AIOps 在腾讯的探索和实践
腾讯云技术社区
赵建春 腾讯 技术运营通道主席 腾讯 社交网络运营部助理总经理 AIOps 白皮书核心编写专家
我今天要讲的主题,AIOps,是一个比较新的话题,其实从概念的提出到我们做,只有差不多一年的时间。一个新事物,有其发展的周期,在腾讯里面我们做了比较多的探索,但是肯定还是有不足的地方,就像咱们看到的 AI 的发展也还有很多不足的地方。今天带来一些案例跟大家分享,希望对大家有一些借鉴和参考的意义。

1 从一个 NLP 故事说起
首先我想从一个 NLP 小的故事来说起。
在二十世纪三四十年代,人们大量尝试用机器的方式去理解自然语言,开始是用类似于左图一样的语法树的基于规则的方式处理的,但后来逐渐地变化为以统计的方式去做。
到了二十世纪七十年代之后,基于规则的句法分析逐渐地走到了尽头。
1972年的时候,自然语言处理领域大师贾里尼克加入了IBM。1974年左右,他在 IBM 提出了基于统计概念的语音识别概念,之后自然语音识别的效果就不断被突破。
2005年谷歌基于统计方面的翻译系统全面超过基于规则的翻译系统,规则方法固守的最后一个语音识别的堡垒被拔掉了。
可以看到二十世纪七十年代前,基于规则的自然语言处理的学者和专家们,注定是失落的。
为什么用这个故事来做引子,是因为我觉得咱们的运维环境,每年会有大量的开发人员加入,写了大量的代码交给我们。
随着业务量的增长,设备会不断增加,系统会越来越庞大,复杂度成指数级增长,而这些压力全给了我们,还有如我们的监控 log 等数据也是非常的海量。
所以我觉得运维系统和自然语言处理是有相似之处的,语言是非常复杂的,量级也是非常大的。

第二个,运维的经验,本质上就是一组组的规则。在我们的运维环境里,很多自动化的运维系统,就是一组组规则的实现。规则有一个好处,就是易理解,但往往有场景遗漏。
规则肯定是一个人写的,一个人面对海量的数据时,处理这些问题会显得力不从心。AIOps 不是替代 DevOps 的,而是对 DevOps 的一个辅助和补充,是对里面规则化部分进行 AI 化的改造的过程。
规则是我们的经验,也是我们的负担,就好比20世纪70年代前的那些专家,我们也需要进行一个转型。

那什么是AI呢?
AI就是从大量输入中总结出准确预测的规律(模型)。我们通过x1 x2 x3这样的大量的输入,通过统计一些参数,abcdwb这样的一些参数,让我们在新的环境中来拟合的预测做一些数值、01、概率型的预测。包括强化的学习,也是通过另外一种形式获取数据进行统计,通过每次的探测,你能知道这一次成功和受益是多少,是正收益或者是负收益,还是零收益。
其实我们只要有足够的数据的量级,可以重复地去探测,并且获得反馈。
易于接入 AI 的场景是特征清晰、正负特征易抽取,就是什么是对的,什么是错的,我们可以比较好分类,有持续地反馈。

数据+算法+训练,可以训练出一个模型,这和之前的规则是有差异的,可以认为是一种有记忆功能的模型。
但是如果要接触AIOps会发现一个问题,就是我可能是一个小团队,或者说我缺乏算法专家,还有即使用了别人的算法模型,我还希望了解这个算法的原理。
最后一个是,提供算法的一方和使用算法的一方,都不愿意提供数据,担心数据泄露给对方,那双方都有这样一个担忧,这是面临的困难。

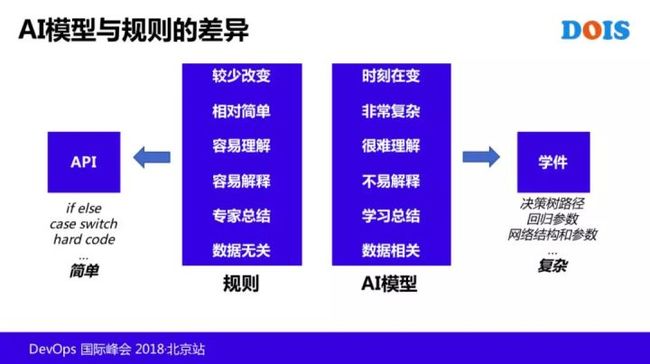
那对于以前的运维的环境里面规则来讲,其实你可以认为他是API,或者是一些编写的逻辑处理,特点就是很少会变,因为是人编写的,所以容易理解,专家总结了,和数据无关,他写好就放在那里,类似 if-else,case swich 等。
但是 在AI,前面讲了,其实是一组带有记忆能力的 API,这个记忆能力是从哪里来的,就是对数据有依赖的,从数据里面统计学习而来的,同时环境里面不断地在积累这个数据,可能不断有新的案例进来。
所以这个模型时刻地在变,非常复杂,它可能是决策树的决策路径、回归参数或神经网络的网络结构及路径权重。
因为它的各种的算法,决策树的神经网络的结构,以及他的权重,或者是回归参数相当复杂,这个不是人编写出来的,所以就难理解。
2 从API到学件
所以 AIOps 我们可以来一个从 API 到学件的转变,“学件” 概念是南京大学的周志华老师提出来的,他是国内 AI 领域的泰斗级的人物,非常厉害,他提出学件是通过数据可以不断地学习,随着数据的不断地加入会更好,另外它的算法是公开的,你也可以了解它是怎么实现的。
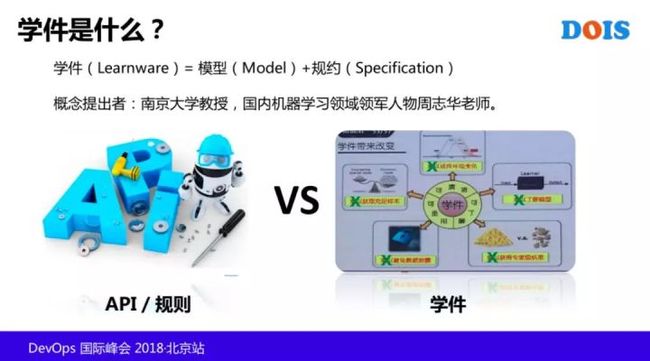
你也可以拿过来用,通过我的数据训练好模型后给你,但没有把数据交给你,把参数、网络结构这些东西交给你,并没有把数据交给你,来解决数据安全问题。
你也可以用自己的数据重新去训练改进适应自己环境的模型,所以是可演进的。算法也是公开可了解的,拿来可以重用,来解决里面的一些问题。

这是我们前一段时间和业界同仁一起编写的 AIOps 白皮书的一个能力框架,我不展开来细讲。
我们大体的想法就是说最底层就是各种机器的学习算法,这个算法和我们的实际环境场景结合起来,通过训练一些单个的 AIOps 学件,单点场景也可以解决问题,之后把单点学件串联起来组成 AIOps 的串联应用场景,最终就可以形成一个智能调度的模型,去解决我们的运维环节的成本、质量、效率等运维关心的问题。
AIOps 五级分类:
一级,尝试应用
二级,单点应用
三级,串联引用
第四是智能解决大多数比较重要场景的串联问题
第五级,既然都提到AI,我们还是希望可以有更大的梦想。我们是否可以有一个就是像黑客帝国里的天网一样的智能运维大脑,能做到质量、成本、效率多目标优化。 比如在推荐场景里,我即希望用户规模越来越大,也希望活跃越来越高,同时希望他的消费水平越来越高,但是这三个目标是有冲突的,就像我们的成本和质量是有冲突的,但是我们希望它在多目标里有一个比较好的均衡,最高级别的时候,连多目标都可以进行同步的优化去平衡。

总体来讲,希望 AIOps 是 DevOps 的一个补充,然后从单点到串联到智能调度这样一个过程,去解决运维里成本、质量和效率的问题。
然后我们团队跟高效运维社区做了一些实践和理论方面的探索和尝试,今天也希望通过这几个单点的串联质量效率这些纬度跟大家分享一下。

3 我们的实践案例分享
1. 单点案例:成本 - 内存存储智能降冷
单点第一个是成本,就是内存存储智能降冷,因为我们是社交网络业务,用户规模大,又有大量的访问,这样就导致团队喜欢用内存型的KV存储。
上线的时候,请求量可能很高,但是随着时间的推移,他的数据量不断地增长,访问密度反而在下降,对我们的成本造成很大的压力。
那大家会想到降冷,但是降冷之前大家都熟悉就是利用数据的最晚使用时间按规则处理,但是这个你想想其实只有一个指标,这个数据的最后使用时间,作为特征去分析,其实远远不够的。
我们对每一类数据做了非常多的特征的抽样提取,有几十个特征,如周期的热度变化这些,就是如图上这些,还有一些没有写出来的。
然后我们同学根据的经验,因为他们之前手工处理过很多,就会有一些经验,哪些数据条目是可以降冷的,把他标注之后,用逻辑回归和随机森林,去学习和训练,其实就是做分类,机器学习绝大部分都是做分类。

做一个分类之后,上面是 LR 和 逻辑的回归,下面是随机森林。那在随机森林,在 30 棵树的时候效果最好,因为随机森林本来就是一个 bagging 的方法,对稳定性效果有提高。

最终的效果就是说,我们把数据进行了一个下沉,把接近 90% 的数据,下沉到硬盘上,我们的访问量并没有下降,SS D数据没有造成访问压力,可以看到下沉和下降是非常精准的。
而且这里面的数据延迟和成功率几乎没有变化,其实之前的同事通过人工的设置做下沉的设置,其实效率是非常的低,这个模块提升了 8 到 10 倍的下沉的效率,这是第一个案例是成本的。

2. 单点案例:质量 — 统一监控去阈值
质量,大家可以看到统一监控去阈值是很有意义的一件事情。监控有两种情况,一种是成功率的监控,它应该是一个直线,正常应该在 100% 左右,但它会往下掉。
第二个就是类似于一个累计性的曲线,或者 CPU 的曲线,这个曲线监控其实是非常的千变万化的。
之前我们可能是通过设置阈值的方法,最大值最小值,阈值设置这样的方式,去设置告警。
这个曲线一直在变化,最大值和最小值也一直在变化,然后他的形式也非常的多变,也很难去设置这样的东西。
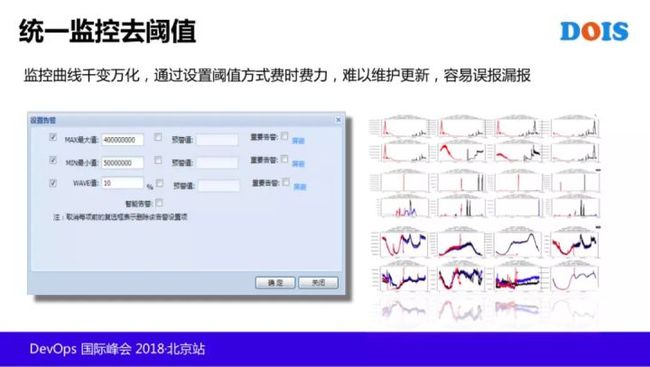
那我们做了两种的方式第一个是成功率的方式,我们使用了 3sigma 方式,来自于工业界,是来控制产品的次品率的,如果是 3sigma 是 99.7% 是正品,其实用这个方式我们统计出来的告警里面,超过正常值范围里面的多少多我们认为是多少个次品,把它找出来。

第二步用孤立森林,就是长的相似的一类的东西,是比较难分类的,要通过很多步才可以去到叶子节点上,所以看到这个 Gap,这一块就是说在比较浅的叶子的节点,就是异常的节点。
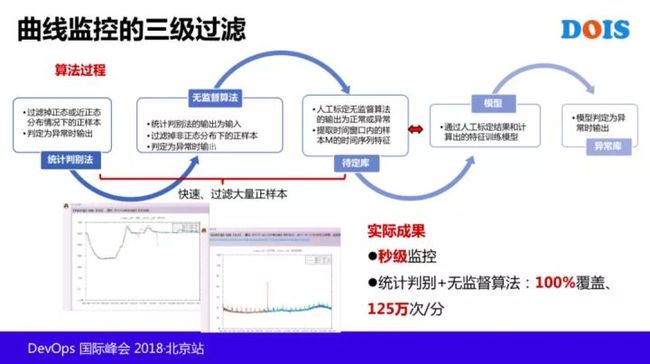
我们通过第一步统计的方式,第二步的无监督方式找到一场。目前最后一步我们还是加了一些规则,让告警更可靠。这个规则其实就是看到我在什么时候告警和恢复,这样一个逻辑既然是一个规则,在未来我们会进一步做一个 AI 化的改造。
那对于这个曲线型的监控,目前我们就是因为曲线不是属于正态分布的,一个曲线是一个曲线,所以极差很大。我们把它做了一个分段的 3sigma,就是一个小时一个段,过去7天进行一个采样。

还有曲线我们可以用多项式去拟合这个曲线,我们用 3sigma、统计方法、多项式拟合几种方法作为第一步,就是相当于推荐系统里的多路召回。
第二步依然就是孤立森林,和前面讲的原理一致。
第三步就是有监督的人工标注,就是图上画圈的有些告警有一些不应该告警的标注,标注训练集后去训练自动地分类。
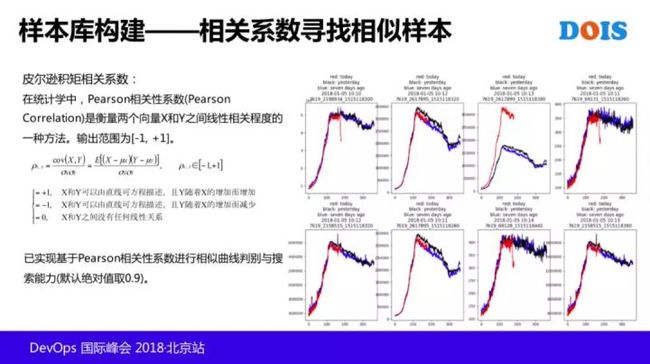
为了获得更多的样本库,同事们用这个叫相关系数的协方差算法,寻找更多的样本库。大家可以关注一下,就是说去找一些相似的曲线,对训练不好的模型,就再进行打包去训练。
总的方式,通过三级的过滤找到异常的告警。
我们有十万多台设备,超过 120 万个监控视图,其实之前我们 70% 以上都没有设告警,因为很难每个都设一个最高值最低值,所以说目前就把这些模块都纳入到这个监控里面去,百分之百覆盖,这是一个监控区域值,去设置的一个案例。
3. 串联应用案例:质量 — ROOT智能根源异常分析
第三个案例,就是质量的串联案例,异常根因分析,其实我们的同学其实在很多的场合分享过。
我们对我们的系统做了很多这样的访问关系统计,生成一个业务访问关系视图,就是业务的访问关系是什么样子的,最后就会画出这样一个图来,就像蜘蛛网一样,这只是其中的一个部分,但是故障发生之后,到底哪一个是根源的问题。
根因分析最开始的做法,是通过先降维关系的方式,右图左边这一列全是同一个模块,由这个模块产生的每一条路径,我们都列出来,就是右边多条路径,这个路径模块里面,把告警出现叠加在模块上,然后设置一个人为定义的面积算法,从面积的大小,就判定哪个模块是异常的根源,虽然是基于规则的,但之前效果还不错,可以帮助我们找到可能是根源的 TOPN 告警,但现在我们又把它做了一些基于AI算法的更新。
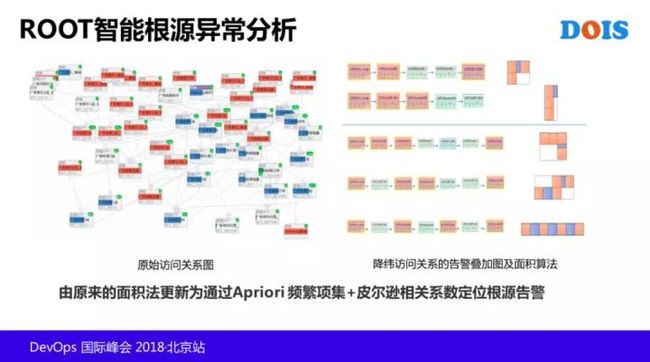
中间这一排,就是前面介绍的根因分析的主逻辑。在告警叠加前面,访问相关的模块才是导致根源告警的模块,所以我们先通过访问关系紧密度进行社团 Group 划分,把一些互相访问紧密的模块,做了一个聚类。
然后告警严重程度接近的,互相导致告警的可能性也更高一些,再用 DBSCAN 类的密度聚类算法,进行聚类。最后再用频繁项集和相关系数等去找一些重复出现的,就是相关性的,贡献度和支持度这样的一些方式去找这个原因。
另外我们在做交流的时候,也有人给我们提出一个建议,就是用贝叶斯算法来找TOP根因的概率,因为这个是一个概率性的统计,我们目前也在进行实验和测试。

4. 智能调度案例:效率 — 织云全自动扩容
再来看一个智能的调度的案例,我之前想智能调度是一个很宏大的目标,并不是只是有点像这样的东西是一个小的改进,那我们智能的全自控的扩容流程。
之前我们在很多的场合讲过智能的工作的流程,他实际上把一个业务模块上需要的资源全部登记进去,之后通过申请设备、获取的资源,发布部署、发布自检、业务测试、灰度上线这样的 6 大步,实际上有二十多小步,我们会组合,组合成不同的流程,那我们看一下这个流程。

(视频播放时对视频内容的简要解释)一个模块的自动扩容,先是添加一些资源,其实就是上线一个新的业务,但是正常情况下他是自动执行的。会有一些业务包,会有一些基础包,还有一些权限,这个权限也是基础化的东西。
我们监控看到压力不断地增长, CPU 增长到 75% 以上,随着增长,我们发现这个系统压力超标了,系统自动启动了扩容,这个是加快的了好几倍的样子。
这样一个过程,就是刚才列了 20 多步的扩容的步骤,就自动地在执行,执行之后企业微信提示对这个模块进行快速上线,然后监控到他有问题,就是快速地上线。
上了两台新的设备,然后这两台新的设备,负载在增加,老的流量在逐渐地下降,最后达到一个平衡。

这就是我们腾讯织云的全自动扩容,目前其中的容量预测及很多监控都已经经过了一定程度的AI化的改造。

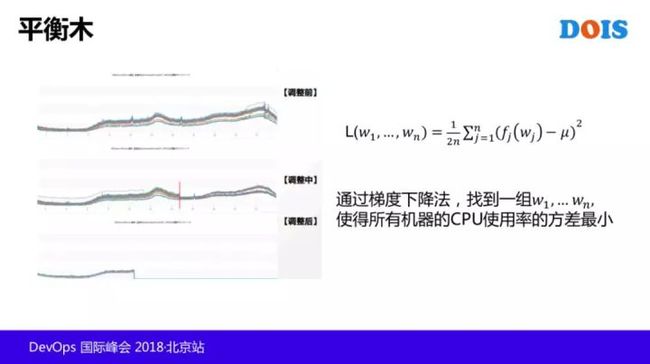
我还想重点讲下其中有一个叫平衡木的模块。为什么要平衡木,因为监控这一块也讲过了,平衡木对于一个模块来讲,一个模块几百台上千台的设备都有,虽然对它设的同样的压力权重,这是真实环境里的数据,就是上下差异非常大。

然后我们通过平衡木这样的一个调整,就可以把上面这样的负载曲线,基本上可以缩成一条线,第二个的曲线容量就变成的 40%,也就是说你通过这样的一个调整,让你的支撑能力,增长了 22%,那它是怎么做的?
实际上我们有一个机器学习,就是希望我们的模块里面,每台单机的负载,尽可能的一致,设置一个loss function,我们用梯度下降的方式,找到这个 loss function 里参数w1~wn的设置。之后通过几轮调整,使得所有设备的负载趋于一致。
5. 更多单点或串联应用
还有更多的单点和串联应用,其中一些由于之前在 GOPS 上海分享过,这里只是简述一下,做为一些案例参考。
第一就是多维下钻智能分析,因为一个 APP 上线之后,你可能会有播放平台,运营商有域名,每个里面有几百个设备,运营商里面有多个运营商,一旦出现一个问题,有可能是魔方里面的块出现问题,很难定位。
比如我们找到前后数据差异化很大,但访问量很小,那它就不是核心的,核心的就是差异性越大,贡献度越大的那些异常,就可能是出问题的那个。

大家都知道啤酒尿布的案例,那频繁项集算法,就是 A 告警出现之后,B 告警肯定会出现,同时 AB 出现的概率还会超过一定的比例,我们就可以找到这样的一些东西,对他进行合并的告警。

第三个就是我们一直有一个智能体检变更报告的东西,就像之前谷歌的讲师也讲到,谷歌通过各种的监控方式发现这次变更之后,是否出现故障。比如可能流量增高,或者有异常告警。
我们的变更检测报告,会自动监测变更后模块的各项指标变化,来辅助工程师判断,这次变更是否正常,输出分 2 类,正常情况不输出可以忽略:
一类是变更后导致了数据的大幅波动,但可能不是异常,如流量大幅增长;
一类是变更后可能出现了异常,如产生了大量 coredump,需要去处理。如何处理也是一个二分类的问题,我们也会在未来改造。

上一次也讲到我们智能客服的问题,利用 NLP 技术,可以做信息检索类、操作执行类的智能客服工具机器人。

4 思考和展望
做一点简单的思考和展望, AIOps 才刚刚起步,但是做的时候,可以考虑把它做成类似公共的组件这样的形式,就是学件,不同的是它们带了一种学习的结果在里面。
有些场景是公司的内部的场景,可以在内部变成一个学件来用。但是对于一些共性的东西,比如说监控,各个公司的监控场景是一样的,如果我们把它定义成标准的上报的格式,标准的时间区间,训练好了 AIOps 的模型,大家认可了效果,就可以一起来使用。
“学件”这个词,周志华老师也在多个场合去讲过。通过编写类似这些共识的上报格式,命名规范等,会让公共的 AIOps 组件变得更加的共享、共识,这个也是我们未来希望更多放到标准里面东西。

这个也是AIOps的标准委员会存在的一个意义。
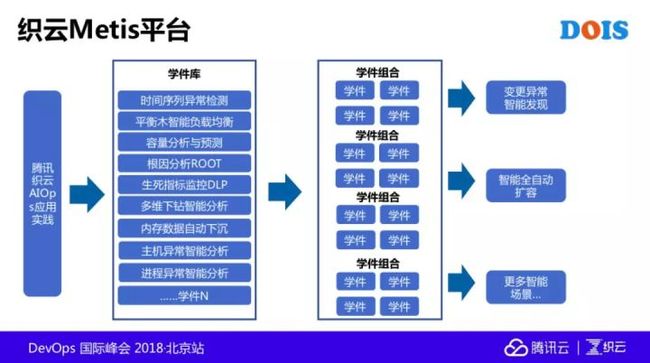
下面这个图是我们织云的 Metis 平台,我们希望先在内部形成更多的学件库,再去解决一些串联的问题,刚才也举了一些例子,也希望在未来的几个月,或者一段时间里,开放出来跟大家一起学习,共同地探讨和改进,可能我的演讲就到这里了。
最后用一句很有名的话做个总结:一般情况下,人们常常会高估一个新技术在一两年内的影响而低估其在未来五到十年的影响。
而 AIOps 就是这么一个技术,作为 DevOps 的辅助和改进,相信它一定会让 IT 运维变的更简单从容,真正地成为运维同学,运维线的一个助手工具和智能化的大脑。谢谢大家。