HashMap、ConcurrentHashMap深入讲解(JDK7/8)
下载地址(已将图片传到云端,md文件方便浏览更改):https://download.csdn.net/download/hancoder/12318377
对应视频地址:https://www.bilibili.com/video/BV1FE411t7M7
在线预览地址:https://blog.csdn.net/hancoder/article/details/105424922
一 HashMap(源码级解读)
1.HashMap简介
HashMap基于哈希表的Map接口实现,是以key-value存储形式存在,即主要用来存放键值对。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null,但是key只能有一个为null。此外,HashMap中的映射不是有序的。
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突**(两个对象调用的hashCode方法计算的哈希码值一致导致计算的数组索引值相同)**而存在的(“拉链法”解决冲突)。
JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8,或者红黑树的边界值)并且当前数组的长度大于64时,此时此索引位置上的所有数据改为使用红黑树存储。
如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间,具体可以参考 treeifyBin方法。
这样做的目的是因为数组比较小,尽量避开红黑树结构,这种情况下变为红黑树结构,反而会降低效率,因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡 。同时数组长度小于64时,搜索时间相对要快些。所以综上所述为了提高性能和减少搜索时间,底层在阈值大于8并且数组长度大于64时,链表才转换为红黑树。具体可以参考 treeifyBin方法。
当然虽然增了红黑树作为底层数据结构,结构变得复杂了,但是阈值大于8并且数组长度大于64时,链表转换为红黑树时,效率也变的更高效。
2.HashMap底层的数据结构
2.1数据结构概念
在JDK1.8 之前 HashMap 由 数组+链表 数据结构组成的。
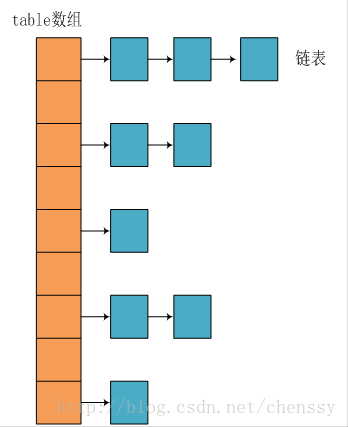
在JDK1.8 之后 HashMap 由 数组+链表 +红黑树数据结构组成的。
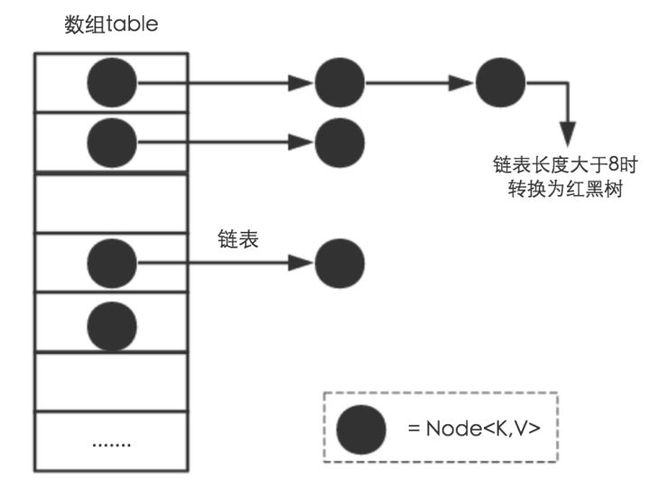
2.2HashMap底层的数据结构存储数据的过程
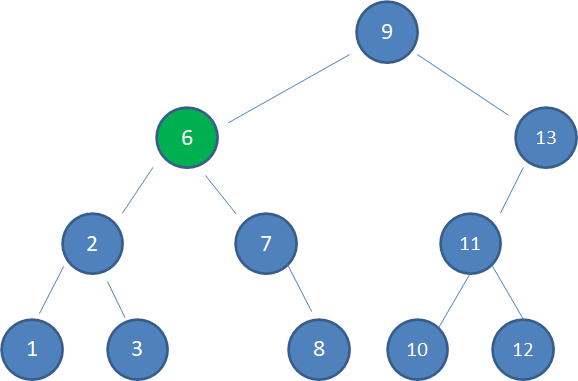
测试:
public class Demo01 {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
map.put("刘德华", 53);
map.put("柳岩", 35);
map.put("张学友", 55);
map.put("郭富城", 52);
map.put("黎明", 51);
map.put("林青霞", 55);
map.put("刘德华", 50);
}
}
存储过程如下所示:

说明:
1.面试题1:HashMap中hash函数是怎么实现的?还有哪些hash函数的实现方式?
对于key的hashCode做hash操作,无符号右移16位然后做异或运算。
还有伪随机数法和取余数法。这2种效率都比较低。而无符号右移16位和异或运算效率是最高的。至于底层是如何计算的我们下面看源码时给大家讲解。
2.面试题2:当两个对象的hashCode相等时会怎么样?
会产生哈希碰撞,若key值内容相同则替换旧的value.不然连接到链表后面,链表长度超过阈值8并且数组长度大于等于64就转换为红黑树存储。
3.面试题3:何时发生哈希碰撞和什么是哈希碰撞,如何解决哈希碰撞?
只要两个元素的key计算的哈希码值相同就会发生哈希碰撞。jdk8前使用链表解决哈希碰撞。jdk8之后使用链表+红黑树解决哈希碰撞。
4.面试题4:如果两个键的hashcode相同,如何存储键值对?
hashcode相同,通过equals比较内容是否相同。
相同:则新的value覆盖之前的value
不相同:则将新的键值对添加到哈希表中
5.在不断的添加数据的过程中,会涉及到扩容问题,当超出临界值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
6.通过上述描述,当位于一个链表中的元素较多,即hash值相等但是内容不相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度(阈值)超过 8 时且当前数组的长度 > 64时,将链表转换为红黑树,这样大大减少了查找时间。jdk8在哈希表中引入红黑树的原因只是为了查找效率更高。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的。如下图所示。

但是这样的话问题来了,传统hashMap的缺点,1.8为什么引入红黑树?这样结构的话不是更麻烦了吗,为何阈值大于8换成红黑树?
JDK 1.8 以前 HashMap 的实现是 数组+链表,即使哈希函数取得再好,也很难达到元素百分百均匀分布。当 HashMap 中有大量的元素都存放到同一个桶中时,这个桶下有一条长长的链表,这个时候 HashMap 就相当于一个单链表,假如单链表有 n 个元素,遍历的时间复杂度就是 O(n),完全失去了它的优势。针对这种情况,JDK 1.8 中引入了 红黑树(查找时间复杂度为 O(logn))来优化这个问题。 当链表长度很小的时候,即使遍历,速度也非常快,但是当链表长度不断变长,肯定会对查询性能有一定的影响,所以才需要转成树。
至于为什么阈值是8,我想,去源码中找寻答案应该是最可靠的途径。 下面我们在分析源码的时候会介绍。
7.总结:
上述我们大概阐述了HashMap底层存储数据的方式。为了方便大家更好的理解,我们结合一个存储流程图来进一步说明一下:(jdk8存储过程)
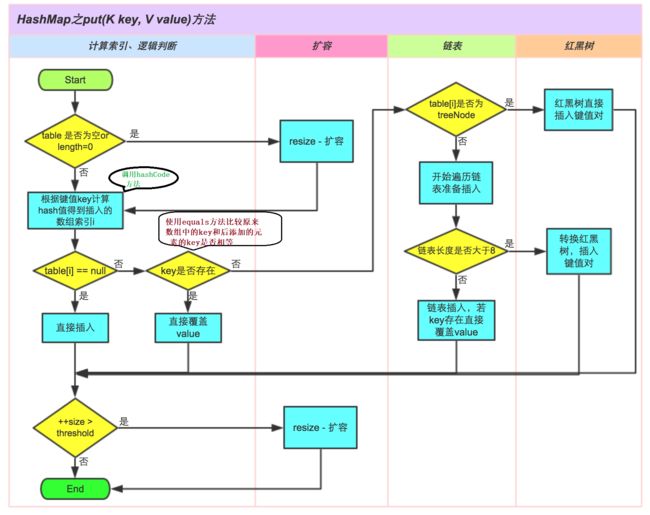
说明:
1.size表示 HashMap中K-V的实时数量 , 注意这个不等于数组的长度 。
2.threshold( 临界值) =capacity(容量) * loadFactor( 加载因子 )。这个值是当前已占用数组长度的最大值。size超过这个临界值就重新resize(扩容),扩容后的 HashMap 容量是之前容量的两倍 。
3.HashMap继承关系
HashMap继承关系如下图所示:

说明:
- Cloneable 空接口,表示可以克隆。 创建并返回HashMap对象的一个副本。
- Serializable 序列化接口。属于标记性接口。HashMap对象可以被序列化和反序列化。
- AbstractMap 父类提供了Map实现接口。以最大限度地减少实现此接口所需的工作。
补充:通过上述继承关系我们发现一个很奇怪的现象, 就是HashMap已经继承了AbstractMap而AbstractMap类实现了Map接口,那为什么HashMap还要在实现Map接口呢?同样在ArrayList中LinkedList中都是这种结构。
据 java 集合框架的创始人Josh Bloch描述,这样的写法是一个失误。在java集合框架中,类似这样的写法很多,最开始写java集合框架的时候,他认为这样写,在某些地方可能是有价值的,直到他意识到错了。显然的,JDK的维护者,后来不认为这个小小的失误值得去修改,所以就这样存在下来了。
4.HashMap类成员+方法
4.1成员变量
//JDK8
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小大小
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍
transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容
int threshold;
// 加载因子
final float loadFactor;
}
Node内部类
Node节点类源码:
// 继承自 Map.Entry树节点类源码:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父
TreeNode<K,V> left; // 左
TreeNode<K,V> right; // 右
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; // 判断颜色
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// 返回根节点
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
}
DEFAULT_INITIAL_CAPACITY初始大小
1.集合的初始化容量( 必须是二的n次幂 )
//默认的初始容量是16 -- 1<<4相当于1*2的4次方---1*16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
问题: 为什么必须是2的n次幂?如果输入值不是2的幂比如10会怎么样?
HashMap构造方法还可以指定集合的初始化容量大小:
HashMap(int initialCapacity) 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
根据上述讲解我们已经知道,当向HashMap中添加一个元素的时候,需要根据key的hash值,去确定其在数组中的具体位置。 HashMap为了存取高效,要尽量减少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现就在把数据存到哪个链表中的算法。
这个算法实际就是取模,hash%length,但是计算机中直接求余效率不如位运算(这点上述已经讲解)。所以源码中做了优化,使用 hash&(length-1),而实际上hash%length等于hash&(length-1)的前提是length是2的n次幂。
为什么这样能均匀分布减少碰撞呢?2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1;
举例:
说明:按位与运算:相同的二进制数位上,都是1的时候,结果为1,否则为零。
例如长度为8时候,3&(8-1)=3 2&(8-1)=2 ,不同位置上,不碰撞;
例如长度length为8时候,8是2的3次幂。二进制是:1000
length-1 二进制运算:
1000
- 1
---------------------
111
如下所示:当hash为3时
hash&(length-1)
3 &(8 - 1)=3
00000011 3 hash
& 00000111 7 length-1
---------------------
00000011-----》3 数组下标
hash&(length-1) 当hash为2时
2 & (8 - 1) = 2
00000010 2 hash
& 00000111 7 length-1
---------------------
00000010-----》2 数组下标
说明:上述计算结果是不同位置上,不碰撞;
例如长度为9时候,3&(9-1)=0 2&(9-1)=0 ,都在0上,碰撞了;
例如长度length为9时候,9不是2的n次幂。二进制是:00001001
length-1 二进制运算:
1001
- 1
---------------------
1000
如下所示:
hash&(length-1) 当hash为3时
3 &(9 - 1)=0
00000011 3 hash
& 00001000 8 length-1
---------------------
00000000-----》0 数组下标
hash&(length-1) 当hash为2时
2 & (9 - 1) = 2
00000010 2 hash
& 00001000 8 length-1
---------------------
00000000-----》0 数组下标
说明:上述计算结果都在0上,碰撞了;
注意: 当然如果不考虑效率直接求余即可(就不需要要求长度必须是2的n次方了)
小结:
1.由上面可以看出,当我们根据key的hash确定其在数组的位置时,如果n为2的幂次方,可以保证数据的均匀插入,如果n不是2的幂次方,可能数组的一些位置永远不会插入数据,浪费数组的空间,加大hash冲突。
2.另一方面,一般我们可能会想通过 % 求余来确定位置,这样也可以,只不过性能不如 & 运算。而且当n是2的幂次方时:hash & (length - 1) == hash % length
3.因此,HashMap 容量为2次幂的原因,就是为了数据的的均匀分布,减少hash冲突,毕竟hash冲突越大,代表数组中一个链的长度越大,这样的话会降低hashmap的性能
4.如果创建HashMap对象时,输入的数组长度是10,不是2的幂,HashMap通过一通位移运算和或运算得到的肯定是2的幂次数,并且是大于且离那个数最近的数字。
tableSizeFor()向上取整2次幂
JDK8
//创建HashMap集合的对象,指定数组长度是10,不是2的幂
HashMap hashMap = new HashMap(10);
public HashMap(int initialCapacity) {//initialCapacity=10
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {//initialCapacity=10
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
static final int tableSizeFor(int cap) {//int cap = 10 //把输入值变成2的次幂
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;//+1
}
说明:
由此可以看到,当在实例化HashMap实例时,如果给定了initialCapacity(假设是10),由于HashMap的capacity必须都是2的幂,因此tableSizeFor()这个方法用于找到大于等于initialCapacity(假设是10)的最小的2的幂(initialCapacity如果就是2的幂,则返回的还是这个数)。
下面分析这个算法:
1)、首先,为什么要对cap做减1操作。int n = cap - 1;
这是为了防止,cap已经是2的幂。如果cap已经是2的幂, 又没有执行这个减1操作,则执行完后面的几条无符号右移操作之后,返回的capacity将是这个cap的2倍。如果不懂,要看完后面的几个无符号右移之后再回来看看。
下面看看这几个无符号右移操作:
2)、如果n这时为0了(经过了cap-1之后),则经过后面的几次无符号右移依然是0,最后返回的capacity是 1(最后有个(n < 0) ? 1的操作)。
这里只讨论n不等于0的情况。
3)、注意:|(按位或运算):运算规则:相同的二进制数位上,都是0的时候,结果为0,否则为1。
只要是1就是1
//关于移位的说明:
>> :按二进制形式把所有的数字向右移动对应位数,低位移出(舍弃),高位的空位补符号位,即正数补零,负数补1。符号位不变。
>>>:按二进制形式把所有的数字向右移动对应位数,低位移出(舍弃),高位的空位补零。对于正数来说和带符号右移相同,对于负数来说不同。
-1在32位二进制中表示为:
11111111 11111111 11111111 11111111
-1>>1:按位右移,符号位不变,仍旧得到
11111111 11111111 11111111 11111111
因此值仍为-1
而-1>>>1的结果为 01111111 11111111 11111111 11111111
第一次右移 :
int n = cap - 1;//cap=10 n=9
n |= n >>> 1;
00000000 00000000 00000000 00001001 //9
|
00000000 00000000 00000000 00000100 //9右移之后变为4
-------------------------------------------------
00000000 00000000 00000000 00001101 //按位异或之后是13
由于n不等于0,则n的二进制表示中总会有一bit为1,这时考虑最高位的1。通过无符号右移1位,则将最高位的1右移了1位,再做或操作,使得n的二进制表示中与最高位的1紧邻的右边一位也为1,如:
00000000 00000000 00000000 00001101
第二次右移 :
n |= n >>> 2;//n通过第一次右移变为了:n=13
00000000 00000000 00000000 00001101 // 13
|
00000000 00000000 00000000 00000011 //13右移之后变为3
-------------------------------------------------
00000000 00000000 00000000 00001111 //按位异或之后是15
注意,这个n已经经过了n |= n >>> 1; 操作。假设此时n为00000000 00000000 00000000 00001101 ,则n无符号右移两位,会将最高位两个连续的1右移两位,然后再与原来的n做或操作,这样n的二进制表示的高位中会有4个连续的1。如:
00000000 00000000 00000000 00001111 //按位异或之后是15
第三次右移 :
n |= n >>> 4;//n通过第一、二次右移变为了:n=15
00000000 00000000 00000000 00001111 // 15
|
00000000 00000000 00000000 00000000 //15右移之后变为0
-------------------------------------------------
00000000 00000000 00000000 00001111 //按位异或之后是15
这次把已经有的高位中的连续的4个1,右移4位,再做或操作,这样n的二进制表示的高位中正常会有8个连续的1。如00001111 1111xxxxxx 。
以此类推
注意,容量最大也就是32bit的正数,因此最后n |= n >>> 16; ,最多也就32个1(但是这已经是负数了。在执行tableSizeFor之前,对initialCapacity做了判断,如果大于MAXIMUM_CAPACITY(2 ^ 30),则取MAXIMUM_CAPACITY。如果等于MAXIMUM_CAPACITY(2 ^ 30),会执行移位操作。所以这里面的移位操作之后,最大30个1,不会大于等于MAXIMUM_CAPACITY。30个1,加1之后得2 ^ 30) 。
请看下面的一个完整例子:
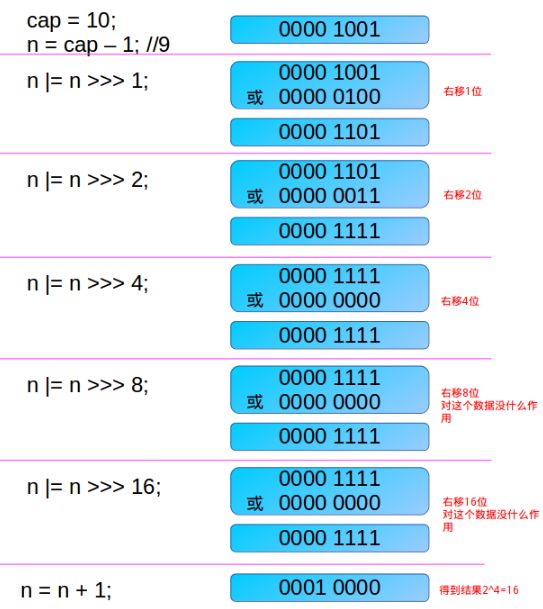
注意,得到的这个capacity却被赋值给了threshold。
this.threshold = tableSizeFor(initialCapacity);//initialCapacity=10
2.默认的负载因子,默认值是0.75 。达到这个值后就扩容
static final float DEFAULT_LOAD_FACTOR = 0.75f;
3.集合最大容量
//集合最大容量的上限是:2的30次幂
static final int MAXIMUM_CAPACITY = 1 << 30;
4.当链表的值超过8则会转红黑树(1.8新增)
//当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
问题:为什么Map桶中节点个数超过8才转为红黑树?
8这个阈值定义在HashMap中,针对这个成员变量,在源码的注释中只说明了8是bin(bin就是bucket(桶))从链表转成树的阈值,但是并没有说明为什么是8:
在HashMap中有一段注释说明: 我们继续往下看 :
Because TreeNodes are about twice the size of regular nodes, we use them only when bins contain enough nodes to warrant use (see TREEIFY_THRESHOLD). And when they become too small (due to removal or resizing) they are converted back to plain bins. In usages with well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution
(http://en.wikipedia.org/wiki/Poisson_distribution) with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance, the expected occurrences of list size k are (exp(-0.5)*pow(0.5, k)/factorial(k)).
The first values are:
因为树节点的大小大约是普通节点的两倍,所以我们只在箱子包含足够的节点时才使用树节点(参见TREEIFY_THRESHOLD)。当它们变得太小(由于删除或调整大小)时,就会被转换回普通的桶。在使用分布良好的用户hashcode时,很少使用树箱。理想情况下,在随机哈希码下,箱子中节点的频率服从泊松分布
(http://en.wikipedia.org/wiki/Poisson_distribution),默认调整阈值为0.75,平均参数约为0.5,尽管由于调整粒度的差异很大。忽略方差,列表大小k的预期出现次数是(exp(-0.5)*pow(0.5, k)/factorial(k))。
第一个值是:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
TreeNodes占用空间是普通Nodes的两倍,所以只有当bin包含足够多的节点时才会转成TreeNodes,而是否足够多就是由TREEIFY_THRESHOLD的值决定的。当bin中节点数变少时,又会转成普通的bin。并且我们查看源码的时候发现,链表长度达到8就转成红黑树,当长度降到6就转成普通bin。
这样就解释了为什么不是一开始就将其转换为TreeNodes,而是需要一定节点数才转为TreeNodes,说白了就是权衡,空间和时间的权衡。
这段内容还说到:当hashCode离散性很好的时候,树型bin用到的概率非常小,因为数据均匀分布在每个bin中,几乎不会有bin中链表长度会达到阈值。但是在随机hashCode下,离散性可能会变差,然而JDK又不能阻止用户实现这种不好的hash算法,因此就可能导致不均匀的数据分布。不过理想情况下随机hashCode算法下所有bin中节点的分布频率会遵循泊松分布,我们可以看到,一个bin中链表长度达到8个元素的概率为0.00000006,几乎是不可能事件。所以,之所以选择8,不是随便决定的,而是根据概率统计决定的。由此可见,发展将近30年的java每一项改动和优化都是非常严谨和科学的。
也就是说:选择8因为符合泊松分布,超过8的时候,概率已经非常小了,所以我们选择8这个数字。
补充:
1).
Poisson分布(泊松分布),是一种统计与概率学里常见到的离散[概率分布]。
泊松分布的概率函数为:
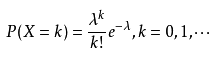
泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生次数。 泊松分布适合于描述单位时间内随机事件发生的次数。
2).以下是我在研究这个问题时,在一些资料上面翻看的解释:供大家参考:
红黑树的平均查找长度是log(n),如果长度为8,平均查找长度为log(8)=3,链表的平均查找长度为n/2,当长度为8时,平均查找长度为8/2=4,这才有转换成树的必要;链表长度如果是小于等于6,6/2=3,而log(6)=2.6,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
5.当链表的值小于6则会从红黑树转回链表
//当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
6.当Map里面的数量超过这个值时,表中的桶才能进行树形化 ,否则桶内元素太多时会扩容,而不是树形化 为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD (8)
//桶中结构转化为红黑树对应的数组长度最小的值
static final int MIN_TREEIFY_CAPACITY = 64;
7、table用来初始化(必须是二的n次幂)(重点)
//存储元素的数组
transient Node<K,V>[] table;
table在JDK1.8中我们了解到HashMap是由数组加链表加红黑树来组成的结构其中table就是HashMap中的数组,jdk8之前数组类型是Entry
8、 HashMap中存放元素的个数(重点)
//存放元素的个数,注意这个不等于数组的长度。
transient int size;
size为HashMap中K-V的实时数量,不是数组table的长度。
9、 用来记录HashMap的修改次数
// 每次扩容和更改map结构的计数器
transient int modCount;
10、 用来调整大小下一个容量的值计算方式为(容量*负载因子)
// 临界值 当实际大小(容量*负载因子)超过临界值时,会进行扩容
int threshold;
jdk7
private static int roundUpToPowerOf2(int number) {
//number >= 0,不能为负数,
//(1)number >= 最大容量:就返回最大容量
//(2)0 =< number <= 1:返回1
//(3)1 < number < 最大容量:
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;//-1
}
//该方法和jdk8中的tabSizeFor实现基本差不多,只不过这里求的是小于该数的最大2次幂
public static int Integer::highestOneBit(int i) {//只保留最大的位,如果后面都是0还好我没就是想要这个值,但后面不全为0我没就想求更大的幂,所以我们代入此方法时先-1
//因为传入的i>0,所以i的高位还是0,这样使用>>运算符就相当于>>>了,高位0。
//还是举个例子,假设i=5=0101
i |= (i >> 1); //(1)i>>1=0010;(2)i= 0101 | 0010 = 0111
i |= (i >> 2); //(1)i>>2=0011;(2)i= 0111 | 0011 = 0111
i |= (i >> 4); //(1)i>>4=0000;(2)i= 0111 | 0000 = 0111
i |= (i >> 8); //(1)i>>8=0000;(2)i= 0111 | 0000 = 0111
i |= (i >> 16); //(1)i>>16=0000;(2)i= 0111 | 0000 = 0111
return i - (i >>> 1); //(1)0111>>>1=0011(2)0111-0011=0100=4
//所以这里返回4。
//而在上面的roundUpToPowerOf2方法中,最后会将highestOneBit的返回值进行 << 1 操作,即最后的结果为4<<1=8.就是返回大于number的最小2次幂
}
loadFactor加载因子
// 加载因子
final float loadFactor;
说明:
1.loadFactor加载因子,默认0.75,是用来衡量 HashMap 满的程度,表示HashMap的数组存放数据疏密程度,影响hash操作到同一个数组位置的概率,计算HashMap的实时加载因子的方法为:size/capacity,而不是占用桶的数量去除以capacity。capacity 是桶的数量,也就是 table 的长度length。
loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值。
当HashMap里面容纳的元素已经达到HashMap数组长度的75%时,表示HashMap太挤了,需要扩容,而扩容这个过程涉及到 rehash、复制数据等操作,非常消耗性能。,所以开发中尽量减少扩容的次数,可以通过创建HashMap集合对象时指定初始容量来尽量避免。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
如何传入加载因子;构造haspMap时构造传入
构造方法:
HashMap(int initialCapacity, float loadFactor) 构造一个带指定初始容量和加载因子的空 HashMap。
2.为什么加载因子设置为0.75,初始化临界值是12?
loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏。
如果希望链表尽可能少些。要提前扩容,有的数组空间有可能一直没有存储数据。加载因子尽可能小一些。
举例:
例如:加载因子是0.4。 那么16*0.4--->6 如果数组中满6个空间就扩容会造成数组利用率太低了。
加载因子是0.9。 那么16*0.9---->14 那么这样就会导致链表有点多了。导致查找元素效率低。
所以既兼顾数组利用率又考虑链表不要太多,经过大量测试0.75是最佳方案。
- threshold计算公式:capacity(数组长度默认16) * loadFactor(负载因子默认0.75)。这个值是当前已占用数组长度的最大值。当Size>=threshold的时候,那么就要考虑对数组的resize(扩容),也就是说,这个的意思就是 衡量数组是否需要扩增的一个标准。 扩容后的 HashMap 容量是之前容量的两倍.
哈希种子:默认为0
final boolean initHashSeedAsNeeded(int capacity) {
//通过上面的过程,我们知道了currentAltHashing =false
boolean currentAltHashing = hashSeed != 0;
//useAltHashing = false
//我们想让useAl
tHashing为true
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);//容量大于//ALTERNATIVE_HASHING_THRESHOLD是JVM中配置的参数
// false ^ false 结果为false,switching为false
boolean switching = currentAltHashing ^ useAltHashing;//两个不相等返回true
if (switching) {//true了后种子才可能不是0
hashSeed = useAltHashing//只有在这个地方会改变种子
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
//返回false
return switching;
}
4.2构造方法
HashMap 中重要的构造方法,它们分别如下:
1、构造一个空的 HashMap ,默认初始容量(16)和默认负载因子(0.75)。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // 将默认的加载因子0.75赋值给loadFactor,并没有创建数组
}
2、 构造一个具有指定的初始容量和默认负载因子(0.75) HashMap。
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);//重载
}
3、传入另一个Map
// 包含另一个“Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);//下面会分析到这个方法
}
4、 构造一个具有指定的初始容量和负载因子的 HashMap。
HashMap(initialCapacity,loadFactor)
public HashMap(int initialCapacity, float loadFactor) {//初试容量,加载因子
//判断初始化容量initialCapacity是否小于0
if (initialCapacity < 0)
//如果小于0,则抛出非法的参数异常IllegalArgumentException
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//判断初始化容量initialCapacity是否大于集合的最大容量MAXIMUM_CAPACITY-》2的30次幂
if (initialCapacity > MAXIMUM_CAPACITY)
//如果超过MAXIMUM_CAPACITY,会将MAXIMUM_CAPACITY赋值给initialCapacity
initialCapacity = MAXIMUM_CAPACITY;
//判断负载因子loadFactor是否小于等于0或者是否是一个非数值
if (loadFactor <= 0 || Float.isNaN(loadFactor))
//如果满足上述其中之一,则抛出非法的参数异常IllegalArgumentException
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
//将指定的加载因子赋值给HashMap成员变量的负载因子loadFactor
this.loadFactor = loadFactor;
/*
tableSizeFor(initialCapacity) 判断指定的初始化容量是否是2的n次幂,如果不是那么会变为比指定初始化容量大的最小的2的n次幂。这点上述已经讲解过。
但是注意,在tableSizeFor方法体内部将计算后的数据返回给调用这里了,并且直接赋值给threshold边界值了。有些人会觉得这里是一个bug,应该这样书写:
this.threshold = tableSizeFor(initialCapacity) * this.loadFactor;
这样才符合threshold的意思(当HashMap的size到达threshold这个阈值时会扩容)。
但是,请注意,在jdk8以后的构造方法中,并没有对table这个成员变量进行初始化,table的初始化被推迟到了put方法中,在put方法中会对threshold重新计算,put方法的具体实现我们下面会进行讲解
*/
this.threshold = tableSizeFor(initialCapacity);
}
//-------------------------------
求2的次幂:我们可能输入了一个10,而HashMap会让他初始化为16大小。
//-----JDK8--------
static final int tableSizeFor(int cap) {//给容量返回一个2的幂大小的数
//思路:把最高位1后面的位全变成1,然后+1
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
//-----JDK7--------
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
public static int Integer.highestOneBit(int i) {//最高位为1,其余为0
// HD, Figure 3-1
i |= (i >> 1);
i |= (i >> 2);
i |= (i >> 4);
i |= (i >> 8);
i |= (i >> 16);
return i - (i >>> 1);
}
4.3成员方法
计算索引思路:
由key到hashCode:key有个key.hashCode()方法
由hashCode()得到hash:利用hash()函数。JDK7和8主要是hash()不同,但思想都是移位后按位异或。
hash值得到坐标:直接 i = (length - 1) & hash;
hash()
流程:key–>key.hashCode()–>hash=hash(key.hashCode())–>hash移位、求异或–>取余得到坐标i
JDK8的hash():
这个哈希方法首先计算出key的hashCode赋值给h,然后与h无符号右移16位后的二进制进行按位异或得到最后的hash值。计算过程如下所示:
//JDK8
static final int hash(Object key) {
int h;
/* 1)如果key等于null:null也是有哈希值的,返回的是0.
2)如果key不等于null:
首先计算出key的hashCode赋值给h,然后与h【无符号右移16位】后的二进制进行【按位异或】得到最后的hash值
*/
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);//>>>无符号右移后按位异或
}
//------------------
从上面可以得知HashMap是支持Key为空的,而HashTable是直接用Key来获取HashCode所以key为空会抛异常。
{其实上面就已经解释了为什么HashMap的长度为什么要是2的幂因为HashMap 使用的方法很巧妙,它通过 hash & (table.length -1)来得到该对象的保存位,前面说过 HashMap 底层数组的长度总是2的n次方,这是HashMap在速度上的优化,位操作比取模操作速度快。
当 length 总是2的n次方时,hash & (length-1)运算等价于对 length 取模,也就是hash%length,但是&比%具有更高的效率。比如 n % 32 = n & (32 -1)。}
jdk1.7之前的hash():
//JDK7
static int hash(int h) {//h是k.hashCode();与hash种子的结合,初学认为是k.hashCode();即可
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}//性能会稍差一点,因为扰动了4次hashCode
在putVal函数中使用到了上述hash函数计算的哈希值:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
。。。。。。。。。。。。。。
if ((p = tab[i = (n - 1) & hash]) == null)//这里的n表示数组长度16
。。。。。。。。。。。。。。
}
hash()的按位处理演示:
- key.hashCode();返回散列值也就是hashcode。假设随便生成的一个值。
- n:数组初始化的长度是16
- &(按位与运算):运算规则:相同的二进制数位上,都是1的时候,结果为1,否则为零。
- ^(按位异或运算):运算规则:相同的二进制数位上,数字相同,结果为0,不同为1。
>>>:按位无符号右移。无符号右移无论正负,左面都填充0;而有符号右移>>是正补0负补1
1)key.hashCode();返回散列值也就是hashcode。假设随便生成的一个值。

简单来说就是:
-
高16 bit 不变,低16 bit 和高16 bit 做了一个异或(得到的 hashcode 转化为32位二进制,前16位和后16位低16 bit和高16 bit做了一个异或)
问题:为什么要这样操作呢?
如果当n即数组长度很小,假设是16的话,那么n-1即为 —》1111 ,这样的值和hashCode()直接做按位与操作,实际上只使用了哈希值的后4位。如果当哈希值的高位变化很大,低位变化很小,这样就很容易造成哈希冲突了,所以这里把hashCode的高低位都利用起来,从而解决了这个问题。
例如上述:hashCode()的异或结果为h
h: 1111 1111 1111 1111 1111 0000 1110 1010
&
n-1即16-1--》15: 。。。。。。。。。。。。。。。。。....1111
-------------------------------------------------------------------
0000 0000 0000 0000 0000 0000 0000 1010 ----》10作为索引
其实就是将hashCode值作为数组索引,那么如果下个高位hashCode不一致,低位一致的话,就会造成计算的索引还是10,从而造成了哈希冲突了。降低性能。
-
(n-1) & hash = -> 得到下标 (n-1) n表示数组长度16,n-1就是15
-
取余数本质是不断做除法,把剩余的数减去,运算效率要比位运算低。
put()
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);//final V putVal()方法缺省权限修饰符,对外不可见,用户无法调用,只能通过put()
}
putVal()
主要参数:
- hash: key的hash值
- key: 原始Key
- value: 要存放的值
- onlyIfAbsent: true代表只插入新值,不修改
- evict: 如果为false表示table为创建状态
putVal()方法流程:

-
if坐标为null先resize()然后直接赋值
-
else原来有值
- if判断第一个key对不对。key同则拿到e结点
- elif判断是不是树,是树就按照树的方法处理
- else往后遍历for
- 到了尾结点,顺便判断超没超8,树化或者直接插入。加入后e还是为null。break
- 没到尾结点判断key是否等,同则拿到e后break for,不同则往后遍历for binCount++
- if(e!=null),e为null代表是新插入的,跳过if;不为null代表是修改,修改并给调用者return旧值;
-
执行至此代表e是新插入的,++size判断是否需要resize
与JDK1.7区别:JDK1.7采用头插,1.8采用尾插
JDK8 put():尾插
//JDK8
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//JDK8
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
/*
1)transient Node[] table; 表示存储Map集合中元素的数组。
2)(tab = table) == null 表示将空的table赋值给tab,然后判断tab是否等于null,第一次肯定是 null
3)(n = tab.length) == 0 表示将数组的长度赋值给n,然后判断n是否等于0,n等于0
由于if判断使用双或,满足一个即可,则执行代码 n = (tab = resize()).length; 进行数组初始化。
并将初始化好的数组长度赋值给n.
4)执行完n = (tab = resize()).length,数组tab每个空间都是null
*/
if ((tab = table) == null || (n = tab.length) == 0)//Node数组为空的话就resize
n = (tab = resize()).length;
/*
1)i = (n - 1) & hash 表示计算数组的索引赋值给i,即确定元素存放在哪个桶(数组坐标)中
2)p = tab[i = (n - 1) & hash]表示获取计算出的位置的数据赋值给节点p
3) (p = tab[i = (n - 1) & hash]) == null 判断节点位置是否等于null,如果为null,则执行代码:tab[i] = newNode(hash, key, value, null);直接根据键值对创建新的节点放入该位置的桶中
小结:如果当前桶没有哈希碰撞冲突,则直接把键值对插入空间位置
*/
if ((p = tab[i = (n - 1) & hash]) == null)//该索引上没有Node
//p为该位置"链表",也是一个Node结点
//创建一个新的节点存入到桶中
tab[i] = newNode(hash, key, value, null);//还不return,一会做些记录后再return
else {// tab[i]!=null,表示这个位置已经有值了。下面基本都是在“位置上有值”的基础上进行操作的
Node<K,V> e; K k;//e标识要修改的那个结点,先查出来那个结点(不存在就创建),最后再改
/*
比较桶中第一个元素(数组中的结点)的hash值和key是否相等
1)p.hash == hash :p.hash表示原来存在数据的hash值,hash表示后添加数据的hash值,比较两个hash值是否相等。不等就直接跳过if
2)(k = p.key) == key :p.key获取原来数据的key赋值给k,key表示后添加数据的key,比较两个key的地址值是否相等
3)key != null && key.equals(k):能够执行到这里说明两个key的地址值不相等,那么先判断后添加的key是否等于null,如果不等于null再调用equals方法判断两个key的内容是否相等
//把首节点与后面的for分离是为了拿到
*/
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))){//k为该链表的key
e = p;//将旧的元素整体对象赋值给e,用e来记录
}else if (p instanceof TreeNode)// key不同;判断p是否为红黑树结点
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {// 不是红黑树,说明是链表节点//不是首结点,往后遍历
/*
1)如果是链表的话需要遍历到最后节点然后插入
2)采用循环遍历的方式,判断链表中是否有重复的key
*/
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//说明到达该位置尾Node,没有重复key//p为当前结点,e为下一结点
p.next = newNode(hash, key, value, null);//传入Node的4个成员(hash,k,v,next)
//这里已经连接上了p e
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //bin为0时,e为第2个结点。所以bin为7时,e为第9个>8开始变成红黑树
//转换为红黑树//传入tab与队友的hash,就可知道位置
//treeifyBin()里不一定会把链表转成红黑树。如果长度小于64,会去调用resize。如果长度>=64,则会执行真正的红黑树变形
treeifyBin(tab, hash);
break;//到达了尾结点,结束for遍历"链表"
}//endif key==p.key//下面即!=
/*
执行到这里说明(e = p.next)!=null,且不是最后一个元素。继续判断链表中结点的key值与插入的元素的key值是否相等
*/
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
/*
要添加的元素和链表中的存在的元素的key相等了,则跳出for循环。不用再继续比较了
直接执行下面的if语句去替换去 if (e != null)
*/
break;
/*
说明新添加的元素和当前节点不相等,继续查找下一个节点。
用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
*/
p = e;//更新p为下一结点,for binCount++
}//end for
}//endif key等不等
/*
表示在桶中找到key值、hash值与插入元素相等的结点
也就是说通过上面的操作找到了重复的键,所以这里就是把该键的值变为新的值,并返回旧值
这里完成了put方法的修改功能
*/
if (e != null) { //e==null代表put是添加无需返回旧值。如果e!=null代表put是修改,需要返回旧值
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false(默认)或者旧值为null
if (!onlyIfAbsent || oldValue == null)//这里说明旧值可以为null
//用新值替换旧值
//e.value 表示旧值 value表示新值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}//endif tab[i]!=null
++modCount;//添加记录次数+1//修改不计入数量//结构性修改次数
// 判断实际大小是否大于threshold阈值,如果超过则扩容
if (++size > threshold)//第一次阈值为16,后面resize会操作。
resize();//扩容或者
// 插入后回调
afterNodeInsertion(evict);
return null;
}
JDK7 put():头插
//jdk7
public V put(K key, V value) {
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//key存在,覆盖旧值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
//key不存在,添加值
modCount++;
addEntry(hash, key, value, i);
return null;
}
//原来没有这个key,需要添加
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果元素的个数达到 threshold 的扩容阈值且数组下标位置已经存在元素,则进行扩容
if ((size++ >= threshold) && (null != table[bucketIndex])){
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
//1.7采用头插,对于链表,头插法快
void createEntry(int hash. K key, V value, int bucketIndex){
//不管原来的数组对应的下标是否为 null ,都作为 Entry 的 BucketIndex 的 next值
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
size++;
}
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h,K k,V v,Entry<K,V> n){//n为旧索引上结点
value=v;
next=n;//由此可见是头插
key=k;
hash=h;
}
}
static class Node<K,V> implements Map.Entry<K,V> {//JDK8
final int hash; // hash值,不可变
final K key; // 键,不可变
V value; // 值
Node<K,V> next; // 下一个节点
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;//由此可见是尾插
}
}
inal int hash(Object k) {
int h = hashSeed;//种子让更散列
h ^= k.hashCode();//相当于直接赋值h
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
treeifyBin()转红黑树
功能:将链表转换为红黑树
从哪里调用的这个函数:putVal()里判断添加节点后链表节点个数是否大于TREEIFY_THRESHOLD临界值8,如果大于则将链表转换为红黑树,调用 treeifyBin()。但是在它里面也不一定执行红黑树化,如果数组长度小于64,是进行resize的,而不是红黑树化。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//转换为红黑树 tab表示数组名 hash表示哈希值
treeifyBin(tab, hash);
树结点:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion //双向链表
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
...();//其他方法
}
treeifyBin方法如下所示:
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
替换指定哈希表的索引处桶中的所有链接节点,除非表太小,否则将修改大小。
Node[] tab = tab 数组名
int hash = hash表示哈希值
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//长度大于64才会树化,如果小于 64只会进行扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();//只是扩容tab[]
else if ((e = tab[index = (n - 1) & hash]) != null) {
/*
1)执行到这里说明哈希表中的数组长度大于阈值64,开始进行树形化
2)e = tab[index = (n - 1) & hash]表示将数组中的元素取出赋值给e
*/
//hd:红黑树的头结点head tl :红黑树的尾结点tail
TreeNode<K,V> hd = null, tl = null;
do {
//把链表的当前结点转成一个树结点。
TreeNode<K,V> p = replacementTreeNode(e, null);//如何转成红黑树:首先根据原来Node结点的顺序转成一个双向链表,即增加一个pre指针,然后再根据这个双向链表从上到下依次插入到一颗红黑树中,转成一棵树
if (tl == null)
//将新创键的p节点赋值给红黑树的头结点
hd = p;
else {
p.prev = tl;//将上一个节点p赋值给现在的p的前一个节点
tl.next = p;//将现在节点p作为树的尾结点的下一个节点
}
tl = p;
} while ((e = e.next) != null);//更新结点 且 判断是否继续查找
/*
让桶中的第一个元素即数组中的元素指向新建的红黑树的节点,以后这个桶里的元素就是红黑树
而不是链表数据结构了
*/
if ((tab[index] = hd) != null)
hd.treeify(tab);//在这里把双线链表转成红黑树
}
}
treeify():双向链表转成红黑树
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (root == null) {//第一个结点直接作为红黑树根节点
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;//key的class类型
for (TreeNode<K,V> p = root;;) {//遍历现有红黑树
int dir, ph;
K pk = p.key;//p是红黑树里的当前结点,x是我们要插入的结点
//要插入得先比较,但先比较的是哈希值,
if ((ph = p.hash) > h)//如果红黑树里当前结点p的哈希值大于要插入的结点x哈希值
dir = -1;//direction,往左子树查
else if (ph < h)//p的哈希值小于x的哈希值
dir = 1;//往右子树查
//等于
else if ((kc == null && (kc = comparableClassFor(k)) == null) ||
//如果kc为空就先赋值kc//如果该key实现了Comparable可进行比较,就返回Class对象。没实现就返回null //这里应该这是插入根节点的时候或的前半部分才为true,从第二个开始或语句的前半句就不满足了,直接执行或的后半句
(dir = compareComparables(kc, k, pk)) == 0)//前面只是比较哈希值,哈希值相对未必就key相等,所以进一步比较p的key和x的key,并且把结果给dir
//如果上面的dir==0满足,就进行插入,否则继续进行再查找
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {//看向左还是向右查找,更新红黑树的当前结点 //如果进入if,代表没有x对应的这个key值,要进行插入了
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;//先连接上,再调整
root = balanceInsertion(root, x);//当前结点插入到红黑树中
break;
}
}
}
}
moveRootToFront(tab, root);//把根节点赋值给HashMap的table[i]//树结点同时也是以链表形式存在的
//红黑树生成的过程中只是改变了left和right,而原来的next和prev还在,所以还是可以拿双线链表查出来原来后红黑树前的顺序的。我们的结点同时是链表里的一个结点,同时也是红黑树里的一个节点。
//但这里还是做了一些变化的,他让红黑树里根节点那个结点移动到了双向链表的头部,即单独单出来放到头部,其他结点再双向链表中的相对顺序不变,包括因拿出来根节点断掉的那个地方,也自动粘合拼接了。
}
resize()扩容
原理
1.什么时候才需要扩容
- 当前数组一个元素都没有的时候,初始长度为0,添加第一个元素后要改成16
- 当数组中的元素超过一定比例。当HashMap中的元素个数超过数组大小(数组长度)*loadFactor(负载因子)。loadFactor的默认值(DEFAULT_LOAD_FACTOR)是0.75。那么当HashMap中的元素个数超过16×0.75=12(这个值就是阈值或者边界值threshold值)的时候,就把数组的大小扩展为2×16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预知元素的个数能够有效的提高HashMap的性能。
- 当HashMap中的其中一个链表的对象个数如果达到了8个,此时如果数组长度没有达到64,那么HashMap会先扩容解决,如果已经达到了64,那么这个链表会变成红黑树,节点类型由Node变成TreeNode类型。当然,如果映射关系被移除后,下次执行resize方法时判断树的节点个数低于6,也会再把树转换为链表。
2.HashMap的扩容是什么
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
HashMap在进行扩容时,使用的rehash方式非常巧妙,因为每次扩容都是翻倍,与原来的数组长度n计算的 (n-1)&hash的结果相比,只是多了一个bit位,所以节点要么就在原来的位置,要么就被分配到"原位置+旧容量"这个位置。那么多的这一位怎么判断是0还是1呢?:e.hash & oldCap原容量,然后判断等不等于0即可。等0即新位是0,不等0即新位是1。
怎么理解呢?例如我们从16扩展为32时,具体的变化如下所示:
&(按位与运算):运算规则:相同的二进制数位上,都是1的时候,结果为1,否则为零。

n-1=15:0000 0000 0000 0000 0000 0000 000【0】 1111
hash1: 1111 1111 1111 1111 0000 1111 000【0】 0101
hash2: 1111 1111 1111 1111 0000 1111 000【1】 0101
(n-1)&hash
5 : 0000 0000 0000 0000 0000 0000 000【0】 0101
16 : 0000 0000 0000 0000 0000 0000 000【1】 0101
n=16 : 0000 0000 0000 0000 0000 0000 000【1】 0000
n & hash
5 : 0000 0000 0000 0000 0000 0000 000【0】 0000 ==0
16 : 0000 0000 0000 0000 0000 0000 000【1】 0000 !=0
因此元素在重新计算hash之后,因为n变为2倍,那么n-1的标记范围在高位多1bit(红色),因此新的index就会发生这样的变化:

说明:5是假设计算出来的原来的索引。这样就验证了上述所描述的:扩容之后所以节点要么就在原来的位置,要么就被分配到"原位置+旧容量"这个位置。
因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就可以了,是0的话索引没变,是1的话索引变成“原索引+oldCap(原位置+旧容量)”。为1还是为0可以通过这个式子判断:(e.hash & oldCap) == 0,代表为0。可以看看下图为16扩充为32的resize示意图:
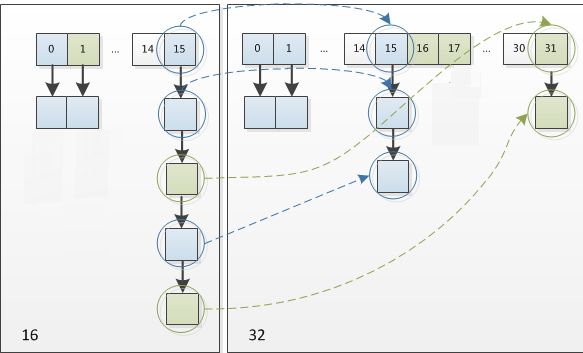
正是因为这样巧妙的rehash方式,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,在resize的过程中保证了rehash之后每个桶上的节点数一定小于等于原来桶上的节点数,保证了rehash之后不会出现更严重的hash冲突,均匀的把之前的冲突的节点分散到新的桶中了。
流程:
调用resize肯定是在求变,容量一定变化
- 拿到Node[] table,计算原来的数组长度oldCap
- if(oldCap>0),把阈值设置为oldCap<<1
- else(oldCap==0),设置容量为16,设置阈值为12
- if (oldTab != null)
- for(oldCap),循环每个坐标位置
- if ((e = oldTab[j]) != null),先清空原坐标位置的链表,原来链表拿e保存。
- if如果只有一个结点,直接计算该结点新的坐标
- elif如果是树结点,变形
- else如果是链表不只一个结点,构造两个链表,while原来的链表把结点重新定位到两个链表上。最后把两个链表接到坐标上。
- if ((e = oldTab[j]) != null),先清空原坐标位置的链表,原来链表拿e保存。
- for(oldCap),循环每个坐标位置
JDK8
//jdk8
final Node<K,V>[] resize() {
//得到当前数组
Node<K,V>[] oldTab = table;//Node[] table
//原容量:如果当前数组等于null长度返回0,否则返回当前数组的长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//当前阈值点 默认是12(16*0.75)
int oldThr = threshold;//容量为0时,threshold
//HashMap构造函数中有这么一句:this.threshold = tableSizeFor(initialCapacity);//即第一次扩容(包括0->16)前阈值==容量
int newCap, newThr = 0;//新的容量和阈值
//如果老的数组长度大于0,开始计算扩容后的大小
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {//2^30
//修改阈值为int的最大值
threshold = Integer.MAX_VALUE;
return oldTab;
}
/*
没超过最大值,就扩充为原来的2倍
1)(newCap = oldCap << 1) < MAXIMUM_CAPACITY 扩大到2倍之后容量要小于最大容量
2)oldCap >= DEFAULT_INITIAL_CAPACITY 原数组长度大于等于数组初始化长度16
*/
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//阈值扩大一倍
newThr = oldThr << 1; // double threshold
}
//老阈值点大于0 直接赋值
else if (oldThr > 0) // oldCap==0,老阈值赋值给新的数组长度
newCap = oldThr;
else {// oldCap==0 && oldThr==0,直接使用默认值16与0.75
newCap = DEFAULT_INITIAL_CAPACITY;//16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);//重新计算阈值16*0.75
}
// 计算新的resize最大上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//新的阈值 默认原来是12 乘以2之后变为24
threshold = newThr;
//创建新的哈希表
@SuppressWarnings({"rawtypes","unchecked"})
//newCap是新的数组长度--》32
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//创建空Node数组
table = newTab;
//判断旧数组是否等于空
if (oldTab != null) {//原来有值则复制到新Node数组里
// 把每个bucket都移动到新的buckets中
//遍历旧的哈希表的每个桶,重新计算桶里元素的新位置
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
//原来的数据赋值为null 便于GC回收
oldTab[j] = null;
//如果数组当前位置只有一个元素
if (e.next == null)
//没有下一个引用,说明不是链表,当前桶上只有一个键值对,直接插入
newTab[e.hash & (newCap - 1)] = e;
//判断是否是红黑树
else if (e instanceof TreeNode)
//说明是红黑树来处理冲突的,则调用相关方法把树分开
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 采用链表处理冲突
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
//通过上述讲解的原理来计算节点的新位置
do {
// 原索引//记录下个结点
next = e.next;
//这里来判断如果等于true e这个节点在resize之后不需要移动位置
if ((e.hash & oldCap) == 0) {// hash最高位为1
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;//更新尾节点
}
// 原索引+oldCap
else {//hash最高位为1
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到索引为j的bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到索引为j+oldCap的bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
JDK7
//jdk7
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {//扩容前的数组大小如果已经达到最大(2^30)了
threshold = Integer.MAX_VALUE;//修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
return;
}
Entry[] newTable = new Entry[newCapacity];//新Entry数组
transfer(newTable, initHashSeedAsNeeded(newCapacity));//转移数据
table = newTable; //这句要放在transfer之后
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);//修改阈值
}
void transfer(Entry[] newTable, boolean rehash) {//JDK7
//新table的容量
int newCapacity = newTable.length;
//遍历原table
for (Entry<K,V> e : table) {
while(null != e) {
//保存下一次循环的 EntryJDK7是一个一个resize转移过去,JDK8是先组成两个链表再贴上去
resize时线程安全问题
为什么线程不安全:https://blog.csdn.net/loveliness_peri/article/details/81092360
get()
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 数组元素相等
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶中不止一个节点
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
遍历map
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.print(key+" ");
}
Collection<String> values = map.values();
for (String value : values) {
System.out.print(value+" ");
}
Set<java.util.Map.Entry<String, String>> entrys = map.entrySet();
for (java.util.Map.Entry<String, String> entry : entrys) {
System.out.println(entry.getKey() + "--" + entry.getValue());
}
5 其他问题
容量问题
建议:如果我们确切的知道我们有多少键值对需要存储,那么我们在初始化HashMap的时候就应该指定它的容量,以防止HashMap自动扩容,影响使用效率。
默认情况下HashMap的容量是16,但是,如果用户通过构造函数指定了一个数字作为容量,那么Hash会选择大于该数字的第一个2的幂作为容量。(3->4、7->8、9->16) .这点我们在上述已经进行过讲解。
《阿里巴巴java开发手册》中建议我们设置HashMap的初始化容量。
10.【推荐】 集合初始化时,指定集合初始值大小。
说明:HashMap使用HashMap(int initialCapacacity)初始化
那么,为什么要这么建议?你有想过没有。
当然,以上建议也是有理论支撑的。我们上面介绍过,HashMap的扩容机制,就是当达到扩容条件时会进行扩容。HashMap的扩容条件就是当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。在HashMap中,threshold = loadFactor * capacity。
所以,如果我们没有设置初始容量大小,随着元素的不断增加,HashMap会有可能发生多次扩容,而HashMap中的扩容机制决定了每次扩容都需要重建hash表,是非常影响性能的。
容量多少合适?
在《阿里巴巴java开发手册》有以下建议:
正例:initialCapacity=(需要存储的元素个数/负载因子)+1。注意负载因子(即loader factor)默认为0.75
也就是说,如果我们设置的默认值是7,经过Jdk处理之后,会被设置成8,但是,这个HashMap在元素个数达到 8*0.75 = 6的时候就会进行一次扩容,这明显是我们不希望见到的。我们应该尽量减少扩容。原因也已经分析过。
如果我们通过initialCapacity/ 0.75F + 1.0F计算,7/0.75 + 1 = 10 ,10经过Jdk处理之后,会被设置成16,这就大大的减少了扩容的几率。
当HashMap内部维护的哈希表的容量达到75%时(默认情况下),会触发rehash,而rehash的过程是比较耗费时间的。所以初始化容量要设置成initialCapacity/0.75 + 1的话,可以有效的减少冲突也可以减小误差。
所以,我可以认为,当我们明确知道HashMap中元素的个数的时候,把默认容量设置成initialCapacity/ 0.75F + 1.0F是一个在性能上相对好的选择,但是,同时也会牺牲些内存。
我们想要在代码中创建一个HashMap的时候,如果我们已知这个Map中即将存放的元素个数,给HashMap设置初始容量可以在一定程度上提升效率。
但是,JDK并不会直接拿用户传进来的数字当做默认容量,而是会进行一番运算,最终得到一个2的幂。原因也已经分析过。
但是,为了最大程度的避免扩容带来的性能消耗,我们建议可以把默认容量的数字设置成initialCapacity/ 0.75F + 1.0F。
二 HashMap补充知识点
2.1 快速失败fail-fast
https://blog.csdn.net/zymx14/article/details/78394464
简介:fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件。例如:当某一个线程A通过 iterator 去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛 ConcurrentModificationException 异常,产生 fail-fast 事件
当然,不仅是多个线程,单个线程也会出现 fail-fast 机制,包括 ArrayList、HashMap 无论在单线程和多线程状态下,都会出现 fail-fast 机制,即上面提到的异常
先记住一句话:
刚开始得到迭代器时候会同步一下modCount 和expectedModCount ,每当next会先校验modCount 和expectedModCount 是否相等,而list.remove会修改modCount
①单线程fail-fast
1.1ArrayList发生fail-fast例子
public class ArrayListTest {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>();
arrayList.add(10);
arrayList.add(11);
Iterator<Integer> iterator = arrayList.iterator();
while (iterator.hasNext()) {
Integer next = iterator.next();
if (next == 11) {
arrayList.remove(next);//list的remove方法
}
}
}
}
/*
10
11
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:859)
at java.util.ArrayList$Itr.next(ArrayList.java:831)
at edu.just.failfast.ArrayListTest.main(ArrayListTest.java:15)
*/
从结果看出,在单线程下,在使用迭代器进行遍历的情况下,如果调用 ArrayList 的 remove 方法,此时会报 ConcurrentModificationException 的错误,从而产生 fail-fast 机制
错误信息告诉我们,发生在 iterator.next() 这一行,继续点进去,定位到 checkForComodification() 这一行
public E next() {//iterator.next()
checkForComodification();//这里会校验,报错在这
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
继续点进去,可以在 ArrayList 的 Itr 这个内部类中找到该方法的详细定义,这里涉及到两个变量,modCount 和 expectedModCount,modCount 是在 ArrayList 的父类 AbstractList 中进行定义的,初始值为 0,而 expectedModCount 则是在 ArrayList 的 内部类中进行定义的,在执行 arrayList.iterator() 的时候,首先会实例化 Itr 这个内部类,在实例化的同时也会对 expectedModCount 进行初始化,将 modCount 的值赋给 expectedModCount
AbstractList源码
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
// modCount 初始值为 0//抽象类的成员变量
protected transient int modCount = 0;
}
//ArrayList+Iterator源码
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
public Iterator<E> iterator() {//迭代器
// 实例化内部类 Itr
return new Itr();
}
/* An optimized version of AbstractList.Itr
*/
private class Itr implements Iterator<E> {
//即将遍历的元素的索引
int cursor; // index of next element to return
//刚刚遍历过的元素的索引。lastRet=cursor-1,默认为1,即不存在上一个时,为-1.
int lastRet = -1; // index of last element returned; -1 if no such//
//迭代器记录的修改次数,一般线程不共享
int expectedModCount = modCount;//初始赋值
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();//校验
int i = cursor;//当前要遍历的
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;//下个要遍历的
return (E) elementData[lastRet = i];//上个遍历的
}
public void remove() {
if (lastRet < 0)//没有遍历过
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
/*
可以看到,该remove方法并不会修改modCount的值,并且不会对后面的遍历造成影响,**因为该方法remove不能指定元素,只能remove当前遍历过的那个元素**,所以调用该方法并不会发生fail-fast现象。该方法有局限性。
*/
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
}
知道了这两个变量是从何而来之后,我们来看 checkForComodification() 这个方法,如果 modCount 和 expectedModCount 不等,就会抛出 ConcurrentModificationException 这个异常,换句话说,一般情况下,这两个变量是相等的,那么啥时候这两个变量会不等呢?
经过观察,发现 ArrayList 在增加、删除(根据对象删除集合元素)、清除等操作中,都有 modCount++ 这一步骤,即代表着,每次执行完相应的方法,modCount 这一变量就会加 1
public boolean add(E e) {//ArrayList
ensureCapacityInternal(size + 1); // modCount++
elementData[size++] = e;
return true;
}
// 根据传入的对象来删除,而不是根据位置
public boolean remove(Object o) {//ArrayList
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index); // modCount++
return true;
}
}
return false;
}
public void clear() {//ArrayList
modCount++;//++
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
分析到这儿,似乎有些明白了,我们来完整的分析一下整个过程,在没有执行删除操作之前,ArrayList 中的 modCount 变量和迭代器中的 expectedModCount 的值一直都是相同的。在迭代的过程中,调用了 ArrayList 的 remove(Object o) 方法,使得 ArrayList 的 modCount 这个变量发生变化(删除成功一次加1),一开始和 modCount 相等的 expectedModCount 是属于内部类的,它直到迭代结束都没能发生变化。在迭代器执行下一次迭代的时候,因为这两个变量不等,所以便会抛出 ConcurrentModificationException 异常,即产生了 fail-fast 异常
要点:modCount 共享,expectedModCount 不共享
1.2HashMap发生fail-fast:
public class HashMapTest {
public static void main(String[] args) {
HashMap<Integer, String> hashMap = new HashMap<>();
hashMap.put(1, "QQQ");
hashMap.put(2, "JJJ");
hashMap.put(3, "EEE");
Set<Map.Entry<Integer, String>> entries = hashMap.entrySet();
Iterator<Map.Entry<Integer, String>> iterator = entries.iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> next = iterator.next();
if (next.getKey() == 2) {
hashMap.remove(next.getKey());
}
}
System.out.println(hashMap);
}
}
/*
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextEntry(HashMap.java:922)
at java.util.HashMap$EntryIterator.next(HashMap.java:962)
at java.util.HashMap$EntryIterator.next(HashMap.java:960)
at edu.just.failfast.HashMapTest.main(HashMapTest.java:20)
*/
根据错误的提示,找到出错的位置,也是在 Map.Entry next = iterator.next() 这一行,继续寻找源头,定位到了 HashMap 中的内部类 EntryIterator 下的 next() 方法
private final class EntryIterator extends HashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}
继续往下找,来到了 HashMap 下的另一个私有内部类 HashIterator,该内部类也有 expectedModCount,modCount 是直接定义在 HashMap 中的,初始值为 0,expectedModCount 直接定义在 HashMap 的内部类中,当执行 arrayList.iterator() 这段代码的时候,便会初始化 HashIterator 这个内部类,同时调用构造函数 HashIterator(),将 modCount 的值赋给 expectedModCount
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
// 初始值为 0
transient int modCount;
// HashMap 的内部类 HashIterator
private abstract class HashIterator<E> implements Iterator<E> {
Entry<K,V> next; // next entry to return
// 期待改变的值,初始值为 0
int expectedModCount; // For fast-fail
int index; // current slot
Entry<K,V> current; // current entry
HashIterator() {
// expectedModCount 和 modCount 一样,初始值为 0
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
public final boolean hasNext() {
return next != null;
}
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
...
}
}
来看抛出异常的 nextEntry() 这个方法,只要 modCount 和 expectedModCount 不等,便会抛出 ConcurrentModificationException 这个异常,即产生 fast-fail 错误
同样,我们看一下 modCount 这个变量在 HashMap 的哪些方法中使用到了,和 ArrayList 类似,也是在添加、删除和清空等方法中,对 modCount 这个变量进行了加 1 操作
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 将 modCount 加 1
modCount++;
addEntry(hash, key, value, i);
return null;
}
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);//该方法里面,如果删除成功,则将 modCount 加 1
return (e == null ? null : e.value);
}
public void clear() {
// 将 modCount 加 1
modCount++;
Arrays.fill(table, null);
size = 0;
}
我们来捋一下整个过程,在对 HashMap 和 Iterator 进行初始化之后,没有执行 remove 方法之前,HashMap 中的 modCount 和内部类 HashIterator 中的 expectedModCount 一直是相同的。在 HashMap 调用 remove(Object key) 方法时,如果删除成功,则会将 modCount 这个变量加 1,而 expectedModCount 是在内部类中的,一直没有发生变化,当进行到下一次迭代的时候(执行 next 方法),因为 modCount 和 expectedModCount 不同,所以抛出 ConcurrentModificationException 这个异常
在 HashMap 添加了三个键不同的元素,且 Iterator 完成初始化之后,modCount 和 expectedModCount 的值都为 3,直到 HashMap 执行 remove(Object key) 方法,modCount 加 1 变成 4,而 expectedModCount 依然为 3,在下一次循环执行 next() 方法的时候,会检查这两个值,如果不同,则会抛出 ConcurrentModificationException 异常,即产生 fail-fast 机制
②多线程failt-fast
2.1ArrayList
public class ArrayListThreadTest {
public static void main(String[] args) throws InterruptedException {
final ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Thread thread = new Thread("线程1") {
@Override
public void run() {
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
Integer next = iterator.next();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程1: " + next);
}
}
};
Thread thread1 = new Thread("线程2") {
@Override
public void run() {
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
Integer next = iterator.next();
if (next == 2) {
iterator.remove();
}
System.out.println("线程2: " + next);
}
}
};
thread.start();
thread1.start();
}
}
/*
线程2: 1
线程2: 2
线程2: 3
线程2: 4
线程2: 5
线程1: 1
Exception in thread "线程1" java.util.ConcurrentModificationException
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:859)
at java.util.ArrayList$Itr.next(ArrayList.java:831)
at edu.just.failfast.ArrayListThreadTest$1.run(ArrayListThreadTest.java:21)
*/
同样,在 next 处,抛出了 ConcurrentModificationException 这个异常。
这里和单线程中不同的是,在删除的时候,调用的是 Iterator 对象的 remove() 方法,这是个内部类 Itr 中的方法。该内部类下的 remove 方法,其实还是调用 ArrayList 下的 remove(int index) 方法,但是,删除完之后,会将修改后的 modCount 赋值给 expectedModCount,相当于将这两个变量进行同步了
// ArrayList 中的内部类 Itr
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
// 将 modCount 赋给 expectedModCount
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
那么既然已经同步了,为什么还是会抛出这样的异常呢?通过输出的结果,大概可以分析出两个线程执行的流程
线程1先获得处理器的资源,进入运行状态,即执行 run() 方法里的代码,执行完 Iterator iterator = list.iterator() 这段代码之后,线程1因为执行了 sleep 方法,线程1进入阻塞状态
线程2获取处理器的资源,开始执行 run() 方法里面的代码,当迭代到 key 等于 2 的时候,执行 iterator.remove(),同时,ArrayList 下的 modCount 加 1,同时线程2迭代器下的 expectedModCount 的值和 modCount 一样,需要注意的是,modCount 是个共享的变量,即两个线程都可以同时对其进行操作,而 expectedModCount 则是各个线程各自拥有的,这一点很重要。最终,线程1下的 modCount 和 expectedModCount 都变成了 6
当线程2执行完毕,线程1重新获得处理器资源,开始执行,第一次循环没问题,第二次循环时,当执行到 Integer next = iterator.next() 的时候,因为共享变量 modCount 已经变成了 6,而线程 1 的 expectedModCount 依然是 5,两个变量不等,此时抛出 ConcurrentModificationException 异常,即产生 fail-fast 机制
简单的说,因为 modCount 是共享变量,expectedModCount 则是各自独有的变量,这就导致了,一个线程更新了 modCount,同时更新了自己拥有的 expectedModCount,当另一个线程执行的时候,发现 modCount 更新了,但是自己的 expectedModCount 并没有更新,便会产生这样的错误
2.2HashMap
public class HashMapThreadTest {
public static void main(String[] args) {
final HashMap<Integer, String> hashMap = new HashMap<>();
hashMap.put(1, "AAA");
hashMap.put(2, "BBB");
Thread thread = new Thread("线程1") {
@Override
public void run() {
Iterator<Map.Entry<Integer, String>> iterator = hashMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> next = iterator.next();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程1: " + next);
}
}
};
Thread thread1 = new Thread() {
@Override
public void run() {
Iterator<Map.Entry<Integer, String>> iterator = hashMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> next = iterator.next();
if (next.getKey() == 2) {
hashMap.remove(next.getKey());
}
System.out.println("线程2: " + next);
}
}
};
thread.start();
thread1.start();
}
}
/*
线程2: 1=AAA
线程2: 2=BBB
线程1: 1=AAA
Exception in thread "Thread-0" java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextEntry(HashMap.java:922)
at java.util.HashMap$EntryIterator.next(HashMap.java:962)
at java.util.HashMap$EntryIterator.next(HashMap.java:960)
at edu.just.failfast.HashMapThreadTest$1.run(HashMapThreadTest.java:19)
*/
HashMap 的过程和上面的 ArrayList 类似,因为 modCount 是共享变量,expectedModCount 是每个线程独有的变量,线程2的 HashMap 执行了 remove(),导致 modCount 和expectedModCount 同时加 1,而线程1的 expectedModCount 变量的值并没有修改,导致了 modCount 和 expectedModCount 这两个变量的值不同,因此抛出异常
③避免fail-fast
3.1对于单线程
对应单线程来说,我们执行删除操作的时候,不要使用集合自身的删除方法,而使用集合中迭代器的删除方法
因为无论是 ArrayList 还是 HashMap,他们对应的迭代器中的 remove 方法中,都有这么一句代码,expectedModCount = modCount,这就意味着,即使删除了,这两个变量也是一直同步的,不会发生 modCount 加 1,而 expectedModCount 不变的情况
3.2对于多线程
使用java并发包JUC(java.util.concurrent)中的类来代替ArrayList 和hashMap。
如使用 CopyOnWriterArrayList代替ArrayList,CopyOnWriterArrayList在是使用上跟ArrayList几乎一样,CopyOnWriter是写时复制的容器(COW),在读写时是线程安全的。该容器在对add和remove等操作时,并不是在原数组上进行修改,而是将原数组拷贝一份,在新数组上进行修改,待完成后,才将指向旧数组的引用指向新数组,所以对于CopyOnWriterArrayList在迭代过程并不会发生fail-fast现象。但 CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。
对于HashMap,可以使用ConcurrentHashMap,ConcurrentHashMap采用了锁机制,是线程安全的。在迭代方面,ConcurrentHashMap使用了一种不同的迭代方式。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据 ,iterator完成后再将头指针替换为新的数据 ,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变。即迭代不会发生fail-fast,但不保证获取的是最新的数据。
参考链接:
http://www.jb51.net/article/84468.htm
http://www.cnblogs.com/ccgjava/p/6347425.html
https://blog.csdn.net/babycan5/article/details/89004482
我们可以发现在put方法中modCount的增加有一个前提,就是只有在key不存在的情况下才会进行自增操作,在进行覆盖时并不会出现自增。也就是说,如果是覆盖HashMap中原有的key的话并不会触发ConcurrentModificationException。例如下面所示代码,在遍历中对Map进行了修改 但是并无异常抛出。
仔细分析不难发现唯一的区别在于key的覆盖并没有更改Map的结构。无论此key的存储方式是链表还是树,key的覆盖都只是简单的替换。遍历下去都可以正常的获取到所有值。但是涉及到Map结构修改的操作都有可能导致遍历无法遍历到所有值,因此才会触发ConcurrentModificationException。
2.2 红黑树
参考:https://mp.weixin.qq.com/s/X3zYwQXxq93P_XUzFmKluQ
插入和查询复杂度都是logn
2.2.1 五个特性
性质1:每个节点要么是黑色,要么是红色。
性质2:根节点是黑色。
性质3:每个叶子节点(NIL)是黑色。(空节点也是结点)
性质4:每个红色结点的两个子结点一定都是黑色。
性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
从性质5又可以推出:
- 性质5.1:如果一个结点存在黑子结点,那么该结点肯定有两个子结点
图1就是一颗简单的红黑树。其中Nil为叶子结点,并且它是黑色的。(值得提醒注意的是,在Java中,叶子结点是为null的结点。)

红黑树并不是一个 完美 平衡二叉查找树,从图1可以看到,根结点P的左子树显然比右子树高,但左子树和右子树的黑结点的层数是相等的,也即任意一个结点到到每个叶子结点的路径都包含数量相同的黑结点(性质5)。所以我们叫红黑树这种平衡为黑色完美平衡。
下面代码是java8中HashMap的内部类:红黑树TreeNode
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;//是否为红结点
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
}
介绍到此,为了后面讲解不至于混淆,我们还需要来约定下红黑树一些结点的叫法

我们把正在处理(遍历)的结点叫做当前结点,如图2中的D,它的父亲叫做父结点,它的父亲的另外一个子结点叫做兄弟结点,父亲的父亲叫做祖父结点。
前面讲到红黑树能自平衡,它靠的是什么?三种操作:左旋、右旋和变色。
- 左旋:以某个结点作为支点(旋转结点),其右子结点变为旋转结点的父结点,右子结点的左子结点变为旋转结点的右子结点,左子结点保持不变。如图3。
- 右旋:以某个结点作为支点(旋转结点),其左子结点变为旋转结点的父结点,左子结点的右子结点变为旋转结点的左子结点,右子结点保持不变。如图4。
- 变色:结点的颜色由红变黑或由黑变红。


我们先忽略颜色,可以看到旋转操作不会影响旋转结点的父结点,父结点以上的结构还是保持不变的。
左旋只影响旋转结点和其右子树的结构,把右子树的结点往左子树挪了。
右旋只影响旋转结点和其左子树的结构,把左子树的结点往右子树挪了。
所以旋转操作是局部的。另外可以看出旋转能保持红黑树平衡的一些端详了:当一边子树的结点少了,那么向另外一边子树“借”一些结点;当一边子树的结点多了,那么向另外一边子树“租”一些结点。
但要保持红黑树的性质,结点不能乱挪,还得靠变色了。怎么变?具体情景又不同变法,后面会具体讲到,现在只需要记住红黑树总是通过旋转和变色达到自平衡。
balabala了这么多,相信你对红黑树有一定印象了,那么现在来考考你:
*思考题1:黑结点可以同时包含一个红子结点和一个黑子结点吗?* (答案见文末)
2.2.2 红黑树查找
因为红黑树是一颗二叉平衡树,并且查找不会破坏树的平衡,所以查找跟二叉平衡树的查找无异:
- 从根结点开始查找,把根结点设置为当前结点;
- 若当前结点为空,返回null;
- 若当前结点不为空,用当前结点的key跟查找key作比较;
- 若当前结点key等于查找key,那么该key就是查找目标,返回当前结点;
- 若当前结点key大于查找key,把当前结点的左子结点设置为当前结点,重复步骤2;
- 若当前结点key小于查找key,把当前结点的右子结点设置为当前结点,重复步骤2;
如图5所示。

图5 二叉树查找流程图
非常简单,但简单不代表它效率不好。正由于红黑树总保持黑色完美平衡,所以它的查找最坏时间复杂度为O(2lgN),也即整颗树刚好红黑相隔的时候。能有这么好的查找效率得益于红黑树自平衡的特性,而这背后的付出,红黑树的插入操作功不可没~
2.2.3 红黑树插入
插入操作包括两部分工作:一查找插入的位置;二插入后自平衡。查找插入的父结点很简单,跟查找操作区别不大:
找到插入位置没什么好讲的。
插入位置已经找到,把插入结点放到正确的位置就可以啦,但插入结点是应该是什么颜色呢?答案是红色。理由很简单,红色在父结点(如果存在)为黑色结点时,红黑树的黑色平衡没被破坏,不需要做自平衡操作。但如果插入结点是黑色,那么插入位置所在的子树黑色结点总是多1,必须做自平衡。
我的思路
思路:插入的结点为红色,因为红黑树是黑色节点要求严格。
尽管网上有很多插入的方法,但是我还是希望看我的文章的能以下面的方式记忆,因为我觉得我的方法你理解了后红容易记,在这里我只简写几个分类,至于他们代表什么意思,希望你看完下面5个局面后再看看我为什么这么简写,然后如果你觉得我的分类很好的话,我希望收获你的掌声
- ① 根节点,很简单,不需要特殊记
- ② 父节点是黑色,我们直接插入红色节点即可,也没什么需要特殊记的,这里还没凸显我所提的优势。下面我开始讲我的简写
- ③ 3红情况:即新结点,父节点,叔叔结点都是红色。新结点没什么好说的,因为本来就是红的,这是新结点的初始颜色。父和叔是同一层的结点,那同时变色也无所谓了。而祖父结点变色也无所谓,因为祖父代表的是一个子树。这里的无所谓指的是父节点和叔结点的红色与祖父结点的黑色调换下无所谓,调换完还是满足性质的,而又满足了我们插入新结点后的要求。
- ④ 2红右左:即新结点和父节点是红色,简写里不提的叔叔结点说明他不是红色,即他可以不存在,也可以是黑色,但就是不能是红色,因为我们的简写是2红。此外还有要求,“右”指的是新结点是父节点的右树,“左”指的是父结点是祖父结点的左树。这里写的右左是由顺序的,是从子代到祖代的顺序的。“左”不要理解为父节点是叔结点的左树,没有这个逻辑。我们要做的是让第二个"左"旋成2红右右的情况,结合后面的图比较好理解些。旋完后进入的是逻辑⑤
- ⑤ 2红左左:即新结点和父节点是红色,“1左”指的是新结点是父节点的左树,“2左”指的是父结点是祖父结点的左树。好了,简写意思说明白了,那怎么处理呢?想想平衡树我们为什么左旋/右旋,因为一个分支高度高太多了,扁担很不平衡了,所以你挑扁担的中心点就往树高的那边挪,即我们要把树高那边的结点作为新的子树根节点。这其实没什么好讲的,有平衡树的知识很容易理解,定语有些多,但我觉得是准确的。左为根节点后的处理我希望你结合图再想想接下来怎么做,我觉得只要你静下心来想,你自己都能想出来。原来子树根节点是黑的,右面有个黑的,现在把原来的根节点挪到右面了,那再从右面给挪回根节点不就好了。挪完发现,又符合红黑树要求了。
- 还有一个镜像的问题,下面看完一遍就明白了。还有一个向上再调整的问题,看完练习1就明白了。
这就是我的思路,希望提供给你另外一种想法,如果觉得不适合你,那希望你能总结你自己的,反正我是记住了。这个思路不仅仅是为了解释,同时JDK8的HashMap也是这个顺序分析的,个人认为把我的思路看完后代码大概瞅一眼后就知道他怎么写的了
**局面1:**新结点(A)位于树根,没有父结点。
(空心三角形代表结点下面的子树)
这种局面,直接让新结点变色为黑色,规则2得到满足。同时,黑色的根结点使得每条路径上的黑色结点数目都增加了1,所以并没有打破规则5。
**局面2:**新结点(B)的父结点是黑色。
这种局面,新插入的红色结点B并没有打破红黑树的规则,所以不需要做任何调整。
**局面3:**新结点(D)的父结点和叔叔结点都是红色。(3红)

这种局面,两个红色结点B和D连续,违反了规则4。因此我们先让结点B变为黑色:

这样一来,结点B所在路径凭空多了一个黑色结点,打破了规则5。因此我们让结点A变为红色:
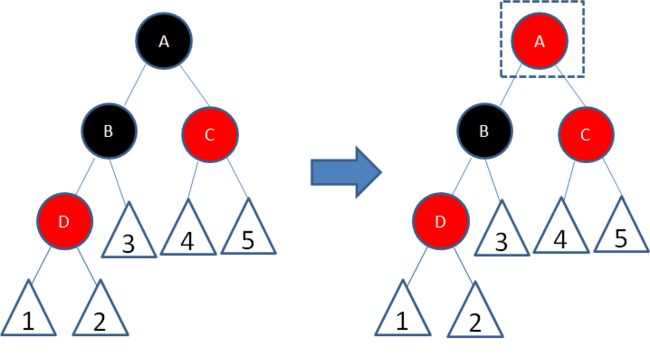
这时候,结点A和C又成为了连续的红色结点,我们再让结点C变为黑色:
经过上面的调整,这一局部重新符合了红黑树的规则。
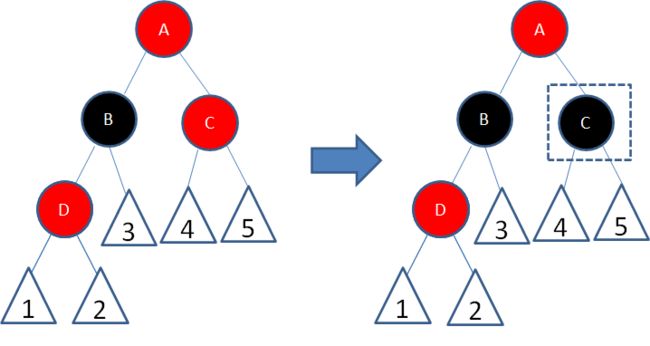
局面4:2红右左
解释:新结点(D)的父结点是红色,叔叔结点是黑色或者没有叔叔,且新结点是父结点的右孩子,父结点(B)是祖父结点的左孩子。(2红右左)
新节点红,父节点红,叔节点黑/无,新节点为父节点右树,父节点为祖父节点左树。
我们以结点B为轴,做一次左旋转,使得新结点D成为父结点,原来的父结点B成为D的左孩子:

这样一来,进入了局面5。
**局面5:**2红左左
解释:新结点(D)的父结点是红色,叔叔结点是黑色或者没有叔叔,且新结点是父结点的左孩子,父结点(B)是祖父结点的左孩子。
新节点红,父节点红,叔叔黑/无,新节点为父节点左树,父节点为祖父节点左树。
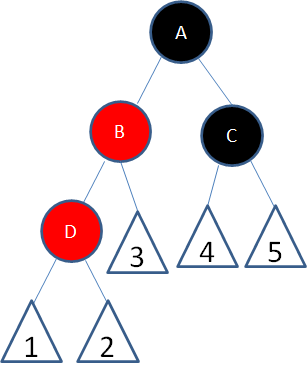
我们以结点A为轴,做一次右旋转,使得结点B成为祖父结点,结点A成为结点B的右孩子:
接下来,我们让结点B变为黑色,结点A变为红色:
经过上面的调整,这一局部重新符合了红黑树的规则。
以上就是红黑树插入操作所涉及的5种局面。
或许有人会问,如果局面4和局面5当中的父结点B是祖父结点A的右孩子该怎么办呢?
很简单,如果局面4中的父结点B是右孩子,则成为了局面5的镜像,原本的右旋操作改为左旋;如果局面5中的父结点B是右孩子,则成为了局面4的镜像,原本的左旋操作改为右旋。
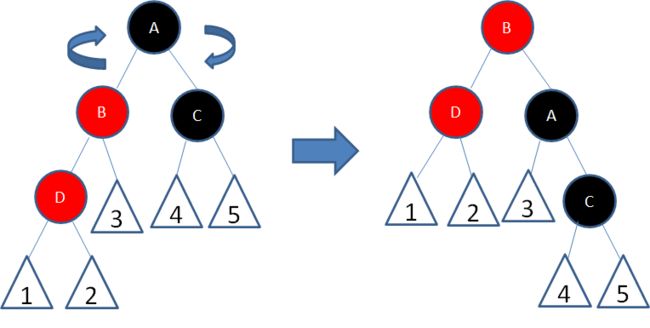
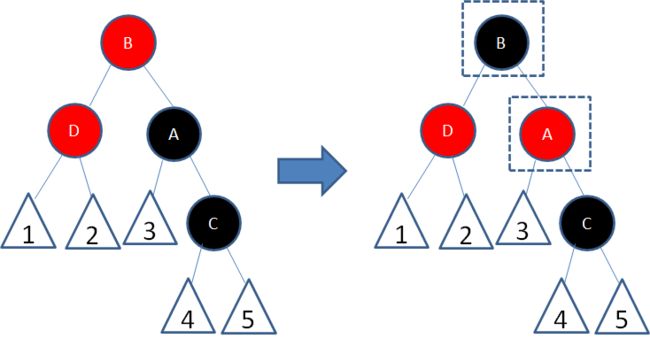
练习1
给定下面这颗红黑树,新插入的结点是21:
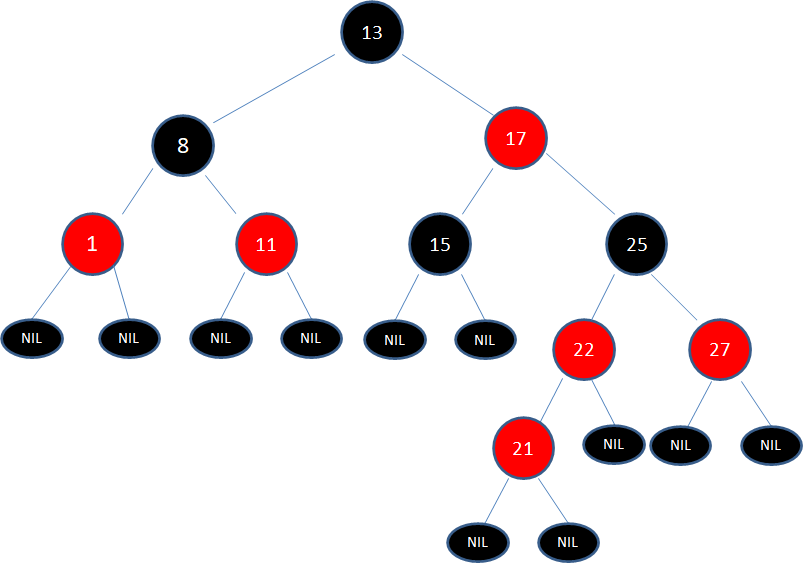
显然,新结点21和它的父结点22是连续的红色结点,违背了规则4,我们应该如何调整呢?
让我们回顾一下刚才讲的5种局面,当前的情况符合局面3:
”新结点的父结点和叔叔结点都是红色。“
于是我们经过三次变色,22变为黑色,25变为红色,27变为黑色:
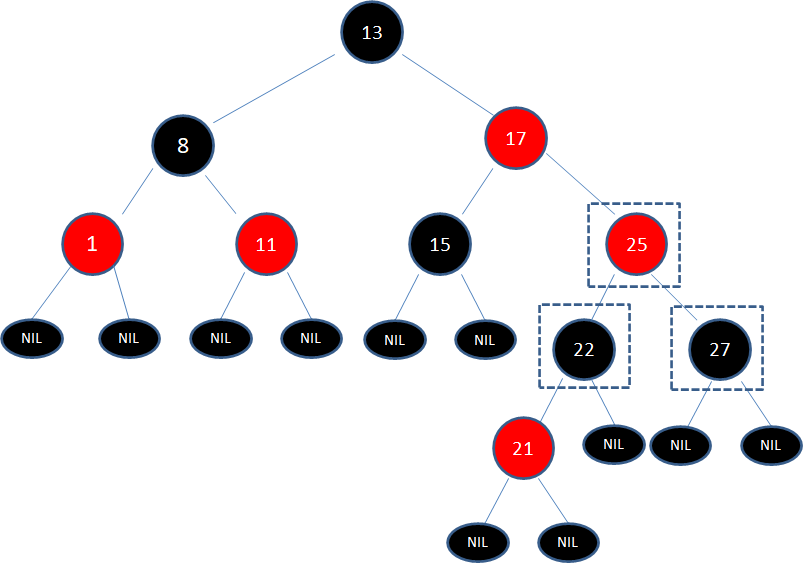
经过上面的调整,以结点25为根的子树符合了红黑树规则,但结点25和结点17成为了连续的红色结点,违背规则4。
于是,我们把结点25看做一个新结点,正好符合局面5的镜像:
“新结点的父结点是红色,叔叔结点是黑色或者没有叔叔,且新结点是父结点的右孩子,父结点是祖父结点的右孩子”
于是我们以根结点17为轴进行左旋转,使得结点17成为了新的根结点:
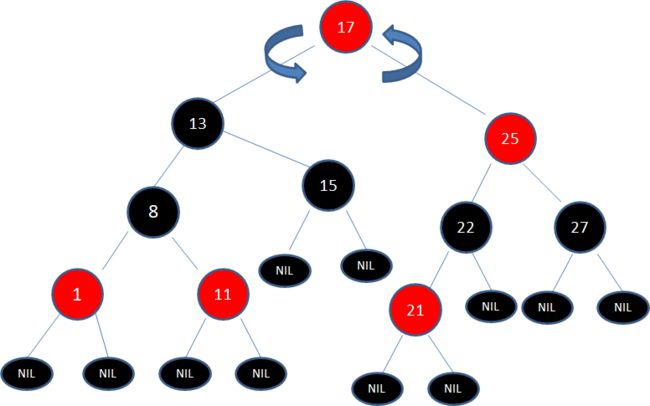
接下来,让结点17变为黑色,结点13变为红色:
如此一来,我们的红黑树变得重新符合规则。
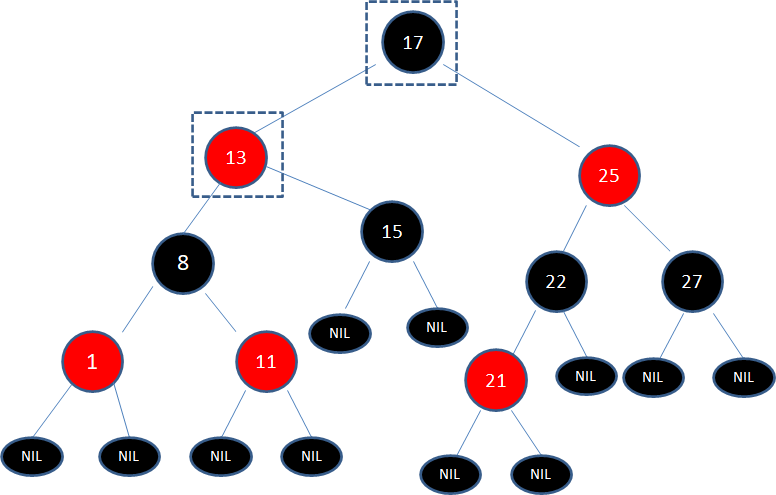
*习题1:请画出图15的插入自平衡处理过程。*(答案见文末)
2.2.4 红黑树删除
红黑树插入已经够复杂了,但删除更复杂,也是红黑树最复杂的操作了。但稳住,胜利的曙光就在前面了!
红黑树的删除操作也包括两部分工作:一查找目标结点;而删除后自平衡。查找目标结点显然可以复用查找操作,当不存在目标结点时,忽略本次操作;当存在目标结点时,删除后就得做自平衡处理了。删除了结点后我们还需要找结点来替代删除结点的位置,不然子树跟父辈结点断开了,除非删除结点刚好没子结点,那么就不需要替代。
二叉树删除结点找替代结点有3种情情景:
- 情景1:若删除结点无子结点,直接删除
- 情景2:若删除结点只有一个子结点,用子结点替换删除结点
- 情景3:若删除结点有两个子结点,用后继结点(大于删除结点的最小结点)替换删除结点
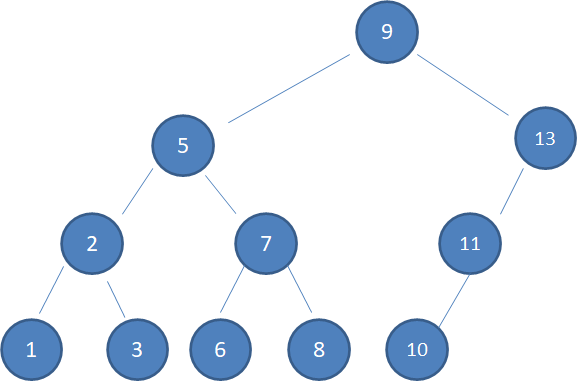
情况1,待删除的结点没有子结点:

上图中,待删除的结点12是叶子结点,没有孩子,因此直接删除即可:
情况2,待删除的结点有一个孩子:
上图中,待删除的结点13只有左孩子,于是我们让左孩子结点11取代被删除的结点,结点11以下的结点关系无需变动:
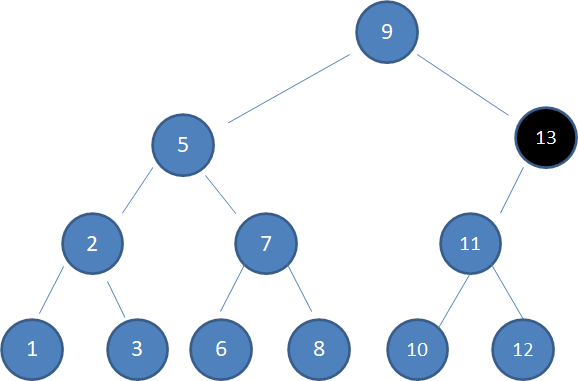
情况3,待删除的结点有两个孩子:

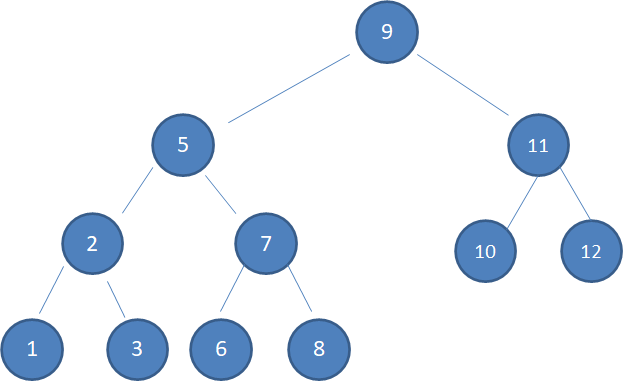
上图中,待删除的结点5有两个孩子,这种情况比较复杂。此时,我们需要选择与待删除结点最接近的结点来取代它。
上面的例子中,结点3仅小于结点5,结点6仅大于结点5,两者都是合适的选择。但习惯上我们选择仅大于待删除结点的结点,也就是结点6来取代它。
于是我们复制结点6到原来结点5的位置:
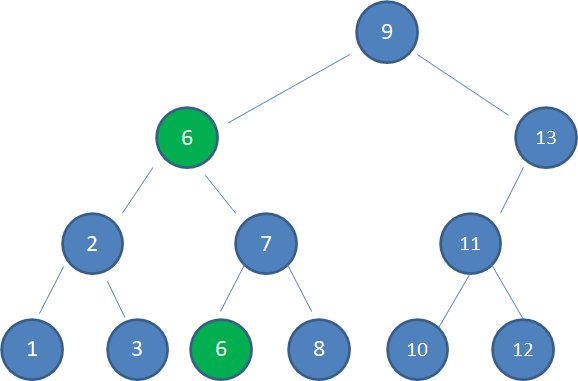
被选中的结点6,仅大于结点5,因此一定没有左孩子。所以我们按照情况1或情况2的方式,删除多余的结点6:
补充说明下,情景3的后继结点是大于删除结点的最小结点,也是删除结点的右子树种最左结点。那么可以拿前继结点(删除结点的左子树最右结点)替代吗?可以的。但习惯上大多都是拿后继结点来替代,后文的讲解也是用后继结点来替代。另外告诉大家一种找前继和后继结点的直观的方法(不知为何没人提过,大家都知道?):把二叉树所有结点投射在X轴上,所有结点都是从左到右排好序的,所有目标结点的前后结点就是对应前继和后继结点。如图16所示。

图16 二叉树投射x轴后有序
接下来,讲一个重要的思路:**删除结点被替代后,在不考虑结点的键值的情况下,对于树来说,可以认为删除的是替代结点!**话很苍白,我们看图17。在不看键值对的情况下,图17的红黑树最终结果是删除了Q所在位置的结点!这种思路非常重要,大大简化了后文讲解红黑树删除的情景!

图17 删除结点换位思路
基于此,上面所说的3种二叉树的删除情景可以相互转换并且最终都是转换为情景1!
- 情景2:删除结点用其唯一的子结点替换,子结点替换为删除结点后,可以认为删除的是子结点,若子结点又有两个子结点,那么相当于转换为情景3,一直自顶向下转换,总是能转换为情景1。(对于红黑树来说,根据性质5.1,只存在一个子结点的结点肯定在树末了)
- 情景3:删除结点用后继结点(肯定不存在左结点),如果后继结点有右子结点,那么相当于转换为情景2,否则转为为情景1。
二叉树删除结点情景关系图如图18所示。

图18 二叉树删除情景转换
综上所述,**删除操作删除的结点可以看作删除替代结点,而替代结点最后总是在树末。**有了这结论,我们讨论的删除红黑树的情景就少了很多,因为我们只考虑删除树末结点的情景了。
同样的,我们也是先来总体看下删除操作的所有情景,如图19所示。
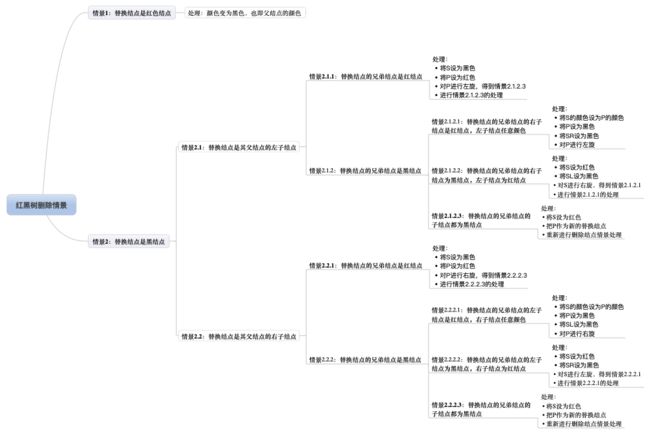
图19 红黑树删除情景
哈哈,是的,即使简化了还是有9种情景!但跟插入操作一样,存在左右对称的情景,只是方向变了,没有本质区别。同样的,我们还是来约定下,如图20所示。
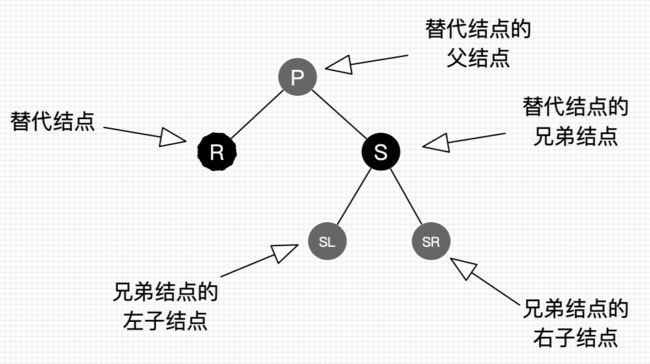
图20 删除操作结点的叫法约定
图20的字母并不代表结点Key的大小。R表示替代结点,P表示替代结点的父结点,S表示替代结点的兄弟结点,SL表示兄弟结点的左子结点,SR表示兄弟结点的右子结点。灰色结点表示它可以是红色也可以是黑色。
值得特别提醒的是,R是即将被替换到删除结点的位置的替代结点,在删除前,它还在原来所在位置参与树的子平衡,平衡后再替换到删除结点的位置,才算删除完成。
万事具备,我们进入最后的也是最难的讲解。
删除情景1:替换结点是红色结点
我们把替换结点换到了删除结点的位置时,由于替换结点时红色,删除也了不会影响红黑树的平衡,只要把替换结点的颜色设为删除的结点的颜色即可重新平衡。
处理:颜色变为删除结点的颜色
删除情景2:替换结点是黑结点
当替换结点是黑色时,我们就不得不进行自平衡处理了。我们必须还得考虑替换结点是其父结点的左子结点还是右子结点,来做不同的旋转操作,使树重新平衡。
删除情景2.1:替换结点是其父结点的左子结点
删除情景2.1.1:替换结点的兄弟结点是红结点
若兄弟结点是红结点,那么根据性质4,兄弟结点的父结点和子结点肯定为黑色,不会有其他子情景,我们按图21处理,得到删除情景2.1.2.3(后续讲解,这里先记住,此时R仍然是替代结点,它的新的兄弟结点SL和兄弟结点的子结点都是黑色)。
处理:
- 将S设为黑色
- 将P设为红色
- 对P进行左旋,得到情景2.1.2.3
- 进行情景2.1.2.3的处理

图21 删除情景2.1.1
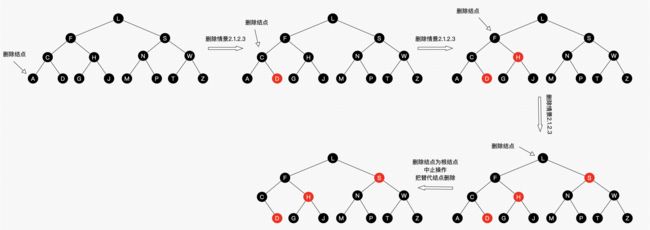
删除情景2.1.2:替换结点的兄弟结点是黑结点
当兄弟结点为黑时,其父结点和子结点的具体颜色也无法确定(如果也不考虑自底向上的情况,子结点非红即为叶子结点Nil,Nil结点为黑结点),此时又得考虑多种子情景。
删除情景2.1.2.1:替换结点的兄弟结点的右子结点是红结点,左子结点任意颜色
即将删除的左子树的一个黑色结点,显然左子树的黑色结点少1了,然而右子树又又红色结点,那么我们直接向右子树“借”个红结点来补充黑结点就好啦,此时肯定需要用旋转处理了。如图22所示。
处理:
- 将S的颜色设为P的颜色
- 将P设为黑色
- 将SR设为黑色
- 对P进行左旋

图22 删除情景2.1.2.1
平衡后的图怎么不满足红黑树的性质?前文提醒过,R是即将替换的,它还参与树的自平衡,平衡后再替换到删除结点的位置,所以R最终可以看作是删除的。另外图2.1.2.1是考虑到第一次替换和自底向上处理的情况,如果只考虑第一次替换的情况,根据红黑树性质,SL肯定是红色或为Nil,所以最终结果树是平衡的。如果是自底向上处理的情况,同样,每棵子树都保持平衡状态,最终整棵树肯定是平衡的。后续的情景同理,不做过多说明了。
删除情景2.1.2.2:替换结点的兄弟结点的右子结点为黑结点,左子结点为红结点
兄弟结点所在的子树有红结点,我们总是可以向兄弟子树借个红结点过来,显然该情景可以转换为情景2.1.2.1。图如23所示。
处理:
- 将S设为红色
- 将SL设为黑色
- 对S进行右旋,得到情景2.1.2.1
- 进行情景2.1.2.1的处理
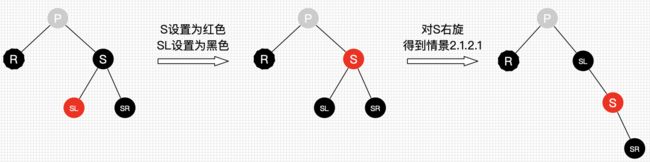
图23 删除情景2.1.2.2
删除情景2.1.2.3:替换结点的兄弟结点的子结点都为黑结点
好了,此次兄弟子树都没红结点“借”了,兄弟帮忙不了,找父母呗,这种情景我们把兄弟结点设为红色,再把父结点当作替代结点,自底向上处理,去找父结点的兄弟结点去“借”。但为什么需要把兄弟结点设为红色呢?显然是为了在P所在的子树中保证平衡(R即将删除,少了一个黑色结点,子树也需要少一个),后续的平衡工作交给父辈们考虑了,还是那句,当每棵子树都保持平衡时,最终整棵总是平衡的。
处理:
- 将S设为红色
- 把P作为新的替换结点
- 重新进行删除结点情景处理

图24 情景2.1.2.3
删除情景2.2:替换结点是其父结点的右子结点
好啦,右边的操作也是方向相反,不做过多说明了,相信理解了删除情景2.1后,肯定可以理解2.2。
删除情景2.2.1:替换结点的兄弟结点是红结点
处理:
- 将S设为黑色
- 将P设为红色
- 对P进行右旋,得到情景2.2.2.3
- 进行情景2.2.2.3的处理

图25 删除情景2.2.1
删除情景2.2.2:替换结点的兄弟结点是黑结点
删除情景2.2.2.1:替换结点的兄弟结点的左子结点是红结点,右子结点任意颜色
处理:
- 将S的颜色设为P的颜色
- 将P设为黑色
- 将SL设为黑色
- 对P进行右旋

图26 删除情景2.2.2.1
删除情景2.2.2.2:替换结点的兄弟结点的左子结点为黑结点,右子结点为红结点
处理:
- 将S设为红色
- 将SR设为黑色
- 对S进行左旋,得到情景2.2.2.1
- 进行情景2.2.2.1的处理
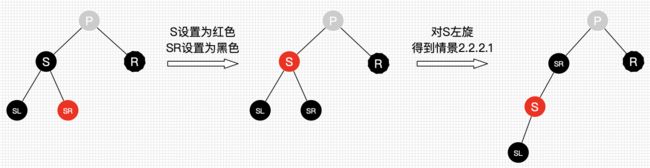
图27 删除情景2.2.2.2
删除情景2.2.2.3:替换结点的兄弟结点的子结点都为黑结点
处理:
- 将S设为红色
- 把P作为新的替换结点
- 重新进行删除结点情景处理
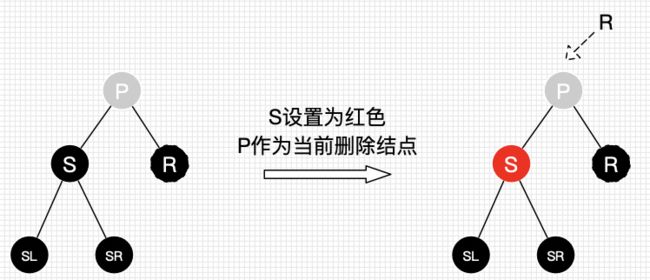
图28 删除情景2.2.2.3
综上,红黑树删除后自平衡的处理可以总结为:
- 自己能搞定的自消化(情景1)
- 自己不能搞定的叫兄弟帮忙(除了情景1、情景2.1.2.3和情景2.2.2.3)
- 兄弟都帮忙不了的,通过父母,找远方亲戚(情景2.1.2.3和情景2.2.2.3)
哈哈,是不是跟现实中很像,当我们有困难时,首先先自己解决,自己无力了总兄弟姐妹帮忙,如果连兄弟姐妹都帮不上,再去找远方的亲戚了。这里记忆应该会好记点~
最后再做个习题加深理解(请不熟悉的同学务必动手画下):
***习题2:请画出图29的删除自平衡处理过程。
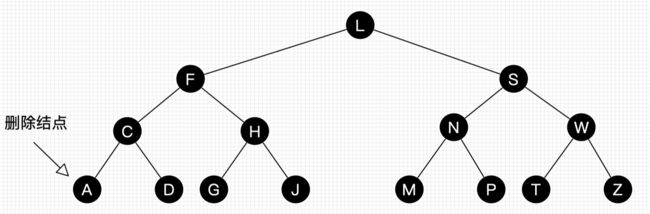
思考题和习题答案
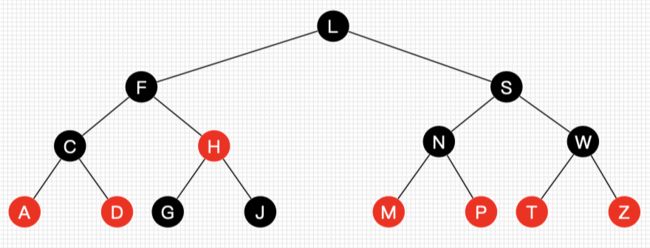
思考题1:黑结点可以同时包含一个红子结点和一个黑子结点吗?
答:可以。如下图的F结点:
习题1:请画出图15的插入自平衡处理过程。
答:
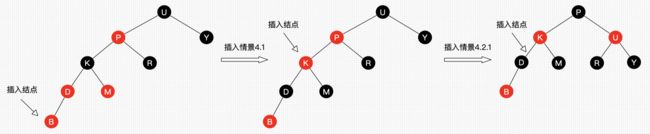
习题2:请画出图29的删除自平衡处理过程。
答:
2.2.5 JDK8中的 红黑树
JDK8中的hashMap的红黑树代码在这个地方解读。
JDK8 HashMap前情回顾:put()–调用–putVal()—对应索引位置是红黑树的话,调用e = ((TreeNode
putTreeVal() put红黑树
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
balanceInsertion()红黑树插入代码
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
x.red = true;//插入的结点直接给红色
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {//为什么要for:因为调整完子树后可能导致上面的红黑树失衡,需要向上调整
//变量解释:p:parent
//xp:父节点
//xpp:祖父
// xppl:左面的叔结点(值得是xpp的left左结点,而不是xpp左面的兄弟结点)
// xppr:右面的叔结点
if ((xp = x.parent) == null) {//局面1:作为根节点
x.red = false;
return x;
}
else if (!xp.red || (xpp = xp.parent) == null)//局面2:父黑//或指的是原来只有一个黑结点,没有第2个结点了
return root;
//走到这里代表父节点是红色的
if (xp == (xppl = xpp.left)) { //父节点是祖父结点的左结点
if ((xppr = xpp.right) != null && xppr.red) {//局面3:3红
xppr.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {//叔结点为空和叔结点为黑都会走到这里
if (x == xp.right) {//2红右左//局面4
root = rotateLeft(root, x = xp);//先左旋
xpp = (xp = x.parent) == null ? null : xp.parent;
}//局面4还没处理完,转成局面5了,扔给局面5处理
if (xp != null) {//2红左左//局面5
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);//右旋
}
}
}
}
else { //父节点是祖父结点的右结点
if (xppl != null && xppl.red) { //局面3:3红
xppl.red = false;
xp.red = false;
xpp.red = true;
x = xpp;
}
else {//叔结点为空和叔结点为黑都会走到这里
if (x == xp.left) { //2红左右 //局面4的镜像
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}//局面4(的镜像)还没处理完,转成局面5(的镜像)了,扔给局面5(的镜像)处理
if (xp != null) {//2红右右//局面5的镜像
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
balanceDeletion()红黑树删除代码
static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root,
TreeNode<K,V> x) {
for (TreeNode<K,V> xp, xpl, xpr;;) {
if (x == null || x == root)
return root;
else if ((xp = x.parent) == null) {
x.red = false;
return x;
}
else if (x.red) {
x.red = false;
return root;
}
else if ((xpl = xp.left) == x) {
if ((xpr = xp.right) != null && xpr.red) {
xpr.red = false;
xp.red = true;
root = rotateLeft(root, xp);
xpr = (xp = x.parent) == null ? null : xp.right;
}
if (xpr == null)
x = xp;
else {
TreeNode<K,V> sl = xpr.left, sr = xpr.right;
if ((sr == null || !sr.red) &&
(sl == null || !sl.red)) {
xpr.red = true;
x = xp;
}
else {
if (sr == null || !sr.red) {
if (sl != null)
sl.red = false;
xpr.red = true;
root = rotateRight(root, xpr);
xpr = (xp = x.parent) == null ?
null : xp.right;
}
if (xpr != null) {
xpr.red = (xp == null) ? false : xp.red;
if ((sr = xpr.right) != null)
sr.red = false;
}
if (xp != null) {
xp.red = false;
root = rotateLeft(root, xp);
}
x = root;
}
}
}
else { // symmetric
if (xpl != null && xpl.red) {
xpl.red = false;
xp.red = true;
root = rotateRight(root, xp);
xpl = (xp = x.parent) == null ? null : xp.left;
}
if (xpl == null)
x = xp;
else {
TreeNode<K,V> sl = xpl.left, sr = xpl.right;
if ((sl == null || !sl.red) &&
(sr == null || !sr.red)) {
xpl.red = true;
x = xp;
}
else {
if (sl == null || !sl.red) {
if (sr != null)
sr.red = false;
xpl.red = true;
root = rotateLeft(root, xpl);
xpl = (xp = x.parent) == null ?
null : xp.left;
}
if (xpl != null) {
xpl.red = (xp == null) ? false : xp.red;
if ((sl = xpl.left) != null)
sl.red = false;
}
if (xp != null) {
xp.red = false;
root = rotateRight(root, xp);
}
x = root;
}
}
}
}
}
三 ConcurrentHashMap
我们先了解HashTable的做法:
//直接在方法上加synchronized锁住this,这样效率很低
public synchronized V put(k key,V value){}//效率低//put不同索引的时候是没有线程安全的,但也是得等待
3.1 JDK1.7
3.1.1 属性:
Segments[] segments
ConcurrentHashMap:有个Segment
每个segment[i]维护一个HashEntry,初始容量指的是table的大小
HashEntry[] table
每个ConcurrentHashMap下有一个Segments[]数组,数组的每一个元素Segments[i]下面有一个table[]数组,每个元素table[i]下有一个链表。因为java中只要一个对象有next指针,那么这个对象代码的也是一个链表。所以table[i]对应的是一个HashEntry元素,同时也是一个链表
3.1.2 方法
ConcurrentHashMap(无参)
public ConcurrentHashMap(){
return this(DEFAULT_INITIAL_CAPACITY,//segment[].length×table[].length,每个table大小为segment[i]=DEFAULT_INITIAL_CAPACITY/DEFAULT_CONCURRENCY_LEVEL
DEFAULT_LOAD_FACTOR,
DEFAULT_CONCURRENCY_LEVEL)//并发级别,segment[]数组长度//segments也是2的幂
}
ConcurrentHashMap(有参)
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)//1^16
concurrencyLevel = MAX_SEGMENTS;//最大并发级别
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;//sigment Size
while (ssize < concurrencyLevel) {//如果并发级别输入的是15,那么我们就可以通过while转成16
++sshift;//移位次数
ssize <<= 1;
}//用ssize表示并发级别,肯定为2的幂
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;//并发级别-1,掩码,即1111..用作位运算
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;//总共节点数//1^30
int c = initialCapacity / ssize;//c=segment[i]下链表长度
if (c * ssize < initialCapacity)//上面有余数造成的
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;//2链表长度至少2
while (cap < c)
cap <<= 1;//我们后面用的是cap,而不是c。即链表长度最少为2
// create segments and segments[0] 先创建数组和索引0
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);//cap先只用于s0 //segment[0]
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];//创建Segments[]
UNSAFE.putOrderedObject(ss, SBASE, s0); // segments[0]=s0
this.segments = ss;
}
扩容是扩segment[i] tab,先吼
别的地方刚开始都是空的,要放的时候先new ,如果没有s0,那么每个地方都需要除一下,很麻烦,根据s0 就可以快速算出来。原型。
不够了rehash
Concurrent.put()
首先了解ConcurrentHashMap类中有如下的关于unsafe的逻辑,对Unsafe类一点不了解的同学去后面先了解下Unsafe
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class tc = HashEntry[].class;//segment[i]
Class sc = Segment[].class;//并发数组
TBASE = UNSAFE.arrayBaseOffset(tc);
SBASE = UNSAFE.arrayBaseOffset(sc);
ts = UNSAFE.arrayIndexScale(tc);
ss = UNSAFE.arrayIndexScale(sc);
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);//获取key的hash值//而这个hash值我们不直接用数组长度取余,而是再hash一下,即hash >>> segmentShift,即无符号右移20多位,得到前几位,位数与和原来hashmap取余位数一样,保留原来hash值的高位
int j = (hash >>> segmentShift) & segmentMask;//先取前面的位,然后掩码前面的位。效果为取高位的掩码
//通过unsafe的getObject方法获取数组segment中的元素,我们最起码应该先得到他的坐标。
//这里通过j << SSHIFT可以算得我们索引对应的偏移。放到下面讲解
//segmentMask就是我们的segment.length-1
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) //如果当前索引位置为null,则创建一个segment对象 //效果同segments[i]
s = ensureSegment(j);
return s.put(key, hash, value, false);//调用segment的put方法
}
//下面介绍一下为什么j << SSHIFT就是我们想要的 ss 乘 索引,==
//而 SSHIFT=31-Integer.numberOfLeadingZeros(ss);//numberOfLeadingZeros二进制时ss前面有多少个0,SSHIFT表示ss表示的二进制的1后面有多少个0//我们不妨再转换回来,用i表示1后面有多少个
//验证:j<<31-Integer.numberOfLeadingZeros(ss) == ss×j
//ss为2的次幂,假设为2的i次幂,那么==左式就为j<
segment[]是我们的并发数组,HashEntry[] tablle是每个segment[i]下的数组
Segment.put()
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//tryLock()尝试加锁//与lock()的区别在于:tryLock()不阻塞,如果能获取到锁就取得锁返回true,如果获取不到就返回false
//尝试能否一下就获取到lock锁
HashEntry<K,V> node = tryLock() ? null ://如果获取到锁就返回null给node
scanAndLockForPut(key, hash, value);//没有获取到锁就调用scanAndLockForPut()方法
//执行到这里的时候,已经拿到锁了
//如果是通过scanAndLockForPut得到的node,我们此时还顺便拿到了头结点
V oldValue;//如果是修改,则返回旧值
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;和原来方法一样,取低位
HashEntry<K,V> first = entryAt(tab, index);//用UNSAFE.getObjectVolatile方法获取tab[index]
for (HashEntry<K,V> e = first;;) {
if (e != null) {//如果tab[i]下有链表
K k;
if ((k = e.key) == key || //如果两个new String那么此时不是同一个引用地址
(e.hash == hash && key.equals(k))) {//equals能判断key值的内置是否相等,而不是比较引用地址
oldValue = e.value;//保存旧值
if (!onlyIfAbsent) {//如果onlyIfAbsent==true,就代表map只能添加删除,不能修改
e.value = value;
++modCount;
}
break;
}
e = e.next;//更新e
}
else {//当前tab[i]下没有链表//或者说遍历到链表了最后了还是没找到key对应的值,那么就new Node
if (node != null)//在等锁的过程中已经创建了个node结点了
node.setNext(first);//调用unsafe赋值给first
else//还没创建node结点,先创建一个node
node = new HashEntry<K,V>(hash, key, value, first);//在这里同时赋值给first
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)//tab[]里元素到达阈值,扩容table[]
rehash(node);
else
setEntryAt(tab, index, node);//没有超过阈值直接赋值给tab[index]=node
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();//解锁
}
return oldValue;
}
Segment.scanAndLockForPut()
先解读下tryLock再解读scanAndLockForPut。tryLock()和lock()的区别:
//学习测试用例
import java.util.Collections;
import java.util.Scanner;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Test123123 {
public static Lock lock = new ReentrantLock();
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
// lock.lock();
while(!lock.tryLock()){
System.out.println("没获取到锁,可以去做一些其他的事情");
//应用到concurrentHashMap中就是获取锁的过程中可以去做一些其他的事情,比如new HashEntry()
}
System.out.println("线程1");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.unlock();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
// lock.lock();
while(!lock.tryLock()){
System.out.println("没获取到锁,可以去做一些其他的事情");
}
System.out.println("线程2");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.unlock();
}
}).start();
}
}
scanAndLockForPut():
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);//取得table[i]对应的链表
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // 初始值为负。negative while locating node
while (!tryLock()) {//如果获取不到锁就先去做点别的事情
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {//进入的几个条件://1 第一次时候进入//2 key不等时也进入//退出if条件://1 直到找到最后一个节点还没找打key,所以new了个新node//2 找到对应的key了
if (e == null) {//table[i]上没有链表//或者该链表遍历到最后一个节点了还没有对应的key,就新建
if (node == null) //new一个node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;//改为0
}
else if (key.equals(e.key))//是否为当前节点
retries = 0;//改为0
else
e = e.next;//更新为下一节点
}//后面的操作都代码的前提:已经找到key对应的node了
else if (++retries > MAX_SCAN_RETRIES) {//++retries//细节:找到key对应的node时才开始累加
lock();//重试次数大于64了,直接阻塞等锁吧//如果只有一个CPU的话就只重试一次
break;
}
else if ((retries & 1) == 0 && //偶数次 //拿到key对应的node之后的,偶数次重试时,判断table[i]对应的first有没有被其他线程改变
(f = entryForHash(this, hash)) != first) {//在while (!tryLock())的过程中,很可能其他进程已经改了该数组。//JDK7头插法新增//头结点发生了变化
e = first = f; // re-traverse if entry changed//被其他线程改变了,重新给当前线程赋值其他线程改了的first
retries = -1;//如果头结点发生了变化,重新设置为-1//重新去获取node,万一node被别的线程删除了呢?//所以其实源码这里有点错误,应该把node再重置为null,否则还是会返回删除的结点
}
}
return node;//可能我们在等待锁的过程中已经找到key对应的node了。也可能还没找到对应的node
}
//segment[s]下的取tab[i]
static final <K,V> HashEntry<K,V> entryForHash(Segment<K,V> seg, int h) {//h:hash
HashEntry<K,V>[] tab;
//先判断seg == null,否则seg未必有table属性
return (seg == null || (tab = seg.table) == null) ? null :
(HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);//如果seg不为空,就返回tab[i]
}
Segment.rehash()
解释:即resize(),只不过是resize的HashEntry[] table
private void rehash(HashEntry<K,V> node) {//resize table[]//即rehash是相当于我们HahsMap里的resize() //问题:如何保证resize时没有线程安全:resize操作是在put函数内的,而put获取了锁才调用resize
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;//原长度×2
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];//新建table[]
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {//进行元素转移
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {//一次转移多个结点,所以顺序并非只是倒序了
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);//让node连接上原来的链表
newTable[nodeIndex] = node;//放在头结点
table = newTable;
}
remove()
final V remove(Object key, int hash, Object value) {
if (!tryLock())//也添加了锁
scanAndLock(key, hash);
V oldValue = null;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> e = entryAt(tab, index);
HashEntry<K,V> pred = null;
while (e != null) {
K k;
HashEntry<K,V> next = e.next;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
V v = e.value;
if (value == null || value == v || value.equals(v)) {
if (pred == null)
setEntryAt(tab, index, next);
else
pred.setNext(next);
++modCount;
--count;
oldValue = v;
}
break;
}
pred = e;
e = next;
}
} finally {
unlock();
}
return oldValue;
}
3.2 JDK8
JDK8里面没有了Segment[],那拿什么实现的呢?
JDK8只有一个数组,每个数组位置包含一个链表(一个node结点)
put()
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();//如果没空抛异常
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)//如果整个table[]为空
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //f为tab[i]对应的node
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null))) //如果tab[i]为空,就通过CAS创建node
//如果CAS失败就进行下一次循环,失败的原因可能是其他线程已经new了,所以下一次循环可能不进入这个else if了
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)//把tab[i]头结点的hash赋值给fh,看这个node值的hash值是否为-1,代表有其他线程在对整个tab[]进行扩容
tab = helpTransfer(tab, f);//帮助进行扩容
else {
V oldVal = null;
synchronized (f) { //同步//拿到当前tab[i]的头结点node 同步锁
//我们这里只是拿了根节点的同步锁,万一经过旋转后根节点变化了呢?那其他线程岂不是有自己的根节点锁从而也能执行?所以有下一句的判断
if (tabAt(tab, i) == f) {//重新拿一下头结点,防止这个头结点被其他线程删除了
if (fh >= 0) {//头结点hash值不为负,代表不是树结点
binCount = 1;//记录链表上有多少个元素
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { //当前结点是红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}//End Of if (fh >= 0) {
}//end of if (tabAt(tab, i) == f)
}//synchronized同步结束
if (binCount != 0) {//这里没锁,所以在里面得加锁 //==0代表put没生效,
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);//转为为红黑树//里面有锁
if (oldVal != null)//修改后返回旧值
return oldVal;
break;//没有转为红黑树,同时也是新建结点插入,而不是修改
}
}
}//for
addCount(1L, binCount);
return null;
}
treeifyBin()树化
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {//仍然对头结点加锁
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
初始化
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;//sizeCtrl
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin //一个线程初始化就行 //yield代表放弃cpu拥有权,重新去排队,而重新配对再进入的时候别的线程已经初始化好了
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {//只有一个线程能够减一,如果多个线程都减了,会进入上面的if
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;//16
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);//0.75
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
三 Unsafe类解读
static块。
UNSAFE =sun.misc.Unsafe.getUnsafe()
会报错。
在他内部获取到了Person类的类加载器,如果不为null就报错。
而ConcurrentHashMap的类加载器是boot,所以为null不报错。
在他类内部有个static theUnsafe对象,他new了。所以可以通过反射的方式拿到一个对象。
类对象,偏移量,
获取unsafe
点击UNSAFE源码,可以看到
//UNSAFE类成员 //静态成员
private static final Unsafe theUnsafe;
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();//得到调用者的类
if (var0.getClassLoader() != null) {//如果加载器不是根加载器
throw new SecurityException("Unsafe");//报错
} else {//如果是根加载器
return theUnsafe;
}
}
import sun.misc.Unsafe;
import java.lang.reflect.Field;
private static Unsafe unsafe = null;
private static Field getUnsafe = null;
static {
try {
getUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
getUnsafe.setAccessible(true);//设置为可访问
unsafe = (Unsafe) getUnsafe.get(null);//获取该属性值
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
数组操作:
int base = unsafe.arrayBaseOffset(类[].class);//获取base
long scale = unsafe.arrayIndexScale(String[].class);//获取每个索引的长度
//获取元素值
unsafe.getObject(strings, base + scale * 0);//获取对应索引的值//0代表[0]
//设置元素值
unsafe.putObject(strings, base + scale * 0, "222");//设置对应位置的值//0代表[0]
/**
* 操作数组:
* 可以获取数组的在内容中的基本偏移量(arrayBaseOffset),获取数组内元素的间隔(比例),
* 根据数组对象和偏移量获取元素值(getObject),设置数组元素值(putObject),示例如下。
*/
String[] strings = new String[]{"1", "2", "3"};
long i = unsafe.arrayBaseOffset(String[].class);
System.out.println("string[] base offset is :" + i);
//every index scale
long scale = unsafe.arrayIndexScale(String[].class);
System.out.println("string[] index scale is " + scale);
//print first string in strings[]
System.out.println("first element is :" + unsafe.getObject(strings, i));
//set 100 to first string
unsafe.putObject(strings, i + scale * 0, "100");
//print first string in strings[] again
System.out.println("after set ,first element is :" + unsafe.getObject(strings, i + scale * 0));
//设置[1]为222
unsafe.putObject(strings, i + scale * 1, "222");
//print first string in strings[] again
System.out.println("after set ,first element is :" + unsafe.getObject(strings, i + scale * 1));
System.out.println(strings[1]);
设置对象
unsafe.compareAndSwapInt(person,I_OFFSET,原值,新值);//设置对象的对应属性
unsafe.compareAndSwapInt(person,I_OFFSET,person.i,person.i+1);//设置对象的对应属性
unsafe.getIntVolatile(person,I_OFFSET);//获取对应属性值
/**
* 对象操作
* 实例化Data
*
* 可以通过类的class对象创建类对象(allocateInstance),获取对象属性的偏移量(objectFieldOffset)
* ,通过偏移量设置对象的值(putObject)
*
* 对象的反序列化
* 当使用框架反序列化或者构建对象时,会假设从已存在的对象中重建,你期望使用反射来调用类的设置函数,
* 或者更准确一点是能直接设置内部字段甚至是final字段的函数。问题是你想创建一个对象的实例,
* 但你实际上又不需要构造函数,因为它可能会使问题更加困难而且会有副作用。
*
*/
//调用allocateInstance函数避免了在我们不需要构造函数的时候却调用它
Data data = (Data) unsafe.allocateInstance(Data.class);
data.setId(1L);
data.setName("unsafe");
System.out.println(data);
//返回成员属性在内存中的地址相对于对象内存地址的偏移量
Field nameField = Data.class.getDeclaredField("name");
long fieldOffset = unsafe.objectFieldOffset(nameField);
//putLong,putInt,putDouble,putChar,putObject等方法,直接修改内存数据(可以越过访问权限)
unsafe.putObject(data,fieldOffset,"这是新的值");
System.out.println(data.getName());
/**
* 我们可以在运行时创建一个类,比如从已编译的.class文件中。将类内容读取为字节数组,
* 并正确地传递给defineClass方法;当你必须动态创建类,而现有代码中有一些代理, 这是很有用的
*/
File file = new File("C:\\workspace\\idea2\\disruptor\\target\\classes\\com\\onyx\\distruptor\\test\\Data.class");
FileInputStream input = new FileInputStream(file);
byte[] content = new byte[(int)file.length()];
input.read(content);
Class c = unsafe.defineClass(null, content, 0, content.length,null,null);
c.getMethod("getId").invoke(c.newInstance(), null);
/**
* 内存操作
* 可以在java内存区域中分配内存(allocateMemory),设置内存(setMemory,用于初始化),
* 在指定的内存位置中设置值(putInt\putBoolean\putDouble等基本类型)
*/
//分配一个8byte的内存
long address = unsafe.allocateMemory(8L);
//初始化内存填充1
unsafe.setMemory(address, 8L, (byte) 1);
//测试输出
System.out.println("add byte to memory:" + unsafe.getInt(address));
//设置0-3 4个byte为0x7fffffff
unsafe.putInt(address, 0x7fffffff);
//设置4-7 4个byte为0x80000000
unsafe.putInt(address + 4, 0x80000000);
//int占用4byte
System.out.println("add byte to memory:" + unsafe.getInt(address));
System.out.println("add byte to memory:" + unsafe.getInt(address + 4));
/**
* CAS操作
* Compare And Swap(比较并交换),当需要改变的值为期望的值时,那么就替换它为新的值,是原子
* (不可在分割)的操作。很多并发框架底层都用到了CAS操作,CAS操作优势是无锁,可以减少线程切换耗费
* 的时间,但CAS经常失败运行容易引起性能问题,也存在ABA问题。在Unsafe中包含compareAndSwapObject、
* compareAndSwapInt、compareAndSwapLong三个方法,compareAndSwapInt的简单示例如下。
*/
Data data = new Data();
data.setId(1L);
Field id = data.getClass().getDeclaredField("id");
long l = unsafe.objectFieldOffset(id);
id.setAccessible(true);
//比较并交换,比如id的值如果是所期望的值1,那么就替换为2,否则不做处理
unsafe.compareAndSwapLong(data,1L,1L,2L);
System.out.println(data.getId());
/**
* 常量获取
*
* 可以获取地址大小(addressSize),页大小(pageSize),基本类型数组的偏移量
* (Unsafe.ARRAY_INT_BASE_OFFSET\Unsafe.ARRAY_BOOLEAN_BASE_OFFSET等)、
* 基本类型数组内元素的间隔(Unsafe.ARRAY_INT_INDEX_SCALE\Unsafe.ARRAY_BOOLEAN_INDEX_SCALE等)
*/
//get os address size
System.out.println("address size is :" + unsafe.addressSize());
//get os page size
System.out.println("page size is :" + unsafe.pageSize());
//int array base offset
System.out.println("unsafe array int base offset:" + Unsafe.ARRAY_INT_BASE_OFFSET);
/**
* 线程许可
* 许可线程通过(park),或者让线程等待许可(unpark),
*/
Thread packThread = new Thread(() -> {
long startTime = System.currentTimeMillis();
//纳秒,相对时间park
unsafe.park(false,3000000000L);
//毫秒,绝对时间park
//unsafe.park(true,System.currentTimeMillis()+3000);
System.out.println("main thread end,cost :"+(System.currentTimeMillis()-startTime)+"ms");
});
packThread.start();
TimeUnit.SECONDS.sleep(1);
//注释掉下一行后,线程3秒数后进行输出,否则在1秒后输出
unsafe.unpark(packThread);
* java数组大小的最大值为Integer.MAX_VALUE。使用直接内存分配,我们创建的数组大小受限于堆大小;
* 实际上,这是堆外内存(off-heap memory)技术,在java.nio包中部分可用;
*
* 这种方式的内存分配不在堆上,且不受GC管理,所以必须小心Unsafe.freeMemory()的使用。
* 它也不执行任何边界检查,所以任何非法访问可能会导致JVM崩溃
*/
public class SuperArray {
private static Unsafe unsafe = null;
private static Field getUnsafe = null;
static {
try {
getUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
getUnsafe.setAccessible(true);
unsafe = (Unsafe) getUnsafe.get(null);
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
private final static int BYTE = 1;
private long size;
private long address;
public SuperArray(long size) {
this.size = size;
address = unsafe.allocateMemory(size * BYTE);
}
public void set(long i, byte value) {
unsafe.putByte(address + i * BYTE, value);
}
public int get(long idx) {
return unsafe.getByte(address + idx * BYTE);
}
public long size() {
return size;
}
public static void main(String[] args) {
long SUPER_SIZE = (long)Integer.MAX_VALUE * 2;
SuperArray array = new SuperArray(SUPER_SIZE);
System.out.println("Array size:" + array.size()); // 4294967294
int sum=0;
for (int i = 0; i < 100; i++) {
array.set((long)Integer.MAX_VALUE + i, (byte)3);
sum += array.get((long)Integer.MAX_VALUE + i);
}
System.out.println(sum);
}
}