kafka (三) kafka的底层原理分析
kafka的底层原理分析
- 分区的副本机制
- 副本数据同步
- 数据丢失
- kafka消息的可靠性
这一篇主要讲解:
1、分区副本
2、副本之间数据同步
分区的副本机制
每个topic都可以分为多个分区,多个分区均匀分布在集群的
但是每个分区存储的消息是不一样的,如果这个节点挂了,
怎么办。所以kafka为了提高分区的可靠性提出了副本的概念。
每个分区一般3个,最多5个副本。副本集合存在一个leader副本,
读写都是leader处理,follow去leader副本同步消息日志。
同一个分区的副本均匀分配到其他的节点上。以防不测,提高可用性
创建带副本机制topic
sh kafka-topics.sh --create --zookeeper 192.168.11.156:2181 --replication-factor 3 --partitions 3 --topic secondTopic
在/tmp/kafka-log 路径下看副本信息
如何知道各分区中的leader是谁
get /brokers/topics/secondTopic/partitions/1/state
得到结果:
{"controller_epoch":12,"leader":0,"version":1,"leader_epoch":0,"isr":[0,1]}
或者指令:
sh kafka-topics.sh --zookeeper 192.168.13.106:2181 --describe --topic test_partition
leader表示当前分区leader是那个broker-id
kafka集群一个broker最多只有一个副本.
leader副本:读写请求
follwo副本:只从leader副本同步数据
ISR副本集合:是所有副本的子集,包含leader和leader数据比较接近的follow
副本,如何判断接近,通过LEO和HW,所有的副本都有这俩属性
LEO:log end offset,记录了每条消息的偏移位置。
HW:水位值,简单来说就是follow同步了多少leader数据的位置。
LEO>=HW
一条消息进入leader副本,要等待所有isr集合所有副本同步完成,才行。
然后更新分区的hw,才可以给消费者消费
ISR副本集合
存放与leader副本差不多的副本集合,包含leader。必须满足两个条件
1、副本所在节点与zk链接
2、副本最后一条消息offset和leader的最后一条消息offset之间差值不超过一
定的值(replica.lag.time.max.ms),如果follow副本在一定时间内还没追上
就剔除出isr集合
3、isr数据保存在zk的 /brokers/topics//partitions//state 节点中
follow副本把leader的LEO之前的日志全部同步完,认为follow赶上了leader。再跟新follow的lastCaughtUpTimeMs标识,kafka去检查当前时间和
lastCaughtUpTimeMs的差值是否大于参数replica.lag.time.max.ms,大于就88
副本协同机制
leader副本获取消息后,follow副本拉取写入的消息,如果存在宕机,网络延迟,导致follow副本消息少,且超过一定范围,就被leader踢出isr集合。
副本的leader选举
leader副本所在的节点挂了,需要重新选一个leader副本。
分区副本如果全部挂了怎么办?
1、等ISR任意副本活过来,选做leader
2、等待第一个活过来的副本,有可能不是Isr中的
选择第一个可能要等很久;选择第二个,可能消费的数据就有问题
副本数据同步
副本之间数据同步,怎么实现呢?
1、怎么传播消息
2、在生产者返回ack之前需要保证多少分区副本已经接收到消息
看下分区副本,深色是leader,浅色是follow

producer发送消息到分区时:
1、先通过zk找到该分区的leader
get /brokers/topics//partitions/2/state
producer只会把消息发送到该分区的leader副本
2、leader把消息写入本地log。follow副本从leader副本拉取数据,
从而保持和leader数据一致
3、follower 同步到消息后,写入自己的log,向leader发送ack
4、leader收到所有isr中副本的ack,认为该消息被提交了。leader增加HW并向producer发送ack
LEO 、HW 之前已经介绍过了
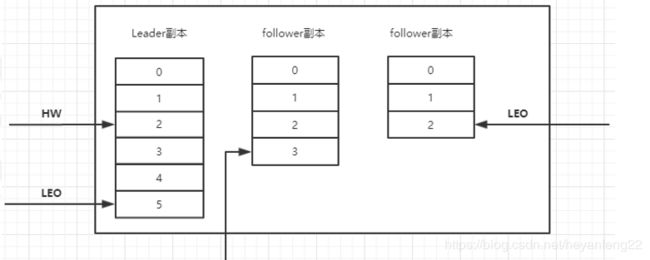
初始状态
一开始leader和follow的 HW和LEO都是0,leader 保存remote LEO,表示所有follow LEO 都被初始化为0。
follow不断的向leader发送fetch请求。
没数据:leader会保留一段时间再失效,然后follow再请求,这个时间配置是(replica.fetch.wait.max.ms)
有消息过来了,会把数据同步到follow副本
数据同步有两种情况,处理方式不一样
1、发fetch请求时,leader已经写完消息了
2、fetch请求持续的时间内(阻塞),有消息来leader了
第一种情况,leader处理完消息
生产者发送一条消息,leader处理完了。follow来fetch请求同步消息
leader收到消息做了什么:
1、把消息追加到log文件,更新leader副本LEO
2、尝试更新leader的HW值,follow的fetch请求还没来,leader的remote LEO是0,leader比较自己的LEO 和remote LEO 。发现最小值是0,和HW相同,不会更新HW
follower副本fetch请求
follow发送了fetch请求,leader做了什么操作
1、读取log数据,更新remote LEO=0(follower还没写入消息,从follower副本fetch请求中的offset来确定)
2、尝试更新HW,LEO 和 remote LEO 还是不一致,HW还是0
3、把消息内容和当前分区HW值发送给follower副本
follower收到返回消息
1、消息写入自己本地log,更新follower自己额LEO
2、跟新follower HW,本地LEO 和leader返回的HW 比较取小的值
所以还是0
所以第一轮交互后看下各自的值
leader:LEO =1,HW=0,remote LEO =0
follower:LEO=1;HW=0
follower 再发fetch请求
这次leader做了什么操作:
1、读取log数据
2、跟新remote LEO =1,因为这次fetch携带的offset是1
3、更新分区的HW,这时候leader LEO 和 remote LEO 都是1,所以HW也是1
4、把数据和当前分区 HW返回给follower副本,这个时候如果没有数据,则返回空
follow副本收到res后
1、如果有数据写本地日志,并且更新LEO
2、更新follower的HW值
此时,数据同步完成,以为这消费者能够消费offset=1这条消息
第二种情况
leader暂时没有数据过来,fetch会被阻塞,等待超时或者有数据来
leader接收到新数据,leader唤醒fetch请求,同步数据
1、leader将消息写入本地日志,更新leader的LEO
2、唤醒follower的 fetch请求
3、更新HW
kafka 使用 HW 和LEO 的方式来实现Ian副本之间的数据同步。
但是出现异常的情况下会丢失数据
数据丢失
如果leader接收了数据,还没来得及同步给followe副本就挂了,产生新的leader,新leader的数据、HW都是旧的,最新的消息可能会被删除。
生产者acks
min.insync.replicas=1 设定isr的最小副本数,默认为1,
acks参数设置为-1时,参数才生效。
acks:0,1,-1
0:生产者送完就不管了
1:leader接受了数据生产者才认为发送完成
all(-1):所有isr的follower副本都接受了消息,才认为发送完成
但是isr可能会缩小到只有一个副本,所以数据也可能丢失
可以看出这三种方案,性能&安全性是不一样的
解决方案
思路:需要引入一个新的标识来解决这个问题。这就是leader epoch;
epoch实际上是一对值,(epoch,offset),epoch代表leader版本号,从0开始递增,leader发生变更,epoch就+1,offset则是这个版本的leader写入的第一条消息的offset。
(0,0)标识第一个leader从offset=0开始写
(1,50)表示第二个leader,从offset开始写,
这个信息保存在 /tmp/kafkalog/topic/leader-epoch-checkpoint
就是 索引文件和日志文件一个路径下
leader写log时,会更新这个缓存,如果是新leader第一次写数据,会加一条记录。每次副本重新成为leader时会查询这个缓存,获取对应leader版本的offset
还原丢失数据的场景
follower宕机恢复后,如果
1、leader没挂,没什么事发生,赶紧去跟leader同步信息,leader返回当前LEO
如果follower和leader的epoch相同,leader的LEO只可能大于等于follow的LEO,不会截断信息
如果follower和leader的epoch的值不同,leader会查找follower带过来的epoch+1,在本地文件中存储的statOffset返回给follower副本,也就是leader的LEO,避免数据丢失。
2、leader挂了,有的follower变成了leader,假如epoch 从0变成1,原来的follower副本中的LEO值保留了下来
leader副本的选举
kafkacontroller监听 ZK 的节点路径,发现broker挂了,重新选举leader
leader副本在该broker上的分区就要重新选举没,策略是:
1、从isr中选出一个做leader(应该有优先leader策略)
2、isr为空,查看topic的unclean.leader.election.enable配置
为true则允许非isr列标配的follower当leader,但是这可能导致数据丢失
false则不允许,直接抛出异常、
3、如果为true,新的leader上位,isr只有leader一个副本,将新的leader和其他isr副本信息写入到该分区的zk路径上。
kafka消息的可靠性
1、生产者acks机制
2、broker分区副本机制
3、消费者提交方式(尽量手动提交,避免异常导致的消费错乱)