深度分析NVIDIA A100显卡架构(附论文&源码下载)
计算机视觉研究院专栏
作者:Edison_G
英伟达A100 Tensor Core GPU架构深度讲解
上次“计算机视觉研究院”已经简单介绍了GPU的发展以及安培架构的A100显卡,今天我们就来更加深入讲解其高性能技术和结构,值得深度学习研究者深入学习,有兴趣加入我们学习群, 一起来讨论学习,共同进步!
NVIDIA®GPU是推动人工智能革命的主要计算引擎,为人工智能训练和推理工作负载提供了巨大的加速。此外,NVIDIA GPU加速了许多类型的HPC和数据分析应用程序和系统,使客户能够有效地分析、可视化和将数据转化为洞察力。NVIDIA的加速计算平台是世界上许多最重要和增长最快的行业的核心。
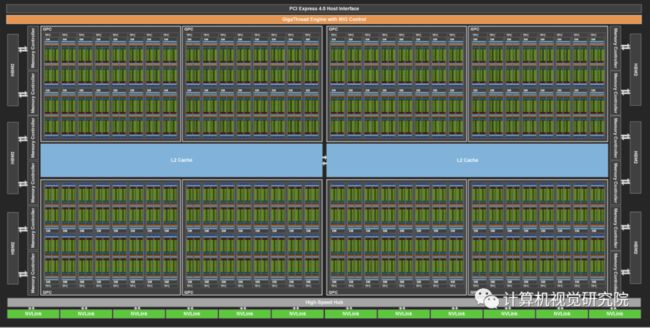
1、A100单元组成
基于安培体系结构的NVIDIA A100 GPU是为了从其许多新的体系结构特征和优化中提供尽可能多的AI和HPC计算能力而设计的。在台积电7nm N7 FinFET制造工艺上,A100提供了比Tesla V100中使用的12nm FFN工艺更高的晶体管密度、更好的性能和更好的功率效率。一种新的Multi-Instance GPU(MIG)能为多租户和虚拟化GPU环境提供了增强的客户端/应用程序故障隔离和QoS,这对云服务提供商特别有利。一个更快和更强的错误抗力的第三代NVIDIA的NVLink互连提供了改进的多GPU性能缩放的超尺度数据中心。
NVIDIA GA100 GPU由多个GPU处理集群(gpc)、纹理处理集群(tpc)、流式多处理器(SMs)和HBM2内存控制器组成。 GA100 GPU的完整实现包括以下单元:
· 8 GPCs, 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs per full GPU
· 64 FP32 CUDA Cores/SM, 8192 FP32 CUDA Cores per full GPU
· 4 third-generation Tensor Cores/SM, 512 third-generation Tensor Cores per full GPU
· 6 HBM2 stacks, 12 512-bit memory controllers
GA100 GPU的A100 Tensor Core GPU实现包括以下单元:
· 7 GPCs, 7 or 8 TPCs/GPC, 2 SMs/TPC, up to 16 SMs/GPC, 108 SMs
· 64 FP32 CUDA Cores/SM, 6912 FP32 CUDA Cores per GPU
· 4 third-generation Tensor Cores/SM, 432 third-generation Tensor Cores per GPU
· 5 HBM2 stacks, 10 512-bit memory controllers
2、A100 SM Architecture

新的A100 SM显著提高了性能,建立在Volta和Turing SM体系结构中引入的特性的基础上,并增加了许多新的功能和增强。 A100 SM图如上图所示。
Volta和Turing每个SM有8个张量核,每个张量核每个时钟执行64个FP16/FP32混合精度融合乘法加法(FMA)操作。A100 SM包括新的第三代张量核心,每个核心执行256 FP16/FP32 FMA操作每时钟。A100每个SM有四个张量核,每个时钟总共提供1024个密集的FP16/FP32 FMA操作,与Volta和Turing相比,每个SM的计算功率增加了两倍。 本文简要强调了SM的主要功能:
Third-generation Tensor Cores:
所有数据类型的加速,包括FP16、BF16、TF32、FP64、INT8、INT4和Binary;
新的张量核稀疏特性利用了深度学习网络中的细粒度结构稀疏性,使标准张量核操作的性能提高了一倍;
A100中的TF32 Tensor核心操作为在DL框架和HPC中加速FP32输入/输出数据提供了一条简单的途径,运行速度比V100 FP32 FMA操作快10倍,或在稀疏情况下快20倍;
FP16/FP32混合精度张量核运算为DL提供了前所未有的处理能力,运行速度比V100张量核运算快2.5倍,稀疏性增加到5倍;
BF16/FP32混合精度张量核心运算的运行速度与FP16/FP32混合精度相同;
FP64 Tensor核心操作为HPC提供了前所未有的双精度处理能力,运行速度比V100 FP64 DFMA操作快2.5倍;
具有稀疏性的INT8张量核操作为DL推理提供了前所未有的处理能力,运行速度比V100 INT8操作快20倍;
192kb的共享内存和L1数据缓存,比V100 SM大1.5x;
新的异步复制指令将数据直接从全局内存加载到共享内存中,可以选择绕过一级缓存,并且不需要使用中间寄存器文件(RF);
新的基于共享内存的屏障单元(异步屏障),用于新的异步复制指令;
二级缓存管理和常驻控制的新说明;
CUDA协作组支持的新的扭曲级缩减指令;
许多可编程性改进以降低软件复杂性。
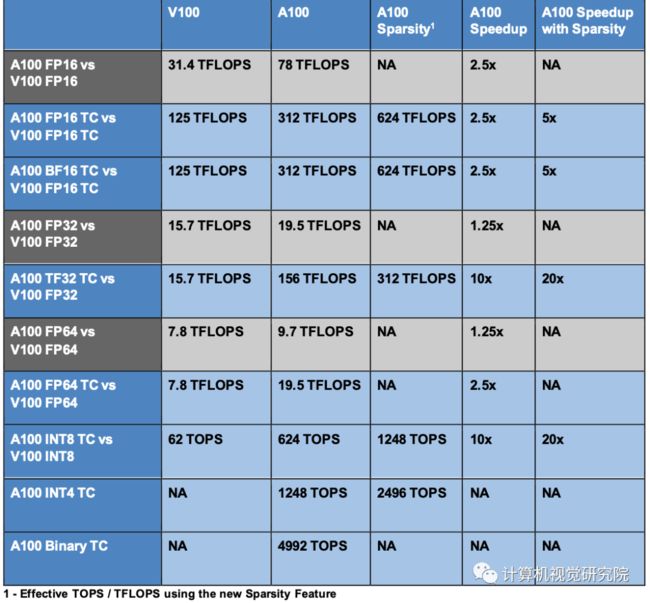
上表,比较了V100和A100 FP16张量核心操作,还将V100 FP32、FP64和INT8标准操作与各自的A100 TF32、FP64和INT8张量核心操作进行了比较。吞吐量是每个GPU的聚合,A100使用FP16、TF32和INT8的稀疏张量核心操作。左上角的图显示了两个V100 FP16张量核,因为V100 SM每个SM分区有两个张量核,而A100 SM分区有两个张量核。
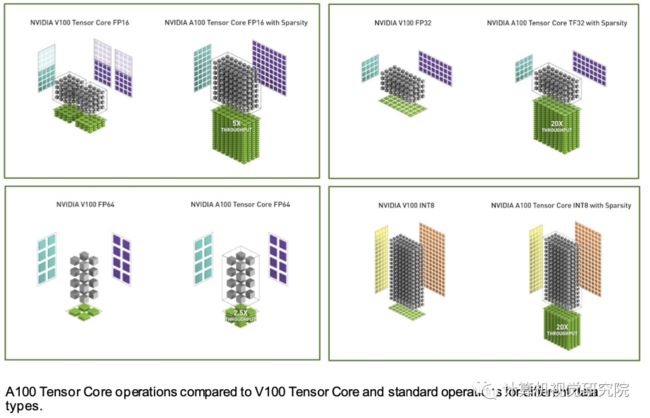
3、A100 Tensor Cores 支持所有数据类型
人工智能训练的默认是FP32,没有张量核心加速度。NVIDIA安培体系结构引入了对TF32的新支持,使得人工智能训练在默认情况下可以使用张量核,而用户不必费劲。在产生标准IEEE FP32输出之前,非张量操作继续使用FP32数据路径,而TF32张量核读取FP32数据并使用与FP32相同的范围,同时降低内部精度。TF32包括8位指数(与FP32相同)、10位尾数(与FP16精度相同)和1个符号位。
与Volta一样,自动混合精度(AMP)使你能够使用FP16的混合精度进行人工智能训练,只需更改几行代码。使用AMP,A100提供比TF32快2倍的张量核心性能。
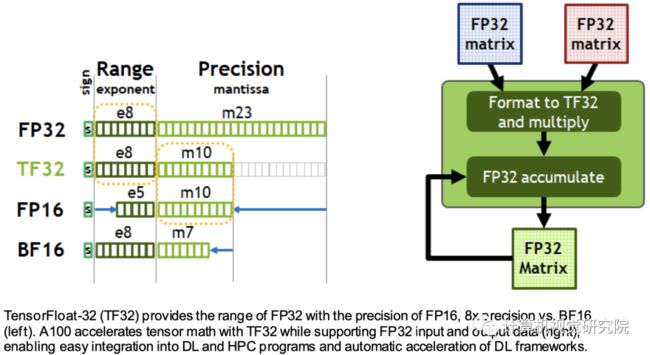
综上所述,用户对NVIDIA安培架构数学进行DL训练的选择如下:
默认情况下,使用TF32张量核,不调整用户脚本。与A100上的FP32相比,吞吐量高出8倍;与V100上的FP32相比,吞吐量高出10倍。 应使用FP16或BF16混合精度训练以获得最大训练速度。与TF32相比,吞吐量增加了2倍,与A100上的FP32相比,吞吐量增加了16倍,与V100上的FP32相比,吞吐量增加了20倍。
高性能计算机应用的性能需求正在迅速增长。许多科学和研究领域的应用都依赖于双精度(FP64)计算。

为了满足HPC计算快速增长的计算需求,A100 GPU支持张量运算,加速符合IEEE标准的FP64计算,使FP64的性能达到NVIDIA Tesla V100 GPU的2.5倍。
A100上新的双精度矩阵乘法加法指令取代了V100上的8条DFMA指令,减少了指令获取、调度开销、寄存器读取、数据路径功率和共享内存读取带宽。 A100中的每个SM总共计算64个FP64 FMA操作/时钟(或128个FP64操作/时钟),是特斯拉V100吞吐量的两倍。A100 Tensor Core GPU具有108条短信息,峰值FP64吞吐量为19.5tflops,是Tesla V100的2.5倍。
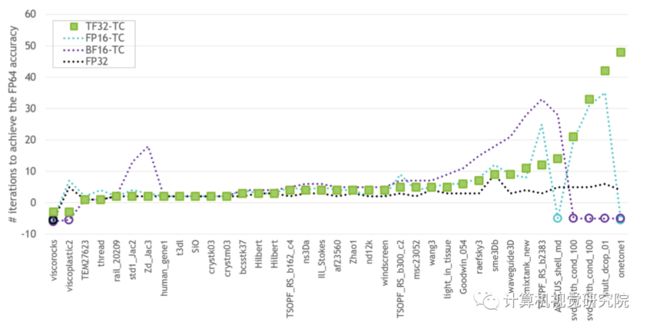
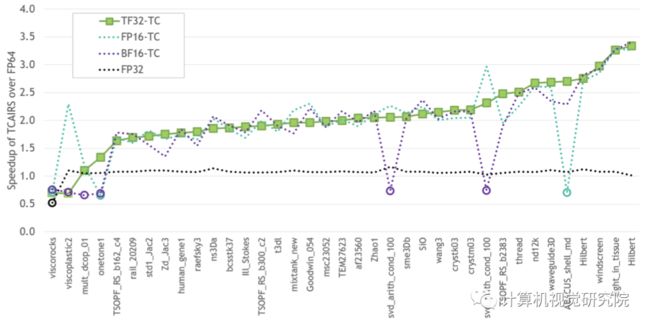
4、A100 GPU引入了细粒度结构稀疏性
新精度的引入是A100的深度学习运算效率提高的关键之一。而另一个运算效率提高的关键是第三代Tensor Core的结构化稀疏特性,稀疏方法是指通过从神经网络中提取尽可能多不需要的参数,来压缩神经网络计算量。Tensor Core的矩阵稀疏加速原理如下图所示,首先对计算模型做 50% 稀疏,稀疏化后不重要的参数置0,之后通过稀疏指令,在进行矩阵运算时,矩阵中每一行只有非零值的元素与另一矩阵相应元素匹配,这将计算转换成一个更小的密集矩阵乘法,实现 2 倍的加速。这一特性可提供高达 2 倍的峰值吞吐量,同时不会牺牲深度学习核心矩阵乘法累加作业的准确率。
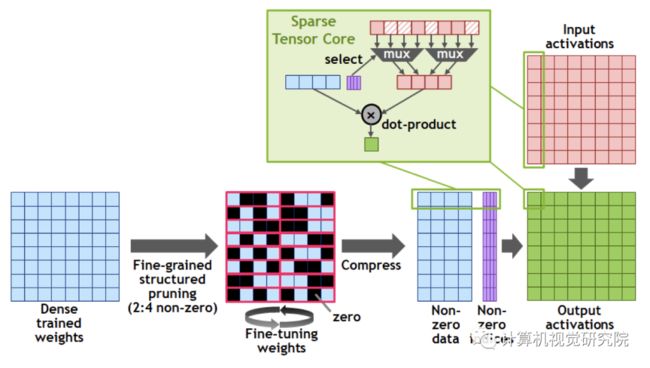
A100 稀疏矩阵运算示意图
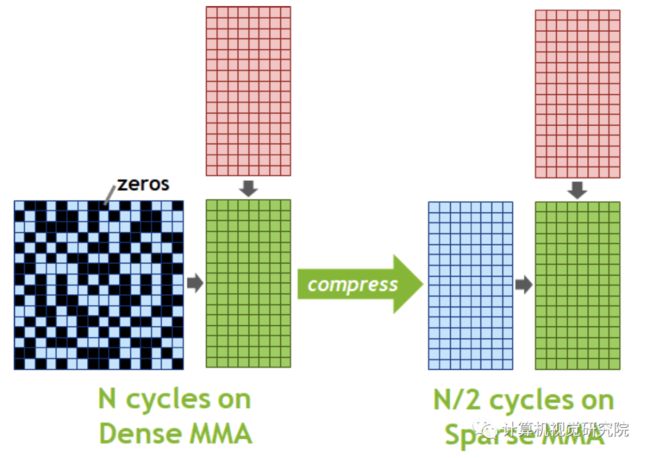
5、Sparse Matrix Multiply-Accumulate (MMA) Operations
A100的新Sparse MMA指令跳过对具有零值的条目的计算,导致Tensor Core计算吞吐量增加一倍。例如,在下图中,矩阵A是一个稀疏矩阵,稀疏率为50%,遵循所需的2:4结构模式,矩阵B是一个大小一半的密集矩阵。标准的MMA操作不会跳过零值,并将计算整个16x8x16矩阵在N个周期中相乘的结果。使用稀疏MMA指令,只有矩阵A的每一行中具有非零值的元素与来自矩阵B的相应元素匹配。这将计算转化为一个较小的矩阵乘法,只需要N/2周期,一个2倍的加速。
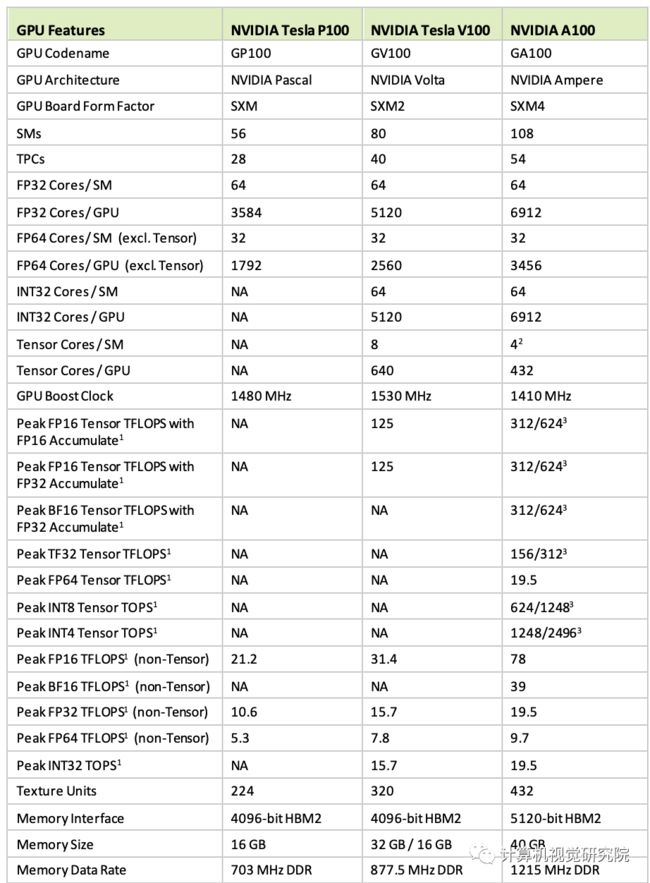
Comparison of NVIDIA Data Center GPUs

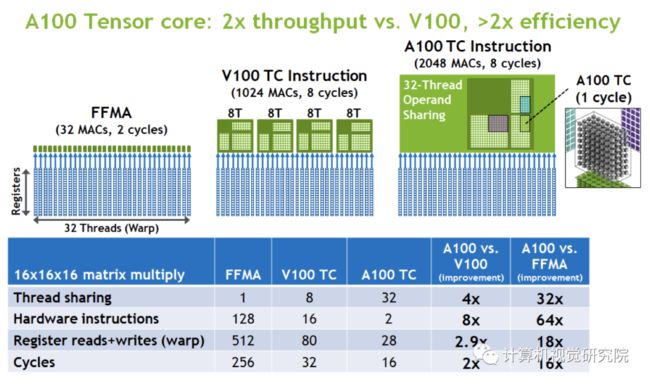
A100 Tensor Core高效的吞吐量
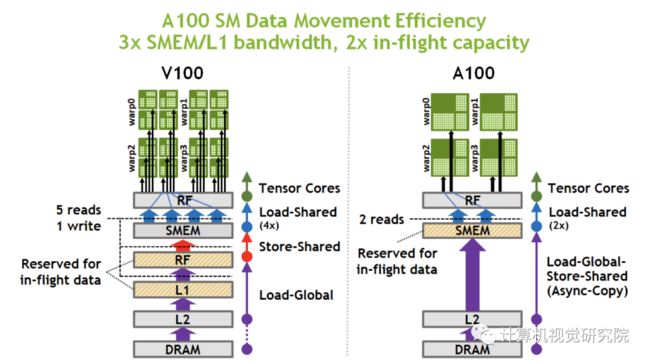
A100 SM Data Movement Efficiency
A100 2级缓存residency controls
A100 Compute Data Compression

具有多个独立GPU计算工作负载的MIG配置

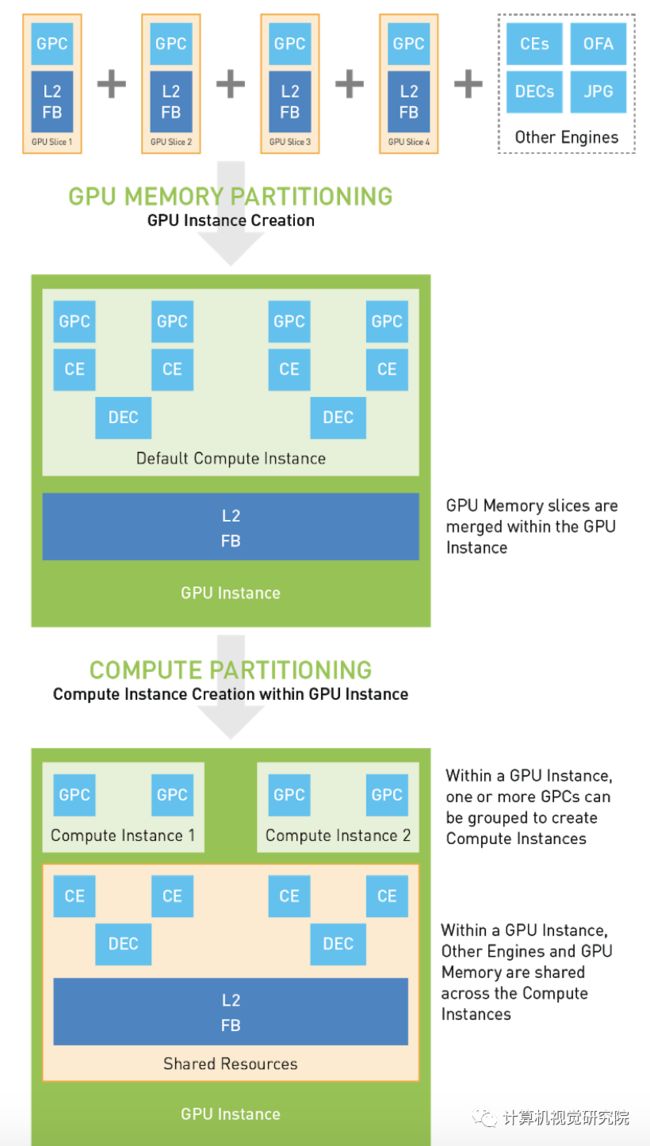
敬请关注下一期深入讲解GPU实例!
✄-----------------------------------
如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注我们
公众号 : 计算机视觉研究院
关注回复“A100”获取论文