblogs.com/hany-postq473111315/p/12841899.html
[] 和 () 的区别
https://www.cnblogs.com/hany-postq473111315/p/12842366.html
使用 you-get 下载免费电影或电视剧
https://www.cnblogs.com/hany-postq473111315/p/12843854.html
Django学习路5_更新和删除数据库表中元素
https://www.cnblogs.com/hany-postq473111315/p/12844479.html
Django学习路6_修改数据库为 mysql ,创建mysql及进行迁徙
https://www.cnblogs.com/hany-postq473111315/p/12844651.html
python 连接 mysql 的三种驱动
https://www.cnblogs.com/hany-postq473111315/p/12844667.html
pandas_DateFrame的创建
https://www.cnblogs.com/hany-postq473111315/p/12844777.html
pandas_一维数组与常用操作
https://www.cnblogs.com/hany-postq473111315/p/12844790.html
pandas_使用属性接口实现高级功能
https://www.cnblogs.com/hany-postq473111315/p/12844800.html
pandas_使用透视表与交叉表查看业绩汇总数据
https://www.cnblogs.com/hany-postq473111315/p/12844818.html
pandas_分类与聚合
https://www.cnblogs.com/hany-postq473111315/p/12844831.html
pandas_处理异常值缺失值重复值数据差分
https://www.cnblogs.com/hany-postq473111315/p/12844851.html
pandas_数据拆分与合并
https://www.cnblogs.com/hany-postq473111315/p/12844857.html
pandas_数据排序
https://www.cnblogs.com/hany-postq473111315/p/12844866.html
pandas_时间序列和常用操作
https://www.cnblogs.com/hany-postq473111315/p/12844876.html
pandas_学习的时候总会忘了的知识点
https://www.cnblogs.com/hany-postq473111315/p/12844887.html
pandas_查看数据特征和统计信息
https://www.cnblogs.com/hany-postq473111315/p/12844895.html
pandas_读取Excel并筛选特定数据
https://www.cnblogs.com/hany-postq473111315/p/12844906.html
pandas_重采样多索引标准差协方差
https://www.cnblogs.com/hany-postq473111315/p/12844921.html
Numpy random函数
https://www.cnblogs.com/hany-postq473111315/p/12844924.html
Numpy修改数组中的元素值
https://www.cnblogs.com/hany-postq473111315/p/12844928.html
Numpy创建数组
https://www.cnblogs.com/hany-postq473111315/p/12844937.html
Numpy改变数组的形状
https://www.cnblogs.com/hany-postq473111315/p/12844944.html
Numpy数组排序
https://www.cnblogs.com/hany-postq473111315/p/12844954.html
Numpy数组的函数
https://www.cnblogs.com/hany-postq473111315/p/12844962.html
Numpy数组的运算
https://www.cnblogs.com/hany-postq473111315/p/12844978.html
Numpy访问数组元素
https://www.cnblogs.com/hany-postq473111315/p/12845013.html
关于这几天发布的文章
https://www.cnblogs.com/hany-postq473111315/p/12845031.html
TCP 客户端
https://www.cnblogs.com/hany-postq473111315/p/12845038.html
TCP 服务器端
https://www.cnblogs.com/hany-postq473111315/p/12845044.html
UDP 绑定信息
https://www.cnblogs.com/hany-postq473111315/p/12845055.html
UDP 网络程序-发送_接收数据
https://www.cnblogs.com/hany-postq473111315/p/12845060.html
WSGI应用程序示例
https://www.cnblogs.com/hany-postq473111315/p/12845068.html
定义 WSGI 接口
https://www.cnblogs.com/hany-postq473111315/p/12845080.html
encode 和 decode 的使用
https://www.cnblogs.com/hany-postq473111315/p/12845094.html
abs,all,any函数的使用
https://www.cnblogs.com/hany-postq473111315/p/12845118.html
一行代码合并两个字典
https://www.cnblogs.com/hany-postq473111315/p/12845131.html
一行代码求多个列表中的最大值
https://www.cnblogs.com/hany-postq473111315/p/12845153.html
文件的某些操作(以前发过类似的)
https://www.cnblogs.com/hany-postq473111315/p/12845193.html
冒泡排序
https://www.cnblogs.com/hany-postq473111315/p/12845219.html
希尔排序
https://www.cnblogs.com/hany-postq473111315/p/12845247.html
归并排序
https://www.cnblogs.com/hany-postq473111315/p/12845260.html
快速排序
https://www.cnblogs.com/hany-postq473111315/p/12845271.html
插入排序
https://www.cnblogs.com/hany-postq473111315/p/12845283.html
选择排序
https://www.cnblogs.com/hany-postq473111315/p/12845306.html
数据库基础应用
https://www.cnblogs.com/hany-postq473111315/p/12845310.html
数据库进行参数化,查询一行或多行语句
https://www.cnblogs.com/hany-postq473111315/p/12845325.html
数据结构_链表(单链表,单向循环链表,双链表)
https://www.cnblogs.com/hany-postq473111315/p/12845339.html
数据结构_队列(普通队列和双端队列)
https://www.cnblogs.com/hany-postq473111315/p/12845346.html
数据结构_栈
https://www.cnblogs.com/hany-postq473111315/p/12845356.html
数据结构_二叉树
https://www.cnblogs.com/hany-postq473111315/p/12845365.html
二分法查找
https://www.cnblogs.com/hany-postq473111315/p/12845370.html
正则表达式_合集上
https://www.cnblogs.com/hany-postq473111315/p/12845456.html
正则表达式_合集下(后续还会有补充)
https://www.cnblogs.com/hany-postq473111315/p/12845485.html
线程_apply堵塞式
https://www.cnblogs.com/hany-postq473111315/p/12845503.html
线程_FIFO队列实现生产者消费者
https://www.cnblogs.com/hany-postq473111315/p/12845511.html
线程_GIL最简单的例子
https://www.cnblogs.com/hany-postq473111315/p/12845522.html
线程_multiprocessing实现文件夹copy器
https://www.cnblogs.com/hany-postq473111315/p/12845531.html
线程_multiprocessing异步
https://www.cnblogs.com/hany-postq473111315/p/12845536.html
线程_Process实例
https://www.cnblogs.com/hany-postq473111315/p/12845545.html
线程_Process基础语法
https://www.cnblogs.com/hany-postq473111315/p/12845549.html
线程_ThreadLocal
https://www.cnblogs.com/hany-postq473111315/p/12845560.html
线程_互斥锁_Lock及fork创建子进程
https://www.cnblogs.com/hany-postq473111315/p/12845573.html
线程_gevent实现多个视频下载及并发下载
https://www.cnblogs.com/hany-postq473111315/p/12845587.html
线程_gevent自动切换CPU协程
https://www.cnblogs.com/hany-postq473111315/p/12845603.html
线程_使用multiprocessing启动一个子进程及创建Process 的子类
https://www.cnblogs.com/hany-postq473111315/p/12845615.html
线程_共享全局变量(全局变量在主线程和子线程中不同)
https://www.cnblogs.com/hany-postq473111315/p/12845624.html
线程_多线程_列表当做实参传递到线程中
https://www.cnblogs.com/hany-postq473111315/p/12845630.html
线程_threading合集
https://www.cnblogs.com/hany-postq473111315/p/12845649.html
线程_进程间通信Queue合集
https://www.cnblogs.com/hany-postq473111315/p/12845662.html
线程_进程池
https://www.cnblogs.com/hany-postq473111315/p/12845673.html
线程_可能发生的问题
https://www.cnblogs.com/hany-postq473111315/p/12845683.html
== 和 is 的区别
https://www.cnblogs.com/hany-postq473111315/p/12845720.html
__getattribute__小例子
https://www.cnblogs.com/hany-postq473111315/p/12846865.html
__new__方法理解
https://www.cnblogs.com/hany-postq473111315/p/12846871.html
ctime使用及datetime简单使用
https://www.cnblogs.com/hany-postq473111315/p/12846876.html
functools函数中的partial函数及wraps函数
https://www.cnblogs.com/hany-postq473111315/p/12846888.html
gc 模块常用函数
https://www.cnblogs.com/hany-postq473111315/p/12846892.html
hashlib加密算法
https://www.cnblogs.com/hany-postq473111315/p/12846896.html
__slots__属性
https://www.cnblogs.com/hany-postq473111315/p/12846904.html
isinstance方法判断可迭代和迭代器
https://www.cnblogs.com/hany-postq473111315/p/12846908.html
metaclass 拦截类的创建,并返回
https://www.cnblogs.com/hany-postq473111315/p/12846911.html
timeit_list操作测试
https://www.cnblogs.com/hany-postq473111315/p/12846913.html
nonlocal 访问变量
https://www.cnblogs.com/hany-postq473111315/p/12846915.html
pdb 进行调试
https://www.cnblogs.com/hany-postq473111315/p/12846921.html
使用property取代getter和setter方法
https://www.cnblogs.com/hany-postq473111315/p/12846925.html
使用types库修改函数
https://www.cnblogs.com/hany-postq473111315/p/12846932.html
type 创建类,赋予类\静态方法等
https://www.cnblogs.com/hany-postq473111315/p/12846940.html
迭代器实现斐波那契数列
https://www.cnblogs.com/hany-postq473111315/p/12846943.html
创建生成器
https://www.cnblogs.com/hany-postq473111315/p/12846945.html
动态给类的实例对象 或 类 添加属性
https://www.cnblogs.com/hany-postq473111315/p/12846946.html
线程_同步应用
https://www.cnblogs.com/hany-postq473111315/p/12846947.html
垃圾回收机制_合集
https://www.cnblogs.com/hany-postq473111315/p/12846950.html
协程的简单实现
https://www.cnblogs.com/hany-postq473111315/p/12846953.html
实现了__iter__和__next__的对象是迭代器
https://www.cnblogs.com/hany-postq473111315/p/12846956.html
对类中私有化的理解
https://www.cnblogs.com/hany-postq473111315/p/12846958.html
拷贝的一些生成式
https://www.cnblogs.com/hany-postq473111315/p/12846961.html
查看 __class__属性
https://www.cnblogs.com/hany-postq473111315/p/12846966.html
运行过程中给类添加方法 types.MethodType
https://www.cnblogs.com/hany-postq473111315/p/12846970.html
查看对象的引用计数及计数加一
https://www.cnblogs.com/hany-postq473111315/p/12846975.html
浅拷贝和深拷贝
https://www.cnblogs.com/hany-postq473111315/p/12846978.html
点format方式输出星号字典的值是键
https://www.cnblogs.com/hany-postq473111315/p/12846982.html
类可以打印,赋值,作为实参和实例化
https://www.cnblogs.com/hany-postq473111315/p/12846988.html
类可以在函数中创建,作为返回值(返回类)
https://www.cnblogs.com/hany-postq473111315/p/12846992.html
查看某一个字符出现的次数
https://www.cnblogs.com/hany-postq473111315/p/12847012.html
闭包函数
https://www.cnblogs.com/hany-postq473111315/p/12847006.html
自定义创建元类
https://www.cnblogs.com/hany-postq473111315/p/12846996.html
迪杰斯特拉算法(网上找的)
https://www.cnblogs.com/hany-postq473111315/p/12847011.html
装饰器_上
https://www.cnblogs.com/hany-postq473111315/p/12846997.html
装饰器_下
https://www.cnblogs.com/hany-postq473111315/p/12847002.html
Django学习路7_注册app到能够在页面上显示app网页内容
https://www.cnblogs.com/hany-postq473111315/p/12849466.html
Django学习路8_学生表和班级表级联并相互查询信息
https://www.cnblogs.com/hany-postq473111315/p/12852064.html
Django学习路9_流程复习
https://www.cnblogs.com/hany-postq473111315/p/12856419.html
设计模式_理解单例设计模式
https://www.cnblogs.com/hany-postq473111315/p/12856511.html
设计模式_单例模式的懒汉式实例化
https://www.cnblogs.com/hany-postq473111315/p/12856586.html
Django学习路10_创建一个新的数据库,指定列名并修改表名
https://www.cnblogs.com/hany-postq473111315/p/12857363.html
Django学习路11_向数据库中添加 和 获取指定条件数据
https://www.cnblogs.com/hany-postq473111315/p/12859172.html
Django学习路12_objects 方法(all,filter,exclude,order by,values)
https://www.cnblogs.com/hany-postq473111315/p/12859187.html
数据库实验内容,不包括对表的增删改查
https://www.cnblogs.com/hany-postq473111315/p/12862517.html
Django学习路13_创建用户登录,判断数据库中账号名密码是否正确
https://www.cnblogs.com/hany-postq473111315/p/12864746.html
Django学习路14_获取数据库中用户名字并展示,获取指定条数
https://www.cnblogs.com/hany-postq473111315/p/12867317.html
在类外创建函数,然后使用类的实例化对象进行调用
https://www.cnblogs.com/hany-postq473111315/p/12867420.html
Django坑_02
https://www.cnblogs.com/hany-postq473111315/p/12868042.html
Django学习路15_创建一个订单信息,并查询2020年\9月的信息都有哪些
https://www.cnblogs.com/hany-postq473111315/p/12868272.html
Django学习路16_获取学生所在的班级名
https://www.cnblogs.com/hany-postq473111315/p/12868775.html
Django学习路17_聚合函数(Avg平均值,Count数量,Max最大,Min最小,Sum求和)基本使用
https://www.cnblogs.com/hany-postq473111315/p/12868786.html
Django学习路18_F对象和Q对象
https://www.cnblogs.com/hany-postq473111315/p/12870354.html
PageRank算法
https://www.cnblogs.com/hany-postq473111315/p/12871080.html
Python实现数据结构 图
https://www.cnblogs.com/hany-postq473111315/p/12871103.html
Django学习路19_is_delete属性,重写类方法,显性隐性属性
https://www.cnblogs.com/hany-postq473111315/p/12881137.html
Django学习路20_流程复习
https://www.cnblogs.com/hany-postq473111315/p/12881490.html
Django学习路21_views函数中定义字典及html中使用类实例对象的属性及方法
https://www.cnblogs.com/hany-postq473111315/p/12882201.html
Django学习路22_empty为空,forloop.counter 从1计数,.counter0 从0计数 .revcounter最后末尾数字是1,.revcounter0 倒序,末尾为 0
https://www.cnblogs.com/hany-postq473111315/p/12887676.html
Django学习路23_if else 语句,if elif else 语句 forloop.first第一个元素 .last最后一个元素,注释
https://www.cnblogs.com/hany-postq473111315/p/12887789.html
Django学习路24_乘法和除法
https://www.cnblogs.com/hany-postq473111315/p/12890956.html
Django学习路25_ifequal 和 ifnotequal 判断数值是否相等及加减法 {{数值|add 数值}}
https://www.cnblogs.com/hany-postq473111315/p/12891104.html
Django学习路26_转换字符串大小写 upper,lower
https://www.cnblogs.com/hany-postq473111315/p/12891253.html
Django学习路27_HTML转义
https://www.cnblogs.com/hany-postq473111315/p/12898638.html
Django学习路28_ .html 文件继承及,include 'xxx.html'
https://www.cnblogs.com/hany-postq473111315/p/12898808.html
Django学习路29_css样式渲染 h3 标签
https://www.cnblogs.com/hany-postq473111315/p/12899854.html
Django学习路30_view中存在重复名时,取第一个满足条件的
https://www.cnblogs.com/hany-postq473111315/p/12899918.html
Django学习路31_使用 locals 简化 context 写法,点击班级显示该班学生信息
https://www.cnblogs.com/hany-postq473111315/p/12909241.html
分解质因数
https://www.cnblogs.com/hany-postq473111315/p/12910220.html
计算皮球下落速度
https://www.cnblogs.com/hany-postq473111315/p/12910268.html
给定年月日,判断是这一年的第几天
https://www.cnblogs.com/hany-postq473111315/p/12910344.html
Django学习路32_创建管理员及内容补充+前面内容复习
https://www.cnblogs.com/hany-postq473111315/p/12911605.html
Django学习路33_url 地址及删除元素 delete() 和重定向 return redirect('路径')
https://www.cnblogs.com/hany-postq473111315/p/12917747.html
Django学习路34_models 文件创建数据表
https://www.cnblogs.com/hany-postq473111315/p/12920060.html
Django学习路35_视图使用方法(复制的代码) + 简单总结
https://www.cnblogs.com/hany-postq473111315/p/12922362.html
实验1-5
https://www.cnblogs.com/hany-postq473111315/p/12932750.html
学生成绩表数据包括:学号,姓名,高数,英语和计算机三门课成绩,计算每个学生总分,每课程平均分,最高分和最低分
https://www.cnblogs.com/hany-postq473111315/p/12939916.html
四位玫瑰数
https://www.cnblogs.com/hany-postq473111315/p/12940081.html
四平方和
https://www.cnblogs.com/hany-postq473111315/p/12940256.html
学生管理系统-明日学院的
https://www.cnblogs.com/hany-postq473111315/p/12941008.html
定义函数,给定一个列表作为函数参数,将列表中的非数字字符去除
https://www.cnblogs.com/hany-postq473111315/p/12943097.html
给定几位数,查看数根(使用函数实现)
https://www.cnblogs.com/hany-postq473111315/p/12943740.html
水果系统(面向过程,面向对象)
https://www.cnblogs.com/hany-postq473111315/p/12950313.html
matplotlib基础汇总_01
https://www.cnblogs.com/hany-postq473111315/p/12950862.html
matplotlib基础汇总_02
https://www.cnblogs.com/hany-postq473111315/p/12950897.html
matplotlib基础汇总_03
https://www.cnblogs.com/hany-postq473111315/p/12950922.html
matplotlib基础汇总_04
https://www.cnblogs.com/hany-postq473111315/p/12951001.html
根据列表的值来显示每一个元素出现的次数
https://www.cnblogs.com/hany-postq473111315/p/12951610.html
钻石和玻璃球游戏(钻石位置固定)
https://www.cnblogs.com/hany-postq473111315/p/12952401.html
小人推心图(网上代码)
https://www.cnblogs.com/hany-postq473111315/p/12952806.html
0525习题
https://www.cnblogs.com/hany-postq473111315/p/12957586.html
jieba尝鲜
https://www.cnblogs.com/hany-postq473111315/p/12957868.html
inf
https://www.cnblogs.com/hany-postq473111315/p/12968590.html
读取文件进行绘图
https://www.cnblogs.com/hany-postq473111315/p/12968611.html
双约束重力模型
https://www.cnblogs.com/hany-postq473111315/p/12968621.html
未解决问题01
https://www.cnblogs.com/hany-postq473111315/p/12971205.html
Sqlite3 实现学生信息增删改查
https://www.cnblogs.com/hany-postq473111315/p/12953587.html
未解决问题02
https://www.cnblogs.com/hany-postq473111315/p/12971235.html
简单绘图
https://www.cnblogs.com/hany-postq473111315/p/12971256.html
钻石和玻璃球游戏(钻石位置不固定)
https://www.cnblogs.com/hany-postq473111315/p/12971307.html
使用正则匹配数字
https://www.cnblogs.com/hany-postq473111315/p/12971958.html
打包文件一闪而过及导入文件措施
https://www.cnblogs.com/hany-postq473111315/p/12976957.html
文件简单操作
https://www.cnblogs.com/hany-postq473111315/p/12978701.html
0528习题 1-5
https://www.cnblogs.com/hany-postq473111315/p/12978717.html
Django学习路36_函数参数 反向解析 修改404 页面
https://www.cnblogs.com/hany-postq473111315/p/12980002.html
关于某一爬虫实例的总结
https://www.cnblogs.com/hany-postq473111315/p/12980219.html
小技巧_01
https://www.cnblogs.com/hany-postq473111315/p/12983898.html
安装 kreas 2.2.4 版本问题
https://www.cnblogs.com/hany-postq473111315/p/12984543.html
是否感染病毒
https://www.cnblogs.com/hany-postq473111315/p/12985989.html
python文件操作
https://www.cnblogs.com/hany-postq473111315/p/12986729.html
pandas 几个重要知识点
https://www.cnblogs.com/hany-postq473111315/p/12989028.html
一千美元的故事(钱放入信封中)
https://www.cnblogs.com/hany-postq473111315/p/12989353.html
给定两个列表,转换为 DataFrame 类型
https://www.cnblogs.com/hany-postq473111315/p/12989923.html
通过文档算学生的平均分
https://www.cnblogs.com/hany-postq473111315/p/12990789.html
0528习题 11-15
https://www.cnblogs.com/hany-postq473111315/p/12978739.html
0528习题 6-10
https://www.cnblogs.com/hany-postq473111315/p/12978731.html
0528习题 16-20
https://www.cnblogs.com/hany-postq473111315/p/12978750.html
0528习题 21-25
https://www.cnblogs.com/hany-postq473111315/p/12978764.html
0528习题 26-31
https://www.cnblogs.com/hany-postq473111315/p/12978781.html
python 安装 0x000007b错误解决及VC++ 安装第三方库报红
https://www.cnblogs.com/hany-postq473111315/p/12993454.html
读取 csv , xlsx 表格并添加总分列
https://www.cnblogs.com/hany-postq473111315/p/13020328.html
matplotlib 显示中文问题
https://www.cnblogs.com/hany-postq473111315/p/13021265.html
gbk codec can't encode character
https://www.cnblogs.com/hany-postq473111315/p/13024069.html
cmd 安装第三方库问题
https://www.cnblogs.com/hany-postq473111315/p/13030558.html
十进制转换
https://www.cnblogs.com/hany-postq473111315/p/13030835.html
正则表达式巩固_从别的资料上弄下来的
https://www.cnblogs.com/hany-postq473111315/p/13030596.html
pandas巩固
https://www.cnblogs.com/hany-postq473111315/p/13034160.html
numpy巩固
https://www.cnblogs.com/hany-postq473111315/p/13035346.html
Django学习路37_request属性
https://www.cnblogs.com/hany-postq473111315/p/12981943.html
菜鸟教程的 mysql-connector 基础
https://www.cnblogs.com/hany-postq473111315/p/13037118.html
爬虫流程(前面发过的文章的合集)巩固
https://www.cnblogs.com/hany-postq473111315/p/13040839.html
matplotlib示例
https://www.cnblogs.com/hany-postq473111315/p/13047992.html
matplotlib颜色线条及绘制直线
https://www.cnblogs.com/hany-postq473111315/p/13049034.html
matplotlib绘制子图
https://www.cnblogs.com/hany-postq473111315/p/13054122.html
下载数据到csv中(乱码),使用numpy , pandas读取失败 解决方案
https://www.cnblogs.com/hany-postq473111315/p/13054802.html
查看一个数所有的因子及因子的和
https://www.cnblogs.com/hany-postq473111315/p/13059879.html
输入 1,2,4,5,78 返回 (1, 78, 2, 4, 5, 90) 返回形式:最小值 最大值 其余值 及 总和
https://www.cnblogs.com/hany-postq473111315/p/13059889.html
1000以内能被3或5整除但不能被10整除的数的个数为
https://www.cnblogs.com/hany-postq473111315/p/13059900.html
输入数字判断是否是偶数,输出两个质数的和为该偶数的值
https://www.cnblogs.com/hany-postq473111315/p/13059922.html
十进制转换为其他进制(不使用format)
https://www.cnblogs.com/hany-postq473111315/p/13059936.html
字典元组列表常用方法
https://www.cnblogs.com/hany-postq473111315/p/13061946.html
设置x 轴斜体(每次我都百度,这次单独为它发一个)
https://www.cnblogs.com/hany-postq473111315/p/13062468.html
对字典进行排序
https://www.cnblogs.com/hany-postq473111315/p/13080091.html
终于,我还是对自己的博客下手了
https://www.cnblogs.com/hany-postq473111315/p/13087385.html
字符串常用函数总结
https://www.cnblogs.com/hany-postq473111315/p/13112074.html
解决SyntaxError: Non-UTF-8 code starting with '\xbb'问题
https://www.cnblogs.com/hany-postq473111315/p/13113564.html
获取列表中出现的值,并按降序进行排列
https://www.cnblogs.com/hany-postq473111315/p/13120968.html
CSV文件指定页脚
https://www.cnblogs.com/hany-postq473111315/p/13130528.html
重置spyder 解决 gbk 编码不能读取问题
https://www.cnblogs.com/hany-postq473111315/p/13159943.html
使用 eval(input()) 的便利
https://www.cnblogs.com/hany-postq473111315/p/13159954.html
flask的第一次尝试
https://www.cnblogs.com/hany-postq473111315/p/13161637.html
条件表达式
https://www.cnblogs.com/hany-postq473111315/p/13167125.html
安装fiddler 谷歌插件
https://www.cnblogs.com/hany-postq473111315/p/13168359.html
绘图小结
https://www.cnblogs.com/hany-postq473111315/p/13169418.html
今日成果:爬取百度贴吧
https://www.cnblogs.com/hany-postq473111315/p/13170170.html
map,reduce,filter基础实现
https://www.cnblogs.com/hany-postq473111315/p/13171509.html
数据分析小题
https://www.cnblogs.com/hany-postq473111315/p/13173809.html
求最大公约数最小公倍数及整除求余数等
https://www.cnblogs.com/hany-postq473111315/p/13189664.html
matplotlib 去掉坐标轴
https://www.cnblogs.com/hany-postq473111315/p/13193886.html
字符串的三个函数
https://www.cnblogs.com/hany-postq473111315/p/13213108.html
关于这学期的总结
https://www.cnblogs.com/hany-postq473111315/p/13228741.html
转义字符
https://www.cnblogs.com/hany-postq473111315/p/13233072.html
format格式
https://www.cnblogs.com/hany-postq473111315/p/13233095.html
IPython magic命令
https://www.cnblogs.com/hany-postq473111315/p/13246648.html
关键字
https://www.cnblogs.com/hany-postq473111315/p/13246716.html
运算符
https://www.cnblogs.com/hany-postq473111315/p/13246732.html
常用类型转换函数
https://www.cnblogs.com/hany-postq473111315/p/13246740.html
数学方法内置函数
https://www.cnblogs.com/hany-postq473111315/p/13246749.html
字符串常用函数
https://www.cnblogs.com/hany-postq473111315/p/13246759.html
常用内置函数
https://www.cnblogs.com/hany-postq473111315/p/13246765.html
math库常用函数
https://www.cnblogs.com/hany-postq473111315/p/13246775.html
random随机数函数
https://www.cnblogs.com/hany-postq473111315/p/13246781.html
time模块
https://www.cnblogs.com/hany-postq473111315/p/13246790.html
datetime模块
https://www.cnblogs.com/hany-postq473111315/p/13246801.html
列表字典集合常用函数
https://www.cnblogs.com/hany-postq473111315/p/13246827.html
选择结构和循环结构
https://www.cnblogs.com/hany-postq473111315/p/13246839.html
函数调用
https://www.cnblogs.com/hany-postq473111315/p/13246864.html
jieba.lcut方法
https://www.cnblogs.com/hany-postq473111315/p/13246933.html
turtle库常用函数
https://www.cnblogs.com/hany-postq473111315/p/13246941.html
int转换sys,argv参数问题
https://www.cnblogs.com/hany-postq473111315/p/13246955.html
文件基本用法
https://www.cnblogs.com/hany-postq473111315/p/13253872.html
读/写docx文件
https://www.cnblogs.com/hany-postq473111315/p/13253912.html
读/写xlsx文件
https://www.cnblogs.com/hany-postq473111315/p/13253937.html
os模块常用方法
https://www.cnblogs.com/hany-postq473111315/p/13253955.html
pandas属性和方法
https://www.cnblogs.com/hany-postq473111315/p/13254000.html
numpy的random方法和常用数据类型
https://www.cnblogs.com/hany-postq473111315/p/13254012.html
matplotlib常用基础知识
https://www.cnblogs.com/hany-postq473111315/p/13254039.html
学习python的几个资料网站
https://www.cnblogs.com/hany-postq473111315/p/13265849.html
机器学习网址
https://www.cnblogs.com/hany-postq473111315/p/13278370.html
机器学习算法速查表
https://www.cnblogs.com/hany-postq473111315/p/13278528.html
matpltlib 示例
https://www.cnblogs.com/hany-postq473111315/p/13278593.html
statsmodels 示例
https://www.cnblogs.com/hany-postq473111315/p/13278607.html
Biopython 第三方库示例
https://www.cnblogs.com/hany-postq473111315/p/13278677.html
爬取三寸人间
https://www.cnblogs.com/hany-postq473111315/p/13306001.html
爬取图虫网 示例网址 https://wangxu.tuchong.com/23892889/
https://www.cnblogs.com/hany-postq473111315/p/13306056.html
爬虫基础巩固
https://www.cnblogs.com/hany-postq473111315/p/13306114.html
老男孩Django笔记(非原创)
https://www.cnblogs.com/hany-postq473111315/p/13339511.html
import requests
from fake_useragent import UserAgent
from lxml import etree
headers = {
'UserAgent':UserAgent().random
}
title_xpath = "//a[@class='postTitle2 vertical-middle']/span/text()"
title_url_xpath = "//a[@class='postTitle2 vertical-middle']/@href"
url_list = ["https://www.cnblogs.com/hany-postq473111315/default.html?page={}".format(num) for num in range(49,0,-1) ]
file = open('随笔.txt','w')
num = 0
for url in url_list:
print("第{}页随笔获取完毕!".format(num + 1))
num = num + 1
response = requests.get(url,headers = headers)
e = etree.HTML(response.text)
title = e.xpath(title_xpath)
url = e.xpath(title_url_xpath)
for t,u in zip(title[::-1],url[::-1]):
file.write(t + '\n')
file.write(u + '\n')
file.close()
python 打包 在线生成图标网站 http://www.ico51.cn/ 打包命令(带图标) pyinstaller -F -i 图标名称.ico 文件名.py 不带图标 pyinstaller -F 文件名.py
将黑框去掉,使用 -w
pyinstaller -F -w -i favicon.ico 文件名.py
注:此篇随笔为以前的随笔的总结,过于基础的并没有展现,只是将以前的随笔中的重点提取出来了
Python 语言遵循 GPL(GNU General Public Licence) 协议。
GPL 指的是GNU通用公共许可协议,该协议通过提供给作者软件版权保护和许可证保障作者的权益
查看关键字。
help("keywords")
关键字如下:(注:复制代码只复制上一行代码即可,下面为输出结果)
False class from or
None continue global pass
True def if raise
and del import return
as elif in try
assert else is while
async except lambda with
await finally nonlocal yield
break for not
Python具有可扩展性,能够导入使用 C/C++ 语言编写的程序,从而提高程序运行速度。
Python具有可嵌入性,可以把Python程序嵌入到 C/C++ 程序中。
Python支持 GUI 编程,提供多个图形开发界面的库,如 Tkinter ,wxPython ,Jython 等。
学了这么久,tkinter 接触的要明显多余 Jython 和 wxPython ..
在 Windows 中设置环境变量时,打开命令提示框,输入:
path %path%;python的安装目录
Python 的重要环境变量:
PYTHONPATH:使用 import 语句后会从该环境变量进行寻找。
PYTHONSTARTUP:在 Python 启动后,会执行此文件中变量指定的执行代码。
PYTHONCASEOK:写在这里面的环境变量,在导入时模块不区分大小写。
PYTHONHOME:通常存在于 PYTHONSTARTUP 和 PYTHONPATH 目录中,便于切换模块库。
使用 Python 在命令提示符中运行 .py 程序
python 文件名.py 参数 参数
补充:
参数可以使用 sys.args 进行获取
但是是从第2个开始进行获取参数
python2 中使用
#-*-coding:UTF-8-*-
对中文进行编码
以单个下划线开头的变量或方法 _temp ,表示不能够直接访问的类属性,需要通过类提供的接口(函数)进行访问。
当使用 from xx import * 时,_temp不能够被导入。使用者不应该访问 _temp 的变量或方法。
以两个下划线开头的变量 __temp ,可以通过类提供的接口(函数)进行访问。
使用了__xxx 表示的变量或方法,实际上是实现了 名称转写 机制。
__temp 会被转写成 _classname__temp ,避免了使用者的错误访问。
使用 __temp 的类,在被子类继承时,能够避免子类中方法的命名冲突。
定义子类时,往往会使用到父类的 __init__构造方法,实际上为了避免冲突,调用的是_父类名 _initalize() 方法。
输出关键字的另一种方式
import keyword
print(keyword.kwlist)
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break',
'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally',
'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal',
'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
类方法和静态方法在使用装饰器方面(好久没有使用了,有点生疏了)
@classmethod
def eat(cls):
pass
@staticmethod
def eat():
pass
关于 finally 语句,最后一定会执行的问题,有一些遗忘
# 使用 try 语句
try :
pass
except Exception as e:
pass
finally:
pass
使用 ctime 获取当前时间
from time import ctime
print("{}".format(ctime()))
%c 格式化字符及其ASCII码
%s 格式化字符串
%d 格式化整数
%u 格式化无符号整型
%f 格式化浮点数字,可指定小数点后的精度
%e 用科学计数法格式化浮点数
%E 作用同%e,用科学计数法格式化浮点数
print("pi = %.*f" % (3,pi)) #用*从后面的元组中读取字段宽度或精度
# pi = 3.142
print('%010.3f' % pi) #用0填充空白
# 000003.142
print('%-10.3f' % pi) #使用 - 号左对齐
# 3.142
在 Python 中,变量不一定占用内存变量。变量就像是对某一处内存的引用,可以通过变量访问到其所指向的内存中的值,
并且可以让变量指向其他的内存。在 Python 中,变量不需要声明,但是使用变量之前,一定要先对变量进行赋值。
当创建了一个新对象时,Python 会向操作系统请求内存,Python 本身实现了内存分配系统。变量类型指的是变量所指向的内存中 对象 的类型。
Python 中变量赋值使用 = 等号,等号左面为创建的变量,等号右面为需要的值。
变量包含的内容主要包含四个方面:
1.变量的名称:在对变量赋值时也就是创建变量时所使用的名字。注:根据标识符规则。
2.变量保存的数据:通常为赋值时 = 等号 右面的对象。
对象主要包括:
①.数字:int 、float 、complex 、bool、表达式、函数调用返回值等。
数字: int 表示整数,包含正数,负数,0
float 表示浮点数,带有小数点的数
complex 表示复数,实部 + 虚部 J 或 j 均可
bool 布尔类型,True 为真,False 为假
②.字符串:字符串变量、带有" "的字符串、表达式、函数调用的返回值等。
注:Python3 以 Unicode 编码方式编码。
使用双引号 " " 或单引号 ' ' 创建字符串或者进行强制转换 str 。
③.列表:列表变量、带有 [ ] 的对象、表达式、函数调用的返回值等。
使用了 [ ] 的,[ ] 内可以是数字,字符串,字典,元组,列表,集合,表达式等。
④.元组:元组变量、带有逗号的或被( )包围的多个变量或值、表达式、函数调用的返回值等。
空元组 ( )
创建一个只包含数字 1 的元素的元组 (1,) 注:一定要带有 , 号
创建包含多个元素的元组,可以直接用 (元素1,元素2,...,元素n) 赋值
或者元素1,元素2,...,元素n ,使用,逗号进行赋值
⑤.集合:空集合 set( )、使用了{ }的内部为单个变量或值、表达式、函数调用的返回值等。
空集合 set( )
创建多个元素的集合,{元素1,元素2,...,元素n}
注:集合中元素不重复,可利用此特性判断别的序列对象是否存在重复元素。
⑥.字典:字典变量、带有 {键:值} 的变量或值、表达式、函数调用的返回值等。
空字典 { }
创建多个元素的字典,变量名 = {键1:值1,键2:值2,...,键n:值n}
⑦.类:通常为类创建实例时,函数调用的返回值等。
class关键字声明。
⑧.函数:函数名、函数调用等。
def 关键字声明,在函数前可能会有装饰器。另外,函数可以嵌套函数,当内部函数使用了外部函数的某些对象时称为闭包函数。
注:表达式是指关于对象之间的运算。
变量的地址,也就是所指向的内存中的地址。使用 id(变量名) 函数获取。
# 查看 a 的内存地址
a = 123
print(id(a))
# 140734656708688
字典: {键 : 值} 对的元素的集合。字典内部的元素是无序的,通过键来获取键所对应的值。字典中的键是不能够改变的,并且是唯一的。
# 创建一个元素的集合,可以不使用 ,
set_2 = {1}
print(set_2)
# {1}
print(type(set_2))
#
set_3 = {1,}
print(set_3)
# {1}
print(type(set_3))
#
集合中不能包含列表和字典对象
# 负数
num_int_3 = -226
print(type(num_int_3))
#
# 扩大100倍
num_float_3 = 2.5e2
print(num_float_3)
# 250.0
print(type(num_float_3))
#
关于复数 0 进行隐藏问题
num_complex_3 = 3.j
print(num_complex_3)
# 3j
print(type(num_complex_3))
#
num_complex_4 = .6j
print(num_complex_4)
# 0.6j
print(type(num_complex_4))
#
有时判断条件是否成立使用 not True
比如说某一个元素不在列表中使用 not in
Unicode码:主要有三种,分别为 utf-8、utf-16、utf-32。utf-8 占用一到四个字节,utf-16 占用二到四个字节,utf-32 占用四个字节。
Python 在访问时,使用方括号 [ 索引位置 ] ,进行访问。字符串可以进行拼接操作,就是将两个字符串进行拼接,然后产生新的字符串。可以进行切片操作 [ : ] ,(注:左闭右开)。
列表可以进行增加元素、删除元素、查询是否存在该元素、修改某一位置上的元素、查看列表的长度、确定最大最小元素以及对列表排序等。有时候,还可以通过强制转换修改元组。
Python 的元组与列表类似。元组使用小括号 ( ) 包含数据。元组可以通过索引下标进行访问元组中的值。元组中的值不是允许修改的,但是可以对元组进行拼接。
# 创建只包含一个元素的元组
tuple_2 = (1,)
print(type(tuple_1))
#
# 创建包含多个元素的元组
tuple_4 = 7,8,9
print(tuple_4)
# (7, 8, 9)
print(type(tuple_4))
#
字典创建之后,可以使用 字典名['键名'] 进行访问。
增加字典元素,可以直接使用 字典名['新的键'] = 新的值
使用 del 可以将字典元素进行删除。
可以对字典求长度,强制转换,拷贝字典等操作。
注:当后来又添加了新的键,而原来有同名的键时,以后来的为准。
在字典中创建键值对,没有写明: 时,创建的是值
dic = {'a':123,888:'n',(4,5):[7,8]}
dic.keys()
# dict_keys(['a', 888, (4, 5)])
dic.values()
# dict_values([123, 'n', [7, 8]])
# 使用 dict 转化为字典
dic = dict(zip(['a','b','c'],[4,5,6]))
print(dic)
# {'a': 4, 'b': 5, 'c': 6}
Python中的数据类型可以进行相互转换:
1.将 float 浮点型转化成 int 长整型。int( )
2. 将 2,3 转化为复数。complex(实部,虚部)
3.将数字、列表、元组、字典转化为字符串类型。str( ) , json.dumps(字典)
4.将字符串转化为数字类型。eval( )
5.将列表转化成元组。tuple( )
6.将元组转化成列表。list( )
7.将列表转化成集合,用来消除多余重复元素。set( )
8.将字符串转化为集合元素。set( )
9.将整数转化为字符。 chr( )
10.将字符转化为整数。ord( )
11.将十进制整数转化为十六进制数。hex( )
12.将十进制整数转化为八进制数。 oct( )
# 将整数转化为字符。
print(chr(65))
# A
print(chr(90))
# Z
print(chr(97))
# a
print(chr(122))
# z
# 将字符转化为整数。
print(ord('A'))
# 65
# 将十进制整数转化为十六进制数。
print(hex(17))
# 0x11
# 将十进制整数转化为八进制数。
print(oct(9))
# 0o11
Python算术运算符。
算术运算符:
+ :两个对象相加。
-:得到负数 或 前一个数减去后一个数。
* : 两个数进行相乘 或 重复字符串元素、列表元素、元组元素。
/ : 前一个数对后一个数进行除法操作,返回浮点数类型。
%: 取模,返回前一个数除去后一个数的余数。
** : 返回前一个数的后面数次幂。
// : 前一个数对后一个数整除,返回整数部分。
Python 比较运算符,多用于条件判断语句 if 中,返回值为 True (真)或 False (假):
== : 等于,比较两个对象的值是否相等。
!= : 不等于,比较两个对象的值是否不相等。
> : 大于,前面一个数是否大于后面的数。
< : 小于,前面一个数是否小于后面的数。
>= : 大于等于,前面的是是否大于等于后面的数。
<=: 小于等于,前面的数是否小于等于后面的数。
Python赋值运算符:
= : 赋值运算符
+= : 加法赋值运算符
-= : 减法赋值运算符
*= : 乘法赋值运算符
/= : 除法赋值运算符
%= : 取模赋值运算符 ,当前面的数小于后面的数时,返回前一个数本身(数大于 0)。
**= : 幂赋值运算符
//= : 取整赋值运算符
注:a 符号等于 b 等价于 a 等于 a 符号 (b)
# *= 乘法赋值运算符
a = 4
b = 5
a *= b #等价于 a = a * (b)
print("a = {0} , b = {1} ".format(a,b))
# a = 20 , b = 5
# /= 除法赋值运算符
a = 4
b = 5
a /= b #等价于 a = a / (b)
print("a = {0} , b = {1} ".format(a,b))
# a = 0.8 , b = 5
# %= 取模赋值运算符
a = 4
b = 5
a %= b #等价于 a = a % (b)
print("a = {0} , b = {1} ".format(a,b))
# a = 4 , b = 5
a = 6
b = 4
a %= b #等价于 a = a % (b)
print("a = {0} , b = {1} ".format(a,b))
# a = 2 , b = 4
# **= 幂赋值运算符
a = 4
b = 2
a **= b #等价于 a = a ** (b)
print("a = {0} , b = {1} ".format(a,b))
# a = 16 , b = 2
# //= 取整赋值运算符,返回整数
a = 4
b = 3
a //= b #等价于 a = a // (b)
print("a = {0} , b = {1} ".format(a,b))
# a = 1 , b = 3
Python位运算符:将 int 长整型数据看做二进制进行计算,主要是将前面的数和后面的数的对应位置上的数字 0,1 进行判断。
& 按位与:如果对应位置上的两个数都为 1,那么得到的该结果的该位置上也为 1 。其他情况都为 0。
| 按位或:如果对应位置上的两个数有一个为 1 或都为 1,则得到的该结果的该位置上也为 1 。其他情况都为 0。
^ 按位异或:如果对应位置上的两个数为 0 和 1 或 1 和 0,则得到的该结果的该位置上也为 1 。其他情况都为 0。
~ 按位取反:如果~后面为正数或 0,则结果为-(数+1),
如果后面的数为负数,则结果为-(负数(带符号)+1)。
<< 左移运算符:将前面的数乘以 2 的(后面的数) 次幂。
>> 右移运算符:将前面的数除以 2 的(后面的数) 次幂。
# ~ 按位取反:如果后面的为正数,则结果为-(正数+1)
print(~2)
# -3
# 如果后面的数为负数,则结果为-(负数(带符号)+1)。
print(~(-5))
# 4
注意返回的是对象,不是True 和 False
Python逻辑运算符:
and 布尔‘与’: 当左面的对象为真时,返回右面的对象。
当左面的对象不为真时,返回左面的对象。
or 布尔‘或’: 当左面的对象为真时,返回左面的对象。
当左面的对象不为真时,返回右面的对象。
not 布尔'非': 如果后面的对象为True,则返回False。否则返回True。
Python成员运算符:
in:如果左面的对象在右面的对象中,则返回 True,不在则返回 False。
not in:如果左面的对象不在右面的对象中,则返回 True,在则返回 False。
a = 'a'
d = 'd'
dic = {'a':123,'b':456,'c':789}
# 判断 a 是否在 dic 中
# 字典主要是看,是否存在该键
print(a in dic)
# True
# 判断 d 是否在 s 中
print(d in dic)
# False
a = 'a'
d = 'd'
strs = 'abc'
# 判断 a 是否不在 strs 中
print(a not in strs)
# False
# 判断 d 是否不在 strs 中
print(d not in strs)
# True
Python身份运算符:
is :判断左右两个对象内存地址是否相等。
is not :判断左右两个对象内存地址是否不相等。
注:对于不可变类型数据,当引用自相同数据时,is 返回值为 True 。
数字、字符串、元组。
对于可变类型数据,当引用自相同数据时,is not 返回值为 True 。
列表、字典、集合。
# 对于不可变类型数据,引用自相同数据时,is 为真
# 数字
num = 123
num_two = 123
# 输出 num 和 num_two 的地址
print("num地址为:{0},num_two地址为:{1}".format(id(num),id(num_two)))
# num地址为:140729798131792,num_two地址为:140729798131792
print(num is num_two)
# True ,num 和 num_two 指向同一块内存地址
print(num is not num_two)
# False
# 对于可变类型,即使引用自相同数据,内存地址也不相同。is not 为 True
# 列表
lst = [1,2,3]
lst_two = [1,2,3]
# 输出 lst 和 lst_two 的地址
print("lst地址为:{0},lst_two地址为:{1}".format(id(lst),id(lst_two)))
# lst地址为:2781811921480,lst_two地址为:2781811921992
print(lst is lst_two)
# False
print(lst is not lst_two)
# True
Python运算符优先级(从高到低、有括号则最先算括号):
** :指数
~ 按位取反
* 乘法、/ 除法、% 取模、// 整除
+ 加法、- 减法
>> 右移运算、<< 左移运算
& 按位与
^ 按位异或、| 按位或
<= 小于等于、< 小于、> 大于、>= 大于等于
== 是否相等、!= 是否不相等
= 赋值、%= 取模赋值、/= 除法赋值、//= 整除赋值、-= 减法赋值、+= 加法赋值、*= 乘法赋值、**= 幂赋值
is 是、is not 不是 引用自同一地址空间
in 是否在、not in 是否不在
not 非、and 与、or 或
条件语句的几种情况
第一种:
'''
if 条件1:
条件1满足时,需要运行的内容
'''
第二种:
'''
if 条件1:
条件1满足时,需要运行的内容
else:
条件1不满足时,需要运行的内容
'''
第三种:
'''
if 条件1:
条件1满足时,需要运行的内容
elif 条件2:
条件1不满足时,条件2满足,需要运行的内容
'''
第四种:
'''
if 条件1:
当条件1满足时,需要运行的内容
elif 条件2:
当条件1不满足,满足条件2时,需要运行的内容
...
elif 条件n:
前面的 n-1 条条件都不满足,第n条条件满足,需要运行的内容
else:
前面的所有条件都不满足时,需要运行的内容
'''
在 if 中常用的操作运算符:
< 小于、<= 小于等于、> 大于、>= 大于等于、== 等于、!= 不等于
注:可以配合 and、or、not 进行混合搭配。
Python 中的循环包括 for 循环和 while 循环。
while 循环,当给定的判断条件为 True 时,会执行循环体,否则退出循环。(可能不知道具体执行多少次)
for 循环,重复执行某一块语句,执行 n 次。
在 Python 中可以进行嵌套使用循环。while 中包含 for ,或 for 包含 while。
Python循环控制语句:主要有三种,break、continue 和 pass 语句。
break 语句 :在语句块执行过程中,终止循环、并跳出整个循环。
continue 语句 :在语句执行过程中,跳出本次循环,进行下一次循环。
pass 语句 :空语句,用来保持结构的完整性。
Python while循环语句(代码块中要有使判断条件不成立的时候、否则会陷入无限循环):
第一种结构:
'''
while 判断条件:
一行语句 或 多行语句组
'''
第二种结构、else 表示只有程序正常运行才会进行使用的代码块:
'''
while 判断条件:
一行语句 或 多行语句组
else:
一行语句 或 多行语句组
'''
Python 无限循环:在 while 循环语句中,可以通过让判断条件一直达不到 False ,实现无限循环。
Python while 循环中使用 else 语句:
else:表示 while 中的语句正常执行完,然后执行 else 语句的部分。
示例:
while 判断条件:
一行语句 或 多行语句组
else:
一行语句 或 多行语句组
Python for 循环语句:遍历任何序列的项目,可以是字符串、列表、元组、字典、集合对象
for 中的 else 依旧为正常执行之后会进行输出的代码块
第一种:
'''
for 迭代对象 in 序列:
代码块(一行语句或多行代码)
'''
第二种:
'''
for 迭代对象 in 序列:
代码块(一行语句或多行代码)
else:
代码块(一行语句或多行代码)
'''
Python for 循环通过序列索引迭代:
注:集合 和 字典 不可以通过索引进行获取元素,因为集合和字典都是无序的。
使用 len (参数) 方法可以获取到遍历对象的长度。
使用 range 方法(左闭右开):
range 函数参数如下,起始位置、终止位置(不包含)、步长。
注:起始位置默认为 0 。
步长可以为负,默认为 1。
lst = [i for i in range(5)]
print(lst) # 起始位置默认为 0
# [0, 1, 2, 3, 4]
lst = [i for i in range(1,5)]
print(lst) # 不包含终止位置
# [1, 2, 3, 4]
lst = [i for i in range(1,5,2)]
print(lst) #步长可以根据自己需要进行更改
# [1, 3]
lst = [i for i in range(-5,-1,1)]
print(lst) # 起始位置和终止位置可以为负
# [-5, -4, -3, -2]
通过序列索引进行迭代操作程序:
字符串:
strs = "Hello World."
for i in range(len(strs)):
print(strs[i],end = " ")
# H e l l o W o r l d .
Python循环嵌套:将 for 循环和 while 循环进行嵌套。
示例:
while 循环嵌套 for 循环:
while True:
for i in range(3):
print("while 和 for 进行嵌套")
break
# while 和 for 进行嵌套
# while 和 for 进行嵌套
# while 和 for 进行嵌套
for 循环嵌套 while 循环、不推荐进行使用:
a = 1
for i in range(3):
while a < 3:
print("while 和 for 进行嵌套")
a += 1
# while 和 for 进行嵌套
# while 和 for 进行嵌套
关于 break 的理解
Python break语句:当运行到 break 语句时,终止包含 break 的循环语句。
注:无论判断条件是否达到 False 或 序列是否遍历完都会停止执行循环语句和该 break 下的所有语句。
当使用循环嵌套时,break 语句将会终止最内层的 while 或 for 语句、然后执行外一层的 while 或 for 循环。
lst = [7,8,9,4,5,6]
for i in range(len(lst)):
if lst[i] == 4:
print("循环终止")
break #终止循环语句
print(lst[i],end = " ")
# 7 8 9 循环终止
关于 continue 的理解
当执行到 continue 语句时,将不再执行本次循环中 continue 语句接下来的部分,而是继续下一次循环
lst = [7,8,9,4,5,6]
for i in range(len(lst)):
if lst[i] == 9:
continue
#当运行到 continue 语句时,不执行本次循环中剩余的代码,而是继续下一层循环
print(lst[i],end = " ")
# 7 8 4 5 6
Python pass语句:空语句,主要用于保持程序结构的完整性 或者 函数想要添加某种功能,但是还没有想好具体应该怎么写。
Python数字类型转换:
int(x):将 x 转换为一个整数
float(x):将 x 转换为一个浮点数
complex(x,y):将 x 和 y 转换为一个复数。x 为复数的实部,y 为复数的虚部。
eval(x):将 x 转化为一个整数
chr(x):x 为数字,将数字转化为对应的 ASCII 码。 65 -> A 、90 -> Z
ord(x):x 为单个字符,将字符转换为对应的整数。 a -> 97、122 -> z
# 将 2,3 转化为复数
num_complex = complex(2,3)
print(num_complex)
# (2+3j)
print(type(num_complex))
#
Python数学函数
abs(x)
返回数字的绝对值,如abs(-10) 返回 10
math.ceil(x)
返回数字的上入整数,如math.ceil(4.1) 返回 5
math.exp(x)
返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045
fabs(x)
返回数字的绝对值,如math.fabs(-10) 返回10.0
floor(x)
返回数字的下舍整数,如math.floor(4.9)返回 4
log(x)
如math.log(math.e)返回1.0,math.log(100,10)返回2.0
log10(x)
返回以10为基数的x的对数,如math.log10(100)返回 2.0
max(x1, x2,...)
返回给定参数的最大值,参数可以为序列。
min(x1, x2,...)
返回给定参数的最小值,参数可以为序列。
modf(x)
返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。
pow(x, y)
x**y 运算后的值。
round(x [,n])
返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。
其实准确的说是保留值将保留到离上一位更近的一端。
sqrt(x)
返回数字x的平方根。
# math.floor(x) 返回比 x 稍小的整数
print(math.floor(-5.9),math.floor(8.6))
# -6 8
# math.modf(x) 返回 x 的整数部分与小数部分,
# 两部分的数值符号与x相同,整数部分以浮点型表示。
print(math.modf(-5.9),math.modf(8.6))
# (-0.9000000000000004, -5.0) (0.5999999999999996, 8.0)
# math.round(x[,n]) # n 为保留的位数,将 x 进行四舍五入输出
print(round(-5.984,2),round(8.646,2))
# -5.98 8.65
# math.log(x) log 以 e 结尾,e 的 返回值 为 x
print(math.log(math.e),math.log(math.e ** 2))
# 1.0 2.0
Python随机数函数:
choice(seq)
从序列的元素中随机选出一个元素
randrange ([start,] stop [,step])
从指定范围内,在指定步长递增的集合中 获取一个随机数,步长默认为 1 。注:不包含 stop 值
random()
随机生成下一个实数,它在[0,1)范围内。
shuffle(lst)
将序列的所有元素随机排序,返回值为 None
uniform(x, y)
随机生成下一个实数,它在[x,y]范围内。
python 三角函数
math.sin(x)
返回的x弧度的正弦值。
math.asin(x)
返回x的反正弦弧度值。
math.cos(x)
返回x的弧度的余弦值。
math.acos(x)
返回x的反余弦弧度值。
math.tan(x)
返回x弧度的正切值。
math.atan(x)
返回x的反正切弧度值。
math.degrees(x)
将弧度转换为角度,如degrees(math.pi/2) , 返回90.0
math.radians(x)
将角度转换为弧度
math.hypot(x, y)
返回 sqrt(x*x + y*y) 的值。
import math
# π/2 的正弦值
print(math.sin(math.pi/2))
# 1.0
# 1 的反正弦值
print(math.asin(1))
# 1.5707963267948966 π/2
# π 的余弦值
print(math.cos(math.pi))
# -1.0
# -1 的反余弦值
print(math.acos(-1))
# 3.141592653589793
# 四分之三 π 的正切值
print(math.tan(math.pi*3/4))
# -1.0000000000000002
# 使用 math.degrees(x) 函数查看 四分之一 π 的角度
print(math.degrees(math.pi/4))
# 45.0
# 使用 math.radians(x) 函数查看 135° 对应的弧度制
print(math.radians(135))
# 2.356194490192345
print(math.pi*3/4)
# 2.356194490192345
# math.hypot(x, y) 查看 sqrt(x*x + y*y) 的值
print(math.hypot(3,4))
# 5.0
print(math.hypot(6,8))
# 10.0
print(math.sqrt(6*6 + 8*8))
# 10.0
Python数学常量:
math.pi:π
math.e:自然常数 e
# lg 函数中求值
a = math.e
b = math.e ** 5
print("ln(a)的值为:",math.log(a))
# ln(a)的值为: 1.0
print("ln(b)的值为:",math.log(b))
# ln(b)的值为: 5.0
Python创建字符串:
一般情况下可以使用 ' 或 " 创建字符串 或 使用引用字符串变量 或 字符串表达式。
# 使用字符串表达式进行赋值
a = 'ABCD'
b = 'EFG'
c = a + b
print(c)
Python访问字符串中的值:
1.可以使用索引下标进行访问,索引下标从 0 开始:
# 使用索引下标进行访问,索引下标从 0 开始
strs = "ABCDEFG"
print(strs[0])
# A
2.使用切片操作获取字符串:
示例:[start:stop:step]
start :需要获取的字符串的开始位置,默认为 0 。(通常可以不写)
stop :需要获取的字符串的结束位置 的后一个位置。
step :步长,默认为 1 、当 start 大于 stop 时,step 为负数。
# 使用[start:stop:step]切片操作获取字符串
strs = "ABCDEFG"
print(strs[:4])
# ABCD
print(strs[:4:2])
# AC
print(strs[2:6])
# CDEF
print(strs[2:6:2])
# CE
# 不包含结束位置
print(strs[6:2:-1])
# GFED
print(strs[6:2:-2])
# GE
3.通过 for 循环进行获取字符串:
strs = "ABCDEFG"
for i in strs:
# 其中 i 为字符串中的单个字母
# 注:此时的 i 不要用做索引下标
print(i,end =" ")
# A B C D E F G
Python字符串更新:截取字符串的某一部分 和 其他字符串进行拼接。
注:可以修改字符串的值,但修改的不是内存中的值,而是创建新的字符串。
1.使用字符串常量进行更新:
# 使用字符串常量
strs = "hello,hey"
print(strs[:6] + "world.")
# hello,world.
2.使用切片操作(不包含结尾 stop)进行更新:
strs = "hello,hey"
py = "Tom,Jerry"
s_2 = strs[:5] + py[3:]
print(strs[:5])
# hello
print(py[3:])
# ,Jerry
print("更新后的字符串:",s_2)
# 更新后的字符串: hello,Jerry
修改字符串:
# 修改字符串,将 world 修改为 python
strs = "hello,world"
strs = strs[:6] + "python"
print("更新后的字符串:{0}".format(strs))
# 更新后的字符串:hello,python
Python转义字符:当需要在字符串中使用特殊字符时,使用 \ 转义字符。
注:转义字符在字符串中,注释也是字符串类型。
\(在行尾时):续行符
\\ :反斜杠符号
\' :单引号
\" :双引号
\a :响铃
\b :退格(Backspace)
\000:空
\n :换行
\v :纵向制表符
\t :横向制表符
\r :回车
Python字符串运算符:
+ :连接左右两端的字符串。
* :重复输出字符串。
[ ] :通过索引获取字符串中的值。
[start:stop:step]:开始,结束位置的后一个位置,步长。
in :判断左端的字符是否在右面的序列中。
not in:判断左端的字符是否不在右面的序列中。
r/R :在字符串开头使用,使转义字符失效。
Python字符串格式化:
字符串中符号:
%c :单个字符
%s :字符串
%d :整数
%u :无符号整数
%o :无符号八进制数
%x :无符号十六进制数
%X :无符号十六进制数(大写)
%f :浮点数,可指定小数点后的精度
%e :对浮点数使用科学计数法,可指定小数点后的精度。%E 与 %e 作用相同
%g :%f 和 %e 的简写,%G 与 %g 作用相同
注:%o 为八进制(oct)、%x 为十六进制(hex)。
# %o 八进制数
num = 11
print("%o"%(num))
# 13 1*8**1 + 3*8**0 = 11
print(oct(11))
# 0o13
# %x 十六进制数
num = 18
print("%x"%(num))
# 12 1*16**1 + 2*8**0 = 18
print(hex(num))
# 0o12
# %e 科学计数法
num = 120000
print("%e"%(num))
# 1.200000e+05
print("%.2e"%(num))
# 1.20e+05
print("%E"%(num))
# 1.200000E+05
print("%.2E"%(num))
# 1.20E+05
# %g : %f 和 %e 的简写
num = 31415926
print("%g"%(num))
# 3.14159e+07
print("%G"%(num))
# 3.14159E+07
格式化操作符的辅助指令:
* :定义宽度 或 小数点精度
- : 左对齐
+ : 使正数显示符号
:在正数前显示空格
# :在八进制前显示 0 ,在十六进制前显示 0x 或 0X
0 :显示的数字前面填充 '0'
% :%%输出单个%
(var) :字典参数映射变量
m.n. :m是显示的宽度,n 是小数点后的位数
Python三引号:多用作注释、数据库语句、编写 HTML 文本
UTF-8 编码将英文字母编码成一个字节,汉字通常是三个字节。适用于存在大量英文字符时,节省空间
Python字符串内建函数:
注:汉字属于字符(既是大写又是小写)、数字可以是: Unicode 数字,全角数字(双字节),罗马数字,汉字数字。
1.capitalize( ):
将字符串第一个字母大写
# 使用 字符串.capitalize() 方法将字符串首字母大写
strs = 'abc'
print(strs.capitalize())
# Abc
2.center(width[,fillchar]) :
让字符串在 width 长度居中,两边填充 fillchar 字符(默认是空格)
# center(width,fillchar)
# 使用 字符串.center() 方法,将字符串在 width 长度居中,两边补充 fillchar
strs = 'abcdefgh'
print(strs.center(20,'-'))
#------abcdefgh------
3.count(str,start=0,end=len(string)):
返回 str 在字符串从 start 到 end 范围内出现的次数(不包含end)。
# 使用 字符串.count(str) 方法,返回 str 在 字符串中出现的次数
strs = 'abcdefghabcd'
print(strs.count('c'))
#2
# 使用 字符串.count(str) 方法,返回 str 在 字符串中出现的次数
strs = 'abcdefghabcd' # a 的索引位置为 0,8
print(len(strs)) # 12
print(strs.count('a',2,8))
# 0
print(strs.count('a',2,9))
# 1
4.bytes.decode(encoding="UTF-8"):
将字节码转换为字符串
strs_bytes = b'\xe6\xac\xa2\xe8\xbf\x8e'
print(strs_bytes.decode(encoding='UTF-8'))
# 欢迎
5.encode(encoding='UTF-8'):
将字符串转换为字节码
strs = '欢迎'
print(strs.encode(encoding='UTF-8'))
# b'\xe6\xac\xa2\xe8\xbf\x8e'
6.endswith(str[,start[,end]]):
判断字符串在 start 到 end 是否以 str结尾
# 字符串.endswith(str[,start[,end]])
strs = 'ABCDEFG'
print(strs.endswith('G'))
# True
print(strs.endswith('F',0,6))
# True
7.expandtabs(tabsize = 4):
将字符串中的 tab 符号转换为空格,tabsize 为替换的空格数
# 字符串.expandtabs(tabsize = 4)
# 将字符串中的 tab 符号转换为空格,tabsize 为替换的空格数
strs = 'ABCD EFG'
print(strs.expandtabs(tabsize = 4))
# ABCD EFG
8.find(str,start = 0,end = len(string)):
在 start 到 end 范围内寻找 str 元素,如果找到则返回 str 元素的索引位置,否则返回 -1。
# find(str,start = 0,end = len(string)):
# 在 start 到 end 范围内寻找 str 元素,如果找到则返回 str 元素的索引位置,否则返回 -1
strs = 'ABCDEFG' #索引位置,从 0 开始
print(strs.find('E'))
# 4
print(strs.find('K'))
# -1
9.index(str,start = 0,end = len(string)):
在 start 到 end 范围内寻找 str 元素,如果找到则返回 str 元素的索引位置,找不到则会报错。
# index(str,start = 0,end = len(string)):
# 在 start 到 end 范围内寻找 str 元素,如果找到则返回 str 元素的索引位置,找不到则返回-1。
strs = 'ABCDEFG'
print(strs.index('F'))
# 5
10.isalnum( ):
如果字符串所有字符都是 字母 或者 数字 则返回 True,否则返回 False。
# isalnum( ):
# 如果字符串所有字符都是 字母 或者 数字 则返回 True,否则返回 False。
strs = 'abcd123'
print(strs.isalnum())
# True
strs = '好的'
print(strs.isalnum())
# True
strs = 'abc_'
print(strs.isalnum())
# False
11.isalpha( ):
如果字符串中所有字符都是字母则返回 True,否则返回 False。
# isalpha( ):
# 如果字符串中所有字符都是字母则返回 True,否则返回 False。
strs = 'ABCD汉字'
print(strs.isalpha())
# True
strs_two = 'ABCD123'
print(strs_two.isalpha())
# False
12.isdigit( ):
如果字符串中所有字符都是数字则返回True,否则返回 False。
# isdigit( ):
# 如果字符串中所有字符都是数字则返回True,否则返回 False。
# 注: ① 也是数字
strs = '①②12'
print(strs.isdigit())
# True
strs_two = 'ABCD123'
print(strs_two.isdigit())
# False
13.islower( ):
如果字符串中所有能够区分大小写的字符都是小写的,则返回True。否则返回 False。
# islower( ):
# 如果字符串中所有字符都是小写的,则返回True。否则返回 False。
strs = 'abcd'
print(strs.islower())
# True
strs_two = 'abc123'
print(strs.islower())
# True
strs_three = 'Abcd'
print(strs_three.islower())
# False
14.isnumeric( ):
如果字符串只包含数字字符,则返回 True。否则返回 False。
# isnumeric( ):
# 如果字符串只包含数字字符,则返回 True。否则返回 False。
strs = '123456'
print(strs.isnumeric())
#True
strs_two = '½⅓123①②ⅡⅣ❶❷'
print(strs_two.isnumeric())
# True
strs_three = 'abc123A'
print(strs_three.isnumeric())
# False
15.isspace( ):
如果字符串只包含空格,则返回True。否则返回False。
# isspace( ):
# 如果字符串只包含空格,则返回True。否则返回False。
strs = ' '
print(strs.isspace())
# True
strs = ' 1'
print(strs.isspace())
# False
16.istitle( ):
如果所有被空格分割成的子字符串的首字母都大写,则返回 True。否则返回 False。
# istitle( )
# 如果所有被空格分割成的子字符串的首字母都大写,则返回 True。否则返回 False。
strs = 'Hello World'
print(strs.istitle())
# True
strs_two = 'Welcome to Harbin'
print(strs_two.istitle())
# False
strs_three = 'World T12'
print(strs_three.istitle())
# True
17.isupper( ) :
如果字符串中所有能够区分大小写的字符都是大写的,则返回True。否则返回 False。
# isupper( ) :
# 如果字符串中所有能够区分大小写的字符都是大写的,则返回True。否则返回 False。
strs = 'ABCD123汉字'
print(strs.isupper())
# True
strs_two = 'ABCabc汉字'
print(strs_two.isupper())
# False
Python字符串内建函数:
1.join(str) :
使用调用的字符串对 str 进行分割,返回值为字符串类型
# join(str) :
# 使用调用的字符串对 str 进行分割。
strs = "Hello"
strs_two = ' '.join(strs)
print(strs_two)
# H e l l o
print(','.join(strs))
# H,e,l,l,o
2.len(string):
返回字符串的长度
# len(string):
# 返回字符串的长度
strs = 'happy'
print(len(strs))
# 5
3.ljust(width[,fillchar]): 之前的是 center 函数,也可以进行填充。
字符串左对齐,使用 fillchar 填充 width 的剩余部分。
# ljust(width[,fillchar]):
# 字符串左对齐,使用 fillchar 填充 width 的剩余部分。
strs = 'Hello'
print(strs.ljust(20,'-'))
# Hello---------------
# fillchar 默认为空
print(strs.ljust(20))
# Hello
4.lower( ):注:使用了 lower 函数后,原来的字符串不变。
将字符串所有能够区分大小写的字符都转换为小写字符。
# lower( ):
# 将字符串所有能够区分大小写的字符都转换为小写字符。
strs = 'Hello 123'
print(strs.lower())
# hello 123
print(type(strs.lower()))
#
# 原来的字符串没有发生改变
print(strs)
# Hello 123
# 使用字符串接收 lower 函数的返回值
strs = strs.lower()
print(strs)
# hello 123
5.lstrip(str):
将字符串最左面的 str 部分去除,输出剩余的部分(str 默认为空格)。
#lstrip( ):
# 将字符串左面的空格部分去除,输出剩余的部分。
strs = ' hello'
print(strs.lstrip())
# hello
print(strs)
# hello
# 使用 lstrip('过滤的参数') 函数,将最左面的 a 过滤掉
strs = 'abcd'
print(strs.lstrip('a'))
# bcd
6.maketrans(参数1,参数2):调用后,使用字符串.translate函数对字符串进行替换。
创建字符映射的转换表。
参数 1 是需要转换的字符
参数 2 是转换的目标
# maketrans(参数1,参数2):
# 创建字符映射的转换表。
# 参数 1 是需要转换的字符
# 参数 2 是转换的目标
# 将 abcd 使用 1234 替换
keys = 'abcd'
values = '1234'
tran = str.maketrans(keys,values)
print(type(tran)) #
# 使用 字符串.translate(接收了 maketrans 函数的对象)
strs = 'abcdef'
print(strs.translate(tran))
# 1234ef
7.max(str):
返回 str 中最大的字母,小写字母的 Unicode 编码比大写字母的 Unicode 编码大。
# max(str):
# 返回 str 中最大的字母
strs = 'abcABC'
print(max(strs))
# c
strs = 'ABCDE'
print(max(strs))
# E
8.min(str):
返回 str 中最小的字母,大写字母的 Unicode 编码比小写字母的 Unicode 编码小。
# min(str):
# 返回 str 中最小的字母
strs = 'abcABC'
print(min(strs))
# A
strs = 'ABCDE'
print(min(strs))
# A
9.replace(old,new[,num]):
将旧字符串替换为新的字符串,num 为最多替换的次数。(默认为全部替换)
# replace(old,new[,num]):
# 将旧字符串替换为新的字符串,num 为替换的次数。
strs = 'abc abc abc abc'
print(strs.replace('abc','ABC'))
# ABC ABC ABC ABC
# 替换 3 次
print(strs.replace('abc','ABC',3))
# ABC ABC ABC abc
10.rfind(str,start = 0,end = len(string)):
从字符串的最右面查找 str
# rfind(str,start = 0,end = len(string)):
# 从字符串的最右面查找 str,不包含end
strs = 'happy happy' # h 的索引位置分别为 0,6
print(strs.rfind('h'))
# 6
# y 的索引位置分别为 4,10
# 在 索引位置 2 到 11 之间进行查找
print(strs.rfind('y',2,11))
# 10
11.rindex(str,start = 0,end = len(string)):
从字符串右面开始寻找 str ,返回索引值、找不到则报错。
# rindex(str,start = 0,end = len(string)):
# 从字符串右面开始寻找 str ,返回索引值
strs = 'happy happy' # a 的索引位置为 1,7
print(strs.rindex('a'))
# 7
12.rjust(width[,fillchar]):
返回一个以字符串右对齐,使用 fillchar 填充左面空余的部分的字符串
# rjust(width[,fillchar]):
# 返回一个以字符串右对齐,使用 fillchar 填充左面空余的部分的字符串
strs = 'hello'
print(strs.rjust(20))
# hello
print(strs.rjust(20,'*'))
# ***************hello
13.rstrip(str):
删除字符串最右面的 str 字符,str默认为空格
注:遇到不是 str 字符才停止删除
# rstrip(str):
# 删除字符串最右面的 str 字符,str默认为空格
strs = 'hello '
print(strs.rstrip())
# hello
strs = 'hello aaaaa'
print(strs.rstrip('a'))
# hello
14.split(str,num):
对字符串使用 str 进行分割,如果 num有指定值,则分割 num次(默认为全部分割)
# split(str=" ",num=string.count(str)):
# 对字符串使用 str 进行分割,如果 num有指定值,则分割 num次(默认为全部分割)
strs = 'hahahah'
print(strs.split('a'))
# ['h', 'h', 'h', 'h']
# 对字符串进行切割两次
print(strs.split('a',2))
# ['h', 'h', 'hah']
15.splitlines(is_keep):
按照 回车\r 、换行\n 对字符串进行分割。
is_keep :当 is_keep 为 True 时,返回值保留换行符。
当 is_keep 为 False 时,返回值不包留换行符。
# splitlines(is_keep):
#
# 按照 回车\r 、换行\n 对字符串进行分割。
# is_keep :当 is_keep 为 True 时,返回值保留换行符。
# 当 is_keep 为 False 时,返回值不包留换行符。
strs = "a\r\nb\nc"
# True则保留换行符和回车,False则不保存
print(strs.splitlines(True))
# ['a\r\n', 'b\n', 'c']
print(strs.splitlines())
# ['a', 'b', 'c']
16.startswith(str,start = 0,end = len(string)):
查看在字符串的 start 到 end-1 的区间中,是否以 str 开头。
# startswith(str,start = 0,end = len(string)):
# 查看在字符串的 start 到 end-1 的区间中,是否以 str 开头。
strs = 'hello , hey , world'
print(strs.startswith('hello'))
# True
print(strs.startswith('hey',8,13))
# True
print(strs[8:13])
# hey ,
17.strip(str):
返回在最左端和最右端都删除 str 的字符串。
注:遇到其他字符则停止。
# strip(str):
# 返回在最左端和最右端都删除 str 的字符串。
# 注:遇到其他字符则停止,只要是 str 进行删除、不限次数。
strs = 'ABCDEABCD'
print(strs.strip('A'))
# BCDEABCD
# 右端字符因为遇到了D,所以停止了。
strs = 'ABCDEABCDAAA'
print(strs.strip('A'))
# BCDEABCD
strs = 'ABCDEABCD'
# 如果最左和最右两端都没有 str ,则不进行删除
print(strs.strip('E'))
# ABCDEABCD
18.swapcase( ):
将能够区分大小写的字符,大小写互换。
# swapcase( ):
# 将能够区分大小写的字符,大小写互换。
strs = 'ABCDabcdefg'
print(strs.swapcase())
# abcdABCDEFG
19.title( ):
将字符串变为每一个单词都是大写字母开头,其余字母为小写或数字。
# title( ):
# 将字符串变为每一个单词都是大写字母开头,其余字母为小写或数字。
strs = 'hello world abc123'
print(strs.title())
# Hello World Abc123
20.translate(字典 或 接收了字符串.maketrans(被替换元素,替换元素)的对象):
将字符串按照参数进行转换
# translate(字典 或 接收了字符串.maketrans(被替换元素,替换元素)的对象):
# 将字符串按照参数进行转换
keys = 'abcd'
values = '1234'
tran = str.maketrans(keys,values)
print(type(tran)) #
# 使用 字符串.translate(接收了 maketrans 函数的对象)
strs = 'abcdef'
print(strs.translate(tran))
# 1234ef
21.upper( ):
将所有能够区分大小写的字符都转换为大写
# upper():
# 将所有能够区分大小写的字符都转换为大写
strs = 'hello World'
print(strs.upper())
# HELLO WORLD
22.zfill(width):
返回长度为 width 的字符串,在左端填充 0
# zfill(width):
# 返回长度为 width 的字符串,在左端填充 0
strs = 'hello'
print(strs.zfill(10))
# 00000hello
23.isdecimal( ):
字符串是否只包含十进制数,其余进制都返回False。
# isdecimal( ):
# 字符串是否只包含十进制数
# 二进制
strs_bin = '0b11'
print(strs_bin.isdecimal())
# False
# 八进制
strs_oct = '0o56'
print(strs_oct.isdecimal())
# 十六进制
strs_hex = '0xa4'
print(strs_hex.isdecimal())
# False
strs_int = '123'
print(strs_int.isdecimal())
# True
Python列表:在 [ ] 中括号 中添加元素 或者 通过 list 转换其他类型。
列表(个人总结):
1.列表是可变类型,即可以使用列表内置方法对列表进行增删查改排序操作
常用的增删查改排序方法:
增 :append、extend、insert、+ 连接、
删 :pop、remove、clear、del
查 : in、not in、for循环迭代等
改 : 列表变量[索引下标] = 元素、切片修改
排序: sort、sorted
2.列表是序列对象,即列表的索引下标从 0 开始,依次递增,最后一个元素为-1,从右向左依次递减
3.列表可以包含所有数据类型:数字、字符串、列表、元组、集合、字典
4.列表是可迭代对象,即可以进行 for 循环(推荐使用列表推导式)
5.列表可以进行切片操作 [start:end:step] (不包含end)
6.列表可以查看元素出现的次数 count 和 元素的位置(索引下标) index
7.获取列表的长度 len
注:列表还有很多其他的 用法 和 功能,以上只是常见的
访问列表元素:
通过索引下标:
# 通过索引下标获取列表元素
lst = [1,4,7,2,5,8]
print("lst 的第一个元素是",lst[0])
# lst 的第一个元素是 1
print("lst 的第四个元素是",lst[3])
# lst 的第四个元素是 2
通过切片进行获取:
# 切片 [start(默认为 0 ),end(一直到 end-1 位置),step(默认为 1 )]
# 默认的都可以省略不写
# 列表翻转
lst = [1,4,7,2,5,8] # 8 的索引位置是 5
print(lst[::-1])
# [8, 5, 2, 7, 4, 1]
print(lst[2:5]) #不包含 5
# [7, 2, 5]
print(lst[2:5:2]) #不包含 5
# [7, 5]
Python更新列表:
使用索引下标进行更新:
# 修改列表的第 6 个元素为 d
lst = ['a','b','c',1,2,3]
lst[5] = 'd'
print(lst)
# ['a', 'b', 'c', 1, 2, 'd']
使用切片对列表进行更新:
# 修改列表的第2个元素到最后为 hey
lst = ['a','b','c',1,2]
lst[2:] = 'hey'
print(lst)
# ['a', 'b', 'h', 'e', 'y']
# 修改列表的第3个元素到第8个元素为 hello
lst = [1,2,3,'a','b','c','d','e',4,5,6]
lst[3:8] = 'hello'
print(lst)
# [1, 2, 3, 'h', 'e', 'l', 'l', 'o', 4, 5, 6]
使用 append 方法增加元素:
# 使用 append 方法对列表进行更新
lst = ['a','b','c',1,2,3]
lst.append('d')
print(lst)
# ['a', 'b', 'c', 1, 2, 3, 'd']
Python删除列表元素:
pop( ):
删除最后一个元素,返回该元素的值
# 使用 pop 方法删除列表中的元素
lst = ['a','b','c',1,2,3]
print(lst.pop())
# 3 ,pop方法删除最后一个元素并返回它的值
print(lst)
# ['a', 'b', 'c', 1, 2]
remove(str):
在列表中删除 str 元素,无返回值
注:当列表中不存在 str 元素时,则会报错
lst = ['A','B','C','D']
print(lst.remove('C'))
# None
print(lst)
# ['A', 'B', 'D']
remove(str):
# 将 str 从列表中删除一次
# 当列表中存在多个 str 元素时,只删除一次
lst = ['a','b','c','d','a']
lst.remove('a')
print(lst)
# ['b', 'c', 'd', 'a']
del 元素:
删除列表中的元素 或 整个列表
# 使用 del 方法删除列表的第 3 个元素
lst = ['A','B','C','D']
del lst[2]
print(lst)
# ['A', 'B', 'D']
# 删除整个 lst 列表
del lst
Python列表脚本操作符:
len(列表名):
查看列表长度
列表对象 1 + 列表对象 2 :
将两个列表进行组合,有时可用于赋值
lst = [1,2,3,4]
lst_two = [7,8,9]
print(lst + lst_two)
# [1, 2, 3, 4, 7, 8, 9]
成员运算符 in 、not in:
判断左端元素是否在右端列表中
lst = ['a','b','c']
print('a' in lst)
# True
将列表用作可迭代对象
lst = [1,2,3,'a','b','c']
for i in lst:
print(i,end = " ")
# 1 2 3 a b c
# 注:此时的 i 不是数字,而是列表中的元素,不要用于索引下标
Python列表函数和方法:
函数:
len(列表名):
返回列表长度
# len(列表名):
# 返回列表长度
lst = [1,2,3,'a','b','c']
print("lst 列表的长度为 %d"%(len(lst)))
# lst 列表的长度为 6
max(列表名):
返回列表元素的最大值
注:列表内的元素一定要是同一类型,都是字母 或 数字
# max(列表名):
# 返回列表元素的最大值
# 注:列表内的元素一定要是同一类型,都是字母 或 数字
lst = [8,4,5,6,9]
print(max(lst))
# 9
lst = ['a','b','c','A','B','C']
print(max(lst))
# c
min(列表名):
返回列表元素的最小值
注:列表内的元素一定要是同一类型,都是字母 或 数字
# min(列表名):
# 返回列表元素的最小值
# 注:列表内的元素一定要是同一类型,都是字母 或 数字
lst = [8,4,5,6,9]
print(min(lst))
# 4
lst = ['a','b','c','A','B','C']
print(min(lst))
# A
使用 list 将元组转换为列表对象(通常用来修改元组的值):
# 使用 list 将元组转换为列表对象(通常用来修改元组的值)
tup = (1,2,3,'a','b')
tuple_lst = list(tup)
print(tuple_lst)
# [1, 2, 3, 'a', 'b']
方法:
append(对象):
在列表末尾添加该对象
# append(对象):
# 在列表末尾添加该对象
lst = ['A','B','C']
lst.append('D')
print(lst)
# ['A', 'B', 'C', 'D']
# 如果添加元素为列表,则将列表当做一个元素进行添加
lst = ['A','B','C']
lst_two = ['a','b','c']
lst.append(lst_two)
print(lst)
# ['A', 'B', 'C', ['a', 'b', 'c']]
count(str):
返回列表中 str 出现的次数
# count(str):
# 返回列表中 str 出现的次数
lst = [1,2,1,2,1,3]
print(lst.count(1))
# 3
# 如果不存在该元素,则返回 0
print(lst.count(4))
# 0
extend(序列对象):
在列表末尾添加所有序列对象中的元素,返回值为空。多用来扩展原来的列表
# extend(序列对象):
# 在列表末尾添加所有序列对象中的元素,多用来扩展原来的列表
lst = [1,2,3]
lst_two = [7,8,9]
lst.extend(lst_two)
print(lst)
# [1, 2, 3, 7, 8, 9]
index(str):
返回 str 在列表中第一次出现的索引位置,str 不在列表中则报错
# index(str):
# 返回 str 在列表中第一次出现的索引位置
lst = ['a','b','c','d','e','c']
print(lst.index('c'))
# 2
insert(index,对象):
在列表的 index 位置添加对象,原 index 位置及后面位置的所有元素都向后移
# insert(index,对象):
# 在列表的 index 位置添加对象
lst = ['a','b','c','d']
lst.insert(2,'q')
print(lst)
# ['a', 'b', 'q', 'c', 'd']
pop(index = -1):
默认删除列表的最后一个元素,并返回值
当 index 为 2 时,删除第 3 个元素
# pop(index):
# 默认删除列表的最后一个元素,并返回值
lst = ['a','b','c','d']
lst.pop()
print(lst)
# ['a', 'b', 'c']
lst = ['a','b','c','d']
# 删除第二个元素
lst.pop(2)
print(lst)
# ['a', 'b', 'd']
remove(str):
将 str 从列表中删除,注:如果列表中有多个 str 元素,只删除一次 str
# remove(str):
# 将 str 从列表中删除一次
lst = ['a','b','c','d','a']
lst.remove('a')
print(lst)
# ['b', 'c', 'd', 'a']
lst = ['a','b','c','d']
lst.remove('b')
print(lst)
# ['a', 'c', 'd']
reverse( ):
翻转列表的元素
# reverse( ):
# 翻转列表的元素
lst = [1,7,3,2,5,6]
lst.reverse()
print(lst)
# [6, 5, 2, 3, 7, 1]
sort(key = None,reverse = False):
对列表进行排序,无返回值
# sort(key = None,reverse = False):
# key 用来接收函数,对排序的数据进行修改
# 对列表进行排序
lst = [1,4,5,2,7,6]
lst.sort()
print(lst)
# [1, 2, 4, 5, 6, 7]
lst = [1,4,5,2,7,6]
# 先排序后翻转
lst.sort(reverse = True)
print(lst)
# [7, 6, 5, 4, 2, 1]
lst = [5,4,1,2,7,6]
# 不满足 key 的放前面,满足 key 的放后面
lst.sort(key = lambda x : x % 2 == 0)
print(lst)
# [1, 5, 7, 4, 2, 6]
clear( ):
清空列表
# clear( ):
# 清空列表,无返回值
lst = ['a','c','e']
lst.clear()
print(lst)
# []
copy( ):
复制一份列表元素
# copy( ):
# 复制列表
lst = ['a','b','c']
print(lst.copy())
# ['a', 'b', 'c']
print(lst)
# ['a', 'b', 'c']
Python元组:元组与字典类似,不同之处在于元组的值不能够修改。
使用 ( ) 或 tuple 强制转换 可以得到元祖
创建空元组:
# 创建空元祖
tuple_1 = ()
print(type(tuple_1))
#
print(tuple_1)
# ()
创建只包含一个元素的元组:
注:一定要使用,逗号,否则会被当做是一个常量值
# 创建只包含一个元素的元组
tuple_2 = (1,)
print(type(tuple_1))
#
print(tuple_2)
# (1,)
创建包含有多个元素的元组:
# 创建包含多个元素的元组
tuple_3 = (4,5)
print(type(tuple_3))
#
print(tuple_3)
# (4, 5)
# 使用 tuple 对列表进行强制转换
lst = [1,2,3,4,5]
tuple_4 = tuple(lst)
print(type(tuple_4))
#
print(tuple_4)
# (1, 2, 3, 4, 5)
不使用括号,创建包含多个元素的元组:
# 创建包含多个元素的元组
tuple_4 = 7,8,9
print(tuple_4)
# (7, 8, 9)
print(type(tuple_4))
#
Python访问元组:
使用索引下标进行访问元组:
# 通过索引下标进行访问
tuple_1 = ('a','b','c','d','e','f','g')
# 输出元组中的第一个值
print(tuple_1[0])
# a
# 输出元组中的第六个值
print(tuple_1[5])
# f
# 输出元组的最后一个元素
print(tuple_1[-1])
# g
通过切片访问元组:
# 使用切片对元组进行输出 [start:end:step] 注:不包含 end 位置
tuple_1 = ('a','b','c',4,5,6,7)
# 输出所有元组的元素
print(tuple_1[::])
# ('a', 'b', 'c', 4, 5, 6, 7)
# 输出元组的第三个元素到第五个元素
print(tuple_1[2:5]) #不包含 end
# ('c', 4, 5)
# 步长可以进行修改
print(tuple_1[2:5:2])
# ('c', 5)
# 将元组倒序输出
print(tuple_1[::-1])
# (7, 6, 5, 4, 'c', 'b', 'a')
Python访问元组:
使用索引下标进行访问元组:
# 通过索引下标进行访问
tuple_1 = ('a','b','c','d','e','f','g')
# 输出元组中的第一个值
print(tuple_1[0])
# a
# 输出元组中的第六个值
print(tuple_1[5])
# f
# 输出元组的最后一个元素
print(tuple_1[-1])
# g
通过切片访问元组:
# 使用切片对元组进行输出 [start:end:step] 注:不包含 end 位置
tuple_1 = ('a','b','c',4,5,6,7)
# 输出所有元组的元素
print(tuple_1[::])
# ('a', 'b', 'c', 4, 5, 6, 7)
# 输出元组的第三个元素到第五个元素
print(tuple_1[2:5]) #不包含 end
# ('c', 4, 5)
# 步长可以进行修改
print(tuple_1[2:5:2])
# ('c', 5)
# 将元组倒序输出
print(tuple_1[::-1])
# (7, 6, 5, 4, 'c', 'b', 'a')
注:
元组没有 reverse 方法
修改元组的元素
# 将元组中的 'c' 改为 'd'
tuple_1 = ('a','b','c',4,5,6,7)
# c 的索引位置是 2
# 修改元组的值,可先将元组转换为列表类型,然后再转变为元组类型
lst = list(tuple_1)
lst[2] = 'd' #进行修改
tuple_1 = tuple(lst) #重新转换为元组类型
print(tuple_1)
# ('a', 'b', 'd', 4, 5, 6, 7)
删除元组中的某一个元素,可以使用del 进行删除,也可以利用切片进行相加
# 方法1
# 将元组中的 'b' 删除
tuple_1 = ('a','b','c',4,5,6,7)
# b 的索引位置是 1
lst = list(tuple_1)
del lst[1]
tuple_1 = tuple(lst) #重新转换为元组类型
print(tuple_1)
# ('a', 'c', 4, 5, 6, 7)
# 方法2
# 将元组中的 'b' 删除
tuple_1 = ('a','b','c',4,5,6,7)
# b 的索引位置是 1
tuple_1 = tuple_1[:1] + tuple_1[2:]
print(tuple_1)
# ('a', 'c', 4, 5, 6, 7)
del 语句 删除元组:
# 删除元组
tuple_1 = ('a','b','c')
del tuple_1
Python元组运算符:
len(元组名):
返回元组对象的长度
tuple_1 = (1,4,5,2,3,6)
print(len(tuple_1))
# 6
+ 连接:
tuple_1 = (1,4,5)
tupel_2 = (3,5,4)
print(tuple_1 + tupel_2)
# (1, 4, 5, 3, 5, 4)
* 重复:
tuple_1 = (1,4,5)
num = 3
print(num * tuple_1)
# (1, 4, 5, 1, 4, 5, 1, 4, 5)
成员运算符 in ,not in:
tuple_1 = (1,4,5,2,3,6)
print(4 in tuple_1)
# True
print(8 in tuple_1)
# False
print(4 not in tuple_1)
# False
print(8 not in tuple_1)
# True
将元组作为可迭代对象:
# 将元组作为可迭代对象
tuple_1 = ('a','b','c')
for i in tuple_1:
print(i , end = " ")
# a b c
Python元组索引、截取:
索引下标:
tuple_1 = ('a','b','c','d','e','f','g','h')
print(tuple_1[0])
# a
print(tuple_1[3])
# d
print(tuple_1[7])
# h
# 当索引下标为负数时,-1表示最右端元素,从右向左依次递减
print(tuple_1[-1])
# h
print(tuple_1[-4])
# e
切片操作:
# 使用切片进行截取列表元素
tuple_1 = (1,2,3,4,5,6,7,8,9,10)
print(tuple_1[::])
# (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
print(tuple_1[2:8])
# (3, 4, 5, 6, 7, 8)
print(tuple_1[2:8:3])
# (3, 6) , 不包含end
print(tuple_1[2::-1])
# (3, 2, 1)
print(tuple_1[8:1:-1])
# (9, 8, 7, 6, 5, 4, 3)
print(tuple_1[8:1:-2])
# (9, 7, 5, 3)
print(tuple_1[-1:-5:-1])
# (10, 9, 8, 7)
Python元组内置函数:
len(元组名):
返回元组长度
tuple_1 = (1,2,3,'a','b','c')
print("tuple_1 元组的长度为 %d"%(len(tuple_1)))
# tuple_1 元组的长度为 6
max(元组名):
返回元组元素的最大值
注:元组内的元素一定要是同一类型,都是字母 或 数字
tuple_1 = (8,4,5,6,9)
print(max(tuple_1))
# 9
tuple_1 = ('a','b','c','A','B','C')
print(max(tuple_1))
# c
min(元组名):
返回元组元素的最小值
注:元组内的元素一定要是同一类型,都是字母 或 数字
tuple_1 = (8,4,5,6,9)
print(min(tuple_1))
# 4
tuple_1 = ('a','b','c','A','B','C')
print(min(tuple_1))
# A
使用 tuple 将列表转换为元组对象
# 使用 tuple 将列表转换为元组对象
tuple_1 = (1,2,3,'a','b')
lst = list(tuple_1)
print(lst)
# [1, 2, 3, 'a', 'b']
Python字典:{键:值},多个键值对使用 , 进行分隔。
创建空字典:
dic = {}
print(type(dic))
#
print(dic)
# {}
创建只有一个元素的字典:
dic = {'a':123}
print(dic)
# {'a': 123}
创建包含多个元素的字典:
dic = {'a':123,888:'n',(4,5):[7,8]}
print(dic)
# {'a': 123, 888: 'n', (4, 5): [7, 8]}
# 键一定是不可变类型
使用 dict 转化为字典:
dic = dict(zip(['a','b','c'],[4,5,6]))
print(dic)
# {'a': 4, 'b': 5, 'c': 6}
Python访问字典中的值:
# 使用字典 ['键'] 获取字典中的元素
dic = {'a':123,'b':456,'c':789}
print(dic['a'])
# 123
修改字典元素:
dic = {'a': 123, 'b': 456, 'c': 789}
dic['b'] = 14
print(dic)
# {'a': 123, 'b': 14, 'c': 789}
增加字典元素:
dic = {'a':123,'b':456,'c':789}
dic['d'] = 555
print(dic)
# {'a': 123, 'b': 456, 'c': 789, 'd': 555}
删除操作:
dic = {'a': 123, 'b': 14, 'c': 789}
# 删除字典元素
del dic['b']
print(dic)
# {'a': 123, 'c': 789}
# 清空字典
dic = {'a': 123, 'b': 14, 'c': 789}
dic.clear()
print(dic)
# {}
# 删除字典
dic = {'a': 123, 'b': 14, 'c': 789}
del dic
Python字典内置函数和方法:
注:使用了 items、values、keys 返回的是可迭代对象,可以使用 list 转化为列表。
len(字典名):
返回键的个数,即字典的长度
dic = {'a':123,'b':456,'c':789,'d':567}
print(len(dic))
# 4
str(字典名):
将字典转化成字符串
dic = {'a':123,'b':456,'c':789,'d':567}
print(str(dic))
# {'a': 123, 'b': 456, 'c': 789, 'd': 567}
type(字典名):
查看字典的类型
dic = {'a':123,'b':456,'c':789,'d':567}
print(type(dic))
#
字典的内置方法
clear( ):
删除字典内所有的元素
dic = {'a':123,'b':456,'c':789,'d':567}
dic.clear()
print(dic)
# {}
copy( ):
浅拷贝一个字典
dic = {'a':123,'b':456,'c':789,'d':567}
dic_two = dic.copy()
print(dic)
# {'a': 123, 'b': 456, 'c': 789, 'd': 567}
print(dic_two)
# {'a': 123, 'b': 456, 'c': 789, 'd': 567}
fromkeys(seq[,value]):
创建一个新字典,seq作为键,value为字典所有键的初始值(默认为None)
# fromkeys(seq[,value]):
# 创建一个新字典,seq作为键,value为字典所有键的初始值(默认为None)
dic = dict.fromkeys('abcd')
# 默认为 None
print(dic)
# {'a': None, 'b': None, 'c': None, 'd': None}
dic = dict.fromkeys('abc',1)
print(dic)
# {'a': 1, 'b': 1, 'c': 1}
get(key,default = None):
返回指定的键的值,如果键不存在,则返会 default 的值
dic = {'a':1,'b':2,'c':3,'d':4}
print(dic.get('b'))
# 2
print(dic.get('e',5))
# 5
成员运算符 in、not in:
查看 键 是否在字典中:
dic = {'a':1,'b':2,'c':3,'d':4}
print('a' in dic)
# True
print('a' not in dic)
# False
items( ):
返回键值对的可迭代对象,使用 list 可转换为 [(键,值)] 形式
dic = {'a':1,'b':2,'c':3,'d':4}
print(dic.items())
# dict_items([('a', 1), ('b', 2), ('c', 3), ('d', 4)])
print(list(dic.items()))
# [('a', 1), ('b', 2), ('c', 3), ('d', 4)]
keys( ):
返回一个迭代器,可以使用 list() 来转换为列表
dic = {'a':1,'b':2,'c':3,'d':4}
print(dic.keys())
# dict_keys(['a', 'b', 'c', 'd'])
print(list(dic.keys()))
# ['a', 'b', 'c', 'd']
setdefault(key,default = None):
如果键存在于字典中,则不修改键的值
如果键不存在于字典中,则设置为 default 值
dic = {'a':1,'b':2,'c':3,'d':4}
dic.setdefault('a',8)
print(dic)
# {'a': 1, 'b': 2, 'c': 3, 'd': 4}
# 如果键不存在于字典中,则设置为 default 值
dic = {'a':1,'b':2,'c':3,'d':4}
dic.setdefault('e',5)
print(dic)
# {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
update(字典对象):
将字典对象更新到字典中
dic = {'a':1,'b':2,'c':3,'d':4}
dic_two = {'f':6}
dic.update(dic_two)
print(dic)
# {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'f': 6}
values( ):
返回一个可迭代对象,使用 list 转换为字典中 值 的列表
dic = {'a':1,'b':2,'c':3,'d':4}
print(list(dic.values()))
pop(key[,default]):
删除字典中 key 的值,返回被删除的值。key 值如果不给出,则返回default的值
dic = {'a':1,'b':2,'c':3,'d':4}
print(dic.pop('a',6))
# 1 , 返回删除的值
print(dic)
# {'b': 2, 'c': 3, 'd': 4}
print(dic.pop('e','字典中没有该值'))
# 字典中没有该值 , 如果字典中不存在该键,则返回 default 的值
print(dic)
# {'b': 2, 'c': 3, 'd': 4}
popitem( ):
随机返回一个键值对(通常为最后一个),并删除最后一个键值对
dic = {'a':1,'b':2,'c':3,'d':4}
print(dic.popitem())
# ('d', 4)
print(dic)
# {'a': 1, 'b': 2, 'c': 3}
print(dic.popitem())
# ('c', 3)
print(dic)
# {'a': 1, 'b': 2}
time 模块
time.time()
# 1595600800.6158447
Python函数使用一个元组装起来的 9 组数字,专门用来处理时间使用
tm_year 年:使用 4 位数字 、2020
tm_mon 月:1~12 、6月
tm_mday 日:1~31 、25号
tm_hour 小时:0~23 、16时
tm_min 分钟:0~59 、33分
tm_sec 秒:0~60 或 0~61 、61 是闰秒
tm_wday 一周的第几日:0~6 、0 是周一
tm_yday 一年的第几日:1~365 或 1~366 、366是闰年
tm_isdst 夏令时:1 为夏令时、0 非夏令时、-1 未知
获取当前时间
#使用 time.localtime(time.time())
import time
times = time.time()
print(times) # 表示自 1970 年 1月 1 日 过去了多久
# 1595601014.0598545
localtime = time.localtime(times)
print(localtime)
# time.struct_time(tm_year=2020, tm_mon=7, tm_mday=24, tm_hour=22, tm_min=30,
# tm_sec=14, tm_wday=4, tm_yday=206, tm_isdst=0)
获取格式化时间:
time.time() 获取到1970年1月1日的秒数 -> time.localtime() 转变为当前时间 -> time.asctime() 将时间格式化
#获取格式化时间
import time
times = time.time()
print(times)
# 1595601087.3453288
local_times = time.localtime(times)
print(local_times)
# time.struct_time(tm_year=2020, tm_mon=7, tm_mday=24, tm_hour=22,
# tm_min=31, tm_sec=27, tm_wday=4, tm_yday=206, tm_isdst=0)
# 使用 asctime 将得到的 local_times 转化为有格式的时间
local_time_asctimes = time.asctime(local_times)
print(local_time_asctimes)
# Fri Jul 24 22:31:27 2020
格式化日期:
%y :两位数的年份表示 (00~99)
%Y :四位数的年份表示 (000~9999)
%m :月份(01~12)
%d :月份中的某一天(0~31)
%H :某时,24小时制(0~23)
%I :某时,12小时制(01~12)
%M :某分(0~59)
%S :某秒(00~59)
%a :周几的英文简称
%A :周几的完整英文名称
%b :月份的英文简称
%B :月份的完整英文名称
%c :本地相应的日期表示和时间表示
%j :年内的某一天(001~366)
%p :本地 A.M. 或 P.M.的等价符
%U :一年中的星期数(00~53)注:星期天为星期的开始
%w :星期(0~6)注:星期天为星期的开始
%W :一年中的星期数(00~53)注:星期一为星期的开始
%x :本地相应的日期表示
%X :本地相应的时间表示
%Z : 当前时区的名称
%% :输出一个%
time.strftime(format[,t]) 参数为日期格式
# 格式化日期
# time.strftime(format[,t]) 参数为日期格式
import time
times = time.time()
local_time = time.localtime(times)
# Y 年 - m 月 - d 日 H 时 - M 分 - S 秒
print(time.strftime("%Y-%m-%d %H:%M:%S",local_time))
# 2020-07-24 22:33:43
# Y 年 - b 月份英文简称 - d 日期 - H 时 - M 分 - S 秒 - a 周几的英文简称
print(time.strftime("%Y %b %d %H:%M:%S %a",local_time))
# 2020 Jul 24 22:33:43 Fri
获取某月的日历:
calendar.month(year,month):
获取 year 年 month 月的日历
import calendar
cal = calendar.month(2020,2)
print("以下为2020年2月的日历")
print(cal)
# February 2020
# Mo Tu We Th Fr Sa Su
# 1 2
# 3 4 5 6 7 8 9
# 10 11 12 13 14 15 16
# 17 18 19 20 21 22 23
# 24 25 26 27 28 29
Python Time模块:
altzone:
注:我们在格林威治的东部,返回负值。对启动夏令时的地区才能使用
返回格林威治西部的夏令时地区的偏移秒数,如果是在东部(西欧),则返回负值
import time
print(time.altzone)
# -32400
time( ):
返回当前时间的时间戳
import time
times = time.time()
print(times)
# 1595601470.093444
asctime(时间元组):时间元组:如使用了 gmtime 或 localtime 函数的对象
接受时间元组并返回可读形式,时间元组可以是使用了 time.localtime(time.time()) 的对象
import time
times = time.time()
print(times)
# 1595601496.8390365
local_time = time.localtime(times)
print(local_time)
# time.struct_time(tm_year=2020, tm_mon=7, tm_mday=24,
# tm_hour=22, tm_min=38, tm_sec=16, tm_wday=4, tm_yday=206, tm_isdst=0)
# 使用 asctime 转变为可读形式
print(time.asctime(local_time))
# Fri Jul 24 22:38:16 2020
perf_counter( ):
返回系统的运行时间
import time
# 使用 perf_counter()函数查看系统运行时间
print(time.perf_counter())
# 2.0289763
process_time( ):
查看进程运行时间
import time
# 使用 process_time() 查看进程运行时间
print(time.process_time())
# 0.0625
gmtime(secs):secs 时间戳:从1970年1月1日到现在的秒数
查看格林威治的时间元组
# 使用 gmtime(时间戳) 查看格林威治的时间元组
import time
times = time.time()
# 查看格林威治的当前时间元组
print(time.gmtime(times))
# time.struct_time(tm_year=2020, tm_mon=2, tm_mday=10, tm_hour=5,
# tm_min=18, tm_sec=7, tm_wday=0, tm_yday=41, tm_isdst=0)
localtime(secs):secs 时间戳:从1970年1月1日到现在的秒数
返回 secs 时间戳下的时间元组
import time
times = time.time()
print(times)
# 1581312227.3952267 , 时间戳
local_time = time.localtime()
print(local_time)
# time.struct_time(tm_year=2020, tm_mon=2, tm_mday=10, tm_hour=13,
# tm_min=23, tm_sec=47, tm_wday=0, tm_yday=41, tm_isdst=0)
mktime(使用了 gmtime 或 localtime 函数的对象):
返回时间戳
import time
times = time.time()
print(times)
# 1581312492.6350465
local_time = time.localtime()
print(time.mktime(local_time))
# 1581312492.0
ctime( ):
返回可读形式的当前时间
# ctime()
# 返回可读形式的当前时间
import time
print(time.ctime())
# Mon Feb 10 13:32:22 2020
sleep(seconds):
使程序延迟 seconds 秒运行
import time
print(time.ctime())
# Mon Feb 10 13:34:38 2020
time.sleep(5)
print(time.ctime())
# Mon Feb 10 13:34:43 2020
strftime(format,时间元组):format表示时间显示格式,如 %Y-%m-%d %H-%M-%S
将时间元组转换为 format 形式
import time
times = time.time()
local_time = time.localtime()
time_strftime = time.strftime("%Y-%m-%d %H-%M-%S",local_time)
print(time_strftime)
# 2020-02-10 13-42-09
strptime(str,format):
按照 format 格式将 str 解析为一个时间元组,如果 str 不是 format 格式,则会报错
import time
str = '2020-02-10 13-42-09'
str_time = time.strptime(str,"%Y-%m-%d %H-%M-%S")
print(str_time)
# time.struct_time(tm_year=2020, tm_mon=2, tm_mday=10, tm_hour=13,
# tm_min=42, tm_sec=9, tm_wday=0, tm_yday=41, tm_isdst=-1)
属性:
timezone:
当前地区距离格林威治的偏移秒数
import time
print(time.timezone)
# -28800
tzname:
属性time.tzname包含一对字符串,分别是带夏令时的本地时区名称,和不带的。
# 使用 time.tzname 查看 带夏令时的本地时区名称 与 不带夏令时的本地时区名称
import time
print(time.tzname)
# ('中国标准时间', '中国夏令时')
Python日历模块 calendar:
0:星期一是第一天
6:星期日是最后一天
注:形参 w,I,c 可以不写,正常使用,使用默认形参即可
calendar(year,w=2,I=1,c=6):
返回一个多行字符格式的 year 年年历,3个月一行,间隔距离为 c。每日宽度间隔为 w 个字符
# calendar(year,w = 2,I = 1,c = 6)
import calendar
# calendar(年份,天与天之间的间隔,周与周之间的间隔,月与月之间的间隔)
print(calendar.calendar(2020,2,1,6))
# 2020
#
# January February March
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 2 3 4 5 1 2 1
# 6 7 8 9 10 11 12 3 4 5 6 7 8 9 2 3 4 5 6 7 8
# 13 14 15 16 17 18 19 10 11 12 13 14 15 16 9 10 11 12 13 14 15
# 20 21 22 23 24 25 26 17 18 19 20 21 22 23 16 17 18 19 20 21 22
# 27 28 29 30 31 24 25 26 27 28 29 23 24 25 26 27 28 29
# 30 31
#
# April May June
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 2 3 4 5 1 2 3 1 2 3 4 5 6 7
# 6 7 8 9 10 11 12 4 5 6 7 8 9 10 8 9 10 11 12 13 14
# 13 14 15 16 17 18 19 11 12 13 14 15 16 17 15 16 17 18 19 20 21
# 20 21 22 23 24 25 26 18 19 20 21 22 23 24 22 23 24 25 26 27 28
# 27 28 29 30 25 26 27 28 29 30 31 29 30
#
# July August September
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 2 3 4 5 1 2 1 2 3 4 5 6
# 6 7 8 9 10 11 12 3 4 5 6 7 8 9 7 8 9 10 11 12 13
# 13 14 15 16 17 18 19 10 11 12 13 14 15 16 14 15 16 17 18 19 20
# 20 21 22 23 24 25 26 17 18 19 20 21 22 23 21 22 23 24 25 26 27
# 27 28 29 30 31 24 25 26 27 28 29 30 28 29 30
# 31
#
# October November December
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 2 3 4 1 1 2 3 4 5 6
# 5 6 7 8 9 10 11 2 3 4 5 6 7 8 7 8 9 10 11 12 13
# 12 13 14 15 16 17 18 9 10 11 12 13 14 15 14 15 16 17 18 19 20
# 19 20 21 22 23 24 25 16 17 18 19 20 21 22 21 22 23 24 25 26 27
# 26 27 28 29 30 31 23 24 25 26 27 28 29 28 29 30 31
# 30
firstweekday( ):
返回当前每周起始日期的设置,默认返回 0 、周一为 0
import calendar
print(calendar.firstweekday())
# 0
isleap(year):
如果是闰年则返回 True,否则返回 False
import calendar
print(calendar.isleap(2020))
# True
leapdays(year1,year2):
返回 year1 到 year2 之间的闰年数量
import calendar
print(calendar.leapdays(2001,2100))
# 24
month(year,month,w = 2,I = 1):
返回 year 年 month 月日历,两行标题,一周一行。
注:每天与每天的宽度间隔为 w 个字符,i 是每个星期与每个星期的间隔的空数
import calendar
print(calendar.month(2020,3,2,1))
# March 2020
# Mo Tu We Th Fr Sa Su
# 1
# 2 3 4 5 6 7 8
# 9 10 11 12 13 14 15
# 16 17 18 19 20 21 22
# 23 24 25 26 27 28 29
# 30 31
monthcalendar(year,month):
以列表形式返回,每一周为内嵌列表,没有日子则为 0
import calendar
print(calendar.monthcalendar(2020,4))
# [[0, 0, 1, 2, 3, 4, 5], [6, 7, 8, 9, 10, 11, 12],
# [13, 14, 15, 16, 17, 18, 19], [20, 21, 22, 23, 24, 25, 26],
# [27, 28, 29, 30, 0, 0, 0]]
monthrange(year,month):
返回(这个月的第一天是星期几,这个月有多少天)
import calendar
print(calendar.monthrange(2020,2))
# (5, 29)
prcal(year,w = 2,I = 1,c = 6):
输出 year 年的日历
import calendar
calendar.prcal(2020)
# print(calendar.prcal(2020,2,1,6))
# 2020
#
# January February March
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 2 3 4 5 1 2 1
# 6 7 8 9 10 11 12 3 4 5 6 7 8 9 2 3 4 5 6 7 8
# 13 14 15 16 17 18 19 10 11 12 13 14 15 16 9 10 11 12 13 14 15
# 20 21 22 23 24 25 26 17 18 19 20 21 22 23 16 17 18 19 20 21 22
# 27 28 29 30 31 24 25 26 27 28 29 23 24 25 26 27 28 29
# 30 31
#
# April May June
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 2 3 4 5 1 2 3 1 2 3 4 5 6 7
# 6 7 8 9 10 11 12 4 5 6 7 8 9 10 8 9 10 11 12 13 14
# 13 14 15 16 17 18 19 11 12 13 14 15 16 17 15 16 17 18 19 20 21
# 20 21 22 23 24 25 26 18 19 20 21 22 23 24 22 23 24 25 26 27 28
# 27 28 29 30 25 26 27 28 29 30 31 29 30
#
# July August September
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 2 3 4 5 1 2 1 2 3 4 5 6
# 6 7 8 9 10 11 12 3 4 5 6 7 8 9 7 8 9 10 11 12 13
# 13 14 15 16 17 18 19 10 11 12 13 14 15 16 14 15 16 17 18 19 20
# 20 21 22 23 24 25 26 17 18 19 20 21 22 23 21 22 23 24 25 26 27
# 27 28 29 30 31 24 25 26 27 28 29 30 28 29 30
# 31
#
# October November December
# Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su
# 1 2 3 4 1 1 2 3 4 5 6
# 5 6 7 8 9 10 11 2 3 4 5 6 7 8 7 8 9 10 11 12 13
# 12 13 14 15 16 17 18 9 10 11 12 13 14 15 14 15 16 17 18 19 20
# 19 20 21 22 23 24 25 16 17 18 19 20 21 22 21 22 23 24 25 26 27
# 26 27 28 29 30 31 23 24 25 26 27 28 29 28 29 30 31
# 30
prmonth(year,month,w = 2,I = 1):
输出 year 年 month 月的日历
import calendar
calendar.prmonth(2020,12)
# December 2020
# Mo Tu We Th Fr Sa Su
# 1 2 3 4 5 6
# 7 8 9 10 11 12 13
# 14 15 16 17 18 19 20
# 21 22 23 24 25 26 27
# 28 29 30 31
setfirstweekday(weekday):
设置每周的起始日期,0为周一,6为周日
import calendar
calendar.setfirstweekday(2)
timegm(时间元组):
返回该时刻的时间戳
import time
import calendar
print(calendar.timegm(time.localtime(time.time())))
# 1581362983
weekday(year,month,day):
查看 year 年 month 月 day 日 星期几
import calendar
print(calendar.weekday(2020,2,10))
# 0 周一
Python函数:实现某种功能的代码段
定义一个函数需要遵循的规则:
1.使用 def 关键字 函数名和( ),括号内可以有形参
匿名函数使用 lambda 关键字定义
2.任何传入参数和自变量必须放在括号中
3.函数的第一行语句可以使用字符串存放函数说明
4.函数内容以冒号开始,函数内的代码块缩进
5.使用了 return [表达式] 函数会返回一个值,如果不使用 return 没有返回值
def 函数名([参数,根据函数运行需要,如果函数不需要参数,可以不写]):
函数声明(可不写,如果怕忘记函数功能,最好是写)
函数语句 ...
return 需要返回的值(有些函数可以不使用 return,只进行某些操作,返回为None)
定义一个 say_hello 函数,使函数能够说出 hello
def say_hello():
print("hello")
定义一个求长方形面积的函数 area,要求具有返回值且参数为 height 和 width
def area(height,width):
return height * width
定义一个函数,输出 欢迎,接收到的参数 name
def huanying(name):
print("欢迎",name)
定义一个求 1~10 的总和的函数,函数名为 one_to_ten,要求具有返回值
def one_to_ten():
sum = 0
for i in range(1,11):
sum += i
return sum
函数名可以赋值给变量,使用变量进行调用(变量此时相当于函数名)
def add(num_1,num_2):
print(num_1 + num_2)
a = add
print(type(a))
#
a(3,5)
# 8
函数内可以进行定义类:
def run():
class student(object):
pass
Python函数调用:
函数定义后,使用函数名(实参)进行调用,如果具有返回值,则使用变量接收。
示例:
无参数,无返回值
# 程序:定义一个 say_hello 函数,使函数能够说出 hello
def say_hello():
print("hello")
say_hello()
# hello
有参数,无返回值
# 定义一个函数,输出 欢迎,接收到的参数 name
def huanying(name):
print("欢迎",name)
huanying("小明")
# 欢迎 小明
无参数,有返回值
#定义一个求 1~10 的总和的函数,函数名为 one_to_ten,要求具有返回值
def one_to_ten():
sum = 0
for i in range(1,11):
sum += i
return sum
sum_1 = one_to_ten()
print(sum_1)
# 55
有参数,有返回值
# 定义一个求长方形面积的函数,要求具有返回值且参数为 height 和 width
def area(height,width):
return height * width
mianji = area(5,4)
print(mianji)
Python按值传递参数和按引用传递参数:
按值传递参数:
使用一个变量的值(数字,字符串),放到实参的位置上
注:传递过去的是变量的副本,无论副本在函数中怎么变,变量的值都不变
传递常量:
# 定义一个函数,输出 欢迎,接收到的参数 name
def huanying(name):
print("欢迎",name)
huanying("小明")
# 欢迎 小明
# 定义一个求长方形面积的函数,要求具有返回值且参数为 height 和 width
def area(height,width):
return height * width
mianji = area(5,4)
print(mianji)
# 20
传递变量:
# 定义一个函数,输出 欢迎,接收到的参数 name
def huanying(name):
print("欢迎",name)
strs_name = "小明"
huanying(strs_name)
# 欢迎 小明
# 定义一个求长方形面积的函数,要求具有返回值且参数为 height 和 width
def area(height,width):
return height * width
height = 5
width = 4
mianji = area(height,width)
print(mianji)
# 20
按引用传递:
输出 列表、元组 和 集合所有元素的总和
lst = [1,2,3,4]
tuple_1 = (4,5,7)
se = {9,6,5,8}
def add(args):
'''将 args 中的元素总和输出'''
print(sum(args))
add(lst)
# 10
add(tuple_1)
# 16
add(se)
# 28
# 输出程序的注释
print(add.__doc__)
# 将 args 中的元素总和输出
使用函数,将参数引用传递输出参数中的奇数
lst = [1,2,3,4]
tuple_1 = (4,5,7)
def jishu(args):
'''将 args 中的奇数输出'''
for i in range(len(args)):
if args[i] % 2 == 1:
print(args[i], end = " ")
print()
jishu(lst)
# 1 3
jishu(tuple_1)
# 5 7
# 输出程序的注释
print(jishu.__doc__)
# 将 args 中的奇数输出
如果参数发生修改
1.原参数如果为可变类型(列表、集合、字典)则也跟着修改
2.原参数如果为不可变类型(数字、字符串、元组)则不发生改变
示例:
列表在函数中调用方法,列表本身发生改变
def add_elem(args,string):
'''将 lst_num 添加到 args 中'''
args.append(string)
# args += string
# args.extend(string)
# args.insert(len(args),string)
return args
lst = [1,2,3,4]
string = "ABC"
print(add_elem(lst,string))
# [1, 2, 3, 4, 'ABC']
print(lst)
# [1, 2, 3, 4, 'ABC']
在函数中,如果列表作为实参,形参发生修改时,列表值发生改变
def add_elem(args,string):
'''将 lst_num 添加到 args 中'''
args[len(args)-1] = string
return args
lst = [1,2,3,4]
string = "ABC"
print(add_elem(lst,string))
# [1, 2, 3, 'ABC']
print(lst)
# [1, 2, 3, 'ABC']
Python函数参数:
注:变量没有类型,有类型的是变量指向的内存空间中的值
可变类型:列表、集合、字典
不可变类型:数字、字符串、元组
可变类型在函数中发生改变时,原变量也会跟着发生变化
列表使用 赋值,+=,append,extend,insert 方法均会使列表的值发生改变
位置参数:
实参必须以正确的顺序传入函数,调用时的数量必须与声明时一致
# 必需参数
def hello(name):
'''输出欢迎信息'''
print("hello {0}".format(name))
name = "XiaoMing"
hello(name)
# hello XiaoMing
# hello() 会报错,因为没有传入参数
关键字参数:
函数在调用时使用关键字确定传入参数的值(可以不根据参数位置)
注:关键字即为函数定义时使用的形参名
对应关键字名进行传递:
def add(num_1,num_2):
'''将两个数字进行相加'''
print("num_1:",num_1)
print("num_2:",num_2)
print("num_1 + num_2",num_1 + num_2)
add(num_2 = 6,num_1 = 8)
# num_1: 8
# num_2: 6
# num_1 + num_2 14
默认参数:
当调用函数时,如果没有传递参数,则会使用默认参数
如果传递了参数,则默认参数不起作用
注:程序有时会设置好已经修改好的默认参数,调用只需要传入不是默认参数的参数即可
# 默认参数
def add(num_1,num_2 = 10):
'''将两个数字进行相加'''
print("num_1:",num_1)
print("num_2:",num_2)
print("num_1 + num_2",num_1 + num_2)
# add(15)
# # num_1: 15
# # num_2: 10
# # num_1 + num_2 25
# 不传入 num_2 的值,使用 num_2 的默认参数
add(num_1 = 15)
# num_1: 15
# num_2: 10
# num_1 + num_2 25
# 传入 num_2 的值,不使用 num_2 的默认参数
add(num_2 = 6,num_1 = 8)
# num_1: 8
# num_2: 6
# num_1 + num_2 14
不定长参数:
当需要的参数不确定,又还想使用参数进行函数内的运算时,可以考虑不定长参数
不定长参数:
* 变量
1.形参使用 *变量名: 实参通常为传入的多余变量(可以是字典变量)、 列表 或 元组 等
如果实参使用了 *列表,*元组,则函数中接收的是列表或元组中的所有的元素值
2.形参使用 **变量名:通常为 **字典变量 或 字典元素(键值对) 等
示例:
# 不定长参数
def print_info(*vartuple):
print(vartuple)
# 调用 printinfo 函数
print_info(70, 60, 50)
# (70, 60, 50)
当不定长参数前面存在位置参数时:
传入参数的值先传递给位置参数,剩余的传递给不定长参数
注:如果没有剩余的实参,则不定长参数没有值
不使用位置参数:
可以接收所有数据类型数据,除了 a = 2 这种键值对,**字典变量等
注:如果实参中使用了 *列表,*元组,则函数接收的为列表或元组的所有元素值
def print_info(*vartuple):
# print(type(vartuple))
print(vartuple)
# for i in vartuple:
# print(i,end =" ")
# print(type(vartuple[5]))
#
# print(vartuple[5])# 不定长参数
# 不使用位置参数
def print_info(*vartuple):
# print(type(vartuple))
print(vartuple)
# for i in vartuple:
# print(i,end =" ")
# print(type(vartuple[5]))
#
# print(vartuple[5])
# 调用 printinfo 函数
print_info(70,12.3,5+9j,True,"hello",[1,2,3],(7,8,9),{'a':123})
# (70, 12.3, (5+9j), True, 'hello', [1, 2, 3], (7, 8, 9), {'a': 123})
print_info([1,2,3])
# # ([1, 2, 3],)
print_info(*[1,2,3],'a')
# (1, 2, 3, 'a')
print_info((1,2,3))
# # ((1, 2, 3),)
print_info(*(1,2,3),'a')
# (1, 2, 3, 'a')
使用位置参数:
def print_info(num,*vartuple):
print(num)
print(vartuple)
# 调用 printinfo 函数
print_info(70, 60, 50)
# 70
# (60, 50)
** 变量名:
形参使用 **变量名:实参可以使用 a = 2、**字典对象
# ** 变量名:
# 形参使用 **变量名:实参可以使用 a = 2、**字典元素
def print_info(**attrs):
print(attrs)
print(type(attrs))
#
dic = {'a':123}
print_info(**dic,b = 4,c = 6)
# {'a': 123, 'b': 4, 'c': 6}
在形参中使用 * 和 ** 参数接收:
def print_info(num,*vartuple,**attrs):
print(num)
print(vartuple)
print(attrs)
# 调用 printinfo 函数
print_info(70, 60, 50,{'a':123},b = 456,c = 789)
# 70
# (60, 50, {'a': 123})
# {'b': 456, 'c': 789}
Python匿名函数:
使用 lambda 关键字创建匿名函数:
lambda 定义的函数只是一个表达式,而不是代码块
lambda 函数拥有自己的命名空间,不能够访问参数列表之外的 或 全局命名空间的参数
# 使 lambda 实现输出 x 的 y 次方
# 使用变量接收函数
cifang = lambda x,y:x**y
# 匿名函数的调用:使用接收到的变量进行调用
print(cifang(3,2))
# 9
# 拓展:使用变量接收函数名,然后可以使用变量进行函数调用
def print_info():
print("hello")
pr = print_info
pr()
# hello
return语句:
在函数内当遇到 return 语句时,退出函数并返回 return 后面的对象,可以是表达式 或 值
不带 return 语句的函数返回值为None,也就是没有返回值
def add_num(num_1, num_2):
# 返回 num_1 和 num_2 的和"
total = num_1 + num_2
print(total)
return total
# 调用 add_num 函数
# 使用变量接收函数的返回值
total = add_num(10, 20)
print(total)
# 30
# 30
Python变量作用域
运行 Python 程序时,Python会在作用域中依次寻找该变量,直到找到为止,否则会报错(未定义)
Python定义的变量并不是任意一个位置都可以进行访问的,主要根据变量的作用域。
局部作用域:比如在一个函数内部
全局作用域:一个 .py 文件中只要不是在函数内部,都是全局变量
内建作用域:
import builtins
print(dir(builtins))
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域
Python全局变量和局部变量:
定义在函数内的为局部变量,在外部访问局部变量会出现未定义的错误
定义在函数外的变量称为全局变量,可以在整个函数范围内访问
当函数中存在与全局变量重名的变量,以函数中的局部变量为准
定义在函数中的局部变量的作用域只在函数中
# 定义全局变量 total
total = 0
def add(num1,num2):
# 定义局部变量 total
total = num1 + num2
# 输出局部变量
print(total)
add(4,6)
# 10
print(total)
# 0
在函数内部,如果想要修改外部变量时,可以使用 global 关键字
global 全局变量名
在函数中使用全局变量,可以对全局变量进行修改。
注:如果只是在函数中使用了和全局变量相同的名字,则只是局部变量
# 定义全局变量 total
total = 0
def add(num1,num2):
# 使用 global 关键字声明全局变量 total
global total
total = num1 + num2
# 输出全局变量
print(total)
add(4,6)
# 10
# 输出全局变量
print(total)
# 10
nonlocal 嵌套作用域中的变量(嵌套函数,外层函数与内层函数之间):
修改嵌套函数之间的变量
def func_out():
num = 5
def func_inner():
# 使用嵌套函数中的 num 值
nonlocal num
num = 10
print("最内部函数中的 num 的值:",num)
func_inner()
print("嵌套函数中的 num 的值:",num)
func_out()
# 最内部函数中的 num 的值: 10
# 嵌套函数中的 num 的值: 10
Python模块:包含了所有定义的函数和变量的文件,后缀名为 .py
将某些方法存放在文件中,当某些脚本 或 交互式需要使用的时候,导入进去。
导入的文件,就称为模块。导入之后就可以使用导入的文件的函数等功能
import math
# 导入 math 库
print(math.exp(1) == math.e)
# 导入 exp() 和 e
# True
import 语句:
import 模块名 或 包:调用方法,使用 模块名.方法
当解释器遇到 import 语句时,如果模块在 搜索路径 中,则模块会被导入
注:搜索路径是解释器进行搜索的所有目录名的一个列表。
在一个 .py 文件中创建函数,在另一个 .py 文件中导入
func.py
# 在 func 模块中定义一个 print_info 函数
def print_info():
print("我是在 func 模块内部的")
test.py
# 导入 func 模块
import func
# 调用自定义的模块函数
func.print_info()
# 我是在 func 模块内部的
一个模块只会被导入一次,无论使用多少次 import 语句,都只导入一次
from 模块名 import 语句
from 模块名 import 子模块 或 函数 或 类 或 变量
导入的不是整个模块,而是 import 后面的对象
注:在调用导入的模块函数使,不使用模块名.函数名 而是 直接使用函数名进行调用
func.py
# 在 func 模块中定义一个 print_info 函数
def print_info():
print("我是在 func 模块内部的")
def get_info():
print("获取到了 func 模块的信息")
test.py
# 导入 func 模块
from func import get_info
# 调用自定义的模块函数
get_info()
# 获取到了 func 模块的信息
注:没有导入 print_info 方法,使用会报错
from 模块名 import *
使用 函数 或 变量 直接进行使用
将模块内的所有内容都导入到当前的模块中,但是不会将该模块的子模块的所有内容也导入
导入语句遵循如下规则:如果包定义文件 __init__.py 存在一个叫做 __all__ 的列表变量,
那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入
from func import *
# 调用自定义的模块函数
print_info()
# 我是在 func 模块内部的
get_info()
# 获取到了 func 模块的信息
注:不导入 _ 单个下划线开头的变量或方法
接着上一篇随笔,继续进行整理总结
注:以下内容基本都在以前的随笔中可以找到
Python定位模块:
导入模块时,系统会根据搜索路径进行寻找模块:
1.在程序当前目录下寻找该模块
2.在环境变量 PYTHONPATH 中指定的路径列表寻找
3.在 Python 安装路径中寻找
搜索路径是一个列表,所以具有列表的方法
使用 sys 库的 path 可以查看系统路径
import sys
# 以列表方式输出系统路径,可以进行修改
print(sys.path)
增加新目录到系统路径中
sys.path.append("新目录路径")
sys.path.insert(0,"新目录路径")
添加环境变量
set PYTHONPATH=安装路径\lib;
Python 会在每次启动时,将 PYTHONPATH 中的路径加载到 sys.path中。
Python命名空间和作用域:
变量拥有匹配对象的名字,命名空间包含了变量的名称(键)和所指向的对象(值)。
Python表达式可以访问局部命名空间和全局命名空间
注:当局部变量和全局变量重名时,使用的是局部变量
每个函数和类都具有自己的命名空间,称为局部命名空间
如果需要在函数中使用全局变量,可以使用 global 关键字声明,声明后,Python会将该关键字看作是全局变量
# global 全局变量名:
# 在函数中使用全局变量,可以对全局变量进行修改。
# 注:如果只是在函数中使用了和全局变量相同的名字,则只是局部变量
# 定义全局变量 total
total = 0
def add(num1,num2):
# 使用 global 关键字声明全局变量 total
global total
total = num1 + num2
# 输出全局变量
print(total)
add(4,6)
# 10
# 输出全局变量
print(total)
# 10
Python dir(模块名 或 模块名.方法名):
查看 模块名 或 模块名.方法名 的所有可以调用的方法
# 导入 math 库
import math
# 查看 math 可以调用的方法
print(dir(math))
'''
['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign', 'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'pi', 'pow', 'radians', 'remainder', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']
'''
import urllib.request
print(dir(urllib.request))
'''
['AbstractBasicAuthHandler', 'AbstractDigestAuthHandler', 'AbstractHTTPHandler', 'BaseHandler', 'CacheFTPHandler', 'ContentTooShortError', 'DataHandler', 'FTPHandler', 'FancyURLopener', 'FileHandler', 'HTTPBasicAuthHandler', 'HTTPCookieProcessor', 'HTTPDefaultErrorHandler', 'HTTPDigestAuthHandler', 'HTTPError', 'HTTPErrorProcessor', 'HTTPHandler', 'HTTPPasswordMgr', 'HTTPPasswordMgrWithDefaultRealm', 'HTTPPasswordMgrWithPriorAuth', 'HTTPRedirectHandler', 'HTTPSHandler', 'MAXFTPCACHE', 'OpenerDirector', 'ProxyBasicAuthHandler', 'ProxyDigestAuthHandler', 'ProxyHandler', 'Request', 'URLError', 'URLopener', 'UnknownHandler', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '__version__', '_cut_port_re', '_ftperrors', '_have_ssl', '_localhost', '_noheaders', '_opener', '_parse_proxy', '_proxy_bypass_macosx_sysconf', '_randombytes', '_safe_gethostbyname', '_splitattr', '_splithost', '_splitpasswd', '_splitport', '_splitquery', '_splittag', '_splittype', '_splituser', '_splitvalue', '_thishost', '_to_bytes', '_url_tempfiles', 'addclosehook', 'addinfourl', 'base64', 'bisect', 'build_opener', 'contextlib', 'email', 'ftpcache', 'ftperrors', 'ftpwrapper', 'getproxies', 'getproxies_environment', 'getproxies_registry', 'hashlib', 'http', 'install_opener', 'io', 'localhost', 'noheaders', 'os', 'parse_http_list', 'parse_keqv_list', 'pathname2url', 'posixpath', 'proxy_bypass', 'proxy_bypass_environment', 'proxy_bypass_registry', 'quote', 're', 'request_host', 'socket', 'ssl', 'string', 'sys', 'tempfile', 'thishost', 'time', 'unquote', 'unquote_to_bytes', 'unwrap', 'url2pathname', 'urlcleanup', 'urljoin', 'urlopen', 'urlparse', 'urlretrieve', 'urlsplit', 'urlunparse', 'warnings']
'''
Python globals和locals函数_reload函数:
globals( ):
返回所有能够访问到的全局名字
num = 5
sum = 0
def add(num):
func_sum = 0
func_sum += num
return func_sum
print(globals())
'''
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001F5F98CC2E0>, '__spec__': None, '__annotations__': {}, '__builtins__': , '__file__': 'G:/code/time/1.py', '__cached__': None, 'num': 5, 'sum': 0, 'add': }
'''
注:我此处的代码是停留在昨天的time模块中,所以在路径下会出现G:/code/time/1.py
locals( ):
在函数中使用 locals ,返回形参和局部变量
num = 5
sum = 0
def add(num):
func_sum = 0
func_sum += num
print(locals())
return func_sum
add(num)
# {'num': 5, 'func_sum': 5}
reload(模块名):reload 在 importlib 模块中
重新导入之前导入过的模块
注:当一个模块导入到另一个脚本时,模块顶层部分的代码只会被执行一次
# 重新导入模块
import func
# 导入自定义的模块
from importlib import reload
# reload 函数在 importlib 模块中
reload(func)
# 重新导入 func 模块
from func import get_info
get_info()
# 获取到了 func 模块的信息
使用reload的前提,是reload的 模块,之前已经使用import或者from导入过,否则会失败
import 导入的模块,使用模块名.方法的方式,reload会强制运行模块文件,然后原来导入的模块会被新使用的导入语句覆盖掉
from 导入的模块,本质是一个赋值操作
即在当前文件中(即执行 from 语句的文件)进行 attr = module.attr
注:reload 函数对 reload 运行之前的from语句没有影响
Python包:
包是一种管理 Python 模块命名空间的形式,采用 “点模块名称”
例:A.B 表示 A 模块的 B子模块
当不同模块间存在相同的变量名时,一个是使用 模块名.变量名 另一个是 变量名
当导入一个包时,Python 会根据 sys 模块的 path 变量中寻找这个包
目录中只有一个 __init__.py 文件才会被认为是一个包
导包常见的几种方式:
import 模块名 或 包:调用方法,使用 模块名.方法
from 模块名 import 子模块(子模块 或 函数 或 类 或 变量):使用函数调用
from 模块名 import * :使用函数进行调用
注:如果 __init__.py 文件中存在 __all__变量,则导入 __all__变量的值,在更新包的时候,注意修改__all__的值
__all__ = ["echo", "surround", "reverse"] 导入 * 时,从 __all__ 导入
包还提供 __path__ ,一个目录列表,每一个目录都有为这个包服务的 __init__.py 文件,先定义,后运行其他的__init__.py文件
__path__ :主要用于扩展包里面的模块
float_num = 2.635
print("输出的是%f"%(float_num))
# 输出的是2.635000
# 保留两位小数
print("输出的是%.2f"%(float_num))
# 输出的是2.63
float_num = 5.99
print("输出的数字是{}".format(float_num))
# 输出的数字是5.99
# 指定参数名
float_num = 5.99
strs = 'happy'
print("输出的数字是{num},输出的字符串是{str}".format(num = float_num,str = strs))
# 输出的数字是5.99,输出的字符串是happy
input(字符串):字符串通常为提示语句
输入语句
注:通常使用变量进行接收,input 返回字符串类型,如果输入的为数字,可使用 int 转化为数字
# input(字符串):字符串通常为提示语句
# 输入语句
# 注:通常使用变量进行接收,input 返回字符串类型,如果输入的为数字,可使用 eval 转化为数字
strs = input("请输入一个字符串")
print(type(strs))
print("输入的字符串为:",strs)
# 请输入一个字符串HELLO
#
# 输入的字符串为: HELLO
num = eval(input("请输入一个数字"))
print(type(num))
print("输入的数字为:",num)
# 请输入一个数字56
#
# 输入的数字为: 56
注:
input 使用 eval 进行转换时,如果输入的是
[1,2,3] 那么转换的就是 [1,2,3] 为列表类型
Python打开和关闭文件:
open(文件名,打开文件的模式[,寄存区的缓冲]):
文件名:字符串值
注:文件名带有后缀名
# 打开创建好的 test.txt 文件
f = open("test.txt",'r')
# 输出文件所有的内容
print(f.readlines( ))
# ['hello,world.\n']
# 关闭文件
f.close()
打开文件的模式:
r
以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
rb
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
r+
打开一个文件用于读写。文件指针将会放在文件的开头。
rb+
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
w
打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb
以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
w+
打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb+
以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+
打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
寄存区的缓冲:
小于 0 的整数:系统默认设置寄存区的大小
0:不进行寄存
1:进行寄存
大于 1 的整数:整数即为寄存区的缓冲区大小
Python read和write方法:
read():
从文件中读取字符串
注:Python 字符串可以是二进制数据,而不仅仅是文字。
语法:
文件对象.read([count])
count:打开文件需要读取的字符数
注:read 函数不使用 count 会尽可能多地读取更多的内容,通常一直读取到文件末尾
# 使用 count
# 打开创建好的 test.txt 文件
f = open("test.txt",'r')
# 输出文件的前 11 个字符
print(f.read(11))
# 关闭文件
f.close()
# hello,world
文件位置:
tell():
返回文件内当前指向的位置
f = open("test.txt",'r')
# 输出文件的前 11 个字符
f.read(11)
print(f.tell())
# 11
seek(offset [,from]):
改变当前文件的位置
offset:表示要移动的字节数
from :指定开始移动字节的参考位置。
0:文件开头
1:当前位置
2:文件末尾
# 打开创建好的 test.txt 文件
f = open("test.txt",'r')
# 输出文件的前 11 个字符
print(f.read(11))
# hello,world
# 返回文件内当前指向的位置
print(f.tell())
# 11
print(f.seek(0,0))
# 0
print(f.tell())
# 0
print(f.read(11))
# hello,world
# 关闭文件
f.close()
write( ):
将任意字符串写入一个文件中
注:Python字符串可以是二进制数据 和 文字,换行符('\n') 需要自己添加
语法:
文件对象.write(字符串)
程序:
# write 方法
# 打开创建好的 test.txt 文件
f = open("test.txt",'w')
# 在开头,添加文件内容
f.write('hey boy')
# 关闭文件
f.close()
PythonFile对象的属性:
一个文件被打开后,使用对象进行接收,接收的对象即为 File 对象
file.closed
返回true如果文件已被关闭,否则返回false
file.mode
返回被打开文件的访问模式
file.name
返回文件的名称
file = open("test.txt",'r')
# file.name 返回文件的名称
print(file.name)
# test.txt
# file.closed 如果文件未关闭返回 False
print(file.closed)
# False
# file.mode 返回被打开文件的访问模式
print(file.mode)
# r
# file.closed 如果文件已关闭返回 True
file.close()
print(file.closed)
# True
os 的方法:
mkdir(目录名):
在当前目录下创建新的目录
程序:
import os
# 创建新的目录-包结构
os.mkdir('新目录-test')
getcwd()方法:
显示当前的工作目录。
程序:
import os
print(os.getcwd())
# G:\code\time
chdir(修改的目录名):
修改当前的目录名为 修改的目录名
程序:
import os
# 创建新的目录-包结构
print(os.getcwd())
# D:\见解\Python\Python代码\vacation\备课\新目录-test
os.chdir('新目录-test2')
print(os.getcwd())
# D:\见解\Python\Python代码\vacation\备课\新目录-test\新目录-test2
rmdir(目录名):
删除目录
注:目录名下为空,没有其他文件
程序:
import os
os.rmdir('新目录-test2')
删除后包文件消失
rename(当前的文件名,新文件名):
将当前的文件名修改为新文件名
程序:
# os.rename('旧名字',’新名字‘)
import os
os.rename('旧名字.txt','新名字.txt')
remove(文件名):
删除文件
程序:
import os
os.remove('名称.txt')
'''
编程完成一个简单的学生管理系统,要求如下:
(1)使用自定义函数,完成对程序的模块化
(2)学生信息至少包括:姓名、性别及手机号
(3)该系统具有的功能:添加、删除、修改、显示、退出系统
设计思路如下:
(1) 提示用户选择功能序号
(2) 获取用户选择的能够序号
(3) 根据用户的选择,调用相应的函数,执行相应的功能
'''
stu_lst = [[],[],[],[],[]]
# 创建存储五个学生的容器
def show_gn():
'''展示学生管理系统的功能'''
print("==========================")
print("学生管理系统v1.0")
print("1.添加学生信息(请先输入1)")
print("2.删除学生信息")
print("3.修改学生信息")
print("4.显示所有学生信息")
print("0.退出系统")
print("==========================")
def tj_gn(num):
'''添加功能'''
stu_lst[num].append(input("请输入新学生的名字:"))
# 第一个参数为新学生的名字
stu_lst[num].append(input("请输入新学生的性别:"))
# 第二个参数为新学生的性别
stu_lst[num].append(input("请输入新学生的手机号:"))
# 第三个参数为新学生的手机号
stu_lst[num].append(num)
# 第四个参数为新学生的默认学号(从 0 开始)
def sc_gn():
'''删除功能'''
stu_xlh = int(eval(input("请输入需要删除的学生序列号:")))
xs_gn_returni = xs_gn(stu_xlh)
pd_str = input("请问确定删除吗? 请输入全小写字母 yes / no ? ")
# pd_str 判断是否删除学生信息
if pd_str == 'yes':
del stu_lst[xs_gn_returni]
print("删除完毕")
if pd_str == 'no':
print("删除失败")
def xg_gn():
'''修改功能'''
stu_xlh = int(eval(input("请输入需要修改的学生序列号:")))
xs_gn_returni = xs_gn(stu_xlh)
# xs_gn_returni 接收的是如果存在输入的学生序列号,则返回经过确认的索引下标
xg_str = input("请问需要修改该名学生哪一处信息,请输入提示后面的小写字母 (姓名)name,(性别)sex,(手机号)sjh")
if xg_str in ['name','sex','sjh']:
if xg_str == 'name':
stu_lst[xs_gn_returni][0] = input("请输入新的姓名值")
elif xg_str == 'sex':
stu_lst[xs_gn_returni][1] = input("请输入新的性别值")
else:
stu_lst[xs_gn_returni][2] = input("请输入新的手机号值")
else:
print("输入错误")
def xs_gn(stu_xlh = -1):
'''显示功能'''
print("姓名性别手机号序列号信息如下")
if stu_xlh == -1:
for i in stu_lst:
if i != []:
print(i)
else:
for i in range(len(stu_lst)):
if stu_xlh in stu_lst[i] and i != []:
print("该学生信息如下:")
print(stu_lst[i])
return i
show_gn()
gn_num = int(eval(input("请输入功能对应的数字:")))
# gn_num 功能对应的数字
num = 0
while 0 <= gn_num < 1000:
if gn_num == 1:
tj_gn(num)
num += 1
gn_num = int(eval(input("请输入功能对应的数字:")))
elif gn_num == 2:
sc_gn()
gn_num = int(eval(input("请输入功能对应的数字:")))
elif gn_num == 3:
xg_gn()
gn_num = int(eval(input("请输入功能对应的数字:")))
elif gn_num == 4:
xs_gn()
gn_num = int(eval(input("请输入功能对应的数字:")))
elif gn_num == 0:
print("退出系统")
exit()
else:
print("请重新运行该程序,输入的数字不在 0~4 之中")
exit()
a = 10
b = 8
print("a>b") if a>b else pass
pass 为何报错问题:
第一部分:print
第二部分:("a>b") if a>b else pass
第一种情况 print ("a>b")
第二种情况 print(pass)
pass 关键字,不用于输出,导致出错
Python 实现分层聚类算法
'''
1.将所有样本都看作各自一类
2.定义类间距离计算公式
3.选择距离最小的一堆元素合并成一个新的类
4.重新计算各类之间的距离并重复上面的步骤
5.直到所有的原始元素划分成指定数量的类
程序要点:
1.生成测试数据
sklearn.datasets.make_blobs
2.系统聚类算法
sklearn.cluster.AgglomerativeClustering
3.必须满足该条件不然会报错(自定义函数中的参数)
assert 1 <= n_clusters <= 4
4.颜色,红绿蓝黄
r g b y
5. o * v +
散点图的形状
6.[] 内可以为条件表达式,输出数组中满足条件的数据
data[predictResult == i]
7.访问 x 轴,y 轴坐标
subData[:,0] subData[:,1]
8.plt.scatter(x轴,y轴,c,marker,s=40)
colors = "rgby"
markers = "o*v+"
c 颜色 c=colors[i]
marker 形状 marker=markers[i]
9.生成随机数据并返回样本点及标签
data,labels = make_blobs(n_samples=200,centers=4)
make_blobs 为 sklearn.datasets.make_blobs 库
n_samples 为需要的样本数量
centers 为标签数
'''
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import AgglomerativeClustering
def AgglomerativeTest(n_clusters):
assert 1 <= n_clusters <= 4
predictResult = AgglomerativeClustering(
n_clusters=n_clusters,
affinity='euclidean',
linkage='ward'
).fit_predict(data)
# 定义绘制散点图时使用的颜色和散点符号
colors = "rgby"
markers = "o*v+"
# 依次使用不同的颜色和符号绘制每个类的散点图
for i in range(n_clusters):
subData = data[predictResult == i]
plt.scatter(
subData[:,0],
subData[:,1],
c = colors[i],
marker = markers[i],
s = 40
)
plt.show()
# 生成随机数据,200个点,4类标签,返回样本及标签
data , labels = make_blobs(n_samples=200,centers=4)
print(data)
AgglomerativeTest(2)
KNN算法基本原理与sklearn实现
'''
KNN 近邻算法,有监督学习算法
用于分类和回归
思路:
1.在样本空间中查找 k 个最相似或者距离最近的样本
2.根据这 k 个最相似的样本对未知样本进行分类
步骤:
1.对数据进行预处理
提取特征向量,对原来的数据重新表达
2.确定距离计算公式
计算已知样本空间中所有样本与未知样本的距离
3.对所有的距离按升序进行排列
4.选取与未知样本距离最小的 k 个样本
5.统计选取的 k 个样本中每个样本所属类别的出现概率
6.把出现频率最高的类别作为预测结果,未知样本则属于这个类别
程序要点:
1.创建模型需要用到的包
sklearn.neighbors.KNeighborsClassifier
2.创建模型,k = 3
knn = KNeighborsClassifier(n_neighbors = 3)
n_neighbors 数值不同,创建的模型不同
3.训练模型,进行拟合
knn.fit(x,y)
x 为二维列表数据
x = [[1,5],[2,4],[2.2,5],
[4.1,5],[5,1],[5,2],[5,3],[6,2],
[7.5,4.5],[8.5,4],[7.9,5.1],[8.2,5]]
y 为一维分类数据,将数据分为 0 1 2 三类
y = [0,0,0,
1,1,1,1,1,
2,2,2,2]
4.进行预测未知数据,返回所属类别
knn.predict([[4.8,5.1]])
5.属于不同类别的概率
knn.predict_proba([[4.8,5.1]])
'''
from sklearn.neighbors import KNeighborsClassifier
# 导包
x = [[1,5],[2,4],[2.2,5],
[4.1,5],[5,1],[5,2],[5,3],[6,2],
[7.5,4.5],[8.5,4],[7.9,5.1],[8.2,5]]
# 设置分类的数据
y = [0,0,0,
1,1,1,1,1,
2,2,2,2]
# 对 x 进行分类,前三个分为 0类,1类和2类
knn = KNeighborsClassifier(n_neighbors=3)
# 创建模型 k = 3
knn.fit(x,y)
# 开始训练模型
'''
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=3, p=2,
weights='uniform')
'''
knn.predict([[4.8,5.1]])
# array([1]) 预测 4.8,5.1 在哪一个分组中
knn = KNeighborsClassifier(n_neighbors=9)
# 设置参数 k = 9
knn.fit(x,y)
'''
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=9, p=2,
weights='uniform')
'''
knn.predict([[4.8,5.1]])
# array([1])
knn.predict_proba([[4.8,5.1]])
# 属于不同类别的概率
# array([[0.22222222, 0.44444444, 0.33333333]])
# 返回的是在不同组的概率
'''
总结:
knn = KNeighborsClassifier(n_neighbors=3)
使用 KNeighborsClassifier 创建模型 n_neighbors 为 k
使用 knn.fit() 进行预测
第一个参数为 二维列表
第二个参数为 一维列表
使用 predict_proba([[num1,num2]])
查看num1,num2 在模型中出现的概率
'''
'''
程序要点:import numpy as np
1.查看 e 的 多少次方
np.exp(参数)
2.查看参数的平方根
np.sqrt(参数)
3.生成三维四列的随机值(-1,1)之间
np.random.random((3,4))
4.向下取整
a = np.floor(参数)
5.将矩阵拉平
a.ravel()
6.修改矩阵的形状
a.shape(6,2)
7.将矩阵转置
a.T
8.将矩阵横行进行拼接
a = np.floor(参数)
b = np.floor(参数)
np.hstack((a,b))
9.将矩阵纵行进行拼接
np.vstack((a,b))
10.按照行进行切分数组,切分为3份
np.hsplit(a,3)
注:第二个参数可以为元组(3,4)
11.按照列进行切分数组,切分为2份
np.vsplit(a,2)
'''
import numpy as np
a = np.floor(10 *np.random.random((3,4)))
'''
array([[6., 8., 0., 9.],
[9., 3., 7., 4.],
[2., 4., 9., 1.]])
'''
np.exp(a)
'''
array([[4.03428793e+02, 2.98095799e+03, 1.00000000e+00, 8.10308393e+03],
[8.10308393e+03, 2.00855369e+01, 1.09663316e+03, 5.45981500e+01],
[7.38905610e+00, 5.45981500e+01, 8.10308393e+03, 2.71828183e+00]])
'''
np.sqrt(a)
'''
array([[2.44948974, 2.82842712, 0. , 3. ],
[3. , 1.73205081, 2.64575131, 2. ],
[1.41421356, 2. , 3. , 1. ]])
'''
a.ravel()
'''array([6., 8., 0., 9., 9., 3., 7., 4., 2., 4., 9., 1.])'''
a = np.floor(10 *np.random.random((3,4)))
b = np.floor(10 *np.random.random((3,4)))
np.hstack((a,b))
'''
array([[8., 2., 3., 8., 0., 1., 8., 6.],
[7., 1., 0., 3., 1., 9., 6., 0.],
[6., 0., 6., 6., 4., 3., 6., 3.]])
'''
np.vstack((a,b))
'''
array([[8., 2., 3., 8.],
[7., 1., 0., 3.],
[6., 0., 6., 6.],
[0., 1., 8., 6.],
[1., 9., 6., 0.],
[4., 3., 6., 3.]])
'''
a = np.floor(10 *np.random.random((2,12)))
np.hsplit(a,3)
'''
[array([[6., 4., 2., 2.],
[6., 2., 2., 8.]]), array([[1., 8., 8., 8.],
[1., 9., 3., 6.]]), array([[2., 6., 0., 8.],
[7., 1., 4., 3.]])]
'''
a = np.floor(10 *np.random.random((12,2)))
np.vsplit(a,3)
'''
[array([[2., 6.],
[7., 1.],
[4., 7.],
[3., 1.]]), array([[2., 5.],
[4., 6.],
[2., 0.],
[4., 4.]]), array([[9., 5.],
[7., 1.],
[2., 1.],
[5., 1.]])]
'''
注:上中下的这三篇随笔,在分类方面都会比较乱.
不同复制操作对比(三种)
'''
1.b = a
b 发生变化 a 也会发生变化
2.浅复制
c = a.view()
c.shape 发生变化,a.shape 不会发生变化
c 和 a 共用元素值,id 指向不同
c[1,0] = 1234 , a 的值也会发生变化
3.深复制
d = a.copy()
d[0,0] = 999
d 发生改变,a 不会发生改变
'''
import numpy as np
a = np.arange(1,8)
# array([1, 2, 3, 4, 5, 6, 7])
b = a
b[2] = 999
b
# array([ 1, 2, 999, 4, 5, 6, 7])
a
# array([ 1, 2, 999, 4, 5, 6, 7])
a = np.arange(1,9)
c = a.view()
c.shape = 4,2
'''
array([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
'''
a
# array([1, 2, 3, 4, 5, 6, 7, 8])
d = a.copy()
d[3] = 888
d
# array([ 1, 2, 3, 888, 5, 6, 7, 8])
a
# array([1, 2, 3, 4, 5, 6, 7, 8])
'''
1.查看列上最大索引的位置
data.argmax(axis = 0)
2.输出索引位置上的元素
data[index,range(data.shape[1])]
使用 range 输出几个元素
3.对numpy 对象进行扩展
a = np.array([4,5,6,2])
np.tile(a,(2,3))
4.对数组按行排序,从小到大
a = np.array([[4,3,5],[1,7,6]])
np.sort(a,axis = 1)
5.对数组元素进行排序,返回索引下标
a = np.array([4,3,1,2])
j = np.argsort(a)
a[j]
'''
import numpy as np
data = np.array([
[4,5,6,8],
[7,4,2,8],
[9,5,4,2]
])
data.argmax(axis = 0)
# array([2, 0, 0, 0], dtype=int64)
data.argmax(axis = 1)
# array([3, 3, 0], dtype=int64)
index = data.argmax(axis = 0)
# array([9, 5, 6, 8])
a = np.array([4,5,6,2])
np.tile(a,(2,3))
'''
array([[4, 5, 6, 2, 4, 5, 6, 2, 4, 5, 6, 2],
[4, 5, 6, 2, 4, 5, 6, 2, 4, 5, 6, 2]])
'''
a = np.array([[4,3,5],[1,7,6]])
'''
array([[4, 3, 5],
[1, 7, 6]])
'''
np.sort(a,axis = 1)
'''
array([[3, 4, 5],
[1, 6, 7]])
'''
np.sort(a,axis = 0)
'''
array([[1, 3, 5],
[4, 7, 6]])
'''
a = np.array([4,3,1,2])
j = np.argsort(a)
# array([1, 2, 3, 4])
正则表达式
1. /b 和 /B
# /bthe 匹配任何以 the 开始的字符串
# /bthe/b 仅匹配 the
# /Bthe 任何包含但并不以 the 作为起始的字符串
2. [cr] 表示 c 或者 r
[cr][23][dp][o2]
一个包含四个字符的字符串,第一个字符是“c”或“r”,
然后是“2”或“3”,后面 是“d”或“p”,最后要么是“o”要么是“2”。
例如,c2do、r3p2、r2d2、c3po等
3.["-a]
匹配在 34-97 之间的字符
4.Kleene 闭包
* 匹配 0 次或 多次
+ 匹配一次或 多次
? 匹配 0 次或 1 次
5.匹配全部有效或无效的 HTML 标签
]+>
6.国际象棋合法的棋盘移动
[KQRBNP][a-h][1-8]-[a-h][1-8]
从哪里开始走棋-跳到哪里
7.信用卡号码
[0-9]{15,16}
8.美国电话号码
\d{3}-/d{3}-/d{4}
800-555-1212
9.简单电子邮件地址
\w+@\w+\.com
[email protected]
10.使用正则表达式,使用一对圆括号可以实现
对正则表达式进行分组
匹配子组
对正则表达式进行分组可以在整个正则表达式中使用重复操作符
副作用:
匹配模式的子字符串可以保存起来
提取所匹配的模式
简单浮点数的字符串:
使用 \d+(\.\d*)?
0.004 2 75.
名字和姓氏
(Mr?s?\.)?[A-Z][a-z]*[A-Za-z-]+
11.在匹配模式时,先使用 ? ,实现前视或后视匹配 条件检查
(?P) 实现分组匹配
(?P:\w+\.)* 匹配以 . 结尾的字符串
google twitter. facebook.
(?#comment) 用作注释
(?=.com) 如果一个字符串后面跟着 .com 则进行匹配
(?<=800-) 如果一个字符串之前为 800- 则进行匹配
不使用任何输入字符串
(?

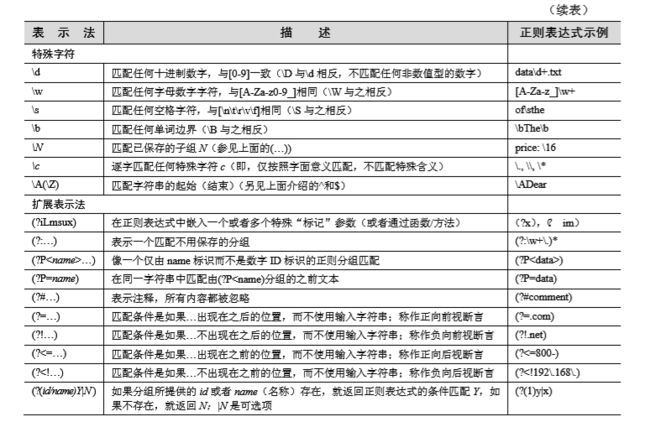



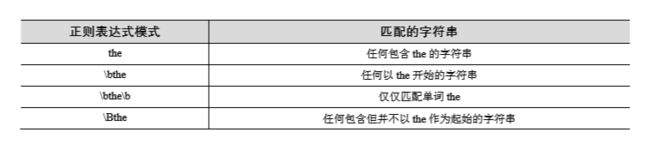






Pandas 复习
1.导包
import pandas as pd
2.数据读取,文件在该代码文件夹内
food_info = pd.read_csv('food_info.csv')
3.查看类型
food_info.dtypes
4.查看前五条数据
food_info.head()
查看前三条数据
food_info.head(3)
5.查看后四行数据
food_info.tail(4)
6.查看列名
food_info.columns
7.查看矩阵的维度
food_info.shape
8.取出第 0 号数据
food_info.loc[0]
使用切片获取数据
food_info.loc[3:6]
使用索引获取数据
food_info.loc['Name']
获取多个列
columns = ["Price","Name"]
food_info.loc[columns]
9.将列名放入到列表中
col_names = food_info.columns.tolist()
10.查看以 d 结尾的列
for c in col_names:
c.endswith("d")
11.将商品价格打一折
food_info["Price"]/10
12.最大值 最小值 均值
food_info["Price"].max()
food_info["Price"].min()
food_info["Price"].mean()
13.根据某一列进行排序
升序:
food_info.sort_values["Price",inplace=True]
降序:
food_info.sort_values["Price",inplace=True,ascending=False]
14.查看该数值是否为 NaN
price = food_info["Price"]
price_is_null = pd.isnull(price)
food_info[price_is_null]
Pandas 复习2
import pandas as pd
import numpy as np
food_info = pd.read_csv('food_info.csv')
1.处理缺失值(可使用平均数,众数填充)
查看非缺失值的数据:
price_is_null = pd.isnull(food_info["Price"])
price = food_info["Price"][price_is_null==False]
使用 fillna 填充
food_info['Price'].fillna(food_info['Price'].mean(),inplace = True)
2.求平均值
food_info["Price"].mean()
3.查看每一个 index 级,values 的平均值
food_info.pivot(index = "",values = "",aggfunc = np.mean)
4.查看总人数
food_info.pivot(index = "",values = ["",""],aggfunc = np.sum)
5.丢弃缺失值
dropna_columns = food_info.dropna(axis = 1)
将 Price 和 Time 列存在 NaN 的行去掉
new_food_info = food_info.dropna(axis = 0,subset = ["Price","Time"])
6.定位具体值到 83
row_index_83_price = food_info.loc[83,"Price"]
7.进行排序(sort_values 默认升序)
new_food_info.sort_values("Price")
8.将索引值重新排序,使用 reset_index
new_food_info.reset_index(drop = True)
9.使用 apply 函数
new_food_info.apply(函数名)
10.查看缺失值的个数
def not_null_count(column):
column_null = pd.isnull(column)
# column_null 为空的布尔类型
null = column[column_null]
# 将为空值的列表传递给 null
return len(null)
column_null_count = food_info.apply(not_null_count)
11.划分等级:年龄 成绩
def which_class(row):
pclass = row["Pclass"]
if pd.isnull(pclass):
return "未知等级"
elif pclass == 1:
return "第一级"
elif pclass == 2:
return "第二级"
elif pclass == 3:
return "第三级"
new_food_info.apply(which_class,axis = 1)
12.使用 pivot_table 展示透视表
new_food_info.pivot_table(index = " ",values=" ")
Series结构(常用)
1.创建 Series 对象
fandango = pd.read_csv("xxx.csv")
series_rt = fandango["RottenTomatoes"]
rt_scores = series_rt.values
series_film = fandango["FILM"]
# 获取数据 使用 .values
film_names = series_film.values
series_custom = Series(rt_scores,index = film_names)
2.使用切片获取数据
series_custom[5:10]
3.转换为列表
original_index = series_custom.index.tolist()
4.进行排序,此时的 original_index 是一个列表
sorted_index = sorted(original_index)
5.排序索引和值
series_custom.sort_index()
series_custom.sort_values()
6.将大于 50 的数据输出
series_custom[series_custom > 50]
7.设置索引值
fandango.set_index("FILM",drop = False)
8.显示索引值
fandango.index
9.显示数据类型
series_film.dtypes
10.在 apply 中使用匿名函数
series_film.apply(lambda x : np.std(x),axis = 1)
部分画图
import pandas as pd
unrate = pd.read_csv("unrate.csv")
1.转换日期时间
unrate["date"] = pd.to_datetime(unrate["DATE"])
import matplotlib.pyplot as plt
2.画图操作
plt.plot()
传递 x y 轴,绘制折线图
plt.plot(unrate["date"],unrate["values"])
3.展示
plt.show()
4.对 x 轴上的标签倾斜 45 度
plt.xticks(rotation = 45)
5.设置 x 轴 y 轴标题
plt.xlabel("xxx")
plt.ylabel("xxx")
6.设置名字
plt.title("xxx")
fig = plt.figure()
7.绘制子图
fig.add_subplot(行,列,x)
x 表示 在第几个模块
fig.add_subplot(4,3,1)
8.创建画图区域时指定大小
fig = plt.figure((3,6))
长为 3 宽为 6
9.画线时指定颜色
plt.plot(x,y,c="颜色")
10.将每一年的数据都显示出来
fig = plt.figure(figsize = (10,6))
colors = ['red','blue','green','orange','black']
# 设置颜色
for i in range(5):
start_index = i*12
end_index = (i+1)*12
# 定义开始和结束的位置
subset = unrate[start_index:end_index]
# 使用切片
label = str(1948 + i)
# 将标签 动态命名
plt.plot(subset['month'],subset['value'],c = colors[i],label = label)
# 进行绘制
plt.legend(loc = 'best')
loc = upper left 显示在左上角
# 打印右上角的数据
plt.show()
# 展示
11.柱状图:
明确:柱与柱之间的距离,柱的高度
高度:
cols = ['FILM','XXX','AAA','FFF','TTT','QQQ']
norm_reviews = reviews[cols]
num_cols = ['A','B','C','D','E','F']
bar_heights = norm_reviews.ix[0,num_cols].values
# 将每一列的高度都存起来
位置(距离 0 的距离):
bar_positions = arange(5) + 0.75
fig,ax = plt.subplots()
ax.bar(bar_positions,bar_heights,0.3)
先写位置后写距离
0.3 表示柱的宽度
ax.barh() 表示横着画
plt.show()
12.散点图
fig,ax = plt.subplots()
# 使用 ax 进行画图,ax 画图的轴,fig 图的样子
ax.scatter(norm_reviews['A'],norm_reviews['B'])
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
# 使用 add_subplot 绘制子图
fig = plt.figure(figsize = (5,10))
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax1.scatter(x,y)
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax2.scatter(x2,y2)
ax2.set_xlabel('x')
ax2.set_ylabel('y')
plt.show()
13.当存在多个值时,可以指定区间进行画图
# 指定 bins 默认为 10
fig,ax = plt.subplots()
ax.hist(unrate['Price'],bins = 20)
ax.hist(unrate['Price'],range(4,5),bins = 20)
14.设置 x y 区间
sey_xlim(0,50)
set_ylim(0,50)
15.盒图:
num_cols = ['AA','BB','CC','DD']
fig,ax = plt.subplots()
ax.boxplot(norm_reviews[num_cols].values)
# 绘制盒图
ax.set_xticklabels(num_cols,rotation = 45)
# 设置 x 轴标签,并倾斜45度
ax.set_ylim(0,5)
# 设置 y 的区间
plt.show()
16.去掉图标后的尺
ax.tick_params(bottom = "off",top = "off",left = "off",right = "off")
17.展示在右上角
ax.legend(loc = "upper right")
提取txt文本有效内容
from re import sub
from jieba import cut
def getWordsFromFile(txtFile):
# 获取每一封邮件中的所有词语
words = []
# 将所有存储邮件文本内容的记事本文件都使用 UTF8 编码
with open(txtFile,encoding = "utf8") as fp:
for line in fp:
# 遍历每一行,删除两端的空白字符
line = line.strip()
# 过滤掉干扰字符
line = sub(r'[.【】 0-9、-。,!~\*]','',line)
# 对 line 进行分词
line = cut(line)
# 过滤长度为 1 的词
line = filter(lambda word:len(word) > 1 ,line)
# 将文本预处理得到的词语添加到 words 列表中
words.extend(line)
return words
chain 和 Counter
from collections import Counter
from itertools import chain
1.使用 chain 对 allwords 二维列表进行解包
解包: chain(*allwords)
将 allwords 里面的子列表解出来
2.获取有效词汇的数目
freq = Counter(chain(*allwords))
3.Counter 返回的是可迭代对象出现的次数
使用 most_common 方法返回出现次数最多的前三个
.most_common(3)
Counter ("dadasfafasfa")
Counter({'a': 5, 'f': 3, 'd': 2, 's': 2})
Counter ("dadasfafasfa").most_common(2)
[('a', 5), ('f', 3)]
1.特征向量
每一个有效词汇在邮件中出现的次数(使用一维列表方法)
word 词汇出现的次数
一维列表.count(word)
2.将列表转换为数组形式 array(参数)
创建垃圾邮件,正常邮件训练集
array(列表对象 或 表达式)
3.使用 朴素贝叶斯算法
model = MultinomialNB()
4.进行训练模型 model.fit
model.fit(array数组,array数组)
5.对指定 topWords 数据使用函数
map(lambda x:words.count(x),topWords)
6.预测数据 model.predict ,返回值为 0 或 1
result = model.predict(array数组.reshape(1,-1))[0]
7.查看在不同区间的概率
model.predict_proba(array数组.reshape(1,-1))
8.条件语句,预测的结果便于区分 1 为垃圾邮件,0 为 正常邮件
return "垃圾邮件" if result == 1 else "正常邮件"
函数进阶1
'''
1.print "a>b" if a>b else pass 出错问题
pass 不可以被输出,导致报错
2.定义函数:
def 函数名():
return 可选
3.print 输出时会运行函数
print func_name()
注:func_name 中有 print 后,最好不要再使用 print 输出
会返回两个结果
4.最好让函数拥有返回值,便于维护
没有返回值会返回 None
5.如何制造函数:
抽象需求,注意可维护性
当创造方法时,注意可维护性和健壮性
6.参数使用 * 号,函数内为元组对象
7.可选参数存在默认值,必选参数没有默认值
8.健壮性:
直到函数会返回什么(异常处理,条件判断)
返回的结果是你需要的
9.测试时使用断言 assert
程序:'''
def func_name():
return 1
print(func_name())
# 1
def func_name2():
print("hello")
print(func_name2())
# hello
# None
def add(num1,num2):
return num1 + num2
print(add(5,6))
# 11
def add(*num):
d = 0
for i in num:
d += i
return d
print(add(1,2,3,4))
# 10
def add(num1,num2 = 4):
return num1 + num2
print(add(5))
# 9
print(add(5,8))
# 13
def add(num1,num2):
# 健壮性
if isinstance(num1,int) and isinstance(num2,int):
return num1 + num2
else:
return "Error"
print(add('a',(1,2,3)))
# Error
print(add(3,4))
# 7
'''
1.在循环中不要使用 排序函数
2.解决问题先要有正确的思路
写出伪代码
第一步做什么
第二步做什么
...
慢慢实现
3.使用 filter 函数
当函数中参数类型为 int 时才进行比较
def func(*num):
num = filter(lambda x:isinstance(x,int),num)
4.参数为 module ,将参数输出
print("doc %s"%module)
5.不要将代码复杂化,让人一看到就知道实现了什么功能
6.os.path.exists(file) 作为条件判断语句,看是否存在该 file 文件
7.检测函数 assert:
类型断言、数据断言
8.将问题实现的越简单越好,测试完整
9.使用下划线或驼峰命名函数名
get_doc getDoc
10.伪代码:
将思路写出来
11.默认值的好处:
省事,方便配置,多写注释
传入参数的数据类型
返回的数据的类型
12.测试
程序:'''
def function(*num):
# 输出 最大值和最小值
num = filter(lambda x : isinstance(x,int),num)
# 过滤掉不是 int 类型的数据
a = sorted(num)
return "max:",a[-1],"min:",a[0]
print(function(5,6,"adaf",1.2,99.5,[4,5]))
# ('max:', 6, 'min:', 5)
Python异常及异常处理:
当程序运行时,发生的错误称为异常
例:
0 不能作为除数:ZeroDivisionError
变量未定义:NameError
不同类型进行相加:TypeError
异常处理:
'''
try:
执行代码
except:
发生异常时执行的代码
执行 try 语句:
如果发生异常,则跳转到 except 语句中
如果没有异常,则运行完 try 语句,继续 except 后面的语句
'''
False:布尔类型,假。当条件判断不成立时,返回False。
# == 判断两个对象的值是否相等
print('' == False)
# False
print(None == False)
# False
print([] == False)
# False
print(() == False)
# False
print({} == False)
# False
# is 判断两个对象是否引用自同一地址空间
print('' is False)
# False
print(None is False)
# False
print([] is False)
# False
print(() is False)
# False
print({} is False)
# False
正则表达式补充2
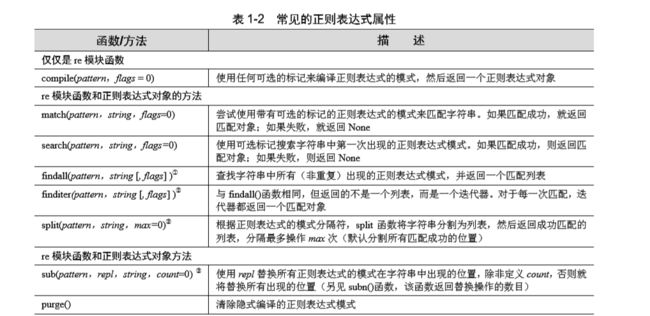

正则表达式基础1
'''
1.指定 eval()调用一个代码对象会提高性能
2.在进行模式匹配之前,正则表达式的模式必须编译为正则表达式对象
匹配时需要进行多次匹配,进行预编译可以提升速度
re.compile(pattern,flags = 0)
3.消除缓存
re.purge()
4.使用 re.S 后 . 可以匹配换行符 \n
5.使用了match() 和 search() 方法之后返回的对象称为匹配对象
匹配对象常用 group() 和 groups() 方法
group() 返回整个匹配对象 或 特定子组
groups() 返回一个包含唯一 或 全部子组的元组
6.match() 方法 对字符串的起始部分进行模式匹配
成功:返回一个匹配对象
失败:返回 None
7.search() 方法 对字符串任意位置进行模式匹配
成功:返回匹配对象
失败:返回 None
8.可以使用 pos , endpos 参数指定目标字符串的搜索范围
9.使用 . 匹配任何单个字符
.end 不能匹配 end
不能匹配 \n 换行符
使用 \. 匹配 .
10.创建字符集 [ ]
[cr][23] 表示 匹配第一个字符 c 或者 r
第二个字符 2 或者 3
程序:'''
import re
# match(pattern,string,flags = 0) 匹配示例
m = re.match('foo','foo')
if m is not None:
# 如果匹配成功则输出匹配内容
print(m.group())
# print(m.groups()) 返回空元组 因为没有子组
# foo
# 匹配对象具有 group() 和 groups() 方法
print(m)
#
# search(pattern,string,flags = 0) 匹配示例
m = re.search('foo','sea food')
if m is not None:
print(m.group())
# foo
print(m)
#
# 返回第四个元素的位置
# | 或 示例
bt = 'bat|bet'
m = re.match(bt,'bat')
# match 只匹配开头
m2 = re.search(bt,'abat')
# search 从开始到结尾
print(m.group())
# bat
print(m2.group())
# bat
# . 匹配任意字符示例
anyend = '.end'
m = re.match(anyend,'aend')
print(m.group())
# aend
m2 = re.search(anyend,'abcdend')
print(m2.group())
# dend
pi_pattern = '3.14'
m = re.match(pi_pattern,'3.14')
print(m.group())
# 3.14
pi_pattern = '3\.14'
# 将 . 转义
m = re.match(pi_pattern,'3.14')
print(m.group())
# 3.14
# [ ] 创建字符集
m = re.match('[cr][23][dp][po]','c3po')
print(m.group())
# c3po
m = re.match('[cr][23][dp][po]','c2do')
print(m.group())
# c2do
两数相加(B站看视频总结)
'''
两数相加:
给出两个 非空 的链表用来表示两个非负的整数
各自的位数是按照逆序的方式存储的 每一个节点只能保存 一位数
示例:
输入:(2->4->3) + (5->6->4)
输出:7->0->8
原因:342 + 465 = 807
'''
class ListNode:
def __init__(self,x):
# 在类声明时进行调用
self.val = x
self.next = None
# self 指的是自身,在类中声明函数需要添加才可以访问自身元素和其他函数
a = ListNode(10086)
# print(a,a.val)
# <__main__.ListNode object at 0x000001F76D46A148> 10086
# # 实现尾部元素指向头部元素
# move = a
# for i in range(4):
# temp = ListNode(i)
# # temp 为 ListNode 节点
# move.next = temp
# # move 下面的节点为 temp
# move = move.next
# # 将节点向下移动
# move.next = a
# # 重新指向头节点 a
class Solution1:
def addTwoNumbers(self,l1:ListNode,l2:ListNode) ->ListNode:
res = ListNode(10086)
move = res
carry = 0
# 进位
while l1 != None or l2 != None:
if l1 == None:
l1,l2 = l2,l1
# 替换位置,将 l1 作为输出
if l2 == None:
carry,l1.val = divmod((l1.val + carry),10)
# 对 l1 进行刷新
move.next = l1
# 设置数据
l1,l2,move = l1.next,l2.next,move.next
# 将数据向下移动
else:
carry,l1.val = divmod((l1.val + l2.val + carry),10)
# 如果都不为 None,则对应位置进行相加,然后进行求余
move.next = l1
# 更新数据
l1,move = l1.next,move.next
# 向下移动
if carry == 1:
move.next = ListNode(carry)
return res.next
class ListNode:
def __init__(self,x):
# 在类声明时进行调用
self.val = x
self.next = None
# self 指的是自身,在类中声明函数需要添加才可以访问自身元素和其他函数
# a = ListNode(10086)
# 使用迭代写法
class Solution1:
def addTwoNumbers(self,l1:ListNode,l2:ListNode) -> ListNode:
def recursive(n1,n2,carry = 0):
if n1 == None and n2 == None:
return ListNode(1) if carry == 1 else None
# 如果存在进位 则 输出 1
if n1 == None:
n1,n2 = n2,n1
# 当 n1 为空时 将位置替换
return recursive(n1,None,carry)
# 进行递归 使用 n1 进行递归
if n2 == None:
carry,n1.val = divmod((n1.val + carry),10)
# 返回值为 进位和数值 将 n1 的值进行替换
n1.next = recursive(n1.next,None,carry)
# 对 n1 接下来的数据继续进行调用,更新 n1 链表
return n1
carry,n1.val = divmod((n1.val + n2.val + carry),10)
# 当不存在空值时,进行相加,更新 n1 值
n1.next = recursive(n1.next,n2.next,carry)
# 设置 n1 接下来的值为 所有 n1 和 n2 接下来的运算调用
return n1
return recursive(l1,l2)
# 返回到内部函数中
猜数字游戏
'''
分析:
参数->指定整数范围,最大次数
在指定范围内随机产生一个整数,让用户猜测该数
提示,猜大,猜小,猜对
给出提示,直到猜对或次数用尽
'''
import random
def fail(os_num):
'''输入数字范围错误,没有猜数字次数'''
print("猜数失败")
print("系统随机的数为:", os_num)
print("游戏结束,欢迎下次再来玩")
return
def cxsr(count):
'''重新输入一个数'''
count -= 1
print("提示:您还有 %d 次机会" % (count))
if count == 0:
fail(os_num)
else:
user_cs = int(eval(input("请重新输入一个 0~8 之间的整数:\n")))
csz(os_num,count,user_cs)
def csz(os_num,count,user_cs,num_range = 8):
'''这是一个猜数字的函数'''
# num_range 是整数范围,count为最大次数,user_cs 为用户猜到的数
if user_cs > num_range or user_cs < 0 :
print("请重新运行,输入错误~")
return
if count == 0:
fail()
else:
if os_num > user_cs:
print("您猜的数字比系统产生的随机数小")
cxsr(count)
elif os_num < user_cs:
print("您猜的数字比系统产生的随机数大")
cxsr(count)
else:
print("恭喜您,猜对了~")
print("欢迎下次再玩!")
os_num = random.randint(0,8)
# os_num 为系统产生的随机数
print("游戏开始~")
user_cs = int(eval(input("这是一个猜数字的游戏(您有三次猜数字的机会),请输入一个 0~8 之间的整数\n")))
# user_cs 为用户猜到的数
csz(os_num,3,user_cs)
由于以前的随笔中的习题和我手里现存的题太多了,大约1000多道左右,所以此处不做整理了.只做一些知识点上的积累
函数进阶3
'''
1.考虑可维护性
一行代码尽量简单
列表推导式 lambda 匿名函数
2.断言语句用于自己测试,不要写在流程控制中
assert 不要写在 for 循环中
3.程序的异常处理 参数处理
try 异常处理 ,参数类型是什么
4.函数->尽量不要在特定环境下使用
5.断言就是异常->出错了就会抛出异常
6.局部变量和全局变量的区别:
当局部变量与全局变量重名时,生成一个在局部作用域中的变量
使用 global 声明 可以让局部变量修改为全局变量
7.参数为可变参数时,使用索引下标会修改原数据
程序:'''
def func1(num1,num2):
return num1 + num2
# 打印变量名
print(func1.__code__.co_varnames)
# ('num1', 'num2')
print(func1.__code__.co_filename)
# 文件名
# 第六点:
arg = 6
def add(num = 3):
arg = 4
return arg + num
print(add())
# 7
arg = 6
def add(num = 3):
# 使用 global 声明
global arg
return arg + num
print(add())
# 9
函数进阶4
'''
1.匿名函数:
一个表达式,没有 return
没有名称
执行很小的功能
2.判断参数是否存在 如果不存在会怎样->给出解决办法
3.可以使用 filter 和 lambda 进行使用
如果不进行 list 转换,则只返回 filter 对象
4.参数:
位置匹配:
func(name)
关键字匹配:
func(key = value)
从最右面开始赋予默认值
收集匹配:
元组收集
func(name,arg1,arg2)
func(*args)
字典收集
func(name,key1 = value1,key2 = value2)
func(**kwargs)
参数顺序
5.递归:
递归就是调用自身
程序:'''
# 第一点:
d = lambda x:x+1
print(d(2))
# 3
d = lambda x:x + 1 if x > 0 else "不大于0"
print(d(3))
# 4
print(d(-3))
# 不大于0
# 列表推导
g = lambda x:[(x,i) for i in range(5)]
print(g(5))
# 只传递了一个参数
# [(5, 0), (5, 1), (5, 2), (5, 3), (5, 4)]
# 第三点:
t = [1,4,7,8,5,3,9]
g = list(filter(lambda x: x > 5,t))
# 使用 list 将结果转换为列表
print(g)
# [7, 8, 9]
# 第四点:
# 对应位置传递参数
def func(arg1,arg2,arg3):
return arg1,arg2,arg3
print(func(1,2,3))
# (1, 2, 3)
# 关键字匹配,不按照位置进行匹配
def func(k1 = '',k2 = '',k3 = ''):
return k1,k2,k3
print(func(k2 = 4 , k3 = 5 , k1 = 3))
# (3, 4, 5)
# 收集匹配
# 元组
def func(*args):
return args
print(func(5,6,7,8,[1,2,3]))
# (5, 6, 7, 8, [1, 2, 3])
def func(a,*args):
# 先匹配 a 后匹配 *args
return args
print(func(5,6,7,8,[1,2,3]))
# (6, 7, 8, [1, 2, 3])
# 字典
def func(**kwargs):
return kwargs
print(func(a = 5,b = 8))
# {'a': 5, 'b': 8}
列表推导式
lst = [1,2,3]
lst2 = [1,2,3,5,1]
lst3 = [1,2]
lst4 = [1,2,3,65,8]
lst5 = [1,2,3,59,5,1,2,3]
def length(*args):
# 返回长度
lens = []
lens = [len(i) for i in args]
return lens
print(length(lst,lst2,lst3,lst4,lst5))
# [3, 5, 2, 5, 8]
dic = dict(zip(['a','b','c','d','e'],[4,5,6,7,8]))
lst = ["%s : %s" %(key,value) for key,value in dic.items()]
print(lst)
# ['a : 4', 'b : 5', 'c : 6', 'd : 7', 'e : 8']
关于类和异常的笔记
原文链接:https://www.runoob.com/python/python-object.html
面向对象技术简介
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
数据成员:类变量或者实例变量, 用于处理类及其实例对象的相关的数据。
方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
局部变量:定义在方法中的变量,只作用于当前实例的类。
实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
实例化:创建一个类的实例,类的具体对象。
方法:类中定义的函数。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
创建类
使用 class 语句来创建一个新类,class 之后为类的名称并以冒号结尾:
class ClassName:
'类的帮助信息' #类文档字符串
class_suite #类体
类的帮助信息可以通过ClassName.__doc__查看
class_suite 由类成员,方法,数据属性组成
实例
以下是一个简单的 Python 类的例子:
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
class Employee:
'所有员工的基类'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
empCount 变量是一个类变量,它的值将在这个类的所有实例之间共享。你可以在内部类或外部类使用 Employee.empCount 访问。
第一种方法__init__()方法是一种特殊的方法,被称为类的构造函数或初始化方法,当创建了这个类的实例时就会调用该方法
self 代表类的实例,self 在定义类的方法时是必须有的,虽然在调用时不必传入相应的参数。
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x10d066878>
__main__.Test
从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.__class__ 则指向类。
self 不是 python 关键字
"创建 Employee 类的第一个对象"
emp1 = Employee("Hany", 9000)
访问属性
可以使用点号 . 来访问对象的属性。使用如下类的名称访问类变量:
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCount
可以添加,删除,修改类的属性,如下所示:
del emp1.age # 删除 'age' 属性
你也可以使用以下函数的方式来访问属性:
getattr(obj, name[, default]) : 访问对象的属性。
hasattr(obj,name) : 检查是否存在一个属性。
setattr(obj,name,value) : 设置一个属性。如果属性不存在,会创建一个新属性。
delattr(obj, name) : 删除属性。
hasattr(emp1, 'age') # 如果存在 'age' 属性返回 True。
getattr(emp1, 'age') # 返回 'age' 属性的值
setattr(emp1, 'age', 8) # 添加属性 'age' 值为 8
delattr(emp1, 'age') # 删除属性 'age'
Python内置类属性
__dict__ : 类的属性(包含一个字典,由类的数据属性组成)
__doc__ :类的文档字符串
__name__: 类名
__module__: 类定义所在的模块(类的全名是'__main__.className',如果类位于一个导入模块mymod中,那么className.__module__ 等于 mymod)
__bases__ : 类的所有父类构成元素(包含了一个由所有父类组成的元组)
Python内置类属性调用实例如下:
python对象销毁(垃圾回收)
Python 使用了引用计数这一简单技术来跟踪和回收垃圾。
在 Python 内部记录着所有使用中的对象各有多少引用。
一个内部跟踪变量,称为一个引用计数器。
当对象被创建时, 就创建了一个引用计数, 当这个对象不再需要时, 也就是说, 这个对象的引用计数变为0 时, 它被垃圾回收。但是回收不是"立即"的,
由解释器在适当的时机,将垃圾对象占用的内存空间回收。
a = 40 # 创建对象 <40>
b = a # 增加引用, <40> 的计数
c = [b] # 增加引用. <40> 的计数
del a # 减少引用 <40> 的计数
b = 100 # 减少引用 <40> 的计数
c[0] = -1 # 减少引用 <40> 的计数
垃圾回收机制不仅针对引用计数为0的对象,同样也可以处理循环引用的情况。循环引用指的是,两个对象相互引用,但是没有其他变量引用他们。
这种情况下,仅使用引用计数是不够的。Python 的垃圾收集器实际上是一个引用计数器和一个循环垃圾收集器。
作为引用计数的补充, 垃圾收集器也会留心被分配的总量很大(及未通过引用计数销毁的那些)的对象。 在这种情况下, 解释器会暂停下来, 试图清理所有未引用的循环。
析构函数 __del__ ,__del__在对象销毁的时候被调用,当对象不再被使用时,__del__方法运行:
类的继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
继承语法
class 派生类名(基类名)
...
在python中继承中的一些特点:
1、如果在子类中需要父类的构造方法就需要显式的调用父类的构造方法,或者不重写父类的构造方法。详细说明可查看: python 子类继承父类构造函数说明。
2、在调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别在于类中调用普通函数时并不需要带上 self 参数
3、Python 总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。
语法:
派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
class SubClassName (ParentClass1[, ParentClass2, ...]):
...
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
class Parent: # 定义父类
parentAttr = 100
def __init__(self):
print "调用父类构造函数"
def parentMethod(self):
print '调用父类方法'
def setAttr(self, attr):
Parent.parentAttr = attr
def getAttr(self):
print "父类属性 :", Parent.parentAttr
class Child(Parent): # 定义子类
def __init__(self):
print "调用子类构造方法"
def childMethod(self):
print '调用子类方法'
c = Child() # 实例化子类
c.childMethod() # 调用子类的方法
c.parentMethod() # 调用父类方法
c.setAttr(200) # 再次调用父类的方法 - 设置属性值
c.getAttr() # 再次调用父类的方法 - 获取属性值
以上代码执行结果如下:
调用子类构造方法
调用子类方法
调用父类方法
父类属性 : 200
你可以继承多个类
class A: # 定义类 A
.....
class B: # 定义类 B
.....
class C(A, B): # 继承类 A 和 B
.....
可以使用issubclass()或者isinstance()方法来检测。
issubclass() - 布尔函数判断一个类是另一个类的子类或者子孙类,语法:issubclass(sub,sup)
isinstance(obj, Class) 布尔函数如果obj是Class类的实例对象或者是一个Class子类的实例对象则返回true。
方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法:
下表列出了一些通用的功能:
1 __init__ ( self [,args...] )
构造函数
简单的调用方法: obj = className(args)
2 __del__( self )
析构方法, 删除一个对象
简单的调用方法 : del obj
3 __repr__( self )
转化为供解释器读取的形式
简单的调用方法 : repr(obj)
4 __str__( self )
用于将值转化为适于人阅读的形式
简单的调用方法 : str(obj)
类属性与方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字可以为类定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,不能在类的外部调用。在类的内部调用 self.__private_methods
Python 通过改变名称来包含类名:
Traceback (most recent call last):
File "test.py", line 17, in
print counter.__secretCount # 报错,实例不能访问私有变量
AttributeError: JustCounter instance has no attribute '__secretCount'
Python不允许实例化的类访问私有数据,但可以使用 object._className__attrName( 对象名._类名__私有属性名 )访问属性:
单下划线、双下划线、头尾双下划线说明:
__foo__: 定义的是特殊方法,一般是系统定义名字 ,类似 __init__() 之类的。
_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *
__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。
原文链接:https://www.runoob.com/python3/python3-class.html
Python中的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。
对象可以包含任意数量和类型的数据。
类定义
语法格式如下:
class ClassName:
.
.
.
类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性。
类对象
类对象支持两种操作:属性引用和实例化。
属性引用使用和 Python 中所有的属性引用一样的标准语法:obj.name。
类对象创建后,类命名空间中所有的命名都是有效属性名:
类有一个名为 __init__() 的特殊方法(构造方法),该方法在类实例化时会自动调用
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
继承
Python 同样支持类的继承,如果一种语言不支持继承,类就没有什么意义。派生类的定义如下所示:
class DerivedClassName(BaseClassName1):
.
.
.
BaseClassName(示例中的基类名)必须与派生类定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:
class DerivedClassName(modname.BaseClassName):
多继承
Python同样有限的支持多继承形式。多继承的类定义形如下例:
class DerivedClassName(Base1, Base2, Base3):
.
.
.
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法:
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
类的实例化对象不能访问类中的私有属性
类的专有方法:
__init__ : 构造函数,在生成对象时调用
__del__ : 析构函数,释放对象时使用
__repr__ : 打印,转换
__setitem__ : 按照索引赋值
__getitem__: 按照索引获取值
__len__: 获得长度
__cmp__: 比较运算
__call__: 函数调用
__add__: 加运算
__sub__: 减运算
__mul__: 乘运算
__truediv__: 除运算
__mod__: 求余运算
__pow__: 乘方
Python 子类继承父类构造函数说明
原文链接:https://www.runoob.com/w3cnote/python-extends-init.html
如果在子类中需要父类的构造方法就需要显式地调用父类的构造方法,或者不重写父类的构造方法。
子类不重写 __init__,实例化子类时,会自动调用父类定义的 __init__。
父类名称.__init__(self,参数1,参数2,...)
实例
class Father(object):
def __init__(self, name):
self.name=name
print ( "name: %s" %( self.name))
def getName(self):
return 'Father ' + self.name
class Son(Father):
def __init__(self, name):
super(Son, self).__init__(name)
print ("hi")
self.name = name
def getName(self):
return 'Son '+self.name
if __name__=='__main__':
son=Son('runoob')
print ( son.getName() )
输出结果为:
name: runoob
hi
Son runoob
Python 异常(菜鸟教程)
原文:https://www.runoob.com/python/python-exceptions.html
BaseException 所有异常的基类
SystemExit 解释器请求退出
KeyboardInterrupt 用户中断执行(通常是输入^C)
Exception 常规错误的基类
StopIteration 迭代器没有更多的值
GeneratorExit 生成器(generator)发生异常来通知退出
StandardError 所有的内建标准异常的基类
ArithmeticError 所有数值计算错误的基类
FloatingPointError 浮点计算错误
OverflowError 数值运算超出最大限制
ZeroDivisionError 除(或取模)零 (所有数据类型)
AssertionError 断言语句失败
AttributeError 对象没有这个属性
EOFError 没有内建输入,到达EOF 标记
EnvironmentError 操作系统错误的基类
IOError 输入/输出操作失败
OSError 操作系统错误
WindowsError 系统调用失败
ImportError 导入模块/对象失败
LookupError 无效数据查询的基类
IndexError 序列中没有此索引(index)
KeyError 映射中没有这个键
MemoryError 内存溢出错误(对于Python 解释器不是致命的)
NameError 未声明/初始化对象 (没有属性)
UnboundLocalError 访问未初始化的本地变量
ReferenceError 弱引用(Weak reference)试图访问已经垃圾回收了的对象
RuntimeError 一般的运行时错误
NotImplementedError 尚未实现的方法
SyntaxError Python 语法错误
IndentationError 缩进错误
TabError Tab 和空格混用
SystemError 一般的解释器系统错误
TypeError 对类型无效的操作
ValueError 传入无效的参数
UnicodeError Unicode 相关的错误
UnicodeDecodeError Unicode 解码时的错误
UnicodeEncodeError Unicode 编码时错误
UnicodeTranslateError Unicode 转换时错误
Warning 警告的基类
DeprecationWarning 关于被弃用的特征的警告
FutureWarning 关于构造将来语义会有改变的警告
OverflowWarning 旧的关于自动提升为长整型(long)的警告
PendingDeprecationWarning 关于特性将会被废弃的警告
RuntimeWarning 可疑的运行时行为(runtime behavior)的警告
SyntaxWarning 可疑的语法的警告
UserWarning 用户代码生成的警告
什么是异常?
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
一般情况下,在Python无法正常处理程序时就会发生一个异常。
异常是Python对象,表示一个错误。
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
异常处理
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
语法:
以下为简单的try....except...else的语法:
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生
try的工作原理是,当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
使用except而不带任何异常类型
你可以不带任何异常类型使用except,如下实例:
try:
正常的操作
......................
except:
发生异常,执行这块代码
......................
else:
如果没有异常执行这块代码
以上方式try-except语句捕获所有发生的异常。但这不是一个很好的方式,我们不能通过该程序识别出具体的异常信息。因为它捕获所有的异常。
使用except而带多种异常类型
你也可以使用相同的except语句来处理多个异常信息,如下所示:
try:
正常的操作
......................
except(Exception1[, Exception2[,...ExceptionN]]]):
发生以上多个异常中的一个,执行这块代码
......................
else:
如果没有异常执行这块代码
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
try:
<语句>
finally:
<语句> #退出try时总会执行
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
finally:
print "Error: 没有找到文件或读取文件失败"
如果打开的文件没有可写权限,输出如下所示:
try:
fh = open("testfile", "w")
try:
fh.write("这是一个测试文件,用于测试异常!!")
finally:
print "关闭文件"
fh.close()
except IOError:
print "Error: 没有找到文件或读取文件失败"
当在try块中抛出一个异常,立即执行finally块代码。
finally块中的所有语句执行后,异常被再次触发,并执行except块代码。
变量接收的异常值通常包含在异常的语句中。在元组的表单中变量可以接收一个或者多个值。
元组通常包含错误字符串,错误数字,错误位置。
触发异常
我们可以使用raise语句自己触发异常
raise语法格式如下:
raise [Exception [, args [, traceback]]]
语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,args 是自已提供的异常参数。
最后一个参数是可选的(在实践中很少使用),如果存在,是跟踪异常对象。
实例
一个异常可以是一个字符串,类或对象。 Python的内核提供的异常,大多数都是实例化的类,这是一个类的实例的参数。
定义一个异常非常简单,如下所示:
def functionName( level ):
if level < 1:
raise Exception("Invalid level!", level)
# 触发异常后,后面的代码就不会再执行
注意:为了能够捕获异常,"except"语句必须有用相同的异常来抛出类对象或者字符串。
例如我们捕获以上异常,"except"语句如下所示:
try:
正常逻辑
except Exception,err:
触发自定义异常
else:
其余代码
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 定义函数
def mye( level ):
if level < 1:
raise Exception,"Invalid level!"
# 触发异常后,后面的代码就不会再执行
try:
mye(0) # 触发异常
except Exception,err:
print 1,err
else:
print 2
执行以上代码,输出结果为:
$ python test.py
1 Invalid level!
用户自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
Python3 错误和异常
原文链接:
https://www.runoob.com/python3/python3-errors-execptions.html

异常
即便 Python 程序的语法是正确的,在运行它的时候,也有可能发生错误。运行期检测到的错误被称为异常。
大多数的异常都不会被程序处理,都以错误信息的形式展现在这里:
实例
>>> 10 * (1/0) # 0 不能作为除数,触发异常
Traceback (most recent call last):
File "", line 1, in ?
ZeroDivisionError: division by zero
>>> 4 + spam*3 # spam 未定义,触发异常
Traceback (most recent call last):
File "", line 1, in ?
NameError: name 'spam' is not defined
>>> '2' + 2 # int 不能与 str 相加,触发异常
Traceback (most recent call last):
File "", line 1, in
TypeError: can only concatenate str (not "int") to str
异常以不同的类型出现,这些类型都作为信息的一部分打印出来: 例子中的类型有 ZeroDivisionError,NameError 和 TypeError。
错误信息的前面部分显示了异常发生的上下文,并以调用栈的形式显示具体信息。
异常处理
try/except
异常捕捉可以使用 try/except 语句。
以下例子中,让用户输入一个合法的整数,但是允许用户中断这个程序(使用 Control-C 或者操作系统提供的方法)。用户中断的信息会引发一个 KeyboardInterrupt 异常。
while True:
try:
x = int(input("请输入一个数字: "))
break
except ValueError:
print("您输入的不是数字,请再次尝试输入!")
try 语句按照如下方式工作;
首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)。
如果没有异常发生,忽略 except 子句,try 子句执行后结束。
如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。
如果一个异常没有与任何的 except 匹配,那么这个异常将会传递给上层的 try 中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
处理程序将只针对对应的 try 子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组,例如:
except (RuntimeError, TypeError, NameError):
pass
try/except...else
try/except 语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后。
else 子句将在 try 子句没有发生任何异常的时候执行。
以下实例在 try 语句中判断文件是否可以打开,如果打开文件时正常的没有发生异常则执行 else 部分的语句,读取文件内容:
for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except IOError:
print('cannot open', arg)
else:
print(arg, 'has', len(f.readlines()), 'lines')
f.close()
使用 else 子句比把所有的语句都放在 try 子句里面要好,这样可以避免一些意想不到,而 except 又无法捕获的异常。
异常处理并不仅仅处理那些直接发生在 try 子句中的异常,而且还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。例如:
>>> def this_fails():
x = 1/0
>>> try:
this_fails()
except ZeroDivisionError as err:
print('Handling run-time error:', err)
Handling run-time error: int division or modulo by zero
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
以下实例中 finally 语句无论异常是否发生都会执行:
实例
try:
runoob()
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
finally:
print('这句话,无论异常是否发生都会执行。')
抛出异常
Python 使用 raise 语句抛出一个指定的异常。
raise语法格式如下:
raise [Exception [, args [, traceback]]]
以下实例如果 x 大于 5 就触发异常:
x = 10
if x > 5:
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
执行以上代码会触发异常:
Traceback (most recent call last):
File "test.py", line 3, in
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
Exception: x 不能大于 5。x 的值为: 10
raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
>>> try:
raise NameError('HiThere')
except NameError:
print('An exception flew by!')
raise
An exception flew by!
Traceback (most recent call last):
File "", line 2, in ?
NameError: HiThere
用户自定义异常
你可以通过创建一个新的异常类来拥有自己的异常。异常类继承自 Exception 类,可以直接继承,或者间接继承,例如:
>>> class MyError(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
>>> try:
raise MyError(2*2)
except MyError as e:
print('My exception occurred, value:', e.value)
My exception occurred, value: 4
>>> raise MyError('oops!')
Traceback (most recent call last):
File "", line 1, in ?
__main__.MyError: 'oops!'
在这个例子中,类 Exception 默认的 __init__() 被覆盖。
当创建一个模块有可能抛出多种不同的异常时,一种通常的做法是为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类:
class Error(Exception):
"""Base class for exceptions in this module."""
pass
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
class TransitionError(Error):
"""Raised when an operation attempts a state transition that's not
allowed.
Attributes:
previous -- state at beginning of transition
next -- attempted new state
message -- explanation of why the specific transition is not allowed
"""
def __init__(self, previous, next, message):
self.previous = previous
self.next = next
self.message = message
大多数的异常的名字都以"Error"结尾,就跟标准的异常命名一样。
定义清理行为
try 语句还有另外一个可选的子句,它定义了无论在任何情况下都会执行的清理行为。 例如:
>>> try:
... raise KeyboardInterrupt
... finally:
... print('Goodbye, world!')
...
Goodbye, world!
Traceback (most recent call last):
File "", line 2, in
KeyboardInterrupt
以上例子不管 try 子句里面有没有发生异常,finally 子句都会执行。
如果一个异常在 try 子句里(或者在 except 和 else 子句里)被抛出,而又没有任何的 except 把它截住,那么这个异常会在 finally 子句执行后被抛出。
预定义的清理行为
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行。
这面这个例子展示了尝试打开一个文件,然后把内容打印到屏幕上:
for line in open("myfile.txt"):
print(line, end="")
以上这段代码的问题是,当执行完毕后,文件会保持打开状态,并没有被关闭。
关键词 with 语句就可以保证诸如文件之类的对象在使用完之后一定会正确的执行他的清理方法:
with open("myfile.txt") as f:
for line in f:
print(line, end="")
以上这段代码执行完毕后,就算在处理过程中出问题了,文件 f 总是会关闭。
Python assert(断言)
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况
语法格式如下:
assert expression
等价于:
if not expression:
raise AssertionError
assert 后面也可以紧跟参数:
assert expression [, arguments]
等价于:
if not expression:
raise AssertionError(arguments)
非常感谢菜鸟教程.
以下为网址:
https://www.runoob.com/
以前学习的时候会经常翻阅,学习一些编程知识
已附上原文链接,推荐到原链接进行访问,毕竟显示效果会差很多
类 巩固小结
'''
1.当方法具有结构时,使用 class 比函数要好
2.类中定义的 方法 或 属性 如果没有声明权限
在类外使用实例化对象可以直接访问
3.类中的方法,第一个参数一定要写上 self ,self 是约定好的
4.析构方法通常调用不到,垃圾回收机制中引用计数后会自动销毁
5.写程序之前:
伪代码 小的程序->直接写流程
大项目-> 先分析结构
6.父类通常具有一些公共的方法,使用子类进行扩展
子类可以使用父类中定义的初始化方法 __init__ , 但是参数可能不全
7.找到最小的节点,将节点与节点之间发生的关系使用不同的类进行标识
8._xxx, __xxx 外界都不应该直接访问,放到类中的方法中使用
9.方法一定要先实现再进行优化
10.使用装饰器 @property 后 下面的方法会变为属性
@property
def function(self,args):
pass
类实例化对象.function 调用 function 方法
11.@staticmethod 静态方法,下面的方法声明为"内置方法"
不需要再使用 self 进行调用
@staticmethod
def function(object):pass
12.最小惊讶原则
让很多人一看就知道在写什么
13.注意代码的复杂度
'''
# 示例:
class stu(object):
# 继承 object 基类
a = 'a'
# 定义一个属性
def __init__(self,name,age):
# 初始化赋值
self.name = name
self.age = age
def showName(self):
print(self.name)
def __del__(self):
# 析构方法,通常自动销毁
del self.name
del self.age
student = stu('张三',20)
student.showName()
print(student.a)
# 输出类中的属性
# a
class stu_extends(stu):
""" 继承 stu 类"""
pass
class lst_extends(list):
def append(self):
pass
# 继承列表类
模块小结
1.import 模块名(文件)
导入模块
2.查看模块内的方法
dir(模块名)
3.if __name__ == "__main__":
需要测试的语句
4.from 模块名 import 方法/属性/*
再使用时 使用 方法即可 不再使用模块名.方法
5.使用 __all__ = ["方法1","方法2","属性名1","属性名2"]
在导入 * 时,只导入该 all 中的方法或属性
在 __init__.py 文件第一行
6.import 模块名(文件) as 模块别名
7.搜索模块:
import sys
sys.path.append(r'绝对路径')
绝对路径指 导入的模块的 文件夹的位置
a.py 程序:
import linecache
print(linecache.__file__)
def show( ):
print("我是 0411 的模块")
程序:
import linecache
# 导入模块
print(dir(linecache))
# 查看都具有哪些方法
'''
['__all__', '__builtins__', '__cached__',
'__doc__', '__file__', '__loader__', '__name__',
'__package__', '__spec__', 'cache', 'checkcache',
'clearcache', 'functools', 'getline', 'getlines',
'lazycache', 'os', 'sys', 'tokenize', 'updatecache']
'''
linecache.__file__
# 查看模块地址
# F:\Python IDLE\lib\linecache.py
from math import pi
import sys
sys.path.append(r'D:\见解\Python\Python代码\学习\0411')
if __name__ == "__main__":
# 执行文件时,进行测试
print(linecache.__file__)
# F:\Python IDLE\lib\linecache.py
print(pi)
# 使用 math 中的 pi 属性
# 3.141592653589793
import a
# 导入 0411 的 a.py 文件
a.show()
# 我是 0411 的模块
以下部分内容为对以前内容的巩固,部分存在重复现象.
异常 巩固1
'''
1.索引异常
IndexError: list index out of range
2.语法异常
SyntaxError
3.缩进异常
IndentationError: unexpected indent
4.try 语句完整形态:try except else finally
5.try 内的语句 出错之后不会运行出现异常之后的 try 内语句
6.开发某些功能时 任何地方都可能会出错
通常参数传递过来时
读取某些未知文件时
打开某个网页时
7.except 捕获正确的异常,对异常进行处理
程序:'''
# lst = [1,2,3,4,5]
# print(lst[5])
# 索引异常,不存在下标为 5 的元素
# IndexError: list index out of range
# print 444
# 语法异常
# SyntaxError
# print(444)
# 缩进异常
# IndentationError: unexpected indent
lst = [1,2,3,4,5]
try :
print(lst[5])
print("出错之后不会运行出现异常之后的语句")
except IndexError as e :
'''try 出现异常时执行'''
print("出现索引异常")
else:
'''try 正常运行时执行'''
print("程序运行 OK, 没有问题")
finally:
print("无论是否出错一定会运行到 finally")
# 出现索引异常
# 无论是否出错一定会运行到 finally
异常 巩固2
'''
1.找到可能会抛出异常的地方,仅对这几行代码进行异常处理
2.明确会出现的异常类型
缩进,类型,语法,索引等等
3.捕获出现的异常
import sys
exc = sys.exc_info()
exc[1] 为问题出现的原因
4.日志 logging 模块
import logging
logger = logging.getLogger()
# 获取日志对象
logfile = 'test.log'
hdlr = logging.FileHandler('senging.txt')
# 存储文件日志
formatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')
# 以什么格式进行存储,时间,等级,日志信息
hdlr.setFormatter(formatter)
# 导入日志格式
logger.addHandler(hdlr)
# 将日志绑定
logger.setLevel(logging.NOTSET)
# 设置日志级别
5.断言 assert
assert 表达式,出错以后抛出的提示信息
表达式 : 1 > 4 3 > 2 1 == 2
断言绝对不能发生的错误,然后再处理异常
程序:'''
import logging
logger = logging.getLogger()
# 获取日志对象
logfile = 'test.log'
hdlr = logging.FileHandler('senging.txt')
# 存储文件日志
formatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')
# 以什么格式进行存储,时间,等级,日志信息
hdlr.setFormatter(formatter)
# 导入日志格式
logger.addHandler(hdlr)
# 将日志绑定
logger.setLevel(logging.NOTSET)
# 设置日志级别
import sys
try:
print(a)
except:
exc = sys.exc_info()
print(exc[1])
# 查看异常的问题
# name 'a' is not defined
print(exc[0])
#
print(exc)
# (, NameError("name 'a' is not defined"),
# )
logging.debug(exc[1])
附:日志这个还是很不错的,以下为显示的内容,会将错误保存起来,便于以后的查看
2020-07-25 09:51:01,344 DEBUG name 'a' is not defined
logging 日志基础
import logging
logger = logging.getLogger()
# 获取日志对象
logfile = 'test.log'
hdlr = logging.FileHandler('senging.txt')
# 存储文件日志
formatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')
# 以什么格式进行存储,时间,等级,日志信息
hdlr.setFormatter(formatter)
# 导入日志格式
logger.addHandler(hdlr)
# 将日志绑定
logger.setLevel(logging.NOTSET)
# 设置日志级别
注:此处只是显示了拥有哪些方法,具体实例还需要进行查阅相关资料
异常 巩固3
'''
1.with open("文件路径","模式") as fp:
操作
进入时 调用 __enter__ 方法
def __enter__(self):
print("开始执行 with 方法")
退出时 调用 __exit__ 方法
def __exit__(self,type,value,traceback):
print("退出 with 方法")
2.文件操作方法:
打开、读取、关闭
d = open('a','r')
d.read()
d.close()
3.可以自己定义异常,继承 Exception 类
程序:'''
# 查看 with 执行的方法
class sth(object):
def __enter__(self):
print("开始执行 with 方法")
def __exit__(self,type,value,traceback):
print("退出 with 方法")
with sth( ) as fp:
# with 自动关闭文件
pass
# 自定义异常
class myException(Exception):
# 继承 Exception
def __init__(self,error,msg):
self.args = (error,msg)
self.error = error
self.msg = msg
try:
raise myException(1,'my exception')
except Exception as e :
print(str(e))
# (1, 'my exception')
多线程复习1
多线程复习1
'''
1.进程在运行时会创建一个主线程,每一个进程只有一个主线程
2.子进程 pid 唯一标识符
3.任意时间里,只有一个线程在运行,且运行顺序不能确定(全局锁限制)
4.threading.Thread(target = test,args = [i])
target = 函数名 ,args = [ 参数 ]
5.可以继承 threading.Thread 然后重写 run 方法
class myThread(threading.Thread):
def run():
pass
程序:'''
import threading
# 导入线程库
def test():
print(1)
a = threading.Thread(target = test)
# 创建 a 线程
b = threading.Thread(target = test)
a.start()
# 启动线程
b.start()
a.join()
b.join()
# 结束之前使用 join 等待其他线程
import threading
# 导入线程库
import time
def test(i):
time.sleep(0.1)
print(i)
tests_thread = []
for i in range(0,10):
threads = threading.Thread(target = test,args = [i])
# 创建 a 线程
tests_thread.append(threads)
for i in tests_thread:
i.start()
# 启动线程
for i in tests_thread:
i.join()
# 结束之前使用 join 等待其他线程
print("线程结束")
'''
运行结果
2
0
1
8
7
9
6
534
线程结束
'''
多线程复习2
import time
def func_a():
print("a 函数开始")
time.sleep(2)
print("a 函数结束")
def func_b():
print("b 函数开始")
time.sleep(2)
print("b 函数结束")
b_time = time.time()
func_a()
func_b()
print(time.time() - b_time)
# 查看运行多少秒
'''
运行结果:
a 函数开始
a 函数结束
b 函数开始
b 函数结束
4.00050163269043
'''
import threading
import time
def func_a():
print("a 函数开始")
time.sleep(2)
print("a 函数结束")
def func_b():
print("b 函数开始")
time.sleep(2)
print("b 函数结束")
b_time = time.time()
_a = threading.Thread(target = func_a)
_b = threading.Thread(target = func_b)
_a.start()
_b.start()
# 开始
_a.join()
_b.join()
# 等待
print(time.time() - b_time)
# 查看时间
'''
运行结果:
a 函数开始
b 函数开始
b 函数结束a 函数结束
2.001542091369629
'''
通过使用了线程和不使用线程的对比,使用了线程的要快很多
线程里面的加锁和释放锁
# 加锁和释放
import threading
mlock = threading.Lock()
# 创建一把锁, mlock
# 当存在死锁时,防止死锁 可重用锁
num = 0
def a():
global num
mlock.acquire()
# 加锁
num += 1
mlock.release()
# 释放锁
print(num)
for i in range(10):
d = threading.Thread(target = a)
d.start()
'''
1.协程,微型进程:
yield 生成器
yield 会保存声明的变量,可以进行迭代
使用 接收函数返回的对象.__next__()
next(接收函数返回的对象)
.send() 方法
传递给函数中 yield 声明的对象
x = yield i
会发送给 x 变量
如果一直没有使用 send() ,x 值一直为 None
赋值之后如果没有修改则 x 一直为 send 后的值
2.此时 x 的值为 None ,并没有将 i 赋值给 x
x = yield i
程序:'''
# 创建一个包含 yield 声明的函数
def test_yield():
i = 0
a = 4
while i < a:
x = yield i
# x 通过 gener 进行赋值
i += 1
# 使用 .__next__() 查看迭代对象
gener = test_yield()
print(gener.__next__())
# 0
print(gener.__next__())
# 1
print(next(gener))
# 2
gener.send("x 通过 gener 进行赋值")
for i in test_yield():
# i 在 test_yield 中 yield 声明的迭代对象中
print(i,end = " ")
# 0 1 2 3
解决素数(质数)
def is_sushu(int_num):
# 判断输入的数是否为质数
if int_num == 1:
return False
if int_num == 2:
return True
else:
for i in range(2,int_num):
if int_num % i == 0:
return False
return True
def _get_sushu(max_num):
return [i for i in range(1,max_num) if is_sushu(i)]
# 使用列表推导式
if __name__ == "__main__":
a = _get_sushu(101)
# 返回判断素数的列表
print(a)
爬虫流程复习
设置爬虫终端:
URL 管理器 -> 网页下载器 -> 网页解析器 -> 产生价值数据
URL 管理器判断爬取网页链接
流程:
调度器询问 URL 管理器,是否存在要爬取的 URL
URL 管理器返回 是或否
调度器 从 URL 管理器中 取出一个 URL
URL 管理器 将 URL 传递给调度器
调度器将 URL 发送到下载器
下载器将 URL 下载的内容传递给调度器
调度器将 URL 下载的内容传递给解析器
解析器解析后传递给调度器
此时可以收集价值数据 调度器再将需要爬取的 URL 传递给 URL管理器 一直到没有需要爬取的 URL
URL 管理器:
管理待爬取的 URL 集合和已经爬取的 URL 集合
使用管理器是为了防止重复抓取和防止重复抓取一个 URL
URL 功能:
添加新的 URL 到待爬取的集合中
确定待添加的 URL 是否在 URL 中
获取待爬取的 URL
将 URL 从待爬取的移动到已爬取的集合中
判断是否还有待爬取的数据
URL 管理器实现方式:
将 待爬取的 和 已爬取的 URL 存储在集合中
set()
将 URL 存储在 关系数据库中,区分 URL 是待爬取还是已经爬取
MySQL urls(url,is_crawled)
缓存数据库 redis
网页下载器:
将 URL 对应的网页转换为 HTML 数据
存储到本地文件或者内存字符串中
requests 、 urllib 库实现下载
特殊情景处理器:
需要使用 Cookie 访问时:HTTPCookieProcessor
需要使用 代理 访问时:ProxyHandler
需要使用 加密 访问时:HTTPHandler
网页存在跳转关系访问时:HTTPRedirectHandler
网页解析器:
从网页提取有价值的数据
HTML 网页文档字符串
提取出价值数据
提取出新的 URL 列表
正则表达式 -> 模糊匹配
文档作为字符串,直接匹配
html.parser
BeautifulSoup -> 可以使用 html.parser 和 lxml
从 HTML 和 XHTML 中提取数据
语法:
创建 BeautifulSoup 对象
搜索节点 findall find
访问节点(名称,属性,文字)
lxml
->结构化解析
DOM 树
进行上下级的遍历
html
head
title
文本
body
a
href
文本
div
文本
爬虫:
确定目标
分析目标
URL 格式
数据的链接
数据的格式
网页编码
编写代码
执行爬虫
列表常用方法复习:
列表的常用操作:
1.使用 索引下标 或 切片
查找对应元素的值
修改特定位置上的值
2.删除列表元素
del 对象
对象.pop(index=-1)
对象.remove(元素)
对象.clear()
3.查看列表长度
len(对象)
4.重复 n 次
对象 * n
5.拼接两个列表对象
对象 + 对象
6.查看某一个元素是否在对象中
元素 in 对象
7.列表作为可迭代对象使用
for i in 对象
for i in range(len(对象))
8.列表可以嵌套
[[],[],[]]
9.列表内元素类型可以是任意类型
[任意类型,任意类型]
10.查看列表中最大值 最小值
max(对象) min(对象)
11.将其他类型数据转换为列表对象
list(对象)
list(可迭代对象)
12.在尾部增加元素
整体添加 对象.append(元素)
解包添加 对象.extend(元素)
13.在任意位置添加
对象.insert(index,元素)
14.排序
对象.sort()
倒序 对象.reverse()
15.查看元素索引位置
对象.index(元素)
字典常用操作复习
字典的常用操作:
1.创建字典对象
dict.fromkeys(seq[,value])
dic = {key1:value1,key2,value2}
dic = dict(zip([keys],[values]))
2.使用 对象['键值'] 访问字典元素
3.修改字典
对象['键值'] = 对象
4.删除字典元素或字典对象
del 对象['键值']
del 对象
对象.clear()
对象.pop(key)
对象.popitem()
5.获取字典长度
len(对象)
6.复制字典
对象.copy()
对象.update(对象2)
7.获取指定键值的元素
对象.get(key[,default=None])
8.查看 键 是否在字典中
key in 对象
9.获取字典中的元素
对象.keys()
对象.values()
对象.items()
10.对某一个元素设置默认值 如果该键已有值 则设置无效
对象.setdefault(key,default = None)
将"089,0760,009"变为 89,760,9
remove_zeros = lambda s: ','.join(map(lambda sub: str(int(sub)), s.split(',')))
remove_zeros("089,0760,009")
Linux最常用的基本操作复习
1.ctrl + shift + = 放大终端字体
2.ctrl + - 缩小终端字体
3.ls 查看当前文件夹下的内容
4.pwd 查看当前所在的文件夹
5.cd 目录名 切换文件夹
6.touch 如果文件不存在 则创建文件
创建一个文档
7.mkdir 创建目录
创建一个文件夹
8.rm 删除指定的文件名
9.clear 清屏
python连接数据库 MySQLdb 版本
import MySQLdb
# 导入 MySQL 库
class MysqlMethod(object):
def __init__(self):
# 前提:能够连接上数据库
self.get_connect()
def get_connect(self):
# 获取连接
try:
self.conn = MySQLdb.connect(
host = '127.0.0.1',
# 主机
user = 'root',
# 用户名
passwd = 'root',
# 密码
db = 'python_prac',
# 数据库
port = 3306,
# 端口号
charset = 'utf8'
# 避免字符编码问题
)
except MySQLdb.Error as e:
print("连接数据库时,出现错误")
print("错误信息如下:\n %s"%e)
else:
print("连接 MySQL 成功!")
def close_connect(self):
# 关闭连接
try:
# 关闭连接
self.conn.close()
# 关闭数据库连接
except MySQLdb.Error as e:
print("关闭数据库时出现错误")
print("错误信息如下:\n %s"%e)
else:
print("退出成功,欢迎下次使用!")
def get_onedata(self):
# 获取一条数据
cursor = self.conn.cursor()
# 获取游标
sql = 'select * from students where age between %s and %s'
# 查询语句
cursor.execute(sql,(15,25))
# execute(语句,(参数))
result = dict(zip([k[0] for k in cursor.description],cursor.fetchone()))
'''
zip(列表推导式,获取到的值)
字典的键:描述数据的值
字典的值:获取到的值
例:
lst_keys = ['a','b','c']
lst_values = [1,2,3]
dict(zip(lst_keys,lst_values))
得到的结果:
{'a': 1, 'b': 2, 'c': 3}
'''
# 元组类型转换为字典,便于通过索引查找数据
print("获取到一条数据:")
return result
def get_moredata(self,page,page_size):
# 添加多条数据
offset = (page - 1) * page_size
# 起始位置
cursor = self.conn.cursor()
sql = 'select * from students where age between %s and %s limit %s,%s;'
cursor.execute(sql,(15,45,offset,page_size))
result = list(dict(zip([k[0] for k in cursor.description],row)) for row in cursor.fetchall())
'''
使用 zip 将 列名 和 获取到的数据 压缩为一个个单独的二元组
但类型为 需要进行转换才能看到具体的值
zip([k[0] for k in cursor.description],row)
('id', 1)···
使用 dict 将 zip 类型转换为字典类型
dict(zip([k[0] for k in cursor.description],row))
{'id': 1,···}
使用 列表推导式 将每一个 row 变为查找到的多个数据中的一个
原理:[元素操作 for 元素 in 序列对象]
list -> []
list[ row 的操作 for row in 数据集]
'''
print("获取到多条数据:")
# result 为[{},{}] 形式
return result
def insert_onedata(self):
# 添加一条数据
try:
sql = "insert into stu_0415(name,school) values (%s,%s);"
# 查询语句
cursor = self.conn.cursor()
# 获取游标
need_info = ('王五','厦大')
# 需要插入的数据
cursor.execute(sql,need_info)
# 运行 sql 语句
self.conn.commit()
# 提交,如果没有提交,数据库数据不会发生变化
except :
print("插入数据失败")
self.conn.rollback()
# 如果个别数据插入成功了,则也不算入数据库
print("插入数据成功")
def main():
sql_obj = MysqlMethod()
# 创建一个 sql 对象
data = sql_obj.get_onedata()
# 获取一条数据
print(data)
moredata = obj.get_moredata(1,5)
# 查看 0~5 的数据
for item in moredata:
print(item)
# 循环遍历输出字典对象
print("-------------")
obj.insert_onedata()
# 插入一条数据
if __name__ == '__main__':
main()
# 运行主程序
显示列表重复值
lst = [1,2,3,2,1,5,5]
lst = list(filter(lambda x:lst.count(x) != 1,lst))
此处使用了 filter 和 lambda 进行混合使用,
x 为 lst 中的元素
应用场景
列表常用场景:
存储不同类型的数据
任意类型均可
列表存储相同类型的数据
类 node结点 next、data
通过迭代遍历,在循环体内部(多为 while 内),对列表的每一项都进行遍历
树的深度遍历等等
列表推导式的使用等等
元组常用场景:
作为函数的参数和返回值
传递任意多个参数 *args
函数内为元组形式
一次返回多个数据
return (a,b) 或 a,b
return a,b,c
接收函数返回值时
value1,value2 = 函数(参数)
函数(参数)即为 return (a,b)
格式化字符串
s1 = "%s %s"
s2 = ('hello','world')
s1%s2
'hello world'
数据库execute语句
cursor.execute(sql,(15,25))
让列表不可以被修改,保护数据
tuple(list对象)
字典常用场景:
for in 遍历字典
dic = {'a':1,'b':2,'c':3}
遍历键值:
for key in dic.keys():
print(key,end = " ")
遍历值:
for value in dic.values():
print(value,end = " ")
遍历键值对:
for key,value in dic.items():
print(key,":",value,end = " ")
使用字典(多个键值对)存储一个物体的信息
{"name":"张三","age":23}
将多个字典放到列表中,循环时对每一个字典进行相同操作
students_info = [{"name":"张三","age":23},{"name":"李四","age":22}]
访问张三数据:
students_info[0]['name']
操作 for i in range(len(students_info)):
students_info[i] 即可进行操作数据
for stu in students_info:
print(stu) 输出的为单个字典元素
类 扩展
关于类和对象的理解:
类 -> 设计图纸,设计应该具有哪些属性和行为
对象 -> 使用图纸制造出来的模型
类中定义普通方法,第一个参数为 self
self可以修改为别的,但最好还是不要改变,约定好的
self.属性 self.方法 调用 self 指向的对象的属性和行为
在类外可以为实例化对象直接创建属性,但是该属性只适用于该对象
不推荐使用,如果一定要使用,必须先创建属性,后使用方法
在 __init__(self,..) 初始化方法内,定义属性初始值有利于表达属性,定义方法
打印类的实例化对象时,实际调用的是 类中的 __str__方法
__str__必须返回字符串,可以自己定义
如果实例化对象 先使用 del 方法删除了,那么不会再执行类中的 __del__方法
保护私有公有对象,保护私有共有方法 在方法内都可以调用
先开发被使用的类,被包含操作的类
复习 装饰器
'''
装饰器的作用
引入日志
函数执行时间的统计
执行函数前预备处理
执行函数后清理功能
权限校验等场景
缓存
'''
# 定义一个函数,遵循闭包原则(函数作为参数)
def decorator(func):
'''定义一个装饰器函数'''
print("func 函数开始")
def wrapper():
# 创建装饰器内容
print("进行装饰")
func()
print("装饰完毕")
print("func 函数结束")
return wrapper
@decorator
# 加载 wrapper 函数,将 wrapper 函数传递给使用装饰器的函数
def house():
print("大房子")
house()
'''
运行结果:
func 函数开始
func 函数结束
进行装饰
大房子
装饰完毕
'''
re 正则表达式练习
字符串重复出现
'''
有一段英文文本,其中有单词连续重复了 2 次,编写程序检查重复的单词并只保留一个
例: This is a a desk.
输出 This is a desk.
'''
# 方法一
import re
x = 'This is a a desk.'
# 设置字符串
pattern = re.compile(r'\b(\w+)(\s+\1){1,}\b')
# \b 匹配单词和空格间的位置
# \w 匹配包括下划线的任何单词字符 [A-Za-z0-9_]
# \s 匹配任何空白字符
# {1,} 大于 1 个
matchResult = pattern.search(x)
# 查找这样的结果
x = pattern.sub(matchResult.group(1),x)
# sub 进行替换字符
# group(1) 为 a group(0) 为 a a
print(x)
# This is a desk.
# 方法二
import re
x = 'This is a a desk.'
# 设置字符串
pattern = re.compile(r'(?P\b\w+\b)\s(?P=f)')
# # \b 匹配单词和空格间的位置
# \w 匹配包括下划线的任何单词字符 [A-Za-z0-9_]
matchResult = pattern.search(x)
# 匹配到 a a
x = x.replace(matchResult.group(0),matchResult.group(1))
# 字符串对象.replace(旧字符串,新字符串)
# print(matchResult.group(0))
# a a
# print(matchResult.group(1))
# a
print(x)
# This is a desk.
最基本的Tkinter界面操作
'''
1.创建应用程序主窗口对象
root = Tk()
2.在主窗口中,添加各种可视化组件
btn1 = Button(root)
btn1["text"] = "点我"
3.通过几何布局管理器,管理组件得大小和位置
btn1.pack()
4.事件处理
通过绑定事件处理程序,响应用户操作所触发的事件
def songhua(e):
messagebox.showinfo("Message","送你一朵玫瑰花")
print("送花花")
btn1.bind("",songhua)
5.Tk() 的对象.mainloop() 方法会一直进行事件循环,监听用户操作
6.Button() 组件的参数为 Tk() 对象
Button() 的实例化对象 ["text"] 内容为显示在按钮上的内容
7.from tkinter import messagebox 显示点击之后提示的窗口
messagebox.showinfo("Message","送你一朵玫瑰花")
第一个参数为 标题
第二个参数为 显示信息
8.btn1.bind("",songhua)
使用创建好的按钮对象绑定鼠标事件和对应需要运行的函数
9.root.mainloop() 事件循环,一直监听用户操作
程序:'''
from tkinter import *
from tkinter import messagebox
root = Tk()
# 创建一个窗口对象
btn1 = Button(root)
btn1["text"] = "Submit"
btn1.pack()
# 将组件对象合理的放在窗口中
def songhua(e):
# e 为事件 event
messagebox.showinfo("Message","送你一朵玫瑰花")
print("送花花")
btn1.bind("",songhua)
# 表示鼠标左键单击
root.mainloop()
# root.mainloop() 事件循环,一直监听用户操作
Tkinter经典写法
'''
1.继承 tkinter.Frame 类,实现类的基本写法
2.创建 主窗口 及 主窗口大小 位置 及 标题
3.将需要添加的组件放入到类中进行创建,
继承的 Frame 类需要使用 master 参数作为父类的初始化使用
4.初始化时,将属性和方法都进行初始化,此时可以将 GUI 程序所要实现的功能确定好
5.在类中定义事件发生时,需要实现的功能
6.self.btn1["command"] = self.kuaJiang
btn1["command"] 为事件发生时进行相应的函数
7.self.btnQuit = Button(self,text = "退出",command = root.destroy)
退出按钮的写法
'''
from tkinter import *
from tkinter import messagebox
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.btn1 = Button(self)
# self 为组件容器
self.btn1["text"] = "Hany love Python."
# 按钮的内容为 btn1["text"]定义的内容
self.btn1.pack()
# 最佳位置
self.btn1["command"] = self.kuaJiang
# 响应函数
self.btnQuit = Button(self,text = "退出",command = root.destroy)
# 设置退出操作
self.btnQuit.pack()
def kuaJiang(self):
messagebox.showinfo("人艰不拆","继续努力,你是最棒的!")
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("200x200+200+300")
# 创建大小
root.title("GUI 经典写法")
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
Label 组件基本写法
'''
1.width,height 指定区域大小
文本 汉字 2 个字节
2.font 指定字体和字体大小
font(font_name,size)
3.image 显示在 Label 上的图像 支持 gif 格式
4.fg 前景色
5.bg 背景色
6.justify 针对多行文字的对齐
left center right
7.self.lab1 = Label(self,text = "Label实现",width = 10,height = 2,
bg = 'black',fg = 'white')
8. photo_gif = PhotoImage(file = "images/小熊.gif")
self.lab3 = Label(self,image = photo_gif)
将照片传递给 photo_gif 然后使用 Label 将图片变量作为参数进行传递
9.self.lab4 = Label(self,text = " Hany加油\n 人艰不拆!"
,borderwidth = 1,relief = "solid",justify = "right")
borderwidth 设置文本线的宽度 justify 表示左对齐 右对齐
'''
from tkinter import *
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.lab1 = Label(self,text = "Label实现",width = 10,height = 2,
bg = 'black',fg = 'white')
self.lab1.pack()
self.lab2 = Label(self,text = "Labe2实现",width = 10,height = 2,
bg = 'black',fg = 'white',font = ("宋体",14))
self.lab2.pack()
# 显示图像
global photo_gif
# 将 photo_gif 设置为全局变量,防止方法调用后销毁
photo_gif = PhotoImage(file = "路径/图片名.gif")
self.lab3 = Label(self,image = photo_gif)
self.lab3.pack()
# 显示多行文本
self.lab4 = Label(self,text = " Hany加油\n 人艰不拆!"
,borderwidth = 1,relief = "solid",justify = "right")
self.lab4.pack()
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("300x300+400+300")
# 创建大小
root.title("Label 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
注:图片路径和图片要修改为自己的
类实例化的对象调用的方法或属性来自于类的哪个方法中
__init__ 构造方法 对象创建 p = Person()
__del__ 析构方法 对象回收
__repr__ , __str__ 打印,转换 print(a)
__call__ 函数调用 a()
__getattr__ 点号运算 a.xxx
__setattr__ 属性赋值 a.xxx = value
__getitem__ 索引运算 a[key]
__setitem__ 索引赋值 a[key]=value
__len__ 长度 len(a)
每个运算符实际上都对应了相应的方法
运算符+ __add__ 加法
运算符- __sub__ 减法
<,<=,== __lt__,__le__,__eq__ 比较运算符
>,>=,!= __gt__,_ ge__,__ne__ 比较运算符
|,^,& __or__,__xor__,__and__ 或,异或,与
<<,>>__lshift__,__ rshift__ 左移,右移
*,/,%,// __mul__,__truediv__,__mod__,__floordiv__ 乘,浮点除,模运算(取余),整数除
** __pow__ 指数运算
tkinter Button基本用语
'''
1.self.btn2 = Button(root,image = photo,command = self.login)
使用 image 图片作为按钮,command 作为响应
2.self.btn2.config(state = "disabled")
对按钮进行禁用
3.Button 中 anchor 控制按钮上的图片位置
N NE E SE SW W NW CENTER
默认居中
'''
from tkinter import *
from tkinter import messagebox
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.btn1 = Button(root,text = '登录',command = self.login,
width = 5,height = 2,anchor = E)
# command 进行操作的函数
self.btn1.pack()
global photo
photo = PhotoImage(file = "图片路径/图片名.gif")
self.btn2 = Button(root,image = photo,command = self.login)
self.btn2.pack()
# self.btn2.config(state = "disabled")
# # 设置按钮为禁用按钮
def login(self):
messagebox.showinfo("博客园","欢迎使用~")
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("300x300+400+300")
# 创建大小
root.title("Button 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
tkinter Entry基本用法
'''
1.BooleanVar() 布尔类型
2.IntVar() 整数类型
3.DoubleVar() 浮点数类型
4.StringVar() 字符串类型
5.self.entry1 = Entry(self,textviable = v1)
textviable 实现双向关联
6.v1.set("admin")
# 设置单行文本的值
7.v1.get() self.entry1.get() 获取的是单行文本框中的值
8.self.entry_passwd = Entry(self,textvariable = v2,show = "*")
textvariable 进行绑定 v2
v2 = StringVar()
用户输入后,show 显示为 *
9.Button(self,text = "登录",command = self.login).pack()
登录操作
10.点击登陆后执行的函数可以与数据库进行交互,达到验证的目的
self.组件实例化对象.get() 获取值
'''
from tkinter import *
from tkinter import messagebox
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.lab1 = Label(self,text = "用户名")
self.lab1.pack()
# StringVar() 绑定到指定的组件,StringVar 和 v1 一起变化
v1 = StringVar()
self.entry_user = Entry(self,textvariable = v1)
self.entry_user.pack()
v1.set("admin")
# 设置单行文本的值
# v1.get() self.entry_user.get() 获取的是单行文本框中的值
# 创建密码框
self.lab2 = Label(self,text = "密码")
self.lab2.pack()
v2 = StringVar()
self.entry_passwd = Entry(self,textvariable = v2,show = "*")
self.entry_passwd.pack()
Button(self,text = "登录",command = self.login).pack()
def login(self):
username = self.entry_user.get()
passwd = self.entry_passwd.get()
# 数据库进行操作,查看是否存在该用户
print("用户名:" + username)
print("密码:" + passwd)
if username == "Hany" and passwd == "123456":
messagebox.showinfo("博客园","欢迎使用~")
else:
messagebox.showinfo("Error","请重新输入~")
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("300x300+400+300")
# 创建大小
root.title("Button 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
此处的用户名是 Hany , 密码是 123456
Text多行文本框基本用法
#coding=gbk
'''
1.Text(root,width,height,bg)
主窗口,宽度,高度,背景色
2.使用 .insert() 方法添加内容
Text 对象.insert(几行.几列,"内容")
w1.insert(2.3,"···")
END 为最后位置
self.w1.insert(END,'[end]')
3.Button(窗口对象,text = "内容",command = "self.函数名").pack([side = "left"])
Button(self,text = "返回文本",command = self.returnText).pack(side = "left")
text 显示的内容 command 运行的函数 pack 位置,使用 side 后,按钮按照 pack 来
4.在类中定义的属性,不会因为运行函数方法后,就销毁
self.photo 不用再使用 global 进行声明
5.使用 PhotoImage 将图片存起来后,将图片显示在多行文本 Text 中
self.photo = PhotoImage(file = '图片路径/图片名.gif')
self.photo = PhotoImage(file = 'images/logo.gif')
使用 .image_create(位置,image = self.photo) 进行添加
self.w1.image_create(END,image = self.photo)
6.添加按钮组件到文本中
btn1 = Button(文本内容,text = "内容")
7.self.w1.tag_config (内容,background 背景颜色,foreground 文字颜色)
8.self.w1.tag_add("内容",起始位置,终止位置)
tag_add 加入内容
9.self.w1.tag_bind("内容","事件",self.函数名)
self.w1.tag_bind("baidu","",self.webshow)
10.webbrowser.open("网址")
打开一个网址
'''
from tkinter import *
from tkinter import messagebox
# 显示消息
import webbrowser
# 导入 webbrowser 到时候点击字体跳转使用
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
# 创建文字 Text(root 主窗口对象,width 宽度,height 高度,bg 背景色)
# 只对于文本有效
self.w1 = Text(root,width = 100,height = 40,bg = "gray")
# 设置背景色 bg = "gray"
self.w1.pack()
self.w1.insert(1.0,"0123456789\nabcdefg")
# 1.0 在 第一行 第零列 插入数据
self.w1.insert(2.3,"活在当下\n结发为夫妻,恩爱两不疑\n言行在于美,不在于多")
# 2.3 在 第二行 第三列
Button(self,text = "重复插入文本",command = self.insertText).pack(side = "left")
# 水平排列 side = "left"
Button(self,text = "返回文本",command = self.returnText).pack(side = "left")
Button(self,text = "添加图片",command = self.addImage).pack(side = "left")
Button(self,text = "添加组件",command = self.addWidget).pack(side = "left")
Button(self,text = "通过 tag 控制文本",command = self.testTag).pack(side = "left")
def insertText(self):
'''INSERT 索引表示在光标处插入'''
self.w1.insert(INSERT,'Hany')
# END 索引号表示在最后插入
self.w1.insert(END,'[end]')
# 在文本区域最后
self.w1.insert(1.2,"(.-_-.)")
def returnText(self):
'''返回文本内容'''
# Indexes(索引) 是用来指向 Text 组件中文本的位置
# Text 的组件索引 也是对应实际字符之间的位置
# 核心:行号从 1 开始,列号从 0 开始
print(self.w1.get(1.2,1.6))
print("文本内容:\n" + self.w1.get(1.0,END))
def addImage(self):
'''增加图片'''
self.photo = PhotoImage(file = 'images/logo.gif')
self.w1.image_create(END,image = self.photo)
def addWidget(self):
'''添加组件'''
btn1 = Button(self.w1,text = "Submit")
self.w1.window_create(INSERT,window = btn1)
# 添加组件
def testTag(self):
'''将某一块作为特殊标记,并使用函数'''
self.w1.delete(1.0,END)
self.w1.insert(INSERT,"Come on, you're the best.\n博客园\nHany 加油!!!")
# self.w1.tag_add("good",1.0,1.9)
# 选中标记区域
# self.w1.tag_config("good",background = "yellow",foreground = "red")
# 单独标记某一句,背景色 字体色
self.w1.tag_add("baidu",3.0,3.4)
#
self.w1.tag_config("baidu",underline = True,background = "yellow",foreground = "red")
self.w1.tag_bind("baidu","",self.webshow)
def webshow(self,event):
webbrowser.open("http://www.baidu.com")
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("500x300+400+300")
# 创建大小
root.title("Button 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
Radiobutton基础语法
'''
1.Radiobutton(root 主窗口,text 文本内容,value 值(可以通过set 和 get 获取到的值),variable 变量修改原来的StringVar)
self.radio_man = Radiobutton(root,text = "男性",value = "man",variable = self.v)
2.Button(root,text = "提交",command = self.confirm).pack(side = "left")
设置按钮进行提交,然后响应的函数
'''
from tkinter import *
from tkinter import messagebox
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.v = StringVar()
#String类型
self.v.set("man")
# 默认为 man 选中
self.radio_man = Radiobutton(self,text = "男性",value = "man",variable = self.v)
# Radiobutton(root/self 主窗口,text 文本内容,value 值(可以通过set 和 get 获取到的值),variable 变量修改原来的StringVar()变量也修改)
self.radio_woman = Radiobutton(self,text = "女性",value = "woman",variable = self.v)
self.radio_man.pack(side = "left")
self.radio_woman.pack(side = "left")
# 放到最佳位置
Button(self,text = "提交",command = self.confirm).pack(side = "left")
# 设置按钮进行提交,然后响应的函数
def confirm(self):
messagebox.showinfo("选择结果","选择的性别是 : "+self.v.get())
# 两个参数,一个是标题另一个是内容
# 显示内容
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("300x100+400+300")
# 创建大小
root.title("Button 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
Checkbutton基本写法
'''
1.Checkbutton(self 窗口对象,text 按钮显示内容,variable 绑定变量->一起变化,
onvalue 用户点击时得到的值,offvalue 没有点击得到的值)
self.choose1 = Checkbutton(self,text = "玩游戏",variable = self.playHobby,
onvalue = 1,offvalue = 0)
2.self.playHobby.get() == 1 :
.get() 获取到值 判断是否时 onvalue 的值
'''
from tkinter import *
from tkinter import messagebox
class Application(Frame):
'''GUI程序经典写法'''
def __init__(self,master = None):
super().__init__(master)
# super() 表示父类的定义,父类使用 master 参数
self.master = master
# 子类定义一个属性接收传递过来的 master 参数
self.pack()
# .pack 设置布局管理器
self.createWidget()
# 在初始化时,将按钮也实现
# master传递给父类 Frame 使用后,子类中再定义一个 master 对象
def createWidget(self):
'''创建组件'''
self.playHobby = IntVar()
# 默认为 0
# .get() 获取值 .set() 设置值
self.travelHobby = IntVar()
self.watchTvHobby = IntVar()
# print(self.playHobby.get()) 0
self.choose1 = Checkbutton(self,text = "玩游戏",variable = self.playHobby,
onvalue = 1,offvalue = 0)
# Checkbutton(self 窗口对象,text 按钮显示内容,variable 绑定变量->一起变化,
# onvalue 用户点击时得到的值,offvalue 没有点击得到的值)
self.choose2 = Checkbutton(self,text = "去旅游",variable = self.travelHobby,
onvalue = 1,offvalue = 0)
self.choose3 = Checkbutton(self,text = "看电影",variable = self.watchTvHobby,
onvalue = 1,offvalue = 0)
self.choose1.pack(side = "left")
self.choose2.pack(side = "left")
self.choose3.pack(side = "left")
Button(self,text = "确定",command = self.confirm).pack(side = "left")
def confirm(self):
if self.playHobby.get() == 1 :
# 获取到的数据是 1 的话,进行接下来的操作
messagebox.showinfo("假期项目","玩游戏----")
if self.travelHobby.get() == 1 :
messagebox.showinfo("假期项目","去旅游----")
if self.watchTvHobby.get() == 1 :
messagebox.showinfo("假期项目","看电影----")
if __name__ == '__main__':
root = Tk()
# 定义主窗口对象
root.geometry("300x200+400+300")
# 创建大小
root.title("Button 测试")
# 设置标题
app = Application(master = root)
# 传递 master 参数为 主窗口对象
root.mainloop()
# 一行代码合并字典
# {**{'键':'值','键':'值'},**{'键','值'}}
dic = {**{'a':1,'b':2},**{'c':3},**{'d':4}}
print(dic)
# {'a': 1, 'b': 2, 'c': 3, 'd': 4}
# 一行代码查看多个列表最大值
print(max([[1,2,3],[4,5,7,8],[6]],key = lambda v:max(v)))
# [4, 5, 7, 8]
print(max(max([[1,2,3],[4,5,7,8],[6]],key = lambda v:max(v))))
# 8
整理上课内容
加载数据集
sklearn.datasets 集成了部分数据分析的经典数据集·
load_boston 回归
load_breast_cancer 分类 聚类
fetch_california_housing 回归
load_iris 分类 聚类
load_digits 分类
load_wine 分类
from sklearn.datasets import load_breast_cancer
cancer=load_ breast_cancer()
print('breast_cancer数据集的长度为:',len(cancer))
print('breast_cancer数据集的类型为:',type(cancer))
数据集可以看作字典
可以使用 data target feature_names DESCR
分别获取数据集的数据 标签 特征名称 描述信息
cancer['data'] cancer['target']
cancer['feature_names'] cancer['DESCR']
将样本分为三部分
训练集(train set)用于估计模型
验证集(validation set) 用于确定 网络结构 或 控制模型复杂程度 的参数
测试集(test set) 检验最优的模型的性能
占比
50% 25% %25
通过一些数据建立一些模型 通过模型可以将新数据分组
K折交叉验证法
常用的方法是留少部分做测试集
对其余 N 个样本采用 K 折交叉验证法
将样本打乱 均匀分成K份。
轮流选择其中 K-1 份做训练 剩余的一份做验证。
计算预测误差平方和 把K次的预测误差平方和的均值作为选择最优模型结构的依据
对数据集进行拆分
sklearn.model_selection 的 train_test_split 函数
参数
*arrays 接收一个或多个需要划分的数据集
分类->数据和标签
聚类->数据
test_size 接收 float int None 数据
表示测试集的大小
float 类型 0-1 之间 表示测试集在总数中的占比
int 类型 表示测试集的绝对数目
test_size 默认为 25%
train_size 接收 float int None 类型的数据
表示训练集的大小 和 test_size 只能有一个
random_state 接收 int 类型 表示随机种子的编号
相同随机种子编号产生相同的随机结果
不同的随机种子编号产生不同的随机结果
shuffle 接收布尔类型 代表是否进行有放回抽样’
stratify 接收 array标签 或者 None
使用标签进行分层抽样
train_test_split 函数根据传入的数据
分别将传入的数据划分为训练集和测试集
如果传入的是1组数据,那么生成的就是这一组数据随机划分后训练集和测试集
如果传入的是2组数据,则生成的训练集和测试集分别2组
将breast_cancer数据划分为训练集和测试集
from sklearn.model_selection import train_test_split
cancer_data_train,cancer_data_test,cancer_target_train,cancer_target_test
= train_test_split(cancer_data,cancer_target,test_size=0.2,random_state=42)
.shape 查看形状
numpy.max() 查看最大值
使用 sklearn 转换器
fit 分析特征和目标值,提取有价值的信息 如 统计量 或 权值系数等。
transform 对特征进行转换
无信息转换 指数和对数函数转换等
有信息转换
无监督转换
只利用特征的统计信息 如 标准化 和 PCA 降维
有监督转换
利用 特征信息 和 目标值信息 如通过模型->选择特征 LDA降维等
fit_tranform 先调用 fit 方法 然后调用 transform 方法
使用 sklearn 转换器 能够实现对传入的 Numpy数组
进行标准化处理、归一化处理、二值化处理、PCA降维等操作
注 各类特征处理相关的操作都要将 训练集和测试集 分开
将训练集的操作规则、权重系数等应用到测试集中
.shape 查看形状
sklearn 提供的方法
MinMaxScaler 对特征进行离差标准化
StandardScaler 对特征进行标准差标准化
Normalizer 对特征进行归一化
Binarizer 对定量特征进行二值化处理
OneHotEncoder 对定性特征进行独热编码处理
Function Transformer 对特征进行自定义函数变换
from sklearn.decomposition import PCA
PCA 降维算法常用参数及作用
n_components 接收 None int float string 参数
未指定时,代表所有特征都会保留下来
int -> 降低到 n 个维度
float 同时 svd_solver 为full
string 如 n_components='mle'
自动选取特征个数为 n 满足所要求的方差百分比 默认为 None
copy 接收 布尔类型数据
True 运行后 原始数据不会发生变化
False 运行 PCA 算法后,原始数据 会发生变化
默认为 True
whiten 接收 布尔类型数据
表示白化 对降维后的数据的每个特征进行归一化
默认为 False
svd_solver 接收 'auto' 'full' 'arpack' 'randomized'
默认为auto
auto 代表PCA类会自动在上述三种算法中去权衡 选择一个合适的SVD算法来降维
full 使用SciPy库实现的传统SVD算法
arpack 和randomized的适用场景类似
区别是 randomized 使用的是 sklearn 的SVD实现
而arpack直接使用了 SciPy 库的 sparse SVD实现
randomized 一般适用于数据量大 数据维度多 同时主成分数目比例又较低的PCA降维 使用一些加快SVD的随机算法
聚类分析 在没有给定 划分类别 的情况下,根据 数据相似度 进行样本分组的一种方法
聚类模型 可以将 无类标记的数据 聚集为多个簇 视为一类 是一种 非监督的学习算法
聚类的输入是 一组未被标记的样本
根据 自身的距离 或 相似度 将他们划分为若干组
原则 组内样本最小化 组间距离最大化
常用的聚类算法
划分方法
K-Means算法(K-平均)
K-MEDOIDS算法(K-中心点)
CLARANS算法(基于选择的算法)
层次分析方法
BIRCH算法(平衡送代规约和聚类)
CURE算法(代表点聚类)
CHAMELEON算法(动态模型)
基于密度的方法
DBSCAN算法(基于高密度连接区域)
DENCLUE算法(密度分布函数)
OPTICS算法(对象排序识别)
基于网格的方法
STING算法(统计信息网络)
CLIOUE算法(聚类高维空间)
WAVE-CLUSTER算法(小波变换)
sklearn.cluster 提供的聚类算法
函数名称 K-Means
参数 簇数
适用范围 样本数目很大 聚类数目中等
距离度量 点之间的距离
函数名称 Spectral clustering
参数 簇数
适用范围 样本数目中等 聚类数目较小
距离度量 图距离
函数名称 Ward hierarchical clustering
参数 簇数
适用范围 样本数目较大 聚类数目较大
距离度量 点之间的距离
函数名称 Agglomerative clustering
参数 簇数 链接类型 距离
适用范围 样本数目较大 聚类数目较大
距离度量 任意成对点线图间的距离
函数名称 DBSCAN
参数 半径大小 最低成员数目
适用范围 样本数目很大 聚类数目中等
距离度量 最近的点之间的距离
函数名称 Birch
参数 分支因子 阈值 可选全局集群
适用范围 样本数目很大 聚类数目较大
距离度量 点之间的欧式距离
聚类算法实现需要sklearn估计器 fit 和 predict
fit 训练算法 接收训练集和标签
可用于有监督和无监督学习
predict 预测有监督学习的测试集标签
可用于划分传入数据的类别
将规则通过 fit 训练好后 将规则进行 预测 predict
如果存在数据 还可以检验规则训练的好坏
引入离差标准化
from sklearn.preprocessing import MinMaxScaler
from sklearn.datasets import load_iris
from sklearn.cluster import K-Means
iris = load_iris()
数据集的特征
iris_data = iris['data']
数据集的标签
iris_target = iris['target']
数据集的特征名
iris_names = iris['feature_names']
训练规则
scale = MinMaxScaler().fit(iris_data)
应用规则
iris_dataScale = scale.transform(iris_data)
构建并训练模型
kmeans = KMeans(n_components = 3,random_state = 123).fit(iris_dataScale)
n_components = 3 分为三类
预测模型
result = kmeans.predict([[1.5,1.5,1.5,1.5]])
查看预测类别
result[0]
使用 sklearn.manifold 模块的 TSNE 函数
实现多维数据的可视化展现
原理 使用 TSNE 进行数据降维
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
使用 TSNE 进行数据降维 降为两维
tsne = TSNE(n_components = 2,init = 'random',random_state = 177).fit(iris_data)
n_components = 2 降为两维
将原始数据转换为 DataFrame 对象
df = pd.DataFrame(tsne.embedding_)
转换为二维表格式
将聚类结果存到 df 数据表中
df['labels'] = kmeans.labels_
提取不同标签的数据
df1 = df[df['labels'] == 0]
df2 = df[df['labels'] == 1]
df3 = df[df['labels'] == 2]
绘制图形
fig = plt.figure(figsize = (9,6))
使用不同的颜色表示不同的数据
plt.plot(df1[0],df1[1],'bo',df2[0],df2[1],'r*')
储存为 .png 图片
plt.savefig('../tmp/名称.png')
plt.show()
聚类模型评价指标
标准
组内的对象相互之间是相似的(相关的)
不同组中的对象是不同的(不相关的)
sklearn.metrics 提供评价指标
ARI评价法(兰德系数) adjusted _rand_score
AMI评价法(互信息) adjusted_mutual_info_score
V-measure评分 completeness_score
FMI评价法 fowlkes_mallows_score
轮廓系数评价法 silhouette _score
Calinski-Harabasz指数评价法 calinski_harabaz_score
前四种更有说服力 评分越高越好
聚类方法的评价可以等同于分类算法的评价
FMI评价法 fowlkes_mallows_score
from sklearn.metrics import fowlkes_mallows_score
for i in range(2,7):
kmeans =KMeans(n_clusters =i,random_state=123).fit(iris_data)
score = fowlkes_mallows_score(iris_target,kmeans.labels_)
print('iris数据聚 %d 类FMI评价分值为:%f'%(i,score))
轮廓系数评价法 silhouette_score
from sklearn.metrics import silhouette_score
import matplotlib.pyplot as plt
silhouettteScore=[]
for i in range(2,15):
kmeans=KMeans(n_clusters =i,random state=123).fit(iris data)
score = silhouette_score(iris_data,kmeans.labels_)
silhouettteScore.append(score)
plt.figure(figsize=(10,6))
plt.plot(range(2,15),silhouettteScore,linewidth=1.5,linestyle="-")
plt.show()
使用 Calinski-Harabasz 指数评价 K-Means 聚类模型
分值越高聚类效果越好
from sklearn.metrics import calinski_harabaz_score
for i in range(2,7):
kmeans=KMeans(n_clusters =i,random_state=123).fit(iris_data)
进行评价
score=calinski_harabaz_score(iris_data,kmeans.labels_)
print('iris数据聚%d类calinski harabaz指数为:%f'%(i,score)
构建并评价分类模型(有监督学习)
输入样本的特征值 输出对应的类别
将每个样本映射到预先定义好的类别
分类模型建立在已有模型的数据集上
用于 图像检测 物品分类
分类算法
模块名 函数名称 算法名称
linear_model LogisticRegression 逻辑斯蒂回归
svm SVC 支持向量机
neighbors KNeighborsClassifier K最近邻分类
naive_bayes GaussianNB 高斯朴素贝叶斯
tree DecisionTreeClassifier 分类决策树
ensemble RandomForestClassifier 随机森林分类
ensemble GradientBoostingClassifier 梯度提升分类树
以 breast_cancer 数据为例 使用sklearn估计器构建支持向量机(SVM)模型
import numpy as np
from sklearn.datasets import load_breast.cancer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
cancer = load_breast_cancer()
cancer_data = cancerf['data']
Cancer_target = cancert['target']
cancer_names = cancer['feature_names']
建立 SVM 模型
svm = SVC().fit(cancer_trainStd,cancer_target_train)
预测训练集结果
cancer_target_pred = svm.predict(cancer_testStd)
将预测结果和真实结果比对 求出预测对的结果和预测错的结果
true = np.sum(cancer_target_pred == cancer_target_test)
预测对的结果的数目
true
预测错的结果的数目
cancer_target_test.shape[0] - true
准确率
true/cancer_target_test.shape[0]
评价分类模型
分类模型对测试集进行预测得到的准确率并不能很好的反映模型的性能
结合真实值->计算准确率、召回率 F1 值和 Cohen's Kappa 系数等指标
方法名称 最佳值 sklearn 函数
Precision(精确率) 1.0 metrics.precision_score
Recall(召回率) 1.0 metrics.recall_score
F1值 1.0 metrics.f1_score
Cohen's Kappa 系数 1.0 metrics.cohen_kappa_score
ROC曲线 最靠近y轴 metrics.roc_curve
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
使用SVM预测breast_cancer数据的准确率为
accuracy_score(cancer_target_test,cancer_target_pred)
使用SVM预测breast_cancer数据的精确率为
precision_score(cancer_target_test,cancer_target_pred)
绘制ROC曲线
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
求出ROC曲线的x轴和y轴
fpr,tpr,thresholds = roc_curve(cancer_target_test,cancer_target_pred)
plIt.figure(figsize=(10,6))
plt.xlim(O,1)##设定x轴的范围
plt.ylim(0.0,1.1)##设定y轴的范围
plt.xlabel('False Postive Rate')
plt.ylabel('True Postive Rate')
plt.plot(fpr,tpr,linewidth=2,linestyle=*-".color='red")
plt.show()
ROC曲线 与 x 轴面积越大 模型性能越好
构建并评价回归模型
分类和回归的区别
分类算法的标签是离散的
回归算法的标签是连续的
作用 交通 物流 社交网络和金融领域等
回归模型
自变量已知
因变量未知 需要预测
回归算法实现步骤 分为 学习 和 预测 两个步骤
学习 通过训练样本数据来拟合回归方程
预测 利用学习过程中拟合出的回归方程 将测试数据放入方程中求出预测值
回归算法
模块名称 函数名称 算法名称
linear_model LinearRegression 线性回归
svm SVR 支持向量回归
neighbors KNeighborsRegressor 最近邻回归
tree DecisionTreeRegressor 回归决策树
ensemble RandomForestRegressor 随机森林回归
ensemble GradientBoostingRegressor 梯度提升回归树
以boston数据集为例 使用skllearn估计器构建线性回归模型
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
boston = load_boston()
X = boston['data']
y = boston['target']
names = boston['feature_names']
划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,Y.test_size=0.2,random_state=125)
建立线性回归模型
clf = LinearRegression().fit(X_train.y_train)
预测训练集结果
y_pred = clf.predict(X_test)
前二十个结果
y_pred[:20]
使用不同的颜色表示不同的数据
plt.plot(range(y_test.shape[0]),y_test,color='blue',linewidth=1.5,linestyle='-')
评价回归模型
方法名称 最优值 sklearn函数
平均绝对误差 0.0 metrics.mean_absolute_error
均方误差 0.0 metrics.mean_squared_error
中值绝对误差 0.0 metrics.median_absolute_error
可解释方差值 1.0 metrics.explained_variance_score
R方值 1.0 metrics.r2_score
平均绝对误差 均方误差和中值绝对误差的值越靠近 0
模型性能越好
可解释方差值 和 R方值 则越靠近1 模型性能越好
from sklearn.metrics import explained_variance_score,mean_absolute_error,mean_squared_error,median_absolute_error,r2_score
Boston数据线性回归模型的平均绝对误差为
mean_absolute_error(y_test,y_pred)
Boston数据线性回归模型的均方误差为
mean_squared_error(y_test,y _pred)
Boston数据线性回归模型的中值绝对误差为
median_absolute_error(y_test,y_pred)
Boston数据线性回归模型的可解释方差值为
explained_variance_score(y_test,y_pred)
Boston数据线性回归模型的R方值为
r2_score(y test,y_pred)
注:此篇随笔进行读取内容时,所读取的文件可以修改为自己的文件.
Seaborn基础1
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# # 折线图
def sinplot(flip = 1):
x = np.linspace(0,14,100)
for i in range(1,7):
plt.plot(x,np.sin(x+i*0.5) * (7-i) * flip)
sns.set()
# # 默认组合
sinplot()
plt.show()
# # 不带灰色格子
sns.set_style("white")
sinplot()
plt.show()
# 坐标加上竖线
sns.set_style("ticks")
sinplot()
plt.show()
# 将右上角的两条线去掉
sinplot()
sns.despine()
plt.show()
# # 盒图
sns.set_style("whitegrid")
data = np.random.normal(size=(20,6)) + np.arange(6)/2
sns.boxplot(data = data)
plt.show()
Seaborn基础2
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
def sinplot(flip = 1):
x = np.linspace(0,14,100)
for i in range(1,7):
plt.plot(x,np.sin(x+i*0.5) * (7-i) * flip)
data = np.random.normal(size=(20,6)) + np.arange(6)/2
# 使用 despine 进行操作
sns.violinplot(data)
sns.despine(offset = 10)
# offset 设置距离轴的距离
plt.show()
# 底部变为白色
sns.set_style("whitegrid")
# 让左面的竖线消失
sns.boxplot(data = data,palette = "deep")
sns.despine(left = True)
plt.show()
# 五种主题风格 darkgrid whitegrid dark white ticks
# 绘制子图
with sns.axes_style("darkgrid"):
# 第一种风格背景为黑色
plt.subplot(211)
# 分两个一列上面
sinplot()
plt.subplot(212)
sinplot(-1)
plt.show()
# 设置布局,画图的大小和风格
sns.set_context("paper")
# sns.set_context("talk")
# sns.set_context("poster")
# sns.set_context("notebook")
# 线条粗细依次变大
plt.figure(figsize=(8,6))
sinplot()
plt.show()
# 设置坐标字体大小 参数 font_scale
sns.set_context("paper",font_scale=3)
plt.figure(figsize=(8,6))
sinplot()
plt.show()
# 设置线的粗度 rc = {"lines.linewidth":4.5}
sns.set_context("paper",font_scale=1.5,rc={"lines.linewidth":3})
plt.figure(figsize=(8,6))
sinplot()
plt.show()
Seaborn基础3
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
sns.set(rc = {"figure.figsize":(6,6)})
# 调色板
# color_palette() 默认颜色 , 可以传入所有支持颜色
# set_palette() 设置所有图的颜色
# 分类色板,显示十种颜色
current_palette = sns.color_palette()
sns.palplot(current_palette)
plt.show()
current_palette = sns.color_palette("hls",8)
# 设置八种颜色
sns.palplot(current_palette)
plt.show()
# 将八种颜色应用在盒图中
current_palette = sns.color_palette("hls",8)
data = np.random.normal(size = (20,8)) + np.arange(8)/2
sns.boxplot(data = data,palette = current_palette)
plt.show()
# 指定亮度和饱和度
# hls_palette()
# l 亮度 s 饱和度
# 使用饱和度方法
sns.palplot(sns.hls_palette(8,l = 1,s = 5))
# 将两个相邻的颜色相近 使用 Paired 参数
sns.palplot(sns.color_palette("Paired",10))
plt.show()
# 连续型渐变色画板 color_palette("颜色名")
sns.palplot(sns.color_palette("Blues"))
# 从浅到深
plt.show()
# 从深到浅 加上 _r 后缀名
sns.palplot(sns.color_palette("BuGn_r"))
plt.show()
# cubehelix_palette() 调色板
# 八种颜色分别渐变
sns.palplot(sns.color_palette("cubehelix",8))
plt.show()
# 指定 start 值,在区间中颜色的显示也不同
sns.palplot(sns.cubehelix_palette(8,start=5,rot=-0.75))
plt.show()
# 颜色从浅到深 light_palette
sns.palplot(sns.light_palette("green"))
plt.show()
# 颜色从深到浅 dark_palette
sns.palplot(sns.dark_palette("green"))
plt.show()
# 实现反转颜色 在 light_palette 中添加参数 reverse
sns.palplot(sns.light_palette("green",reverse = True))
plt.show()
Seaborn实现单变量分析
import numpy as np
import pandas as pd
from scipy import stats,integrate
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制直方图
sns.set(color_codes=True)
np.random.seed(sum(map(ord,"distributions")))
# 生成高斯数据
x = np.random.normal(size = 100)
#
# sns.distplot(x,kde = False)
# x 数据 kde 是否做密度估计
# 将数据划分为 15 份 bins = 15
sns.distplot(x,kde = False,bins = 15)
plt.show()
# 查看数据分布状况,根据某一个指标画一条线
x = np.random.gamma(6,size = 200)
sns.distplot(x,kde = False,fit = stats.gamma)
plt.show()
mean,cov = [0,1],[(1,5),(0.5,1)]
data = np.random.multivariate_normal(mean,cov,200)
df = pd.DataFrame(data,columns=["x","y"])
# 单变量使用直方图,关系使用散点图
# 关系 joinplot (x,y,data)
sns.jointplot(x = "x",y = "y",data = df)
# 绘制散点图和直方图
plt.show()
# hex 图,数据越多 色越深
mean,cov = [0,1],[(1,8),(0.5,1)]
x,y = np.random.multivariate_normal(mean,cov,500).T
# 注意 .T 进行倒置
with sns.axes_style("white"):
sns.jointplot(x = x,y = y,kind = "hex",color = "k")
plt.show()
Seaborn实现回归分析
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
iris = pd.read_csv("iris.csv")
# 对角线上是单个数据的情况,旁边的图都是关系分布的情况
sns.pairplot(iris)
plt.show()
tips = pd.read_csv("tips.csv")
print(tips.head())
# 画图方式 regplot() 和 lmplot
sns.regplot(x = "total_bill",y = "tip",data = tips)
# x y 都是原数据的列名
plt.show()
# lmplot 画图方式,支持更高级的功能,但是规范多
sns.lmplot(x = "total_bill",y = "tip",data = tips)
plt.show()
sns.lmplot(x = "size",y = "tip",data = tips)
plt.show()
# 加上抖动,使回归更准确
sns.regplot(x = "size",y = "tip",data = tips,x_jitter=0.08)
# x_jitter=0.05 在原始数据集中加上小范围浮动
plt.show()
Seaborn实现多变量分析
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
sns.set(style = "whitegrid",color_codes = True)
np.random.seed(sum(map(ord,"categorical")))
titanic = pd.read_csv("titanic.csv")
tips = pd.read_csv("tips.csv")
iris = pd.read_csv("iris.csv")
# 显示多个点
sns.stripplot(x = "day",y = "total_bill",data = tips)
plt.show()
sns.swarmplot(x = "day",y = "total_bill",data = tips,hue = "sex")
# hue="sex" 生成两个颜色的小圆圈 混合进行查看,进行优化
plt.show()
# 四分位距 IQR 四分之一到四分之三位 之间的距离
# N = 1.5 * IQR
# 离群点 > Q3 + N , < Q1 - N
sns.boxplot(x = "day",y = "total_bill",data = tips)
# hue = "time" 列名
plt.show()
# 小提琴图
sns.violinplot(x = "total_bill",y = "day",hue = "time",data = tips)
plt.show()
# 加入 split 竖着展示
sns.violinplot(x = "day",y = "total_bill",hue = "sex",data = tips,split = True)
plt.show()
由于图片太多,请复制代码后运行查看.文件名修改为自己的文件夹的名字.
将形如 5D, 30s 的字符串转为秒
import sys
def convert_to_seconds(time_str):
# write code here
if 's' in time_str:
return float(time_str[:-1])
elif 'm' in time_str:
return float(time_str[:-1]) * 60
elif 'h' in time_str:
return float(time_str[:-1]) * 3600
elif 'd' in time_str:
return float(time_str[:-1]) * 3600 *24
elif 'D' in time_str:
return float(time_str[:-1]) * 3600 *24
while True:
line = sys.stdin.readline()
line = line.strip()
if line == '':
break
print(convert_to_seconds(line))
获得昨天和明天的日期
import datetime
import sys
def next_day(date_str):
date = datetime.datetime.strptime(date_str, '%Y-%m-%d')
return (date + datetime.timedelta(days=1)).date()
def prev_day(date_str):
date = datetime.datetime.strptime(date_str,'%Y-%m-%d')
return (date - datetime.timedelta(days = 1)).date()
while True:
line = sys.stdin.readline()
line = line.strip()
if line == '':
break
print('前一天:', prev_day(line))
print('后一天:', next_day(line))
计算两个日期相隔的秒数
import datetime
def date_delta(start, end):
# 转换为标准时间
start = datetime.datetime.strptime(start,"%Y-%m-%d %H:%M:%S")
end = datetime.datetime.strptime(end,"%Y-%m-%d %H:%M:%S")
# 获取时间戳
timeStamp_start = start.timestamp()
timeStamp_end = end.timestamp()
return timeStamp_end - timeStamp_start
start = input() # sys.stdin.readline()
end = input() # sys.stdin.readline()
print(date_delta(start, end))
遍历多个 txt 文件进行获取值
import random
def load_config(path):
with open(path,'r') as tou:
return [line for line in tou.readlines()]
headers = {
'User-Agent':load_config('useragents.txt')[random.randint(0,len(load_config('useragents.txt'))-1)].strip("\n"),
'Referer':load_config('referers.txt')[random.randint(0,len(load_config('referers.txt'))-1)].strip("\n"),
'Accept':load_config('acceptall.txt')[random.randint(0,len(load_config('acceptall.txt'))-1)].strip("\n"),
}
print(headers)
安装第三方库
pip install 包名 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
安装第三方库进阶
# 安装 pip 包
from tkinter import *
def getBao():
pip = 'pip install %s -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com'%entry_bao.get()
print(pip)
root = Tk()
root.title("pip包")
root.geometry("250x150+400+300")
url = StringVar()
url_lab1 = Label(text = "请输入包名:")
url_lab1.pack()
entry_bao = Entry(root,textvariable = url)
entry_bao.pack()
btn1 = Button(root,text = "提交",command = getBao,width = 8,height = 2)
btn1.pack()
root.mainloop()
Python第一次实验
'''
计算
1.输入半径,输出面积和周长
2.输入面积,输出半径及周长
3.输入周长,输出半径及面积
'''
# 1.输入半径,输出面积和周长
from math import pi
# 定义半径
r = int(input("请输入半径的值(整数)"))
if r < 0 :
exit("请重新输入半径")
''' S 面积: pi * r * r '''
S = pi * pow(r,2)
print(" 半径为 %d 的圆,面积为 %.2f"%(r,S))
'''C 周长: C = 2 * pi * r '''
C = 2 * pi * r
print(" 半径为 %d 的圆,周长为 %.2f"%(r,C))
# 2.输入面积,输出半径及周长
from math import pi,sqrt
S = float(input("请输入圆的面积(支持小数格式)"))
if S < 0 :
exit("请重新输入面积")
'''r 半径: r = sqrt(S/pi)'''
r = sqrt(S/pi)
print("面积为 %.2f 的圆,半径为 %.2f"%(S,r))
'''C 周长: C = 2 * pi * r '''
C = 2 * pi * r
print("面积为 %.2f 的圆,周长为 %.2f"%(S,C))
# 3.输入周长,输出半径及面积
from math import pi
C = float(input("请输入圆的周长(支持小数格式)"))
if C < 0 :
exit("请重新输入周长")
'''r 半径: r = C/(2*pi)'''
r = C/(2*pi)
print("周长为 %.2f 的圆,半径为 %.2f"%(C,r))
''' S 面积: pi * r * r '''
S = pi * pow(r,2)
print("周长为 %.2f 的圆,面积为 %.2f"%(C,S))
'''
数据结构
列表练习
1.创建列表对象 [110,'dog','cat',120,'apple']
2.在字符串 'dog' 和 'cat' 之间插入空列表
3.删除 'apple' 这个字符串
4.查找出 110、120 两个数值,并以 10 为乘数做自乘运算
'''
# 1.创建列表对象 [110,'dog','cat',120,'apple']
'''创建一个名为 lst 的列表对象'''
lst = [110,'dog','cat',120,'apple']
print(lst)
# 2.在字符串 'dog' 和 'cat' 之间插入空列表
lst = [110,'dog','cat',120,'apple']
'''添加元素到 'dog' 和 'cat' 之间'''
lst.insert(2,[])
print(lst)
# 3.删除 'apple' 这个字符串
lst = [110,'dog','cat',120,'apple']
'''删除最后一个元素'''
lst.pop()
print(lst)
# 4.查找出 110、120 两个数值,并以 10 为乘数做自乘运算
lst = [110,'dog','cat',120,'apple']
try:
# 如果找不到数据,进行异常处理
lst[lst.index(110)] *= 10
lst[lst.index(120)] *= 10
except Exception as e:
print(e)
print(lst)
'''
字典练习
1.创建字典 {'Math':96,'English':86,'Chinese':95.5,'Biology':86,'Physics':None}
2.在字典中添加键值对 {'Histore':88}
3.删除 {'Physisc':None} 键值对
4.将键 'Chinese' 所对应的值进行四舍五入后取整
5.查询键 'Math' 的对应值
'''
# 1.创建字典 {'Math':96,'English':86,'Chinese':95.5,'Biology':86,'Physics':None}
stu_score = {'Math':96,'English':86,'Chinese':95.5,'Biology':86,'Physics':None}
# 2.在字典中添加键值对 {'Histore':88}
stu_score['Histore'] = 88
# 3.删除 {'Physisc':None} 键值对
if 'Physisc' in stu_score.keys():
'''如果存在 "Physisc" '''
del stu_score['Physisc']
# 4.将键 'Chinese' 所对应的值进行四舍五入后取整
if 'Chinese' in stu_score.keys():
# 四舍五入 使用 round
stu_score['Chinese'] = round(stu_score['Chinese'])
# 5.查询键 'Math' 的对应值
print(stu_score.get('Math',"没有找到 Math 的值"))
'''
元组练习
1.创建列表 ['pen','paper',10,False,2.5] 赋给变量并查看变量的类型
2.将变量转换为 tuple 类型,查看变量的类型
3.查询元组中的元素 False 的位置
4.根据获得的位置提取元素
'''
# 1.创建列表 ['pen','paper',10,False,2.5] 赋给变量并查看变量的类型
lst = ['pen','paper',10,False,2.5]
'''查看变量类型'''
print("变量的类型",type(lst))
# 2.将变量转换为 tuple 类型,查看变量的类型
lst = tuple(lst)
print("变量的类型",type(lst))
# 3.查询元组中的元素 False 的位置
if False in lst:
print("False 的位置为(从0开始): ",lst.index(False))
# 4.根据获得的位置提取元素
print("根据获得的位置提取的元素为: ",lst[lst.index(False)])
else:
print("不在元组中")
'''
集合练习
1.创建列表 ['apple','pear','watermelon','peach'] 并赋给变量
2.用 list() 创建列表 ['pear','banana','orange','peach','grape'],并赋给变量
3.将创建的两个列表对象转换为集合类型
4.求两个集合的并集,交集和差集
'''
# 1.创建列表 ['apple','pear','watermelon','peach'] 并赋给变量
lst = ['apple','pear','watermelon','peach']
# 2.用 list() 创建列表 ['pear','banana','orange','peach','grape'],并赋给变量
lst_2 = list({'pear','banana','orange','peach','grape'})
print(lst_2)
# 3.将创建的两个列表对象转换为集合类型
lst_set = set(lst)
lst2_set = set(lst_2)
# 4.求两个集合的并集,交集和差集
''' 并集 | 交集 & 差集 - '''
print("两个集合的 并集为 :",lst_set | lst2_set)
print("两个集合的 交集为 :",lst_set & lst2_set)
print("lst_set 与 lst2_set 的差集为 :",lst_set - lst2_set)
print("lst2_set 与 lst_set 的差集为 :",lst2_set - lst_set)
pip 国内源
常用国内源
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
format 进阶
'''format(数字,str(算术式)+"d或者f")
d 表示 int
f 表示 float
'''
format(5,str(2*4)+"d")
' 5'
format(5,str(2*4)+"f")
'5.000000'
'''使用 .2f 控制小数点个数'''
format(5,str(2*4)+".2f")
' 5.00'
format(5,str(2*15)+"f")
' 5.000000'
'''format(字符串,str(算术式)+"s")'''
format('s',str(2*3)+"s")
's '
进阶删除重复元素
def dedupe(items,key=None):
seen = set()
for item in items:
val = item if key==None else key(item)
#item是否为字典,是则转化为字典key(item),匿名函数调用
if val not in seen:
yield item
seen.add(val)
#集合增加元素val
if __name__=="__main__":
a = [{'x':2,'y':4},{'x':3,'y':5},{'x':5,'y':8},{'x':2,'y':4},{'x':3,'y':5}]
b=[1,2,3,4,1,3,5]
print(b)
print(list(dedupe(b)))
print(a)
print(list(dedupe(a,key=lambda a:(a['x'],a['y']))))
#按照a['x'],a['y']方式
爬虫流程复习2
1.打开网页
urllib.request.urlopen('网址')
例:response = urllib.request.urlopen('http://www.baidu.com/')
返回值为
2.获取响应头信息
urlopen 对象.getheaders()
例:response.getheaders()
返回值为 [('Bdpagetype', '1'), ('Bdqid', '0x8fa65bba0000ba44'),···,('Transfer-Encoding', 'chunked')]
[('头','信息')]
3.获取响应头信息,带参数表示指定响应头
urlopen 对象.getheader('头信息')
例:response.getheader('Content-Type')
返回值为 'text/html;charset=utf-8'
4.查看状态码
urlopen 对象.status
例:response.status
返回值为 200 则表示成功
5.得到二进制数据,然后转换为 utf-8 格式
二进制数据
例:html = response.read()
HTML 数据格式
例:html = response.read().decode('utf-8')
打印输出时,使用 decode('字符集') 的数据 print(html.decode('utf-8'))
6.存储 HTML 数据
fp = open('文件名.html','模式 wb')
例:fp = open('baidu.html', 'wb')
fp.write(response.read() 对象)
例:fp.write(html)
7.关闭文件
open对象.close()
例:fp.close()
8.使用 ssl 进行抓取 https 的网页
例:
import ssl
content = ssl._create_unverified_context()
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
request = urllib.request.Request('http://www.baidu.com/', headers = headers)
response = urllib.request.urlopen(request, context = context)
这里的 response 就和上面一样了
9.获取码
response.getcode()
返回值为 200
10.获取爬取的网页 url
response.geturl()
返回值为 https://www.baidu.com/
11.获取响应的报头信息
response.info()
例:
import ssl
request = urllib.request.Request('http://www.baidu.com/', headers = headers)
context = ssl._create_unverified_context()
response = urllib.request.urlopen(request, context = context)
response.info()
获取的为 头信息
--
response = urllib.request.urlopen('http://www.baidu.com/')
response.info()
返回值为
12.保存网页
urllib.request.urlretrieve(url, '文件名.html')
例:urllib.request.urlretrieve(url, 'baidu.html')
13.保存图片
urllib.request.urlretrieve(url, '图片名.jpg')
例:urllib.request.urlretrieve(url, 'Dog.jpg')
其他字符(如汉字)不符合标准时,要进行编码
14.除了-._/09AZaz 都会编码
urllib.parse.quote()
例:
Param = "全文检索:*"
urllib.parse.quote(Param)
返回值为 '%E5%85%A8%E6%96%87%E6%A3%80%E7%B4%A2%3A%2A'
参考链接:https://blog.csdn.net/ZTCooper/article/details/80165038
15.会编码 / 斜线(将斜线也转换为 %.. 这种格式)
urllib.parse.quote_plus(Param)
16.将字典拼接为 query 字符串 如果有中文,进行url编码
dic_object = {
'user_name':'张三',
'user_passwd':'123456'
}
urllib.parse.urlencode(dic_object)
返回值为 'user_name=%E5%BC%A0%E4%B8%89&user_passwd=123456'
17.获取 response 的行
url = 'http://www.baidu.com'
response = urllib.request.urlopen(url)
response.readline()
18.随机获取请求头(随机包含请求头信息的列表)
user_agent = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
]
ua = random.choice(user_agent)
headers = {'User-Agent':ua}
19.对输入的汉字进行 urlencode 编码
urllib.parse.urlencode(字典对象)
例:
chinese = input('请输入要查询的中文词语:')
wd = {'wd':chinese}
wd = urllib.parse.urlencode(wd)
返回值为 'wd=%E4%BD%A0%E5%A5%BD'
20.常见分页操作
for page in range(start_page, end_page + 1):
pn = (page - 1) * 50
21.通常会进行拼接字符串形成网址
例:fullurl = url + '&pn=' + str(pn)
22.进行拼接形成要保存的文件名
例:filename = 'tieba/' + name + '贴吧_第' + str(page) + '页.html'
23.保存文件
with open(filename,'wb') as f:
f.write(reponse.read() 对象)
24.headers 头信息可以删除的有
cookie、accept-encoding、accept-languag、content-length\connection\origin\host
25.headers 头信息不可以删除的有
Accept、X-Requested-With、User-Agent、Content-Type、Referer
26.提交给网页的数据 formdata
formdata = {
'from':'en',
'to':'zh',
'query':word,
'transtype':'enter',
'simple_means_flag':'3'
}
27.将formdata进行urlencode编码,并且转化为bytes类型
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
28.使用 formdata 在 urlopen() 中
response = urllib.request.urlopen(request, data=formdata)
29.转换为正确数据(导包 json)
read -> decode -> loads -> json.dumps
通过read读取过来为字节码
data = response.read()
将字节码解码为utf8的字符串
data = data.decode('utf-8')
将json格式的字符串转化为json对象
obj = json.loads(data)
禁用ascii之后,将json对象转化为json格式字符串
html = json.dumps(obj, ensure_ascii=False)
json 对象通过 str转换后 使用 utf-8 字符集格式写入
保存和之前的方法相同
with open('json.txt', 'w', encoding='utf-8') as f:
f.write(html)
30.ajax请求自带的头部
'X-Requested-With':'XMLHttpRequest'
31.豆瓣默认都得使用https来进行抓取,所以需要使用ssl模块忽略证书
例:
url = 'http://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action='
page = int(input('请输入要获取页码:'))
start = (page - 1) * 20
limit = 20
key = {
'start':start,
'limit':limit
}
key = urllib.parse.urlencode(key)
url = url + '&' + key
headers = {
'X-Requested-With':'XMLHttpRequest',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
request = urllib.request.Request(url, headers=headers)
# context = ssl._create_unverified_context()
response = urllib.request.urlopen(request)
jsonret = response.read()
with open('douban.txt', 'w', encoding='utf-8') as f:
f.write(jsonret.decode('utf-8'))
print('over')
32.创建处理 http 请求的对象
http_handler = urllib.request.HTTPHandler()
33.处理 https 请求
https_handler = urllib.request.HTTPSHandler()
34.创建支持http请求的opener对象
opener = urllib.request.build_opener(http_handler)
35.创建 reponse 对象
例:opener.open(Request 对象)
request = urllib.request.Request('http://www.baidu.com/')
reponse = opener.open(request)
进行保存
with open('文件名.html', 'w', encoding='utf-8') as f:
f.write(reponse.read().decode('utf-8'))
36.代理服务器
http_proxy_handler = urllib.request.ProxyHandler({'https':'ip地址:端口号'})
例:http_proxy_handler = urllib.request.ProxyHandler({'https':'121.43.178.58:3128'})
37.私密代理服务器(下面的只是一个例子,不一定正确)
authproxy_handler = urllib.request.ProxyHandler({"http" : "user:password@ip:port"})
38.不使用任何代理
http_proxy_handler = urllib.request.ProxyHandler({})
39.使用了代理之后的 opener 写法
opener = urllib.request.build_opener(http_proxy_handler)
40.response 写法
response = opener.open(request)
41.如果访问一个不存在的网址会报错
urllib.error.URLError
42.HTTPError(是URLError的子类)
例:
try:
urllib.request.urlopen(url)
except urllib.error.HTTPError as e:
print(e.code)
print(e.reason)
except urllib.error.URLError as e:
print(e)
43.使用 CookieJar 创建一个 cookie 对象,保存 cookie 值
import http.cookiejar
cookie = http.cookiejar.CookieJar()
44.通过HTTPCookieProcessor构建一个处理器对象,用来处理cookie
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
opener 的写法
opener = urllib.request.build_opener(cookie_handler)
45.使用 r'\x'
\d 表示转义字符 r'\d' 表示 \d
46.设置 正则模式
pattern = re.compile(r'规则', re.xxx )
pattern = re.compile(r'i\s(.*?),')
例:pattern = re.compile(r'LOVE', re.I)
47.match 只匹配开头字符
pattern.match('字符串'[,起始位置,结束位置])
例:m = pattern.match('i love you', 2, 6)
返回值为
48. search 从开始匹配到结尾,返回第一个匹配到的
pattern.search('字符串')
例:m = pattern.search('i love you, do you love me, yes, i love')
返回值为
49.findall 将匹配到的都放到列表中
pattern.findall('字符串')
例:m = pattern.findall('i love you, do you love me, yes, i love')
返回值为 ['love', 'love', 'love']
50.split 使用匹配到的字符串对原来的数据进行切割
pattern.split('字符串',次数)
例:m = pattern.split('i love you, do you love me, yes, i love me', 1)
返回值为 ['i ', ' you, do you love me, yes, i love me']
例:m = pattern.split('i love you, do you love me, yes, i love me', 2)
返回值为 ['i ', ' you, do you ', ' me, yes, i love me']
例:m = pattern.split('i love you, do you love me, yes, i love me', 3)
返回值为 ['i ', ' you, do you ', ' me, yes, i ', ' me']
51.sub 使用新字符串替换匹配到的字符串的值,默认全部替换
pattern.sub('新字符串','要匹配字符串'[,次数])
注:返回的是字符串
例:
string = 'i love you, do you love me, yes, i love me'
m = pattern.sub('hate', string, 1)
m 值为 'i hate you, do you love me, yes, i love me'
52.group 匹配组
m.group() 返回的是匹配都的所有字符
m.group(1) 返回的是第二个规则匹配到的字符
例:
string = 'i love you, do you love me, yes, i love me'
pattern = re.compile(r'i\s(.*?),')
m = pattern.match(string)
m.group()
返回值为 'i love you,'
m.group(1)
返回值为 'love you'
53.匹配标签
pattern = re.compile(r'(.*?)) (.*?)', re.S)
54.分离出文件名和扩展名,返回二元组
os.path.splitext(参数)
例:
获取路径
image_path = './qiushi'
获取后缀名
extension = os.path.splitext(image_url)[-1]
55.合并多个字符串
os.path.join()
图片路径
image_path = os.path.join(image_path, image_name + extension)
保存文件
urllib.request.urlretrieve(image_url, image_path)
56.获取 a 标签下的 href 的内容
pattern = re.compile(r'(.*?)', re.M)
例:
import urllib.parse
import urllib.request
import re
class SmileSpider(object):
"""
爬取笑话网站笑话的排行榜
"""
def __init__(self, url, page=1):
super(SmileSpider, self).__init__()
self.url = url
self.page = page
def handle_url(self):
'''
处理url并且生成request请求对象
'''
self.url = self.url + '?mepage=' + str(self.page)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(self.url, headers=headers)
return request
def xiazai(self, request):
'''
负责下载数据,并且将数据返回
'''
response = urllib.request.urlopen(request)
html = response.read().decode('gbk')
return html
def handle_data(self, data):
'''
开始处理数据,将段子抓取出来并且写入文件
'''
# 这个必须使用多行模式进行抓取,因为是抓取多个a链接
pattern = re.compile(r'(.*?)', re.M)
# 找到所有的笑话链接
alist = pattern.findall(data)
# print(alist)
# exit()
print('开始下载')
for smile in alist:
# 获取标题
# title = alist[14][1]
title = smile[1]
# 获取url
# smile_url = alist[14][0]
smile_url = smile[0]
# 获取内容
content = self.handle_content(smile_url)
# 将抓取的这一页的笑话写到文件中
with open('xiaohua.html', 'a', encoding='gbk') as f:
f.write('
(.*?)', re.S)
54.分离出文件名和扩展名,返回二元组
os.path.splitext(参数)
例:
获取路径
image_path = './qiushi'
获取后缀名
extension = os.path.splitext(image_url)[-1]
55.合并多个字符串
os.path.join()
图片路径
image_path = os.path.join(image_path, image_name + extension)
保存文件
urllib.request.urlretrieve(image_url, image_path)
56.获取 a 标签下的 href 的内容
pattern = re.compile(r'(.*?)', re.M)
例:
import urllib.parse
import urllib.request
import re
class SmileSpider(object):
"""
爬取笑话网站笑话的排行榜
"""
def __init__(self, url, page=1):
super(SmileSpider, self).__init__()
self.url = url
self.page = page
def handle_url(self):
'''
处理url并且生成request请求对象
'''
self.url = self.url + '?mepage=' + str(self.page)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(self.url, headers=headers)
return request
def xiazai(self, request):
'''
负责下载数据,并且将数据返回
'''
response = urllib.request.urlopen(request)
html = response.read().decode('gbk')
return html
def handle_data(self, data):
'''
开始处理数据,将段子抓取出来并且写入文件
'''
# 这个必须使用多行模式进行抓取,因为是抓取多个a链接
pattern = re.compile(r'(.*?)', re.M)
# 找到所有的笑话链接
alist = pattern.findall(data)
# print(alist)
# exit()
print('开始下载')
for smile in alist:
# 获取标题
# title = alist[14][1]
title = smile[1]
# 获取url
# smile_url = alist[14][0]
smile_url = smile[0]
# 获取内容
content = self.handle_content(smile_url)
# 将抓取的这一页的笑话写到文件中
with open('xiaohua.html', 'a', encoding='gbk') as f:
f.write('' + title + '
' + content)
print('下载完毕')
def handle_content(self, smile_url):
# 因为有的href中有中文,所以必须先转码再拼接,如果先拼接再转码,就会将:也给转码了,不符合要求
smile_url = urllib.parse.quote(smile_url)
smile_url = 'http://www.jokeji.cn' + smile_url
# print(smile_url)
# exit()
content = self.xiazai(smile_url)
# 由于抓取的文本中,有的中间有空格,所以使用单行模式进行抓取
pattern = re.compile(r'(.*?)', re.S)
ret = pattern.search(content)
return ret.group(1)
def start(self):
request = self.handle_url()
html = self.xiazai(request)
self.handle_data(html)
if __name__ == '__main__':
url = 'http://www.jokeji.cn/hot.asp'
spider = SmileSpider(url)
spider.start()
57.href 中有中文的需要先进行转码,然后再拼接
smile_url = urllib.parse.quote(smile_url)
smile_url = 'http://www.jokeji.cn' + smile_url
58.导入 etree
from lxml import etree
59.实例化一个 html 对象,DOM模型
etree.HTML(通过requests库的get方法或post方法获取的信息 其实就是 HTML 代码)
例:html_tree = etree.HTML(text)
返回值为
例:type(html_tree)
60.查找所有的 li 标签
html_tree.xpath('//li')
61.获取所有li下面a中属性href为link1.html的a
result = html_tree.xpath('//标签/标签[@属性="值"]')
例:result = html_tree.xpath('//li/a[@href="link.html"]')
62.获取最后一个 li 标签下 a 标签下面的 href 值
result = html_tree.xpath('//li[last()]/a/@href')
63.获取 class 为 temp 的结点
result = html_tree.xpath('//*[@class = "temp"]')
64.获取所有 li 标签下的 class 属性
result = html_tree.xpath('//li/@class')
65.取出内容
[0].text
例:result = html_tree.xpath('//li[@class="popo"]/a')[0].text
例:result = html_tree.xpath('//li[@class="popo"]/a/text()')
66.将 tree 对象转化为字符串
etree.tostring(etree.HTML对象).decode('utf-8')
例:
text = '''
'''
html = etree.HTML(text)
tostring 转换的是bytes 类型数据
result = etree.tostring(html)
将 bytes 类型数据转换为 str 类型数据
print(result.decode('utf-8'))
67.动态保存图片,使用url后几位作为文件名
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html_tree = etree.HTML(html)
img_list = html_tree.xpath('//div[@class="box picblock col3"]/div/a/img/@src2')
for img_url in img_list:
# 定制图片名字为url后10位
file_name = 'image/' + img_url[-10:]
load_image(img_url, file_name)
load_image内容:
def load_image(url, file_name):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
image_bytes = response.read()
with open(file_name, 'wb') as f:
f.write(image_bytes)
print(file_name + '图片已经成功下载完毕')
例:
def load_page(url):
headers = {
#'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
print(url)
# exit()
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read()
# 这是专业的图片网站,使用了懒加载,但是可以通过源码来进行查看,并且重新写xpath路径
with open('7image.html', 'w', encoding='utf-8') as f:
f.write(html.decode('utf-8'))
exit()
# 将html文档解析问DOM模型
html_tree = etree.HTML(html)
# 通过xpath,找到需要的所有的图片的src属性,这里获取到的
img_list = html_tree.xpath('//div[@class="box picblock col3"]/div/a/img/@src2')
for img_url in img_list:
# 定制图片名字为url后10位
file_name = 'image/' + img_url[-10:]
load_image(img_url, file_name)
def load_image(url, file_name):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
image_bytes = response.read()
with open(file_name, 'wb') as f:
f.write(image_bytes)
print(file_name + '图片已经成功下载完毕')
def main():
start = int(input('请输入开始页面:'))
end = int(input('请输入结束页面:'))
url = 'http://sc.chinaz.com/tag_tupian/'
for page in range(start, end + 1):
if page == 1:
real_url = url + 'KaTong.html'
else:
real_url = url + 'KaTong_' + str(page) + '.html'
load_page(real_url)
print('第' + str(page) + '页下载完毕')
if __name__ == '__main__':
main()
68.懒图片加载案例
例:
import urllib.request
from lxml import etree
import json
def handle_tree(html_tree):
node_list = html_tree.xpath('//div[@class="detail-wrapper"]')
duan_list = []
for node in node_list:
# 获取所有的用户名,因为该xpath获取的是一个span列表,然后获取第一个,并且通过text属性得到其内容
user_name = node.xpath('./div[contains(@class, "header")]/a/div/span[@class="name"]')[0].text
# 只要涉及到图片,很有可能都是懒加载,所以要右键查看网页源代码,才能得到真实的链接
# 由于这个获取的结果就是属性字符串,所以只需要加上下标0即可
face = node.xpath('./div[contains(@class, "header")]//img/@data-src')[0]
# .代表当前,一个/表示一级子目录,两个//代表当前节点里面任意的位置查找
content = node.xpath('./div[@class="content-wrapper"]//p')[0].text
zan = node.xpath('./div[@class="options"]//li[@class="digg-wrapper "]/span')[0].text
item = {
'username':user_name,
'face':face,
'content':content,
'zan':zan,
}
# 将其存放到列表中
duan_list.append(item)
# 将列表写入到文件中
with open('8duanzi.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(duan_list, ensure_ascii=False) + '\n')
print('over')
def main():
# 爬取百度贴吧,不能加上headers,加上headers爬取不下来
url = 'http://neihanshequ.com/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html_bytes = response.read()
# fp = open('8tieba.html', 'w', encoding='utf-8')
# fp.write(html_bytes.decode('utf-8'))
# fp.close()
# exit()
# 将html字节串转化为html文档树
# 文档树有xpath方法,文档节点也有xpath方法
# 【注】不能使用字节串转化为文档树,这样会有乱码
html_tree = etree.HTML(html_bytes.decode('utf-8'))
handle_tree(html_tree)
if __name__ == '__main__':
main()
69. . / 和 // 在 xpath 中的使用
.代表当前目录
/ 表示一级子目录
// 代表当前节点里面任意的位置
70.获取内容的示范
获取内容时,如果为字符串,则不需要使用 text 只需要写[0]
face = node.xpath('./div[contains(@class, "header")]//img/@data-src')[0]
div 下 class 为 "content-wrapper" 的所有 p 标签内容
content = node.xpath('./div[@class="content-wrapper"]//p')[0].text
div 下 class 为 "options" 的所有 li 标签下 class为 "digg-wrapper" 的所有 span 标签内容
zan = node.xpath('./div[@class="options"]//li[@class="digg-wrapper"]/span')[0].text
71.将json对象转化为json格式字符串
f.write(json.dumps(duan_list, ensure_ascii=False) + '\n')
72.正则获取 div 下的内容
1.获取 div 到 img 之间的数据
2.img 下 src 的数据
3.img 下 alt 的数据
4.一直到 div 结束的数据
pattern = re.compile(r'(.*?)(.*?)', re.S)
pattern.方法 ,参考上面的正则
73.带有参数的 get 方式
import requests
params = {
'wd':'中国'
}
r = requests.get('http://www.baidu.com/s?', headers=headers, params=params)
requests.get 还可以添加 cookie 参数
74.设置编码
r.encoding='utf-8
75.查看所有头信息
r.request.headers
76.在 requests.get 方法中 url,params,headers,proxies 为参数
url 网址 params 需要的数据 headers 头部 proxies 代理
77.通过 Session 对象,发送请求
s = requests.Session()
78.发送请求
s.post(url,data,headers)
79.接收请求
s.get(url[,proxies])
80.当返回为 json 样式时
例:
city = input('请输入要查询的城市:')
params = {
'city':city
}
r = requests.get(url, params=params)
r.json() 会打印出响应的内容
81.BeautifulSoup 创建对象
from bs4 import BeautifulSoup
soup = BeautifulSoup(open(url,encoding='utf-8),'lxml')
82.查找第一个 标签
soup.title
返回值为 <title>三国猛将
83.查找第一个 a 标签
soup.a
返回值为 百度
84.查找第一个 ul 标签
soup.ul
85.查看标签名字
a_tag = soup.a
a_tag.name
返回值为 a
86.查看标签内容
a_tag.attrs
返回值为 {'href': 'http://www.baidu.com', 'title': 'baidu', 'class': ['aa']}
87.获取找到的 a 标签的 href 内容(第一个 a)
soup.a.get('href')
返回值为 http://www.baidu.com
88.获取 a 标签下的 title 属性(第一个 a)
soup.a.get('title')
返回值为 baidu
89.查看 a 标签下的内容
soup.标签.string 标签还可以是 head、title等
soup.a.string
返回值为 百度
90.获取 p 标签下的内容
soup.p.string
91.查看 div 的内容,包含 '\n'
soup.div.contents
返回值为
['\n', , '\n', , '\n']
92.查看使用的字符集
soup.div.contents[1]
返回值为
93.查看body的子节点
soup.标签.children
例:soup.body.children
返回值是一个迭代对象,需要遍历输出
返回值为
for child in soup.body.children:
print(child)
返回值为 body 中的所有内容
94.查看所有的子孙节点
soup.标签.descendants
例:soup.div.descendants
返回值为
你好
你好
95.查看所有的 a 标签
soup.find_all('a')
返回值为 包含所有的 a 标签的列表
96.查看 a 标签中第二个链接的内容
soup.find_all('a')[1].string
97.查看 a 标签中第二个链接的href值
soup.find_all('a')[1].href
98.将 re 正则嵌入进来,找寻所有以 b 开头的标签
soup.findall(re.compile('^b'))
返回值为 标签
99.找到所有的 a 标签和 b 标签
soup.findall(re.compile(['a','b']))
返回值为 和 标签
100.通过标签名获取所有的 a 标签
soup.select('a')
返回值为 所有的 标签
101.通过 类名 获取标签(在 class 等于的值前面加 .)
soup.select('.aa')
返回值为 class='aa' 的标签
102.通过 id 名获取标签(在 id 等于的值前面加 #)
soup.select('#wangyi')
返回值为 id='wangyi'的标签
103.查看 div 下 class='aa' 的标签
soup.select('标签 .class 等于的值')
soup.select('div .aa')
104.查看 div 下,第一层 class='aa' 的标签
soup.select('.标签名 > .class= 的值')
soup.select('.div > .la')
105.根据属性进行查找,input 标签下class为 haha 的标签
soup.select('input[class="haha"]')
例:
import requests
from bs4 import BeautifulSoup
import json
import lxml
def load_url(jl, kw):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
url = 'http://sou.zhaopin.com/jobs/searchresult.ashx?'
params = {
'jl':jl,
'kw':kw,
}
# 自动完成转码,直接使用即可
r = requests.get(url, params=params, headers=headers)
handle_data(r.text)
def handle_data(html):
# 创建soup对象
soup = BeautifulSoup(html, 'lxml')
# 查找职位名称
job_list = soup.select('#newlist_list_content_table table')
# print(job_list)
jobs = []
i = 1
for job in job_list:
# 因为第一个table只是表格的标题,所以要过滤掉
if i == 1:
i = 0
continue
item = {}
# 公司名称
job_name = job.select('.zwmc div a')[0].get_text()
# 职位月薪
company_name = job.select('.gsmc a')[0].get_text()
# 工作地点
area = job.select('.gzdd')[0].get_text()
# 发布日期
time = job.select('.gxsj span')[0].get_text()
# 将所有信息添加到字典中
item['job_name'] = job_name
item['company_name'] = company_name
item['area'] = area
item['time'] = time
jobs.append(item)
# 将列表转化为json格式字符串,然后写入到文件中
content = json.dumps(jobs, ensure_ascii=False)
with open('python.json', 'w', encoding='utf-8') as f:
f.write(content)
print('over')
def main():
# jl = input('请输入工作地址:')
# kw = input('请输入工作职位:')
load_url(jl='北京', kw='python')
if __name__ == '__main__':
main()
106.将字典进行 json 转换为
import json
str_dict = {"name":"张三", "age":55, "height":180}
print(json.dumps(str_dict, ensure_ascii=False))
使用 ensure_ascii 输出则为 utf-8 编码
107.读取转换的对象,(注意 loads 和 load 方法)
json.loads(json.dumps 对象)
string = json.dumps(str_dict, ensure_ascii=False)
json.loads(string)
{"name":"张三", "age":55, "height":180}
108.将对象序列化之后写入文件
json.dump(字典对象,open(文件名.json,'w',encoding='utf-8,ensure_ascii=False))
json.dump(str_dict, open('jsontest.json', 'w', encoding='utf-8'), ensure_ascii=False)
109.转换本地的 json 文件转换为 python 对象
json.load(open('文件名.json',encoding='utf-8))
110.jsonpath 示例:
book.json文件
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
import json
import jsonpath
obj = json.load(open('book.json', encoding='utf-8'))
所有book
book = jsonpath.jsonpath(obj, '$..book')
print(book)
所有book中的所有作者
authors = jsonpath.jsonpath(obj, '$..book..author')
print(authors)
book中的前两本书 '$..book[:2]'
book中的最后两本书 '$..book[-2:]'
book = jsonpath.jsonpath(obj, '$..book[0,1]')
print(book)
所有book中,有属性isbn的书籍
book = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]')
print(book)
所有book中,价格小于10的书籍
book = jsonpath.jsonpath(obj, '$.store.book[?(@.price<10)]')
print(book)
numpy第三方库
# 导入numpy 并赋予别名 np
import numpy as np
# 创建数组的常用的几种方式(列表,元组,range,arange,linspace(创建的是等差数组),zeros(全为 0 的数组),ones(全为 1 的数组),logspace(创建的是对数数组))
# 列表方式
np.array([1,2,3,4])
# array([1, 2, 3, 4])
# 元组方式
np.array((1,2,3,4))
# array([1, 2, 3, 4])
# range 方式
np.array(range(4)) # 不包含终止数字
# array([0, 1, 2, 3])
# 使用 arange(初始位置=0,末尾,步长=1)
# 不包含末尾元素
np.arange(1,8,2)
# array([1, 3, 5, 7])
np.arange(8)
# array([0, 1, 2, 3, 4, 5, 6, 7])
# 使用 linspace(起始数字,终止数字,包含数字的个数[,endpoint = False]) 生成等差数组
# 生成等差数组,endpoint 为 True 则包含末尾数字
np.linspace(1,3,4,endpoint=False)
# array([1. , 1.5, 2. , 2.5])
np.linspace(1,3,4,endpoint=True)
# array([1. , 1.66666667, 2.33333333, 3. ])
# 创建全为零的一维数组
np.zeros(3)
# 创建全为一的一维数组
np.ones(4)
# array([1., 1., 1., 1.])
np.linspace(1,3,4)
# array([1. , 1.66666667, 2.33333333, 3. ])
# np.logspace(起始数字,终止数字,数字个数,base = 10) 对数数组
np.logspace(1,3,4)
# 相当于 10 的 linspace(1,3,4) 次方
# array([ 10. , 46.41588834, 215.443469 , 1000. ])
np.logspace(1,3,4,base = 2)
# array([2. , 3.1748021, 5.0396842, 8. ])
# 创建二维数组(列表嵌套列表)
np.array([[1,2,3],[4,5,6]])
'''
array([[1, 2, 3],
[4, 5, 6]])
'''
# 创建全为零的二维数组
# 两行两列
np.zeros((2,2))
'''
array([[0., 0.],
[0., 0.]])
'''
# 三行三列
np.zeros((3,2))
'''
array([[0., 0.],
[0., 0.],
[0., 0.]])
'''
# 创建一个单位数组
np.identity(3)
'''
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
'''
# 创建一个对角矩阵,(参数为对角线上的数字)
np.diag((1,2,3))
'''
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
'''
import numpy as np
x = np.arange(8)
# [0 1 2 3 4 5 6 7]
# 在数组尾部追加一个元素
np.append(x,10)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 10])
# 在数组尾部追加多个元素
np.append(x,[15,16,17])
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 15, 16, 17])
# 使用 数组下标修改元素的值
x[0] = 99
# array([99, 1, 2, 3, 4, 5, 6, 7])
# 在指定位置插入数据
np.insert(x,0,54)
# array([54, 99, 1, 2, 3, 4, 5, 6, 7])
# 创建一个多维数组
x = np.array([[1,2,3],[11,22,33],[111,222,333]])
'''
array([[ 1, 2, 3],
[ 11, 22, 33],
[111, 222, 333]])
'''
# 修改第 0 行第 2 列的元素值
x[0,2] = 9
'''
array([[ 1, 2, 9],
[ 11, 22, 33],
[111, 222, 333]])
'''
# 行数大于等于 1 的,列数大于等于 1 的置为 1
x[1:,1:] = 1
'''
array([[ 1, 2, 9],
[ 11, 1, 1],
[111, 1, 1]])
'''
# 同时修改多个元素值
x[1:,1:] = [7,8]
'''
array([[ 1, 2, 9],
[ 11, 7, 8],
[111, 7, 8]])
'''
x[1:,1:] = [[7,8],[9,10]]
'''
array([[ 1, 2, 9],
[ 11, 7, 8],
[111, 9, 10]])
'''
import numpy as np
n = np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 查看数组的大小
n.size
# 10
# 将数组分为两行五列
n.shape = 2,5
'''
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
'''
# 显示数组的维度
n.shape
# (2, 5)
# 设置数组的维度,-1 表示自动计算
n.shape = 5,-1
'''
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
'''
# 将新数组设置为调用数组的两行五列并返回
x = n.reshape(2,5)
'''
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
'''
x = np.arange(5)
# 将数组设置为两行,没有数的设置为 0
x.resize((2,10))
'''
array([[0, 1, 2, 3, 4, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
'''
# 将 x 数组的两行五列形式显示,不改变 x 的值
np.resize(x,(2,5))
'''
array([[0, 1, 2, 3, 4],
[0, 0, 0, 0, 0]])
'''
import numpy as np
n = np.array(([1,2,3],[4,5,6],[7,8,9]))
'''
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
'''
# 第一行元素
n[0]
# array([1, 2, 3])
# 第一行第三列元素
n[0,2]
# 3
# 第一行和第二行的元素
n[[0,1]]
'''
array([[1, 2, 3],
[4, 5, 6]])
'''
# 第一行第三列,第三行第二列,第二行第一列
n[[0,2,1],[2,1,0]]
# array([3, 8, 4])
a = np.arange(8)
# array([0, 1, 2, 3, 4, 5, 6, 7])
# 将数组倒序
a[::-1]
# array([7, 6, 5, 4, 3, 2, 1, 0])
# 步长为 2
a[::2]
# array([0, 2, 4, 6])
# 从 0 到 4 的元素
a[:5]
# array([0, 1, 2, 3, 4])
c = np.arange(16)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
c.shape = 4,4
'''
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
'''
# 第一行,第三个元素到第五个元素(如果没有则输出到末尾截止)
c[0,2:5]
# array([2, 3])
# 第二行元素
c[1]
# array([4, 5, 6, 7])
# 第三行到第六行,第三列到第六列
c[2:5,2:5]
'''
array([[10, 11],
[14, 15]])
'''
# 第二行第三列元素和第三行第四列元素
c[[1,2],[2,3]]
# array([ 6, 11])
# 第一行和第三行的第二列到第三列的元素
c[[0,2],1:3]
'''
array([[ 1, 2],
[ 9, 10]])
'''
# 第一列和第三列的所有横行元素
c[:,[0,2]]
'''
array([[ 0, 2],
[ 4, 6],
[ 8, 10],
[12, 14]])
'''
# 第三列所有元素
c[:,2]
# array([ 2, 6, 10, 14])
# 第二行和第四行的所有元素
c[[1,3]]
'''
array([[ 4, 5, 6, 7],
[12, 13, 14, 15]])
'''
# 第一行的第二列,第四列元素,第四行的第二列,第四列元素
c[[0,3]][:,[1,3]]
'''
array([[ 1, 3],
[13, 15]])
'''
import numpy as np
x = np.array((1,2,3,4,5))
# 使用 * 进行相乘
x*2
# array([ 2, 4, 6, 8, 10])
# 使用 / 进行相除
x / 2
# array([0.5, 1. , 1.5, 2. , 2.5])
2 / x
# array([2. , 1. , 0.66666667, 0.5 , 0.4 ])
# 使用 // 进行整除
x//2
# array([0, 1, 1, 2, 2], dtype=int32)
10//x
# array([10, 5, 3, 2, 2], dtype=int32)
# 使用 ** 进行幂运算
x**3
# array([ 1, 8, 27, 64, 125], dtype=int32)
2 ** x
# array([ 2, 4, 8, 16, 32], dtype=int32)
# 使用 + 进行相加
x + 2
# array([3, 4, 5, 6, 7])
# 使用 % 进行取模
x % 3
# array([1, 2, 0, 1, 2], dtype=int32)
# 数组与数组之间的运算
# 使用 + 进行相加
np.array([1,2,3,4]) + np.array([11,22,33,44])
# array([12, 24, 36, 48])
np.array([1,2,3,4]) + np.array([3])
# array([4, 5, 6, 7])
n = np.array((1,2,3))
# +
n + n
# array([2, 4, 6])
n + np.array([4])
# array([5, 6, 7])
# *
n * n
# array([1, 4, 9])
n * np.array(([1,2,3],[4,5,6],[7,8,9]))
'''
array([[ 1, 4, 9],
[ 4, 10, 18],
[ 7, 16, 27]])
'''
# -
n - n
# array([0, 0, 0])
# /
n/n
# array([1., 1., 1.])
# **
n**n
# array([ 1, 4, 27], dtype=int32)
x = np.array((1,2,3))
y = np.array((4,5,6))
# 数组的内积运算(对应位置上元素相乘)
np.dot(x,y)
# 32
sum(x*y)
# 32
# 布尔运算
n = np.random.rand(4)
# array([0.53583849, 0.09401473, 0.07829069, 0.09363152])
# 判断数组中的元素是否大于 0.5
n > 0.5
# array([ True, False, False, False])
# 将数组中大于 0.5 的元素显示
n[n>0.5]
# array([0.53583849])
# 找到数组中 0.05 ~ 0.4 的元素总数
sum((n > 0.05)&(n < 0.4))
# 3
# 是否都大于 0.2
np.all(n > 0.2)
# False
# 是否有元素小于 0.1
np.any(n < 0.1)
# True
# 数组与数组之间的布尔运算
a = np.array([1,4,7])
# array([1, 4, 7])
b = np.array([4,3,7])
# array([4, 3, 7])
# 在 a 中是否有大于 b 的元素
a > b
# array([False, True, False])
# 在 a 中是否有等于 b 的元素
a == b
# array([False, False, True])
# 显示 a 中 a 的元素等于 b 的元素
a[a == b]
# array([7])
# 显示 a 中的偶数且小于 5 的元素
a[(a%2 == 0) & (a < 5)]
# array([4])
import numpy as np
# 将 0~100 10等分
x = np.arange(0,100,10)
# array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
# 每个数组元素对应的正弦值
np.sin(x)
'''
array([ 0. , -0.54402111, 0.91294525, -0.98803162, 0.74511316,
-0.26237485, -0.30481062, 0.77389068, -0.99388865, 0.89399666])
'''
# 每个数组元素对应的余弦值
np.cos(x)
'''
array([ 1. , -0.83907153, 0.40808206, 0.15425145, -0.66693806,
0.96496603, -0.95241298, 0.6333192 , -0.11038724, -0.44807362])
'''
# 对参数进行四舍五入
np.round(np.cos(x))
# array([ 1., -1., 0., 0., -1., 1., -1., 1., -0., -0.])
# 对参数进行上入整数 3.3->4
np.ceil(x/3)
# array([ 0., 4., 7., 10., 14., 17., 20., 24., 27., 30.])
# 分段函数
x = np.random.randint(0,10,size=(1,10))
# array([[0, 3, 6, 7, 9, 4, 9, 8, 1, 8]])
# 大于 4 的置为 0
np.where(x > 4,0,1)
# array([[1, 1, 0, 0, 0, 1, 0, 0, 1, 0]])
# 小于 4 的乘 2 ,大于 7 的乘3
np.piecewise(x,[x<4,x>7],[lambda x:x*2,lambda x:x*3])
# array([[ 0, 6, 0, 0, 27, 0, 27, 24, 2, 24]])
import numpy as np
x = np.array([1,4,5,2])
# array([1, 4, 5, 2])
# 返回排序后元素的原下标
np.argsort(x)
# array([0, 3, 1, 2], dtype=int64)
# 输出最大值的下标
x.argmax( )
# 2
# 输出最小值的下标
x.argmin( )
# 0
# 对数组进行排序
x.sort( )
import numpy as np
# 生成一个随机数组
np.random.randint(0,6,3)
# array([1, 1, 3])
# 生成一个随机数组(二维数组)
np.random.randint(0,6,(3,3))
'''
array([[4, 4, 1],
[2, 1, 0],
[5, 0, 0]])
'''
# 生成十个随机数在[0,1)之间
np.random.rand(10)
'''
array([0.9283789 , 0.43515554, 0.27117021, 0.94829333, 0.31733981,
0.42314939, 0.81838647, 0.39091899, 0.33571004, 0.90240897])
'''
# 从标准正态分布中随机抽选出3个数
np.random.standard_normal(3)
# array([0.34660435, 0.63543859, 0.1307822 ])
# 返回三页四行两列的标准正态分布数
np.random.standard_normal((3,4,2))
'''
array([[[-0.24880261, -1.17453957],
[ 0.0295264 , 1.04038047],
[-1.45201783, 0.57672288],
[ 1.10282747, -2.08699482]],
[[-0.3813943 , 0.47845782],
[ 0.97708005, 1.1760147 ],
[ 1.3414987 , -0.629902 ],
[-0.29780567, 0.60288726]],
[[ 1.43991349, -1.6757028 ],
[-1.97956809, -1.18713495],
[-1.39662811, 0.34174275],
[ 0.56457553, -0.83224426]]])
'''
# 创建矩阵
import numpy as np
x = np.matrix([[1,2,3],[4,5,6]])
'''
matrix([[1, 2, 3],
[4, 5, 6]])
'''
y = np.matrix([1,2,3,4,5,6])
# matrix([[1, 2, 3, 4, 5, 6]])
# x 的第二行第二列元素
x[1,1]
# 5
# 矩阵的函数
import numpy as np
# 矩阵的转置
x = np.matrix([[1,2,3],[4,5,6]])
'''
matrix([[1, 2, 3],
[4, 5, 6]])
'''
y = np.matrix([1,2,3,4,5,6])
# matrix([[1, 2, 3, 4, 5, 6]])
# 实现矩阵的转置
x.T
'''
matrix([[1, 4],
[2, 5],
[3, 6]])
'''
y.T
'''
matrix([[1],
[2],
[3],
[4],
[5],
[6]])
'''
# 元素平均值
x.mean()
# 3.5
# 纵向平均值
x.mean(axis = 0)
# matrix([[2.5, 3.5, 4.5]])
# 横向平均值
x.mean(axis = 1)
'''
matrix([[2.],
[5.]])
'''
# 所有元素之和
x.sum()
# 21
# 横向最大值
x.max(axis = 1)
'''
matrix([[3],
[6]])
'''
# 横向最大值的索引下标
x.argmax(axis = 1)
'''
matrix([[2],
[2]], dtype=int64)
'''
# 对角线元素
x.diagonal()
# matrix([[1, 5]])
# 非零元素下标
x.nonzero()
# (array([0, 0, 0, 1, 1, 1], dtype=int64),
# array([0, 1, 2, 0, 1, 2], dtype=int64))
# 矩阵的运算
import numpy as np
x = np.matrix([[1,2,3],[4,5,6]])
'''
matrix([[1, 2, 3],
[4, 5, 6]])
'''
y = np.matrix([[1,2],[4,5],[7,8]])
'''
matrix([[1, 2],
[4, 5],
[7, 8]])
'''
# 矩阵的乘法
x*y
'''
matrix([[30, 36],
[66, 81]])
'''
# 相关系数矩阵,可使用在列表元素数组矩阵
# 负相关
np.corrcoef([1,2,3],[8,5,4])
'''
array([[ 1. , -0.96076892],
[-0.96076892, 1. ]])
'''
# 正相关
np.corrcoef([1,2,3],[4,5,7])
'''
array([[1. , 0.98198051],
[0.98198051, 1. ]])
'''
# 矩阵的方差
np.cov([1,1,1,1,1])
# array(0.)
# 矩阵的标准差
np.std([1,1,1,1,1])
# 0.0
x = [-2.1,-1,4.3]
y = [3,1.1,0.12]
# 垂直堆叠矩阵
z = np.vstack((x,y))
'''
array([[-2.1 , -1. , 4.3 ],
[ 3. , 1.1 , 0.12]])
'''
# 矩阵的协方差
np.cov(z)
'''
array([[11.71 , -4.286 ],
[-4.286 , 2.14413333]])
'''
np.cov(x,y)
'''
array([[11.71 , -4.286 ],
[-4.286 , 2.14413333]])
'''
# 标准差
np.std(z)
# 2.2071223094538484
# 列向标准差
np.std(z,axis = 1)
# array([2.79404128, 1.19558447])
# 方差
np.cov(x)
# array(11.71)
# 特征值和特征向量
A = np.array([[1,-3,3],[3,-5,3],[6,-6,4]])
'''
array([[ 1, -3, 3],
[ 3, -5, 3],
[ 6, -6, 4]])
'''
e,v = np.linalg.eig(A)
# e 为特征值, v 为特征向量
'''
e
array([ 4.+0.00000000e+00j, -2.+1.10465796e-15j, -2.-1.10465796e-15j])
v
array([[-0.40824829+0.j , 0.24400118-0.40702229j,
0.24400118+0.40702229j],
[-0.40824829+0.j , -0.41621909-0.40702229j,
-0.41621909+0.40702229j],
[-0.81649658+0.j , -0.66022027+0.j ,
-0.66022027-0.j ]])
'''
# 矩阵与特征向量的乘积
np.dot(A,v)
'''
array([[-1.63299316+0.00000000e+00j, -0.48800237+8.14044580e-01j,
-0.48800237-8.14044580e-01j],
[-1.63299316+0.00000000e+00j, 0.83243817+8.14044580e-01j,
0.83243817-8.14044580e-01j],
[-3.26598632+0.00000000e+00j, 1.32044054-5.55111512e-16j,
1.32044054+5.55111512e-16j]])
'''
# 特征值与特征向量的乘积
e * v
'''
array([[-1.63299316+0.00000000e+00j, -0.48800237+8.14044580e-01j,
-0.48800237-8.14044580e-01j],
[-1.63299316+0.00000000e+00j, 0.83243817+8.14044580e-01j,
0.83243817-8.14044580e-01j],
[-3.26598632+0.00000000e+00j, 1.32044054-7.29317578e-16j,
1.32044054+7.29317578e-16j]])
'''
# 验证两个乘积是否相等
np.isclose(np.dot(A,v),(e * v))
'''
array([[ True, True, True],
[ True, True, True],
[ True, True, True]])
'''
# 行列式 |A - λE| 的值应为 0
np.linalg.det(A-np.eye(3,3)*e)
# 5.965152994198125e-14j
x = np.matrix([[1,2,3],[4,5,6],[7,8,0]])
'''
matrix([[1, 2, 3],
[4, 5, 6],
[7, 8, 0]])
'''
# 逆矩阵
y = np.linalg.inv(x)
'''
matrix([[-1.77777778, 0.88888889, -0.11111111],
[ 1.55555556, -0.77777778, 0.22222222],
[-0.11111111, 0.22222222, -0.11111111]])
注:numpy.linalg.LinAlgError: Singular matrix 矩阵不存在逆矩阵
'''
# 矩阵的乘法
x * y
'''
matrix([[ 1.00000000e+00, 5.55111512e-17, 1.38777878e-17],
[ 5.55111512e-17, 1.00000000e+00, 2.77555756e-17],
[ 1.77635684e-15, -8.88178420e-16, 1.00000000e+00]])
'''
y * x
'''
matrix([[ 1.00000000e+00, -1.11022302e-16, 0.00000000e+00],
[ 8.32667268e-17, 1.00000000e+00, 2.22044605e-16],
[ 6.93889390e-17, 0.00000000e+00, 1.00000000e+00]])
'''
# 求解线性方程组
a = np.array([[3,1],[1,2]])
'''
array([[3, 1],
[1, 2]])
'''
b = np.array([9,8])
# array([9, 8])
# 求解
x = np.linalg.solve(a,b)
# array([2., 3.])
# 验证
np.dot(a,x)
# array([9., 8.])
# 最小二乘解:返回解,余项,a 的秩,a 的奇异值
np.linalg.lstsq(a,b)
# (array([2., 3.]), array([], dtype=float64), 2, array([3.61803399, 1.38196601]))
# 计算向量和矩阵的范数
x = np.matrix([[1,2],[3,-4]])
'''
matrix([[ 1, 2],
[ 3, -4]])
'''
np.linalg.norm(x)
# 5.477225575051661
np.linalg.norm(x,-2)
# 1.9543950758485487
np.linalg.norm(x,-1)
# 4.0
np.linalg.norm(x,1)
# 6.0
np.linalg.norm([1,2,0,3,4,0],0)
# 4.0
np.linalg.norm([1,2,0,3,4,0],2)
# 5.477225575051661
# 奇异值分解
a = np.matrix([[1,2,3],[4,5,6],[7,8,9]])
'''
matrix([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
'''
u,s,v = np.linalg.svd(a)
u
'''
matrix([[-0.21483724, 0.88723069, 0.40824829],
[-0.52058739, 0.24964395, -0.81649658],
[-0.82633754, -0.38794278, 0.40824829]])
'''
s
'''
array([1.68481034e+01, 1.06836951e+00, 4.41842475e-16])
'''
v
'''
matrix([[-0.47967118, -0.57236779, -0.66506441],
[-0.77669099, -0.07568647, 0.62531805],
[-0.40824829, 0.81649658, -0.40824829]])
'''
# 验证
u * np.diag(s) * v
'''
matrix([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
'''
pandas第三方库
# 一维数组与常用操作
import pandas as pd
# 设置输出结果列对齐
pd.set_option('display.unicode.ambiguous_as_wide',True)
pd.set_option('display.unicode.east_asian_width',True)
# 创建 从 0 开始的非负整数索引
s1 = pd.Series(range(1,20,5))
'''
0 1
1 6
2 11
3 16
dtype: int64
'''
# 使用字典创建 Series 字典的键作为索引
s2 = pd.Series({'语文':95,'数学':98,'Python':100,'物理':97,'化学':99})
'''
语文 95
数学 98
Python 100
物理 97
化学 99
dtype: int64
'''
# 修改 Series 对象的值
s1[3] = -17
'''
0 1
1 6
2 11
3 -17
dtype: int64
'''
s2['语文'] = 94
'''
语文 94
数学 98
Python 100
物理 97
化学 99
dtype: int64
'''
# 查看 s1 的绝对值
abs(s1)
'''
0 1
1 6
2 11
3 17
dtype: int64
'''
# 将 s1 所有的值都加 5
s1 + 5
'''
0 6
1 11
2 16
3 -12
dtype: int64
'''
# 在 s1 的索引下标前加入参数值
s1.add_prefix(2)
'''
20 1
21 6
22 11
23 -17
dtype: int64
'''
# s2 数据的直方图
s2.hist()
# 每行索引后面加上 hany
s2.add_suffix('hany')
'''
语文hany 94
数学hany 98
Pythonhany 100
物理hany 97
化学hany 99
dtype: int64
'''
# 查看 s2 中最大值的索引
s2.argmax()
# 'Python'
# 查看 s2 的值是否在指定区间内
s2.between(90,100,inclusive = True)
'''
语文 True
数学 True
Python True
物理 True
化学 True
dtype: bool
'''
# 查看 s2 中 97 分以上的数据
s2[s2 > 97]
'''
数学 98
Python 100
化学 99
dtype: int64
'''
# 查看 s2 中大于中值的数据
s2[s2 > s2.median()]
'''
Python 100
化学 99
dtype: int64
'''
# s2 与数字之间的运算,开平方 * 10 保留一位小数
round((s2**0.5)*10,1)
'''
语文 97.0
数学 99.0
Python 100.0
物理 98.5
化学 99.5
dtype: float64
'''
# s2 的中值
s2.median()
# 98.0
# s2 中最小的两个数
s2.nsmallest(2)
'''
语文 94
物理 97
dtype: int64
'''
# s2 中最大的两个数
s2.nlargest(2)
'''
Python 100
化学 99
dtype: int64
'''
# Series 对象之间的运算,对相同索引进行计算,不是相同索引的使用 NaN
pd.Series(range(5)) + pd.Series(range(5,10))
'''
0 5
1 7
2 9
3 11
4 13
dtype: int64
'''
# pipe 对 Series 对象使用匿名函数
pd.Series(range(5)).pipe(lambda x,y,z :(x**y)%z,2,5)
'''
0 0
1 1
2 4
3 4
4 1
dtype: int64
'''
pd.Series(range(5)).pipe(lambda x:x+3)
'''
0 3
1 4
2 5
3 6
4 7
dtype: int64
'''
pd.Series(range(5)).pipe(lambda x:x+3).pipe(lambda x:x*3)
'''
0 9
1 12
2 15
3 18
4 21
dtype: int64
'''
# 对 Series 对象使用匿名函数
pd.Series(range(5)).apply(lambda x:x+3)
'''
0 3
1 4
2 5
3 6
4 7
dtype: int64
'''
# 查看标准差
pd.Series(range(0,5)).std()
# 1.5811388300841898
# 查看无偏方差
pd.Series(range(0,5)).var()
# 2.5
# 查看无偏标准差
pd.Series(range(0,5)).sem()
# 0.7071067811865476
# 查看是否存在等价于 True 的值
any(pd.Series([3,0,True]))
# True
# 查看是否所有的值都等价于 True
all(pd.Series([3,0,True]))
# False
# 时间序列和常用操作
import pandas as pd
# 每隔五天--5D
pd.date_range(start = '20200101',end = '20200131',freq = '5D')
'''
DatetimeIndex(['2020-01-01', '2020-01-06', '2020-01-11', '2020-01-16',
'2020-01-21', '2020-01-26', '2020-01-31'],
dtype='datetime64[ns]', freq='5D')
'''
# 每隔一周--W
pd.date_range(start = '20200301',end = '20200331',freq = 'W')
'''
DatetimeIndex(['2020-03-01', '2020-03-08', '2020-03-15', '2020-03-22',
'2020-03-29'],
dtype='datetime64[ns]', freq='W-SUN')
'''
# 间隔两天,五个数据
pd.date_range(start = '20200301',periods = 5,freq = '2D')
'''
DatetimeIndex(['2020-03-01', '2020-03-03', '2020-03-05', '2020-03-07',
'2020-03-09'],
dtype='datetime64[ns]', freq='2D')
'''
# 间隔三小时,八个数据
pd.date_range(start = '20200301',periods = 8,freq = '3H')
'''
DatetimeIndex(['2020-03-01 00:00:00', '2020-03-01 03:00:00',
'2020-03-01 06:00:00', '2020-03-01 09:00:00',
'2020-03-01 12:00:00', '2020-03-01 15:00:00',
'2020-03-01 18:00:00', '2020-03-01 21:00:00'],
dtype='datetime64[ns]', freq='3H')
'''
# 三点开始,十二个数据,间隔一分钟
pd.date_range(start = '202003010300',periods = 12,freq = 'T')
'''
DatetimeIndex(['2020-03-01 03:00:00', '2020-03-01 03:01:00',
'2020-03-01 03:02:00', '2020-03-01 03:03:00',
'2020-03-01 03:04:00', '2020-03-01 03:05:00',
'2020-03-01 03:06:00', '2020-03-01 03:07:00',
'2020-03-01 03:08:00', '2020-03-01 03:09:00',
'2020-03-01 03:10:00', '2020-03-01 03:11:00'],
dtype='datetime64[ns]', freq='T')
'''
# 每个月的最后一天
pd.date_range(start = '20190101',end = '20191231',freq = 'M')
'''
DatetimeIndex(['2019-01-31', '2019-02-28', '2019-03-31', '2019-04-30',
'2019-05-31', '2019-06-30', '2019-07-31', '2019-08-31',
'2019-09-30', '2019-10-31', '2019-11-30', '2019-12-31'],
dtype='datetime64[ns]', freq='M')
'''
# 间隔一年,六个数据,年末最后一天
pd.date_range(start = '20190101',periods = 6,freq = 'A')
'''
DatetimeIndex(['2019-12-31', '2020-12-31', '2021-12-31', '2022-12-31',
'2023-12-31', '2024-12-31'],
dtype='datetime64[ns]', freq='A-DEC')
'''
# 间隔一年,六个数据,年初最后一天
pd.date_range(start = '20200101',periods = 6,freq = 'AS')
'''
DatetimeIndex(['2020-01-01', '2021-01-01', '2022-01-01', '2023-01-01',
'2024-01-01', '2025-01-01'],
dtype='datetime64[ns]', freq='AS-JAN')
'''
# 使用 Series 对象包含时间序列对象,使用特定索引
data = pd.Series(index = pd.date_range(start = '20200321',periods = 24,freq = 'H'),data = range(24))
'''
2020-03-21 00:00:00 0
2020-03-21 01:00:00 1
2020-03-21 02:00:00 2
2020-03-21 03:00:00 3
2020-03-21 04:00:00 4
2020-03-21 05:00:00 5
2020-03-21 06:00:00 6
2020-03-21 07:00:00 7
2020-03-21 08:00:00 8
2020-03-21 09:00:00 9
2020-03-21 10:00:00 10
2020-03-21 11:00:00 11
2020-03-21 12:00:00 12
2020-03-21 13:00:00 13
2020-03-21 14:00:00 14
2020-03-21 15:00:00 15
2020-03-21 16:00:00 16
2020-03-21 17:00:00 17
2020-03-21 18:00:00 18
2020-03-21 19:00:00 19
2020-03-21 20:00:00 20
2020-03-21 21:00:00 21
2020-03-21 22:00:00 22
2020-03-21 23:00:00 23
Freq: H, dtype: int64
'''
# 查看前五个数据
data[:5]
'''
2020-03-21 00:00:00 0
2020-03-21 01:00:00 1
2020-03-21 02:00:00 2
2020-03-21 03:00:00 3
2020-03-21 04:00:00 4
Freq: H, dtype: int64
'''
# 三分钟重采样,计算均值
data.resample('3H').mean()
'''
2020-03-21 00:00:00 1
2020-03-21 03:00:00 4
2020-03-21 06:00:00 7
2020-03-21 09:00:00 10
2020-03-21 12:00:00 13
2020-03-21 15:00:00 16
2020-03-21 18:00:00 19
2020-03-21 21:00:00 22
Freq: 3H, dtype: int64
'''
# 五分钟重采样,求和
data.resample('5H').sum()
'''
2020-03-21 00:00:00 10
2020-03-21 05:00:00 35
2020-03-21 10:00:00 60
2020-03-21 15:00:00 85
2020-03-21 20:00:00 86
Freq: 5H, dtype: int64
'''
# 计算OHLC open,high,low,close
data.resample('5H').ohlc()
'''
open high low close
2020-03-21 00:00:00 0 4 0 4
2020-03-21 05:00:00 5 9 5 9
2020-03-21 10:00:00 10 14 10 14
2020-03-21 15:00:00 15 19 15 19
2020-03-21 20:00:00 20 23 20 23
'''
# 将日期替换为第二天
data.index = data.index + pd.Timedelta('1D')
# 查看前五条数据
data[:5]
'''
2020-03-22 00:00:00 0
2020-03-22 01:00:00 1
2020-03-22 02:00:00 2
2020-03-22 03:00:00 3
2020-03-22 04:00:00 4
Freq: H, dtype: int64
'''
# 查看指定日期是星期几
# pd.Timestamp('20200321').weekday_name
# 'Saturday'
# 查看指定日期的年份是否是闰年
pd.Timestamp('20200301').is_leap_year
# True
# 查看指定日期所在的季度和月份
day = pd.Timestamp('20200321')
# Timestamp('2020-03-21 00:00:00')
# 查看日期的季度
day.quarter
# 1
# 查看日期所在的月份
day.month
# 3
# 转换为 python 的日期时间对象
day.to_pydatetime()
# datetime.datetime(2020, 3, 21, 0, 0)
# DateFrame 的创建,包含部分:index , column , values
import numpy as np
import pandas as pd
# 创建一个 DataFrame 对象
dataframe = pd.DataFrame(np.random.randint(1,20,(5,3)),
index = range(5),
columns = ['A','B','C'])
'''
A B C
0 17 9 19
1 14 5 8
2 7 18 13
3 13 16 2
4 18 6 5
'''
# 索引为时间序列
dataframe2 = pd.DataFrame(np.random.randint(5,15,(9,3)),
index = pd.date_range(start = '202003211126',
end = '202003212000',
freq = 'H'),
columns = ['Pandas','爬虫','比赛'])
'''
Pandas 爬虫 比赛
2020-03-21 11:26:00 8 10 8
2020-03-21 12:26:00 9 14 9
2020-03-21 13:26:00 9 5 13
2020-03-21 14:26:00 9 7 7
2020-03-21 15:26:00 11 10 14
2020-03-21 16:26:00 12 7 10
2020-03-21 17:26:00 11 11 13
2020-03-21 18:26:00 8 13 8
2020-03-21 19:26:00 7 7 13
'''
# 使用字典进行创建
dataframe3 = pd.DataFrame({'语文':[87,79,67,92],
'数学':[93,89,80,77],
'英语':[88,95,76,77]},
index = ['张三','李四','王五','赵六'])
'''
语文 数学 英语
张三 87 93 88
李四 79 89 95
王五 67 80 76
赵六 92 77 77
'''
# 创建时自动扩充
dataframe4 = pd.DataFrame({'A':range(5,10),'B':3})
'''
A B
0 5 3
1 6 3
2 7 3
3 8 3
4 9 3
'''
# C:\Users\lenovo\Desktop\总结\Python
# 读取 Excel 文件并进行筛选
import pandas as pd
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额'])
# 打印前十行数据
dataframe[:10]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
4 1005 周七 9:00-14:00 600
5 1006 钱八 14:00-21:00 700
6 1006 钱八 9:00-14:00 850
7 1001 张三 14:00-21:00 600
8 1001 张三 9:00-14:00 1300
9 1002 李四 14:00-21:00 1500
'''
# 跳过 1 2 4 行,以第一列姓名为索引
dataframe2 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
skiprows = [1,2,4],
index_col = 1)
'''注:张三李四赵六的第一条数据跳过
工号 日期 时段 交易额 柜台
姓名
王五 1003 20190301 9:00-14:00 800 食品
周七 1005 20190301 9:00-14:00 600 日用品
钱八 1006 20190301 14:00-21:00 700 日用品
钱八 1006 20190301 9:00-14:00 850 蔬菜水果
张三 1001 20190302 14:00-21:00 600 蔬菜水果
'''
# 筛选符合特定条件的数据
# 读取超市营业额数据
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看 5 到 10 的数据
dataframe[5:11]
'''
工号 姓名 日期 时段 交易额 柜台
5 1006 钱八 20190301 14:00-21:00 700 日用品
6 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
7 1001 张三 20190302 14:00-21:00 600 蔬菜水果
8 1001 张三 20190302 9:00-14:00 1300 化妆品
9 1002 李四 20190302 14:00-21:00 1500 化妆品
10 1003 王五 20190302 9:00-14:00 1000 食品
'''
# 查看第六行的数据,左闭右开
dataframe.iloc[5]
'''
工号 1006
姓名 钱八
时段 14:00-21:00
交易额 700
Name: 5, dtype: object
'''
dataframe[:5]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
4 1005 周七 9:00-14:00 600
'''
# 查看第 1 3 4 行的数据
dataframe.iloc[[0,2,3],:]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
'''
# 查看第 1 3 4 行的第 1 2 列
dataframe.iloc[[0,2,3],[0,1]]
'''
工号 姓名
0 1001 张三
2 1003 王五
3 1004 赵六
'''
# 查看前五行指定,姓名、时段和交易额的数据
dataframe[['姓名','时段','交易额']][:5]
'''
姓名 时段 交易额
0 张三 9:00-14:00 2000
1 李四 14:00-21:00 1800
2 王五 9:00-14:00 800
3 赵六 14:00-21:00 1100
4 周七 9:00-14:00 600
'''
dataframe[:5][['姓名','时段','交易额']]
'''
姓名 时段 交易额
0 张三 9:00-14:00 2000
1 李四 14:00-21:00 1800
2 王五 9:00-14:00 800
3 赵六 14:00-21:00 1100
4 周七 9:00-14:00 600
'''
# 查看第 2 4 5 行 姓名,交易额 数据 loc 函数,包含结尾
dataframe.loc[[1,3,4],['姓名','交易额']]
'''
姓名 交易额
1 李四 1800
3 赵六 1100
4 周七 600
'''
# 查看第四行的姓名数据
dataframe.at[3,'姓名']
# '赵六'
# 查看交易额大于 1700 的数据
dataframe[dataframe['交易额'] > 1700]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
'''
# 查看交易额总和
dataframe.sum()
'''
工号 17055
姓名 张三李四王五赵六周七钱八钱八张三张三李四王五赵六周七钱八李四王五张三...
时段 9:00-14:0014:00-21:009:00-14:0014:00-21:009:00...
交易额 17410
dtype: object
'''
# 某一时段的交易总和
dataframe[dataframe['时段'] == '14:00-21:00']['交易额'].sum()
# 8300
# 查看张三在下午14:00之后的交易情况
dataframe[(dataframe.姓名 == '张三') & (dataframe.时段 == '14:00-21:00')][:10]
'''
工号 姓名 时段 交易额
7 1001 张三 14:00-21:00 600
'''
# 查看日用品的销售总额
# dataframe[dataframe['柜台'] == '日用品']['交易额'].sum()
# 查看张三总共的交易额
dataframe[dataframe['姓名'].isin(['张三'])]['交易额'].sum()
# 5200
# 查看交易额在 1500~3000 之间的记录
dataframe[dataframe['交易额'].between(1500,3000)]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
9 1002 李四 14:00-21:00 1500
'''
# 查看数据特征和统计信息
import pandas as pd
# 读取文件
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看所有的交易额信息
dataframe['交易额'].describe()
'''
count 17.000000
mean 1024.117647
std 428.019550
min 580.000000
25% 700.000000
50% 850.000000
75% 1300.000000
max 2000.000000
Name: 交易额, dtype: float64
'''
# 查看四分位数
dataframe['交易额'].quantile([0,0.25,0.5,0.75,1.0])
'''
0.00 580.0
0.25 700.0
0.50 850.0
0.75 1300.0
1.00 2000.0
Name: 交易额, dtype: float64
'''
# 交易额中值
dataframe['交易额'].median()
# 850.0
# 交易额最小的三个数据
dataframe['交易额'].nsmallest(3)
'''
12 580
4 600
7 600
Name: 交易额, dtype: int64
'''
dataframe.nsmallest(3,'交易额')
'''
工号 姓名 日期 时段 交易额 柜台
12 1005 周七 20190302 9:00-14:00 580 日用品
4 1005 周七 20190301 9:00-14:00 600 日用品
7 1001 张三 20190302 14:00-21:00 600 蔬菜水果
'''
# 交易额最大的两个数据
dataframe['交易额'].nlargest(2)
'''
0 2000
1 1800
Name: 交易额, dtype: int64
'''
dataframe.nlargest(2,'交易额')
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
'''
# 查看最后一个日期
dataframe['日期'].max()
# 20190303
# 查看最小的工号
dataframe['工号'].min()
# 1001
# 第一个最小交易额的行下标
index = dataframe['交易额'].idxmin()
# 0
# 第一个最小交易额
dataframe.loc[index,'交易额']
# 580
# 最大交易额的行下标
index = dataframe['交易额'].idxmax()
dataframe.loc[index,'交易额']
# 2000
import pandas as pd
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额','柜台'])
dataframe[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
2 1003 王五 9:00-14:00 800 食品
3 1004 赵六 14:00-21:00 1100 食品
4 1005 周七 9:00-14:00 600 日用品
'''
# 按照交易额和工号降序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = False)[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
9 1002 李四 14:00-21:00 1500 化妆品
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
'''
# 按照交易额和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'])[:5]
'''
工号 姓名 时段 交易额 柜台
12 1005 周七 9:00-14:00 580 日用品
7 1001 张三 14:00-21:00 600 蔬菜水果
4 1005 周七 9:00-14:00 600 日用品
14 1002 李四 9:00-14:00 680 蔬菜水果
5 1006 钱八 14:00-21:00 700 日用品
'''
# 按照交易额降序和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = [False,True])[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
9 1002 李四 14:00-21:00 1500 化妆品
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
'''
# 按工号升序排序
dataframe.sort_values(by = ['工号'])[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
7 1001 张三 14:00-21:00 600 蔬菜水果
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
'''
dataframe.sort_values(by = ['工号'],na_position = 'last')[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
7 1001 张三 14:00-21:00 600 蔬菜水果
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
'''
# 按列名升序排序
dataframe.sort_index(axis = 1)[:5]
'''
交易额 姓名 工号 时段 柜台
0 2000 张三 1001 9:00-14:00 化妆品
1 1800 李四 1002 14:00-21:00 化妆品
2 800 王五 1003 9:00-14:00 食品
3 1100 赵六 1004 14:00-21:00 食品
4 600 周七 1005 9:00-14:00 日用品
'''
dataframe.sort_index(axis = 1,ascending = True)[:5]
'''
交易额 姓名 工号 时段 柜台
0 2000 张三 1001 9:00-14:00 化妆品
1 1800 李四 1002 14:00-21:00 化妆品
2 800 王五 1003 9:00-14:00 食品
3 1100 赵六 1004 14:00-21:00 食品
4 600 周七 1005 9:00-14:00 日用品
'''
# 分组与聚合
import pandas as pd
import numpy as np
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额','柜台'])
# 对 5 的余数进行分组
dataframe.groupby(by = lambda num:num % 5)['交易额'].sum()
'''
0 4530
1 5000
2 1980
3 3120
4 2780
Name: 交易额, dtype: int64
'''
# 查看索引为 7 15 的交易额
dataframe.groupby(by = {7:'索引为7的行',15:'索引为15的行'})['交易额'].sum()
'''
索引为15的行 830
索引为7的行 600
Name: 交易额, dtype: int64
'''
# 查看不同时段的交易总额
dataframe.groupby(by = '时段')['交易额'].sum()
'''
时段
14:00-21:00 8300
9:00-14:00 9110
Name: 交易额, dtype: int64
'''
# 各柜台的销售总额
dataframe.groupby(by = '柜台')['交易额'].sum()
'''
柜台
化妆品 7900
日用品 2600
蔬菜水果 2960
食品 3950
Name: 交易额, dtype: int64
'''
# 查看每个人在每个时段购买的次数
count = dataframe.groupby(by = '姓名')['时段'].count()
'''
姓名
周七 2
张三 4
李四 3
王五 3
赵六 2
钱八 3
Name: 时段, dtype: int64
'''
#
count.name = '交易人和次数'
'''
'''
# 每个人的交易额平均值并排序
dataframe.groupby(by = '姓名')['交易额'].mean().round(2).sort_values()
'''
姓名
周七 590.00
钱八 756.67
王五 876.67
赵六 1075.00
张三 1300.00
李四 1326.67
Name: 交易额, dtype: float64
'''
# 每个人的交易额
dataframe.groupby(by = '姓名').sum()['交易额'].apply(int)
'''
姓名
周七 1180
张三 5200
李四 3980
王五 2630
赵六 2150
钱八 2270
Name: 交易额, dtype: int64
'''
# 每一个员工交易额的中值
data = dataframe.groupby(by = '姓名').median()
'''
工号 交易额
姓名
周七 1005 590
张三 1001 1300
李四 1002 1500
王五 1003 830
赵六 1004 1075
钱八 1006 720
'''
data['交易额']
'''
姓名
周七 590
张三 1300
李四 1500
王五 830
赵六 1075
钱八 720
Name: 交易额, dtype: int64
'''
# 查看交易额对应的排名
data['排名'] = data['交易额'].rank(ascending = False)
data[['交易额','排名']]
'''
交易额 排名
姓名
周七 590 6.0
张三 1300 2.0
李四 1500 1.0
王五 830 4.0
赵六 1075 3.0
钱八 720 5.0
'''
# 每个人不同时段的交易额
dataframe.groupby(by = ['姓名','时段'])['交易额'].sum()
'''
姓名 时段
周七 9:00-14:00 1180
张三 14:00-21:00 600
9:00-14:00 4600
李四 14:00-21:00 3300
9:00-14:00 680
王五 14:00-21:00 830
9:00-14:00 1800
赵六 14:00-21:00 2150
钱八 14:00-21:00 1420
9:00-14:00 850
Name: 交易额, dtype: int64
'''
# 设置各时段累计
dataframe.groupby(by = ['姓名'])['时段','交易额'].aggregate({'交易额':np.sum,'时段':lambda x:'各时段累计'})
'''
交易额 时段
姓名
周七 1180 各时段累计
张三 5200 各时段累计
李四 3980 各时段累计
王五 2630 各时段累计
赵六 2150 各时段累计
钱八 2270 各时段累计
'''
# 对指定列进行聚合,查看最大,最小,和,平均值,中值
dataframe.groupby(by = '姓名').agg(['max','min','sum','mean','median'])
'''
工号 交易额
max min sum mean median max min sum mean median
姓名
周七 1005 1005 2010 1005 1005 600 580 1180 590.000000 590
张三 1001 1001 4004 1001 1001 2000 600 5200 1300.000000 1300
李四 1002 1002 3006 1002 1002 1800 680 3980 1326.666667 1500
王五 1003 1003 3009 1003 1003 1000 800 2630 876.666667 830
赵六 1004 1004 2008 1004 1004 1100 1050 2150 1075.000000 1075
钱八 1006 1006 3018 1006 1006 850 700 2270 756.666667 720
'''
# 查看部分聚合后的结果
dataframe.groupby(by = '姓名').agg(['max','min','sum','mean','median'])['交易额']
'''
max min sum mean median
姓名
周七 600 580 1180 590.000000 590
张三 2000 600 5200 1300.000000 1300
李四 1800 680 3980 1326.666667 1500
王五 1000 800 2630 876.666667 830
赵六 1100 1050 2150 1075.000000 1075
钱八 850 700 2270 756.666667 720
'''
# 处理异常值缺失值重复值数据差分
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 异常值
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看交易额低于 2000 的三条数据
# dataframe[dataframe.交易额 < 2000]
dataframe[dataframe.交易额 < 2000][:3]
'''
工号 姓名 日期 时段 交易额 柜台
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
3 1004 赵六 20190301 14:00-21:00 1100 食品
'''
# 查看上浮了 50% 之后依旧低于 1500 的交易额,查看 4 条数据
dataframe.loc[dataframe.交易额 < 1500,'交易额'] = dataframe[dataframe.交易额 < 1500]['交易额'].map(lambda num:num*1.5)
dataframe[dataframe.交易额 < 1500][:4]
'''
工号 姓名 日期 时段 交易额 柜台
2 1003 王五 20190301 9:00-14:00 1200.0 食品
4 1005 周七 20190301 9:00-14:00 900.0 日用品
5 1006 钱八 20190301 14:00-21:00 1050.0 日用品
6 1006 钱八 20190301 9:00-14:00 1275.0 蔬菜水果
'''
# 查看交易额大于 2500 的数据
dataframe[dataframe.交易额 > 2500]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# 查看交易额低于 900 或 高于 1800 的数据
dataframe[(dataframe.交易额 < 900)|(dataframe.交易额 > 1800)]
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000.0 化妆品
8 1001 张三 20190302 9:00-14:00 1950.0 化妆品
12 1005 周七 20190302 9:00-14:00 870.0 日用品
16 1001 张三 20190303 9:00-14:00 1950.0 化妆品
'''
# 将所有低于 200 的交易额都替换成 200 处理异常值
dataframe.loc[dataframe.交易额 < 200,'交易额'] = 200
# 查看低于 1500 的交易额个数
dataframe.loc[dataframe.交易额 < 1500,'交易额'].count()
# 9
# 将大于 3000 元的都替换为 3000 元
dataframe.loc[dataframe.交易额 > 3000,'交易额'] = 3000
# 缺失值
# 查看有多少行数据
len(dataframe)
# 17
# 丢弃缺失值之后的行数
len(dataframe.dropna())
# 17
# 包含缺失值的行
dataframe[dataframe['交易额'].isnull()]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# 使用固定值替换缺失值
# dff = copy.deepcopy(dataframe)
# dff.loc[dff.交易额.isnull(),'交易额'] = 999
# 将缺失值设定为 999,包含结尾
# dff.iloc[[1,4,17],:]
# 使用交易额的均值替换缺失值
# dff = copy.deepcopy(dataframe)
# for i in dff[dff.交易额.isnull()].index:
# dff.loc[i,'交易额'] = round(dff.loc[dff.姓名 == dff.loc[i,'姓名'],'交易额'].mean())
# dff.iloc[[1,4,17],:]
# 使用整体均值的 80% 填充缺失值
# dataframe.fillna({'交易额':round(dataframe['交易额'].mean() * 0.8)},inplace = True)
# dataframe.iloc[[1,4,16],:]
# 重复值
dataframe[dataframe.duplicated()]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# dff = dataframe[['工号','姓名','日期','交易额']]
# dff = dff[dff.duplicated()]
# for row in dff.values:
# df[(df.工号 == row[0]) & (df.日期 == row[2]) &(df.交易额 == row[3])]
# 丢弃重复行
dataframe = dataframe.drop_duplicates()
# 查看是否有录入错误的工号和姓名
dff = dataframe[['工号','姓名']]
dff.drop_duplicates()
'''
工号 姓名
0 1001 张三
1 1002 李四
2 1003 王五
3 1004 赵六
4 1005 周七
5 1006 钱八
'''
# 数据差分
# 查看员工业绩波动情况(每一天和昨天的数据作比较)
dff = dataframe.groupby(by = '日期').sum()['交易额'].diff()
'''
日期
20190301 NaN
20190302 1765.0
20190303 -9690.0
Name: 交易额, dtype: float64
'''
# [:5] dataframe.head()
dff.map(lambda num:'%.2f'%(num))[:5]
'''
日期
20190301 nan
20190302 1765.00
20190303 -9690.00
Name: 交易额, dtype: object
'''
# 查看张三的波动情况
dataframe[dataframe.姓名 == '张三'].groupby(by = '日期').sum()['交易额'].diff()[:5]
'''
日期
20190301 NaN
20190302 850.0
20190303 -900.0
Name: 交易额, dtype: float64
'''
# 使用透视表与交叉表查看业绩汇总数据
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 对姓名和日期进行分组,并进行求和
dff = dataframe.groupby(by = ['姓名','日期'],as_index = False).sum()
'''
姓名 日期 工号 交易额
0 周七 20190301 1005 600
1 周七 20190302 1005 580
2 张三 20190301 1001 2000
3 张三 20190302 2002 1900
4 张三 20190303 1001 1300
5 李四 20190301 1002 1800
6 李四 20190302 2004 2180
7 王五 20190301 1003 800
8 王五 20190302 2006 1830
9 赵六 20190301 1004 1100
10 赵六 20190302 1004 1050
11 钱八 20190301 2012 1550
12 钱八 20190302 1006 720
'''
# 将 dff 的索引,列 设置成透视表形式
dff = dff.pivot(index = '姓名',columns = '日期',values = '交易额')
'''
日期 20190301 20190302 20190303
姓名
周七 600.0 580.0 NaN
张三 2000.0 1900.0 1300.0
李四 1800.0 2180.0 NaN
王五 800.0 1830.0 NaN
赵六 1100.0 1050.0 NaN
钱八 1550.0 720.0 NaN
'''
# 查看前一天的数据
dff.iloc[:,:1]
'''
日期 20190301
姓名
周七 600.0
张三 2000.0
李四 1800.0
王五 800.0
赵六 1100.0
钱八 1550.0
'''
# 交易总额小于 4000 的人的前三天业绩
dff[dff.sum(axis = 1) < 4000].iloc[:,:3]
'''
日期 20190301 20190302 20190303
姓名
周七 600.0 580.0 NaN
李四 1800.0 2180.0 NaN
王五 800.0 1830.0 NaN
赵六 1100.0 1050.0 NaN
钱八 1550.0 720.0 NaN
'''
# 工资总额大于 2900 元的员工的姓名
dff[dff.sum(axis = 1) > 2900].index.values
# array(['张三', '李四'], dtype=object)
# 显示前两天每一天的交易总额以及每个人的交易金额
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'sum',margins = True).iloc[:,:2]
'''
日期 20190301 20190302
姓名
周七 600.0 580.0
张三 2000.0 1900.0
李四 1800.0 2180.0
王五 800.0 1830.0
赵六 1100.0 1050.0
钱八 1550.0 720.0
All 7850.0 8260.0
'''
# 显示每个人在每个柜台的交易总额
dff = dataframe.groupby(by = ['姓名','柜台'],as_index = False).sum()
dff.pivot(index = '姓名',columns = '柜台',values = '交易额')
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 1180.0 NaN NaN
张三 4600.0 NaN 600.0 NaN
李四 3300.0 NaN 680.0 NaN
王五 NaN NaN 830.0 1800.0
赵六 NaN NaN NaN 2150.0
钱八 NaN 1420.0 850.0 NaN
'''
# 查看每人每天的上班次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True).iloc[:,:1]
'''
日期 20190301
姓名
周七 1.0
张三 1.0
李四 1.0
王五 1.0
赵六 1.0
钱八 2.0
All 7.0
'''
# 查看每个人每天购买的次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True)
'''
日期 20190301 20190302 20190303 All
姓名
周七 1.0 1.0 NaN 2
张三 1.0 2.0 1.0 4
李四 1.0 2.0 NaN 3
王五 1.0 2.0 NaN 3
赵六 1.0 1.0 NaN 2
钱八 2.0 1.0 NaN 3
All 7.0 9.0 1.0 17
'''
# 交叉表
# 每个人每天上过几次班
pd.crosstab(dataframe.姓名,dataframe.日期,margins = True).iloc[:,:2]
'''
日期 20190301 20190302
姓名
周七 1 1
张三 1 2
李四 1 2
王五 1 2
赵六 1 1
钱八 2 1
All 7 9
'''
# 每个人每天去过几次柜台
pd.crosstab(dataframe.姓名,dataframe.柜台)
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 0 2 0 0
张三 3 0 1 0
李四 2 0 1 0
王五 0 0 1 2
赵六 0 0 0 2
钱八 0 2 1 0
'''
# 将每一个人在每一个柜台的交易总额显示出来
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc='sum')
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 1180.0 NaN NaN
张三 4600.0 NaN 600.0 NaN
李四 3300.0 NaN 680.0 NaN
王五 NaN NaN 830.0 1800.0
赵六 NaN NaN NaN 2150.0
钱八 NaN 1420.0 850.0 NaN
'''
# 每个人在每个柜台交易额的平均值,金额/天数
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc = 'mean').apply(lambda num:round(num,2) )
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 590.0 NaN NaN
张三 1533.33 NaN 600.0 NaN
李四 1650.00 NaN 680.0 NaN
王五 NaN NaN 830.0 900.0
赵六 NaN NaN NaN 1075.0
钱八 NaN 710.0 850.0 NaN
'''
# 重采样 多索引 标准差 协方差
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 将日期设置为 python 中的日期类型
data.日期 = pd.to_datetime(data.日期)
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 1970-01-01 00:00:00.020190301 9:00-14:00 2000 化妆品
1 1002 李四 1970-01-01 00:00:00.020190301 14:00-21:00 1800 化妆品
2 1003 王五 1970-01-01 00:00:00.020190301 9:00-14:00 800 食品
'''
# 每七天营业的总额
data.resample('7D',on = '日期').sum()['交易额']
'''
日期
1970-01-01 17410
Freq: 7D, Name: 交易额, dtype: int64
'''
# 每七天营业总额
data.resample('7D',on = '日期',label = 'right').sum()['交易额']
'''
日期
1970-01-08 17410
Freq: 7D, Name: 交易额, dtype: int64
'''
# 每七天营业额的平均值
func = lambda item:round(np.sum(item)/len(item),2)
data.resample('7D',on = '日期',label = 'right').apply(func)['交易额']
'''
日期
1970-01-08 1024.12
Freq: 7D, Name: 交易额, dtype: float64
'''
# 每七天营业额的平均值
func = lambda num:round(num,2)
data.resample('7D',on = '日期',label = 'right').mean().apply(func)['交易额']
# 1024.12
# 删除工号这一列
data.drop('工号',axis = 1,inplace = True)
data[:2]
'''
姓名 日期 时段 交易额 柜台
0 张三 1970-01-01 00:00:00.020190301 9:00-14:00 2000 化妆品
1 李四 1970-01-01 00:00:00.020190301 14:00-21:00 1800 化妆品
'''
# 按照姓名和柜台进行分组汇总
data = data.groupby(by = ['姓名','柜台']).sum()[:3]
'''
交易额
姓名 柜台
周七 日用品 1180
张三 化妆品 4600
蔬菜水果 600
'''
# 查看张三的汇总数据
data.loc['张三',:]
'''
交易额
柜台
化妆品 4600
蔬菜水果 600
'''
# 查看张三在蔬菜水果的交易数据
data.loc['张三','蔬菜水果']
'''
交易额 600
Name: (张三, 蔬菜水果), dtype: int64
'''
# 多索引
# 重新读取,使用第二列和第六列作为索引,排在前面
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',index_col = [1,5])
data[:5]
'''
工号 日期 时段 交易额
姓名 柜台
张三 化妆品 1001 20190301 9:00-14:00 2000
李四 化妆品 1002 20190301 14:00-21:00 1800
王五 食品 1003 20190301 9:00-14:00 800
赵六 食品 1004 20190301 14:00-21:00 1100
周七 日用品 1005 20190301 9:00-14:00 600
'''
# 丢弃工号列
data.drop('工号',axis = 1,inplace = True)
data[:5]
'''
日期 时段 交易额
姓名 柜台
张三 化妆品 20190301 9:00-14:00 2000
李四 化妆品 20190301 14:00-21:00 1800
王五 食品 20190301 9:00-14:00 800
赵六 食品 20190301 14:00-21:00 1100
周七 日用品 20190301 9:00-14:00 600
'''
# 按照柜台进行排序
dff = data.sort_index(level = '柜台',axis = 0)
dff[:5]
'''
工号 日期 时段 交易额
姓名 柜台
张三 化妆品 1001 20190301 9:00-14:00 2000
化妆品 1001 20190302 9:00-14:00 1300
化妆品 1001 20190303 9:00-14:00 1300
李四 化妆品 1002 20190301 14:00-21:00 1800
化妆品 1002 20190302 14:00-21:00 1500
'''
# 按照姓名进行排序
dff = data.sort_index(level = '姓名',axis = 0)
dff[:5]
'''
工号 日期 时段 交易额
姓名 柜台
周七 日用品 1005 20190301 9:00-14:00 600
日用品 1005 20190302 9:00-14:00 580
张三 化妆品 1001 20190301 9:00-14:00 2000
化妆品 1001 20190302 9:00-14:00 1300
化妆品 1001 20190303 9:00-14:00 1300
'''
# 按照柜台进行分组求和
dff = data.groupby(level = '柜台').sum()['交易额']
'''
柜台
化妆品 7900
日用品 2600
蔬菜水果 2960
食品 3950
Name: 交易额, dtype: int64
'''
#标准差
data = pd.DataFrame({'A':[3,3,3,3,3],'B':[1,2,3,4,5],
'C':[-5,-4,1,4,5],'D':[-45,15,63,40,50]
})
'''
A B C D
0 3 1 -5 -45
1 3 2 -4 15
2 3 3 1 63
3 3 4 4 40
4 3 5 5 50
'''
# 平均值
data.mean()
'''
A 3.0
B 3.0
C 0.2
D 24.6
dtype: float64
'''
# 标准差
data.std()
'''
A 0.000000
B 1.581139
C 4.549725
D 42.700117
dtype: float64
'''
# 标准差的平方
data.std()**2
'''
A 0.0
B 2.5
C 20.7
D 1823.3
dtype: float64
'''
# 协方差
data.cov()
'''
A B C D
A 0.0 0.00 0.00 0.00
B 0.0 2.50 7.00 53.75
C 0.0 7.00 20.70 153.35
D 0.0 53.75 153.35 1823.30
'''
# 指定索引为 姓名,日期,时段,柜台,交易额
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['姓名','日期','时段','柜台','交易额'])
# 删除缺失值和重复值,inplace = True 直接丢弃
data.dropna(inplace = True)
data.drop_duplicates(inplace = True)
# 处理异常值
data.loc[data.交易额 < 200,'交易额'] = 200
data.loc[data.交易额 > 3000,'交易额'] = 3000
# 使用交叉表得到不同员工在不同柜台的交易额平均值
dff = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean')
dff[:5]
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 590.0 NaN NaN
张三 1533.333333 NaN 600.0 NaN
李四 1650.000000 NaN 680.0 NaN
王五 NaN NaN 830.0 900.0
赵六 NaN NaN NaN 1075.0
'''
# 查看数据的标准差
dff.std()
'''
柜台
化妆品 82.495791
日用品 84.852814
蔬菜水果 120.277457
食品 123.743687
dtype: float64
'''
dff.cov()
'''
柜台 化妆品 日用品 蔬菜水果 食品
柜台
化妆品 6805.555556 NaN 4666.666667 NaN
日用品 NaN 7200.0 NaN NaN
蔬菜水果 4666.666667 NaN 14466.666667 NaN
食品 NaN NaN NaN 15312.5
'''
import pandas as pd
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',usecols = ['日期','交易额'])
dff = copy.deepcopy(data)
# 查看周几
dff['日期'] = pd.to_datetime(data['日期']).dt.weekday_name
'''
日期 交易额
0 Thursday 2000
1 Thursday 1800
2 Thursday 800
'''
# 按照周几进行分组,查看交易的平均值
dff = dff.groupby('日期').mean().apply(round)
dff.index.name = '周几'
dff[:3]
'''
交易额
周几
Thursday 1024.0
'''
# dff = copy.deepcopy(data)
# 使用正则规则查看月份日期
# dff['日期'] = dff.日期.str.extract(r'(\d{4}-\d{2})')
# dff[:5]
# 按照日 进行分组查看交易的平均值 -1 表示倒数第一个
# data.groupby(data.日期.str.__getitem__(-1)).mean().apply(round)
# 查看日期尾数为 1 的数据
# data[data.日期.str.endswith('1')][:12]
# 查看日期尾数为 12 的交易数据,slice 为切片 (-2) 表示倒数两个
# data[data.日期.str.slice(-2) == '12']
# 查看日期中月份或天数包含 2 的交易数据
# data[data.日期.str.slice(-5).str.contains('2')][1:9]
import pandas as pd
import numpy as np
# 读取全部数据,使用默认索引
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 修改异常值
data.loc[data.交易额 > 3000,'交易额'] = 3000
data.loc[data.交易额 < 200,'交易额'] = 200
# 删除重复值
data.drop_duplicates(inplace = True)
# 填充缺失值
data['交易额'].fillna(data['交易额'].mean(),inplace = True)
# 使用交叉表得到每人在各柜台交易额的平均值
data_group = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean').apply(round)
# 绘制柱状图
data_group.plot(kind = 'bar')
#
# 数据的合并
data1 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
data2 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',sheet_name = 'Sheet2')
df1 = data1[:3]
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
'''
df2 = data2[:4]
'''
工号 姓名 日期 时段 交易额 柜台
0 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
1 1001 张三 20190302 14:00-21:00 600 蔬菜水果
2 1001 张三 20190302 9:00-14:00 1300 化妆品
3 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 使用 concat 连接两个相同结构的 DataFrame 对象
df3 = pd.concat([df1,df2])
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
0 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
1 1001 张三 20190302 14:00-21:00 600 蔬菜水果
2 1001 张三 20190302 9:00-14:00 1300 化妆品
3 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 合并,忽略原来的索引 ignore_index
df4 = df3.append([df1,df2],ignore_index = True)
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
3 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
4 1001 张三 20190302 14:00-21:00 600 蔬菜水果
5 1001 张三 20190302 9:00-14:00 1300 化妆品
6 1002 李四 20190302 14:00-21:00 1500 化妆品
7 1001 张三 20190301 9:00-14:00 2000 化妆品
8 1002 李四 20190301 14:00-21:00 1800 化妆品
9 1003 王五 20190301 9:00-14:00 800 食品
10 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
11 1001 张三 20190302 14:00-21:00 600 蔬菜水果
12 1001 张三 20190302 9:00-14:00 1300 化妆品
13 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 按照列进行拆分
df5 = df4.loc[:,['姓名','柜台','交易额']]
# 查看前五条数据
df5[:5]
'''
姓名 柜台 交易额
0 张三 化妆品 2000
1 李四 化妆品 1800
2 王五 食品 800
3 钱八 蔬菜水果 850
4 张三 蔬菜水果 600
'''
# 合并 merge 、 join
# 按照工号进行合并,随机查看 3 条数据
rows = np.random.randint(0,len(df5),3)
pd.merge(df4,df5).iloc[rows,:]
'''
工号 姓名 日期 时段 交易额 柜台
7 1002 李四 20190301 14:00-21:00 1800 化妆品
4 1002 李四 20190301 14:00-21:00 1800 化妆品
10 1003 王五 20190301 9:00-14:00 800 食品
'''
# 按照工号进行合并,指定其他同名列的后缀
pd.merge(df1,df2,on = '工号',suffixes = ['_x','_y']).iloc[:,:]
'''
工号 姓名_x 日期_x 时段_x ... 日期_y 时段_y 交易额_y 柜台_y
0 1001 张三 20190301 9:00-14:00 ... 20190302 14:00-21:00 600 蔬菜水果
1 1001 张三 20190301 9:00-14:00 ... 20190302 9:00-14:00 1300 化妆品
2 1002 李四 20190301 14:00-21:00 ... 20190302 14:00-21:00 1500 化妆品
'''
# 两个表都设置工号为索引 set_index
df2.set_index('工号').join(df3.set_index('工号'),lsuffix = '_x',rsuffix = '_y').iloc[:]
'''
姓名_x 日期_x 时段_x 交易额_x ... 日期_y 时段_y 交易额_y 柜台_y
工号 ...
1001 张三 20190302 14:00-21:00 600 ... 20190301 9:00-14:00 2000 化妆品
1001 张三 20190302 14:00-21:00 600 ... 20190302 14:00-21:00 600 蔬菜水果
1001 张三 20190302 14:00-21:00 600 ... 20190302 9:00-14:00 1300 化妆品
1001 张三 20190302 9:00-14:00 1300 ... 20190301 9:00-14:00 2000 化妆品
1001 张三 20190302 9:00-14:00 1300 ... 20190302 14:00-21:00 600 蔬菜水果
1001 张三 20190302 9:00-14:00 1300 ... 20190302 9:00-14:00 1300 化妆品
1002 李四 20190302 14:00-21:00 1500 ... 20190301 14:00-21:00 1800 化妆品
1002 李四 20190302 14:00-21:00 1500 ... 20190302 14:00-21:00 1500 化妆品
1006 钱八 20190301 9:00-14:00 850 ... 20190301 9:00-14:00 850 蔬菜水果
'''
函数实现 多个数据求平均值
def average(*args):
print(args)
# (1, 2, 3)
# (1, 2, 3)
print(len(args))
# 3
# 3
print(sum(args, 0.0) / len(args))
average(*[1, 2, 3])
# 2.0
average(1, 2, 3)
# 2.0
使用 * 对传入的列表进行解包
对传入的数据进行分类
def bifurcate(lst, filter):
print(lst)
# ['beep', 'boop', 'foo', 'bar']
print(filter)
# [True, True, False, True]
# 列表名,不是 filter 函数
print(enumerate(lst))
#
print(list(enumerate(lst)))
# [(0, 'beep'), (1, 'boop'), (2, 'foo'), (3, 'bar')]
print([
[x for i, x in enumerate(lst) if filter[i] == True],
[x for i, x in enumerate(lst) if filter[i] == False]
])
'''
filter[i] 主要是对枚举类型前面的索引和传入的 filter 列表进行判断是否重复
'''
bifurcate(['beep', 'boop', 'foo', 'bar'], [True, True, False, True])
进阶 对传入的数据进行分类
def bifurcate_by(lst, fn):
print(lst)
# ['beep', 'boop', 'foo', 'bar']
print(fn('baby'))
# True
print(fn('abc'))
# False
print([
[x for x in lst if fn(x)],
[x for x in lst if not fn(x)]
])
bifurcate_by(
['beep', 'boop', 'foo', 'bar'], lambda x: x[0] == 'b'
)
# [['beep', 'boop', 'bar'], ['foo']]
二进制字符长度
def byte_size(s):
print(s)
#
# Hello World
print(s.encode('utf-8'))
# b'\xf0\x9f\x98\x80'
# b'Hello World'
print(len(s.encode('utf-8')))
# 4
11
byte_size('') # 4
byte_size('Hello World') # 11
将包含_或-的字符串最开始的字母小写,其余的第一个字母大写
from re import sub
def camel(s):
print(s)
# some_database_field_name
# Some label that needs to be camelized
# some-javascript-property
# some-mixed_string with spaces_underscores-and-hyphens
print(sub(r"(_|-)+", " ", s))
# some database field name
# Some label that needs to be camelized
# some javascript property
# some mixed string with spaces underscores and hyphens
print((sub(r"(_|-)+", " ", s)).title())
# Some Database Field Name
# Some Label That Needs To Be Camelized
# Some Javascript Property
# Some Mixed String With Spaces Underscores And Hyphens
print((sub(r"(_|-)+", " ", s)).title().replace(" ", ""))
# SomeDatabaseFieldName
# SomeLabelThatNeedsToBeCamelized
# SomeJavascriptProperty
# SomeMixedStringWithSpacesUnderscoresAndHyphens
s = sub(r"(_|-)+", " ", s).title().replace(" ", "")
print(s)
# SomeDatabaseFieldName
# SomeLabelThatNeedsToBeCamelized
# SomeJavascriptProperty
# SomeMixedStringWithSpacesUnderscoresAndHyphens
print(s[0].lower())
# s
# s
# s
# s
print(s[0].lower() + s[1:])
# someDatabaseFieldName
# someLabelThatNeedsToBeCamelized
# someJavascriptProperty
# someMixedStringWithSpacesUnderscoresAndHyphens
# s = sub(r"(_|-)+", " ", s).title().replace(" ", "")
# print(s[0].lower() + s[1:])
camel('some_database_field_name')
# someDatabaseFieldName
camel('Some label that needs to be camelized')
# someLabelThatNeedsToBeCamelized
camel('some-javascript-property')
# someJavascriptProperty
camel('some-mixed_string with spaces_underscores-and-hyphens')
# someMixedStringWithSpacesUnderscoresAndHyphens
无论传入什么数据都转换为列表
def cast_list(val):
print(val)
# foo
# [1]
# ('foo', 'bar')
print(type(val))
#
#
#
print(isinstance(val,(tuple, list, set, dict)))
# False
# True
# True
print(list(val) if isinstance(val, (tuple, list, set, dict)) else [val])
'''
如果type(val)在 元组,列表,集合,字典 中,则转换为列表
如果不在,也转换为列表
'''
cast_list('foo')
# ['foo']
cast_list([1])
# [1]
cast_list(('foo', 'bar'))
# ['foo', 'bar']
斐波那契数列进一步讨论性能
'''
生成器求斐波那契数列
不需要担心会使用大量资源
'''
def fibon(n):
a = b = 1
for i in range(n):
yield a
# a 为每次生成的数值
a,b = b,a+b
for x in fibon(1000000):
print(x)
'''
使用列表进行斐波那契数列运算,会直接用尽所有的资源
'''
def fibon(n):
a = b = 1
result = []
for i in range(n):
result.append(a)
# a 为每次生成的数值
a,b = b,a+b
return result
for x in fibon(1000000):
print(x)
生成器使用场景:不想在同一时间将所有计算结果都分配到内存中
迭代器和可迭代对象区别
迭代器:
只要定义了 __next__方法,就是一个迭代器
生成器也是一种迭代器,但是只能迭代一次,因为只保存一次值
yield a
next(yield 对象) 进行遍历
可迭代对象:
只要定义了 __iter__ 方法就是一个可迭代对象
列表,字符串,元组,字典和集合都是可迭代对象
使用 iter(可迭代对象) 可以转换为 迭代器
map 函数基本写法
map(需要对对象使用的函数,要操作的对象)
函数可以是自定义的,也可以是内置函数的,或者 lambda 匿名函数
操作的对象多为 可迭代对象
可以是函数名的列表集合


filter 函数基本写法
filter 返回一个符合要求的元素所构成的新列表
filter(函数,可迭代对象)

map 和 filter 混合使用
将 lst_num 中为偶数的取出来进行加2 和 乘2 操作

functools 中的 reduce 函数基本写法
reduce 返回的往往是一整个可迭代对象的 操作结果
reduce(函数,可迭代对象)
注:lambda x,y 两个参数

三元运算符
条件为真执行的语句 if 条件 else 条件为假执行的语句
注:执行的语句,单独包含一个关键字时可能会出错

学装饰器之前必须要了解的四点
装饰器:
通俗理解:修改其他函数的功能的函数
学习装饰器之前,下面的点都要掌握
1.万物皆对象,当将函数名赋值给另一个对象之后
原来的对象删除,不会影响赋值过的新对象
2.函数内定义函数
注:外部函数返回内部函数,内部函数调用外部函数的参数 才可以称为闭包
3.从函数中返回函数,外部定义的函数返回内部定义的函数名
4.将函数作为参数传递给另一个函数




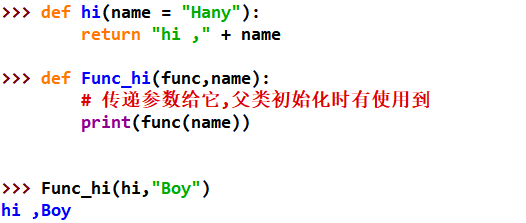
列表推导式,最基本写法
普通写法:
[对象 for 对象 in 可迭代对象]
[对象 for 对象 in 可迭代对象 if 条件]
注: 对象可以进行表达式运算


字典推导式,最基本写法
普通写法
{
对象对 键的操作:对象对 值的操作
for 对象 in 字典 的keys() 或者 values() 或者 items() 方法
}
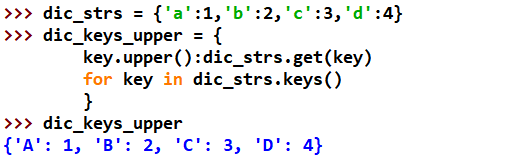

集合推导式,最基本写法
普通写法
{
对象的操作 for 对象 in 可迭代对象
}

状态码
100: ('continue',),
101: ('switching_protocols',),
102: ('processing',),
103: ('checkpoint',),
122: ('uri_too_long', 'request_uri_too_long'),
200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'),
201: ('created',),
202: ('accepted',),
203: ('non_authoritative_info', 'non_authoritative_information'),
204: ('no_content',),
205: ('reset_content', 'reset'),
206: ('partial_content', 'partial'),
207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'),
208: ('already_reported',),
226: ('im_used',),
# 重定向错误.
300: ('multiple_choices',),
301: ('moved_permanently', 'moved', '\\o-'),
302: ('found',),
303: ('see_other', 'other'),
304: ('not_modified',),
305: ('use_proxy',),
306: ('switch_proxy',),
307: ('temporary_redirect', 'temporary_moved', 'temporary'),
308: ('permanent_redirect',
'resume_incomplete', 'resume',), # These 2 to be removed in 3.0
# 客户端错误.
400: ('bad_request', 'bad'),
401: ('unauthorized',),
402: ('payment_required', 'payment'),
403: ('forbidden',),
404: ('not_found', '-o-'),
405: ('method_not_allowed', 'not_allowed'),
406: ('not_acceptable',),
407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'),
408: ('request_timeout', 'timeout'),
409: ('conflict',),
410: ('gone',),
411: ('length_required',),
412: ('precondition_failed', 'precondition'),
413: ('request_entity_too_large',),
414: ('request_uri_too_large',),
415: ('unsupported_media_type', 'unsupported_media', 'media_type'),
416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'),
417: ('expectation_failed',),
418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'),
421: ('misdirected_request',),
422: ('unprocessable_entity', 'unprocessable'),
423: ('locked',),
424: ('failed_dependency', 'dependency'),
425: ('unordered_collection', 'unordered'),
426: ('upgrade_required', 'upgrade'),
428: ('precondition_required', 'precondition'),
429: ('too_many_requests', 'too_many'),
431: ('header_fields_too_large', 'fields_too_large'),
444: ('no_response', 'none'),
449: ('retry_with', 'retry'),
450: ('blocked_by_windows_parental_controls', 'parental_controls'),
451: ('unavailable_for_legal_reasons', 'legal_reasons'),
499: ('client_closed_request',),
# 服务器错误.
500: ('internal_server_error', 'server_error', '/o\\', '✗'),
501: ('not_implemented',),
502: ('bad_gateway',),
503: ('service_unavailable', 'unavailable'),
504: ('gateway_timeout',),
505: ('http_version_not_supported', 'http_version'),
506: ('variant_also_negotiates',),
507: ('insufficient_storage',),
509: ('bandwidth_limit_exceeded', 'bandwidth'),
510: ('not_extended',),
511: ('network_authentication_required', 'network_auth', 'network_authentication'),
爬虫流程复习3
111.requests.get 方法的流程
r = requests.get('https://www.baidu.com/').content.decode('utf-8')
从状态码到 二进制码到 utf-8 编码
112.对 soup 对象进行美化
html = soup.prettify()
百度一下,你就知道
113.将内容 string 化
html.xpath('string(//*[@id="cnblogs_post_body"])')
114.获取属性
soup.p['name']
115.嵌套选择
soup.head.title.string
116.获取父节点和祖孙节点
soup.a.parent
list(enumerate(soup.a.parents))
117.获取兄弟节点
soup.a.next_siblings
list(enumerate(soup.a.next_siblings))
soup.a.previous_siblings
list(enumerate(soup.a.previous_siblings))
118.按照特定值查找标签
查找 id 为 list-1 的标签
soup.find_all(attrs={'id': 'list-1'})
soup.find_all(id='list-1')
119.返回父节点
find_parents()返回所有祖先节点
find_parent()返回直接父节点
120.返回后面兄弟节点
find_next_siblings()返回后面所有兄弟节点
find_next_sibling()返回后面第一个兄弟节点。
121.返回前面兄弟节点
find_previous_siblings()返回前面所有兄弟节点
find_previous_sibling()返回前面第一个兄弟节点。
122.返回节点后符合条件的节点
find_all_next()返回节点后所有符合条件的节点
find_next()返回第一个符合条件的节点
123.返回节点前符合条件的节点
find_all_previous()返回节点前所有符合条件的节点
find_previous()返回第一个符合条件的节点
124.requests 的请求方式
requests.post(url)
requests.put(url)
requests.delete(url)
requests.head(url)
requests.options(url)
125.GET请求
response = requests.get(url)
print(response.text)
126.解析 json
response.json()
json.loads(response.text)
127.发送 post 请求
response = requests.post(url, data=data, headers=headers)
response.json()
128.文件上传
在 post 方法内部添加参数 files 字典参数
import requests
files = {'file': open('favicon.ico', 'rb')}
response = requests.post("http://httpbin.org/post", files=files)
print(response.text)
129.获取 cookie
response.cookie
返回值是 字典对象
for key, value in response.cookies.items():
print(key + '=' + value)
130.模拟登录
requests.get('http://httpbin.org/cookies/set/number/123456789')
response = requests.get('http://httpbin.org/cookies')
131.带有 Session 的登录
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
response = s.get('http://httpbin.org/cookies')
132.证书验证
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn', verify=False)
response = requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key'))
133.超时设置
from requests.exceptions import ReadTimeout
response = requests.get("http://httpbin.org/get", timeout = 0.5)
response = urllib.request.urlopen(url, timeout=1)
134.认证设置
from requests.auth import HTTPBasicAuth
r = requests.get('http://120.27.34.24:9001', auth=HTTPBasicAuth('user', '123'))
r = requests.get('http://120.27.34.24:9001', auth=('user', '123'))
135.异常处理
超时 ReadTimeout
连接出错 ConnectionError
错误 RequestException
136.URL 解析
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
result = urlparse('www.baidu.com/index.html;user?id=5#comment', scheme='https')
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment',allow_fragments=False)
136.urllib.parse.urlunparse
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))
http://www.baidu.com/index.html;user?a=6#comment
137.合并 url
urllib.parse.urljoin
urljoin('http://www.baidu.com', 'FAQ.html')
http://www.baidu.com/FAQ.html
urljoin('www.baidu.com#comment', '?category=2')
www.baidu.com?category=2
由于思维导图过大,不能全部截图进来,所以复制了文字,进行导入
注释导入xxx 是对上一行的解释:
爬虫基础
导包
import requests
from urllib.parse import urlencode
# 导入解析模块
from urllib.request import Request
# Request 请求
from urllib.parse import quote
# 使用 quote 解析中文
from urllib.request import urlopen
# urlopen 打开
from fake_useragent import UserAgent
# 导入 ua
import ssl
# 使用 ssl 忽略证书
from urllib.request import HTTPHandler
from urllib.request import build_opener
# 导入 build_opener
from urllib.request import ProxyHandler
# 导入 私人代理
from http.cookiejar import MozillaCookieJar
# 导入 cookie , 从 http.cookiejar 中
from urllib.error import URLError
# 捕捉 URL 异常
from lxml import etree
# 导入 etree,使用 xpath 进行解析
import http.cookiejar
# 导入 cookiejar
import json
# 导入 json
import jsonpath
# 导入 jsonpath
from selenium import webdriver
# 导入外部驱动
from selenium.webdriver.common.keys import Keys
# 要想调用键盘按键操作需要引入keys包
headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
}
headers = {
'User-Agent':UserAgent().random
}
from fake_useragent import UserAgent
headers = {
'User-Agent':UserAgent().chrome
}
使用 ua 列表
user_agent = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
]
ua = random.choice(user_agent)
headers = {'User-Agent':ua}
url
url = 'https://www.baidu.com/'
# 要进行访问的 URL
url = 'https://www.baidu.com/s?wd={}'.format(quote('瀚阳的小驿站'))
args = {
'wd':"Hany驿站",
"ie":"utf-8"
}
url = 'https://www.baidu.com/s?wd={}'.format(urlencode(args))
获取 response
get 请求
params = {
'wd':'Python'
}
response = requests.get(url,params = params,headers = headers)
params = {
'wd':'ip'
}
proxies = {
'http':'代理'
# "http":"http://用户名:密码@120.27.224.41:16818"
}
response = requests.get(url, params=params, headers=headers, proxies=proxies)
response = requests.get(url,headers = headers)
response = requests.get(url,verify = False,headers = headers)
Request 请求
form_data = {
'user':'账号',
'password':'密码'
}
f_data = urlencode(form_data)
request = Request(url = url,headers = headers,data = f_data)
handler = HTTPCookieProcessor()
opener = build_opener(handler)
response = opener.open(request)
request = Request(url = url,headers = headers)
response = urlopen(request)
request = Request(url,headers=headers)
handler = HTTPHandler()
# 构建 handler
opener = build_opener(handler)
# 将 handler 添加到 build_opener中
response = opener.open(request)
request = urllib.request.Request(url)
request.add_header('User-Agent', ua)
context = ssl._create_unverified_context()
reponse = urllib.request.urlopen(request, context = context)
response = urllib.request.urlopen(request, data=formdata)
# 构建请求体
formdata = {
'from':'en',
'to':'zh',
'query':word,
'transtype':'enter',
'simple_means_flag':'3'
}
# 将formdata进行urlencode编码,并且转化为bytes类型
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
request = urllib.request.Request(url, headers=headers)
# 创建一个HTTPHandler对象,用来处理http请求
http_handler = urllib.request.HTTPHandler()
# 构建一个HTTPHandler 处理器对象,支持处理HTTPS请求
# 通过build_opener,创建支持http请求的opener对象
opener = urllib.request.build_opener(http_handler)
# 创建请求对象
# 抓取https,如果开启fiddler,则会报证书错误
# 不开启fiddler,抓取https,得不到百度网页,
request = urllib.request.Request('http://www.baidu.com/')
# 调用opener对象的open方法,发送http请求
reponse = opener.open(request)
使用 proxies 代理进行请求
proxies = {
'http':'代理'
# "http":"http://用户名:密码@120.27.224.41:16818"
}
response = requests.get(url,headers = headers,proxies = proxies)
request = Request(url,headers = headers)
handler = ProxyHandler({"http":"110.243.3.207"})
# 代理网址
opener = build_opener(handler)
response = opener.open(request)
post 请求
data = {
'user':'用户名',
'password':'密码'
}
response = requests.post(url,headers = headers,data = data)
# 使用 data 传递参数
使用 session
session = requests.Session()
get 请求
session.get(info_url,headers = headers)
post 请求
params = {
'user':'用户名',
'password':'密码'
}
session.post(url,headers = headers,data = params)
使用 ssl 忽略证书
context = ssl._create_unverified_context()
response = urlopen(request,context = context)
使用 cookie
form_data = {
'user':'用户名',
'password':'密码'
}
f_data = urlencode(form_data).encode()
request = Request(url = login_url,headers = headers,data = f_data)
cookie_jar = MozillaCookieJar()
handler = HTTPCookieProcessor(cookie_jar)
opener = build_opener(handler)
response = opener.open(request)
cookie_jar.save('cookie.txt',ignore_discard=True,ignore_expires=True)
# 失效或者过期依旧进行保存
request = Request(url = info_url,headers = headers)
cookie_jar = MozillaCookieJar()
cookie_jar.load('cookie.txt',ignore_expires=True,ignore_discard=True)
handler = HTTPCookieProcessor(cookie_jar)
opener = build_opener(handler)
response = opener.open(request)
设置时间戳
response = requests.get(url,timeout = 0.001)
# 设置时间戳
cookie = http.cookiejar.CookieJar()
# 通过CookieJar创建一个cookie对象,用来保存cookie值
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
# 通过HTTPCookieProcessor构建一个处理器对象,用来处理cookie
opener = urllib.request.build_opener(cookie_handler)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer':'https://passport.weibo.cn/signin/login?entry=mweibo&r=http%3A%2F%2Fweibo.cn%2F&backTitle=%CE%A2%B2%A9&vt=',
'Content-Type':'application/x-www-form-urlencoded',
# 'Host': 'passport.weibo.cn',
# 'Connection': 'keep-alive',
# 'Content-Length': '173',
# 'Origin':'https://passport.weibo.cn',
# 'Accept': '*/*',
}
url = 'https://passport.weibo.cn/sso/login'
formdata = {
'username':'17701256561',
'password':'2630030lzb',
'savestate':'1',
'r':'http://weibo.cn/',
'ec':'0',
'pagerefer':'',
'entry':'mweibo',
'wentry':'',
'loginfrom':'',
'client_id':'',
'code':'',
'qq':'',
'mainpageflag':'1',
'hff':'',
'hfp':''
}
formdata = urllib.parse.urlencode(formdata).encode()
# post表单里面的数据要转化为bytes类型,才能发送过去
request = urllib.request.Request(url, headers=headers)
response = opener.open(request, data=formdata)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer':'https://coding.net/login',
'Content-Type':'application/x-www-form-urlencoded',
}
post_url = 'https://coding.net/api/v2/account/login'
data = {
'account': 'wolfcode',
'password': '7c4a8d09ca3762af61e59520943dc26494f8941b',
'remember_me': 'false'
}
data = urllib.parse.urlencode(data).encode()
# 向指定的post地址发送登录请求
request = urllib.request.Request(post_url, headers=headers)
response = opener.open(request, data=data)
# 通过opener登录
# 登录成功之后,通过opener打开其他地址即可
response 属性和方法
response.getcode()
# 获取 HTTP 响应码 200
response.geturl()
# 获取访问的网址信息
response.info()
# 获取服务器响应的HTTP请求头
info = response.read()
# 读取内容
info.decode()
# 打印内容
response.read().decode()
print(request.get_header("User-agent"))
# 获取请求头信息
response.text
# 获取内容
response.encoding = 'utf-8'
response.json()
# 获取响应信息(json 格式字符串)
response.request.headers
# 请求头内容
response.cookie
# 获取 cookie
response.readline()
# 获取一行信息
response.status
# 查看状态码
正则表达式
$通配符,匹配字符串结尾
ret = re.match("[\w]{4,20}@163\.com$", email)
# \w 匹配字母或数字
# {4,20}匹配前一个字符4到20次
re.match匹配字符(仅匹配开头)
ret = re.findall(r"\d+","Hany.age = 22, python.version = 3.7.5")
# 输出全部找到的结果 \d + 一次或多次
ret = re.search(r"\d+",'阅读次数为:9999')
# 只要找到规则即可,从头到尾
re中匹配 [ ] 中列举的字符
ret = re.match("[hH]","hello Python")
# 大小写h都可以的情况
ret = re.match("[0-3,5-9]Hello Python","7Hello Python")
# 匹配0到3 5到9的数字
re中匹配不是以4,7结尾的手机号码
ret = re.match("1\d{9}[0-3,5-6,8-9]", tel)
re中匹配中奖号码
import re
# 匹配中奖号码
str2 = '17711602423'
pattern = re.compile('^(1[3578]\d)(\d{4})(\d{4})$')
print(pattern.sub(r'\1****\3',str2))
# r 字符串编码转化
'''177****2423'''
re中匹配中文字符
pattern = re.compile('[\u4e00-\u9fa5]')
strs = '你好 Hello hany'
print(pattern.findall(strs))
# ['你', '好']
pattern = re.compile('[\u4e00-\u9fa5]+')
print(pattern.findall(strs))
# ['你好']
re中将括号中字符作为一个分组
ret = re.match("\w{4,20}@163\.com", "[email protected]")
print(ret.group()) # [email protected]
re中对分组起别名
ret = re.match(r"<(?P\w*)><(?P\w*)>.*", "www.itcast.cn
")
print(ret.group())
www.itcast.cn
re中匹配数字
# 使用\d进行匹配
ret = re.match("嫦娥\d号","嫦娥1号发射成功")
print(ret.group())
re中匹配左右任意一个表达式
ret = re.match("[1-9]?\d$|100","78")
print(ret.group()) # 78
re中匹配多个字符 问号
ret = re.match("[1-9]?\d[1-9]","33")
print(ret.group())
# 33
ret = re.match("[1-9]?\d","33")
print(ret.group())
# 33
re中匹配多个字符 星号
ret = re.match("[A-Z][a-z]*","MnnM")
print(ret.group())
# Mnn
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
# Aabcdef
re中匹配多个字符 加号
import re
#匹配前一个字符出现1次或无限次
names = ["name1", "_name", "2_name", "__name__"]
for name in names:
ret = re.match("[a-zA-Z_]+[\w]*",name)
if ret:
print("变量名 %s 符合要求" % ret.group())
else:
print("变量名 %s 非法" % name)
变量名 name1 符合要求
变量名 _name 符合要求
变量名 2_name 非法
变量名 __name__ 符合要求
re中引用分组匹配字符串
# 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
ret = re.match(r"<([a-zA-Z]*)>\w*", "hh")
# 匹配第一个规则
print(ret.group())
# hh
ret = re.match(r"<(\w*)><(\w*)>.*", label)
re中的贪婪和非贪婪
ret = re.match(r"aa(\d+)","aa2343ddd")
# 尽量多的匹配字符
print(ret.group())
# aa2343
# 使用? 将re贪婪转换为非贪婪
ret = re.match(r"aa(\d+?)","aa2343ddd")
# 只输出一个数字
print(ret.group())
# aa2
re使用split切割字符串
str1 = 'one,two,three,four'
pattern = re.compile(',')
# 按照,将string分割后返回
print(pattern.split(str1))
# ['one', 'two', 'three', 'four']
str2 = 'one1two2three3four'
print(re.split('\d+',str2))
# ['one', 'two', 'three', 'four']
re匹配中subn,进行替换并返回替换次数
pattern = re.compile('\d+')
strs = 'one1two2three3four'
print(pattern.subn('-',strs))
# ('one-two-three-four', 3) 3为替换的次数
re匹配中sub将匹配到的数据进行替换
pattern = re.compile('\d')
str1 = 'one1two2three3four'
print(pattern.sub('-',str1))
# one-two-three-four
print(re.sub('\d','-',str1))
# one-two-three-four
获取图片
src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg"
ret = re.search(r"https://.*?\.jpg", src)
print(ret.group())
https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg
re匹配前一个字符出现m次
res = re.compile('[a-zA-Z]{1}')
strs = '123abc456'
print(re.search(res,strs).group( ))
# a
res = re.compile('[a-zA-Z]{1}')
strs = '123abc456'
print(re.findall(res,strs)) #findall返回列表元素对象不具有group函数
# ['a', 'b', 'c']
分组 group
strs = 'hello 123,world 456'
pattern = re.compile('(\w+) (\d+)')
for i in pattern.finditer(strs):
print(i.group(0))
print(i.group(1))
print(i.group(2))#当存在第二个分组时
hello 123
hello
123
world 456
world
456
print(pattern.sub(r'\2 \1',strs))
# 先输出第二组,后输出第一组
# 123 hello,456 world
print(pattern.sub(r'\1 \2',strs))
# 先输出第一组,后输出第二组
# hello 123,world 456
忽略警告
requests.packages.urllib3.disable_warnings()
quote 编码
urllib.parse.quote() 除了-._/09AZaz 都会编码
urllib.parse.quote_plus() 还会编码 /
url = 'kw=中国'
urllib.parse.quote(url)
urllib.parse.quote_plus(url)
保存网址内容为某个文件格式
urllib.request.urlretrieve(url, '名称.后缀名')
json
# 将字节码解码为utf8的字符串
data = data.decode('utf-8')
# 将json格式的字符串转化为json对象
obj = json.loads(data)
# 禁用ascii之后,写入数据,就是正确的
html = json.dumps(obj, ensure_ascii=False)
# 将json对象通过str函数强制转化为字符串然后按照utf-8格式写入,这样就可以写成中文汉字了
# 写文件的时候要指定encoding,否则会按照系统的编码集写文件
loads
引号中为列表
string = '[1, 2, 3, 4, "haha"]'
json.loads(string)
引号中为字典
str_dict = '{"name":"goudan", "age":100, "height":180}'
json.loads(str_dict)
obj = json.load(open('jsontest.json', encoding='utf-8'))
# load 读取文件中json形式的字符串 转化成python对象
dumps
json.dumps() 序列化时默认使用的ascii编码
# 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
json.dump(str_dict, open('jsontest.json', 'w', encoding='utf-8'), ensure_ascii=False)
# dump将对象序列化之后写入文件
load
obj = json.load(open('book.json', encoding='utf-8'))
book = jsonpath.jsonpath(obj, '$..book')
保存文件
# 得到html为bytes类型
html = response.read()
# 将bytes类型转化为字符串类型
html = html.decode('utf-8')
# 输出文件时,需要将bytes类型使用wb写入文件,否则出错
fp = open('baidu.html', 'w')
fp.write(html)
fp.close()
html = reponse.read()
with open(filename, 'wb') as f:
f.write(html)
# 通过read读取过来为字节码
data = response.read()
# 将字节码解码为utf8的字符串
data = data.decode('utf-8')
# 将json格式的字符串转化为json对象
obj = json.loads(data)
# 禁用ascii之后,写入数据,就是正确的
html = json.dumps(obj, ensure_ascii=False)
# 将json对象通过str函数强制转化为字符串然后按照utf-8格式写入,这样就可以写成中文汉字了
# 写文件的时候要指定encoding,否则会按照系统的编码集写文件
with open('json.txt', 'w', encoding='utf-8') as f:
f.write(html)
etree
html_tree = etree.parse('文件名.html')
# 通过读取文件得到tree对象
xpath 用法
result = html_tree.xpath('//li')
# 获取所有的li标签
result = html_tree.xpath('//li/@class')
# 获取所有li标签的class属性
result = html_tree.xpath('//li/a[@href="link1.html"]')
# 获取所有li下面a中属性href为link1.html的a
result = html_tree.xpath('//li[last()]/a/@href')
# 获取最后一个li的a里面的href,结果为一个字符串
result = html_tree.xpath('//*[@class="mimi"]')
# 获取class为mimi的节点
result = html_tree.xpath('//li[@class="popo"]/a')
# 符合条件的所有li里面的所有a节点
result = html_tree.xpath('//li[@class="popo"]/a/text()')
# 符合条件的所有li里面的所有a节点的内容
result = html_tree.xpath('//li[@class="popo"]/a')[0].text
# 符合条件的所有li里面的 a节点的内容
xpath使用后,加上 .extract()
只有一个元素可以使用 .extract_first()
tostring
etree.tostring(result[0]).decode('utf-8')
# 将tree对象转化为字符串
html = etree.tostring(html_tree)
print(html.decode('utf-8'))
etree.HTML
html_tree = etree.HTML('文件名.html')
# 将html字符串解析为文档类型
html_bytes = response.read()
html_tree = etree.HTML(html_bytes.decode('utf-8'))
response = requests.get(url,headers = headers)
e = etree.HTML(response.text)
img_path = '//article//img/@src'
img_urls = e.xpath(img_path)
string(.) 方法
xpath获取到的对象列表中的某一个元素
ret = score.xpath('string(.)').extract()[0]
BeautifulSoup
获取 soup
soup = BeautifulSoup(open('文件名.html', encoding='utf-8'), 'lxml')
soup = BeautifulSoup(driver.page_source, 'lxml')
# 在所有内容中第一个符合要求的标签
soup.title
soup.a
soup.ul
a_tag = soup.a
a_tag.name
# 获得标签名字
a_tag.attrs
# 得到标签的所有属性,字典类型
a_tag.get('href')
# 获取 href
a_tag['title']
# 查看 a 标签的 title 值
a_tag.string
# 获取 a 标签的内容
获取标签下的子节点
contents
soup.div.contents
# 获取 div 标签下所有子节点
soup.head.contents[1]
# 获取 div 下第二个子节点
children
# .children属性得到的是一个生成器,可以遍历生成器
# 遍历生成器打印对象
for child in soup.body.children:
print(child)
# 只遍历直接子节点
for child in soup.div.children:
print(child)
# descendants会递归遍历子孙节点
for child in soup.div.descendants:
print(child)
find_all 方法,查找所有的内容
soup.find_all(re.compile('^b'))
# 传入正则表达式 找到所有以b开头的标签
soup.find_all(['a', 'b'])
# 传入列表 找到所有的a标签和b标签
select 方法
soup.select('a')
# 通过类名
soup.select('.aa')
# 通过id名
soup.select('#wangyi')
# 组合查找
soup.select('div .la')
# 直接层级
soup.select('.div > .la')
# 根据属性查找
soup.select('input[class="haha"]')
# 查找 input 标签下 class 为 haha 的 标签
soup.select('.la')[0].get_text()
# 找到节点之后获取内容 通过get_text()方法,并且记得添加下标
jsonpath
jsonpath 方法
obj = json.load(open('book.json', encoding='utf-8'))
book = jsonpath.jsonpath(obj, '$..book')
# 所有book
authors = jsonpath.jsonpath(obj, '$..book..author')
# 所有book中的所有作者
# book中的前两本书 '$..book[:2]'
# book中的最后两本书 '$..book[-2:]'
book = jsonpath.jsonpath(obj, '$..book[0,1]')
# 获取前面的两本书
book = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]')
# 所有book中,有属性isbn的书籍
book = jsonpath.jsonpath(obj, '$.store.book[?(@.price<10)]')
# 所有book中,价格小于10的书籍
xpath和jsonpath
补充资料
day01
http
状态码
协议简介
fiddler
简介
环境安装
类型
问题
day02
day03
day04
常用函数
webdriver 方法
设置 driver
driver = webdriver.PhantomJS()
driver = webdriver.PhantomJS(executable_path="./phantomjs")
# 如果没有在环境变量指定PhantomJS位置
driver 方法
text
# 获取标签内容
get_attribute('href')
# 获取标签属性
获取id标签值
element = driver.find_element_by_id("passwd-id")
driver.find_element_by_id('kw').send_keys('中国')
driver.find_element_by_id('su').click()
# 点击百度一下
yanzheng = input('请输入验证码:')
driver.find_element_by_id('captcha_field').send_keys(yanzheng)
for x in range(1, 3):
driver.find_element_by_id('loadMore').click()
time.sleep(3)
driver.save_screenshot(str(x) + '.png')
获取name标签值
element = driver.find_element_by_name("user-name")
获取标签名值
element = driver.find_element_by_tag_name("input")
可以通过XPath来匹配
element = driver.find_element_by_xpath("//input[@id='passwd-id']")
通过css来匹配
element = driver.find_element_by_css_selector("#food span.dairy.aged")
获取当前url
driver.current_url
关闭浏览器
driver.quit()
driver.save_screenshot('图片名.png')
# 保存当前网址为一张图片
driver.execute_script(js)
# 调用js方法,同时执行javascript脚本
实例
小说 三寸人间
list 和 [ ] 的功能不相同
对于一个对象:
list(对象) 可以进行强制转换
[对象] 不能够进行强制转换,只是在外围加上 [ ]

列表推导式中相同

数据库设计基础知识
流程:
1.用户需求分析
2.概念结构设计
3.逻辑结构设计(规范化)
4.数据库的物理结构设计
E-R 模型 -> 关系数据模型步骤
①为每个实体建立-张表
②为每个表选择一一个主键(建议添加一-个没有实际意义的字段作为主键)
③使用外键表示实体间关系
④定义约束条件
⑤评价关系的质量,并进行必要的改进(关于范式等知识请参考其他数据库书籍)
⑥为每个字段选择合适的数据类型、属性和索引等
关系:
一对一
将 一 方的主键放入到 另一方 中
一对多
将 一 方的主键 放到 多方 中
多对多
两边都将主键拿出,放入到一个新的表中
最少满足第三范式
定义属性 类型 索引
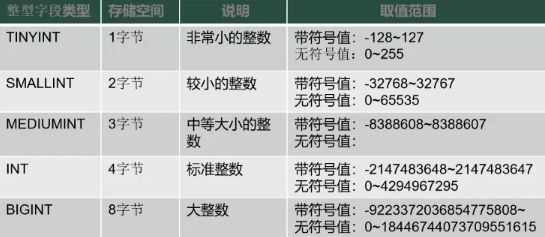
注:
1.当超出范围时,取类型的最大值
2.当无符号数时,给出负数,赋值为 0
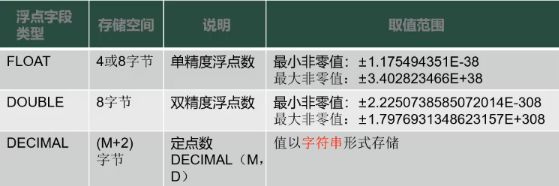
字符串类型
可存储图像或声音之类的二进制数据
可存储用 gzip 压缩的数据
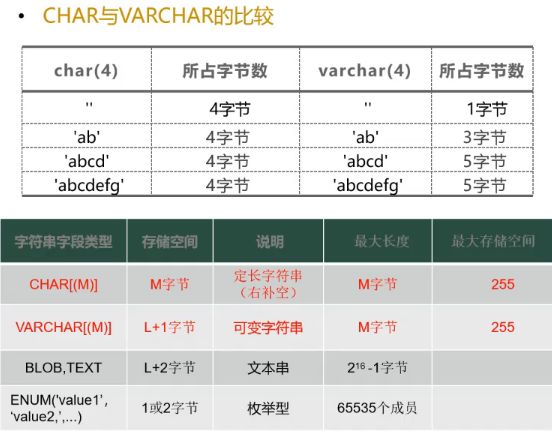
char 使用环境(推荐)
如果字段值长度固定或者相差不多(如性别)
数据库要进行大量字符运算(如比较、排序等)
varchar
如果字段长度变化较大的(如文章标题)
BLOB保存二进制数据(相片、 电影、压缩包)
ENUM('','') 枚举类型


字段属性
UNSIGNED 不允许字段出现负数,可以使最大允许长度增加
ZEROFILL 用零填充,数值之前自动用0补齐不足的位数,只用于设置数值类型
auto_ increment 自动增量属性,默认从整数1开始递增,步长为1
可以指定自增的初始值 auto_ increment=n
如果将 NULL 添加到一个auto increment列,MySQL将自动生成下一个序列编号
DEFAULT 指定一个默认值
索引
确保数据的唯一性
优化查询
对索引字段中文本的搜索进行优化
使用 you-get 下载免费电影或电视剧
安装 you-get 和 ffmpeg
ffmpeg 主要是下载之后,合并音频和视频
pip install you-get -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip install ffmpeg -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
you-get 下载指令:
you-get 视频网址
此处以 完美关系第二集为例:
https://v.qq.com/x/cover/mzc0020095tf0wm/s00338f1hq8.html?ptag=qqbrowser
注:
此下载方式会下载到 C:\Users\lenovo 目录下
选择下载路径使用 -o 文件夹位置
you-get -o + 文件要保存到的位置 +视频链接

python 连接 mysql 的三种驱动
连接 mysql 驱动
mysq1-client
python2,3都能直接使用
对myaq1安装有要求,必须指定位置存在 配置文件
python-mysql
python3 不支持
pymysql
python2, python3都支持
还可以伪装成前面的库
个人在使用 import mysql.connector
使用 pip 命令来安装 mysql-connector:
python -m pip install mysql-connector
创建数据库连接
可以使用以下代码来连接数据库:
import mysql.connector
mydb = mysql.connector.connect(
host="localhost", # 数据库主机地址
user="yourusername", # 数据库用户名
passwd="yourpassword" # 数据库密码
)
print(mydb)
创建数据库
创建数据库使用 "CREATE DATABASE" 语句,以下创建一个名为 runoob_db 的数据库:
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456"
)
mycursor = mydb.cursor()
mycursor.execute("CREATE DATABASE runoob_db")
创建数据表
创建数据表使用 "CREATE TABLE" 语句,创建数据表前,需要确保数据库已存在,以下创建一个名为 sites 的数据表:
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database="website"
)
mycursor = mydb.cursor()
mycursor.execute("CREATE TABLE sites (name VARCHAR(255), url VARCHAR(255))")
主键设置
mycursor.execute("ALTER TABLE sites ADD COLUMN id INT AUTO_INCREMENT PRIMARY KEY")
mycursor.execute("CREATE TABLE sites (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255), url VARCHAR(255))")
插入数据
sql = "INSERT INTO sites (字段名, 字段名) VALUES (%s, %s)"
val = ("字段值", "字段值")
mycursor.execute(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
mycursor = mydb.cursor()
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = ("hany", "值1")
mycursor.execute(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
批量插入数据
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = [
('Google', 'https://www.google.com'),
('Github', 'https://www.github.com'),
('Taobao', 'https://www.taobao.com'),
('stackoverflow', 'https://www.stackoverflow.com/')
]
mycursor.executemany(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
查询全部数据
mycursor = mydb.cursor()
mycursor.execute("SELECT * FROM sites")
myresult = mycursor.fetchall() # fetchall() 获取所有记录
for x in myresult:
print(x)
查询一条数据
myresult = mycursor.fetchone()
关于查询的 sql 语句
sql = "SELECT * FROM sites WHERE name ='RUNOOB'"
sql = "SELECT * FROM sites WHERE url LIKE '%oo%'"
sql = "SELECT * FROM sites WHERE name = %s"
sql = "SELECT * FROM sites ORDER BY name"
sql = "SELECT * FROM sites ORDER BY name DESC"
mycursor.execute("SELECT * FROM sites LIMIT 3")
mycursor.execute("SELECT * FROM sites LIMIT 3 OFFSET 1")
注: # 0 为 第一条,1 为第二条,以此类推
删除记录
sql = "DELETE FROM sites WHERE name = 'stackoverflow'"
mycursor.execute(sql)
sql = "DELETE FROM sites WHERE name = %s"
na = ("stackoverflow", )
mycursor.execute(sql, na)
删除表
sql = "DROP TABLE IF EXISTS sites" # 删除数据表 sites mycursor.execute(sql)
更新记录
sql = "UPDATE sites SET name = 'ZH' WHERE name = 'Zhihu'"
mycursor.execute(sql)
sql = "UPDATE sites SET name = %s WHERE name = %s"
val = ("Zhihu", "ZH")
mycursor.execute(sql, val)
mydb.commit()
pandas_DateFrame的创建
# DateFrame 的创建,包含部分:index , column , values
import numpy as np
import pandas as pd
# 创建一个 DataFrame 对象
dataframe = pd.DataFrame(np.random.randint(1,20,(5,3)),
index = range(5),
columns = ['A','B','C'])
'''
A B C
0 17 9 19
1 14 5 8
2 7 18 13
3 13 16 2
4 18 6 5
'''
# 索引为时间序列
dataframe2 = pd.DataFrame(np.random.randint(5,15,(9,3)),
index = pd.date_range(start = '202003211126',
end = '202003212000',
freq = 'H'),
columns = ['Pandas','爬虫','比赛'])
'''
Pandas 爬虫 比赛
2020-03-21 11:26:00 8 10 8
2020-03-21 12:26:00 9 14 9
2020-03-21 13:26:00 9 5 13
2020-03-21 14:26:00 9 7 7
2020-03-21 15:26:00 11 10 14
2020-03-21 16:26:00 12 7 10
2020-03-21 17:26:00 11 11 13
2020-03-21 18:26:00 8 13 8
2020-03-21 19:26:00 7 7 13
'''
# 使用字典进行创建
dataframe3 = pd.DataFrame({'语文':[87,79,67,92],
'数学':[93,89,80,77],
'英语':[88,95,76,77]},
index = ['张三','李四','王五','赵六'])
'''
语文 数学 英语
张三 87 93 88
李四 79 89 95
王五 67 80 76
赵六 92 77 77
'''
# 创建时自动扩充
dataframe4 = pd.DataFrame({'A':range(5,10),'B':3})
'''
A B
0 5 3
1 6 3
2 7 3
3 8 3
4 9 3
'''
pandas_一维数组与常用操作
# 一维数组与常用操作
import pandas as pd
# 设置输出结果列对齐
pd.set_option('display.unicode.ambiguous_as_wide',True)
pd.set_option('display.unicode.east_asian_width',True)
# 创建 从 0 开始的非负整数索引
s1 = pd.Series(range(1,20,5))
'''
0 1
1 6
2 11
3 16
dtype: int64
'''
# 使用字典创建 Series 字典的键作为索引
s2 = pd.Series({'语文':95,'数学':98,'Python':100,'物理':97,'化学':99})
'''
语文 95
数学 98
Python 100
物理 97
化学 99
dtype: int64
'''
# 使用索引下标进行修改
# 修改 Series 对象的值
s1[3] = -17
'''
0 1
1 6
2 11
3 -17
dtype: int64
'''
s2['语文'] = 94
'''
语文 94
数学 98
Python 100
物理 97
化学 99
dtype: int64
'''
# 查看 s1 的绝对值
abs(s1)
'''
0 1
1 6
2 11
3 17
dtype: int64
'''
# 将 s1 所有的值都加 5、使用加法时,对所有元素都进行
s1 + 5
'''
0 6
1 11
2 16
3 -12
dtype: int64
'''
# 在 s1 的索引下标前加入参数值
s1.add_prefix(2)
'''
20 1
21 6
22 11
23 -17
dtype: int64
'''
# s2 数据的直方图
s2.hist()
# 每行索引后面加上 hany
s2.add_suffix('hany')
'''
语文hany 94
数学hany 98
Pythonhany 100
物理hany 97
化学hany 99
dtype: int64
'''
# 查看 s2 中最大值的索引
s2.argmax()
# 'Python'
# 查看 s2 的值是否在指定区间内
s2.between(90,100,inclusive = True)
'''
语文 True
数学 True
Python True
物理 True
化学 True
dtype: bool
'''
# 查看 s2 中 97 分以上的数据
s2[s2 > 97]
'''
数学 98
Python 100
化学 99
dtype: int64
'''
# 查看 s2 中大于中值的数据
s2[s2 > s2.median()]
'''
Python 100
化学 99
dtype: int64
'''
# s2 与数字之间的运算,开平方 * 10 保留一位小数
round((s2**0.5)*10,1)
'''
语文 97.0
数学 99.0
Python 100.0
物理 98.5
化学 99.5
dtype: float64
'''
# s2 的中值
s2.median()
# 98.0
# s2 中最小的两个数
s2.nsmallest(2)
'''
语文 94
物理 97
dtype: int64
'''
# s2 中最大的两个数
s2.nlargest(2)
'''
Python 100
化学 99
dtype: int64
'''
# Series 对象之间的运算,对相同索引进行计算,不是相同索引的使用 NaN
pd.Series(range(5)) + pd.Series(range(5,10))
'''
0 5
1 7
2 9
3 11
4 13
dtype: int64
'''
# 对 Series 对象使用匿名函数
pd.Series(range(5)).pipe(lambda x,y,z :(x**y)%z,2,5)
'''
0 0
1 1
2 4
3 4
4 1
dtype: int64
'''
pd.Series(range(5)).pipe(lambda x:x+3)
'''
0 3
1 4
2 5
3 6
4 7
dtype: int64
'''
pd.Series(range(5)).pipe(lambda x:x+3).pipe(lambda x:x*3)
'''
0 9
1 12
2 15
3 18
4 21
dtype: int64
'''
# 对 Series 对象使用匿名函数
pd.Series(range(5)).apply(lambda x:x+3)
'''
0 3
1 4
2 5
3 6
4 7
dtype: int64
'''
# 查看标准差
pd.Series(range(0,5)).std()
# 1.5811388300841898
# 查看无偏方差
pd.Series(range(0,5)).var()
# 2.5
# 查看无偏标准差
pd.Series(range(0,5)).sem()
# 0.7071067811865476
# 查看是否存在等价于 True 的值
any(pd.Series([3,0,True]))
# True
# 查看是否所有的值都等价于 True
all(pd.Series([3,0,True]))
# False
pandas_使用属性接口实现高级功能
C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx
这个文档自己创建就可以,以下几篇文章仅作为参考
import pandas as pd
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',usecols = ['日期','交易额'])
dff = copy.deepcopy(data)
# 查看周几
dff['日期'] = pd.to_datetime(data['日期']).dt.weekday_name
'''
日期 交易额
0 Thursday 2000
1 Thursday 1800
2 Thursday 800
'''
# 按照周几进行分组,查看交易的平均值
dff = dff.groupby('日期').mean().apply(round)
dff.index.name = '周几'
dff[:3]
'''
交易额
周几
Thursday 1024.0
'''
# dff = copy.deepcopy(data)
# 使用正则规则查看月份日期
# dff['日期'] = dff.日期.str.extract(r'(\d{4}-\d{2})')
# dff[:5]
# 按照日 进行分组查看交易的平均值 -1 表示倒数第一个
# data.groupby(data.日期.str.__getitem__(-1)).mean().apply(round)
# 查看日期尾数为 1 的数据
# data[data.日期.str.endswith('1')][:12]
# 查看日期尾数为 12 的交易数据,slice 为切片 (-2) 表示倒数两个
# data[data.日期.str.slice(-2) == '12']
# 查看日期中月份或天数包含 2 的交易数据
# data[data.日期.str.slice(-5).str.contains('2')][1:9]
pandas_使用透视表与交叉表查看业绩汇总数据
# 使用透视表与交叉表查看业绩汇总数据
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 对姓名和日期进行分组,并进行求和
dff = dataframe.groupby(by = ['姓名','日期'],as_index = False).sum()
'''
姓名 日期 工号 交易额
0 周七 20190301 1005 600
1 周七 20190302 1005 580
2 张三 20190301 1001 2000
3 张三 20190302 2002 1900
4 张三 20190303 1001 1300
5 李四 20190301 1002 1800
6 李四 20190302 2004 2180
7 王五 20190301 1003 800
8 王五 20190302 2006 1830
9 赵六 20190301 1004 1100
10 赵六 20190302 1004 1050
11 钱八 20190301 2012 1550
12 钱八 20190302 1006 720
'''
# 将 dff 的索引,列 设置成透视表形式
dff = dff.pivot(index = '姓名',columns = '日期',values = '交易额')
'''
日期 20190301 20190302 20190303
姓名
周七 600.0 580.0 NaN
张三 2000.0 1900.0 1300.0
李四 1800.0 2180.0 NaN
王五 800.0 1830.0 NaN
赵六 1100.0 1050.0 NaN
钱八 1550.0 720.0 NaN
'''
# 查看前一天的数据
dff.iloc[:,:1]
'''
日期 20190301
姓名
周七 600.0
张三 2000.0
李四 1800.0
王五 800.0
赵六 1100.0
钱八 1550.0
'''
# 交易总额小于 4000 的人的前三天业绩
dff[dff.sum(axis = 1) < 4000].iloc[:,:3]
'''
日期 20190301 20190302 20190303
姓名
周七 600.0 580.0 NaN
李四 1800.0 2180.0 NaN
王五 800.0 1830.0 NaN
赵六 1100.0 1050.0 NaN
钱八 1550.0 720.0 NaN
'''
# 工资总额大于 2900 元的员工的姓名
dff[dff.sum(axis = 1) > 2900].index.values
# array(['张三', '李四'], dtype=object)
# 显示前两天每一天的交易总额以及每个人的交易金额
dataframe.pivot_table(values = '交易额',index = '姓名',
columns = '日期',aggfunc = 'sum',margins = True).iloc[:,:2]
'''
日期 20190301 20190302
姓名
周七 600.0 580.0
张三 2000.0 1900.0
李四 1800.0 2180.0
王五 800.0 1830.0
赵六 1100.0 1050.0
钱八 1550.0 720.0
All 7850.0 8260.0
'''
# 显示每个人在每个柜台的交易总额
dff = dataframe.groupby(by = ['姓名','柜台'],as_index = False).sum()
dff.pivot(index = '姓名',columns = '柜台',values = '交易额')
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 1180.0 NaN NaN
张三 4600.0 NaN 600.0 NaN
李四 3300.0 NaN 680.0 NaN
王五 NaN NaN 830.0 1800.0
赵六 NaN NaN NaN 2150.0
钱八 NaN 1420.0 850.0 NaN
'''
# 查看每人每天的上班次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True).iloc[:,:1]
'''
日期 20190301
姓名
周七 1.0
张三 1.0
李四 1.0
王五 1.0
赵六 1.0
钱八 2.0
All 7.0
'''
# 查看每个人每天购买的次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True)
'''
日期 20190301 20190302 20190303 All
姓名
周七 1.0 1.0 NaN 2
张三 1.0 2.0 1.0 4
李四 1.0 2.0 NaN 3
王五 1.0 2.0 NaN 3
赵六 1.0 1.0 NaN 2
钱八 2.0 1.0 NaN 3
All 7.0 9.0 1.0 17
'''
# 交叉表
# 每个人每天上过几次班
pd.crosstab(dataframe.姓名,dataframe.日期,margins = True).iloc[:,:2]
'''
日期 20190301 20190302
姓名
周七 1 1
张三 1 2
李四 1 2
王五 1 2
赵六 1 1
钱八 2 1
All 7 9
'''
# 每个人每天去过几次柜台
pd.crosstab(dataframe.姓名,dataframe.柜台)
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 0 2 0 0
张三 3 0 1 0
李四 2 0 1 0
王五 0 0 1 2
赵六 0 0 0 2
钱八 0 2 1 0
'''
# 将每一个人在每一个柜台的交易总额显示出来
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc='sum')
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 1180.0 NaN NaN
张三 4600.0 NaN 600.0 NaN
李四 3300.0 NaN 680.0 NaN
王五 NaN NaN 830.0 1800.0
赵六 NaN NaN NaN 2150.0
钱八 NaN 1420.0 850.0 NaN
'''
# 每个人在每个柜台交易额的平均值,金额/天数
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc = 'mean').apply(lambda num:round(num,2) )
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 590.0 NaN NaN
张三 1533.33 NaN 600.0 NaN
李四 1650.00 NaN 680.0 NaN
王五 NaN NaN 830.0 900.0
赵六 NaN NaN NaN 1075.0
钱八 NaN 710.0 850.0 NaN
'''
pandas_分类与聚合
# 分组与聚合
import pandas as pd
import numpy as np
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额','柜台'])
# 对 5 的余数进行分组
dataframe.groupby(by = lambda num:num % 5)['交易额'].sum()
'''
0 4530
1 5000
2 1980
3 3120
4 2780
Name: 交易额, dtype: int64
'''
# 查看索引为 7 15 的交易额
dataframe.groupby(by = {7:'索引为7的行',15:'索引为15的行'})['交易额'].sum()
'''
索引为15的行 830
索引为7的行 600
Name: 交易额, dtype: int64
'''
# 查看不同时段的交易总额
dataframe.groupby(by = '时段')['交易额'].sum()
'''
时段
14:00-21:00 8300
9:00-14:00 9110
Name: 交易额, dtype: int64
'''
# 各柜台的销售总额
dataframe.groupby(by = '柜台')['交易额'].sum()
'''
柜台
化妆品 7900
日用品 2600
蔬菜水果 2960
食品 3950
Name: 交易额, dtype: int64
'''
# 查看每个人在每个时段购买的次数
count = dataframe.groupby(by = '姓名')['时段'].count()
'''
姓名
周七 2
张三 4
李四 3
王五 3
赵六 2
钱八 3
Name: 时段, dtype: int64
'''
#
count.name = '交易人和次数'
'''
'''
# 每个人的交易额平均值并排序
dataframe.groupby(by = '姓名')['交易额'].mean().round(2).sort_values()
'''
姓名
周七 590.00
钱八 756.67
王五 876.67
赵六 1075.00
张三 1300.00
李四 1326.67
Name: 交易额, dtype: float64
'''
# 每个人的交易额,apply(int) 转换为整数
dataframe.groupby(by = '姓名').sum()['交易额'].apply(int)
'''
姓名
周七 1180
张三 5200
李四 3980
王五 2630
赵六 2150
钱八 2270
Name: 交易额, dtype: int64
'''
# 每一个员工交易额的中值
data = dataframe.groupby(by = '姓名').median()
'''
工号 交易额
姓名
周七 1005 590
张三 1001 1300
李四 1002 1500
王五 1003 830
赵六 1004 1075
钱八 1006 720
'''
data['交易额']
'''
姓名
周七 590
张三 1300
李四 1500
王五 830
赵六 1075
钱八 720
Name: 交易额, dtype: int64
'''
# 查看交易额对应的排名
data['排名'] = data['交易额'].rank(ascending = False)
data[['交易额','排名']]
'''
交易额 排名
姓名
周七 590 6.0
张三 1300 2.0
李四 1500 1.0
王五 830 4.0
赵六 1075 3.0
钱八 720 5.0
'''
# 每个人不同时段的交易额
dataframe.groupby(by = ['姓名','时段'])['交易额'].sum()
'''
姓名 时段
周七 9:00-14:00 1180
张三 14:00-21:00 600
9:00-14:00 4600
李四 14:00-21:00 3300
9:00-14:00 680
王五 14:00-21:00 830
9:00-14:00 1800
赵六 14:00-21:00 2150
钱八 14:00-21:00 1420
9:00-14:00 850
Name: 交易额, dtype: int64
'''
# 设置各时段累计
dataframe.groupby(by = ['姓名'])['时段','交易额'].aggregate({'交易额':np.sum,'时段':lambda x:'各时段累计'})
'''
交易额 时段
姓名
周七 1180 各时段累计
张三 5200 各时段累计
李四 3980 各时段累计
王五 2630 各时段累计
赵六 2150 各时段累计
钱八 2270 各时段累计
'''
# 对指定列进行聚合,查看最大,最小,和,平均值,中值
dataframe.groupby(by = '姓名').agg(['max','min','sum','mean','median'])
'''
工号 交易额
max min sum mean median max min sum mean median
姓名
周七 1005 1005 2010 1005 1005 600 580 1180 590.000000 590
张三 1001 1001 4004 1001 1001 2000 600 5200 1300.000000 1300
李四 1002 1002 3006 1002 1002 1800 680 3980 1326.666667 1500
王五 1003 1003 3009 1003 1003 1000 800 2630 876.666667 830
赵六 1004 1004 2008 1004 1004 1100 1050 2150 1075.000000 1075
钱八 1006 1006 3018 1006 1006 850 700 2270 756.666667 720
'''
# 查看部分聚合后的结果
dataframe.groupby(by = '姓名').agg(['max','min','sum','mean','median'])['交易额']
'''
max min sum mean median
姓名
周七 600 580 1180 590.000000 590
张三 2000 600 5200 1300.000000 1300
李四 1800 680 3980 1326.666667 1500
王五 1000 800 2630 876.666667 830
赵六 1100 1050 2150 1075.000000 1075
钱八 850 700 2270 756.666667 720
'''
pandas_处理异常值缺失值重复值数据差分
# 处理异常值缺失值重复值数据差分
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 异常值
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看交易额低于 2000 的三条数据
# dataframe[dataframe.交易额 < 2000]
dataframe[dataframe.交易额 < 2000][:3]
'''
工号 姓名 日期 时段 交易额 柜台
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
3 1004 赵六 20190301 14:00-21:00 1100 食品
'''
# 查看上浮了 50% 之后依旧低于 1500 的交易额,查看 4 条数据
dataframe.loc[dataframe.交易额 < 1500,'交易额'] = dataframe[dataframe.交易额 < 1500]['交易额'].map(lambda num:num*1.5)
dataframe[dataframe.交易额 < 1500][:4]
'''
工号 姓名 日期 时段 交易额 柜台
2 1003 王五 20190301 9:00-14:00 1200.0 食品
4 1005 周七 20190301 9:00-14:00 900.0 日用品
5 1006 钱八 20190301 14:00-21:00 1050.0 日用品
6 1006 钱八 20190301 9:00-14:00 1275.0 蔬菜水果
'''
# 查看交易额大于 2500 的数据
dataframe[dataframe.交易额 > 2500]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# 查看交易额低于 900 或 高于 1800 的数据
dataframe[(dataframe.交易额 < 900)|(dataframe.交易额 > 1800)]
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000.0 化妆品
8 1001 张三 20190302 9:00-14:00 1950.0 化妆品
12 1005 周七 20190302 9:00-14:00 870.0 日用品
16 1001 张三 20190303 9:00-14:00 1950.0 化妆品
'''
# 将所有低于 200 的交易额都替换成 200
dataframe.loc[dataframe.交易额 < 200,'交易额'] = 200
# 查看低于 1500 的交易额个数
dataframe.loc[dataframe.交易额 < 1500,'交易额'].count()
# 9
# 将大于 3000 元的都替换为 3000 元
dataframe.loc[dataframe.交易额 > 3000,'交易额'] = 3000
# 缺失值
# 查看有多少行数据
len(dataframe)
# 17
# 丢弃缺失值之后的行数
len(dataframe.dropna())
# 17
# 包含缺失值的行
dataframe[dataframe['交易额'].isnull()]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# 使用固定值替换缺失值
# dff = copy.deepcopy(dataframe)
# dff.loc[dff.交易额.isnull(),'交易额'] = 999
# 将缺失值设定为 999
# dff.iloc[[1,4,17],:]
# 使用交易额的均值替换缺失值
# dff = copy.deepcopy(dataframe)
# for i in dff[dff.交易额.isnull()].index:
# dff.loc[i,'交易额'] = round(dff.loc[dff.姓名 == dff.loc[i,'姓名'],'交易额'].mean())
# dff.iloc[[1,4,17],:]
# 使用整体均值的 80% 填充缺失值
# dataframe.fillna({'交易额':round(dataframe['交易额'].mean() * 0.8)},inplace = True)
# dataframe.iloc[[1,4,16],:]
# 重复值
dataframe[dataframe.duplicated()]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# dff = dataframe[['工号','姓名','日期','交易额']]
# dff = dff[dff.duplicated()]
# for row in dff.values:
# df[(df.工号 == row[0]) & (df.日期 == row[2]) &(df.交易额 == row[3])]
# 丢弃重复行
dataframe = dataframe.drop_duplicates()
# 查看是否有录入错误的工号和姓名
dff = dataframe[['工号','姓名']]
dff.drop_duplicates()
'''
工号 姓名
0 1001 张三
1 1002 李四
2 1003 王五
3 1004 赵六
4 1005 周七
5 1006 钱八
'''
# 数据差分
# 查看员工业绩波动情况(每一天和昨天的数据作比较)
dff = dataframe.groupby(by = '日期').sum()['交易额'].diff()
'''
日期
20190301 NaN
20190302 1765.0
20190303 -9690.0
Name: 交易额, dtype: float64
'''
dff.map(lambda num:'%.2f'%(num))[:5]
'''
日期
20190301 nan
20190302 1765.00
20190303 -9690.00
Name: 交易额, dtype: object
'''
# 数据差分
# 查看张三的波动情况
dataframe[dataframe.姓名 == '张三'].groupby(by = '日期').sum()['交易额'].diff()[:5]
'''
日期
20190301 NaN
20190302 850.0
20190303 -900.0
Name: 交易额, dtype: float64
'''
pandas_数据拆分与合并
import pandas as pd
import numpy as np
# 读取全部数据,使用默认索引
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 修改异常值
data.loc[data.交易额 > 3000,'交易额'] = 3000
data.loc[data.交易额 < 200,'交易额'] = 200
# 删除重复值
data.drop_duplicates(inplace = True)
# inplace 表示对源数据也进行修改
# 填充缺失值
data['交易额'].fillna(data['交易额'].mean(),inplace = True)
# 使用交叉表得到每人在各柜台交易额的平均值
data_group = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean').apply(round)
# 绘制柱状图
data_group.plot(kind = 'bar')
#
# 数据的合并
data1 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
data2 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',sheet_name = 'Sheet2')
df1 = data1[:3]
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
'''
df2 = data2[:4]
'''
工号 姓名 日期 时段 交易额 柜台
0 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
1 1001 张三 20190302 14:00-21:00 600 蔬菜水果
2 1001 张三 20190302 9:00-14:00 1300 化妆品
3 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 使用 concat 连接两个相同结构的 DataFrame 对象
df3 = pd.concat([df1,df2])
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
0 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
1 1001 张三 20190302 14:00-21:00 600 蔬菜水果
2 1001 张三 20190302 9:00-14:00 1300 化妆品
3 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 合并,忽略原来的索引 ignore_index
df4 = df3.append([df1,df2],ignore_index = True)
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
3 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
4 1001 张三 20190302 14:00-21:00 600 蔬菜水果
5 1001 张三 20190302 9:00-14:00 1300 化妆品
6 1002 李四 20190302 14:00-21:00 1500 化妆品
7 1001 张三 20190301 9:00-14:00 2000 化妆品
8 1002 李四 20190301 14:00-21:00 1800 化妆品
9 1003 王五 20190301 9:00-14:00 800 食品
10 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
11 1001 张三 20190302 14:00-21:00 600 蔬菜水果
12 1001 张三 20190302 9:00-14:00 1300 化妆品
13 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 按照列进行拆分
df5 = df4.loc[:,['姓名','柜台','交易额']]
# 查看前五条数据
df5[:5]
'''
姓名 柜台 交易额
0 张三 化妆品 2000
1 李四 化妆品 1800
2 王五 食品 800
3 钱八 蔬菜水果 850
4 张三 蔬菜水果 600
'''
# 合并 merge 、 join
# 按照工号进行合并,随机查看 3 条数据
rows = np.random.randint(0,len(df5),3)
pd.merge(df4,df5).iloc[rows,:]
'''
工号 姓名 日期 时段 交易额 柜台
7 1002 李四 20190301 14:00-21:00 1800 化妆品
4 1002 李四 20190301 14:00-21:00 1800 化妆品
10 1003 王五 20190301 9:00-14:00 800 食品
'''
# 按照工号进行合并,指定其他同名列的后缀
pd.merge(df1,df2,on = '工号',suffixes = ['_x','_y']).iloc[:,:]
'''
工号 姓名_x 日期_x 时段_x ... 日期_y 时段_y 交易额_y 柜台_y
0 1001 张三 20190301 9:00-14:00 ... 20190302 14:00-21:00 600 蔬菜水果
1 1001 张三 20190301 9:00-14:00 ... 20190302 9:00-14:00 1300 化妆品
2 1002 李四 20190301 14:00-21:00 ... 20190302 14:00-21:00 1500 化妆品
'''
# 两个表都设置工号为索引 set_index
df2.set_index('工号').join(df3.set_index('工号'),lsuffix = '_x',rsuffix = '_y').iloc[:]
'''
姓名_x 日期_x 时段_x 交易额_x ... 日期_y 时段_y 交易额_y 柜台_y
工号 ...
1001 张三 20190302 14:00-21:00 600 ... 20190301 9:00-14:00 2000 化妆品
1001 张三 20190302 14:00-21:00 600 ... 20190302 14:00-21:00 600 蔬菜水果
1001 张三 20190302 14:00-21:00 600 ... 20190302 9:00-14:00 1300 化妆品
1001 张三 20190302 9:00-14:00 1300 ... 20190301 9:00-14:00 2000 化妆品
1001 张三 20190302 9:00-14:00 1300 ... 20190302 14:00-21:00 600 蔬菜水果
1001 张三 20190302 9:00-14:00 1300 ... 20190302 9:00-14:00 1300 化妆品
1002 李四 20190302 14:00-21:00 1500 ... 20190301 14:00-21:00 1800 化妆品
1002 李四 20190302 14:00-21:00 1500 ... 20190302 14:00-21:00 1500 化妆品
1006 钱八 20190301 9:00-14:00 850 ... 20190301 9:00-14:00 850 蔬菜水果
'''
pandas_数据排序
import pandas as pd
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额','柜台'])
dataframe[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
2 1003 王五 9:00-14:00 800 食品
3 1004 赵六 14:00-21:00 1100 食品
4 1005 周七 9:00-14:00 600 日用品
'''
# 按照交易额和工号降序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = False)[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
9 1002 李四 14:00-21:00 1500 化妆品
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
'''
# 按照交易额和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'])[:5]
'''
工号 姓名 时段 交易额 柜台
12 1005 周七 9:00-14:00 580 日用品
7 1001 张三 14:00-21:00 600 蔬菜水果
4 1005 周七 9:00-14:00 600 日用品
14 1002 李四 9:00-14:00 680 蔬菜水果
5 1006 钱八 14:00-21:00 700 日用品
'''
# 按照交易额降序和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = [False,True])[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
9 1002 李四 14:00-21:00 1500 化妆品
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
'''
# 按工号升序排序
dataframe.sort_values(by = ['工号'])[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
7 1001 张三 14:00-21:00 600 蔬菜水果
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
'''
dataframe.sort_values(by = ['工号'],na_position = 'last')[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
7 1001 张三 14:00-21:00 600 蔬菜水果
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
'''
# 按列名升序排序
dataframe.sort_index(axis = 1)[:5]
'''
交易额 姓名 工号 时段 柜台
0 2000 张三 1001 9:00-14:00 化妆品
1 1800 李四 1002 14:00-21:00 化妆品
2 800 王五 1003 9:00-14:00 食品
3 1100 赵六 1004 14:00-21:00 食品
4 600 周七 1005 9:00-14:00 日用品
'''
dataframe.sort_index(axis = 1,ascending = True)[:5]
'''
交易额 姓名 工号 时段 柜台
0 2000 张三 1001 9:00-14:00 化妆品
1 1800 李四 1002 14:00-21:00 化妆品
2 800 王五 1003 9:00-14:00 食品
3 1100 赵六 1004 14:00-21:00 食品
4 600 周七 1005 9:00-14:00 日用品
'''
pandas_时间序列和常用操作
# 时间序列和常用操作
import pandas as pd
# 每隔五天--5D
pd.date_range(start = '20200101',end = '20200131',freq = '5D')
'''
DatetimeIndex(['2020-01-01', '2020-01-06', '2020-01-11', '2020-01-16',
'2020-01-21', '2020-01-26', '2020-01-31'],
dtype='datetime64[ns]', freq='5D')
'''
# 每隔一周--W
pd.date_range(start = '20200301',end = '20200331',freq = 'W')
'''
DatetimeIndex(['2020-03-01', '2020-03-08', '2020-03-15', '2020-03-22',
'2020-03-29'],
dtype='datetime64[ns]', freq='W-SUN')
'''
# 间隔两天,五个数据
pd.date_range(start = '20200301',periods = 5,freq = '2D')
# periods 几个数据 ,freq 间隔时期,两天
'''
DatetimeIndex(['2020-03-01', '2020-03-03', '2020-03-05', '2020-03-07',
'2020-03-09'],
dtype='datetime64[ns]', freq='2D')
'''
# 间隔三小时,八个数据
pd.date_range(start = '20200301',periods = 8,freq = '3H')
'''
DatetimeIndex(['2020-03-01 00:00:00', '2020-03-01 03:00:00',
'2020-03-01 06:00:00', '2020-03-01 09:00:00',
'2020-03-01 12:00:00', '2020-03-01 15:00:00',
'2020-03-01 18:00:00', '2020-03-01 21:00:00'],
dtype='datetime64[ns]', freq='3H')
'''
# 三点开始,十二个数据,间隔一分钟
pd.date_range(start = '202003010300',periods = 12,freq = 'T')
'''
DatetimeIndex(['2020-03-01 03:00:00', '2020-03-01 03:01:00',
'2020-03-01 03:02:00', '2020-03-01 03:03:00',
'2020-03-01 03:04:00', '2020-03-01 03:05:00',
'2020-03-01 03:06:00', '2020-03-01 03:07:00',
'2020-03-01 03:08:00', '2020-03-01 03:09:00',
'2020-03-01 03:10:00', '2020-03-01 03:11:00'],
dtype='datetime64[ns]', freq='T')
'''
# 每个月的最后一天
pd.date_range(start = '20190101',end = '20191231',freq = 'M')
'''
DatetimeIndex(['2019-01-31', '2019-02-28', '2019-03-31', '2019-04-30',
'2019-05-31', '2019-06-30', '2019-07-31', '2019-08-31',
'2019-09-30', '2019-10-31', '2019-11-30', '2019-12-31'],
dtype='datetime64[ns]', freq='M')
'''
# 间隔一年,六个数据,年末最后一天
pd.date_range(start = '20190101',periods = 6,freq = 'A')
'''
DatetimeIndex(['2019-12-31', '2020-12-31', '2021-12-31', '2022-12-31',
'2023-12-31', '2024-12-31'],
dtype='datetime64[ns]', freq='A-DEC')
'''
# 间隔一年,六个数据,年初最后一天
pd.date_range(start = '20200101',periods = 6,freq = 'AS')
'''
DatetimeIndex(['2020-01-01', '2021-01-01', '2022-01-01', '2023-01-01',
'2024-01-01', '2025-01-01'],
dtype='datetime64[ns]', freq='AS-JAN')
'''
# 使用 Series 对象包含时间序列对象,使用特定索引
data = pd.Series(index = pd.date_range(start = '20200321',periods = 24,freq = 'H'),data = range(24))
'''
2020-03-21 00:00:00 0
2020-03-21 01:00:00 1
2020-03-21 02:00:00 2
2020-03-21 03:00:00 3
2020-03-21 04:00:00 4
2020-03-21 05:00:00 5
2020-03-21 06:00:00 6
2020-03-21 07:00:00 7
2020-03-21 08:00:00 8
2020-03-21 09:00:00 9
2020-03-21 10:00:00 10
2020-03-21 11:00:00 11
2020-03-21 12:00:00 12
2020-03-21 13:00:00 13
2020-03-21 14:00:00 14
2020-03-21 15:00:00 15
2020-03-21 16:00:00 16
2020-03-21 17:00:00 17
2020-03-21 18:00:00 18
2020-03-21 19:00:00 19
2020-03-21 20:00:00 20
2020-03-21 21:00:00 21
2020-03-21 22:00:00 22
2020-03-21 23:00:00 23
Freq: H, dtype: int64
'''
# 查看前五个数据
data[:5]
'''
2020-03-21 00:00:00 0
2020-03-21 01:00:00 1
2020-03-21 02:00:00 2
2020-03-21 03:00:00 3
2020-03-21 04:00:00 4
Freq: H, dtype: int64
'''
# 三分钟重采样,计算均值
data.resample('3H').mean()
'''
2020-03-21 00:00:00 1
2020-03-21 03:00:00 4
2020-03-21 06:00:00 7
2020-03-21 09:00:00 10
2020-03-21 12:00:00 13
2020-03-21 15:00:00 16
2020-03-21 18:00:00 19
2020-03-21 21:00:00 22
Freq: 3H, dtype: int64
'''
# 五分钟重采样,求和
data.resample('5H').sum()
'''
2020-03-21 00:00:00 10
2020-03-21 05:00:00 35
2020-03-21 10:00:00 60
2020-03-21 15:00:00 85
2020-03-21 20:00:00 86
Freq: 5H, dtype: int64
'''
# 计算OHLC open,high,low,close
data.resample('5H').ohlc()
'''
open high low close
2020-03-21 00:00:00 0 4 0 4
2020-03-21 05:00:00 5 9 5 9
2020-03-21 10:00:00 10 14 10 14
2020-03-21 15:00:00 15 19 15 19
2020-03-21 20:00:00 20 23 20 23
'''
# 将日期替换为第二天
data.index = data.index + pd.Timedelta('1D')
# 查看前五条数据
data[:5]
'''
2020-03-22 00:00:00 0
2020-03-22 01:00:00 1
2020-03-22 02:00:00 2
2020-03-22 03:00:00 3
2020-03-22 04:00:00 4
Freq: H, dtype: int64
'''
# 查看指定日期是星期几
# pd.Timestamp('20200321').weekday_name
# 'Saturday'
# 查看指定日期的年份是否是闰年
pd.Timestamp('20200301').is_leap_year
# True
# 查看指定日期所在的季度和月份
day = pd.Timestamp('20200321')
# Timestamp('2020-03-21 00:00:00')
# 查看日期的季度
day.quarter
# 1
# 查看日期所在的月份
day.month
# 3
# 转换为 python 的日期时间对象
day.to_pydatetime()
# datetime.datetime(2020, 3, 21, 0, 0)
pandas_学习的时候总会忘了的知识点
对Series 对象使用匿名函数
使用 pipe 函数对 Series 对象使用 匿名函数
pd.Series(range(5)).pipe(lambda x,y,z :(x**y)%z,2,5)
pd.Series(range(5)).pipe(lambda x:x+3).pipe(lambda x:x*3)
使用 apply 函数对 Series 对象使用 匿名函数
pd.Series(range(5)).apply(lambda x:x+3)
# 查看无偏标准差,使用 sem 函数
pd.Series(range(0,5)).sem()
# 按照日 进行分组查看交易的平均值 -1 表示倒数第一个
# data.groupby(data.日期.str.__getitem__(-1)).mean().apply(round)
# 查看日期尾数为 1 的数据
# data[data.日期.str.endswith('1')][:12]
# 查看日期尾数为 12 的交易数据,slice 为切片 (-2) 表示倒数两个
# data[data.日期.str.slice(-2) == '12']
# 查看日期中月份或天数包含 2 的交易数据
# data[data.日期.str.slice(-5).str.contains('2')][1:9]
# 对姓名和日期进行分组,并进行求和
dff = dataframe.groupby(by = ['姓名','日期'],as_index = False).sum()
# 使用 pivot 进行设置透视表
# 将 dff 的索引,列 设置成透视表形式
dff = dff.pivot(index = '姓名',columns = '日期',values = '交易额')
index 设置行索引
columns 设置列索引
values 对应的值
# 查看第一天的数据
dff.iloc[:,:1]
# 显示前两天每一天的交易总额以及每个人的交易金额
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'sum',margins = True).iloc[:,:2]
# 查看每个人每天购买的次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True)
# 每个人每天去过几次柜台,使用交叉表 crosstab
pd.crosstab(dataframe.姓名,dataframe.柜台)
# 每个人在每个柜台交易额的平均值,金额/天数
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc = 'mean').apply(lambda num:round(num,2) )
# 对 5 的余数进行分组
by 可以为匿名函数,字典,字符串
dataframe.groupby(by = lambda num:num % 5)['交易额'].sum()
dataframe.groupby(by = {7:'索引为7的行',15:'索引为15的行'})['交易额'].sum()
dataframe.groupby(by = '时段')['交易额'].sum()
# sort_values() 进行排序
# 查看交易额对应的排名
data['排名'] = data['交易额'].rank(ascending = False)
# 每个人不同时段的交易额
dataframe.groupby(by = ['姓名','时段'])['交易额'].sum()
# 查看上浮了 50% 之后依旧低于 1500 的交易额,查看 4 条数据
# 对 DataFrame 对象使用 map 匹配函数
dataframe.loc[dataframe.交易额 < 1500,'交易额'] = dataframe[dataframe.交易额 < 1500]['交易额'].map(lambda num:num*1.5)
# 丢弃缺失值之后的行数
len(dataframe.dropna())
# 包含缺失值的行
dataframe[dataframe['交易额'].isnull()]
# 使用整体均值的 80% 填充缺失值
# dataframe.fillna({'交易额':round(dataframe['交易额'].mean() * 0.8)},inplace = True)
# dataframe.iloc[[1,4,16],:]
# 重复值
dataframe[dataframe.duplicated()]
# 丢弃重复行
dataframe = dataframe.drop_duplicates()
# 查看是否有录入错误的工号和姓名
dff = dataframe[['工号','姓名']]
dff.drop_duplicates()
# 使用 diff 对数据进行差分
# 查看员工业绩波动情况(每一天和昨天的数据作比较)
dff = dataframe.groupby(by = '日期').sum()['交易额'].diff()
# 使用交叉表得到每人在各柜台交易额的平均值
data_group = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean').apply(round)
# 使用 concat 连接两个相同结构的 DataFrame 对象
df3 = pd.concat([df1,df2])
# 合并 merge 、 join
# 按照工号进行合并,随机查看 3 条数据
# 合并 df4 和 df5 两个DataFrame 对象
rows = np.random.randint(0,len(df5),3)
pd.merge(df4,df5).iloc[rows,:]
# 按照工号进行合并,指定其他同名列的后缀
# on 对应索引列名 suffixes 区分两个连接的对象
pd.merge(df1,df2,on = '工号',suffixes = ['_x','_y']).iloc[:,:]
# 两个表都设置工号为索引 set_index,设置两个连接对象的索引
df2.set_index('工号').join(df3.set_index('工号'),lsuffix = '_x',rsuffix = '_y').iloc[:]
# 读取 csv 对象时使用 usecols
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额','柜台'])
# 按照交易额降序和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = [False,True])[:5]
# 按工号升序排序
dataframe.sort_values(by = ['工号'])[:5]
# 三分钟重采样,计算均值
data.resample('3H').mean()
# 计算OHLC open,high,low,close
data.resample('5H').ohlc()
# 将日期替换为第二天
data.index = data.index + pd.Timedelta('1D')
# 查看指定日期的年份是否是闰年
pd.Timestamp('20200301').is_leap_year
# 查看所有的交易额信息
dataframe['交易额'].describe()
# 第一个最小交易额的行下标
index = dataframe['交易额'].idxmin()
# 最大交易额的行下标
index = dataframe['交易额'].idxmax()
dataframe.loc[index,'交易额']
# 2000
# 跳过 1 2 4 行,以第一列姓名为索引
dataframe2 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
skiprows = [1,2,4],
index_col = 1)
skiprows 跳过的行
index_col 指定的列
dataframe.iloc[[0,2,3],:]
# 查看第四行的姓名数据
dataframe.at[3,'姓名']
pandas_查看数据特征和统计信息
# 查看数据特征和统计信息
import pandas as pd
# 读取文件
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看所有的交易额信息
dataframe['交易额'].describe()
'''
count 17.000000
mean 1024.117647
std 428.019550
min 580.000000
25% 700.000000
50% 850.000000
75% 1300.000000
max 2000.000000
Name: 交易额, dtype: float64
'''
# 查看四分位数
dataframe['交易额'].quantile([0,0.25,0.5,0.75,1.0])
'''
0.00 580.0
0.25 700.0
0.50 850.0
0.75 1300.0
1.00 2000.0
Name: 交易额, dtype: float64
'''
# 交易额中值
dataframe['交易额'].median()
# 850.0
# 交易额最小的三个数据
dataframe['交易额'].nsmallest(3)
'''
12 580
4 600
7 600
Name: 交易额, dtype: int64
'''
dataframe.nsmallest(3,'交易额')
'''
工号 姓名 日期 时段 交易额 柜台
12 1005 周七 20190302 9:00-14:00 580 日用品
4 1005 周七 20190301 9:00-14:00 600 日用品
7 1001 张三 20190302 14:00-21:00 600 蔬菜水果
'''
# 交易额最大的两个数据
dataframe['交易额'].nlargest(2)
'''
0 2000
1 1800
Name: 交易额, dtype: int64
'''
# 查看最大的交易额数据
dataframe.nlargest(2,'交易额')
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
'''
# 查看最后一个日期
dataframe['日期'].max()
# 20190303
# 查看最小的工号
dataframe['工号'].min()
# 1001
# 第一个最小交易额的行下标
index = dataframe['交易额'].idxmin()
# 0
# 第一个最小交易额
dataframe.loc[index,'交易额']
# 580
# 最大交易额的行下标
index = dataframe['交易额'].idxmax()
dataframe.loc[index,'交易额']
# 2000
pandas_读取Excel并筛选特定数据
# C:\Users\lenovo\Desktop\总结\Python
# 读取 Excel 文件并进行筛选
import pandas as pd
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额'])
# 打印前十行数据
dataframe[:10]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
4 1005 周七 9:00-14:00 600
5 1006 钱八 14:00-21:00 700
6 1006 钱八 9:00-14:00 850
7 1001 张三 14:00-21:00 600
8 1001 张三 9:00-14:00 1300
9 1002 李四 14:00-21:00 1500
'''
# 跳过 1 2 4 行,以第一列姓名为索引
dataframe2 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
skiprows = [1,2,4],
index_col = 1)
'''注:张三李四赵六的第一条数据跳过
工号 日期 时段 交易额 柜台
姓名
王五 1003 20190301 9:00-14:00 800 食品
周七 1005 20190301 9:00-14:00 600 日用品
钱八 1006 20190301 14:00-21:00 700 日用品
钱八 1006 20190301 9:00-14:00 850 蔬菜水果
张三 1001 20190302 14:00-21:00 600 蔬菜水果
'''
# 筛选符合特定条件的数据
# 读取超市营业额数据
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看 5 到 10 的数据
dataframe[5:11]
'''
工号 姓名 日期 时段 交易额 柜台
5 1006 钱八 20190301 14:00-21:00 700 日用品
6 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
7 1001 张三 20190302 14:00-21:00 600 蔬菜水果
8 1001 张三 20190302 9:00-14:00 1300 化妆品
9 1002 李四 20190302 14:00-21:00 1500 化妆品
10 1003 王五 20190302 9:00-14:00 1000 食品
'''
# 查看第六行的数据
dataframe.iloc[5]
'''
工号 1006
姓名 钱八
时段 14:00-21:00
交易额 700
Name: 5, dtype: object
'''
dataframe[:5]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
4 1005 周七 9:00-14:00 600
'''
# 查看第 1 3 4 行的数据
dataframe.iloc[[0,2,3],:]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
'''
# 查看第 1 3 4 行的第 1 2 列
dataframe.iloc[[0,2,3],[0,1]]
'''
工号 姓名
0 1001 张三
2 1003 王五
3 1004 赵六
'''
# 查看前五行指定,姓名、时段和交易额的数据
dataframe[['姓名','时段','交易额']][:5]
'''
姓名 时段 交易额
0 张三 9:00-14:00 2000
1 李四 14:00-21:00 1800
2 王五 9:00-14:00 800
3 赵六 14:00-21:00 1100
4 周七 9:00-14:00 600
'''
dataframe[:5][['姓名','时段','交易额']]
'''
姓名 时段 交易额
0 张三 9:00-14:00 2000
1 李四 14:00-21:00 1800
2 王五 9:00-14:00 800
3 赵六 14:00-21:00 1100
4 周七 9:00-14:00 600
'''
# 查看第 2 4 5 行 姓名,交易额 数据 loc 函数
dataframe.loc[[1,3,4],['姓名','交易额']]
'''
姓名 交易额
1 李四 1800
3 赵六 1100
4 周七 600
'''
# 查看第四行的姓名数据
dataframe.at[3,'姓名']
# '赵六'
# 查看交易额大于 1700 的数据
dataframe[dataframe['交易额'] > 1700]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
'''
# 查看交易额总和
dataframe.sum()
'''
工号 17055
姓名 张三李四王五赵六周七钱八钱八张三张三李四王五赵六周七钱八李四王五张三...
时段 9:00-14:0014:00-21:009:00-14:0014:00-21:009:00...
交易额 17410
dtype: object
'''
# 某一时段的交易总和
dataframe[dataframe['时段'] == '14:00-21:00']['交易额'].sum()
# 8300
# 查看张三在下午14:00之后的交易情况
dataframe[(dataframe.姓名 == '张三') & (dataframe.时段 == '14:00-21:00')][:10]
'''
工号 姓名 时段 交易额
7 1001 张三 14:00-21:00 600
'''
# 查看日用品的销售总额
# dataframe[dataframe['柜台'] == '日用品']['交易额'].sum()
# 查看张三总共的交易额
dataframe[dataframe['姓名'].isin(['张三'])]['交易额'].sum()
# 5200
# 查看交易额在 1500~3000 之间的记录
dataframe[dataframe['交易额'].between(1500,3000)]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
9 1002 李四 14:00-21:00 1500
'''
pandas_重采样多索引标准差协方差
# 重采样 多索引 标准差 协方差
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 将日期设置为 python 中的日期类型
data.日期 = pd.to_datetime(data.日期)
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 1970-01-01 00:00:00.020190301 9:00-14:00 2000 化妆品
1 1002 李四 1970-01-01 00:00:00.020190301 14:00-21:00 1800 化妆品
2 1003 王五 1970-01-01 00:00:00.020190301 9:00-14:00 800 食品
'''
# 每七天营业的总额
data.resample('7D',on = '日期').sum()['交易额']
'''
日期
1970-01-01 17410
Freq: 7D, Name: 交易额, dtype: int64
'''
# 每七天营业总额
data.resample('7D',on = '日期',label = 'right').sum()['交易额']
'''
日期
1970-01-08 17410
Freq: 7D, Name: 交易额, dtype: int64
'''
# 每七天营业额的平均值
func = lambda item:round(np.sum(item)/len(item),2)
data.resample('7D',on = '日期',label = 'right').apply(func)['交易额']
'''
日期
1970-01-08 1024.12
Freq: 7D, Name: 交易额, dtype: float64
'''
# 每七天营业额的平均值
func = lambda num:round(num,2)
data.resample('7D',on = '日期',label = 'right').mean().apply(func)['交易额']
# 1024.12
# 删除工号这一列
data.drop('工号',axis = 1,inplace = True)
data[:2]
'''
姓名 日期 时段 交易额 柜台
0 张三 1970-01-01 00:00:00.020190301 9:00-14:00 2000 化妆品
1 李四 1970-01-01 00:00:00.020190301 14:00-21:00 1800 化妆品
'''
# 按照姓名和柜台进行分组汇总
data = data.groupby(by = ['姓名','柜台']).sum()[:3]
'''
交易额
姓名 柜台
周七 日用品 1180
张三 化妆品 4600
蔬菜水果 600
'''
# 查看张三的汇总数据
data.loc['张三',:]
'''
交易额
柜台
化妆品 4600
蔬菜水果 600
'''
# 查看张三在蔬菜水果的交易数据
data.loc['张三','蔬菜水果']
'''
交易额 600
Name: (张三, 蔬菜水果), dtype: int64
'''
# 多索引
# 重新读取,使用第二列和第六列作为索引,排在前面
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',index_col = [1,5])
data[:5]
'''
工号 日期 时段 交易额
姓名 柜台
张三 化妆品 1001 20190301 9:00-14:00 2000
李四 化妆品 1002 20190301 14:00-21:00 1800
王五 食品 1003 20190301 9:00-14:00 800
赵六 食品 1004 20190301 14:00-21:00 1100
周七 日用品 1005 20190301 9:00-14:00 600
'''
# 丢弃工号列
data.drop('工号',axis = 1,inplace = True)
data[:5]
'''
日期 时段 交易额
姓名 柜台
张三 化妆品 20190301 9:00-14:00 2000
李四 化妆品 20190301 14:00-21:00 1800
王五 食品 20190301 9:00-14:00 800
赵六 食品 20190301 14:00-21:00 1100
周七 日用品 20190301 9:00-14:00 600
'''
# 按照柜台进行排序
dff = data.sort_index(level = '柜台',axis = 0)
dff[:5]
'''
工号 日期 时段 交易额
姓名 柜台
张三 化妆品 1001 20190301 9:00-14:00 2000
化妆品 1001 20190302 9:00-14:00 1300
化妆品 1001 20190303 9:00-14:00 1300
李四 化妆品 1002 20190301 14:00-21:00 1800
化妆品 1002 20190302 14:00-21:00 1500
'''
# 按照姓名进行排序
dff = data.sort_index(level = '姓名',axis = 0)
dff[:5]
'''
工号 日期 时段 交易额
姓名 柜台
周七 日用品 1005 20190301 9:00-14:00 600
日用品 1005 20190302 9:00-14:00 580
张三 化妆品 1001 20190301 9:00-14:00 2000
化妆品 1001 20190302 9:00-14:00 1300
化妆品 1001 20190303 9:00-14:00 1300
'''
# 按照柜台进行分组求和
dff = data.groupby(level = '柜台').sum()['交易额']
'''
柜台
化妆品 7900
日用品 2600
蔬菜水果 2960
食品 3950
Name: 交易额, dtype: int64
'''
#标准差
data = pd.DataFrame({'A':[3,3,3,3,3],'B':[1,2,3,4,5],
'C':[-5,-4,1,4,5],'D':[-45,15,63,40,50]
})
'''
A B C D
0 3 1 -5 -45
1 3 2 -4 15
2 3 3 1 63
3 3 4 4 40
4 3 5 5 50
'''
# 平均值
data.mean()
'''
A 3.0
B 3.0
C 0.2
D 24.6
dtype: float64
'''
# 标准差
data.std()
'''
A 0.000000
B 1.581139
C 4.549725
D 42.700117
dtype: float64
'''
# 标准差的平方
data.std()**2
'''
A 0.0
B 2.5
C 20.7
D 1823.3
dtype: float64
'''
# 协方差
data.cov()
'''
A B C D
A 0.0 0.00 0.00 0.00
B 0.0 2.50 7.00 53.75
C 0.0 7.00 20.70 153.35
D 0.0 53.75 153.35 1823.30
'''
# 指定索引为 姓名,日期,时段,柜台,交易额
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['姓名','日期','时段','柜台','交易额'])
# 删除缺失值和重复值,inplace = True 直接丢弃
data.dropna(inplace = True)
data.drop_duplicates(inplace = True)
# 处理异常值
data.loc[data.交易额 < 200,'交易额'] = 200
data.loc[data.交易额 > 3000,'交易额'] = 3000
# 使用交叉表得到不同员工在不同柜台的交易额平均值
dff = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean')
dff[:5]
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 590.0 NaN NaN
张三 1533.333333 NaN 600.0 NaN
李四 1650.000000 NaN 680.0 NaN
王五 NaN NaN 830.0 900.0
赵六 NaN NaN NaN 1075.0
'''
# 查看数据的标准差
dff.std()
'''
柜台
化妆品 82.495791
日用品 84.852814
蔬菜水果 120.277457
食品 123.743687
dtype: float64
'''
# 协方差
dff.cov()
'''
柜台 化妆品 日用品 蔬菜水果 食品
柜台
化妆品 6805.555556 NaN 4666.666667 NaN
日用品 NaN 7200.0 NaN NaN
蔬菜水果 4666.666667 NaN 14466.666667 NaN
食品 NaN NaN NaN 15312.5
'''
Numpy random函数
import numpy as np
# 生成一个随机数组
np.random.randint(0,6,3)
# array([1, 1, 3])
# 生成一个随机数组(二维数组)
np.random.randint(0,6,(3,3))
'''
array([[4, 4, 1],
[2, 1, 0],
[5, 0, 0]])
'''
# 生成十个随机数在[0,1)之间
np.random.rand(10)
'''
array([0.9283789 , 0.43515554, 0.27117021, 0.94829333, 0.31733981,
0.42314939, 0.81838647, 0.39091899, 0.33571004, 0.90240897])
'''
# 从标准正态分布中随机抽选出3个数
np.random.standard_normal(3)
# array([0.34660435, 0.63543859, 0.1307822 ])
# 返回三页四行两列的标准正态分布数
np.random.standard_normal((3,4,2))
'''
array([[[-0.24880261, -1.17453957],
[ 0.0295264 , 1.04038047],
[-1.45201783, 0.57672288],
[ 1.10282747, -2.08699482]],
[[-0.3813943 , 0.47845782],
[ 0.97708005, 1.1760147 ],
[ 1.3414987 , -0.629902 ],
[-0.29780567, 0.60288726]],
[[ 1.43991349, -1.6757028 ],
[-1.97956809, -1.18713495],
[-1.39662811, 0.34174275],
[ 0.56457553, -0.83224426]]])
'''
Numpy修改数组中的元素值
import numpy as np
x = np.arange(8)
# [0 1 2 3 4 5 6 7]
# 在数组尾部追加一个元素
np.append(x,10)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 10])
# 在数组尾部追加多个元素
np.append(x,[15,16,17])
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 15, 16, 17])
# 使用 数组下标修改元素的值
x[0] = 99
# array([99, 1, 2, 3, 4, 5, 6, 7])
# 在指定位置插入数据
np.insert(x,0,54)
# array([54, 99, 1, 2, 3, 4, 5, 6, 7])
# 创建一个多维数组
x = np.array([[1,2,3],[11,22,33],[111,222,333]])
'''
array([[ 1, 2, 3],
[ 11, 22, 33],
[111, 222, 333]])
'''
# 修改第 0 行第 2 列的元素值
x[0,2] = 9
'''
array([[ 1, 2, 9],
[ 11, 22, 33],
[111, 222, 333]])
'''
# 行数大于等于 1 的,列数大于等于 1 的置为 0
x[1:,1:] = 1
'''
array([[ 1, 2, 9],
[ 11, 1, 1],
[111, 1, 1]])
'''
# 同时修改多个元素值
x[1:,1:] = [7,8]
'''
array([[ 1, 2, 9],
[ 11, 7, 8],
[111, 7, 8]])
'''
x[1:,1:] = [[7,8],[9,10]]
'''
array([[ 1, 2, 9],
[ 11, 7, 8],
[111, 9, 10]])
'''
Numpy创建数组
# 导入numpy 并赋予别名 np
import numpy as np
# 创建数组的常用的几种方式(列表,元组,range,arange,linspace(创建的是等差数组),zeros(全为 0 的数组),ones(全为 1 的数组),logspace(创建的是对数数组))
# 列表方式
np.array([1,2,3,4])
# array([1, 2, 3, 4])
# 元组方式
np.array((1,2,3,4))
# array([1, 2, 3, 4])
# range 方式
np.array(range(4)) # 不包含终止数字
# array([0, 1, 2, 3])
# 使用 arange(初始位置=0,末尾,步长=1)
np.arange(1,8,2)
# array([1, 3, 5, 7])
np.arange(8)
# array([0, 1, 2, 3, 4, 5, 6, 7])
# 使用 linspace(起始数字,终止数字,包含数字的个数[,endpoint = False]) 生成等差数组
# 生成等差数组,endpoint 为 True 则包含末尾数字
np.linspace(1,3,4,endpoint=False)
# array([1. , 1.5, 2. , 2.5])
np.linspace(1,3,4,endpoint=True)
# array([1. , 1.66666667, 2.33333333, 3. ])
# 创建全为零的一维数组
np.zeros(3)
# 创建全为一的一维数组
np.ones(4)
# array([1., 1., 1., 1.])
np.linspace(1,3,4)
# array([1. , 1.66666667, 2.33333333, 3. ])
# np.logspace(起始数字,终止数字,数字个数,base = 10) 对数数组
np.logspace(1,3,4)
# 相当于 10 的 linspace(1,3,4) 次方
# array([ 10. , 46.41588834, 215.443469 , 1000. ])
np.logspace(1,3,4,base = 2)
# 2 的 linspace(1,3,4) 次方
# array([2. , 3.1748021, 5.0396842, 8. ])
# 创建二维数组(列表嵌套列表)
np.array([[1,2,3],[4,5,6]])
'''
array([[1, 2, 3],
[4, 5, 6]])
'''
# 创建全为零的二维数组
# 两行两列
np.zeros((2,2))
'''
array([[0., 0.],
[0., 0.]])
'''
# 三行三列
np.zeros((3,2))
'''
array([[0., 0.],
[0., 0.],
[0., 0.]])
'''
# 创建一个单位数组
np.identity(3)
'''
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
'''
# 创建一个对角矩阵,(参数为对角线上的数字)
np.diag((1,2,3))
'''
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
'''
Numpy改变数组的形状
import numpy as np
n = np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 查看数组的大小
n.size
# 10
# 将数组分为两行五列
n.shape = 2,5
'''
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
'''
# 显示数组的维度
n.shape
# (2, 5)
# 设置数组的维度,-1 表示自动计算
n.shape = 5,-1
'''
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
'''
# 将新数组设置为调用数组的两行五列并返回
x = n.reshape(2,5)
'''
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
'''
x = np.arange(5)
# 将数组设置为两行,没有数的设置为 0
x.resize((2,10))
'''
array([[0, 1, 2, 3, 4, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
'''
# 将 x 数组的两行五列形式显示,不改变 x 的值
np.resize(x,(2,5))
'''
array([[0, 1, 2, 3, 4],
[0, 0, 0, 0, 0]])
'''
Numpy数组排序
import numpy as np
x = np.array([1,4,5,2])
# array([1, 4, 5, 2])
# 返回排序后元素的原下标
np.argsort(x)
# array([0, 3, 1, 2], dtype=int64)
# 输出最大值的下标
x.argmax( )
# 2
# 输出最小值的下标
x.argmin( )
# 0
# 对数组进行排序
x.sort( )
print(x)
# [1 2 4 5]
Numpy数组的函数
import numpy as np
# 将 0~100 10等分
x = np.arange(0,100,10)
# array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
# 每个数组元素对应的正弦值
np.sin(x)
'''
array([ 0. , -0.54402111, 0.91294525, -0.98803162, 0.74511316,
-0.26237485, -0.30481062, 0.77389068, -0.99388865, 0.89399666])
'''
# 每个数组元素对应的余弦值
np.cos(x)
'''
array([ 1. , -0.83907153, 0.40808206, 0.15425145, -0.66693806,
0.96496603, -0.95241298, 0.6333192 , -0.11038724, -0.44807362])
'''
# 对参数进行四舍五入
np.round(np.cos(x))
# array([ 1., -1., 0., 0., -1., 1., -1., 1., -0., -0.])
# 对参数进行上入整数 3.3->4
np.ceil(x/3)
# array([ 0., 4., 7., 10., 14., 17., 20., 24., 27., 30.])
# 分段函数
x = np.random.randint(0,10,size=(1,10))
# array([[0, 3, 6, 7, 9, 4, 9, 8, 1, 8]])
# 大于 4 的置为 0
np.where(x > 4,0,1)
# array([[1, 1, 0, 0, 0, 1, 0, 0, 1, 0]])
# 小于 4 的乘 2 ,大于 7 的乘3
np.piecewise(x,[x<4,x>7],[lambda x:x*2,lambda x:x*3])
# array([[ 0, 6, 0, 0, 27, 0, 27, 24, 2, 24]])
Numpy数组的运算
import numpy as np
x = np.array((1,2,3,4,5))
# 使用 * 进行相乘
x*2
# array([ 2, 4, 6, 8, 10])
# 使用 / 进行相除
x / 2
# array([0.5, 1. , 1.5, 2. , 2.5])
2 / x
# array([2. , 1. , 0.66666667, 0.5 , 0.4 ])
# 使用 // 进行整除
x//2
# array([0, 1, 1, 2, 2], dtype=int32)
10//x
# array([10, 5, 3, 2, 2], dtype=int32)
# 使用 ** 进行幂运算
x**3
# array([ 1, 8, 27, 64, 125], dtype=int32)
2 ** x
# array([ 2, 4, 8, 16, 32], dtype=int32)
# 使用 + 进行相加
x + 2
# array([3, 4, 5, 6, 7])
# 使用 % 进行取模
x % 3
# array([1, 2, 0, 1, 2], dtype=int32)
# 数组与数组之间的运算
# 使用 + 进行相加
np.array([1,2,3,4]) + np.array([11,22,33,44])
# array([12, 24, 36, 48])
np.array([1,2,3,4]) + np.array([3])
# array([4, 5, 6, 7])
n = np.array((1,2,3))
# +
n + n
# array([2, 4, 6])
n + np.array([4])
# array([5, 6, 7])
# *
n * n
# array([1, 4, 9])
n * np.array(([1,2,3],[4,5,6],[7,8,9]))
'''
array([[ 1, 4, 9],
[ 4, 10, 18],
[ 7, 16, 27]])
'''
# -
n - n
# array([0, 0, 0])
# /
n/n
# array([1., 1., 1.])
# **
n**n
# array([ 1, 4, 27], dtype=int32)
x = np.array((1,2,3))
y = np.array((4,5,6))
# 数组的内积运算(对应位置上元素相乘)
np.dot(x,y)
# 32
sum(x*y)
# 32
# 布尔运算
n = np.random.rand(4)
# array([0.53583849, 0.09401473, 0.07829069, 0.09363152])
# 判断数组中的元素是否大于 0.5
n > 0.5
# array([ True, False, False, False])
# 将数组中大于 0.5 的元素显示
n[n>0.5]
# array([0.53583849])
# 找到数组中 0.05 ~ 0.4 的元素总数
sum((n > 0.05)&(n < 0.4))
# 3
# 是否都大于 0.2
np.all(n > 0.2)
# False
# 是否有元素小于 0.1
np.any(n < 0.1)
# True
# 数组与数组之间的布尔运算
a = np.array([1,4,7])
# array([1, 4, 7])
b = np.array([4,3,7])
# array([4, 3, 7])
# 在 a 中是否有大于 b 的元素
a > b
# array([False, True, False])
# 在 a 中是否有等于 b 的元素
a == b
# array([False, False, True])
# 显示 a 中 a 的元素等于 b 的元素
a[a == b]
# array([7])
# 显示 a 中的偶数且小于 5 的元素
a[(a%2 == 0) & (a < 5)]
# array([4])
Numpy访问数组元素
import numpy as np
n = np.array(([1,2,3],[4,5,6],[7,8,9]))
'''
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
'''
# 第一行元素
n[0]
# array([1, 2, 3])
# 第一行第三列元素
n[0,2]
# 3
# 第一行和第二行的元素
n[[0,1]]
'''
array([[1, 2, 3],
[4, 5, 6]])
'''
# 第一行第三列,第三行第二列,第二行第一列
n[[0,2,1],[2,1,0]]
# array([3, 8, 4])
a = np.arange(8)
# array([0, 1, 2, 3, 4, 5, 6, 7])
# 将数组倒序
a[::-1]
# array([7, 6, 5, 4, 3, 2, 1, 0])
# 步长为 2
a[::2]
# array([0, 2, 4, 6])
# 从 0 到 4 的元素
a[:5]
# array([0, 1, 2, 3, 4])
c = np.arange(16)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
c.shape = 4,4
'''
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
'''
# 第一行,第三个元素到第五个元素(如果没有则输出到末尾截止)
c[0,2:5]
# array([2, 3])
# 第二行元素
c[1]
# array([4, 5, 6, 7])
# 第三行到第六行,第三列到第六列
c[2:5,2:5]
'''
array([[10, 11],
[14, 15]])
'''
# 第二行第三列元素和第三行第四列元素
c[[1,2],[2,3]]
# array([ 6, 11])
# 第一行和第三行的第二列到第三列的元素
c[[0,2],1:3]
'''
array([[ 1, 2],
[ 9, 10]])
'''
# 第一列和第三列的所有横行元素
c[:,[0,2]]
'''
array([[ 0, 2],
[ 4, 6],
[ 8, 10],
[12, 14]])
'''
# 第三列所有元素
c[:,2]
# array([ 2, 6, 10, 14])
# 第二行和第四行的所有元素
c[[1,3]]
'''
array([[ 4, 5, 6, 7],
[12, 13, 14, 15]])
'''
# 第一行的第二列,第四列元素,第四行的第二列,第四列元素
c[[0,3]][:,[1,3]]
'''
array([[ 1, 3],
[13, 15]])
'''
TCP 客户端
"""
创建客户端
绑定服务器ip地址和端口号(端口号是整型)
与服务器建立连接
发送给服务器要发送的数据(转码)
接收服务器返回的数据
关闭客户端
"""
from socket import *
# 创建tcp socket
tcp_client_socket = socket(AF_INET,SOCK_STREAM)
# tcp 使用STREAM
# udp 使用DGRAM
# 连接的服务器及端口号
server_ip = input("请输入服务器ip地址:")
server_port = eval(input("请输入服务器端口号:"))
# 建立连接
tcp_client_socket.connect((server_ip,server_port))#联系ip地址和端口号
# print(type((server_ip,server_port)))元组类型
# 提示用户输入数据
send_data = input("请输入要发送的数据")
tcp_client_socket.send(send_data.encode('gbk'))#对发送的数据进行转码
# 接收对方发送来的数据
recv_data = tcp_client_socket.recv(1024)
print("接收到的数据是:%s"%(recv_data.decode('gbk')))
# 关闭套接字
tcp_client_socket.close()
"""
TCP使用AF_INET,SOCK_STREAM
TCP需要先建立连接,使用connect函数连接服务器端ip地址和端口号(绑定在元组中)
使用send发送转码后的数据,str->bytes 使用encode
接收数据recv (1024)函数 最大接收1024字节
关闭客服端close()
"""
TCP 服务器端
"""
建立tcp服务器
绑定本地服务器信息(ip地址,端口号)
进行监听
获取监听数据(监听到的客户端和地址)
使用监听到的客户端client_socket获取数据
输出获取到的数据
并返回给客户端一个数据
关闭服务器端
"""
from socket import *
# 创建tcp socket
tcp_server_socket = socket(AF_INET,SOCK_STREAM)
# 本地信息 ip地址+端口号
local_address = (('',7788))
# 绑定本地地址,主机号可以不写,固定端口号
tcp_server_socket.bind(local_address)#绑定ip地址和端口号
# 使用socket默认为发送,服务端主要接收数据
tcp_server_socket.listen(128)#对客户端进行监听
# 当接收到数据后,client_socket用来为客户端服务
client_socket,client_address = tcp_server_socket.accept()
# 接收对方发送的数据,客户端socket对象和客户端ip地址
recv_data = client_socket.recv(1024)#使用接收到的客户端对象接收数据
print("接收到的数据为:%s"%(recv_data.decode('gbk')))#对数据进行转码,并输出
# 发送数据到客户端
client_socket.send("Hany在tcp客户端发送数据".encode('gbk'))
# 关闭客户端,如果还有客户需要进行连接,等待下次
client_socket.close()##关闭服务器端
"""
服务端先要绑定信息,使用bind函数((ip地址(默认为''即可),端口号))
进行监听listen(128) 接收监听到的数据 accept() 客户服务对象,端口号
使用客户服务对象,接收数据recv(1024) 输出接收到的bytes->str decode转码 数据
使用gbk 是因为windows使用gbk编码
服务器端发送数据给刚刚监听过的客户端send函数,str->bytes类型
关闭服务器端
"""
UDP 绑定信息
"""
建立->绑定本地ip地址和端口号->接收数据->转码输出->关闭客户端
"""
from socket import *
udp_socket = socket(AF_INET,SOCK_DGRAM)
# 绑定本地的相关信息,如果网络程序不绑定,则系统会随机分配
# UDP使用SOCK_DGRAM
local_addr = ('',7788)#ip地址可以不写
udp_socket.bind(local_addr)#绑定本地ip地址
# 接收对方发送的数据
recv_data = udp_socket.recvfrom(1024)#UDP使用recvfrom方法进行接收
# 输出接收内容
print(recv_data[0].decode('gbk'))
print(recv_data[1])#ip地址+端口号
udp_socket.close()
"""
UDP使用AF_INET,SOCK_DGRAM
绑定ip地址和端口号(固定端口号)
接收recvfrom(1024)传来的元组 (数据,端口号)
数据是以bytes类型传过来的,需要转码decode('gbk')
"""
UDP 网络程序-发送_接收数据
"""
创建udp连接
发送数据给
"""
from socket import *
# 创建udp套接字,使用SOCK_DGRAM
udp_socket = socket(AF_INET,SOCK_DGRAM)
# 准备接收方的地址
dest_addr = ('',8080)#主机号,固定端口号
# 从键盘获取数据
send_data = input("请输入要发送的数据")
# 发送数据到指定的电脑上
udp_socket.sendto(send_data.encode('UTF-8'),dest_addr)#使用sendto方法进行发送,发送的数据,ip地址和端口号
# 等待接收双方发送的数据
recv_data = udp_socket.recvfrom(1024)# 1024表示本次接收的最大字节数
# 显示对方发送的数据,recv_data是一个元组,第一个为对方发送的数据,第二个是ip和端口
print(recv_data[0].decode('gbk'))
# 发送的消息
print(recv_data[1])
# ip地址
# 关闭套接字
udp_socket.close()
WSGI应用程序示例
import time
# WSGI允许开发者自由搭配web框架和web服务器
def app(environ,start_response):
status = '200 OK'
response_headers = [('Content-Type','text/html')]
start_response(status,response_headers)
return str(environ)+" Hello WSGI ---%s----"%(time.ctime())
print(time.ctime()) #Tue Jan 14 21:55:35 2020
定义 WSGI 接口
# WSGI服务器调用
def application(environ,start_response):
start_response('200 OK',[('Content-Type','text/html')])
return 'Hello World'
'''
environ: 包含HTTP请求信息的dict对象
start_response: 发送HTTP响应的函数
'''
encode 和 decode 的使用
txt = '我是字符串'
txt_encode = txt.encode()
print(txt)
# 我是字符串
print(txt_encode)
# b'\xe6\x88\x91\xe6\x98\xaf\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2'
print(type(txt))
#
print(type(txt_encode))
#
txt_copy = txt_encode.decode( )
print(txt_copy)
# 我是字符串
print(type(txt_copy))
#
# str->bytes encode
# bytes->str decode
abs,all,any函数的使用
'''
abs函数:如果参数为实数,则返回绝对值
如果参数为复数,则返回复数的模
'''
a = 6
b = -6
c = 0
# print("a = {0} , b = {1} , c = {2}".format(abs(a),abs(b),abs(c)))
# a = 6 , b = 6 , c = 0
# 负数变为正数,正数不变,零不变
d = 3 + 4j
# print("d的模为 = {0}".format(abs(d)))
# d的模为 = 5.0
'''
总结:返回值是本身的数: 正数,0
返回值是相反数的数: 负数
返回值是模: 复数
'''
'''
all函数,接收一个迭代器,如果迭代器对象都为真,则返回True
有一个不为真,就返回False
'''
a = 6
b = -6
c = 0
d = 1
# print(all([a,b,c]))
# False
# 因为 c 为 0 ,有一个假,则为 False
# print(all([a,b,d]))
# True
# 都为真,实数不为 0 则为真
s = ''
# print(all(s))
# True 字符串为空,返回值为True
e = [0+0j] #all只接收可迭代对象,复数和实数都要使用列表
# print(all(e))
# False
a = ['']
# print(all(a))
# False
# #''空字符串被列表化之后,结果为False
b = []
# print(all(b))
# True 空列表返回为 True
c = [0]
# print(all(c))
# False 列表中存在 0,返回False
d = {}
# print(all(d))
# True 空字典返回值为True
e = set()
# print(all(e))
# True 空集合返回值为True
f = [set()]
# print(all(f))
# False 列表中为空集合元素时,返回False
g = [{}]
# print(all(g))
# False 列表中为空字典时,返回False
'''
总结: True: '' , [] , 除了 0 的实数, {} , set()
False: [''] , [0+0j] , [0] ,[set()] ,[{}]
'''
'''
any函数:接收一个迭代器,如果迭代器中只要有一个元素为真,就返回True
如果迭代器中元素全为假,则返回False
'''
lst = [0,0,1]
# print(any(lst))
# True 因为 1 为真,当存在一个元素为真时,返回True
'''
总结:只要有一个元素为真,则返回True
'''
# 文件的某些操作(以前发过类似的)
#
# 文件写操作
'''
w 写入操作 如果文件存在,则清空内容后进行写入,不存在则创建
a 写入操作 如果文件存在,则在文件内容后追加写入,不存在则创建
with 使用 with 语句后,系统会自动关闭文件并处理异常
'''
import os
print(os.path)
from time import ctime
# 使用 w 方式写入文件
f = open(r"test.txt","w",encoding = "utf-8")
print(f.write("该用户于 {0} 时刻,进行了文件写入".format(ctime())))
f.close()
# 使用 a 方式写入文件
f = open(r"text.txt","a",encoding = 'utf-8')
print(f.write('使用 a 方式进行写入 {0} '.format(ctime())))
f.close()
# 使用 with 方式,系统自动关闭文件并处理异常情况
with open(r"text.txt","w") as f :
'''with方法,对文件进行关闭并处理异常结果'''
f.write('{0}'.format(ctime()))
# 文件读操作
import os
def mkdir(path):
'''创建文件夹,先看是否存在该文件,然后再创建'''
# 如果存在,则不进行创建
is_exist = os.path.exists(path)
if not is_exist:
# 如果不存在该路径
os.mkdir(path)
def open_file(file_name):
'''打开文件,并返回读取到的内容'''
f = open(file_name) #使用 f 接收文件对象
f_lst = f.read( ) #进行读取文件
f.close() #使用完文件后,关闭
return f_lst #返回读取到的内容
# 获取后缀名
import os
'''os.path.splitext('文件路径'),获取后缀名'''
# 将文件路径后缀名和前面进行分割,返回类型为元组类型
file_text = os.path.splitext('./data/py/test.py')
# print(type(file_ext)) #元组类型
front,text = file_text
# front 为元组的第一个元素
# ext 为元组的第二个元素
print(front,file_text[0])
# ./data/py/test ./data/py/test
print(text,file_text[1])
# .py .py
''' os.path.splitext('文件路径')'''
# 路径中的后缀名
import os
'''使用os.path.split('文件路径') 获取文件名'''
file_text = os.path.split('./data/py/test.py')
# print(type(file_text))
# 元组类型
'''第一个元素为文件路径,第二个参数为文件名'''
path,file_name = file_text
print(path)
# ./data/py
print(file_name)
# test.py
'''splitext获取文件后缀名'''
pymysql 数据库基础应用
'''
开始
创建 connection
获取cursor
执行查询,获取数据,处理数据
关闭cursor
关闭connection
结束
'''
from pymysql import *
conn = connect(host='localhost',port=3306,database=hany_vacation,user='root',password='root',charset='utf8')
# conn = connect(host连接的mysql主机,port连接的mysql的主机,
# database数据库名称,user连接的用户名,password连接的密码,charset采用的编码方式)
# 方法:commit()提交,close()关闭连接,cursor()返回Cursor对象,执行sql语句并获得结果
# 主要执行的sql语句:select , insert , update , delete
cs1 = conn.cursor()
# 对象拥有的方法:
'''
close()关闭
execute(operation[,parameters])执行语句,返回受影响的行数,主要执行insert,update,delete,create,alter,drop语句
fetchone()执行查询语句,获取查询结果集的第一个行数据,返回一个元组
fetchall()执行查询语句,获取结果集的所有行,一行构成一个元组,再将这些元组装入一个元组返回
'''
# 对象的属性
'''
rowcount 只读属性,表示最近一次execute()执行后受影响的行数
connection 获取当前连接的对象
'''
数据库进行参数化,查询一行或多行语句
参数化
from pymysql import *
def main():
find_name = input("请输入物品名称")
conn = connect(host='localhost',port=3306,user='root',password='root',database='jing_dong',charset='utf8')
# 主机名、端口号、用户名、密码、数据库名、字符格式
cs1 = conn.cursor()#获取游标
# 构成参数列表
params = [find_name]
# 对查询的数据,使用变量进行赋值
count = cs1.execute('select * from goods where name=%s'%(params))
print(count)
result = cs1.fetchall()
# 输出所有数据
print(result)
# 先关闭游标、后关闭连接
cs1.close()
conn.close()
if __name__ == '__main__':
main()
查询一行语句
from pymysql import *
import time
def main():
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='root',database='jing_dong',charset='utf8')
# 获得Cursor对象
cs1 = conn.cursor()
# 执行select语句,并返回受影响的行数:查询一条数据
count = cs1.execute('select id,name from goods where id>=4')
# count = cs1.execute('select id,name from goods where id between 4 and 15')
# 打印受影响的行数
print("查询到%d条数据:" % count)
for i in range(count):
# 获取查询的结果
result = cs1.fetchone() #每次只输出一条数据 fetchall全部输出
# 打印查询的结果
time.sleep(0.5)
print(result)
# 获取查询的结果
# 关闭Cursor对象
cs1.close()
conn.close()
if __name__ == '__main__':
main()
from pymysql import *
def main():
# 创建Connection连接
conn = connect(host='localhost',port=3306,user='root',password='root',database='jing_dong',charset='utf8')
# 获得Cursor对象
cs1 = conn.cursor()
# 执行select语句,并返回受影响的行数:查询一条数据
count = cs1.execute('select id,name from goods where id>=4')
# 打印受影响的行数
print("查询到%d条数据:" % count)
# for i in range(count):
# # 获取查询的结果
# result = cs1.fetchone()
# # 打印查询的结果
# print(result)
# # 获取查询的结果
result = cs1.fetchall()#直接一行输出
print(result)
# 关闭Cursor对象
cs1.close()
conn.close()
if __name__ == '__main__':
main()
二分法查找
def binary_search(alist, item):
first = 0
last = len(alist) - 1
while first <= last:
midpoint = (first + last) // 2
if alist[midpoint] == item:
return True
elif item < alist[midpoint]:
last = midpoint - 1
else:
first = midpoint + 1
return False
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42, ]
print(binary_search(testlist, 3))
print(binary_search(testlist, 13))
# 递归使用二分法查找数据
def binary_search(alist, item):
if len(alist) == 0:
return False
else:
midpoint = len(alist)//2
if alist[midpoint]==item:
return True
else:
if item < alist[midpoint]:
return binary_search(alist[:midpoint],item)
#从开始到中间
else:#item元素大于alist[midpoint]
return binary_search(alist[midpoint+1:],item)
#从中间到最后
testlist = [0, 1, 2, 8, 13, 17, 19, 32, 42,]
print(binary_search(testlist, 3))
print(binary_search(testlist, 13))
正则表达式_合集上
$通配符,匹配字符串结尾
import re
email_list = ["[email protected]", "[email protected]", "[email protected]"]
for email in email_list:
ret = re.match("[\w]{4,20}@163\.com$", email)
# \w 匹配字母或数字
# {4,20}匹配前一个字符4到20次
if ret:
print("%s 是符合规定的邮件地址,匹配后的结果是:%s" % (email, ret.group()))
elif ret == None :
print("%s 不符合要求" % email)
'''
[email protected] 是符合规定的邮件地址,匹配后的结果是:[email protected]
[email protected] 不符合要求
[email protected] 不符合要求
'''
re.match匹配
import re
# re.match匹配字符(仅匹配开头)
string = 'Hany'
# result = re.match(string,'123Hany hanyang')
result = re.match(string,'Hany hanyang')
# 使用group方法提取数据
if result:
print("匹配到的字符为:",result.group( ))
else:
print("没匹配到以%s开头的字符串"%(string))
'''匹配到的字符为: Hany'''
re中findall用法
import re
ret = re.findall(r"\d+","Hany.age = 22, python.version = 3.7.5")
# 输出全部找到的结果 \d + 一次或多次
print(ret)
# ['22', '3', '7', '5']
re中search用法
import re
ret = re.search(r"\d+",'阅读次数为:9999')
# 只要找到规则即可,从头到尾
print(ret.group())
'''9999'''
re中匹配 [ ] 中列举的字符
import re
# 匹配[]中列举的字符
# 如果hello的首字符小写,那么正则表达式需要小写的h
ret = re.match("h","hello Python")
print(ret.group())
# 如果hello的首字符大写,那么正则表达式需要大写的H
ret = re.match("H","Hello Python")
print(ret.group())
# 大小写h都可以的情况
ret = re.match("[hH]","hello Python")
print(ret.group())
ret = re.match("[hH]","Hello Python")
print(ret.group())
ret = re.match("[hH]ello Python","Hello Python")
print(ret.group())
# 匹配0到9第一种写法
ret = re.match("[0123456789]Hello Python","7Hello Python")
print(ret.group())
# 匹配0到9第二种写法
ret = re.match("[0-9]Hello Python","7Hello Python")
print(ret.group())
# 匹配0到3 5到9的数字
ret = re.match("[0-3,5-9]Hello Python","7Hello Python")
print(ret.group())
# 下面这个正则不能够匹配到数字4,因此ret为None
ret = re.match("[0-3,5-9]Hello Python","4Hello Python")
# print(ret.group())
'''
h
H
h
H
Hello Python
7Hello Python
7Hello Python
7Hello Python
'''
re中匹配不是以4,7结尾的手机号码
import re
tels = ["13100001234", "18912344321", "10086", "18800007777"]
for tel in tels:
ret = re.match("1\d{9}[0-3,5-6,8-9]", tel)
if ret:
print("想要的手机号是:{}".format(ret.group()))
else:
print("%s 不是想要的手机号" % tel)
'''
13100001234 不是想要的手机号
想要的手机号是:18912344321
10086 不是想要的手机号
18800007777 不是想要的手机号
'''
re中匹配中奖号码
import re
# 匹配中奖号码
str2 = '17711602423'
pattern = re.compile('^(1[3578]\d)(\d{4})(\d{4})$')
print(pattern.sub(r'\1****\3',str2))
# r 字符串编码转化
'''177****2423'''
re中匹配中文字符
import re
pattern = re.compile('[\u4e00-\u9fa5]')
strs = '你好 Hello hany'
print(pattern.findall(strs))
pattern = re.compile('[\u4e00-\u9fa5]+')
print(pattern.findall(strs))
# ['你', '好']
# ['你好']
re中匹配任意字符
import re
# 匹配任意一个字符
ret = re.match(".","M")
# ret = re.match(".","M123") # M
# 匹配单个字符
print(ret.group())
ret = re.match("t.o","too")
print(ret.group())
ret = re.match("t.o","two")
print(ret.group())
'''
M
too
two
'''
re中匹配多个字符_加号
import re
#匹配前一个字符出现1次或无限次
names = ["name1", "_name", "2_name", "__name__"]
for name in names:
ret = re.match("[a-zA-Z_]+[\w]*",name)
if ret:
print("变量名 %s 符合要求" % ret.group())
else:
print("变量名 %s 非法" % name)
'''
变量名 name1 符合要求
变量名 _name 符合要求
变量名 2_name 非法
变量名 __name__ 符合要求
'''
re中匹配多个字符_星号
import re
# 匹配前一个字符出现0次或无限次
# *号只针对前一个字符
ret = re.match("[A-Z][a-z]*","M")
# ret = re.match("[a-z]*","M") 没有结果
print(ret.group())
ret = re.match("[A-Z][a-z]*","MnnM")
print(ret.group())
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
'''
M
Mnn
Aabcdef
'''
re中匹配多个字符_问号
import re
# 匹配前一个字符要么1次,要么0次
ret = re.match("[1-9]?[0-9]","7")
print(ret.group())
ret = re.match("[1-9]?","7")
print(ret.group())
ret = re.match("[1-9]?\d","33")
print(ret.group())
ret = re.match("[1-9]?\d[1-9]","33")
print(ret.group())
ret = re.match("[1-9]?\d","09")
print(ret.group())
'''
7
7
33
33
0
'''
re中匹配左右任意一个表达式
import re
ret = re.match("[1-9]?\d","8")
# ? 匹配1次或0次
print(ret.group()) # 8
ret = re.match("[1-9]?\d","78")
print(ret.group()) # 78
# 不正确的情况
ret = re.match("[1-9]?\d","08")
print(ret.group()) # 0
# 修正之后的
ret = re.match("[1-9]?\d$","08")
if ret:
print(ret.group())
else:
print("不在0-100之间")
# 添加|
ret = re.match("[1-9]?\d$|100","8")
print(ret.group()) # 8
ret = re.match("[1-9]?\d$|100","78")
print(ret.group()) # 78
ret = re.match("[1-9]?\d$|100","08")
# print(ret.group()) # 不是0-100之间
ret = re.match("[1-9]?\d$|100","100")
print(ret.group()) # 100
re中匹配数字
import re
# 普通的匹配方式
ret = re.match("嫦娥1号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥2号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥3号","嫦娥3号发射成功")
print(ret.group())
# 使用\d进行匹配
ret = re.match("嫦娥\d号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥\d号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥\d号","嫦娥3号发射成功")
print(ret.group())
'''
嫦娥1号
嫦娥2号
嫦娥3号
嫦娥1号
嫦娥2号
嫦娥3号
'''
re中对分组起别名
#(?P)
import re
ret = re.match(r"<(?P\w*)><(?P\w*)>.*", "www.itcast.cn
")
print(ret.group())
ret = re.match(r"<(?P\w*)><(?P\w*)>.*", "www.itcast.cn")
# (?P=name2) ----- (?P\w*)
# ret.group()
'''
www.itcast.cn
'''
re中将括号中字符作为一个分组
#(ab)将ab作为一个分组
import re
ret = re.match("\w{4,20}@163\.com", "[email protected]")
print(ret.group()) # [email protected]
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
print(ret.group()) # [email protected]
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
print(ret.group()) # [email protected]
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
if ret:
print(ret.group())
else:
print("不是163、126、qq邮箱") # 不是163、126、qq邮箱
'''
[email protected]
[email protected]
[email protected]
不是163、126、qq邮箱
'''
正则表达式_合集下
re中引用分组匹配字符串
import re
# 能够完成对正确的字符串的匹配
ret = re.match("<[a-zA-Z]*>\w*", "hh")
print(ret.group())
# 如果遇到非正常的html格式字符串,匹配出错会一起输出
ret = re.match("<[a-zA-Z]*>\w*", "hh")
#
print(ret.group())
# 正确的理解思路:如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么
# 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
ret = re.match(r"<([a-zA-Z]*)>\w*", "hh")
# 匹配第一个规则
print(ret.group())
# 因为2对<>中的数据不一致,所以没有匹配出来
test_label = "hh"
ret = re.match(r"<([a-zA-Z]*)>\w*", test_label)
if ret:
print(ret.group())
else:
print("%s 这是一对不正确的标签" % test_label)
'''
hh
hh
hh
hh 这是一对不正确的标签
'''
re中引用分组匹配字符串_2
import re
labels = ["www.itcast.cn
", "www.itcast.cn"]
for label in labels:
ret = re.match(r"<(\w*)><(\w*)>.*", label)
# <\2>和第二个匹配一样的内容
if ret:
print("%s 是符合要求的标签" % ret.group())
else:
print("%s 不符合要求" % label)
'''
www.itcast.cn
是符合要求的标签
www.itcast.cn 不符合要求
'''
re中提取区号和电话号码
import re
ret = re.match("([^-]*)-(\d+)","010-1234-567")
# 除了 - 的所有字符
# 对最后一个-前面的所有字符进行分组,直到最后一个数字为止
print(ret.group( ))
print(ret.group(1))#返回-之前的数据,不一定是最后一个-之前
print(ret.group(2))
re中的贪婪
import re
s= "This is a number 234-235-22-423"
r=re.match(".+(\d+-\d+-\d+-\d+)",s)
# .+ 尽量多的匹配任意字符,匹配到-前一个数字之前
# . 匹配任意字符
print(type(r))
print(r.group())
print(r.group(0))
print(r.group(1))
r=re.match(".+?(\d+-\d+-\d+-\d+)",s)
print(r.group())
print(r.group(1))#到数字停止贪婪
'''
This is a number 234-235-22-423
This is a number 234-235-22-423
4-235-22-423
This is a number 234-235-22-423
234-235-22-423
'''
import re
ret = re.match(r"aa(\d+)","aa2343ddd")
# 尽量多的匹配字符
print(ret.group())
# 使用? 将re贪婪转换为非贪婪
ret = re.match(r"aa(\d+?)","aa2343ddd")
# 只输出一个数字
print(ret.group())
'''
aa2343
aa2
'''
re使用split切割字符串
import re
ret = re.split(r":| ","info:XiaoLan 22 Hany.control")
# | 或 满足一个即可
print(ret)
str1 = 'one,two,three,four'
pattern = re.compile(',')
# 按照,将string分割后返回
print(pattern.split(str1))
# ['one', 'two', 'three', 'four']
str2 = 'one1two2three3four'
print(re.split('\d+',str2))
# ['one', 'two', 'three', 'four']
re匹配中subn,进行替换并返回替换次数
import re
pattern = re.compile('\d+')
strs = 'one1two2three3four'
print(pattern.subn('-',strs))
# ('one-two-three-four', 3) 3为替换的次数
re匹配中sub将匹配到的数据进行替换
# import re
# ret = re.sub(r"\d+", '替换的字符串998', "python = 997")
# # python = 替换的字符串998
# print(ret)
# # 将匹配到的数据替换掉,替换成想要替换的数据
# re.sub("规则","替换的字符串","想要替换的数据")
import re
def add(temp):
strNum = temp.group()
# 匹配到的数据.group()方式
print("原来匹配到的字符:",int(temp.group()))
num = int(strNum) + 5 #字符串强制转换
return str(num)
ret = re.sub(r"\d+", add, "python = 997")
# re.sub('正则规则','替换的字符串','字符串')
print(ret)
ret = re.sub(r"\d+", add, "python = 99")
print(ret)
pattern = re.compile('\d')
str1 = 'one1two2three3four'
print(pattern.sub('-',str1))
# one-two-three-four
print(re.sub('\d','-',str1))
# one-two-three-four
'''
原来匹配到的字符: 997
python = 1002
原来匹配到的字符: 99
python = 104
one-two-three-four
one-two-three-four
'''
re匹配的小例子
import re
src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg"
ret = re.search(r"https://.*?\.jpg", src)
print(ret.group())
res = re.compile('[a-zA-Z]{1}')
strs = '123abc456'
print(re.search(res,strs).group( ))
print(re.findall(res,strs)) #findall返回列表元素对象不具有group函数
# print(re.finditer(res,strs)) #返回迭代器对象
'''
https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg
a
['a', 'b', 'c']
'''
匹配前一个字符出现m次
import re
src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg"
ret = re.search(r"https://.*?\.jpg", src)
print(ret.group())
res = re.compile('[a-zA-Z]{1}')
strs = '123abc456'
print(re.search(res,strs).group( ))
print(re.findall(res,strs)) #findall返回列表元素对象不具有group函数
# print(re.finditer(res,strs)) #返回迭代器对象
'''
https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg
a
['a', 'b', 'c']
'''
引用分组
import re
strs = 'hello 123,world 456'
pattern = re.compile('(\w+) (\d+)')
# for i in pattern.finditer(strs):
# print(i.group(0))
# print(i.group(1))
# print(i.group(2))#当存在第二个分组时
'''hello 123
hello
123
world 456
world
456
'''
print(pattern.sub(r'\2 \1',strs))
# 先输出第二组,后输出第一组
print(pattern.sub(r'\1 \2',strs))
当findall遇到分组时,只匹配分组
import re
pattern = re.compile('([a-z])[a-z]([a-z])')
strs = '123abc456asd'
# print(re.findall(pattern,strs))
# [('a', 'c'), ('a', 'd')]返回分组匹配到的结果
result = re.finditer(pattern,strs)
for i in result:
print(i.group( )) #match对象使用group函数输出
print(i.group(0))#返回匹配到的所有结果
print(i.group(1))#返回第一个分组匹配的结果
print(i.group(2))#返回第二个分组匹配的结果
#
#
# 返回完整的匹配结果
'''
abc
abc
a
c
asd
asd
a
d
'''
线程_apply堵塞式
'''
创建三个进程,让三个进程分别执行功能,关闭进程
Pool 创建 ,apply执行 , close,join 关闭进程
'''
from multiprocessing import Pool
import os,time,random
def worker(msg):
# 创建一个函数,用来使进程进行执行
time_start = time.time()
print("%s 号进程开始执行,进程号为 %d"%(msg,os.getpid()))
# 使用os.getpid()获取子进程号
# os.getppid()返回父进程号
time.sleep(random.random()*2)
time_end = time.time()
print(msg,"号进程执行完毕,耗时%0.2f"%(time_end-time_start))
# 计算运行时间
if __name__ == '__main__':
po = Pool(3)#创建三个进程
print("进程开始")
for i in range(3):
# 使用for循环,运行刚刚创建的进程
po.apply(worker,(i,))#进程池调用方式apply堵塞式
# 第一个参数为函数名,第二个参数为元组类型的参数(函数运行会用到的形参)
#只有当进程执行完退出后,才会新创建子进程来调用请求
po.close()# 关闭进程池,关闭后po不再接收新的请求
# 先使用进程的close函数关闭,后使用join函数进行等待
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后
print("进程结束")
'''创建->apply应用->close关闭->join等待结束'''
线程_FIFO队列实现生产者消费者
import threading # 导入线程库
import time
from queue import Queue # 队列
class Producer(threading.Thread):
# 线程的继承类,修改 run 方法
def run(self):
global queue
count = 0
while True:
if queue.qsize() <1000:
for i in range(100):
count = count + 1
msg = '生成产品'+str(count)
queue.put(msg)#向队列中添加元素
print(msg)
time.sleep(1)
class Consumer(threading.Thread):
# 线程的继承类,修改 run 方法
def run(self):
global queue
while True:
if queue.qsize() >100 :
for i in range(3):
msg = self.name + '消费了' + queue.get() #获取数据
# queue.get()获取到数据
print(msg)
time.sleep(1)
if __name__ == '__main__':
queue = Queue()
# 创建一个队列
for i in range(500):
queue.put('初始产品'+str(i))
# 在 queue 中放入元素 使用 put 函数
for i in range(2):
p = Producer()
p.start()
# 调用Producer类的run方法
for i in range(5):
c = Consumer()
c.start()
线程_GIL最简单的例子
#解决多进程死循环
import multiprocessing
def deadLoop():
while True:
print("Hello")
pass
if __name__ == '__main__':
# 子进程死循环
p1 = multiprocessing.Process(target=deadLoop)
p1.start()
# 主进程死循环
deadLoop()
线程_multiprocessing实现文件夹copy器
import multiprocessing
import os
import time
import random
def copy_file(queue,file_name,source_folder_name,dest_folder_name):
f_read = open(source_folder_name+"/"+file_name,"rb")
f_write = open(source_folder_name+"/"+file_name,"wb")
while True:
time.sleep(random.random())
content = f_read.read(1024)
if content:
f_write.write(content)
else:
break
f_read.close()
f_write.close()
# 发送已经拷贝完毕的文件名字
queue.put(file_name)
def main():
# 获取要复制的文件夹
source_folder_name = input("请输入要复制的文件夹名字:")
# 整理目标文件夹
dest_folder_name = source_folder_name + "副本"
# 创建目标文件夹
try:
os.mkdir(dest_folder_name)#创建文件夹
except:
pass
# 获取这个文件夹中所有的普通文件名
file_names = os.listdir(source_folder_name)
# 创建Queue
queue = multiprocessing.Manager().Queue()
# 创建线程池
pool = multiprocessing.Pool(3)
for file_name in file_names:
# 向线程池中添加任务
pool.apply_async(copy_file,args=(queue,file_name,source_folder_name,dest_folder_name))#不堵塞执行
# 主进程显示进度
pool.close()
all_file_num = len(file_names)
while True:
file_name = queue.get()
if file_name in file_names:
file_names.remove(file_name)
copy_rate = (all_file_num - len(file_names)) * 100 / all_file_num
print("\r%.2f...(%s)" % (copy_rate, file_name) + " " * 50, end="")
if copy_rate >= 100:
break
print()
if __name__ == "__main__":
main()
线程_multiprocessing异步
from multiprocessing import Pool
import time
import os
def test():
print("---进程池中的进程---pid=%d,ppid=%d--"%(os.getpid(),os.getppid()))
for i in range(3):
print("----%d---"%i)
time.sleep(1)
return "hahah"
def test2(args):
print("---callback func--pid=%d"%os.getpid())
print("---callback func--args=%s"%args)
if __name__ == '__main__':
pool = Pool(3)
pool.apply_async(func=test,callback=test2)
# 异步执行
time.sleep(5)
print("----主进程-pid=%d----"%os.getpid())
线程_Process实例
from multiprocessing import Process
import os
from time import sleep
def run_proc(name,age,**kwargs):
for i in range(10):
print("子进程运行中,名字为 = %s,年龄为 = %d,子进程 = %d..."%(name,age,os.getpid()))
print(kwargs)
sleep(0.5)
if __name__ == '__main__':
print("父进程: %d"%(os.getpid()))
pro = Process(target=run_proc,args=('test',18),kwargs={'kwargs':20})
print("子进程将要执行")
pro.start( )
sleep(1)
pro.terminate()#将进程进行终止
pro.join()
print("子进程已结束")
from multiprocessing import Process
import time
import os
#两个子进程将会调用的两个方法
def work_1(interval):
# intercal为挂起时间
print("work_1,父进程(%s),当前进程(%s)"%(os.getppid(),os.getpid()))
start_time = time.time()
time.sleep(interval)
end_time = time.time()
print("work_1,执行时间为%f"%(end_time-start_time))
def work_2(interval):
print("work_2,父进程(%s),当前进程(%s)"%(os.getppid(),os.getpid()))
start_time = time.time()
time.sleep(2)
end_time = time.time()
print("work_2执行时间为:%.2f"%(end_time-start_time))
if __name__ == '__main__':
print("进程Id:", os.getpid())
pro1 = Process(target=work_1, args=(2,))
pro2 = Process(target=work_2, name="pro2", args=(3,))
pro1.start()
pro2.start()
print("pro2.is_alive:%s" % (pro2.is_alive()))
print("pro1.name:", pro1.name)
print("pro1.pid=%s" % pro1.pid)
print("pro2.name=%s" % pro2.name)
print("pro2.pid=%s" % pro2.pid)
pro1.join()
print("pro1.is_alive:", pro1.is_alive())
线程_Process基础语法
"""
Process([group[,target[,name[,args[,kwargs]]]]])
group:大多数情况下用不到
target:表示这个进程实例所调用的对象 target=函数名
name:为当前进程实例的别名
args:表示调用对象的位置参数元组 args=(参数,)
kwargs:表示调用对象的关键字参数字典
"""
"""
常用方法:
is_alive( ):判断进程实例是否还在执行
join([timeout]):是否等待进程实例执行结束或等待多少秒
start():启动进程实例(创建子进程)
run():如果没有给定target函数,对这个对象调用start()方法时,
就将执行对象中的run()方法
terminate():不管任务是否完成,立即停止
"""
"""
常用属性:
name:当前进程实例的别名,默认为Process-N,N从1开始
pid:当前进程实例的PID值
"""
线程_ThreadLocal
import threading
# 创建ThreadLocal对象
house = threading.local()
def process_paper():
user = house.user
print("%s是房子的主人,in %s"%(user,threading.current_thread().name))
def process_thread(user):
house.user = user
process_paper()
t1 = threading.Thread(target=process_thread,args=('Xiaoming',),name='佳木斯')
t2 = threading.Thread(target=process_thread,args=('Hany',),name='哈尔滨')
t1.start()
t1.join()
t2.start()
t2.join()
线程_互斥锁_Lock及fork创建子进程
"""
创建锁 mutex = threading.Lock()
锁定 mutex.acquire([blocking])
当blocking为True时,当前线程会阻塞,直到获取到这个锁为止
默认为True
当blocking为False时,当前线程不会阻塞
释放 mutex.release()
"""
from threading import Thread,Lock
g_num = 0
def test1():
global g_num
for i in range(100000):
mutexFlag = mutex.acquire(True)#通过全局变量进行调用函数
# True会发生阻塞,直到结束得到锁为止
if mutexFlag:
g_num += 1
mutex.release()
print("test1--g_num = %d"%(g_num))
def test2():
global g_num
for i in range(100000):
mutexFlag = mutex.acquire(True)
if mutexFlag:
g_num += 1
mutex.release()
print("----test2---g_num = %d "%(g_num))
mutex = Lock()
p1 = Thread(target=test1,)
# 开始进程
p1.start()
p2 = Thread(target=test2,)
p2.start()
print("----g_num = %d---"%(g_num))
fork创建子进程
import os
# fork()在windows下不可用
pid = os.fork()#返回两个值
# 操作系统创建一个新的子进程,复制父进程的信息到子进程中
# 然后父进程和子进程都会得到一个返回值,子进程为0,父进程为子进程的id号
if pid == 0:
print("哈哈1")
else:
print("哈哈2")
线程_gevent实现多个视频下载及并发下载
from gevent import monkey
import gevent
import urllib.request
#有IO操作时,使用patch_all自动切换
monkey.patch_all()
def my_downLoad(file_name, url):
print('GET: %s' % url)
resp = urllib.request.urlopen(url)
# 使用库打开网页
data = resp.read()
with open(file_name, "wb") as f:
f.write(data)
print('%d bytes received from %s.' % (len(data), url))
gevent.joinall([
gevent.spawn(my_downLoad, "1.mp4", 'http://oo52bgdsl.bkt.clouddn.com/05day-08-%E3%80%90%E7%90%86%E8%A7%A3%E3%80%91%E5%87%BD%E6%95%B0%E4%BD%BF%E7%94%A8%E6%80%BB%E7%BB%93%EF%BC%88%E4%B8%80%EF%BC%89.mp4'),
gevent.spawn(my_downLoad, "2.mp4", 'http://oo52bgdsl.bkt.clouddn.com/05day-03-%E3%80%90%E6%8E%8C%E6%8F%A1%E3%80%91%E6%97%A0%E5%8F%82%E6%95%B0%E6%97%A0%E8%BF%94%E5%9B%9E%E5%80%BC%E5%87%BD%E6%95%B0%E7%9A%84%E5%AE%9A%E4%B9%89%E3%80%81%E8%B0%83%E7%94%A8%28%E4%B8%8B%29.mp4'),
])
from gevent import monkey
import gevent
import urllib.request
# 有耗时操作时需要
monkey.patch_all()
def my_downLoad(url):
print('GET: %s' % url)
resp = urllib.request.urlopen(url)
data = resp.read()
print('%d bytes received from %s.' % (len(data), url))
gevent.joinall([
gevent.spawn(my_downLoad, 'http://www.baidu.com/'),
gevent.spawn(my_downLoad, 'http://www.itcast.cn/'),
gevent.spawn(my_downLoad, 'http://www.itheima.com/'),
])
线程_gevent自动切换CPU协程
import gevent
def f(n):
for i in range(n):
print (gevent.getcurrent(), i)
# gevent.getcurrent() 获取当前进程
g1 = gevent.spawn(f, 3)#函数名,数目
g2 = gevent.spawn(f, 4)
g3 = gevent.spawn(f, 5)
g1.join()
g2.join()
g3.join()
import gevent
def f(n):
for i in range(n):
print (gevent.getcurrent(), i)
#用来模拟一个耗时操作,注意不是time模块中的sleep
gevent.sleep(1)
g1 = gevent.spawn(f, 2)
g2 = gevent.spawn(f, 3)
g3 = gevent.spawn(f, 4)
g1.join()
g2.join()
g3.join()
import gevent
import random
import time
def coroutine_work(coroutine_name):
for i in range(10):
print(coroutine_name, i)
time.sleep(random.random())
gevent.joinall([
# 添加可以切换的协程
gevent.spawn(coroutine_work, "work0"),
gevent.spawn(coroutine_work, "work1"),
gevent.spawn(coroutine_work, "work2")
])
from gevent import monkey
import gevent
import random
import time
# 有耗时操作时需要
monkey.patch_all()#自动切换协程
# 将程序中用到的耗时操作的代码,换为gevent中自己实现的模块
def coroutine_work(coroutine_name):
for i in range(10):
print(coroutine_name, i)
time.sleep(random.random())
gevent.joinall([
gevent.spawn(coroutine_work, "work"),
gevent.spawn(coroutine_work, "work1"),
gevent.spawn(coroutine_work, "work2")
])
线程_使用multiprocessing启动一个子进程及创建Process 的子类
from multiprocessing import Process
import os
# 子进程执行的函数
def run_proc(name):
print("子进程运行中,名称:%s,pid:%d..."%(name,os.getpid()))
if __name__ == "__main__":
print("父进程为:%d..."%(os.getpid()))
# os.getpid()获取到进程名
pro = Process(target=run_proc,args=('test',))
# target=函数名 args=(参数,)
print("子进程将要执行")
pro.start()#进程开始
pro.join()#添加进程
print("子进程执行结束...")
from multiprocessing import Process
import time
import os
# 继承Process类
class Process_Class(Process):
def __init__(self,interval):
Process.__init__(self)
self.interval = interval
# 重写Process类的run方法
def run(self):
print("我是类中的run方法")
print("子进程(%s),开始执行,父进程为(%s)"%(os.getpid(),os.getppid()))
start_time = time.time()
time.sleep(2)
end_time = time.time()
print("%s执行时间为:%.2f秒" % (os.getpid(),end_time-start_time))
if __name__ == '__main__':
start_time = time.time()
print("当前进程为:(%s)"%(os.getpid()))
pro1 = Process_Class(2)
# 对一个不包含target属性的Process类执行start()方法,
# 会运行这个类中的run()方法,所以这里会执行p1.run()
pro1.start()
pro1.join()
end_time = time.time()
print("(%s)执行结束,耗时%0.2f" %(os.getpid(),end_time - start_time))
线程_共享全局变量(全局变量在主线程和子线程中不同)
from threading import Thread
import time
g_num = 100
def work1():
global g_num
for i in range(3):
g_num += 1
print("----在work1函数中,g_num 是 %d "%(g_num))
def work2():
global g_num
print("在work2中,g_num为 %d "%(g_num))
if __name__ == '__main__':
print("---线程创建之前 g_num 是 %d"%(g_num))
t1 = Thread(target=work1)
t1.start()
t2 = Thread(target=work2)
t2.start()
线程_多线程_列表当做实参传递到线程中
from threading import Thread
def work1(nums):
nums.append('a')
print('---在work1中---',nums)
def work2(nums):
print("-----在work2中----,",nums)
if __name__ == '__main__':
g_nums = [1,2,3]
t1 = Thread(target=work1,args=(g_nums,))
# target函数,args参数
t1.start()
t2 = Thread(target=work2,args=(g_nums,))
t2.start()
线程_threading合集
# 主线程等待所有子线程结束才结束
import threading
from time import sleep,ctime
def sing():
for i in range(3):
print("正在唱歌---%d"%(i))
sleep(2)
def dance():
for i in range(3):
print("正在跳舞---%d" % (i))
sleep(2)
if __name__ == '__main__':
print("----开始----%s"%(ctime()))
t_sing = threading.Thread(target=sing)
t_dance = threading.Thread(target=dance)
t_sing.start()
t_dance.start()
print("----结束----%s"%(ctime()))
#查看线程数量
import threading
from time import sleep,ctime
def sing():
for i in range(3):
print("正在唱歌---%d"%i)
sleep(1)
def dance():
for i in range(3):
print("正在跳舞---%d"%i)
sleep(i)
if __name__ == '__main__':
t_sing = threading.Thread(target=sing)
t_dance = threading.Thread(target=dance)
t_sing.start()
t_dance.start()
while True:
length = len(threading.enumerate())
print("当前运行的线程数为:%d"%(length))
if length<= 1:
break
sleep(0.5)
import threading
import time
class MyThread(threading.Thread):
# 重写 构造方法
def __init__(self, num, sleepTime):
threading.Thread.__init__(self)
self.num = num
# 类实例不同,num值不同
self.sleepTime = sleepTime
def run(self):
self.num += 1
time.sleep(self.sleepTime)
print('线程(%s),num=%d' % (self.name, self.num))
if __name__ == '__main__':
mutex = threading.Lock()
t1 = MyThread(100, 3)
t1.start()
t2 = MyThread(200, 1)
t2.start()
import threading
from time import sleep
g_num = 1
def test(sleepTime):
num = 1 #num为局部变量
sleep(sleepTime)
num += 1
global g_num #g_num为全局变量
g_num += 1
print('---(%s)--num=%d --g_num=%d' % (threading.current_thread(), num,g_num))
t1 = threading.Thread(target=test, args=(3,))
t2 = threading.Thread(target=test, args=(1,))
t1.start()
t2.start()
import threading
import time
class MyThread1(threading.Thread):
def run(self):
if mutexA.acquire():
print("A上锁了")
mutexA.release()
time.sleep(2)
if mutexB.acquire():
print("B上锁了")
mutexB.release()
mutexA.release()
class MyThread2(threading.Thread):
def run(self):
if mutexB.acquire():
print("B上锁了")
mutexB.release()
time.sleep(2)
if mutexA.acquire():
print("A上锁了")
mutexA.release()
mutexB.release()
# 先看B是否上锁,然后看A是否上锁
mutexA = threading.Lock()
mutexB = threading.Lock()
if __name__ == "__main__":
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()
多线程threading的执行顺序(不确定)
# 只能保证都执行run函数,不能保证执行顺序和开始顺序
import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm "+self.name+' @ '+str(i)
print(msg)
def test():
for i in range(5):
t = MyThread()
t.start()
if __name__ == '__main__':
test()
多线程threading的注意点
import threading
import time
class MyThread(threading.Thread):
# 重写threading.Thread类中的run方法
def run(self):
for i in range(3):#开始线程之后循环三次
time.sleep(1)
msg = "I'm "+self.name+'@'+str(i)
# name属性是当前线程的名字
print(msg)
if __name__ == '__main__':
t = MyThread()#使用threading.Thread的继承类
t.start()#继承线程之后要开始运行 start方法
线程_进程间通信Queue合集
# Queue的工作原理
from multiprocessing import Queue
q = Queue(3)#初始化一个Queue对象,最多可接收3条put消息
q.put("Info1")
q.put("Info2")
print("q是否满了",q.full())#查看q是否满了
q.put("Info3")
print("q是否满了",q.full())
try:
q.put_nowait("info4")
except:
print("消息列队已经满了,现有消息数量为:%s"%(q.qsize()))
# 使用q.qsize()查看数量
# 先验证是否满了,再写入
if not q.full():
q.put_nowait("info4")
# 读取信息时,先判断消息列队是否为空,再读取
if not q.empty():
print("开始读取")
for i in range(q.qsize()):
print(q.get_nowait())
from multiprocessing import Queue
from multiprocessing import Process
import os,time,random
def write(q):
for value in ['a','b','c']:
print("Put %s to q ..."%(value))
q.put(value)
time.sleep(random.random())
def read(q):
while True:
if not q.empty():
value = q.get(True)
print("Get %s from Queue..."%(value))
time.sleep(random.random())
else:
break
if __name__ == '__main__':
#父进程创建Queue,传给各个子进程
q = Queue()
pw = Process(target=write,args=(q,))
pr = Process(target=read,args=(q,))
pw.start()
# 等待pw结束
pw.join()
pr.start()
pr.join()
print("数据写入读写完成")
from multiprocessing import Manager,Pool
import os,time,random
# 名称为reader 输出子进程和父进程 os 输出q的信息
def reader(q):
print("reader启动,子进程:%s,父进程:%s"%(os.getpid(),os.getppid()))
for i in range(q.qsize()):#在0 ~ qsize范围内
print("获取到queue的信息:%s"%(q.get(True)))
def writer(q):
print("writer启动,子进程:%s,父进程:%s"%(os.getpid(),os.getppid()))
for i in "HanYang":#需要写入到 q 的数据
q.put(i)
if __name__ == '__main__':
print("%s 开始 "%(os.getpid()))
q = Manager().Queue()#Queue使用multiprocessing.Manager()内部的
po = Pool()#创建一个线程池
po.apply(writer,(q,))#使用apply阻塞模式
po.apply(reader,(q,))
po.close()#关闭
po.join()#等待结束
print("(%s) 结束"%(os.getpid()))
线程_进程池
from multiprocessing import Pool
import os,time,random
def worker(msg):
start_time = time.time()
print("(%s)开始执行,进程号为(%s)"%(msg,os.getpid()))
time.sleep(random.random()*2)
end_time = time.time()
print(msg,"(%s)执行完毕,执行时间为:%.2f"%(os.getpid(),end_time-start_time))
if __name__ == '__main__':
po = Pool(3)#定义一个进程池,最大进程数为3
for i in range(0,6):
po.apply_async(worker,(i,))
# 参数:函数名,(传递给目标的参数元组)
# 每次循环使用空闲的子进程调用函数,满足每个时刻都有三个进程在执行
print("---开始---")
po.close()
po.join()
print("---结束---")
"""
multiprocessing.Pool的常用函数:
apply_async(func[,args[,kwds]]):
使用非阻塞方式调用func,并行执行
args为传递给func的参数列表
kwds为传递给func的关键字参数列表
apply(func[,args[,kwds]])
使用堵塞方式调用func
堵塞方式:必须等待上一个进程退出才能执行下一个进程
close()
关闭Pool,使其不接受新的任务
terminate()
无论任务是否完成,立即停止
join()
主进程堵塞,等待子进程的退出
注:必须在terminate,close函数之后使用
"""
线程_可能发生的问题
from threading import Thread
g_num = 0
def test1():
global g_num
for i in range(1000000):
g_num += 1
print("---test1---g_num=%d"%g_num)
def test2():
global g_num
for i in range(1000000):
g_num += 1
print("---test2---g_num=%d"%g_num)
p1 = Thread(target=test1)
p1.start()
# time.sleep(3)
p2 = Thread(target=test2)
p2.start()
print("---g_num=%d---"%g_num)
内存泄漏
import gc
class ClassA():
def __init__(self):
print('对象产生 id:%s'%str(hex(id(self))))
def f2():
while True:
c1 = ClassA()
c2 = ClassA()
c1.t = c2#引用计数变为2
c2.t = c1
del c1#引用计数变为1 0才进行回收
del c2
#把python的gc关闭
gc.disable()
f2()
== 和 is 的区别
import copy
a = ['a','b','c']
b = a #b和a引用自同一块地址空间
print("a==b :",a==b)
print("a is b :",a is b)
c = copy.deepcopy(a)# 对a进行深拷贝
print("a的id值为:",id(a))
print("b的id值为:",id(b))
print("c的id值为:",id(c))#深拷贝,不同地址
print("a==c :",a==c)
print("a is c :",a is c)
"""
is 是比较两个引用是否指向了同一个对象(引用比较)。
== 是比较两个对象是否相等。
"""
'''
a==b : True
a is b : True
a的id值为: 2242989720448
b的id值为: 2242989720448
c的id值为: 2242989720640
a==c : True
a is c : False
'''
以下为类的小例子
__getattribute__小例子
class student(object):
def __init__(self,name=None,age=None):
self.name = name
self.age = age
def __getattribute__(self, item):#getattribute方法修改类的属性
if item == 'name':#如果为name属性名
print("XiaoMing被我拦截住了")
return "XiaoQiang " #返回值修改了name属性
else:
return object.__getattribute__(self,item)
def show(self):
print("姓名是: %s" %(self.name))
stu_one = student("XiaoMing",22)
print("学生姓名为:",stu_one.name)
print("学生年龄为:",stu_one.age)
'''
XiaoMing被我拦截住了
学生姓名为: XiaoQiang
学生年龄为: 22
'''
__new__方法理解
class Foo(object):
def __init__(self, *args, **kwargs):
pass
def __new__(cls, *args, **kwargs):
return object.__new__(cls, *args, **kwargs)
# 以上return等同于
# return object.__new__(Foo, *args, **kwargs)
class Child(Foo):
def __new__(cls, *args, **kwargs):
return object.__new__(cls, *args, **kwargs)
class Round2Float(float):
def __new__(cls,num):
num = round(num,2)
obj = float.__new__(Round2Float,num)
return obj
f=Round2Float(4.324599)
print(f)
'''派生不可变类型'''
ctime使用及datetime简单使用
from time import ctime,sleep
def Clock(func):
def clock():
print("现在是:",ctime())
func()
sleep(3)
print("现在是:",ctime())
return clock
@Clock
def func():
print("函数计时")
func()
import datetime
now = datetime.datetime.now()#获取当前时间
str = "%s"%(now.strftime("%Y-%m-%d-%H-%M-%S"))
"""
Y 年 y
m 月
d 号
H 时
M 分
S 秒
"""
# 设置时间格式
print(str)
functools函数中的partial函数及wraps函数
'''
partial引用函数,并增加形参
'''
import functools
def show_arg(*args,**kwargs):
print("args",args)
print("kwargs",kwargs)
q = functools.partial(show_arg,1,2,3)#1,2,3为默认值
# functools.partial(函数,形式参数)
q()#相当于将show_arg改写一下,然后换一个名字
q(4,5,6)#没有键值对,kwargs为空
q(a='python',b='Hany')
# 增加默认参数
w = functools.partial(show_arg,a = 3,b = 'XiaoMing')#a = 3,b = 'XiaoMing'为默认值
w()#当没有值时,输出默认值
w(1,2)
w(a = 'python',b = 'Hany')
import functools
def note(func):
"note function"
@functools.wraps(func)
#使用wraps函数消除test函数使用@note装饰器产生的副作用 .__doc__名称 改变
def wrapper():
"wrapper function"
print('note something')
return func()
return wrapper
@note
def test():
"test function"
print('I am test')
test()
print(test.__doc__)
gc 模块常用函数
1、gc.set_debug(flags) 设置gc的debug日志,一般设置为gc.DEBUG_LEAK
2、gc.collect([generation]) 显式进行垃圾回收,可以输入参数,0代表只检查第一代的对象,
1代表检查一,二代的对象,2代表检查一,二,三代的对象,如果不传参数,
执行一个full collection,也就是等于传2。 返回不可达(unreachable objects)对象的数目
3、gc.get_threshold() 获取的gc模块中自动执行垃圾回收的频率。
4、gc.set_threshold(threshold0[, threshold1[, threshold2]) 设置自动执行垃圾回收的频率。
5、gc.get_count() 获取当前自动执行垃圾回收的计数器,返回一个长度为3的列表
hashlib加密算法
# import hashlib
# mima = hashlib.md5()#创建hash对象,md5是信息摘要算法,生成128位密文
# print(mima)
# # mima.update('参数')使用参数更新哈希对象
# print(mima.hexdigest())#返回16进制的数字字符串
import hashlib
import datetime
KEY_VALUE = 'XiaoLiu'
now = datetime.datetime.now()
m = hashlib.md5()
# 创建一个MD5密文
str = "%s%s%s"%(KEY_VALUE," ",now.strftime("%Y-%m-%d"))
# strftime日期格式
m.update(str.encode('UTF-8'))
value = m.hexdigest()
# 以十六进制进行输出
print(str,value)
__slots__属性
使用__slots__时,子类不受影响
class Person(object):
__slots__ = ("name","age")
def __str__(self):
return "姓名:%s,年龄:%d"%(self.name,self.age)
p = Person()
class man(Person):
pass
m = man()
m.score = 78
print(m.score)
使用__slots__限制类添加的属性
class Person(object):
__slots__ = ("name","age")
def __str__(self):
return "姓名:%s,年龄:%d"%(self.name,self.age)
p = Person()
p.name = "Xiaoming"
p.age = 15
print(p)
try:
p.score = 78
except AttributeError :
print(AttributeError)
isinstance方法判断可迭代和迭代器
from collections import Iterable
print(isinstance([],Iterable))
print(isinstance( {}, Iterable))
print(isinstance( (), Iterable))
print(isinstance( 'abc', Iterable))
print(isinstance( '100', Iterable))
print(isinstance((x for x in range(10) ), Iterable))
'''
True
D:/见解/Python/Python代码/vacation/python高级/使用isinstance判断是否可以迭代.py:1: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
True
from collections import Iterable
True
True
True
True
'''
from collections import Iterator
print(isinstance( [ ], Iterator))
print(isinstance( 'abc', Iterator))
print(isinstance(() , Iterator))
print(isinstance( {} , Iterator))
print(isinstance( 123, Iterator))
print(isinstance( 5+2j, Iterator))
print(isinstance( (x for x in range(10)) , Iterator))
# 生成器可以是迭代器
'''
False
D:/见解/Python/Python代码/vacation/python高级/使用isinstance判断是否是迭代器.py:1: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3, and in 3.9 it will stop working
False
from collections import Iterator
False
False
False
False
True
'''
metaclass 拦截类的创建,并返回
def upper_attr(future_class_name, future_class_parents, future_class_attr):
#遍历属性字典,把不是__开头的属性名字变为大写
newAttr = {}
for name,value in future_class_attr.items():#遍历字典
if not name.startswith("__"):#如果不是以__开头
newAttr[name.upper()] = value
# 将future_class_attr字典中的键大写,然后赋值
return type(future_class_name, future_class_parents, newAttr)#第三个参数为新修改好的值(类名,父类,字典)
class Foo(object, metaclass=upper_attr):
# 使用upper_attr对类中值进行修改
bar = 'bip'#一开始创建Foo类时
print(hasattr(Foo, 'bar'))# hasattr查看Foo类中是否存在bar属性
print(hasattr(Foo, 'BAR'))
f = Foo()#实例化对象
print(f.BAR)#输出
timeit_list操作测试
'''
timeit库Timer函数
'''
from timeit import Timer
def test1():
l = list(range(1000))
def test2():
l = []
for i in range(1000):
l.append(i)
def test3():
l = []
for i in range(1000):
l = l + [i]
def test4():
l = [i for i in range(1000)]
if __name__ == '__main__':
# Timer函数,函数名,导入包
t1 = Timer("test1()","from __main__ import test1")
# timeit运行次数
print(t1.timeit(number = 1000))
t2 = Timer("test2()","from __main__ import test2")
print(t2.timeit(number =1000))
t3 = Timer("test3","from __main__ import test3")
print(t3.timeit(number=1000))
t4 = Timer("test4","from __main__ import test4")
print(t4.timeit(number=1000))
nonlocal 访问变量
def counter(start = 0):
def incr():
nonlocal start #分别保存每一个变量的临时值、类似yield
start += 1
return start
return incr
c1 = counter(5)
print(c1())
c2 = counter(50)
print(c2())
# c1 继续上次,输出接下来的值
print(c1())
print(c2())
pdb 进行调试
import pdb
a = 'aaa'
pdb.set_trace( )
b = 'bbb'
c = 'ccc'
final = a+b+c
print(final)
import pdb
a = 'aaa'
pdb.set_trace( )
b = 'bbb'
c = 'ccc'
pdb.set_trace()
final = a+b+c
print(final)
import pdb
def combine(s1,s2):
pdb.set_trace( )
s3 = s1 + s2
return s3
a = 'aaa'
pdb.set_trace( )
b = 'bbb'
c = 'ccc'
pdb.set_trace( )
final = combine(a,b)
print(final)
使用property取代getter和setter方法
class Days(object):
def __init__(self):
self.__days = 0
@property
def days(self):#获取函数,名字是days days 是get方法
return self.__days
@days.setter #get方法的set方法
def day(self,days):
self.__days = days
dd = Days()
print(dd.days)
dd.day = 15 #通过day函数设置__days的值
print(dd.days)
'''
0
15
'''
使用types库修改函数
import types
class ppp:
pass
p = ppp()#p为ppp类实例对象
def run(self):
print("run函数")
r = types.MethodType(run,p) #函数名,类实例对象
r()
'''
run函数
'''
type 创建类,赋予类\静态方法等
类方法
class ObjectCreator(object):
pass
@classmethod
def testClass(cls):
cls.temp = 666
print(cls.temp)
test = type("Test",(ObjectCreator,),{'testClass':testClass})
t = test()
t.testClass()#字典中的键
静态方法
class Test:
pass
@staticmethod
def TestStatic():
print("我是静态方法----------")
t = type('Test_two',(Test,),{"TestStatic":TestStatic})
print(type(t))
print(t.TestStatic)
print(t.TestStatic())
class Test:
pass
def Method():
return "定义了一个方法"
test2 = type("Test2",(Test,),{'Method':Method})
# 第一个参数为类名,第二个参数为父类(必须是元组类型),
# 第三个参数为类属性,不是实例属性
# print(type(test2))
# print(test2.Method())
print(hasattr(test2,'Method'))
# hasattr查看test2是否包含有Method方法
迭代器实现斐波那契数列
class FibIterator(object):
"""斐波那契数列迭代器"""
def __init__(self, n):
"""
:param n: int, 指明生成数列的前n个数
"""
self.n = n
# current用来保存当前生成到数列中的第几个数了
self.current = 0
# num1用来保存前前一个数,初始值为数列中的第一个数0
self.num1 = 0
# num2用来保存前一个数,初始值为数列中的第二个数1
self.num2 = 1
def __next__(self):
"""被next()函数调用来获取下一个数"""
if self.current < self.n:
num = self.num1
self.num1, self.num2 = self.num2, self.num1+self.num2
self.current += 1
return num
else:
raise StopIteration
def __iter__(self):
"""迭代器的__iter__返回自身即可"""
return self
if __name__ == '__main__':
fib = FibIterator(10)
for num in fib:
print(num, end=" ")
在( ) 中使用推导式 创建生成器
G = (x*2 for x in range(4))
print(G)
print(G.__next__())
print(next(G))#两种方法等价
# G每一次读取,指针都会下移
for x in G:
print(x,end = " ")
动态给类的实例对象 或 类 添加属性
class Person(object):
def __init__(self,name = None,age = None):
self.name = name
self.age = age
def __str__(self):
return "%s 的年龄为 %d 岁 %s性"%(self.name,self.age,self.sex)
pass
Xiaoming = Person('小明',20)
Xiaoming.sex = '男'#只有Xiaoming对象拥有sex属性
print(Xiaoming)
小明 的年龄为 20 岁 男性
class Person(object):
def __init__(self,name = None,age = None):
self.name = name
self.age = age
def __str__(self):
return "%s 的年龄为 %d 岁 %s性"%(self.name,self.age,self.sex)
Xiaoming = Person('小明',20)
Xiaolan = Person('小兰',19)
Person.sex = None #类创建sex默认属性为None
Xiaolan.sex = '女'
print(Xiaoming)
print(Xiaolan)
小明 的年龄为 20 岁 None性
小兰 的年龄为 19 岁 女性
线程_同步应用
'''
创建mutex = threading.Lock( )
锁定mutex.acquire([blocking])
释放mutex.release( )
创建->锁定->释放
'''
from threading import Thread,Lock
from time import sleep
class Task1(Thread):
def run(self):
while True:
if lock1.acquire():
#对lock1锁定
print("------Task 1 -----")
sleep(0.5)
lock2.release()
# 释放lock2锁的绑定
# 锁1上锁,锁2解锁
class Task2(Thread):
def run(self):
while True:
if lock2.acquire():
print("------Task 2 -----")
sleep(0.5)
lock3.release()
# 锁2上锁,锁3解锁
class Task3(Thread):
def run(self):
while True:
if lock3.acquire():
print("------Task 3 -----")
sleep(0.5)
lock1.release()
#使用Lock创建出的锁默认没有“锁上”
lock1 = Lock()
#创建另外的锁,并且上锁
lock2 = Lock()
lock2.acquire()
lock3 = Lock()
lock3.acquire()
t1 = Task1()
t2 = Task2()
t3 = Task3()
t1.start()
t2.start()
t3.start()
垃圾回收机制_合集
#大整数对象池
b = 1500
a = 1254
print(id(a))
print(id(b))
b = a
print(id(b))
a1 = "Hello 垃圾机制"
a2 = "Hello 垃圾机制"
print(id(a1),id(a2))
del a1
del a2
a3 = "Hello 垃圾机制"
print(id(a3))
s = "Hello"
print(id (s))
s = "World"
print(id (s))
s = 123
print(id (s))
s = 12
print(id (s))
lst1 = [1,2,3]
lst2 = [4,5,6]
lst1.append(lst2)
lst2.append(lst1)#循环进行引用
print(lst1)
print(lst2)
class Node(object):
def __init__(self,value):
self.value = value
print(Node(1))
"""
创建一个新对象,python向操作系统请求内存,
python实现了内存分配系统,
在操作系统之上提供了一个抽象层
"""
print(Node(2))#再次请求,分配内存
import gc
class ClassA():
def __init__(self):
print('object born,id:%s'%str(hex(id(self))))
def f3():
print("-----0------")
# print(gc.collect())
c1 = ClassA()
c2 = ClassA()
c1.t = c2
c2.t = c1
del c1
del c2
print("gc.garbage:",gc.garbage)
print("gc.collect",gc.collect()) #显式执行垃圾回收
print("gc.garbage:",gc.garbage)
if __name__ == '__main__':
gc.set_debug(gc.DEBUG_LEAK) #设置gc模块的日志
f3()
协程的简单实现
import time
# yield配合next使用
def work1():
while True:
print("----work1---")
yield
time.sleep(0.3)
def work2():
while True:
print("----work2---")
yield
time.sleep(0.3)
def main():
w1 = work1()
w2 = work2()
while True:
next(w1)
next(w2)
if __name__ == "__main__":
main( )
实现了__iter__和__next__的对象是迭代器
class MyList(object):
"""自定义的一个可迭代对象"""
def __init__(self):
self.items = []
def add(self, val):
self.items.append(val)
def __iter__(self):
myiterator = MyIterator(self)
return myiterator
class MyIterator(object):
"""自定义的供上面可迭代对象使用的一个迭代器"""
def __init__(self, mylist):
self.mylist = mylist
# current用来记录当前访问到的位置
self.current = 0
def __next__(self):
if self.current < len(self.mylist.items):
item = self.mylist.items[self.current]
self.current += 1
return item
else:
raise StopIteration
def __iter__(self):
return self
if __name__ == '__main__':
mylist = MyList()
mylist.add(1)
mylist.add(2)
mylist.add(3)
mylist.add(4)
mylist.add(5)
for num in mylist:
print(num)
对类中私有化的理解
class Person(object):
def __init__(self,name,age,taste):
self.name = name
self._age = age
self.__taste = taste
def showPerson(self):
print(self.name)
print(self._age)
print(self.__taste)
def do_work(self):
self._work()
self.__away()
def _work(self):
print("_work方法被调用")
def __away(self):
print("__away方法被调用")
class Student(Person):
def construction(self,name,age,taste):
self.name = name
self._age = age
self.__taste = taste
def showStudent(self):
print(self.name)
print(self._age)
print(self.__taste)
@staticmethod
def testbug():
_Bug.showbug()
class _Bug(Student):
@staticmethod
def showbug():
print("showbug函数开始运行")
s1 = Student('Xiaoming',22,'basketball')
s1.showPerson()
# s1.showStudent()
# s1.construction( )
s1.construction('rose',18,'football')
s1.showPerson()
s1.showStudent()
Student.testbug()
'''
Xiaoming
22
basketball
rose
18
basketball
rose
18
football
showbug函数开始运行
'''
拷贝的一些生成式
a = "abc"
b = a[:]
print(a,b)#值相同
print(id(a),id(b))#地址相同(字符串是不可变类型)
d = dict(name = "Xiaoming",age = 22)
d_copy = d.copy()
print( d ,id(d))
print(d_copy ,id(d_copy))#地址不同(字典是可变类型)
q = list(range(10))
q_copy = list(q)
print( q ,id(q))#值相同,地址不同 ()为可变类型
print(q_copy,id(q_copy))
'''
abc abc
2233026983024 2233026983024
{'name': 'Xiaoming', 'age': 22} 2233146632896
{'name': 'Xiaoming', 'age': 22} 2233027001984
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 2233146658048
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 2233164085888
'''
查看 __class__属性
查看complex的__class__属性
a = 5+2j
print(a.__class__)
print(a.__class__.__class__)
'''
'''
查看int的__class__属性
a = 123
print(a.__class__)
print(a.__class__.__class__)
'''
'''
查看str的__class__属性
a = 'str'
print(a.__class__)
print(a.__class__.__class__)
'''
'''
class ObjectCreator(object):
pass
print(type(ObjectCreator))#输出类的类型
print(type(ObjectCreator()))#
print(ObjectCreator.__class__)#输出类的类型
'''
'''
运行过程中给类添加方法 types.MethodType
class Person(object):
def __init__(self,name = None,age = None):
self.name = name#类中拥有的属性
self.age = age
def eat (self):
print("%s在吃东西"%(self.name))
p = Person("XiaoLiu",22)
p.eat()#调用Person中的方法
def run(self,speed):#run方法为需要添加到Person类中的方法
# run方法 self 给类添加方法,使用self指向该类
print("%s在以%d米每秒的速度在跑步"%(self.name,speed))
run(p,2)#p为类对象
import types
p1= types.MethodType(run,p)#p1只是用来接收的对象,MethodType内参数为 函数+类实例对象 ,接收之后使用函数都是对类实例对象进行使用的
# 第二个参数不能够使用类名进行调用
p1(2) #p1(2)调用实际上时run(p,2)
'''
XiaoLiu在吃东西
XiaoLiu在以2米每秒的速度在跑步
XiaoLiu在以2米每秒的速度在跑步
'''
import types
class Person(object):
num = 0 #num是一个类属性
def __init__(self, name = None, age = None):
self.name = name
self.age = age
def eat(self):
print("eat food")
#定义一个类方法
@classmethod #函数具有cls属性
def testClass(cls):
cls.num = 100
# 类方法对类属性进行修改,使用cls进行修改
#定义一个静态方法
@staticmethod
def testStatic():
print("---static method----")
P = Person("老王", 24)
#调用在class中的构造方法
P.eat()
#给Person类绑定类方法
Person.testClass = testClass #使用函数名进行引用
#调用类方法
print(Person.num)
Person.testClass()#Person.testClass相当于testClass方法
print(Person.num)#验证添加的类方法是否执行成功,执行成功后num变为100,类方法中使用cls修改的值
#给Person类绑定静态方法
Person.testStatic = testStatic#使用函数名进行引用
#调用静态方法
Person.testStatic()
'''
eat food
0
100
---static method----
'''
查看一个对象的引用计数
a = "Hello World "
import sys
print("a的引用计数为:",sys.getrefcount(a))
'''a的引用计数为: 4'''
浅拷贝和深拷贝
a = [1,2,3,4]
print(id(a))
b = a
print(id(b))
# 地址相同
a.append('a')
print(a)
print(b)#b和a的值一致,a改变,b就跟着改变
'''
2342960103104
2342960103104
[1, 2, 3, 4, 'a']
[1, 2, 3, 4, 'a']
'''
浅拷贝对不可变类型和可变类型的copy不同
import copy
a = [1,2,3]
b = copy.copy(a)
a.append('a')
print(a," ",b)
print(id(a),id(b))
a = (1,2,3)
b = copy.copy(a)
print(id(a),id(b))
# 浅拷贝copy.copy()对于可变类型赋予的地址不同,对于不可变类型赋予相同地址
'''
[1, 2, 3, 'a'] [1, 2, 3]
2053176165376 2053176165568
2053175778688 2053175778688
'''
深拷贝
import copy
a = [1,2,3,4]
print(id(a))
b = copy.deepcopy(a)
print(id(b))#地址不同
a.append('a')
print(a," ",b)
# 深拷贝:不跟着拷贝的对象发生变化
'''
2944424869376
2944424869568
[1, 2, 3, 4, 'a'] [1, 2, 3, 4]
'''
.format方式输出星号字典的值是键
dic = {'a':123,'b':456}
print("{0}:{1}".format(*dic))
# a:b
类可以打印,赋值,作为实参和实例化
class ObjectCreator(object):
pass
print(ObjectCreator)
# 打印
ObjectCreator.name = 'XiaoLiu'
# 对ObjectCreator类增加属性,以后使用ObjectCreator类时,都具有name属性
g = lambda x:x
# 把函数赋值给对象g
g(ObjectCreator)
# 将ObjectCreator作为实参传递给刚刚赋值过的g函数
Obj = ObjectCreator()
# 赋值给变量
'''
'''
类可以在函数中创建,作为返回值(返回类)
def func_class(string):
if string == 'class_one':
class class_one:
pass
return class_one
else:
class class_two:
pass
return class_two
MyClass = func_class('')
print("MyClass为 " , MyClass)
m = MyClass()
print("m为 ",m)
'''
MyClass为 .class_two'>
m为 <__main__.func_class..class_two object at 0x000002BC0491B190>
'''
查看某一个字符出现的次数
#方法一
import random
range_lst = [random.randint(0,100) for i in range(100)]
# 创建一个包含有 100 个数据的随机数
range_set = set(range_lst)
# 创建集合,不包含重复元素
for num in range_set:
# 对集合进行遍历,查找元素出现的次数
# list.count(元素) 查看元素在列表中出现的次数
print(num,":",range_lst.count(num))
# 方法二
import random
range_lst = [random.randint(0,5) for i in range(10)]
range_dict = dict()
for i in range_lst:
# 默认为 0 次,如果出现一次就 + 1
range_dict[i] = range_dict.get(i,0) +1
print(range_dict)
闭包函数
def test(number):
#在函数内部再定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称之为闭包
def test_in(number_in):
print("in test_in 函数, number_in is %d"%number_in)
return number+number_in#使用到了外部的变量number
return test_in #将内部函数作为返回值
#给test函数赋值,这个20就是给参数number
ret = test(20)#ret接收返回值(内部函数test_in)
#注意这里的100其实给参数number_in
print(ret(100)) #100+20
print(ret(200)) #200+20
def test1():
print("----test1----")
test1()
ret = test1#使用对象引用函数,使用函数名进行传递
print(id(ret))
# 引用的对象地址和原函数一致
print(id(test1))
ret()
'''
----test1----
1511342483488
1511342483488
----test1----
'''
def line_conf(a,b):
def line(x):
return "%d * %d + %d"%(a,x,b)
# 内部函数一定要使用外部函数,才能称为闭包函数
return line
line_one = line_conf(1,1)
# 使用变量进行接收外部函数,然后使用变量进行调用闭包函数中的内部函数
line_two = line_conf(2,3)
print(line_one(7))
print(line_two(7))
'''
1 * 7 + 1
2 * 7 + 3
'''
自定义创建元类
#coding=utf-8
class UpperAttrMetaClass(type):
# __new__ 是在__init__之前被调用的特殊方法
# __new__是用来创建对象并返回之的方法
# 而__init__只是用来将传入的参数初始化给对象
# __new__能够控制对象的创建
# 这里,创建的对象是类,自定义这个类,我们这里改写__new__
# 如果你希望的话,你也可以在__init__中做些事情
# 可改写__call__特殊方法
def __new__(cls, future_class_name, future_class_parents, future_class_attr):
# cls、类名、父类、需要修改的字典
#遍历属性字典,把不是__开头的属性名字变为大写
newAttr = {}
for key,value in future_class_attr.items():
if not key.startswith("__"):
newAttr[key.upper()] = value
#使字典的键值大写
# 方法1:通过'type'来做类对象的创建
# return type(future_class_name, future_class_parents, newAttr)
# type 类名、父类名、字典(刚刚进行修改的字典)
# 方法2:复用type.__new__方法
# 这就是基本的OOP编程,没什么魔法
# return type.__new__(cls, future_class_name, future_class_parents, newAttr)
# 类名、父类名、字典(刚刚进行修改的字典)
# 方法3:使用super方法
return super(UpperAttrMetaClass,cls).__new__(cls, future_class_name, future_class_parents, newAttr)
# python3的用法
class Foo(object, metaclass = UpperAttrMetaClass):
# metaclass运行类的时候,根据metaclass的属性。修改类中的属性
bar = 'bip'
# hasattr 查看类中是否具有该属性
print(hasattr(Foo, 'bar'))
# 输出: False
print(hasattr(Foo, 'BAR'))
# 输出:True
f = Foo()
# 进行构造,产生 f 对象
print(f.BAR)
# 输出:'bip',metaclass修改了Foo类
class UpperAttrMetaClass(type):
# __new__ 是在__init__之前被调用的特殊方法
# __new__是用来创建对象并返回之的方法
# 而__init__只是用来将传入的参数初始化给对象
# 你很少用到__new__,除非你希望能够控制对象的创建
# 这里,创建的对象是类,我们希望能够自定义它,所以我们这里改写__new__
# 如果你希望的话,你也可以在__init__中做些事情
# 还有一些高级的用法会涉及到改写__call__特殊方法,但是我们这里不用
def __new__(cls, future_class_name, future_class_parents, future_class_attr):
#遍历属性字典,把不是__开头的属性名字变为大写
newAttr = {}
for name,value in future_class_attr.items():
if not name.startswith("__"):
newAttr[name.upper()] = value
# 方法1:通过'type'来做类对象的创建
return type(future_class_name, future_class_parents, newAttr)
# 方法2:复用type.__new__方法
# return type.__new__(cls, future_class_name, future_class_parents, newAttr)
#return type.__new__(cls,future_class_name,future_class_parents,newAttr)
# 方法3:使用super方法
return super(UpperAttrMetaClass, cls).__new__(cls, future_class_name, future_class_parents, newAttr)
# python3的用法
class Foo(object, metaclass = UpperAttrMetaClass):
bar = 'bip'
print(hasattr(Foo, 'bar'))
print(hasattr(Foo, 'BAR'))
f = Foo()
print(f.BAR)
迪杰斯特拉算法(网上找的)
"""
输入
graph 输入的图
src 原点
返回
dis 记录源点到其他点的最短距离
path 路径
"""
import json
def dijkstra(graph, src):
if graph == None:
return None
# 定点集合
nodes = [i for i in range(len(graph))] # 获取顶点列表,用邻接矩阵存储图
# 顶点是否被访问
visited = []
visited.append(src)
# 初始化dis
dis = {src: 0} # 源点到自身的距离为0
for i in nodes:
dis[i] = graph[src][i]
path = {src: {src: []}} # 记录源节点到每个节点的路径
k = pre = src
while nodes:
temp_k = k
mid_distance = float('inf') # 设置中间距离无穷大
for v in visited:
for d in nodes:
if graph[src][v] != float('inf') and graph[v][d] != float('inf'): # 有边
new_distance = graph[src][v] + graph[v][d]
if new_distance <= mid_distance:
mid_distance = new_distance
graph[src][d] = new_distance # 进行距离更新
k = d
pre = v
if k != src and temp_k == k:
break
dis[k] = mid_distance # 最短路径
path[src][k] = [i for i in path[src][pre]]
path[src][k].append(k)
visited.append(k)
nodes.remove(k)
print(nodes)
return dis, path
if __name__ == '__main__':
# 输入的有向图,有边存储的就是边的权值,无边就是float('inf'),顶点到自身就是0
graph = [
[0, float('inf'), 10, float('inf'), 30, 100],
[float('inf'), 0, 5, float('inf'), float('inf'), float('inf')],
[float('inf'), float('inf'), 0, 50, float('inf'), float('inf')],
[float('inf'), float('inf'), float('inf'), 0, float('inf'), 10],
[float('inf'), float('inf'), float('inf'), 20, 0, 60],
[float('inf'), float('inf'), float('inf'), float('inf'), float('inf'), 0]]
dis, path = dijkstra(graph, 0) # 查找从源点0开始带其他节点的最短路径
print(dis)
print(json.dumps(path, indent=4))
装饰器_上
def foo():
print("foo")
print(foo)
# 输出foo的地址
foo()#对foo函数的调用
def foo():
print("foo2")
foo = lambda x : x+1
# 使用foo对象接收函数
print(foo(2))
def w(func):
def inner():
# 验证、使用内部函数的inner函数进行验证
print("对函数进行验证中~~~")
func()#内部函数使用了外部函数的func函数
return inner#闭包函数、返回内部函数名
@w #对w的装饰
def fun1():
print("fun1验证完毕,开始接下来的工作")
@w
def fun2():
print("fun2验证完毕,开始接下来的工作")
fun1()#运行、先运行装饰器,后运行函数
fun2()
def makeBold(fn):
# fn形参实际上是使用了makeBold装饰器的函数
def wrapped():
return ""+fn()+""
return wrapped
def makeitalic(fn):
def wrapped():
return ""+fn()+""
return wrapped
@makeBold
def test1():
return "hello world -1 "
@makeitalic
def test2():
return "hello world -2 "
@makeBold#后使用makeBold
@makeitalic#先使用装饰器makeitalic
def test3():
return "hello world -3 " #@makeitalic先执行然后是@makeBold 先执行最近的
print(test1())
print(test2())
print(test3())
装饰器_下
# 示例1
from time import ctime,sleep
#导包就不需要使用包名.函数了
def timefun(func):
def wrappedfunc():
print("%s called at %s"%(func.__name__,ctime()))
func()#内部函数需要使用外部函数的参数
return wrappedfunc#返回内部函数
@timefun #timefun是一个闭包函数
def foo():#将foo函数传递给timefun闭包函数
print("I'm foo ")
foo()
sleep(3)
foo()
'''
foo called at Fri May 8 01:00:18 2020
I'm foo
foo called at Fri May 8 01:00:21 2020
I'm foo
'''
# 示例2
from time import ctime,sleep
import functools
def timefun(func):
#functools.wraps(func)
def wrappedfunc(a,b):#使用了timefun函数的参数a,b
print("%s called at %s"%(func.__name__,ctime()))
print(a,b)
func(a,b)
return wrappedfunc
@timefun
def foo(a,b):
print(a+b)
foo(3,5)
sleep(2)
foo(2,4)
'''
foo called at Fri May 8 01:01:16 2020
3 5
8
foo called at Fri May 8 01:01:18 2020
2 4
6
'''
# 示例3
from time import ctime,sleep
def timefun(func):
def wrappedfunc(*args,**kwargs):
# *args主要是元组,列表,单个值的集合
# **kwargs 主要是键值对,字典
print("%s called at %s"%(func.__name__,ctime()))
func(*args,**kwargs)
return wrappedfunc
@timefun
def foo(a,b,c):
print(a+b+c)
foo(3,5,7)
sleep(2)
foo(2,4,9)
'''
foo called at Fri May 8 01:01:38 2020
15
foo called at Fri May 8 01:01:40 2020
15
'''
# 示例4
def timefun(func):
def wrappedfunc( ):
return func( )#闭包函数返回调用的函数(原函数有return)
return wrappedfunc
@timefun
def getInfo():
return '----haha----'
info = getInfo()#接收函数的返回值
print(info)#输出getInfo 如果闭包函数没有return 返回,则为None
'''
----haha----
'''
# 示例5
from time import ctime,sleep
def timefun_arg(pre = "Hello"):#使用了pre默认参数
def timefun(func):
def wrappedfunc():#闭包函数嵌套闭包函数
print("%s called at %s"%(func.__name__,ctime()))
print(pre)
# func.__name__函数名 ctime()时间
return func#返回使用了装饰器的函数
return wrappedfunc
return timefun
@timefun_arg("foo的pre")#对闭包函数中最外部函数进行形参传递pre
def foo( ):
print("I'm foo")
@timefun_arg("too的pre")
def too():
print("I'm too")
foo()
sleep(2)
foo()
too()
sleep(2)
too()
'''foo called at Fri May 8 01:02:34 2020
foo的pre
foo called at Fri May 8 01:02:36 2020
foo的pre
too called at Fri May 8 01:02:36 2020
too的pre
too called at Fri May 8 01:02:38 2020
too的pre
'''
设计模式_理解单例设计模式
设计模式分类:
结构型
行为型
创建型
单例模式属于创建型设计模式
单例模式主要使用在
日志记录 ->将多项服务的日志信息按照顺序保存到一个特定日志文件
数据库操作 -> 使用一个数据库对象进行操作,保证数据的一致性
打印机后台处理程序
以及其他程序
该程序运行过程中
只能生成一个实例
避免对同一资源产生相互冲突的请求
单例设计模式的意图:
确保类有且只有一个对象被创建。
为对象提供一个访问点,以使程序可以全局访问该对象。
控制共享资源的并行访问
实现单例模式的一个简单方法是:
使构造函数私有化
并创建一个静态方法来完成对象的初始化
这样做的目的是:
对象将在第一次调用时创建
此后,这个类将返回同一个对象
实践:
1.只允许Singleton类生成一个实例。
2.如果已经有一个实例了 则重复提供同-个对象
class Singletion(object):
def __new__(cls):
'''
覆盖 __new__方法,控制对象的创建
'''
if not hasattr(cls,'instance'):
'''
hasattr 用来了解对象是否具有某个属性
检查 cls 是否具有属性 instance
instance 属性的作用是检查该类是否已经生成了一个对象
'''
cls.instance = super(Singletion,cls).__new__(cls)
'''
当对象s1被请求创建时,hasattr发现对象已经存在
对象s1将被分配到已有的对象实例
'''
return cls.instance
s = Singletion()
'''
s对象 通过 __new__ 方法进行创建
在创建之前,会检查对象是否已存在
'''
print("对象已经创建好了:",s)
s1 = Singletion()
print("对象已经创建好了:",s1)
'''
运行结果:
对象已经创建好了: <__main__.Singletion object at 0x000001EE59F93340>
对象已经创建好了: <__main__.Singletion object at 0x000001EE59F93340>
'''
设计模式_单例模式的懒汉式实例化
单例模式的懒汉式
在导入模块的时候,可能会无意中创建一个对象,但当时根本用不到
懒汉式实例化能够确保在实际需要时才创建对象
懒汉式实例化是一种节约资源并仅在需要时才创建它们的方式
class Singleton:
_instance = None
def __init__(self):
if not Singleton._instance:
print("__init__的方法使用了,在静态 getinstance 方法才创建了实例对象")
else:
# 在静态 getinstance 方法,改变了 _instance 的值
print("实例已创建",self.getinstance())
@classmethod
def getinstance(cls):
'''
在 getinstance 内写创建实例的语句
如果在 __init__ 内写明创建语句
如果那个对象创建之后没有立即使用,会造成资源浪费
'''
if not cls._instance:
cls._instance = Singleton()
'''
创建实例化对象时,还会再调用一次 __init__方法
cls._instance = Singleton() 修改了 _instance 属性的状态
'''
return cls._instance
s = Singleton()
# __init__的方法使用了,在静态 getinstance 方法才创建了实例对象
print('已创建对象',Singleton.getinstance())
'''
此时才是真正的创建了对象
运行结果:
__init__的方法使用了,在静态 getinstance 方法才创建了实例对象
已创建对象 <__main__.Singleton object at 0x00000206AA2436D0>
'''
print(id(s))
# 2227647559520
s1 = Singleton()
# 实例已创建 <__main__.Singleton object at 0x00000206AA2436D0>
print('已创建对象',Singleton.getinstance())
# 已创建对象 <__main__.Singleton object at 0x00000206AA2436D0>
print(id(s1))
# 2227647561248
创建一个静态变量 _instance = None
在 __init__ 方法内部,不进行创建对象的操作
在类方法 getinstance 方法中,进行类的创建
注:
此时会调用一次 __init__ 方法
创建对象时
s = Singleton() 还会调用一次 __init__ 方法
查看MySQL支持的存储引擎

查看当前所有数据库
创建一个数据库

选择当前操作的数据库

删除数据库

查看数据库表
创建一个数据库表

显示表的结构

查看创建表的创建语句

向表中加入记录

删除记录

更新记录

删除表

在类外创建函数,然后使用类的实例化对象进行调用
def f(self,x):
y = x + 3
return y
class Add:
# 创建一个 Add 类
def add(self,a):
return a + 4
f1 = f
# 让 f1 等于外面定义的函数 f
n = Add()
# 创建实例化对象
print(n.add(4))
# 调用类内定义方法
print(n.f1(4))
# 调用类外创建的方法
运行结果:
8
7
[Finished in 0.2s]
需要注意的点:
外部定义的函数第一个参数为 self
创建类的实例化对象使用 Add()
括号不要丢
PageRank算法
def create(q,graph,N):
#compute Probability Matrix
L = [[(1-q)/N]*N for i in range(N)]
for node,edges in enumerate(graph):
num_edge = len(edges)
for each in edges:
L[each][node] += q/num_edge
return L
def transform(A):
n,m = len(A),len(A[0])
new_A = [[A[j][i] for j in range(n) ] for i in range(m)]
return new_A
def mul(A,B):
n = len(A)
m = len(B[0])
B = transform(B)
next = [[0]*m for i in range(n)]
for i in range(n):
row = A[i]
for j in range(m):
col = B[j]
next[i][j] = sum([row[k]*col[k] for k in range(n)])
return next
def power(A,N):
n = len(A)
assert(len(A[0])==n)
final_ans,temp = A,A
N-=1
while N>0:
if N&1:
final_ans = mul(final_ans,temp)
temp = mul(temp,temp)
N >>=1
return final_ans
def PageRank(q,graph,N):
X = [[1] for i in range(N)]
A = create(q,graph,N)
X = mul(power(A,20),X)
return X
print(PageRank(0.85,[[1,2],[2],[0]],3))
————————————————
原文链接:https://blog.csdn.net/pp634077956/java/article/details/52604137
穷人版PageRank算法的Python实现
#用于存储图
class Graph():
def __init__(self):
self.linked_node_map = {}#邻接表,
self.PR_map ={}#存储每个节点的入度
#添加节点
def add_node(self, node_id):
if node_id not in self.linked_node_map:
self.linked_node_map[node_id] = set({})
self.PR_map[node_id] = 0
else:
print("这个节点已经存在")
#增加一个从Node1指向node2的边。允许添加新节点
def add_link(self, node1, node2):
if node1 not in self.linked_node_map:
self.add_node(node1)
if node2 not in self.linked_node_map:
self.add_node(node2)
self.linked_node_map[node1].add(node2)#为node1添加一个邻接节点,表示ndoe2引用了node1
#计算pr
def get_PR(self, epoch_num=10, d=0.5):#配置迭代轮数,以及阻尼系数
for i in range(epoch_num):
for node in self.PR_map:#遍历每一个节点
self.PR_map[node] = (1-d) + d*sum([self.PR_map[temp_node] for temp_node in self.linked_node_map[node]])#原始版公式
print(self.PR_map)
edges = [[1,2], [3,2], [3,5], [1,3], [2,3], [3, 1], [5,1]]#模拟的一个网页链接网络
if __name__ == '__main__':
graph = Graph()
for edge in edges:
graph.add_link(edge[0], edge[1])
graph.get_PR()
分解质因数
把一个合数分解成若干个质因数的乘积的形式,即求质因数的过程叫做分解质因数。
Python练习题问题如下:
要求:将一个正整数分解质因数;例如您输入90,分解打印90=2*3*3*5。
Python解题思路分析:
这道题需要分三部分来分解,具体分解说明如下。
1、首先当这个质数恰等于n的情况下,则说明分解质因数的过程已经结束,打印出即可。
2、如果遇到n<>k,但n能被k整除的情况,则应打印出k的值。同时用n除以k的商,作为新的正整数你n,之后再重复执行第一步的操作。
3、如果n不能被k整除时,那么用k+1作为k的值,再来重复执行第一步的操作系统。
def reduceNum(n):
print ('{} = '.format(n))
if not isinstance(n, int) or n <= 0 :
print ('请输入一个正确的数字')
exit(0)
elif n in [1] :
# 如果 n 为 1
print('{}'.format(n))
while n not in [1] : # 循环保证递归
for index in range(2, n + 1) :
if n % index == 0:
n //= index # n 等于 n//index
if n == 1:
print (index)
else : # index 一定是素数
print ('{} *'.format(index),end = " ")
break
reduceNum(90)
reduceNum(100)

计算皮球下落速度
问题简述:假设一支皮球从100米高度自由落下。条件,每次落地后反跳回原高度的一半后,再落下。
要求:算出这支皮球,在它在第10次落地时,共经过多少米?第10次反弹多高?
解题思路
总共初始高度 100 米
高度 每次弹起一半距离
每一次弹起 上升的高度和下降的高度 是一次的距离
每一次弹起,高度都会是之前的一半
Sn = 100.0
Hn = Sn / 2
for n in range(2,11):
Sn += 2 * Hn
Hn /= 2
print ('总共经过 %.2f 米' % Sn)
print ('第十次反弹 %.2f 米' % Hn)
![]()
给定年月日,判断是这一年的第几天
# 输入年月日
year = int(input('year:'))
month = int(input('month:'))
day = int(input('day:'))
# 将正常情况下,每一个月的累计天数放入到元组中进行保存
months = (0,31,59,90,120,151,181,212,243,273,304,334)
if 0 < month <= 12:
# 如果输入的数据正确,月份在 1~12 之间
sum_days = months[month - 1]
# 总天数就为 列表中的天数,索引值根据 输入的月份进行选择
else:
print ('数据错误,请重新输入')
# 加上输入的日期
sum_days += day
# 默认不是闰年
leap = 0
# 判断是否是闰年,被 400 整除,可以整除4 但是不能被 100 除掉
if (year % 400 == 0) or ((year % 4 == 0) and (year % 100 != 0)):
leap = 1
# 如果为 1 则表示 这一年是闰年
if (leap == 1) and (month > 2):
# 当这一年是闰年,并且月份大于 2 时,说明存在 29 日,所以总天数再增加 1
sum_days += 1
print ('这是 %d 年的第 %d 天.' % (year,sum_days))

实验1-5
Django暂时停止更新,先把学校实验报告弄完
'''
计算
1.输入半径,输出面积和周长
2.输入面积,输出半径及周长
3.输入周长,输出半径及面积
'''
'''1.输入半径,输出面积和周长'''
from math import pi
'''定义半径'''
r = int(input("请输入半径的值(整数)"))
if r <= 0 :
exit("请重新输入半径")
''' S 面积: pi * r * r '''
S = pi * pow(r,2)
print(" 半径为 %d 的圆,面积为 %.2f"%(r,S))
'''C 周长: C = 2 * pi * r '''
C = 2 * pi * r
print(" 半径为 %d 的圆,周长为 %.2f"%(r,C))
'''2.输入面积,输出半径及周长'''
from math import pi,sqrt
S = float(input("请输入圆的面积(支持小数格式)"))
if S < 0 :
exit("请重新输入面积")
'''r 半径: r = sqrt(S/pi)'''
r = sqrt(S/pi)
print("面积为 %.2f 的圆,半径为 %.2f"%(S,r))
'''C 周长: C = 2 * pi * r '''
C = 2 * pi * r
print("面积为 %.2f 的圆,周长为 %.2f"%(S,C))
'''3.输入周长,输出半径及面积'''
from math import pi
C = float(input("请输入圆的周长(支持小数格式)"))
if C < 0 :
exit("请重新输入周长")
'''r 半径: r = C/(2*pi)'''
r = C/(2*pi)
print("周长为 %.2f 的圆,半径为 %.2f"%(C,r))
''' S 面积: pi * r * r '''
S = pi * pow(r,2)
print("周长为 %.2f 的圆,面积为 %.2f"%(C,S))
'''
数据结构
列表练习
1.创建列表对象 [110,'dog','cat',120,'apple']
2.在字符串 'dog' 和 'cat' 之间插入空列表
3.删除 'apple' 这个字符串
4.查找出 110、120 两个数值,并以 10 为乘数做自乘运算
'''
'''1.创建列表对象 [110,'dog','cat',120,'apple']'''
# '''创建一个名为 lst 的列表对象'''
lst = [110,'dog','cat',120,'apple']
print(lst)
'''2.在字符串 'dog' 和 'cat' 之间插入空列表'''
lst = [110,'dog','cat',120,'apple']
'''添加元素到 'dog' 和 'cat' 之间'''
lst.insert(2,[])
print(lst)
'''3.删除 'apple' 这个字符串'''
lst = [110,'dog','cat',120,'apple']
'''删除最后一个元素'''
lst.pop()
print(lst)
'''4.查找出 110、120 两个数值,并以 10 为乘数做自乘运算'''
lst = [110,'dog','cat',120,'apple']
try:
'''如果找不到数据,进行异常处理'''
lst[lst.index(110)] *= 10
lst[lst.index(120)] *= 10
except Exception as e:
print(e)
print(lst)
'''
元组练习
1.创建列表 ['pen','paper',10,False,2.5] 赋给变量并查看变量的类型
2.将变量转换为 tuple 类型,查看变量的类型
3.查询元组中的元素 False 的位置
4.根据获得的位置提取元素
'''
'''1.创建列表 ['pen','paper',10,False,2.5] 赋给变量并查看变量的类型'''
lst = ['pen','paper',10,False,2.5]
'''查看变量类型'''
print("变量的类型",type(lst))
'''2.将变量转换为 tuple 类型,查看变量的类型'''
lst = tuple(lst)
print("变量的类型",type(lst))
'''3.查询元组中的元素 False 的位置'''
if False in lst:
print("False 的位置为(从0开始): ",lst.index(False))
'''4.根据获得的位置提取元素'''
print("根据获得的位置提取的元素为: ",lst[lst.index(False)])
else:
print("不在元组中")
'''
1.创建字典{‘Math’:96,’English’:86,’Chinese’:95.5,
’Biology’:86,’Physics’:None}
2.在字典中添加键对{‘Histore’:88}
3.删除{’Physics’:None}键值对
4.将键‘Chinese’所对应的值进行四舍五入后取整
5.查询键“Math”的对应值
'''
'''1.创建字典'''
dic = {'Math':96,'English':86,'Chinese':95.5,'Biology':86,'Physics':None}
print(dic)
'''2.添加键值对'''
dic['Histore'] = 88
print(dic)
'''3.删除{’Physics’:None}键值对'''
del dic['Physics']
print(dic)
'''4.将键‘Chinese’所对应的值进行四舍五入后取整'''
print(round(dic['Chinese']))
'''5.查询键“Math”的对应值'''
print(dic['Math'])
'''
1.创建列表[‘apple’,’pear’,’watermelon’,’peach’]并赋给变量
2.用list()创建列表[‘pear’,’banana’,’orange’,’peach’,’grape’],并赋给变量
3.将创建的两个列表对象转换为集合类型
4.求两个集合的并集、交集和差集
'''
'''1.创建列表'''
lst = ['apple','pear','watermelon','peach']
print(lst)
'''2.用list()创建,并赋给变量'''
lstTwo = list(('pear','banana','orange','peach','grape'))
print(lstTwo)
'''3.将创建的两个列表对象转换为集合类型'''
lst = set(lst)
lstTwo = set(lstTwo)
'''4.求两个集合的并集、交集和差集'''
print("并集是:",lst | lstTwo)
print("交集是:",lst & lstTwo)
print("差集:")
print(lst - lstTwo)
print(lstTwo - lst)
'''
1 输出数字金字塔
(1)设置输入语句,输入数字
(2)创建变量来存放金字塔层数
(3)编写嵌套循环,控制变量存放每一层的长度
(4)设置条件来打印每一行输出的数字
(5)输出打印结果
'''
num = int(input("请输入金字塔的层数"))
'''cs 层数'''
cs = 1
while cs <= num:
kk = 1
t = cs
length = 2*t - 1
while kk <= length:
if kk == 1:
if kk == length:
print(format(t,str(2*num-1)+"d"),'\n')
break
else:
print(format(t,str(2*num+1 - 2*cs) + "d"),"",end = "")
t -= 1
else:
if kk == length:
'''最右侧数字 length 位置上数字为 t'''
print(t,"\n")
break
elif kk <= length/2:
'''到中间的数字不断减小'''
print(t,"",end = "")
t -= 1
else:
'''中间的数字到右侧的数字不断增大'''
print(t,"",end = "")
t += 1
kk += 1
'''层数加 1'''
cs += 1
'''
(1)使用自定义函数,完成对程序的模块化
(2)学生信息至少包括:姓名、性别及手机号
(3)该系统具有的功能:添加、删除、修改、显示、退出系统
'''
'''创建一个容纳所有学生的基本信息的列表'''
stusInfo = []
def menu():
'''定义页面显示'''
print('-'*20)
print('学生管理系统')
print('1.添加学生信息')
print('2.删除学生信息')
print('3.修改学生信息')
print('4.显示所有学生信息')
print('0.退出系统')
print('-' * 20)
def addStuInfo():
'''添加学生信息'''
'''设置变量容纳学生基本信息'''
newStuName = input('请输入新学生的姓名')
newStuGender = input('请输入新学生的性别')
newStuPhone = input('请输入新学生的手机号')
'''设置字典将变量保存'''
newStudent = {}
newStudent['name'] = newStuName
newStudent['gender'] = newStuGender
newStudent['phone'] = newStuPhone
'''添加到信息中'''
stusInfo.append(newStudent)
def delStuInfo():
'''删除学生信息'''
showStusInfo()
defStuId = int(input('请输入要删除的序号:'))
'''从列表中删除 该学生'''
del stusInfo[defStuId - 1]
def changeStuInfo():
'''修改学生信息'''
showStusInfo()
'''查看修改的学生序号'''
stuId = int(input("请输入需要修改的学生的序号: "))
changeStuName = input('请输入修改后的学生的姓名')
changeStuGender = input('请输入修改后的学生的性别')
changeStuPhone = input('请输入修改后的学生的手机号')
'''对列表修改学生信息'''
stusInfo[stuId - 1]['name'] = changeStuName
stusInfo[stuId - 1]['gender'] = changeStuGender
stusInfo[stuId - 1]['phone'] = changeStuPhone
def showStusInfo():
print('-'*30)
print("学生的信息如下:")
print('-'*30)
print('序号 姓名 性别 手机号码')
'''展示学生序号(位置),姓名,性别,手机号码'''
stuAddr = 1
for stuTemp in stusInfo:
print("%d %s %s %s"%(stuAddr,stuTemp['name'],stuTemp['gender'],stuTemp['phone']))
stuAddr += 1
def main():
'''主函数'''
while True:
'''显示菜单'''
menu()
keyNum = int(input("请输入功能对应的数字"))
if keyNum == 1:
addStuInfo()
elif keyNum == 2:
delStuInfo()
elif keyNum == 3:
changeStuInfo()
elif keyNum == 4:
showStusInfo()
elif keyNum == 0:
print("欢迎下次使用")
break
if __name__ == '__main__':
main()
import numpy as np
'''一维数组'''
'''np.array 方法'''
print(np.array([1,2,3,4]))
# [1 2 3 4]
print(np.array((1,2,3,4)))
# [1 2 3 4]
print(np.array(range(4)))
# [0 1 2 3]
'''np.arange 方法'''
print(np.arange(10))
# [0 1 2 3 4 5 6 7 8 9]
'''np.linspace 方法'''
print(np.linspace(0,10,11))
# [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
print(np.linspace(0,10,11,endpoint = False))
# [0. 0.90909091 1.81818182 2.72727273 3.63636364 4.54545455
# 5.45454545 6.36363636 7.27272727 8.18181818 9.09090909]
'''np.logspace 方法'''
print(np.logspace(0,100,10))
# [1.00000000e+000 1.29154967e+011 1.66810054e+022 2.15443469e+033
# 2.78255940e+044 3.59381366e+055 4.64158883e+066 5.99484250e+077
# 7.74263683e+088 1.00000000e+100]
print(np.logspace(1,4,4,base = 2))
# [ 2. 4. 8. 16.]
'''zeros 方法'''
print(np.zeros(3))
# [0. 0. 0.]
'''ones 方法'''
print(np.ones(3))
# [1. 1. 1.]
'''二维数组'''
'''np.array 方法'''
print(np.array([[1,2,3],[4,5,6]]))
# [[1 2 3]
# [4 5 6]]
'''np.identify 方法'''
print(np.identity(3))
# [[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]
'''np.empty 方法'''
print(np.empty((3,3)))
# [[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]
'''np.zeros 方法'''
print(np.zeros((3,3)))
# [[0. 0. 0.]
# [0. 0. 0.]
# [0. 0. 0.]]
'''np.ones 方法'''
print(np.ones((3,3)))
# [[1. 1. 1.]
# [1. 1. 1.]
# [1. 1. 1.]]
import numpy as np
'''一维数组'''
'''np.random.randint 方法'''
print(np.random.randint(0,6,3))
# [4 2 1]
'''np.random.rand 方法'''
print(np.random.rand(10))
# [0.12646424 0.59660184 0.52361248 0.1206141 0.28359949 0.46069696
# 0.18397493 0.73839455 0.99115088 0.98297331]
'''np.random.standard_normal 方法'''
print(np.random.standard_normal(3))
# [-0.12944733 -0.32607943 0.58582095]
'''二维数组'''
'''np.random.randint 方法'''
print(np.random.randint(0,6,(3,3)))
# [[0 0 0]
# [4 4 0]
# [5 0 3]]
'''多维数组'''
print(np.random.standard_normal((3,4,2)))
# [[[-0.79751104 -1.40814148]
# [-1.06189896 1.19993648]
# [ 1.68883868 0.09190824]
# [ 0.33723433 0.28246094]]
#
# [[ 0.3065646 1.1177714 ]
# [-0.48928572 0.55461195]
# [ 0.3880272 -2.27673705]
# [-0.97869759 -0.07330554]]
#
# [[ 0.62155155 -0.17690222]
# [ 1.61473949 -0.34930031]
# [-1.41535777 1.32646137]
# [-0.22865775 -2.00845225]]]
import numpy as np
n = np.array([10,20,30,40])
print(n + 5)
# [15 25 35 45]
print(n - 10)
# [ 0 10 20 30]
print(n * 2)
# [20 40 60 80]
print(n / 3)
# [ 3.33333333 6.66666667 10. 13.33333333]
print(n // 3)
# [ 3 6 10 13]
print(n % 3)
# [1 2 0 1]
print(n ** 2)
# [ 100 400 900 1600]
n = np.array([1,2,3,4])
print(2 ** n)
# [ 2 4 8 16]
print(16//n)
# [16 8 5 4]
print(np.array([1,2,3,4]) + np.array([1,1,2,2]))
# [2 3 5 6]
print(np.array([1,2,3,4]) + np.array(4))
# [5 6 7 8]
print(n)
# [1 2 3 4]
print(n + n)
# [2 4 6 8]
print(n - n)
# [0 0 0 0]
print(n * n)
# [ 1 4 9 16]
print(n / n)
# [1. 1. 1. 1.]
print(n ** n)
# [ 1 4 27 256]
x = np.array([4,7,3])
print(np.argsort(x))
# [2 0 1]
print(x.argmax())
# 1
print(x.argmin())
# 2
print(np.sort(x))
# [3 4 7]
print(np.where(x < 5,0,1))
x = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(x)
# [[1 2 3]
# [4 5 6]
# [7 8 9]]
x.resize((2,5))
print(x)
# [[1 2 3 4 5]
# [6 7 8 9 0]]
print(np.piecewise(x,[x<3],[lambda x:x + 1]))
# [[2 3 0 0 0]
# [0 0 0 0 1]]
import pandas as pd
import numpy as np
'''对 sepal_length 这一列进行分析'''
irisSepalLength = np.loadtxt('iris.csv')
print(irisSepalLength[:5])
# [5.1 4.9 4.7 4.6 5. ]
'''对数据进行排序'''
irisSepalLength.sort()
print(irisSepalLength[:15])
# [4.3 4.4 4.4 4.4 4.5 4.6 4.6 4.6 4.6 4.7 4.7 4.8 4.8 4.8 4.8]
'''查看去重后的数据集'''
print(np.unique(irisSepalLength)[:15])
# [4.3 4.4 4.5 4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7]
'''查看长度的总和'''
print(np.sum(irisSepalLength))
# 876.5
'''累计和'''
print(np.cumsum(irisSepalLength)[:10])
# [ 4.3 8.7 13.1 17.5 22. 26.6 31.2 35.8 40.4 45.1]
'''均值'''
print(np.mean(irisSepalLength))
# 5.843333333333334
'''标准差'''
print(np.std(irisSepalLength))
# 0.8253012917851409
'''方差'''
print(np.var(irisSepalLength))
# 0.6811222222222223
'''最小值'''
print(np.min(irisSepalLength))
# 4.3
'''最大值'''
print(np.max(irisSepalLength))
# 7.9
import pandas as pd
'''创建 Series 对象 s'''
s = pd.Series(range(1,20,5))
print(s)
# 0 1
# 1 6
# 2 11
# 3 16
# dtype: int64
s = pd.Series({'语文':90,'数学':92,'物理':88,'化学':99})
print(s)
# 语文 90
# 数学 92
# 物理 88
# 化学 99
# dtype: int64
'''修改数据'''
s['语文'] = 100
print(s)
# 语文 100
# 数学 92
# 物理 88
# 化学 99
# dtype: int64
'''使用绝对值'''
print(abs(s))
# 语文 100
# 数学 92
# 物理 88
# 化学 99
# dtype: int64
'''对数据列加后缀'''
# s.add_suffix('后缀')
'''查看某些数据是否满足条件'''
print(s.between(90,99,inclusive = True))
# 语文 False
# 数学 True
# 物理 False
# 化学 True
# dtype: bool
'''查看属性最大的列名'''
print(s.idxmax())
# 语文
'''查看属性最小的列名'''
print(s.idxmin())
# 物理
'''大于 95 的列'''
print(s[s > 95])
# 语文 100
# 化学 99
# dtype: int64
'''查看中值'''
print(s.median())
# 95.5
'''大于中值的列'''
print(s[s > s.median()])
# 语文 100
# 化学 99
# dtype: int64
'''查看最小的 3 个值'''
print(s.nsmallest(3))
# 物理 88
# 数学 92
# 化学 99
# dtype: int64
'''查看最大的 3 个值'''
print(s.nlargest(3))
# 语文 100
# 化学 99
# 数学 92
# dtype: int64
'''两个 Series 对象进行相加'''
print(pd.Series(range(5)) + pd.Series(range(7,12)))
# 0 7
# 1 9
# 2 11
# 3 13
# 4 15
# dtype: int64
'''对 Series 对象使用函数'''
print(pd.Series(range(5)).pipe(lambda x,y:(x**y),4))
# 0 0
# 1 1
# 2 16
# 3 81
# 4 256
# dtype: int64
print(pd.Series(range(5)).pipe(lambda x:x + 3))
# 0 3
# 1 4
# 2 5
# 3 6
# 4 7
# dtype: int64
print(pd.Series(range(5)).apply(lambda x:x + 3))
# 0 3
# 1 4
# 2 5
# 3 6
# 4 7
# dtype: int64
'''查看标准差方差'''
print(s)
print(s.std())
# 5.737304826019502
print(s.var())
# 32.916666666666664
'''查看是否全部为真'''
print(any(pd.Series([1,0,1])))
# True
print(all(pd.Series([1,0,1])))
# False
import pandas as pd
import numpy as np
'''创建一个 DataFrame 对象'''
df = pd.DataFrame(np.random.randint(1,5,(5,3)),index = range(5),columns = ['A','B','C'])
print(df)
# A B C
# 0 4 4 2
# 1 1 4 1
# 2 4 3 4
# 3 3 1 3
# 4 2 3 1
'''读取数据'''
market = pd.read_excel('超市营业额.xlsx')
print(market.head())
# 工号 姓名 日期 时段 交易额 柜台
# 0 1001 张三 2019-03-01 9:00-14:00 1664.0 化妆品
# 1 1002 李四 2019-03-01 14:00-21:00 954.0 化妆品
# 2 1003 王五 2019-03-01 9:00-14:00 1407.0 食品
# 3 1004 赵六 2019-03-01 14:00-21:00 1320.0 食品
# 4 1005 周七 2019-03-01 9:00-14:00 994.0 日用品
'''查看不连续行的数据'''
print(market.iloc[[1,8,19],:])
# 工号 姓名 日期 时段 交易额 柜台
# 1 1002 李四 2019-03-01 14:00-21:00 954.0 化妆品
# 8 1001 张三 2019-03-02 9:00-14:00 1530.0 化妆品
# 19 1004 赵六 2019-03-03 14:00-21:00 1236.0 食品
print(market.iloc[[1,8,19],[1,4]])
# 姓名 交易额
# 1 李四 954.0
# 8 张三 1530.0
# 19 赵六 1236.0
'''查看前五条记录的 姓名 时段 和 交易额'''
print(market[['姓名','时段','交易额']].head())
# 姓名 时段 交易额
# 0 张三 9:00-14:00 1664.0
# 1 李四 14:00-21:00 954.0
# 2 王五 9:00-14:00 1407.0
# 3 赵六 14:00-21:00 1320.0
# 4 周七 9:00-14:00 994.0
print(market.loc[[3,4,7],['姓名','时段','柜台']])
# 姓名 时段 柜台
# 3 赵六 14:00-21:00 食品
# 4 周七 9:00-14:00 日用品
# 7 张三 14:00-21:00 蔬菜水果
'''查看交易额大于 2000 的数据'''
print(market[market.交易额 > 1500].head())
# 工号 姓名 日期 时段 交易额 柜台
# 0 1001 张三 2019-03-01 9:00-14:00 1664.0 化妆品
# 8 1001 张三 2019-03-02 9:00-14:00 1530.0 化妆品
# 14 1002 李四 2019-03-02 9:00-14:00 1649.0 蔬菜水果
# 18 1003 王五 2019-03-03 9:00-14:00 1713.0 食品
# 20 1005 周七 2019-03-03 9:00-14:00 1592.0 日用品
'''查看交易额的总和'''
print(market['交易额'].sum())
# 327257.0
print(market[market['时段'] == '9:00-14:00']['交易额'].sum())
# 176029.0
'''查看某员工在 14:00-21:00 的交易数据'''
print(market[(market.姓名 == '张三') & (market.时段 == '14:00-21:00')].head())
# 工号 姓名 日期 时段 交易额 柜台
# 7 1001 张三 2019-03-01 14:00-21:00 1442.0 蔬菜水果
# 39 1001 张三 2019-03-05 14:00-21:00 856.0 蔬菜水果
# 73 1001 张三 2019-03-10 14:00-21:00 1040.0 化妆品
# 91 1001 张三 2019-03-12 14:00-21:00 1435.0 食品
# 99 1001 张三 2019-03-13 14:00-21:00 1333.0 食品
'''查看交易额在 1500 到 2500 的数据'''
print(market[market['交易额'].between(1500,2000)].head())
# 工号 姓名 日期 时段 交易额 柜台
# 0 1001 张三 2019-03-01 9:00-14:00 1664.0 化妆品
# 8 1001 张三 2019-03-02 9:00-14:00 1530.0 化妆品
# 14 1002 李四 2019-03-02 9:00-14:00 1649.0 蔬菜水果
# 18 1003 王五 2019-03-03 9:00-14:00 1713.0 食品
# 20 1005 周七 2019-03-03 9:00-14:00 1592.0 日用品
'''查看描述'''
print(market['交易额'].describe())
# count 246.000000
# mean 1330.313008
# std 904.300720
# min 53.000000
# 25% 1031.250000
# 50% 1259.000000
# 75% 1523.000000
# max 12100.000000
# Name: 交易额, dtype: float64
print(market['交易额'].quantile([0,0.25,0.5,0.75,1]))
# 0.00 53.00
# 0.25 1031.25
# 0.50 1259.00
# 0.75 1523.00
# 1.00 12100.00
# Name: 交易额, dtype: float64
'''查看中值'''
print(market['交易额'].median())
# 1259.0
'''查看最大值'''
print(market['交易额'].max())
# 12100.0
print(market['交易额'].nlargest(5))
# 105 12100.0
# 223 9031.0
# 113 1798.0
# 188 1793.0
# 136 1791.0
'''查看最小值'''
print(market['交易额'].min())
# 53.0
print(market['交易额'].nsmallest(5))
# 76 53.0
# 97 98.0
# 194 114.0
# 86 801.0
# 163 807.0
# Name: 交易额, dtype: float64
import pandas as pd
market = pd.read_excel('超市营业额.xlsx')
print(market.head())
# 工号 姓名 日期 时段 交易额 柜台
# 0 1001 张三 2019-03-01 9:00-14:00 1664.0 化妆品
# 1 1002 李四 2019-03-01 14:00-21:00 954.0 化妆品
# 2 1003 王五 2019-03-01 9:00-14:00 1407.0 食品
# 3 1004 赵六 2019-03-01 14:00-21:00 1320.0 食品
# 4 1005 周七 2019-03-01 9:00-14:00 994.0 日用品
'''对数据进行排序'''
print(market.sort_values(by = ['交易额','工号'],ascending = False).head())
# 工号 姓名 日期 时段 交易额 柜台
# 105 1001 张三 2019-03-14 9:00-14:00 12100.0 日用品
# 223 1003 王五 2019-03-28 9:00-14:00 9031.0 食品
# 113 1002 李四 2019-03-15 9:00-14:00 1798.0 日用品
# 188 1002 李四 2019-03-24 14:00-21:00 1793.0 蔬菜水果
# 136 1001 张三 2019-03-17 14:00-21:00 1791.0 食品
print(market.sort_values(by = ['交易额','工号'],ascending = True).head())
# 工号 姓名 日期 时段 交易额 柜台
# 76 1005 周七 2019-03-10 9:00-14:00 53.0 日用品
# 97 1002 李四 2019-03-13 14:00-21:00 98.0 日用品
# 194 1001 张三 2019-03-25 14:00-21:00 114.0 化妆品
# 86 1003 王五 2019-03-11 9:00-14:00 801.0 蔬菜水果
# 163 1006 钱八 2019-03-21 9:00-14:00 807.0 蔬菜水果
'''groupby 对象 的使用'''
print(market.groupby(by = lambda x:x%3)['交易额'].sum())
# 0 113851.0
# 1 108254.0
# 2 105152.0
# Name: 交易额, dtype: float64
'''查看 柜台的交易额 '''
print(market.groupby(by = '柜台')['交易额'].sum())
# 柜台
# 化妆品 75389.0
# 日用品 88162.0
# 蔬菜水果 78532.0
# 食品 85174.0
# Name: 交易额, dtype: float64
'''查看日期个数'''
print(market.groupby(by = '姓名')['日期'].count())
# 姓名
# 周七 42
# 张三 38
# 李四 47
# 王五 40
# 赵六 45
# 钱八 37
# Name: 日期, dtype: int64
'''将员工的营业额汇总出来'''
print(market.groupby(by = '姓名')['交易额'].sum().apply(int))
# 姓名
# 周七 47818
# 张三 58130
# 李四 58730
# 王五 58892
# 赵六 56069
# 钱八 47618
# Name: 交易额, dtype: int64
'''查看交易额的 最大最小平均值和中值'''
print(market.groupby(by = '姓名').agg(['max','min','mean','median'])['交易额'])
# max min mean median
# 姓名
# 周七 1778.0 53.0 1195.450000 1134.5
# 张三 12100.0 114.0 1529.736842 1290.0
# 李四 1798.0 98.0 1249.574468 1276.0
# 王五 9031.0 801.0 1472.300000 1227.0
# 赵六 1775.0 825.0 1245.977778 1224.0
# 钱八 1737.0 807.0 1322.722222 1381.0
'''处理异常值'''
# 考虑使用其他数据替代
'''处理缺失值'''
print(market[market['交易额'].isnull()])
# 工号 姓名 日期 时段 交易额 柜台
# 110 1005 周七 2019-03-14 14:00-21:00 NaN 化妆品
# 124 1006 钱八 2019-03-16 14:00-21:00 NaN 食品
# 168 1005 周七 2019-03-21 14:00-21:00 NaN 食品
# 考虑使用 平均值 替换
'''处理重复值'''
# 考虑是否删除数据
'''duplicated() 和 drop_duplicates()'''
'''使用透视表,查看前五天的数据'''
print(market.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'sum').iloc[:,:5])
print(market.pivot_table(values = '交易额',index = '姓名',columns = '柜台',aggfunc = 'count').iloc[:,:5])
'''使用交叉表,查看员工和柜台的次数'''
print(pd.crosstab(market['姓名'],market['柜台']))
# 姓名
# 周七 9 11 14 8
# 张三 19 6 6 7
# 李四 16 9 18 4
# 王五 8 9 9 14
# 赵六 10 18 2 15
# 钱八 0 9 14 14
print(pd.crosstab(market['姓名'],market['日期']))
# 日期 2019-03-01 2019-03-02 2019-03-03 ... 2019-03-29 2019-03-30 2019-03-31
# 姓名 ...
# 周七 1 1 2 ... 1 1 2
# 张三 2 1 1 ... 1 2 0
# 李四 1 2 1 ... 2 2 2
# 王五 1 2 1 ... 1 1 1
# 赵六 1 1 2 ... 2 1 2
# 钱八 2 1 1 ... 1 1 1
print(pd.crosstab(market['姓名'],market['柜台'],market['交易额'],aggfunc = 'mean').apply(lambda x:round(x)))
# 柜台 化妆品 日用品 蔬菜水果 食品
# 姓名
# 周七 1190.0 1169.0 1174.0 1285.0
# 张三 1209.0 3105.0 1211.0 1323.0
# 李四 1279.0 1123.0 1292.0 1224.0
# 王五 1264.0 1262.0 1164.0 1925.0
# 赵六 1232.0 1294.0 1264.0 1196.0
# 钱八 NaN 1325.0 1326.0 1318.0
学生成绩表数据包括:学号,姓名,高数,英语和计算机三门课成绩,计算每个学生总分,每课程平均分,最高分和最低分
'''
每一个学生的总分,每个课程的平均分,最高分,最低分
'''
# 创建学生列表
stuLst = []
# 创建学生信息
stu1 = {'学号':'1001','姓名':'小明','高数':95,'英语':88,'计算机':80}
stu2 = {'学号':'1002','姓名':'小李','高数':84,'英语':70,'计算机':60}
stu3 = {'学号':'1003','姓名':'小王','高数':79,'英语':78,'计算机':75}
# 将学生列表加入到学生信息中
stuLst.append(stu1)
stuLst.append(stu2)
stuLst.append(stu3)
def sumScore(stuLst):
'''计算每名学生的总分'''
for stu in stuLst:
print(stu['姓名'],"的三科总分是 ",stu['高数'] + stu['英语'] + stu['计算机'])
def meanScore(stuLst):
'''计算课程的平均分'''
sumProjectScore_gs = 0
# 设置高数学科总分
sumProjectScore_yy = 0
# 设置英语学科总分
sumProjectScore_jsj = 0
# 设置计算机学科总分(_拼音缩写)
for stu in stuLst:
sumProjectScore_gs += stu['高数']
sumProjectScore_yy += stu['英语']
sumProjectScore_jsj += stu['计算机']
print("高数的平均分是 %.2f"%(sumProjectScore_gs//len(stuLst)))
print("英语的平均分是 %.2f" % (sumProjectScore_yy // len(stuLst)))
print("计算机的平均分是 %.2f" % (sumProjectScore_jsj // len(stuLst)))
def maxScore(stuLst):
'''求最大值'''
# 高数 英语 计算机
gs = []
yy = []
jsj = []
for stu in stuLst:
gs.append(stu['高数'])
yy.append(stu['英语'])
jsj.append(stu['计算机'])
print("高数的最高分是 %.2f"%(max(gs)))
print("英语的最高分是 %.2f" % (max(yy)))
print("计算机的最高分是 %.2f" % (max(jsj)))
def minScore(stuLst):
'''求最小值'''
# 高数 英语 计算机
gs = []
yy = []
jsj = []
for stu in stuLst:
gs.append(stu['高数'])
yy.append(stu['英语'])
jsj.append(stu['计算机'])
print("高数的最低分是 %.2f" % (min(gs)))
print("英语的最低分是 %.2f" % (min(yy)))
print("计算机的最低分是 %.2f" % (min(jsj)))
sumScore(stuLst)
meanScore(stuLst)
maxScore(stuLst)
minScore(stuLst)
四位玫瑰数
for i in range(1000,10000):
t=str(i)
if pow(eval(t[0]),4)+pow(eval(t[1]),4)+pow(eval(t[2]),4)+pow(eval(t[3]),4) == i:
print(i)
四平方和
import math
def f(n):
if isinstance(n,int):
for i in range(round(math.sqrt(n))):
for j in range(round(math.sqrt(n))):
for k in range(round(math.sqrt(n))):
h = math.sqrt(n - i*i - j*j - k*k)
# 剪掉使用了的值
if h == int(h):
print("(%d,%d,%d,%d)"%(i,j,k,h))
return
else:
print("(0,0,0,0)")
f(5)
f(12)
f("aaa")

学生管理系统-明日学院的
import re # 导入正则表达式模块
import os # 导入操作系统模块
filename = "students.txt" # 定义保存学生信息的文件名
def menu():
# 输出菜单
print('''
╔———————学生信息管理系统————————╗
│ │
│ =============== 功能菜单 =============== │
│ │
│ 1 录入学生信息 │
│ 2 查找学生信息 │
│ 3 删除学生信息 │
│ 4 修改学生信息 │
│ 5 排序 │
│ 6 统计学生总人数 │
│ 7 显示所有学生信息 │
│ 0 退出系统 │
│ ========================================== │
│ 说明:通过数字或↑↓方向键选择菜单 │
╚———————————————————————╝
''')
def main():
ctrl = True # 标记是否退出系统
while (ctrl):
menu() # 显示菜单
option = input("请选择:") # 选择菜单项
option_str = re.sub("\D", "", option) # 提取数字
if option_str in ['0', '1', '2', '3', '4', '5', '6', '7']:
option_int = int(option_str)
if option_int == 0: # 退出系统
print('您已退出学生成绩管理系统!')
ctrl = False
elif option_int == 1: # 录入学生成绩信息
insert()
elif option_int == 2: # 查找学生成绩信息
search()
elif option_int == 3: # 删除学生成绩信息
delete()
elif option_int == 4: # 修改学生成绩信息
modify()
elif option_int == 5: # 排序
sort()
elif option_int == 6: # 统计学生总数
total()
elif option_int == 7: # 显示所有学生信息
show()
'''1 录入学生信息'''
def insert():
stdentList = [] # 保存学生信息的列表
mark = True # 是否继续添加
while mark:
id = input("请输入ID(如 1001):")
if not id: # ID为空,跳出循环
break
name = input("请输入名字:")
if not name: # 名字为空,跳出循环
break
try:
english = int(input("请输入英语成绩:"))
python = int(input("请输入Python成绩:"))
c = int(input("请输入C语言成绩:"))
except:
print("输入无效,不是整型数值....重新录入信息")
continue
stdent = {"id": id, "name": name, "english": english, "python": python, "c": c} # 将输入的学生信息保存到字典
stdentList.append(stdent) # 将学生字典添加到列表中
inputMark = input("是否继续添加?(y/n):")
if inputMark == "y": # 继续添加
mark = True
else: # 不继续添加
mark = False
save(stdentList) # 将学生信息保存到文件
print("学生信息录入完毕!!!")
# 将学生信息保存到文件
def save(student):
try:
students_txt = open(filename, "a") # 以追加模式打开
except Exception as e:
students_txt = open(filename, "w") # 文件不存在,创建文件并打开
for info in student:
students_txt.write(str(info) + "\n") # 按行存储,添加换行符
students_txt.close() # 关闭文件
'''2 查找学生成绩信息'''
def search():
mark = True
student_query = [] # 保存查询结果的学生列表
while mark:
id = ""
name = ""
if os.path.exists(filename): # 判断文件是否存在
mode = input("按ID查输入1;按姓名查输入2:")
if mode == "1":
id = input("请输入学生ID:")
elif mode == "2":
name = input("请输入学生姓名:")
else:
print("您的输入有误,请重新输入!")
search() # 重新查询
with open(filename, 'r') as file: # 打开文件
student = file.readlines() # 读取全部内容
for list in student:
d = dict(eval(list)) # 字符串转字典
if id != "": # 判断是否按ID查
if d['id'] == id:
student_query.append(d) # 将找到的学生信息保存到列表中
elif name != "": # 判断是否按姓名查
if d['name'] == name:
student_query.append(d) # 将找到的学生信息保存到列表中
show_student(student_query) # 显示查询结果
student_query.clear() # 清空列表
inputMark = input("是否继续查询?(y/n):")
if inputMark == "y":
mark = True
else:
mark = False
else:
print("暂未保存数据信息...")
return
'''3 删除学生成绩信息'''
def delete():
mark = True # 标记是否循环
while mark:
studentId = input("请输入要删除的学生ID:")
if studentId != "": # 判断要删除的学生是否存在
if os.path.exists(filename): # 判断文件是否存在
with open(filename, 'r') as rfile: # 打开文件
student_old = rfile.readlines() # 读取全部内容
else:
student_old = []
ifdel = False # 标记是否删除
if student_old: # 如果存在学生信息
with open(filename, 'w') as wfile: # 以写方式打开文件
d = {} # 定义空字典
for list in student_old:
d = dict(eval(list)) # 字符串转字典
if d['id'] != studentId:
wfile.write(str(d) + "\n") # 将一条学生信息写入文件
else:
ifdel = True # 标记已经删除
if ifdel:
print("ID为 %s 的学生信息已经被删除..." % studentId)
else:
print("没有找到ID为 %s 的学生信息..." % studentId)
else: # 不存在学生信息
print("无学生信息...")
break # 退出循环
show() # 显示全部学生信息
inputMark = input("是否继续删除?(y/n):")
if inputMark == "y":
mark = True # 继续删除
else:
mark = False # 退出删除学生信息功能
'''4 修改学生成绩信息'''
def modify():
show() # 显示全部学生信息
if os.path.exists(filename): # 判断文件是否存在
with open(filename, 'r') as rfile: # 打开文件
student_old = rfile.readlines() # 读取全部内容
else:
return
studentid = input("请输入要修改的学生ID:")
with open(filename, "w") as wfile: # 以写模式打开文件
for student in student_old:
d = dict(eval(student)) # 字符串转字典
if d["id"] == studentid: # 是否为要修改的学生
print("找到了这名学生,可以修改他的信息!")
while True: # 输入要修改的信息
try:
d["name"] = input("请输入姓名:")
d["english"] = int(input("请输入英语成绩:"))
d["python"] = int(input("请输入Python成绩:"))
d["c"] = int(input("请输入C语言成绩:"))
except:
print("您的输入有误,请重新输入。")
else:
break # 跳出循环
student = str(d) # 将字典转换为字符串
wfile.write(student + "\n") # 将修改的信息写入到文件
print("修改成功!")
else:
wfile.write(student) # 将未修改的信息写入到文件
mark = input("是否继续修改其他学生信息?(y/n):")
if mark == "y":
modify() # 重新执行修改操作
'''5 排序'''
def sort():
show() # 显示全部学生信息
if os.path.exists(filename): # 判断文件是否存在
with open(filename, 'r') as file: # 打开文件
student_old = file.readlines() # 读取全部内容
student_new = []
for list in student_old:
d = dict(eval(list)) # 字符串转字典
student_new.append(d) # 将转换后的字典添加到列表中
else:
return
ascORdesc = input("请选择(0升序;1降序):")
if ascORdesc == "0": # 按升序排序
ascORdescBool = False # 标记变量,为False表示升序排序
elif ascORdesc == "1": # 按降序排序
ascORdescBool = True # 标记变量,为True表示降序排序
else:
print("您的输入有误,请重新输入!")
sort()
mode = input("请选择排序方式(1按英语成绩排序;2按Python成绩排序;3按C语言成绩排序;0按总成绩排序):")
if mode == "1": # 按英语成绩排序
student_new.sort(key=lambda x: x["english"], reverse=ascORdescBool)
elif mode == "2": # 按Python成绩排序
student_new.sort(key=lambda x: x["python"], reverse=ascORdescBool)
elif mode == "3": # 按C语言成绩排序
student_new.sort(key=lambda x: x["c"], reverse=ascORdescBool)
elif mode == "0": # 按总成绩排序
student_new.sort(key=lambda x: x["english"] + x["python"] + x["c"], reverse=ascORdescBool)
else:
print("您的输入有误,请重新输入!")
sort()
show_student(student_new) # 显示排序结果
''' 6 统计学生总数'''
def total():
if os.path.exists(filename): # 判断文件是否存在
with open(filename, 'r') as rfile: # 打开文件
student_old = rfile.readlines() # 读取全部内容
if student_old:
print("一共有 %d 名学生!" % len(student_old))
else:
print("还没有录入学生信息!")
else:
print("暂未保存数据信息...")
''' 7 显示所有学生信息 '''
def show():
student_new = []
if os.path.exists(filename): # 判断文件是否存在
with open(filename, 'r') as rfile: # 打开文件
student_old = rfile.readlines() # 读取全部内容
for list in student_old:
student_new.append(eval(list)) # 将找到的学生信息保存到列表中
if student_new:
show_student(student_new)
else:
print("暂未保存数据信息...")
# 将保存在列表中的学生信息显示出来
def show_student(studentList):
if not studentList:
print("无数据信息 \n")
return
format_title = "{:^6}{:^12}\t{:^8}\t{:^10}\t{:^10}\t{:^10}"
print(format_title.format("ID", "名字", "英语成绩", "Python成绩", "C语言成绩", "总成绩"))
format_data = "{:^6}{:^12}\t{:^12}\t{:^12}\t{:^12}\t{:^12}"
for info in studentList:
print(format_data.format(info.get("id"), info.get("name"), str(info.get("english")), str(info.get("python")),
str(info.get("c")),
str(info.get("english") + info.get("python") + info.get("c")).center(12)))
if __name__ == "__main__":
main()
定义函数,给定一个列表作为函数参数,将列表中的非数字字符去除
'''定义函数,给定一个列表作为函数参数,将列表中的非数字字符去除。'''
class list:
def __init__(self,alist):
self.alist=alist
def remove_str(self):
a=""
for i in self.alist:
b=str(i)
a+=b
"".join (filter(str.isdigit,a))
print("".join(filter(str.isdigit,a)))
a=list([1,2,3,"q",6,"sd","[][]{"])
a.remove_str()
给定几位数,查看数根(使用函数实现)
def numRoot(num):
'''定义数根函数'''
if len(num) == 1:
return int(num)
else:
nums = []
for i in range(len(num)):
# 对字符串进行遍历
nums.append(int(num[i]))
if sum(nums) >= 10:
# 如果数值加起来大于 10
numRoot(str(sum(nums)))
else:
# 输出树根
print(sum(nums))
num = input("请输入一个数,查看它的数根")
numRoot(num)
水果系统(面向过程,面向对象)
fruit = []
def menu():
print(
'''
********************水果超市******************** (面向对象,面向过程)
1. 查询全部水果
2. 查询指定名称的水果
3. 增加水果(增加到数据库)
4. 修改水果数量或者价格
5. 删除水果
6. 按照价格排序
7. 退出系统
***********************************************
'''
)
def showFruit():
'''功能1 查询全部水果'''
print('-' * 30)
print("水果的信息如下:")
print('-' * 30)
print('序号 水果名 价格 数量')
fru_id = 1
for fru_temp in fruit:
print("%s %s %s %s "%(fru_id,fru_temp['name'],fru_temp['price'],fru_temp['num']))
fru_id += 1
def searchFruitName():
'''功能2 查询指定名称的水果'''
showFruit()
fru_name = input("请输入想要查询的水果名称")
fru_id = 1
for fru in fruit:
if fru_name in fru['name']:
print("该水果信息如下:")
print("%d %s %s %s " % (fru_id, fru['name'], fru['price'], fru['num']))
return
fru_id += 1
print("没有查询到该水果名称")
def addFruit():
'''功能3 增加水果(增加到数据库)'''
newFruitName = input('请输入新水果的名称')
newFruitPrice = input('请输入新水果的价格')
newFruitNum = input('请输入新水果的数量')
newFruit = {}
newFruit['name'] = newFruitName
newFruit['price'] = newFruitPrice
newFruit['num'] = newFruitNum
fruit.append(newFruit)
def changeFruit():
'''功能4 修改水果数量或者价格'''
showFruit()
fru_id = int(input("请输入需要修改的水果的序号: "))
changeFruitName = input('请输入修改后的水果的名称')
changeFruitPrice = input('请输入修改后的水果的价格')
changeFruitNum = input('请输入修改后的水果的数量')
fruit[fru_id - 1]['name'] = changeFruitName
fruit[fru_id - 1]['price'] = changeFruitPrice
fruit[fru_id - 1]['num'] = changeFruitNum
def delFruit():
'''功能5 删除水果'''
showFruit()
delFruitId = int(input('请输入要删除的序号:'))
del fruit[delFruitId - 1]
def sortFruit():
'''功能6 按照价格排序'''
showFruit()
sortStandard = input("请选择(0升序;1降序):")
if sortStandard == "0":
sortStandard = True
elif sortStandard == "1":
sortStandard = False
else:
print("您的输入有误,请重新输入!")
fruit.sort(key = lambda x:x['price'],reverse = sortStandard)
showFruit()
def exitSystem():
'''功能7 退出系统'''
print("您已经退出水果超市系统")
exit()
def main():
notExit = True
while notExit:
menu()
try:
option = int(input("请选择功能:"))
except Exception as e:
print("请重新输入")
if option in [i for i in range(1,8)]:
if option == 1:
showFruit()
elif option == 2:
searchFruitName()
elif option == 3:
addFruit()
elif option == 4:
changeFruit()
elif option == 5:
delFruit()
elif option == 6:
sortFruit()
elif option == 7:
notExit = False
exitSystem()
if __name__ == '__main__':
main()
class FruitMarket():
def __init__(self):
self.fruit = []
def showFruit(self):
'''功能1 查询全部水果'''
print('-' * 30)
print("水果的信息如下:")
print('-' * 30)
print('序号 水果名 价格 数量')
fru_id = 1
for fru_temp in self.fruit:
print("%s %s %s %s " % (fru_id, fru_temp['name'], fru_temp['price'], fru_temp['num']))
fru_id += 1
def searchFruitName(self):
'''功能2 查询指定名称的水果'''
self.showFruit()
fru_name = input("请输入想要查询的水果名称")
fru_id = 1
for fru in self.fruit:
if fru_name in fru['name']:
print("该水果信息如下:")
print("%d %s %s %s " % (fru_id, fru['name'], fru['price'], fru['num']))
return
fru_id += 1
print("没有查询到该水果名称")
def addFruit(self):
'''功能3 增加水果(增加到数据库)'''
newFruitName = input('请输入新水果的名称')
newFruitPrice = input('请输入新水果的价格')
newFruitNum = input('请输入新水果的数量')
newFruit = {}
newFruit['name'] = newFruitName
newFruit['price'] = newFruitPrice
newFruit['num'] = newFruitNum
self.fruit.append(newFruit)
def changeFruit(self):
'''功能4 修改水果数量或者价格'''
self.showFruit()
fru_id = int(input("请输入需要修改的水果的序号: "))
changeFruitName = input('请输入修改后的水果的名称')
changeFruitPrice = input('请输入修改后的水果的价格')
changeFruitNum = input('请输入修改后的水果的数量')
self.fruit[fru_id - 1]['name'] = changeFruitName
self.fruit[fru_id - 1]['price'] = changeFruitPrice
self.fruit[fru_id - 1]['num'] = changeFruitNum
def delFruit(self):
'''功能5 删除水果'''
self.showFruit()
delFruitId = int(input('请输入要删除的序号:'))
del self.fruit[delFruitId - 1]
def sortFruit(self):
'''功能6 按照价格排序'''
self.showFruit()
sortStandard = input("请选择(0升序;1降序):")
if sortStandard == "0":
sortStandard = True
elif sortStandard == "1":
sortStandard = False
else:
print("您的输入有误,请重新输入!")
self.fruit.sort(key=lambda x: x['price'], reverse=sortStandard)
self.showFruit()
def exitSystem(self):
'''功能7 退出系统'''
print("您已经退出水果超市系统")
exit()
def menu( ):
print(
'''
********************水果超市******************** (面向对象,面向过程)
1. 查询全部水果
2. 查询指定名称的水果
3. 增加水果(增加到数据库)
4. 修改水果数量或者价格
5. 删除水果
6. 按照价格排序
7. 退出系统
***********************************************
'''
)
fruitmarket = FruitMarket()
def main():
notExit = True
while notExit:
menu()
try:
option = int(input("请选择功能:"))
except Exception as e:
print("请重新输入")
if option == 1:
fruitmarket.showFruit()
elif option == 2:
fruitmarket.searchFruitName()
elif option == 3:
fruitmarket.addFruit()
elif option == 4:
fruitmarket.changeFruit()
elif option == 5:
fruitmarket.delFruit()
elif option == 6:
fruitmarket.sortFruit()
elif option == 7:
notExit = False
fruitmarket.exitSystem()
if __name__ == '__main__':
main()
matplotlib基础汇总_01
灰度化处理就是将一幅色彩图像转化为灰度图像的过程。彩色图像分为R,G,B三个分量,
分别显示出红绿蓝等各种颜色,灰度化就是使彩色的R,G,B分量相等的过程。
灰度值大的像素点比较亮(像素值最大为255,为白色),反之比较暗(像素最下为0,为黑色)。
图像灰度化的算法主要有以下3种:

data2 = data.mean(axis = 2)


data3 = np.dot(data,[0.299,0.587,0.114])
Matplotlib中的基本图表包括的元素
x轴和y轴
水平和垂直的轴线
x轴和y轴刻度
刻度标示坐标轴的分隔,包括最小刻度和最大刻度
x轴和y轴刻度标签
表示特定坐标轴的值
绘图区域
实际绘图的区域
绘制一条曲线
x = np.arange(0.0,6.0,0.01)
plt.plot(x, x**2)
plt.show()
绘制多条曲线
x = np.arange(1, 5,0.01)
plt.plot(x, x**2)
plt.plot(x, x**3.0)
plt.plot(x, x*3.0)
plt.show()
x = np.arange(1, 5)
plt.plot(x, x*1.5, x, x*3.0, x, x/3.0)
plt.show()
绘制网格线
设置grid参数(参数与plot函数相同)
lw代表linewidth,线的粗细
alpha表示线的明暗程度
# 使用子图显示不同网格线对比
fig = plt.figure(figsize=(20,3))
x = np.linspace(0, 5, 100)
# 使用默认网格设置
ax1 = fig.add_subplot(131)
ax1.plot(x, x**2, x, x**3,lw=2)
ax1.grid(True) # 显式网格线
# 对网格线进行设置
ax2 = fig.add_subplot(132)
ax2.plot(x, x**2, x, x**4, lw=2)
ax2.grid(color='r', alpha=0.5, linestyle='dashed', linewidth=0.5) # grid函数中用与plot函数同样的参数设置网格线
# 对网格线进行设置
ax3 = fig.add_subplot(133)
ax3.plot(x, x**2, x, x**4, lw=2)
ax3.grid(color='r', alpha=0.5, linestyle='-.', linewidth=0.5) # grid函数中用与plot函数同样的参数设置网格线
坐标轴界限 axis 方法
x = np.arange(1, 5)
plt.plot(x, x*1.5, x, x*3.0, x, x/3.0)
# plt.axis() # shows the current axis limits values;如果axis方法没有任何参数,则返回当前坐标轴的上下限
# (1.0, 4.0, 0.0, 12.0)
# plt.axis([0, 15, -5, 13]) # set new axes limits;axis方法中有参数,设置坐标轴的上下限;参数顺序为[xmin, xmax, ymin, ymax]
plt.axis(xmax=5,ymax=23) # 可使用xmax,ymax参数
plt.show()
设置紧凑型坐标轴
x = np.arange(1, 5)
plt.plot(x, x*1.5, x, x*3.0, x, x/3.0)
plt.axis('tight') # 紧凑型坐标轴
plt.show()
plt除了axis方法设置坐标轴范围,还可以通过xlim,ylim设置坐标轴范围
x = np.arange(1, 5)
plt.plot(x, x*1.5, x, x*3.0, x, x/3.0)
plt.xlim([0, 5]) # ylim([ymin, ymax])
plt.ylim([-1, 13]) # xlim([xmin, xmax])
plt.show()
坐标轴标签
plt.plot([1, 3, 2, 4])
plt.xlabel('This is the X axis')
plt.ylabel('This is the Y axis')
plt.show()
坐标轴标题
plt.plot([1, 3, 2, 4])
plt.title('Simple plot')
plt.show()
label参数为'_nolegend_',则图例中不显示
x = np.arange(1, 5)
plt.plot(x, x*1.5, label = '_nolegend_') # label参数为'_nolegend_',则图例中不显示
plt.plot(x, x*3.0, label='Fast')
plt.plot(x, x/3.0, label='Slow')
plt.legend()
plt.show()


图例 legend
legend方法
两种传参方法:
【推荐使用】在plot函数中增加label参数
在legend方法中传入字符串列表
方法一:
x = np.arange(1, 5)
plt.plot(x, x*1.5, label='Normal') # 在plot函数中增加label参数
plt.plot(x, x*3.0, label='Fast')
plt.plot(x, x/3.0, label='Slow')
plt.legend()
plt.show()
方法二:
x = np.arange(1, 5)
plt.plot(x, x*1.5)
plt.plot(x, x*3.0)
plt.plot(x, x/3.0)
plt.legend(['Normal', 'Fast', 'Slow']) # 在legend方法中传入字符串列表
plt.show()
loc 参数
x = np.arange(1, 5)
plt.plot(x, x*1.5, label='Normal')
plt.plot(x, x*3.0, label='Fast')
plt.plot(x, x/3.0, label='Slow')
plt.legend(loc=10)
plt.show()
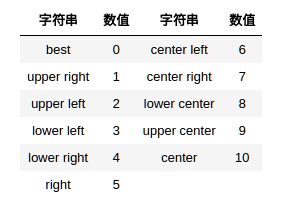

loc参数可以是2元素的元组,表示图例左下角的坐标
x = np.arange(1, 5)
plt.plot(x, x*1.5, label='Normal')
plt.plot(x, x*3.0, label='Fast')
plt.plot(x, x/3.0, label='Slow')
plt.legend(loc=(0,1)) # loc参数可以是2元素的元组,表示图例左下角的坐标
plt.show()

ncol参数控制图例中有几列
x = np.arange(1, 5)
plt.plot(x, x*1.5, label='Normal')
plt.plot(x, x*3.0, label='Fast')
plt.plot(x, x/3.0, label='Slow')
plt.legend(loc=0, ncol=2) # ncol控制图例中有几列
plt.show()

linestyle 属性
plt.plot(np.random.randn(1000).cumsum(), linestyle = ':',marker = '.', label='one')
plt.plot(np.random.randn(1000).cumsum(), 'r--', label='two')
plt.plot(np.random.randn(1000).cumsum(), 'b.', label='three')
plt.legend(loc='best') # loc='best'
plt.show()

保存图片
filename
含有文件路径的字符串或Python的文件型对象。图像格式由文件扩展名推断得出,例如,.pdf推断出PDF,.png推断出PNG (“png”、“pdf”、“svg”、“ps”、“eps”……)
dpi
图像分辨率(每英寸点数),默认为100
facecolor
图像的背景色,默认为“w”(白色)
x = np.random.randn(1000).cumsum()
fig = plt.figure(figsize = (10,3))
splt = fig.add_subplot(111)
splt.plot(x)
fig.savefig(filename = "filena.eps",dpi = 100,facecolor = 'g')
matplotlib基础汇总_02
设置plot的风格和样式
点和线的样式
颜色
参数color或c
五种定义颜色值的方式
别名
color='r'
合法的HTML颜色名
color = 'red'
HTML十六进制字符串
color = '#eeefff'
归一化到[0, 1]的RGB元组
color = (0.3, 0.3, 0.4)
灰度
color = (0.1)

透明度
y = np.arange(1, 3)
plt.plot(y, c="red", alpha=0.1); # 设置透明度
plt.plot(y+1, c="red", alpha=0.5);
plt.plot(y+2, c="red", alpha=0.9);
设置背景色
通过plt.subplot()方法传入facecolor参数,来设置坐标轴的背景色
plt.subplot(facecolor='orange');
plt.plot(np.random.randn(10),np.arange(1,11))

线型

不同宽度破折线
# 第一段线2个点的宽度,接下来的空白区5个点的宽度,第二段线5个点的宽度,空白区2个点的宽度,以此类推
plt.plot(np.linspace(-np.pi, np.pi, 256, endpoint=True),
np.cos(np.linspace(-np.pi, np.pi, 256, endpoint=True)),
dashes=[2, 5, 5, 2]);

点型
y = np.arange(1, 3, 0.2)
plt.plot(y, '1', y+0.5, '2', y+1, '3', y+1.5,'4');
plt.plot(y+2, '3') #不声明marker,默认ls = None
plt.plot(y+2.5,marker = '3') #声明了marker,ls 默认是实线
plt.show()

多参数连用
颜色、点型、线型
x = np.linspace(0, 5, 10)
plt.plot(x,3*x,'r-.')
plt.plot(x, x**2, 'b^:') # blue line with dots
plt.plot(x, x**3, 'go-.') # green dashed line
plt.show()
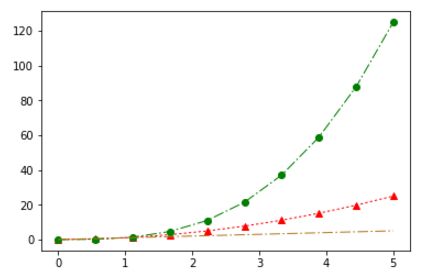
更多点和线的设置
y = np.arange(1, 3, 0.3)
plt.plot(y, color='blue',
linestyle='dashdot',
linewidth=4, marker='o',
markerfacecolor='red',
markeredgecolor='black',
markeredgewidth=3,
markersize=12);
plt.show()
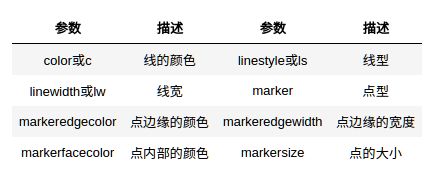
在一条语句中为多个曲线进行设置
多个曲线同一设置¶
plt.plot(x1, y1, x2, y2, fmt, ...)
多个曲线不同设置¶
plt.plot(x1, y1, fmt1, x2, y2, fmt2, ...)
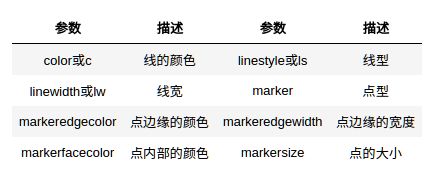
在一条语句中为多个曲线进行设置
多个曲线同一设置¶
plt.plot(x1, y1, x2, y2, fmt, ...)
多个曲线不同设置¶
plt.plot(x1, y1, fmt1, x2, y2, fmt2, ...)
三种设置方式
向方法传入关键字参数
对实例使用一系列的setter方法
x = np.arange(0,10)
y = np.random.randint(10,30,size = 10)
line,= plt.plot(x, y)
line2 = plt.plot(x,y*2,x,y*3)
line.set_linewidth(5)
line2[1].set_marker('o')
print(line,line2)
使用setp()方法
line = plt.plot(x, y)
plt.setp(line, 'linewidth', 1.5,'color','r','marker','o','linestyle','--')
X、Y轴坐标刻度
xticks()和yticks()方法
x = [5, 3, 7, 2, 4, 1]
plt.plot(x);
plt.xticks(range(len(x)), ['a', 'b', 'c', 'd', 'e', 'f']); # 传入位置和标签参数,以修改坐标轴刻度
plt.yticks(range(1, 8, 2));
plt.show()

面向对象方法
set_xticks、set_yticks、set_xticklabels、set_yticklabels方法
fig = plt.figure(figsize=(10, 4))
ax = fig.add_subplot(111)
x = np.linspace(0, 5, 100)
ax.plot(x, x**2, x, x**3, lw=2)
ax.set_xticks([1, 2, 3, 4, 5])
ax.set_xticklabels(['a','b','c','d','e'], fontsize=18)
yticks = [0, 50, 100, 150]
ax.set_yticks(yticks)
ax.set_yticklabels([y for y in yticks], fontsize=18); # use LaTeX formatted labels
正弦余弦:LaTex语法,用$\pi$等表达式在图表上写上希腊字母
x = np.arange(-np.pi,np.pi,0.01)
plt.figure(figsize=(12,9))
plt.plot(x,np.sin(x),x,np.cos(x))
plt.axis([x.min()-1,x.max()+1,-1.2,1.2])
#xticks:参数一刻度,参数二,对应刻度上的值
plt.xticks(np.arange(-np.pi,np.pi+1,np.pi/2),
['$-\delta$','$-\pi$/2','0','$\pi$/2','$\pi$'],size = 20)
plt.yticks([-1,0,1],['min','0','max'],size = 20)
plt.show()
matplotlib基础汇总_03
四图
直方图
【直方图的参数只有一个x!!!不像条形图需要传入x,y】
hist()的参数
bins
可以是一个bin数量的整数值,也可以是表示bin的一个序列。默认值为10
normed
如果值为True,直方图的值将进行归一化处理,形成概率密度,默认值为False
color
指定直方图的颜色。可以是单一颜色值或颜色的序列。如果指定了多个数据集合,颜色序列将会设置为相同的顺序。如果未指定,将会使用一个默认的线条颜色
orientation
通过设置orientation为horizontal创建水平直方图。默认值为vertical
x = np.random.randint(5,size = 5)
display(x)
plt.hist(x,histtype = 'bar'); # 默认绘制10个bin
plt.show()
普通直方图/累计直方图
n = np.random.randn(10000)
fig,axes = plt.subplots(1,2,figsize = (12,4))
axes[0].hist(n,bins = 50)#普通直方图
axes[0].set_title('Default histogram')
axes[0].set_xlim(min(n),max(n))
axes[1].hist(n,bins = 50,cumulative = True)# 累计直方图
axes[1].set_title('Cumulative detailed histogram')
axes[1].set_xlim(min(n),max(n))

正太分布
u = 100 #数学期望
s = 15 #方差
x = np.random.normal(u,s,1000) # 生成正太分布数据
ax = plt.gca() #获取当前图表
ax.set_xlabel('Value')
ax.set_ylabel('Frequency') #设置x,y轴标题
ax.set_title("Histogram normal u = 100 s = 15") #设置图表标题
ax.hist(x,bins = 100,color = 'r',orientation='horizontal')
plt.show()

条形图
bar
# 第一个参数为条形左下角的x轴坐标,第二个参数为条形的高度;
# matplotlib会自动设置条形的宽度,本例中条形宽0.8
plt.bar([1, 2, 3], [3, 2, 5]);
plt.show()
# width参数设置条形宽度;color参数设置条形颜色;bottom参数设置条形底部的垂直坐标
plt.bar([1, 2, 3], [3, 2, 5], width=0.5, color='r', bottom=1);
plt.ylim([0, 7])
plt.show()

# 例子:绘制并列条形图
data1 = 10*np.random.rand(5)
data2 = 10*np.random.rand(5)
data3 = 10*np.random.rand(5)
locs = np.arange(1, len(data1)+1)
width = 0.27
plt.bar(locs, data1, width=width);
plt.bar(locs+width, data2, width=width, color='red');
plt.bar(locs+2*width, data3, width=width, color='green') ;
plt.xticks(locs + width*1, locs);
plt.show()

barh
plt.barh([1, 2, 3], [3, 2, 5],height = 0.27,color = 'yellow');
plt.show()

饼图
【饼图也只有一个参数x!】
pie()
饼图适合展示各部分占总体的比例,条形图适合比较各部分的大小
plt.figure(figsize = (4,4)) # 饼图绘制正方形
x = [45,35,20] #百分比
labels = ['Cats','Dogs','Fishes'] #每个区域名称
plt.pie(x,labels = labels)
plt.show()

plt.figure(figsize=(4, 4));
x = [0.1, 0.2, 0.3] # 当各部分之和小于1时,则不计算各部分占总体的比例,饼的大小是数值和1之比
labels = ['Cats', 'Dogs', 'Fishes']
plt.pie(x, labels=labels); # labels参数可以设置各区域标签
plt.show()

# labels参数设置每一块的标签;labeldistance参数设置标签距离圆心的距离(比例值)
# autopct参数设置比例值的显示格式(%1.1f%%);pctdistance参数设置比例值文字距离圆心的距离
# explode参数设置每一块顶点距圆形的长度(比例值);colors参数设置每一块的颜色;
# shadow参数为布尔值,设置是否绘制阴影
plt.figure(figsize=(4, 4));
x = [4, 9, 21, 55, 30, 18]
labels = ['Swiss', 'Austria', 'Spain', 'Italy', 'France', 'Benelux']
explode = [0.2, 0.1, 0, 0, 0.1, 0]
colors = ['r', 'k', 'b', 'm', 'c', 'g']
plt.pie(x,
labels=labels,
labeldistance=1.2,
explode=explode,
colors=colors,
autopct='%1.1f%%',
pctdistance=0.5,
shadow=True);
plt.show()
散点图
【散点图需要两个参数x,y,但此时x不是表示x轴的刻度,而是每个点的横坐标!】
scatter()
# s参数设置散点的大小;c参数设置散点的颜色;marker参数设置散点的形状
x = np.random.randn(1000)
y = np.random.randn(1000)
size = 50*abs(np.random.randn(1000))
colors = np.random.randint(16777215,size = 1000)
li = []
for color in colors:
a = hex(color)
str1 = a[2:]
l = len(str1)
for i in range(1,7-l):
str1 = '0'+str1
str1 = "#" + str1
li.append(str1)
plt.scatter(x, y,s = size, c=li, marker='d');
plt.show()
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
x = np.random.randn(1000)
y1 = np.random.randn(1000)
y2 = 1.2 + np.exp(x) #exp(x) 返回的是e的x次方
ax1 = plt.subplot(121)
plt.scatter(x,y1,color = 'purple',alpha = 0.3,edgecolors = 'white',label = 'no correl')
plt.xlabel('no correlation')
plt.grid(True)
plt.legend()
ax2 = plt.subplot(122)
plt.scatter(x,y2,color = 'green',alpha = 0.3,edgecolors = 'gray',label = 'correl')
plt.xlabel('correlation')
plt.grid(True)
plt.legend()
plt.show()

图形内的文字、注释、箭头
文字
x = np.arange(0, 7, .01)
y = np.sin(x)
plt.plot(x, y);
plt.text(0.1, -0.04, 'sin(0)=0'); # 位置参数是坐标
plt.show()
注释
# xy参数设置箭头指示的位置,xytext参数设置注释文字的位置
# arrowprops参数以字典的形式设置箭头的样式
# width参数设置箭头长方形部分的宽度,headlength参数设置箭头尖端的长度,
# headwidth参数设置箭头尖端底部的宽度,shrink参数设置箭头顶点、尾部与指示点、注释文字的距离(比例值)
y = [13, 11, 13, 12, 13, 10, 30, 12, 11, 13, 12, 12, 12, 11, 12]
plt.plot(y);
plt.ylim(ymax=35); # 为了让注释不会超出图的范围,需要调整y坐标轴的界限
plt.annotate('this spot must really\nmean something', xy=(6, 30), xytext=(8, 31.5),
arrowprops=dict(width=15, headlength=20, headwidth=20, facecolor='black', shrink=0.1));
plt.show()
# 生成3个正态分布数据数据集
x1 = np.random.normal(30, 3, 100)
x2 = np.random.normal(20, 2, 100)
x3 = np.random.normal(10, 3, 100)
# 绘制3个数据集,并为每个plot指定一个字符串标签
plt.plot(x1, label='plot') # 如果不想在图例中显示标签,可以将标签设置为_nolegend_
plt.plot(x2, label='2nd plot')
plt.plot(x3, label='last plot')
# 绘制图例
plt.legend(bbox_to_anchor=(0, 1.02, 1, 0.102), # 指定边界框起始位置为(0, 1.02),并设置宽度为1,高度为0.102
ncol=3, # 设置列数为3,默认值为1
mode="expand", # mode为None或者expand,当为expand时,图例框会扩展至整个坐标轴区域
borderaxespad=0.) # 指定坐标轴和图例边界之间的间距
# 绘制注解
plt.annotate("Important value", # 注解文本的内容
xy=(55,20), # 箭头终点所在位置
xytext=(5, 38), # 注解文本的起始位置,箭头由xytext指向xy坐标位置
arrowprops=dict(arrowstyle='->')); # arrowprops字典定义箭头属性,此处用arrowstyle定义箭头风格
箭头

matplotlib基础汇总_04
3D图形
导包
import numpy as np
import matplotlib.pyplot as plt
#3d图形必须的
from mpl_toolkits.mplot3d.axes3d import Axes3D
%matplotlib inline
生成数据
#系数,由X,Y生成Z
a = 0.7
b = np.pi
#计算Z轴的值
def mk_Z(X, Y):
return 2 + a - 2 * np.cos(X) * np.cos(Y) - a * np.cos(b - 2*X)
#生成X,Y,Z
x = np.linspace(0, 2*np.pi, 100)
y = np.linspace(0, 2*np.pi, 100)
X,Y = np.meshgrid(x, y)
Z = mk_Z(X, Y)
绘制图形
fig = plt.figure(figsize=(14,6))
#创建3d的视图,使用属性projection
ax = fig.add_subplot(1, 2, 1, projection='3d')
ax.plot_surface(X,Y,Z,rstride = 5,cstride = 5)
#创建3d视图,使用colorbar,添加颜色柱
ax = fig.add_subplot(1, 2, 2, projection='3d')
p = ax.plot_surface(X, Y, Z, rstride=5, cstride=5, cmap='rainbow', antialiased=True)
cb = fig.colorbar(p, shrink=0.5)

玫瑰图
#极坐标条形图
def showRose(values,title):
max_value = values.max()
# 分为8个面元
N = 8
# 面元的分隔角度
angle = np.arange(0.,2 * np.pi, 2 * np.pi / N)
# 每个面元的大小(半径)
radius = np.array(values)
# 设置极坐标条形图
plt.axes([0, 0, 2, 2], polar=True,facecolor = 'g')
colors = [(1 - x/max_value, 1 - x/max_value, 0.75) for x in radius]
# 画图
plt.bar(angle, radius, width=(2*np.pi/N), bottom=0.0, color=colors)
plt.title(title,x=0.2, fontsize=20)
绘制图形
#拉韦纳(Ravenna)又译“腊万纳”“拉文纳”“拉温拿”。意大利北部城市。位于距亚得里亚海10公里的沿海平原上
data = np.load('Ravenna_wind.npy')
hist, angle = np.histogram(data,8,[0,360])
showRose(hist,'Ravenna')
城市气候与海洋关系
导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
%matplotlib inline
加载数据
#意大利小镇费拉拉
ferrara1 = pd.read_csv('./ferrara_150715.csv')
ferrara2 = pd.read_csv('./ferrara_250715.csv')
ferrara3 = pd.read_csv('./ferrara_270615.csv')
ferrara = pd.concat([ferrara1,ferrara2,ferrara3],ignore_index=True)
去除没用的列
asti.drop(['Unnamed: 0'],axis = 1,inplace=True)
bologna.drop(['Unnamed: 0'],axis = 1,inplace=True)
cesena.drop(['Unnamed: 0'],axis = 1,inplace=True)
ferrara.drop(['Unnamed: 0'],axis = 1,inplace=True)
mantova.drop(['Unnamed: 0'],axis = 1,inplace=True)
milano.drop(['Unnamed: 0'],axis = 1,inplace=True)
piacenza.drop(['Unnamed: 0'],axis = 1,inplace=True)
ravenna.drop(['Unnamed: 0'],axis = 1,inplace=True)
torino.drop(['Unnamed: 0'],axis = 1,inplace=True)
获取个城市距离海边距离,最高温度,最低温度,最高湿度,最低湿度
dist = [ravenna['dist'][0],
cesena['dist'][0],
faenza['dist'][0],
ferrara['dist'][0],
bologna['dist'][0],
mantova['dist'][0],
piacenza['dist'][0],
milano['dist'][0],
asti['dist'][0],
torino['dist'][0]
]
temp_max = [ravenna['temp'].max(),
cesena['temp'].max(),
faenza['temp'].max(),
ferrara['temp'].max(),
bologna['temp'].max(),
mantova['temp'].max(),
piacenza['temp'].max(),
milano['temp'].max(),
asti['temp'].max(),
torino['temp'].max()
]
temp_min = [ravenna['temp'].min(),
cesena['temp'].min(),
faenza['temp'].min(),
ferrara['temp'].min(),
bologna['temp'].min(),
mantova['temp'].min(),
piacenza['temp'].min(),
milano['temp'].min(),
asti['temp'].min(),
torino['temp'].min()
]
hum_min = [ravenna['humidity'].min(),
cesena['humidity'].min(),
faenza['humidity'].min(),
ferrara['humidity'].min(),
bologna['humidity'].min(),
mantova['humidity'].min(),
piacenza['humidity'].min(),
milano['humidity'].min(),
asti['humidity'].min(),
torino['humidity'].min()
]
hum_max = [ravenna['humidity'].max(),
cesena['humidity'].max(),
faenza['humidity'].max(),
ferrara['humidity'].max(),
bologna['humidity'].max(),
mantova['humidity'].max(),
piacenza['humidity'].max(),
milano['humidity'].max(),
asti['humidity'].max(),
torino['humidity'].max()
]
显示最高温度与离海远近的关系
plt.axis([0,400,32,35])
plt.plot(dist,temp_max,'ro')

根据距海远近划分数据
观察发现,离海近的可以形成一条直线,离海远的也能形成一条直线。
首先使用numpy:把列表转换为numpy数组,用于后续计算。
分别以100公里和50公里为分界点,划分为离海近和离海远的两组数据
# 把列表转换为numpy数组
x = np.array(dist)
display('x:',x)
y = np.array(temp_max)
display('y:',y)
# 离海近的一组数据
x1 = x[x<100]
x1 = x1.reshape((x1.size,1))
display('x1:',x1)
y1 = y[x<100]
display('y1:',y1)
# 离海远的一组数据
x2 = x[x>50]
x2 = x2.reshape((x2.size,1))
display('x2:',x2)
y2 = y[x>50]
display('y2:',y2)
机器学习计算回归模型
from sklearn.svm import SVR
svr_lin1 = SVR(kernel='linear', C=1e3)
svr_lin2 = SVR(kernel='linear', C=1e3)
svr_lin1.fit(x1, y1)
svr_lin2.fit(x2, y2)
xp1 = np.arange(10,100,10).reshape((9,1))
xp2 = np.arange(50,400,50).reshape((7,1))
yp1 = svr_lin1.predict(xp1)
yp2 = svr_lin2.predict(xp2)
绘制回归曲线
plt.plot(xp1, yp1, c='r', label='Strong sea effect')
plt.plot(xp2, yp2, c='b', label='Light sea effect')
#plt.axis('tight')
plt.legend()
plt.scatter(x, y, c='k', label='data')
最低温度与海洋距离关系
plt.axis((0,400,16,21))
plt.plot(dist,temp_min,'bo')

最低湿度与海洋距离关系
plt.axis([0,400,70,120])
plt.plot(dist,hum_min,'bo')
最高湿度与海洋距离关系
plt.axis([0,400,70,120])
plt.plot(dist,hum_max,'bo')
平均湿度与海洋距离的关系
hum_mean = [ravenna['humidity'].mean(),
cesena['humidity'].mean(),
faenza['humidity'].mean(),
ferrara['humidity'].mean(),
bologna['humidity'].mean(),
mantova['humidity'].mean(),
piacenza['humidity'].mean(),
milano['humidity'].mean(),
asti['humidity'].mean(),
torino['humidity'].mean()
]
plt.plot(dist,hum_mean,'bo')
风速与风向的关系
plt.plot(ravenna['wind_deg'],ravenna['wind_speed'],'ro')
在子图中,同时比较风向与湿度和风力的关系
plt.subplot(211)
plt.plot(cesena['wind_deg'],cesena['humidity'],'bo')
plt.subplot(212)
plt.plot(cesena['wind_deg'],cesena['wind_speed'],'bo')
玫瑰图
def showRoseWind(values,city_name):
'''
查看风向图,半径越大,代表这个方向上的风越多
'''
max_value = values.max()
# 分为8个面元
N = 8
# 面元的分隔角度
theta = np.arange(0.,2 * np.pi, 2 * np.pi / N)
# 每个面元的大小(半径)
radii = np.array(values)
# 设置极坐标条形图
plt.axes([0.025, 0.025, 0.95, 0.95], polar=True)
colors = [(1 - x/max_value, 1 - x/max_value, 0.75) for x in radii]
# 画图
plt.bar(theta, radii, width=(2*np.pi/N), bottom=0.0, color=colors)
plt.title(city_name,x=0.2, fontsize=20)
用numpy创建一个直方图,将360度划分为8个面元,将数据分类到这8个面元中
hist, bin = np.histogram(ravenna['wind_deg'],8,[0,360])
print(hist)
hist = hist/hist.sum()
print(bin)
showRoseWind(hist,'Ravenna')

计算米兰各个方向的风速
print(milano[milano['wind_deg']<45]['wind_speed'].mean())
print(milano[(milano['wind_deg']>44) & (milano['wind_deg']<90)]['wind_speed'].mean())
print(milano[(milano['wind_deg']>89) & (milano['wind_deg']<135)]['wind_speed'].mean())
print(milano[(milano['wind_deg']>134) & (milano['wind_deg']<180)]['wind_speed'].mean())
print(milano[(milano['wind_deg']>179) & (milano['wind_deg']<225)]['wind_speed'].mean())
print(milano[(milano['wind_deg']>224) & (milano['wind_deg']<270)]['wind_speed'].mean())
print(milano[(milano['wind_deg']>269) & (milano['wind_deg']<315)]['wind_speed'].mean())
print(milano[milano['wind_deg']>314]['wind_speed'].mean())
将各个方向风速保存到列表中
degs = np.arange(45,361,45)
tmp = []
for deg in degs:
tmp.append(milano[(milano['wind_deg']>(deg-46)) & (milano['wind_deg']
画出各个方向的风速
N = 8
theta = np.arange(0.,2 * np.pi, 2 * np.pi / N)
radii = np.array(speeds)
plt.axes([0.025, 0.025, 0.95, 0.95], polar=True)
colors = [(1-x/10.0, 1-x/10.0, 0.75) for x in radii]
bars = plt.bar(theta, radii, width=(2*np.pi/N), bottom=0.0, color=colors)
plt.title('Milano',x=0.2, fontsize=20)

抽取函数
def RoseWind_Speed(city):
degs = np.arange(45,361,45)
tmp = []
for deg in degs:
tmp.append(city[(city['wind_deg']>(deg-46)) & (city['wind_deg']
函数调用
showRoseWind_Speed(RoseWind_Speed(ravenna),'Ravenna')
根据列表的值来显示每一个元素出现的次数
lst = ['中雨','雷阵雨','中到大雨','阴','多云','晴','中雨']
dic = {}
for i in lst:
if i not in dic:
dic[i] = lst.count(i)
print(dic)
钻石和玻璃球游戏(钻石位置固定)

'''
开始,你可以随意选择一个抽屉,在开启它之前,
主持人会开启另外一个抽屉,露出抽屉里的玻璃球。
这时,主持人会给你一次更换自己选择的机会。
请自己认真分析一下“不换选择能有更高的几率获得钻石,
还是换选择能有更高的几率获得钻石?或几率没有发生变化?”写出你分析的思路和结果。
设法编写python程序验证自己的想法,
验证的结果支持了你的分析结果,还是没有支持你的分析结果,
请写出结果,并附上你的程序代码,并在程序代码中通过注释说明你解决问题的思路。
(提示:可以借助随机数函数完成此程序)
'''
import random
print("钻石和玻璃球的游戏开始了")
# 摆在你面前有3个关闭的抽屉
lst_dic = [{'抽屉':'钻石'},{'抽屉':'玻璃球'},{'抽屉':'玻璃球'}]
# 定义钻石
zs = 0
# 定义玻璃球
blq = 0
def Game(your_choice,lst_dic):
isLouchu = False
# 查看主持人是否露出
for num in range(len(lst_dic)):
if not isLouchu:
if lst_dic[your_choice]['抽屉'] == '钻石':
# 第一种 抽到 钻石
if num != your_choice:
print("主持人露出了 %d 号抽屉的玻璃球"%(num + 1))
isLouchu = True
else:
# 第二种 抽到 玻璃球
if num != your_choice and lst_dic[num]['抽屉'] != '钻石':
print("主持人露出了 %d 号抽屉的玻璃球"%(num + 1))
isLouchu = True
choice = 'yn'
you_select = random.choice(choice)
if you_select == 'y':
lst_nums = [0,1,2]
ischoose = False
for new_choice in lst_nums:
if not ischoose :
if (new_choice != num) and (new_choice != your_choice):
print("你新的选择是:",new_choice+1,"号抽屉")
your_choice = new_choice
ischoose = True
ChooseLater(your_choice)
else:
print("不变选择,继续坚持我的 %d 号抽屉"%(your_choice + 1))
your_choice = your_choice
ChooseLater(your_choice)
def ChooseLater(your_choice):
# 选择后进行计数 公布答案
global zs, blq
if lst_dic[your_choice]['抽屉'] == '钻石':
zs += 1
# 钻石数 +1
else:
blq += 1
# 玻璃球数 +1
answer_num = 0
isanswer = False
for answer in lst_dic:
if not isanswer:
if answer['抽屉'] == '钻石':
print("钻石在 %d 号抽屉 "%(answer_num + 1))
isanswer = True
answer_num += 1
nums = int(input("请输入想要实验的次数"))
for i in range(nums):
# 你可以随意选择一个抽屉
your_choice = random.randint(0, 2)
print("你当前想要选择的是 %d 号抽屉" % (your_choice + 1))
Game(your_choice,lst_dic)
print("抽到的钻石数为: %d"%(zs))
print("抽到的玻璃球数为: %d"%(blq))
print("钻石的概率是 %.2f"%(zs/nums))
小人推心图(网上代码)
from turtle import *
def go_to(x, y):
up()
goto(x, y)
down()
def head(x, y, r):
go_to(x, y)
speed(1)
circle(r)
leg(x, y)
def leg(x, y):
right(90)
forward(180)
right(30)
forward(100)
left(120)
go_to(x, y - 180)
forward(100)
right(120)
forward(100)
left(120)
hand(x, y)
def hand(x, y):
go_to(x, y - 60)
forward(100)
left(60)
forward(100)
go_to(x, y - 90)
right(60)
forward(100)
right(60)
forward(100)
left(60)
eye(x, y)
def eye(x, y):
go_to(x - 50, y + 130)
right(90)
forward(50)
go_to(x + 40, y + 130)
forward(50)
left(90)
def big_Circle(size):
speed(20)
for i in range(150):
forward(size)
right(0.3)
def line(size):
speed(1)
forward(51 * size)
def small_Circle(size):
speed(10)
for i in range(210):
forward(size)
right(0.786)
def heart(x, y, size):
go_to(x, y)
left(150)
begin_fill()
line(size)
big_Circle(size)
small_Circle(size)
left(120)
small_Circle(size)
big_Circle(size)
line(size)
end_fill()
def main():
pensize(2)
color('red', 'pink')
head(-120, 100, 100)
heart(250, -80, 1)
go_to(200, -300)
write("To: Hany", move=True, align="left", font=("楷体", 20, "normal"))
done()
main()

0525习题
for i in range(1000,2201):
if i % 7 == 0 and i % 5 != 0:
print(i,end = " ")
def func(num):
if num == 0:
return 1
return num * func(num - 1)
print(func(5))
for i in range(100,1000):
a = i//100
b = i//10 % 10
c = i%100%10
if a**3 + b**3 + c**3 == i:
print(i)
name = 'seven'
passwd = '123'
num = 3
while num:
input_name = input("请输入用户名")
input_passwd = input("请输入密码")
if input_name == name and input_passwd == passwd:
print("登陆成功")
break
else:
print("登陆失败")
num = num - 1
x,y=eval(input("请输入两个数字,逗号分隔:"))
lst_num=[]
for i in range(x):
L=[]
for j in range(y):
L.append(j*i)
lst_num.append(L)
print(lst_num)
def rank(score):
if isinstance(score,int):
if 90 <= score <= 100:
print("优秀")
elif 80<= score <= 89:
print("良好")
elif 60<= score <= 79:
print("及格")
elif 0<= score <= 59:
print("不及格")
else:
print("输入有误!")
try:
score = eval(input("请输入一个学生的成绩"))
rank(score)
except Exception as e:
print("请输入数字")
def test(name):
if name == 'exit':
print('欢迎下次使用')
if name[0].isalpha() or name[0] == '_':
for i in name[1:]:
if not (i.isalnum() or i == '_'):
print('变量名不合法')
break
else:
print('变量名合法!')
else:
print('变量名非法!')
name = input()
test(name)
def comb(n,m):
if(n == m or (not m)):
return 1
else:
return comb(n-1,m) + comb(n-1,m-1)
try:
n,m = eval(input())
print(comb(n,m))
except :
print("输入有误!")
def sort(dct):
newDct={}
items = list(dct.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(len(dct)):
name,score = items[i]
newDct[name] = score
print("第%d名:%s,成绩: %.2f分"%(i+1,name,newDct[name]))
def avg(dct):
scores = list(dct.values())
print("最高分:%.2f"%(max(scores)),end = "")
print("最低分:%.2f" % (min(scores)),end="")
print("平均分:%.2f" % (sum(scores) / len(scores)),end="")
dct={}
dct['张三'],dct['李四'],dct['王五'],dct['赵六'],dct['侯七']=eval(input())
sort(dct)
avg(dct)
words = "Python"
print("{:#^9}".format(words))
string = "Python"
if "p" in string:
print(string[:-1])
else:
print(string[0:4])
# 创建文件data.txt,共100000行,每行存放一个1~100之间的整数
import random
f = open('data.txt','w+')
for i in range(100000):
f.write(str(random.randint(1,100)) + '\n')
f.seek(0,0)
print(f.read())
f.close()
# 生成100个MAC地址并写入文件中,MAC地址前6位(16进制)为01-AF-3B
# 01-AF-3B(-xx)(-xx)(-xx)
# -xx
# 01-AF-3B-xx
# -xx
# 01-AF-3B-xx-xx
# -xx
# 01-AF-3B-xx-xx-xx
import random
import string
def create_mac():
mac = '01-AF-3B'
# 生成16进制的数
hex_num = string.hexdigits
for i in range(3):
# 从16进制字符串中随机选择两个数字
# 返回值是一个列表
n = random.sample(hex_num,2)
# 拼接内容 将小写字母转换称大写字母
sn = '-' + ''.join(n).upper()
mac += sn
return mac
# 主函数 随机生成100个mac地址
def main():
with open('mac.txt','w') as f:
for i in range(100):
mac = create_mac()
print(mac)
f.write(mac + '\n')
main()
# 生成一个大文件ips.txt,要求1200行,每行随机为172.25.254.0/24段的ip
# 读取ips.txt文件统计这个文件中ip出现频率排前10的ip
import random
def create_ip(filename):
ip=['172.25.254.'+str(i) for i in range(1,255)]
with open(filename,'w') as f:
for i in range(1200):
f.write(random.sample(ip,1)[0]+'\n')
create_ip('ips.txt')
ips_dict={}
with open('ips.txt') as f :
for ip in f:
ip=ip.strip()
if ip in ips_dict:
ips_dict[ip]+=1
else:
ips_dict[ip]=1
sorted_ip=sorted(ips_dict.items(),key=lambda x:x[1],reverse=True)[:10]
print(sorted_ip)
jieba尝鲜
import jieba
strings = '我工作在安徽的安徽师范大学,这个大学很美丽,在芜湖'
# print(dir(jieba))
dic_strings = {}
lst_strings = jieba.lcut(strings)
for ci in lst_strings:
# 对得到的分词进行汇总
dic_strings[ci] = lst_strings.count(ci)
# 更改字典中单词出现的次数
print(dic_strings)
inf 无穷
inf = float('inf')
读取文件进行绘图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
cqlq=pd.read_csv("cqlq.txt",sep="\s+",encoding="gbk")
dxnt=pd.read_csv("dxnt.txt",sep="\s+",encoding="gbk")
ggdq=pd.read_csv("ggdq.txt",sep="\s+",encoding="gbk")
giyy=pd.read_csv("gjyy.txt",sep="\s+",encoding="gbk")
cqlq.columns = ["date","oppr","hipr","lopr","clpr","TR"]
dxnt.columns = ["date","oppr","hipr","lopr","clpr"]
ggdq.columns = ["date","oppr","hipr","lopr","clpr","TR"]
giyy.columns = ["date","oppr","hipr","lopr","clpr","TR"]
a=cqlq
b=dxnt
c=ggdq
d=giyy
ua=(a["clpr"]-a["clpr"].shift(1))/a["clpr"]
ub=(b["clpr"]-b["clpr"].shift(1))/b["clpr"]
uc=(c["clpr"]-c["clpr"].shift(1))/c["clpr"]
ud=(d["clpr"]-d["clpr"].shift(1))/d["clpr"]
u=pd.concat([ua,ub,uc,ud],axis=1)
u.dropna()
miu=u.mean()+0.005
jz=u.cov()
yi = np.ones(4)
miu= np.mat(miu)
jz = np.mat(jz)
yi = np.mat(yi)
nijz = jz.I
a = miu*nijz*miu.T
b =yi*nijz*miu.T
c = yi*nijz*yi.T
deta=a*c-b**2
stock_y=[i*0.0001 for i in range(100)]
stock_x=[(np.sqrt(( c/deta)*(rp-b/c)**2+1/c)).max() for rp in stock_y]
plt.rcParams['font.sans-serif']=['SimHei']
plt.plot(stock_x,stock_y)
plt.xlabel("方差")
plt.ylabel("期望")
print(miu)
print(jz)
plt.show()

Sqlite3 实现学生信息增删改查
import sqlite3
conn = sqlite3.connect('studentsdb.db')
# 连接数据库
cursor = conn.cursor( )
# 创建数据表
def createDatabase():
'''创建一个数据表'''
sql = 'create table student(stuId int primary key,stuName text,stuAge text,stuGender text,stuClass text)'
cursor.execute(sql)
conn.commit()
def addInfo(sql = ''):
'''添加数据'''
if sql =='':
# 如果是初始化,则默认会进行增加 6 条数据
stuInfo = [(1001, '小华', '20', '男', '二班'),
(1002, '小明', '19', '女', '二班'),
(1003, '小李', '20', '女', '一班'),
(1004, '小王', '18', '男', '一班'),
(1005, '小刘', '20', '女', '二班'),
(1006, '小张', '19', '女', '一班')]
cursor.executemany("insert into student values(?,?,?,?,?)",stuInfo)
# 插入多条语句
conn.commit()
def deleteInfo():
'''删除数据'''
cursor.execute("delete from student where stuId = 1005")
# 将学号为 1005 的小刘同学删除
conn.commit()
def modifyInfo():
'''修改数据'''
sql = "update student set stuAge = ? where stuId = ?"
cursor.execute(sql,(20,1006))
# 将小张的年龄修改为 20
conn.commit()
def selectInfo():
'''查询学生信息'''
sql = 'select * from student'
# 查询全部数据
cursor.execute(sql)
print(cursor.fetchall())
def main():
# 创建一个数据表
createDatabase()
# 添加数据
print("添加六条学生数据之后")
addInfo()
selectInfo()
# 修改数据
print("将小张的年龄修改为 20")
modifyInfo()
selectInfo()
# 删除数据
print("将学号为 1005 的小刘同学删除")
deleteInfo()
selectInfo()
# cursor.execute('drop table student')
# conn.commit()
main()
绘图 示例
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
cqlq=pd.read_csv("cqlq.txt",sep="\s+",encoding="gbk")
dxnt=pd.read_csv("dxnt.txt",sep="\s+",encoding="gbk")
ggdq=pd.read_csv("ggdq.txt",sep="\s+",encoding="gbk")
giyy=pd.read_csv("gjyy.txt",sep="\s+",encoding="gbk")
cqlq.columns = ["date","oppr","hipr","lopr","clpr","TR"]
dxnt.columns = ["date","oppr","hipr","lopr","clpr"]
ggdq.columns = ["date","oppr","hipr","lopr","clpr","TR"]
giyy.columns = ["date","oppr","hipr","lopr","clpr","TR"]
a=cqlq
b=dxnt
c=ggdq
d=giyy
ua=(a["clpr"]-a["clpr"].shift(1))/a["clpr"]
ub=(b["clpr"]-b["clpr"].shift(1))/b["clpr"]
uc=(c["clpr"]-c["clpr"].shift(1))/c["clpr"]
ud=(d["clpr"]-d["clpr"].shift(1))/d["clpr"]
u=pd.concat([ua,ub,uc,ud],axis=1)
u.dropna()
miu=u.mean()+0.005
jz=u.cov()
yi = np.ones(4)
miu= np.mat(miu)
jz = np.mat(jz)
yi = np.mat(yi)
nijz = jz.I
a = miu*nijz*miu.T
b =yi*nijz*miu.T
c = yi*nijz*yi.T
deta=a*c-b**2
stock_y=[i*0.0001 for i in range(100)]
stock_x=[(np.sqrt(( c/deta)*(rp-b/c)**2+1/c)).max() for rp in stock_y]
plt.rcParams['font.sans-serif']=['SimHei']
plt.plot(stock_x,stock_y)
plt.xlabel("方差")
plt.ylabel("期望")
print(miu)
print(jz)
plt.show()
使用正则匹配数字
import re
pattern = '\d+?\.\d+'
s = "[Decimal('90.900000')]"
s2 = "[Decimal('75.900000'),Decimal('57.280000')]"
[print(i,end = " ") for i in re.findall(pattern,s)]
print()
[print(i,end = " ") for i in re.findall(pattern,s2)]

0528习题
'''
1. 编写程序实现:计算并输出标准输入的三个数中绝对值最小的数。
'''
#计算并输出标准输入的三个数中绝对值最小的数。
import math
num1 = int(input())
num2 = int(input())
num3 = int(input())
num_list = (num1, num2, num3)
index_min = 0 #绝对值最小的元素的下标
if math.fabs(num_list[index_min]) > math.fabs(num_list[1]):
index_min = 1
if math.fabs(num_list[index_min]) > math.fabs(num_list[2]):
index_min = 2
for n in num_list:
if math.fabs(num_list[index_min]) == math.fabs(n):
print(n, end=' ')
'''
2. 编写程序,功能是输入五分制成绩,
输出对应的百分制分数档。 不考虑非法输入的情形。
对应关系为:A: 90~100, B: 80~89, C: 70~79,D: 60~69, E: 0~59
'''
score = int(input())
if 90 <= score <= 100:
print("A")
elif 80 <= score <= 89:
print("B")
elif 70 <= score <= 79:
print("C")
elif 60 <= score <= 69:
print("D")
elif 0 <= score <= 59:
print("E")
else:
print("请输入正确分数")
'''
3. 编写程序,
输入年(year)、月(month),输出该年份该月的天数。
公历闰年的计算方法为:年份能被4整除且不能被100整除的为闰年;
或者,年份能被400整除的是闰年。
'''
year = int(input("请输入年份"))
month = int(input("请输入月份"))
month_lst = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
if (year %4 == 0 and year % 100 !=0) and year % 400 == 0:
month_lst[1] = 29
print(month_lst[month - 1])
'''
4. 编写程序,功能是输入一个数,输出该数的绝对值
'''
num = int(input())
print(abs(num))
'''
5. 编写“猜数游戏”程序,
功能是:
如果用户输入的数等于程序选定的数(该数设定为10),则输出“you win”,
否则如果大于选定的数,则输出“too big”,反之输出“too small”。
'''
num = 10
your_num = int(input())
if your_num == num:
print("you win")
elif your_num > num:
print("too big")
else:
print("too small")
关于某一爬虫实例的总结
os.chdir(r"C:\Users\47311\Desktop\code\") #修改为自己文件路径
data = pd.read_excel(r"公司公告2020.xlsx")[:-1] #读入数据,并删除最后一行(最后一行为空值)
读取的数据在 chdir 之下
存在多个数据时,使用字符串类型进行 split 分割 "
可能会出错,需要异常处理
DataFrame 对象.apply(函数名)
经常会使用,可以用来赋值新的值
def address(str): #定义提取公告地址函数
try:
return str.split('"')[1]
except:
pass
data["公告地址"] = data["公告地址"].apply(address)
对代码进行获取某一个值时
可以先获取数据上面的内容
html = requests.get(url).text
使用 etree.HTML(html) 进行解析
使用 xpath 读取路径
tree.xpath("xxxx")
返回读取到的内容,对原内容进行更新
return "http://xxxx.com/" + url[0]
data.iterrows()
读取每一行的数据
for index, row in data.iterrows():
row['属性'] 进行获取值
添加文件后缀
name = row['公告标题'].split(':')[0] + row["证券代码"][:6] + "_" + row["公告日期"] + ".pdf"
爬取时,进行必要的条件信息的说明
使用 urlretrieve(url,filename = r' xxx ')
进行保存
当获取到的数据不存在时,可以通过设置一个 len( data )
设置一个长度 ,过滤掉 不到长度的数据
设置一个布尔类型的全局变量
当访问到时 设置为 True
如果没有访问到,则设置为 False
根据全局变量的值,判断是否继续进行访问
是否感染病毒
import random
ganran = float(input("请输入感染概率"))
is_person_ganran = False
# 人是否感染了
person_ganran = random.randint(0,100)
if person_ganran /100 < ganran:
is_person_ganran = True
print(person_ganran)
if is_person_ganran:
print("被感染了")
else:
print("还是正常人")
python文件操作
file = open('abc.txt','r',encoding='utf-8')
file = open('abc.txt','w',encoding='utf-8')
'w' 写入模式
会清空掉文件,然后再写入
不想完全覆盖掉原文件的话,使用'a'
关键字with,with open(xxx) as f
避免打开文件后忘记关闭
readline() 读取一行
读取出来的数据 后面都有\n
readlines() 将每一行形成一个元素,放到一个列表中
seek操作
seek(n)光标移动到n位置
注意: 移动单位是byte
如果是utf-8的中文部分要是3的倍数
seek(0,0)默认为0,移动到文件头
seek(0,1)移动到当前位置
seek(0,2)移动到文件尾
tell() 获取当前光标在什么位置
修改文件
将文件中的内容读取到内存中
将信息修改完毕, 然后将源文件删除, 将新文件的名字改成原来文件的名字
可以一行一行的读取修改,避免溢出
pandas 几个重要知识点
将 NaN 替换成某一数值
使用 fillna
dataframe.fillna(value = 'xxx',inplace=True)
删除某一个值
使用 drop
dataframe.drop(10,inplace=True)
交换两行的值
if m != n:
temp = np.copy(dataframe[m])
dataframe[m] = dataframe[n]
dataframe[n] = temp
else:
temp = np.copy(dataframe[dataframe.shape[1]-1])
dataframe[dataframe.shape[1]-1] = dataframe[n]
dataframe[n] = temp
删除 columns 这些列
dataframe.drop(columns = list, inplace=True)
一千美元的故事(钱放入信封中)
def dollar(n):
global story_money
money = []
for i in range(10):
if 2**(i+1) > story_money-sum(money):
money.append(story_money-2**i+1)
break
money.append(2 ** i)
# print(money)
answer = []
if n >= money[-1]:
answer.append(10)
n -= money[-1]
n = list(bin(n))[2:]
n.reverse()
rank = 1
for i in n:
if i == '1':
answer.append(rank)
rank += 1
print(answer)
story_money = 1000
dollar(500)
给定两个列表,转换为DataFrame类型
import pandas as pd
def get_data():
q1 = []
q2 = []
p1 = input("list 1:")
p2 = input("list 2:")
q1=p1.split(',')
q2=p2.split(',')
for i,j in zip(range(len(q1)),range(len(q2))):
q1[i] = int(q1[i])**1
q2[j] = float(q2[j])**2
dic = {
"L":q1,
"I":q2
}
A = pd.DataFrame(dic)
print(A)
get_data()
1.将输入的使用 split(',') 进行分割
2.使用 for i,j in zip(range(len(q1)),range(len(q2)))
对 q1 和 q2 都进行遍历
3.使用字典,将列表作为值,传递过去
使用 pd.DataFrame 进行转换
通过文档算学生的平均分
tom 85 90
jerry 95 80
lucy 80 90
rose 88 90
jay 76 75
summer 87 85
horry 84 80
dic = {}
with open('score.txt','r') as f:
lines = f.readlines()
f.close()
for line in lines:
line = line.strip('\n').split(' ')
dic[line[0]] = (int(line[1]),int(line[2]))
name = input()
if name not in dic.keys():
print("not found")
else:
print(sum(dic[name])/len(dic[name]))
0528习题 11-15
'''
6. 一元二次方程:ax2+bx+c=0 (a ╪ 0)
【输入形式】输入a、b和c的值(有理数)
【输出形式】输出x的两个值,或者No(即没有有理数的解)
'''
import math
a = int(input())
b = int(input())
c = int(input())
disc = b*b - 4*a*c
p = -b/(2*a)
if disc > 0:
q = math.sqrt(disc)/(2*a)
x1 = p + q
x2 = p - q
print("x1 = %s,x2 = %s"%(str(x1,x2)))
elif disc == 0:
x1 = p
print("x1 = x2 = ",x1)
else:
disc = -disc
q = math.sqrt(disc)/(2*a)
print("x1 = ",p,"+",q)
print("x2 = ", p, "-", q)
'''
7. 计算1+1/2+1/3+...+1/n
'''
n = int(input())
sum = 0
for i in range(1,n+1):
sum += 1/i
print(sum)
'''
8. 编写猜数游戏程序,功能是:允许用户反复输入数,
直至猜中程序选定的数(假定为100)。
输入的数如果大于选定的数,则提示"larger than expected";
如果小于选定的数,则提示"less than expected";
如果等于选定的数,则输出"you win"并结束程序。
'''
import random
num = random.randint(1,5)
while True:
your_num = int(input())
if your_num == num:
print("you win")
break
elif your_num > num:
print("larger than expected")
else:
print("less than expected")
'''
9. 计算1-100之间的偶数和
'''
num_lst = [i for i in range(1,101) if i % 2 == 0]
print(sum(num_lst))
'''
10. 猴子摘下若干个桃子,第一天吃了桃子的一半多一个,
以后每天吃了前一天剩下的一半多一个,
到第n天吃以前发现只剩下一个桃子,
编写程序实现:据输入的天数计算并输出猴子共摘了几个桃子
【输入形式】输入的一行为一个非负整数,表示一共吃的天数。
【输出形式】输出的一行为一个非负整数,表示共摘了几个桃子,
若输入的数据不合法(如:负数或小数),则输出"illegal data"。
'''
def Peach(day,yesterday_sum,now_rest):
if day != 0:
day -= 1
yesterday_sum = (now_rest + 1) * 2
now_rest = yesterday_sum
return Peach(day,yesterday_sum,now_rest)
else:
return yesterday_sum
yesterday_sum = 0
now_rest = 1
day = int(input())
if day <= 0:
print("illegal data")
exit()
print(Peach(day,yesterday_sum,now_rest))
0528习题 6-10
'''
1. 编写程序,功能是把输入的字符串的大写字母变成小写字母,
小写字母变成大写字母,非字母的字符不作变换。输出变换后的结果
'''
string = input()
s = ''
for str in string:
if 'a' <= str <= 'z':
s += str.upper()
elif 'A' <= str <= 'Z':
s += str.lower()
else:
s += str
print(s)
'''
2. 已知10个四位数输出所有对称数及个数 n,
例如1221、2332都是对称数。
【输入形式】10个四位数,以空格分隔开
【输出形式】输入的四位数中的所有对称数,对称数个数
'''
input_nums = input().split()
nums = []
for num in input_nums:
nums.append(int(num))
symmetric_num = []
for num in nums:
num = str(num)
if num[0] == num[3] and num[1] == num[2]:
symmetric_num.append(num)
print("对称数:")
[print(i,end = " ") for i in symmetric_num]
print(len(symmetric_num))
# 1221 2243 2332 1435 1236 5623 4321 4356 6754 3234
'''
学校举办新生歌手大赛,每个选手的成绩
由评委的评分去掉一个最高分和一个最低分剩下评分的平均值得到。
编写程序实现:输入第一行指定n,从第二行开始每行输入一个评委的得分(共n行),
计算选手的成绩,并输出。
'''
n = int(input())
player = []
for i in range(n):
score = float(input())
player.append(score)
player.remove(max(player))
player.remove(min(player))
print("%.1f"%(sum(player)/len(player)))
'''
1. 编写程序实现:计算并输出标准输入的三个数中绝对值最小的数。
'''
#计算并输出标准输入的三个数中绝对值最小的数。
import math
num1 = int(input())
num2 = int(input())
num3 = int(input())
num_list = (num1, num2, num3)
index_min = 0 #绝对值最小的元素的下标
if math.fabs(num_list[index_min]) > math.fabs(num_list[1]):
index_min = 1
if math.fabs(num_list[index_min]) > math.fabs(num_list[2]):
index_min = 2
for n in num_list:
if math.fabs(num_list[index_min]) == math.fabs(n):
print(n, end=' ')
'''
5. 从键盘输入非0整数,以输入0为输入结束标志,求平均值,统计正数负数个数
【输入形式】 每个整数一行。最后一行是0,表示输入结束。
【输出形式】输出三行。
第一行是平均值。第二行是正数个数。第三行是负数个数。
'''
nums = []
n_z = 0
n_f = 0
while True:
num = int(input())
if num == 0:
print(sum(nums)/len(nums))
for n in nums:
if n > 0:
n_z += 1
elif n < 0:
n_f += 1
print(n_z)
print(n_f)
exit()
else:
nums.append(num)
0528习题 16-20
'''
11. 编写程序,判断一个数是不是素数,是则输出“Yes”,不是输出“No”.(while循环)
'''
num = int(input())
i = 2
flag = True
while i < num:
if num % i ==0:
flag = False
i += 1
if flag:
print("Yes")
else:
print("No")
'''
12. 编程实现:从键盘输入5个分数,计算平均分。
【输入形式】5个分数,每个分数占一行。
【输出形式】新起一行输出平均分。
'''
nums = []
for i in range(5):
num = float(input())
nums.append(num)
print(sum(nums)/len(nums))
'''
13. 输入3个整数,输出其中最大的一个 。
'''
nums = []
for i in range(3):
num = int(input())
nums.append(num)
print(max(nums))
'''
14. 输入n,计算n!(n!=1*2*3*...*n)
'''
n = int(input())
sum = 1
for i in range(1,n+1):
sum *= i
print(sum)
'''
编写程序,打印菱形图案,行数n从键盘输入。
下为n=3时的图案,其中的点号实际为空格。图案左对齐输出。
'''
n = 3
for i in range(1, n + 1):
print(" " * (n - i) + "* " * (2 * i - 1))
for i in range(n-1,0,-1):
print(" " * (n - i) + "* " * (2 * i - 1))
0528习题 21-25
'''
16. 编写程序计算学生的平均分。
【输入形式】输入的第一行表示学生人数n;
标准输入的第2至n+1行表示学生成绩。
【输出形式】输出的一行表示平均分(保留两位小数)。
若输入的数据不合法(学生人数不是大于0的整数,
或学生成绩小于0或大于100),输出“illegal input”。
'''
n = int(input())
nums = []
for i in range(n):
score = float(input())
if not 0<= score <= 100:
print("illegal input")
nums.append(score)
print("%.2f"%(sum(nums)/len(nums)))
'''
17. 请将一万以内的完全平方数输出 .
'''
for x in range(1,101):
y = x*x
if y <= 10000:
print(y)
else:
break
'''
18. 从键盘输入非0整数,以输入0为输入结束标志,求平均值,统计正数负数个数
【输入形式】每个整数一行。最后一行是0,表示输入结束。
【输出形式】输出三行。 第一行是平均值。第二行是正数个数。第三行是负数个数。
'''
nums = []
n_z = 0
n_f = 0
while True:
num = int(input())
if num == 0:
print(sum(nums)/len(nums))
for n in nums:
if n > 0:
n_z += 1
elif n < 0:
n_f += 1
print(n_z)
print(n_f)
exit()
else:
nums.append(num)
'''
【问题描述】从键盘输入一个大写字母,要求输出其对应的小写字母。
【输入形式】输入大写字母,不考虑不合法输入。
【输出形式】输出对应的小写字母。
【样例输入】A
【样例输出】a
'''
s = input()
print(s.lower())
'''
【问题描述】
从键盘输入三个字符,按ASCII码值从小到大排序输出,字符之间间隔一个空格。
【输入形式】
输入三个字符,每个字符用空格隔开。
【输出形式】
相对应的输出按照ASCII码值从小到大排列的三个字符,每个字符间用空格隔开。
【样例输入】a c b
【样例输出】a b c
'''
strings = input().split(' ')
strings = sorted(strings)
for s in strings:
print(s,end = " ")
0528习题 26-31
'''
【问题描述】定义一个函数判断是否为素数isPrime(),
主程序通过调用函数输出2-30之间所有的素数。
素数:一个大于1的自然数,除了1和它本身外,不能被其他自然数整除。
【输入形式】无【输出形式】2~30之间所有的索数(逗号分隔)
【样例输入】【样例输出】2,3,5,7,11,13,17,19,23,29,
【样例说明】【评分标准】
'''
def isPrime(n):
i = 2
flag = True
while i < n:
if n % i == 0:
flag = False
i += 1
if flag:
return True
else:
return False
for i in range(2,31):
if isPrime(i):
print(i,end = ',')
'''
【问题描述】有182只兔子,分别装在甲乙两种笼子里,
甲种笼子(x)每个装6只,乙种笼子(y)每个装4只,
两种笼子正好用36个,问两种笼子各用多少个?
【输入形式】无
【输出形式】笼子的个数
【样例输入】
【样例输出】x=*;y=*
【输出说明】
1)*代表输出的值;
2)输出的等号和分号都是英文字符
'''
for i in range(1,36):
x = i
y = 36 - i
if 6*x + 4*y == 182:
print("x=%d;y=%d"%(x,y))
'''
输入圆柱体的底面半径和高,求圆柱体的体积并输出。
圆周率T取固定值3.14。
【输入形式】圆柱体的底面半径和高
【输出形式】圆柱体的体积
【样例输入】2
【样例输出】50.24
'''
r = float(input())
h = float(input())
pi = 3.14
print("%.2f"%(pi*r*r*h))
'''
【问题描述】猴子吃桃问题:
猴子摘下若干个桃子,第一天吃了桃子的一半多一个,
以后每天吃了前一天剩下的一半多一个,
到第n天吃以前发现只剩下一个桃子,
编写程序实现:据输入的天数计算并输出猴子共摘了几个桃子。
【输入形式】n。
【输出形式】共摘了几个桃子
【样例输入】3
【样例输出】10
【样例输入】1
【样例输出】1
'''
day = int(input())
now = 1
yesterday = 0
while day > 1:
yesterday = (now + 1) * 2
now = yesterday
day -= 1
print(now)
'''
输入5名学生的成绩,保存到列表,
统计最高分、最低分、平均分和及格率。平均分
和及格率保留两位小数,及格率的输出格式为x%。
【输入形式】5个人的成绩
【输出形式】最高分、最低分、平均分、及格率
【样例输入】
56
67
55
66
70
【样例输出】
70
55
62.80
60.00%
'''
score = []
for i in range(5):
num = float(input())
score.append(num)
n = 0
for i in score:
if i > 60:
n += 1
print(max(score))
print(min(score))
print(sum(score)/len(score))
print("%.2f%%"%(n*100/len(score)))
'''
【问题描述】
文件“in.txt”中存储了学生的姓名和成绩,
每个人的姓名成绩放在一行,中间用空格隔开,
形式如下:Sunny 70 Susan 88从文件读取数据后,
存入字典,姓名作为字典的键,成绩作为字典的值。
然后输入姓名,查询相应的成绩,查不到,显示"not found"。
【输入形式】姓名
【输出形式】成绩
【样例输入】键盘输入:Susan
'''
name = input()
flag = False
with open('in.txt','r',encoding='utf-8') as fp:
for line in fp:
line = line.replace('\n','')
if line != "":
lst = line.split()
tup = tuple(lst)
# print(tup)
if tup[0] == name:
flag = True
print(tup[-1])
if not flag:
print("not found")
in.txt文件内容
Sunny 70
Susan 80
读取 csv , xlsx 表格并添加总分列
import pandas as pd
import numpy as np
data = pd.read_excel('学生成绩表.csv',columns = ['学号','姓名','高数','英语','计算机'])
sum_score = [ ]
for i in range(len(data)):
sum_score.append(sum(data.loc[i,:][data.columns[2:]]))
data['总分'] = sum_score
print(data['总分'])
data.to_csv('学生成绩表1.csv',encoding='gbk')
matplotlib 显示中文问题
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
十进制转换
# bin2dec
# 二进制 to 十进e5a48de588b662616964757a686964616f31333335336437制: int(str,n=10)
def bin2dec(string_num):
return str(int(string_num, 2))
# hex2dec
# 十六进制 to 十进制
def hex2dec(string_num):
return str(int(string_num.upper(), 16))
# dec2bin
# 十进制 to 二进制: bin()
def dec2bin(string_num):
num = int(string_num)
mid = []
while True:
if num == 0: break
num,rem = divmod(num, 2)
mid.append(base[rem])
return ''.join([str(x) for x in mid[::-1]])
# dec2hex
# 十进制 to 八进制: oct()
# 十进制 to 十六进制: hex()
def dec2hex(string_num):
num = int(string_num)
mid = []
while True:
if num == 0: break
num,rem = divmod(num, 16)
mid.append(base[rem])
return ''.join([str(x) for x in mid[::-1]])
base = [str(x) for x in range(10)] + [chr(x) for x in range(ord('A'), ord('A') + 6)]
def dec2bin(string_num):
'''十进制转换为 二进制'''
num = int(string_num)
mid = []
while True:
if num == 0: break
num, rem = divmod(num, 2)
mid.append(base[rem])
return ''.join([str(x) for x in mid[::-1]])
def dec2oct(string_num):
'''转换为 八进制'''
num = int(string_num)
mid = []
while True:
if num == 0: break
num, rem = divmod(num, 8)
mid.append(base[rem])
return ''.join([str(x) for x in mid[::-1]])
def dec2hex(string_num):
'''转换为 十六进制'''
num = int(string_num)
mid = []
while True:
if num == 0: break
num, rem = divmod(num, 16)
mid.append(base[rem])
return ''.join([str(x) for x in mid[::-1]])
num = float(input())
print(dec2bin(num),dec2oct(num),dec2hex(num))
正则表达式巩固
# 导入re模块
import re
# 使用match方法进行匹配操作
result = re.match(正则表达式,要匹配的字符串)
# 如果上一步匹配到数据的话,可以使用group方法来提取数据
result.group()
re.match用来进行正则匹配检查
若字符串匹配正则表达式,则match方法返回匹配对象(Match Object)
否则返回None
import re
result = re.match("itcast","itcast.cn")
result.group()
re.match() 能够匹配出以xxx开头的字符串

大写字母表示 非
\w 匹配字母,数字,下划线
\W 表示除了字母 数字 下划线的
import re
ret = re.match(".","a")
ret.group()
ret = re.match(".","b")
ret.group()
ret = re.match(".","M")
ret.group()

import re
# 如果hello的首字符小写,那么正则表达式需要小写的h
ret = re.match("h","hello Python")
ret.group()
# 如果hello的首字符大写,那么正则表达式需要大写的H
ret = re.match("H","Hello Python")
ret.group()
# 大小写h都可以的情况
ret = re.match("[hH]","hello Python")
ret.group()
ret = re.match("[hH]","Hello Python")
ret.group()
# 匹配0到9第一种写法
ret = re.match("[0123456789]","7Hello Python")
ret.group()
# 匹配0到9第二种写法
ret = re.match("[0-9]","7Hello Python")
ret.group()
import re
# 普通的匹配方式
ret = re.match("嫦娥1号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥2号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥3号","嫦娥3号发射成功")
print(ret.group())
# 使用\d进行匹配
ret = re.match("嫦娥\d号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥\d号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥\d号","嫦娥3号发射成功")
print(ret.group())

正则表达式里使用"\"作为转义字符
需要匹配文本中的字符"\"
使用反斜杠"\\"


import re
ret = re.match("[A-Z][a-z]*","Mm")
print(ret.group())
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
![]()
import re
ret = re.match("[a-zA-Z_]+[\w_]*","name1")
print(ret.group())
ret = re.match("[a-zA-Z_]+[\w_]*","_name")
print(ret.group())
ret = re.match("[a-zA-Z_]+[\w_]*","2_name")
print(ret.group())

import re
ret = re.match("[1-9]?[0-9]","7")
print(ret.group())
ret = re.match("[1-9]?[0-9]","33")
print(ret.group())
ret = re.match("[1-9]?[0-9]","09")
print(ret.group())

import re
ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678")
print(ret.group())
ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")
print(ret.group())
![]()
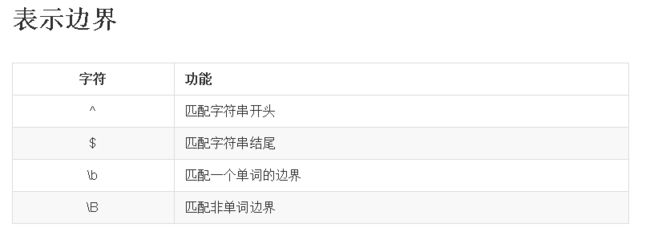
import re
# 正确的地址
ret = re.match("[\w]{4,20}@163\.com", "[email protected]")
print(ret.group())
# 不正确的地址
ret = re.match("[\w]{4,20}@163\.com", "[email protected]")
print(ret.group())
# 通过$来确定末尾
ret = re.match("[\w]{4,20}@163\.com$", "[email protected]")
print(ret.group())

\b 匹配一个单词的边界
\B 匹配非单词边界
![]()
![]()

import re
ret = re.match("[1-9]?\d","8")
print(ret.group())
ret = re.match("[1-9]?\d","78")
print(ret.group())
# 添加|
ret = re.match("[1-9]?\d$|100","8")
print(ret.group())
ret = re.match("[1-9]?\d$|100","78")
print(ret.group())
ret = re.match("[1-9]?\d$|100","100")
print(ret.group())

import re
ret = re.match("\w{4,20}@163\.com", "[email protected]")
print(ret.group())
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
print(ret.group())
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
print(ret.group())


import re
# 能够完成对正确的字符串的匹配
ret = re.match("<[a-zA-Z]*>\w*", "hh")
print(ret.group())
# 如果遇到非正常的html格式字符串,匹配出错
ret = re.match("<[a-zA-Z]*>\w*", "hh")
print(ret.group())
# 正确的理解思路:如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么
# 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
ret = re.match(r"<([a-zA-Z]*)>\w*", "hh")
print(ret.group())
# 因为2对<>中的数据不一致,所以没有匹配出来
ret = re.match(r"<([a-zA-Z]*)>\w*", "hh")
print(ret.group())

import re
ret = re.match(r"<(\w*)><(\w*)>.*", "www.itcast.cn
")
print(ret.group())
# 因为子标签不同,导致出错
ret = re.match(r"<(\w*)><(\w*)>.*", "www.itcast.cn")
print(ret.group())

import re
ret = re.match(r"<(?P\w*)><(?P\w*)>.*", "www.itcast.cn
")
print(ret.group())
ret = re.match(r"<(?P\w*)><(?P\w*)>.*", "www.itcast.cn")
print(ret.group())

import re
ret = re.search(r"\d+", "阅读次数为 9999")
print(ret.group())
![]()
import re
ret = re.findall(r"\d+", "python = 9999, c = 7890, c++ = 12345")
print(ret)
![]()
import re
ret = re.sub(r"\d+", '998', "python = 997")
print(ret)
![]()
import re
def add(temp):
strNum = temp.group()
num = int(strNum) + 1
return str(num)
# 替换的是 原数据 + 1
ret = re.sub(r"\d+", add, "python = 997")
print(ret)
ret = re.sub(r"\d+", add, "python = 99")
print(ret)

import re
ret = re.split(r":| ","info:xiaoZhang 33 shandong")
print(ret)
![]()
Python里数量词默认是贪婪的 匹配尽可能多的字符
非贪婪 总匹配尽可能少的字符。
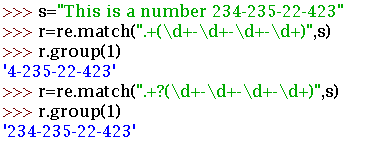

pandas巩固
导包
import pandas as pd
设置输出结果列对齐
pd.set_option('display.unicode.ambiguous_as_wide',True)
pd.set_option('display.unicode.east_asian_width',True)
创建 从 0 开始的非负整数索引
s1 = pd.Series(range(1,20,5))
使用字典创建 Series 字典的键作为索引
s2 = pd.Series({'语文':95,'数学':98,'Python':100,'物理':97,'化学':99})
修改 Series 对象的值
s1[3] = -17
查看 s1 的绝对值
abs(s1)
将 s1 所有的值都加 5、使用加法时,对所有元素都进行
s1 + 5
在 s1 的索引下标前加入参数值
s1.add_prefix(2)
s2 数据的直方图
s2.hist()
每行索引后面加上 hany
s2.add_suffix('hany')
查看 s2 中最大值的索引
s2.argmax()
查看 s2 的值是否在指定区间内
s2.between(90,100,inclusive = True)
查看 s2 中 97 分以上的数据
s2[s2 > 97]
查看 s2 中大于中值的数据
s2[s2 > s2.median()]
s2 与数字之间的运算,开平方根 * 10 保留一位小数
round((s2**0.5)*10,1)
s2 的中值
s2.median()
s2 中最小的两个数
s2.nsmallest(2)
s2 中最大的两个数
s2.nlargest(2)
Series 对象之间的运算,对相同索引进行计算,不是相同索引的使用 NaN
pd.Series(range(5)) + pd.Series(range(5,10))
对 Series 对象使用匿名函数
pd.Series(range(5)).pipe(lambda x,y,z :(x**y)%z,2,5)
pd.Series(range(5)).pipe(lambda x:x+3)
pd.Series(range(5)).pipe(lambda x:x+3).pipe(lambda x:x*3)
对 Series 对象使用匿名函数
pd.Series(range(5)).apply(lambda x:x+3)
查看标准差
pd.Series(range(0,5)).std()
查看无偏方差
pd.Series(range(0,5)).var()
查看无偏标准差
pd.Series(range(0,5)).sem()
查看是否存在等价于 True 的值
any(pd.Series([3,0,True]))
查看是否所有的值都等价于 True
all(pd.Series([3,0,True]))
创建一个 DataFrame 对象
dataframe = pd.DataFrame(np.random.randint(1,20,(5,3)),
index = range(5),
columns = ['A','B','C'])
索引为时间序列
dataframe2 = pd.DataFrame(np.random.randint(5,15,(9,3)),
index = pd.date_range(start = '202003211126',
end = '202003212000',
freq = 'H'),
columns = ['Pandas','爬虫','比赛'])
使用字典进行创建
dataframe3 = pd.DataFrame({'语文':[87,79,67,92],
'数学':[93,89,80,77],
'英语':[88,95,76,77]},
index = ['张三','李四','王五','赵六'])
创建时自动扩充
dataframe4 = pd.DataFrame({'A':range(5,10),'B':3})
查看周几
dff['日期'] = pd.to_datetime(data['日期']).dt.weekday_name
按照周几进行分组,查看交易的平均值
dff = dff.groupby('日期').mean().apply(round)
dff.index.name = '周几'
对姓名和日期进行分组,并进行求和
dff = dataframe.groupby(by = ['姓名','日期'],as_index = False).sum()
将 dff 的索引,列 设置成透视表形式
dff = dff.pivot(index = '姓名',columns = '日期',values = '交易额')
查看前一天的数据
dff.iloc[:,:1]
交易总额小于 4000 的人的前三天业绩
dff[dff.sum(axis = 1) < 4000].iloc[:,:3]
工资总额大于 2900 元的员工的姓名
dff[dff.sum(axis = 1) > 2900].index.values
显示前两天每一天的交易总额以及每个人的交易金额
dataframe.pivot_table(values = '交易额',index = '姓名',
columns = '日期',aggfunc = 'sum',margins = True).iloc[:,:2]
显示每个人在每个柜台的交易总额
dff = dataframe.groupby(by = ['姓名','柜台'],as_index = False).sum()
dff.pivot(index = '姓名',columns = '柜台',values = '交易额')
查看每人每天的上班次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True).iloc[:,:1]
查看每个人每天购买的次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True)
每个人每天上过几次班
pd.crosstab(dataframe.姓名,dataframe.日期,margins = True).iloc[:,:2]
每个人每天去过几次柜台
pd.crosstab(dataframe.姓名,dataframe.柜台)
将每一个人在每一个柜台的交易总额显示出来
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc='sum')
每个人在每个柜台交易额的平均值,金额/天数
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc = 'mean').apply(lambda num:round(num,2) )
对 5 的余数进行分组
dataframe.groupby(by = lambda num:num % 5)['交易额'].sum()
查看索引为 7 15 的交易额
dataframe.groupby(by = {7:'索引为7的行',15:'索引为15的行'})['交易额'].sum()
查看不同时段的交易总额
dataframe.groupby(by = '时段')['交易额'].sum()
各柜台的销售总额
dataframe.groupby(by = '柜台')['交易额'].sum()
查看每个人在每个时段购买的次数
count = dataframe.groupby(by = '姓名')['时段'].count()
每个人的交易额平均值并排序
dataframe.groupby(by = '姓名')['交易额'].mean().round(2).sort_values()
每个人的交易额,apply(int) 转换为整数
dataframe.groupby(by = '姓名').sum()['交易额'].apply(int)
每一个员工交易额的中值
data = dataframe.groupby(by = '姓名').median()
查看交易额对应的排名
data['排名'] = data['交易额'].rank(ascending = False)
data[['交易额','排名']]
每个人不同时段的交易额
dataframe.groupby(by = ['姓名','时段'])['交易额'].sum()
设置各时段累计
dataframe.groupby(by = ['姓名'])['时段','交易额'].aggregate({'交易额':np.sum,'时段':lambda x:'各时段累计'})
对指定列进行聚合,查看最大,最小,和,平均值,中值
dataframe.groupby(by = '姓名').agg(['max','min','sum','mean','median'])
查看部分聚合后的结果
dataframe.groupby(by = '姓名').agg(['max','min','sum','mean','median'])['交易额']
查看交易额低于 2000 的三条数据
dataframe[dataframe.交易额 < 2000][:3]
查看上浮了 50% 之后依旧低于 1500 的交易额,查看 4 条数据
dataframe.loc[dataframe.交易额 < 1500,'交易额'] = dataframe[dataframe.交易额 < 1500]['交易额'].map(lambda num:num*1.5)
查看交易额大于 2500 的数据
dataframe[dataframe.交易额 > 2500]
查看交易额低于 900 或 高于 1800 的数据
dataframe[(dataframe.交易额 < 900)|(dataframe.交易额 > 1800)]
将所有低于 200 的交易额都替换成 200
dataframe.loc[dataframe.交易额 < 200,'交易额'] = 200
查看低于 1500 的交易额个数
dataframe.loc[dataframe.交易额 < 1500,'交易额'].count()
将大于 3000 元的都替换为 3000 元
dataframe.loc[dataframe.交易额 > 3000,'交易额'] = 3000
查看有多少行数据
len(dataframe)
丢弃缺失值之后的行数
len(dataframe.dropna())
包含缺失值的行
dataframe[dataframe['交易额'].isnull()]
使用固定值替换缺失值
dff = copy.deepcopy(dataframe)
dff.loc[dff.交易额.isnull(),'交易额'] = 999
使用交易额的均值替换缺失值
dff = copy.deepcopy(dataframe)
for i in dff[dff.交易额.isnull()].index:
dff.loc[i,'交易额'] = round(dff.loc[dff.姓名 == dff.loc[i,'姓名'],'交易额'].mean())
使用整体均值的 80% 填充缺失值
dataframe.fillna({'交易额':round(dataframe['交易额'].mean() * 0.8)},inplace = True)
查看重复值
dataframe[dataframe.duplicated()]
丢弃重复行
dataframe = dataframe.drop_duplicates()
查看员工业绩波动情况(每一天和昨天的数据作比较)
dff = dataframe.groupby(by = '日期').sum()['交易额'].diff()
对数据使用 map 函数
dff.map(lambda num:'%.2f'%(num))[:5]
查看张三的波动情况
dataframe[dataframe.姓名 == '张三'].groupby(by = '日期').sum()['交易额'].diff()
修改异常值
data.loc[data.交易额 > 3000,'交易额'] = 3000
data.loc[data.交易额 < 200,'交易额'] = 200
删除重复值
data.drop_duplicates(inplace = True)
填充缺失值
data['交易额'].fillna(data['交易额'].mean(),inplace = True)
使用交叉表得到每人在各柜台交易额的平均值
data_group = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean').apply(round)
绘制柱状图
data_group.plot(kind = 'bar')
使用 concat 连接两个相同结构的 DataFrame 对象
df3 = pd.concat([df1,df2])
合并,忽略原来的索引 ignore_index
df4 = df3.append([df1,df2],ignore_index = True)
按照列进行拆分
df5 = df4.loc[:,['姓名','柜台','交易额']]
按照工号进行合并,随机查看 3 条数据
rows = np.random.randint(0,len(df5),3)
pd.merge(df4,df5).iloc[rows,:]
按照工号进行合并,指定其他同名列的后缀
pd.merge(df1,df2,on = '工号',suffixes = ['_x','_y']).iloc[:,:]
两个表都设置工号为索引 set_index
df2.set_index('工号').join(df3.set_index('工号'),lsuffix = '_x',rsuffix = '_y').iloc[:]
按照交易额和工号降序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = False)[:5]
按照交易额和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'])[:5]
按照交易额降序和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = [False,True])[:5]
按工号升序排序
dataframe.sort_values(by = ['工号'])[:5]
按列名升序排序
dataframe.sort_index(axis = 1)[:5]
每隔五天--5D
pd.date_range(start = '20200101',end = '20200131',freq = '5D')
每隔一周--W
pd.date_range(start = '20200301',end = '20200331',freq = 'W')
间隔两天,五个数据
pd.date_range(start = '20200301',periods = 5,freq = '2D')
间隔三小时,八个数据
pd.date_range(start = '20200301',periods = 8,freq = '3H')
三点开始,十二个数据,间隔一分钟
pd.date_range(start = '202003010300',periods = 12,freq = 'T')
每个月的最后一天
pd.date_range(start = '20190101',end = '20191231',freq = 'M')
间隔一年,六个数据,年末最后一天
pd.date_range(start = '20190101',periods = 6,freq = 'A')
间隔一年,六个数据,年初最后一天
pd.date_range(start = '20200101',periods = 6,freq = 'AS')
使用 Series 对象包含时间序列对象,使用特定索引
data = pd.Series(index = pd.date_range(start = '20200321',periods = 24,freq = 'H'),data = range(24))
三分钟重采样,计算均值
data.resample('3H').mean()
五分钟重采样,求和
data.resample('5H').sum()
计算OHLC open,high,low,close
data.resample('5H').ohlc()
将日期替换为第二天
data.index = data.index + pd.Timedelta('1D')
查看指定日期的年份是否是闰年
pd.Timestamp('20200301').is_leap_year
查看指定日期所在的季度和月份
day = pd.Timestamp('20200321')
查看日期的季度
day.quarter
查看日期所在的月份
day.month
转换为 python 的日期时间对象
day.to_pydatetime()
查看所有的交易额信息
dataframe['交易额'].describe()
查看四分位数
dataframe['交易额'].quantile([0,0.25,0.5,0.75,1.0])
查看最大的交易额数据
dataframe.nlargest(2,'交易额')
查看最后一个日期
dataframe['日期'].max()
查看最小的工号
dataframe['工号'].min()
第一个最小交易额的行下标
index = dataframe['交易额'].idxmin()
第一个最小交易额
dataframe.loc[index,'交易额']
最大交易额的行下标
index = dataframe['交易额'].idxmax()
跳过 1 2 4 行,以第一列姓名为索引
dataframe2 = pd.read_excel('超市营业额.xlsx',
skiprows = [1,2,4],
index_col = 1)
查看 5 到 10 的数据
dataframe[5:11]
查看第六行的数据
dataframe.iloc[5]
查看第 1 3 4 行的数据
dataframe.iloc[[0,2,3],:]
查看第 1 3 4 行的第 1 2 列
dataframe.iloc[[0,2,3],[0,1]]
查看前五行指定,姓名、时段和交易额的数据
dataframe[['姓名','时段','交易额']][:5]
查看第 2 4 5 行 姓名,交易额 数据 loc 函数
dataframe.loc[[1,3,4],['姓名','交易额']]
查看第四行的姓名数据
dataframe.at[3,'姓名']
某一时段的交易总和
dataframe[dataframe['时段'] == '14:00-21:00']['交易额'].sum()
查看张三总共的交易额
dataframe[dataframe['姓名'].isin(['张三'])]['交易额'].sum()
查看日用品的销售总额
dataframe[dataframe['柜台'] == '日用品']['交易额'].sum()
查看交易额在 1500~3000 之间的记录
dataframe[dataframe['交易额'].between(1500,3000)]
将日期设置为 python 中的日期类型
data.日期 = pd.to_datetime(data.日期)
每七天营业的总额
data.resample('7D',on = '日期').sum()['交易额']
每七天营业总额
data.resample('7D',on = '日期',label = 'right').sum()['交易额']
每七天营业额的平均值
func = lambda item:round(np.sum(item)/len(item),2)
data.resample('7D',on = '日期',label = 'right').apply(func)['交易额']
每七天营业额的平均值
func = lambda num:round(num,2)
data.resample('7D',on = '日期',label = 'right').mean().apply(func)['交易额']
删除工号这一列
data.drop('工号',axis = 1,inplace = True)
按照姓名和柜台进行分组汇总
data = data.groupby(by = ['姓名','柜台']).sum()
查看张三的汇总数据
data.loc['张三',:]
查看张三在蔬菜水果的交易数据
data.loc['张三','蔬菜水果']
丢弃工号列
data.drop('工号',axis = 1,inplace = True)
按照柜台进行排序
dff = data.sort_index(level = '柜台',axis = 0)
按照姓名进行排序
dff = data.sort_index(level = '姓名',axis = 0)
按照柜台进行分组求和
dff = data.groupby(level = '柜台').sum()['交易额']
平均值
data.mean()
标准差
data.std()
协方差
data.cov()
删除缺失值和重复值,inplace = True 直接丢弃
data.dropna(inplace = True)
data.drop_duplicates(inplace = True)
numpy巩固
导包
import numpy as np
创建二维数组
x = np.matrix([[1,2,3],[4,5,6]])
创建一维数组
y = np.matrix([1,2,3,4,5,6])
x 的第二行第二列元素
x[1,1]
矩阵的乘法
x*y
# 相关系数矩阵,可使用在列表元素数组矩阵
# 负相关
np.corrcoef([1,2,3],[8,5,4])
'''
array([[ 1. , -0.96076892],
[-0.96076892, 1. ]])
'''
# 正相关
np.corrcoef([1,2,3],[4,5,7])
'''
array([[1. , 0.98198051],
[0.98198051, 1. ]])
'''
矩阵的方差
np.cov([1,1,1,1,1])
矩阵的标准差
np.std([1,1,1,1,1])
垂直堆叠矩阵
z = np.vstack((x,y))
矩阵的协方差
np.cov(z)
np.cov(x,y)
标准差
np.std(z)
列向标准差
np.std(z,axis = 1)
方差
np.cov(x)
特征值和特征向量
A = np.array([[1,-3,3],[3,-5,3],[6,-6,4]])
e,v = np.linalg.eig(A)
e 为特征值, v 为特征向量
矩阵与特征向量的乘积
np.dot(A,v)
特征值与特征向量的乘积
e * v
验证两个乘积是否相等
np.isclose(np.dot(A,v),(e * v))
行列式 |A - λE| 的值应为 0
np.linalg.det(A-np.eye(3,3)*e)
逆矩阵
y = np.linalg.inv(x)
矩阵的乘法(注意先后顺序)
x * y
'''
matrix([[ 1.00000000e+00, 5.55111512e-17, 1.38777878e-17],
[ 5.55111512e-17, 1.00000000e+00, 2.77555756e-17],
[ 1.77635684e-15, -8.88178420e-16, 1.00000000e+00]])
'''
y * x
'''
matrix([[ 1.00000000e+00, -1.11022302e-16, 0.00000000e+00],
[ 8.32667268e-17, 1.00000000e+00, 2.22044605e-16],
[ 6.93889390e-17, 0.00000000e+00, 1.00000000e+00]])
'''
求解线性方程组
a = np.array([[3,1],[1,2]])
b = np.array([9,8])
x = np.linalg.solve(a,b)
最小二乘解:返回解,余项,a 的秩,a 的奇异值
np.linalg.lstsq(a,b)
# (array([2., 3.]), array([], dtype=float64), 2, array([3.61803399, 1.38196601]))
计算向量和矩阵的范数
x = np.matrix([[1,2],[3,-4]])
np.linalg.norm(x)
# 5.477225575051661
np.linalg.norm(x,-2)
# 1.9543950758485487
np.linalg.norm(x,-1)
# 4.0
np.linalg.norm(x,1)
# 6.0
np.linalg.norm([1,2,0,3,4,0],0)
# 4.0
np.linalg.norm([1,2,0,3,4,0],2)
# 5.477225575051661
奇异值分解
a = np.matrix([[1,2,3],[4,5,6],[7,8,9]])
u,s,v = np.linalg.svd(a)
u
'''
matrix([[-0.21483724, 0.88723069, 0.40824829],
[-0.52058739, 0.24964395, -0.81649658],
[-0.82633754, -0.38794278, 0.40824829]])
'''
s
'''
array([1.68481034e+01, 1.06836951e+00, 4.41842475e-16])
'''
v
'''
matrix([[-0.47967118, -0.57236779, -0.66506441],
[-0.77669099, -0.07568647, 0.62531805],
[-0.40824829, 0.81649658, -0.40824829]])
'''
# 验证
u * np.diag(s) * v
'''
matrix([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
'''
实现矩阵的转置
x.T
元素平均值
x.mean()
纵向平均值
x.mean(axis = 0)
横向平均值
x.mean(axis = 1)
所有元素之和
x.sum()
横向最大值
x.max(axis = 1)
横向最大值的索引下标
x.argmax(axis = 1)
对角线元素
x.diagonal()
非零元素下标
x.nonzero()
创建数组
np.array([1,2,3,4])
np.array((1,2,3,4))
np.array(range(4)) # 不包含终止数字
# array([0, 1, 2, 3])
# 使用 arange(初始位置=0,末尾,步长=1)
np.arange(1,8,2)
# array([1, 3, 5, 7])
生成等差数组,endpoint 为 True 则包含末尾数字
np.linspace(1,3,4,endpoint=False)
# array([1. , 1.5, 2. , 2.5])
np.linspace(1,3,4,endpoint=True)
# array([1. , 1.66666667, 2.33333333, 3. ])
创建全为零的一维数组
np.zeros(3)
创建全为一的一维数组
np.ones(4)
np.linspace(1,3,4)
# array([1. , 1.66666667, 2.33333333, 3. ])
np.logspace(起始数字,终止数字,数字个数,base = 10) 对数数组
np.logspace(1,3,4)
# 相当于 10 的 linspace(1,3,4) 次方
# array([ 10. , 46.41588834, 215.443469 , 1000. ])
np.logspace(1,3,4,base = 2)
# 2 的 linspace(1,3,4) 次方
# array([2. , 3.1748021, 5.0396842, 8. ])
创建二维数组(列表嵌套列表)
np.array([[1,2,3],[4,5,6]])
# 创建全为零的二维数组
# 两行两列
np.zeros((2,2))
三行两列
np.zeros((3,2))
# 创建一个单位数组
np.identity(3)
'''
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
'''
创建一个对角矩阵,(参数为对角线上的数字)
np.diag((1,2,3))
'''
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
'''
第一行元素
n[0]
第一行第三列元素
n[0,2]
第一行和第二行的元素
n[[0,1]]
第一行第三列,第三行第二列,第二行第一列
n[[0,2,1],[2,1,0]]
将数组倒序
a[::-1]
步长为 2
a[::2]
从 0 到 4 的元素
a[:5]
变换 c 的矩阵行和列
c = np.arange(16)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
c.shape = 4,4
'''
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
'''
第一行,第三个元素到第五个元素(如果没有则输出到末尾截止)
c[0,2:5]
第二行元素
c[1]
第三行到第六行,第三列到第六列
c[2:5,2:5]
第二行第三列元素和第三行第四列元素
c[[1,2],[2,3]]
第一行和第三行的第二列到第三列的元素
c[[0,2],1:3]
第一列和第三列的所有横行元素
c[:,[0,2]]
第三列所有元素
c[:,2]
第二行和第四行的所有元素
c[[1,3]]
第一行的第二列,第四列元素,第四行的第二列,第四列元素
c[[0,3]][:,[1,3]]
使用 * 进行相乘
x*2
使用 / 进行相除
x / 2
2 / x
使用 // 进行整除
x//2
10//x
使用 ** 进行幂运算
x**3
2 ** x
使用 + 进行相加
x + 2
使用 % 进行取模
x % 3
使用 + 进行相加
np.array([1,2,3,4]) + np.array([11,22,33,44])
np.array([1,2,3,4]) + np.array([3])
# array([4, 5, 6, 7])
数组的内积运算(对应位置上元素相乘)
np.dot(x,y)
sum(x*y)
将数组中大于 0.5 的元素显示
n[n>0.5]
找到数组中 0.05 ~ 0.4 的元素总数
sum((n > 0.05)&(n < 0.4))
是否都大于 0.2
np.all(n > 0.2)
是否有元素小于 0.1
np.any(n < 0.1)
在 a 中是否有大于 b 的元素
a > b
# array([False, True, False])
# 在 a 中是否有等于 b 的元素
a == b
# array([False, False, True])
# 显示 a 中 a 的元素等于 b 的元素
a[a == b]
# array([7])
显示 a 中的偶数且小于 5 的元素
a[(a%2 == 0) & (a < 5)]
生成一个随机数组
np.random.randint(0,6,3)
生成一个随机数组(二维数组)
np.random.randint(0,6,(3,3))
生成十个随机数在[0,1)之间
np.random.rand(10)
'''
array([0.9283789 , 0.43515554, 0.27117021, 0.94829333, 0.31733981,
0.42314939, 0.81838647, 0.39091899, 0.33571004, 0.90240897])
'''
从标准正态分布中随机抽选出3个数
np.random.standard_normal(3)
返回三页四行两列的标准正态分布数
np.random.standard_normal((3,4,2))
x = np.arange(8)
在数组尾部追加一个元素
np.append(x,10)
在数组尾部追加多个元素
np.append(x,[15,16,17])
使用 数组下标修改元素的值
x[0] = 99
在指定位置插入数据
np.insert(x,0,54)
创建一个多维数组
x = np.array([[1,2,3],[11,22,33],[111,222,333]])
修改第 0 行第 2 列的元素值
x[0,2] = 9
行数大于等于 1 的,列数大于等于 1 的置为 1
x[1:,1:] = 1
# 同时修改多个元素值
x[1:,1:] = [7,8]
'''
array([[ 1, 2, 9],
[ 11, 7, 8],
[111, 7, 8]])
'''
x[1:,1:] = [[7,8],[9,10]]
'''
array([[ 1, 2, 9],
[ 11, 7, 8],
[111, 9, 10]])
'''
查看数组的大小
n.size
将数组分为两行五列
n.shape = 2,5
显示数组的维度
n.shape
设置数组的维度,-1 表示自动计算
n.shape = 5,-1
将新数组设置为调用数组的两行五列并返回
x = n.reshape(2,5)
x = np.arange(5)
# 将数组设置为两行,没有数的设置为 0
x.resize((2,10))
'''
array([[0, 1, 2, 3, 4, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
'''
# 将 x 数组的两行五列形式显示,不改变 x 的值
np.resize(x,(2,5))
'''
array([[0, 1, 2, 3, 4],
[0, 0, 0, 0, 0]])
'''
x = np.array([1,4,5,2])
# array([1, 4, 5, 2])
# 返回排序后元素的原下标
np.argsort(x)
# array([0, 3, 1, 2], dtype=int64)
输出最大值的下标
x.argmax( )
输出最小值的下标
x.argmin( )
对数组进行排序
x.sort( )
每个数组元素对应的正弦值
np.sin(x)
每个数组元素对应的余弦值
np.cos(x)
对参数进行四舍五入
np.round(np.cos(x))
对参数进行上入整数 3.3->4
np.ceil(x/3)
# 分段函数
x = np.random.randint(0,10,size=(1,10))
# array([[0, 3, 6, 7, 9, 4, 9, 8, 1, 8]])
# 大于 4 的置为 0
np.where(x > 4,0,1)
# array([[1, 1, 0, 0, 0, 1, 0, 0, 1, 0]])
# 小于 4 的乘 2 ,大于 7 的乘3
np.piecewise(x,[x<4,x>7],[lambda x:x*2,lambda x:x*3])
# array([[ 0, 6, 0, 0, 27, 0, 27, 24, 2, 24]])
数据库 mysql-connector 基础
安装驱动
python -m pip install mysql-connector
导包
import mysql.connector
mydb = mysql.connector.connect(
host="localhost", # 数据库主机地址
user="root", # 数据库用户名
passwd="root" # 数据库密码
)
创建游标
mycursor = mydb.cursor()
使用 mycursor.execute("sql 语句") 进行运行
mycursor.execute("CREATE DATABASE runoob_db")
指定数据库名为 runoob_db
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database="runoob_db"
)
创建数据表
mycursor.execute("CREATE TABLE sites (name VARCHAR(255), url VARCHAR(255))")
查看当前数据表有哪些
mycursor.execute("SHOW TABLES")
使用 "INT AUTO_INCREMENT PRIMARY KEY" 语句
创建一个主键,主键起始值为 1,逐步递增
mycursor.execute("ALTER TABLE sites ADD COLUMN id INT AUTO_INCREMENT PRIMARY KEY")
创建表时,添加主键
mycursor.execute("CREATE TABLE sites (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255), url VARCHAR(255))")
插入数据
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = ("RUNOOB", "https://www.runoob.com")
mycursor.execute(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
打印 行号
mycursor.rowcount
插入多条语句
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = [
('Google', 'https://www.google.com'),
('Github', 'https://www.github.com'),
('Taobao', 'https://www.taobao.com'),
('stackoverflow', 'https://www.stackoverflow.com/')
]
mycursor.executemany(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
在数据插入后,获取该条记录的 ID
mycursor.lastrowid
使用 fetchall() 获取所有记录
mycursor.execute("SELECT * FROM sites")
myresult = mycursor.fetchall()
for x in myresult:
print(x)
选取指定数据进行查找
mycursor.execute("SELECT name, url FROM sites")
myresult = mycursor.fetchall()
for x in myresult:
print(x)
使用 .fetchone() 获取一条数据
mycursor.execute("SELECT * FROM sites")
myresult = mycursor.fetchone()
print(myresult)
使用 where 语句
sql = "SELECT * FROM sites WHERE name ='RUNOOB'"
mycursor.execute(sql)
myresult = mycursor.fetchall()
使用 fetchall 之后,需要使用循环进行输出
for x in myresult:
print(x)
使用 通配符 %
sql = "SELECT * FROM sites WHERE url LIKE '%oo%'"
使用 %s 防止发生 SQL 注入攻击
sql = "SELECT * FROM sites WHERE name = %s"
na = ("RUNOOB", )
mycursor.execute(sql, na)
排序
使用 ORDER BY 语句,默认升序,关键字为 ASC
如果要设置降序排序,可以设置关键字 DESC
sql = "SELECT * FROM sites ORDER BY name"
mycursor.execute(sql)
降序 DESC
sql = "SELECT * FROM sites ORDER BY name DESC"
mycursor.execute(sql)
使用 limit 设置查询的数据量
mycursor.execute("SELECT * FROM sites LIMIT 3")
limit 指定起始位置 使用 offset
mycursor.execute("SELECT * FROM sites LIMIT 3 OFFSET 1")
# 0 为 第一条,1 为第二条,以此类推
myresult = mycursor.fetchall()
删除记录 delete from
sql = "DELETE FROM sites WHERE name = 'stackoverflow'"
mycursor.execute(sql)
sql = "DELETE FROM sites WHERE name = %s"
na = ("stackoverflow", )
mycursor.execute(sql, na)
更新表中数据 update
sql = "UPDATE sites SET name = 'ZH' WHERE name = 'Zhihu'"
mycursor.execute(sql)
sql = "UPDATE sites SET name = %s WHERE name = %s"
val = ("Zhihu", "ZH")
mycursor.execute(sql, val)
删除表 drop table
可以先使用 if exists 判断是否存在
sql = "DROP TABLE IF EXISTS sites" # 删除数据表 sites
mycursor.execute(sql)
爬虫流程(前面发过的文章的合集)巩固
1.打开网页
urllib.request.urlopen('网址')
例:response = urllib.request.urlopen('http://www.baidu.com/')
返回值为
2.获取响应头信息
urlopen 对象.getheaders()
例:response.getheaders()
返回值为 [('Bdpagetype', '1'), ('Bdqid', '0x8fa65bba0000ba44'),···,('Transfer-Encoding', 'chunked')]
[('头','信息')]
3.获取响应头信息,带参数表示指定响应头
urlopen 对象.getheader('头信息')
例:response.getheader('Content-Type')
返回值为 'text/html;charset=utf-8'
4.查看状态码
urlopen 对象.status
例:response.status
返回值为 200 则表示成功
5.得到二进制数据,然后转换为 utf-8 格式
二进制数据
例:html = response.read()
HTML 数据格式
例:html = response.read().decode('utf-8')
打印输出时,使用 decode('字符集') 的数据 print(html.decode('utf-8'))
6.存储 HTML 数据
fp = open('文件名.html','模式 wb')
例:fp = open('baidu.html', 'wb')
fp.write(response.read() 对象)
例:fp.write(html)
7.关闭文件
open对象.close()
例:fp.close()
8.使用 ssl 进行抓取 https 的网页
例:
import ssl
content = ssl._create_unverified_context()
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
request = urllib.request.Request('http://www.baidu.com/', headers = headers)
response = urllib.request.urlopen(request, context = context)
这里的 response 就和上面一样了
9.获取码
response.getcode()
返回值为 200
10.获取爬取的网页 url
response.geturl()
返回值为 https://www.baidu.com/
11.获取响应的报头信息
response.info()
12.保存网页
urllib.request.urlretrieve(url, '文件名.html')
例:urllib.request.urlretrieve(url, 'baidu.html')
13.保存图片
urllib.request.urlretrieve(url, '图片名.jpg')
例:urllib.request.urlretrieve(url, 'Dog.jpg')
其他字符(如汉字)不符合标准时,要进行编码
14.除了-._/09AZaz 都会编码
urllib.parse.quote()
例:
Param = "全文检索:*"
urllib.parse.quote(Param)
返回值为 '%E5%85%A8%E6%96%87%E6%A3%80%E7%B4%A2%3A%2A'
15.会编码 / 斜线(将斜线也转换为 %.. 这种格式)
urllib.parse.quote_plus(Param)
16.将字典拼接为 query 字符串 如果有中文,进行url编码
dic_object = {
'user_name':'张三',
'user_passwd':'123456'
}
urllib.parse.urlencode(dic_object)
返回值为 'user_name=%E5%BC%A0%E4%B8%89&user_passwd=123456'
17.获取 response 的行
url = 'http://www.baidu.com'
response = urllib.request.urlopen(url)
response.readline()
18.随机获取请求头(随机包含请求头信息的列表)
user_agent = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
]
ua = random.choice(user_agent)
headers = {'User-Agent':ua}
19.对输入的汉字进行 urlencode 编码
urllib.parse.urlencode(字典对象)
例:
chinese = input('请输入要查询的中文词语:')
wd = {'wd':chinese}
wd = urllib.parse.urlencode(wd)
返回值为 'wd=%E4%BD%A0%E5%A5%BD'
20.常见分页操作
for page in range(start_page, end_page + 1):
pn = (page - 1) * 50
21.通常会进行拼接字符串形成网址
例:fullurl = url + '&pn=' + str(pn)
22.进行拼接形成要保存的文件名
例:filename = 'tieba/' + name + '贴吧_第' + str(page) + '页.html'
23.保存文件
with open(filename,'wb') as f:
f.write(reponse.read() 对象)
24.headers 头信息可以删除的有
cookie、accept-encoding、accept-languag、content-length\connection\origin\host
25.headers 头信息不可以删除的有
Accept、X-Requested-With、User-Agent、Content-Type、Referer
26.提交给网页的数据 formdata
formdata = {
'from':'en',
'to':'zh',
'query':word,
'transtype':'enter',
'simple_means_flag':'3'
}
27.将formdata进行urlencode编码,并且转化为bytes类型
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
28.使用 formdata 在 urlopen() 中
response = urllib.request.urlopen(request, data=formdata)
29.转换为正确数据(导包 json)
read -> decode -> loads -> json.dumps
通过read读取过来为字节码
data = response.read()
将字节码解码为utf8的字符串
data = data.decode('utf-8')
将json格式的字符串转化为json对象
obj = json.loads(data)
禁用ascii之后,将json对象转化为json格式字符串
html = json.dumps(obj, ensure_ascii=False)
json 对象通过 str转换后 使用 utf-8 字符集格式写入
保存和之前的方法相同
with open('json.txt', 'w', encoding='utf-8') as f:
f.write(html)
30.ajax请求自带的头部
'X-Requested-With':'XMLHttpRequest'
31.豆瓣默认都得使用https来进行抓取,所以需要使用ssl模块忽略证书
例:
url = 'http://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action='
page = int(input('请输入要获取页码:'))
start = (page - 1) * 20
limit = 20
key = {
'start':start,
'limit':limit
}
key = urllib.parse.urlencode(key)
url = url + '&' + key
headers = {
'X-Requested-With':'XMLHttpRequest',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
request = urllib.request.Request(url, headers=headers)
# context = ssl._create_unverified_context()
response = urllib.request.urlopen(request)
jsonret = response.read()
with open('douban.txt', 'w', encoding='utf-8') as f:
f.write(jsonret.decode('utf-8'))
print('over')
32.创建处理 http 请求的对象
http_handler = urllib.request.HTTPHandler()
33.处理 https 请求
https_handler = urllib.request.HTTPSHandler()
34.创建支持http请求的opener对象
opener = urllib.request.build_opener(http_handler)
35.创建 reponse 对象
例:opener.open(Request 对象)
request = urllib.request.Request('http://www.baidu.com/')
reponse = opener.open(request)
进行保存
with open('文件名.html', 'w', encoding='utf-8') as f:
f.write(reponse.read().decode('utf-8'))
36.代理服务器
http_proxy_handler = urllib.request.ProxyHandler({'https':'ip地址:端口号'})
例:http_proxy_handler = urllib.request.ProxyHandler({'https':'121.43.178.58:3128'})
37.私密代理服务器(下面的只是一个例子,不一定正确)
authproxy_handler = urllib.request.ProxyHandler({"http" : "user:password@ip:port"})
38.不使用任何代理
http_proxy_handler = urllib.request.ProxyHandler({})
39.使用了代理之后的 opener 写法
opener = urllib.request.build_opener(http_proxy_handler)
40.response 写法
response = opener.open(request)
41.如果访问一个不存在的网址会报错
urllib.error.URLError
42.HTTPError(是URLError的子类)
例:
try:
urllib.request.urlopen(url)
except urllib.error.HTTPError as e:
print(e.code)
print(e.reason)
except urllib.error.URLError as e:
print(e)
43.使用 CookieJar 创建一个 cookie 对象,保存 cookie 值
import http.cookiejar
cookie = http.cookiejar.CookieJar( )
44.通过HTTPCookieProcessor构建一个处理器对象,用来处理cookie
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
opener 的写法
opener = urllib.request.build_opener(cookie_handler)
45.使用 r'\x' 消除转义
\d 表示转义字符 r'\d' 表示 \d
46.设置 正则模式
pattern = re.compile(r'规则', re.xxx )
pattern = re.compile(r'i\s(.*?),')
例:pattern = re.compile(r'LOVE', re.I)
使用 pattern 进行调用匹配
47.match 只匹配开头字符
pattern.match('字符串'[,起始位置,结束位置])
例:m = pattern.match('i love you', 2, 6)
返回值为
48. search 从开始匹配到结尾,返回第一个匹配到的
pattern.search('字符串')
例:m = pattern.search('i love you, do you love me, yes, i love')
返回值为
49.findall 将匹配到的都放到列表中
pattern.findall('字符串')
例:m = pattern.findall('i love you, do you love me, yes, i love')
返回值为 ['love', 'love', 'love']
50.split 使用匹配到的字符串对原来的数据进行切割
pattern.split('字符串',次数)
例:m = pattern.split('i love you, do you love me, yes, i love me', 1)
返回值为 ['i ', ' you, do you love me, yes, i love me']
例:m = pattern.split('i love you, do you love me, yes, i love me', 2)
返回值为 ['i ', ' you, do you ', ' me, yes, i love me']
例:m = pattern.split('i love you, do you love me, yes, i love me', 3)
返回值为 ['i ', ' you, do you ', ' me, yes, i ', ' me']
51.sub 使用新字符串替换匹配到的字符串的值,默认全部替换
pattern.sub('新字符串','要匹配字符串'[,次数])
注:返回的是字符串
例:
string = 'i love you, do you love me, yes, i love me'
m = pattern.sub('hate', string, 1)
m 值为 'i hate you, do you love me, yes, i love me'
52.group 匹配组
m.group() 返回的是匹配都的所有字符
m.group(1) 返回的是第二个规则匹配到的字符
例:
string = 'i love you, do you love me, yes, i love me'
pattern = re.compile(r'i\s(.*?),')
m = pattern.match(string)
m.group()
返回值为 'i love you,'
m.group(1)
返回值为 'love you'
53.匹配标签
pattern = re.compile(r'(.*?)(.*?)', re.S)
54.分离出文件名和扩展名,返回二元组
os.path.splitext(参数)
例:
获取路径
image_path = './qiushi'
获取后缀名
extension = os.path.splitext(image_url)[-1]
55.合并多个字符串
os.path.join()
图片路径
image_path = os.path.join(image_path, image_name + extension)
保存文件
urllib.request.urlretrieve(image_url, image_path)
56.获取 a 标签下的 href 的内容
pattern = re.compile(r'(.*?)', re.M)
57.href 中有中文的需要先进行转码,然后再拼接
smile_url = urllib.parse.quote(smile_url)
smile_url = 'http://www.jokeji.cn' + smile_url
58.导入 etree
from lxml import etree
59.实例化一个 html 对象,DOM模型
etree.HTML
(通过requests库的get方法或post方法获取的信息 其实就是 HTML 代码)
例:html_tree = etree.HTML(text)
返回值为
例:type(html_tree)
60.查找所有的 li 标签
html_tree.xpath('//li')
61.获取所有li下面a中属性href为link1.html的a
result = html_tree.xpath('//标签/标签[@属性="值"]')
例:result = html_tree.xpath('//li/a[@href="link.html"]')
62.获取最后一个 li 标签下 a 标签下面的 href 值
result = html_tree.xpath('//li[last()]/a/@href')
63.获取 class 为 temp 的结点
result = html_tree.xpath('//*[@class = "temp"]')
64.获取所有 li 标签下的 class 属性
result = html_tree.xpath('//li/@class')
65.取出内容
[0].text
例:result = html_tree.xpath('//li[@class="popo"]/a')[0].text
例:result = html_tree.xpath('//li[@class="popo"]/a/text()')
66.将 tree 对象转化为字符串
etree.tostring(etree.HTML对象).decode('utf-8')
67.动态保存图片,使用url后几位作为文件名
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html_tree = etree.HTML(html)
img_list = html_tree.xpath('//div[@class="box picblock col3"]/div/a/img/@src2')
for img_url in img_list:
# 定制图片名字为url后10位
file_name = 'image/' + img_url[-10:]
load_image(img_url, file_name)
load_image内容:
def load_image(url, file_name):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
image_bytes = response.read()
with open(file_name, 'wb') as f:
f.write(image_bytes)
print(file_name + '图片已经成功下载完毕')
例:
def load_page(url):
headers = {
#'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
print(url)
# exit()
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read()
# 这是专业的图片网站,使用了懒加载,但是可以通过源码来进行查看,并且重新写xpath路径
with open('7image.html', 'w', encoding='utf-8') as f:
f.write(html.decode('utf-8'))
exit()
# 将html文档解析问DOM模型
html_tree = etree.HTML(html)
# 通过xpath,找到需要的所有的图片的src属性,这里获取到的
img_list = html_tree.xpath('//div[@class="box picblock col3"]/div/a/img/@src2')
for img_url in img_list:
# 定制图片名字为url后10位
file_name = 'image/' + img_url[-10:]
load_image(img_url, file_name)
def load_image(url, file_name):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
image_bytes = response.read()
with open(file_name, 'wb') as f:
f.write(image_bytes)
print(file_name + '图片已经成功下载完毕')
def main():
start = int(input('请输入开始页面:'))
end = int(input('请输入结束页面:'))
url = 'http://sc.chinaz.com/tag_tupian/'
for page in range(start, end + 1):
if page == 1:
real_url = url + 'KaTong.html'
else:
real_url = url + 'KaTong_' + str(page) + '.html'
load_page(real_url)
print('第' + str(page) + '页下载完毕')
if __name__ == '__main__':
main()
68.懒图片加载案例
例:
import urllib.request
from lxml import etree
import json
def handle_tree(html_tree):
node_list = html_tree.xpath('//div[@class="detail-wrapper"]')
duan_list = []
for node in node_list:
# 获取所有的用户名,因为该xpath获取的是一个span列表,然后获取第一个,并且通过text属性得到其内容
user_name = node.xpath('./div[contains(@class, "header")]/a/div/span[@class="name"]')[0].text
# 只要涉及到图片,很有可能都是懒加载,所以要右键查看网页源代码,才能得到真实的链接
# 由于这个获取的结果就是属性字符串,所以只需要加上下标0即可
face = node.xpath('./div[contains(@class, "header")]//img/@data-src')[0]
# .代表当前,一个/表示一级子目录,两个//代表当前节点里面任意的位置查找
content = node.xpath('./div[@class="content-wrapper"]//p')[0].text
zan = node.xpath('./div[@class="options"]//li[@class="digg-wrapper "]/span')[0].text
item = {
'username':user_name,
'face':face,
'content':content,
'zan':zan,
}
# 将其存放到列表中
duan_list.append(item)
# 将列表写入到文件中
with open('8duanzi.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(duan_list, ensure_ascii=False) + '\n')
print('over')
def main():
# 爬取百度贴吧,不能加上headers,加上headers爬取不下来
url = 'http://neihanshequ.com/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html_bytes = response.read()
# fp = open('8tieba.html', 'w', encoding='utf-8')
# fp.write(html_bytes.decode('utf-8'))
# fp.close()
# exit()
# 将html字节串转化为html文档树
# 文档树有xpath方法,文档节点也有xpath方法
# 【注】不能使用字节串转化为文档树,这样会有乱码
html_tree = etree.HTML(html_bytes.decode('utf-8'))
handle_tree(html_tree)
if __name__ == '__main__':
main()
69. . / 和 // 在 xpath 中的使用
.代表当前目录
/ 表示一级子目录
// 代表当前节点里面任意的位置
70.获取内容的示范
获取内容时,如果为字符串,则不需要使用 text 只需要写[0]
face = node.xpath('./div[contains(@class, "header")]//img/@data-src')[0]
div 下 class 为 "content-wrapper" 的所有 p 标签内容
content = node.xpath('./div[@class="content-wrapper"]//p')[0].text
div 下 class 为 "options" 的所有 li 标签下 class为 "digg-wrapper" 的所有 span 标签内容
zan = node.xpath('./div[@class="options"]//li[@class="digg-wrapper"]/span')[0].text
71.将json对象转化为json格式字符串
f.write(json.dumps(duan_list, ensure_ascii=False) + '\n')
72.正则获取 div 下的内容
1.获取 div 到 img 之间的数据
2.img 下 src 的数据
3.img 下 alt 的数据
4.�