我在德国做SAP CRM One Order redesign工作的心得
时间过得很快,今天是我到德国工作的第四周,刚好一个月。Prototype的框架已经搭起来了,现在Order能够在新的框架下正常读写,能跑一些简单的scenario,这些scenario对于end user来说感觉不到任何区别,因为毕竟只是DB layer变了。
从下周起就是第二个月,要解决一些open question,比如STATUS, DOCUMENT FLOW这些后台存在SAP_ABA的表,怎么合到新表里去?这些都是接下来要解决的东西。
what I have done in first month
one order这个workstream只有Carsten, Oliver ( IMS guy, one order expert ) 和我,而Oliver只有50%的resource放这个workstream上。POC 4300行左右代码,平均下来按1周5天算每天也就写200行。 属于我名下的一共有46个bug,不过都已经fix了,平均下来我每写93行就要生产出一个bug, 囧。不过我之前和一些同事提过,框架开发的复杂度比应用程序开发要高。
举个例子: 创建新的service order,维护header的shipping data,此时order和shipping data的mode 都是creation,然后创建line item,添加product,header的shipping data带到line item,然后在line shipping data做修改,item的mode变成了change,此时不存盘,直接删除该item,然后马上另外创建一个item,继续编辑,此时第二个item的mode是creation,前一个item的change mode变为deletion,然后再删除第二次加的line item,不存盘,再创建第三个product,维护一些数据,存盘。此时我代码里的buffer处理会出问题,存到DB确实有一条item数据,但是已经corrupt掉了。 由于我buffer处理logic有bug, 我花了很大功夫最后发现是第二次被删除的那条数据的内容被错误存到了DB里:
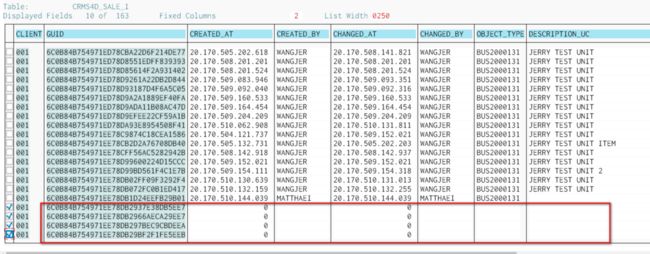
我甚至花了大量的时间来找重现这个错误的办法,因为最初我是偶然的机会发现这个错误,但是没留意我的操作,我花了很长时间在屏幕上进行各种操作,最后才找到能稳定复现问题的步骤,赶紧记录下来:
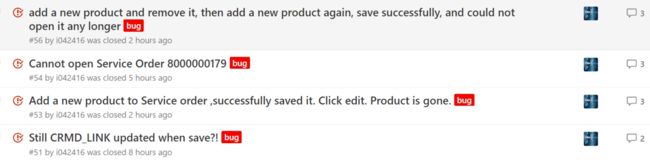
这个buffer处理的bug直接导致了某天有4个新bug开到我头上:
第二阶段 Design improvement - 被Carsten虐
第一阶段,也就是前半个月,我加了很多班让one order能够在新框架下跑起来,然后进入后半个月,也就是第二阶段,对Design的不断改进。
大家都知道老的One order,header和item的administration信息都是存CRMD_ORDERADM_H和CRMD_ORDERADM_I, 然后其他的order节点,每个节点都有1张表,这些表总共有1368张,每次你保存的时候,不同的数据进不同的表。
现在新的design下,所有这1368张表都不要了,所有的数据都往新的Header和item塞。怎么弄?Carsten在我来之前remote和我沟通,说他有一些draft idea,但不sure是否真的能work,需要我把这些idea变成可以运行的代码,run起来之后走一步看一步。Carsten的draft idea很粗,没有实现细节,因此我有充分发挥的空间。
第一阶段我的框架搭起来之后,我自以为实现的很精妙,代码量又不算太多(2000多行),又能够工作,我自我陶醉了。
第二阶段我们每天上午有半个小时的sync meeting,下午有ad hoc的meeting。 上午sync meeting的agenda: 把当前我写的POC代码分成若干块,每天review一块
- review昨天那一块的rework结果
- review今天应该看的那一块
也就是说,这半个小时是我们三个人坐在一起,通过看我的POC代码来改进design。本来是我把代码打到大屏幕上一行行解释这些代码做什么事情,但是实际根本不需要,Carsten看代码速度非常快,反应速度也很快(也可能是我代码可读性实在不错)。我代码质量没任何问题,我自认为算一流,Carsten却每天都能找出需要rework的地方,这些需要rework的都和design相关,比如这件check不应在method A处做而应放到method B处,某逻辑不应放在class A而应放在class B做。所以我第二阶段每天的流程一般都是: 上午review, 下午rework, 改bug. 改bug的时候,我会增加一些代码,这些新增代码又会成为第二天review的input, 周而复始。

我觉得这一个月我收获最多的地方,就是可以和Carsten work on the same topic, learn why he disagrees with my design / code. 因为打比方,如果让Carsten给我做one order的training,我想对我不会有任何帮助。Oliver在我到的第一天问我需不需要他给我讲些one order的session,我说no no no,直接开工吧。我每天和Carsten review他都会找出毛病,而且他挑毛病的尺度和评价标准很值得我学习- 有些毛病他会说,你现在这样做,POC没任何问题,以后productive实现再改。有的毛病他则说,你这样不行,必须改。我事后也会暗自揣摩,他做这些判断的依据。
以前Wuji告诉我,他最开始想学编程,但是没任何基础,不知道怎么入门,所以花1400/月找了一位川大计算机老师,每周三天去这位老师家让他给Wuji讲些计算机基础。所以我现在把自己每天做的事情当成一个类似北大青鸟的培训,这个培训每天有T5的Chief Architecture作为我的老师, 能够和我坐在一起,就一个具体的项目一起动手做,既有纸上的项目设计,又有上机作业,而且这个老师还会认真批改我的作业,这种机会太难得了。我做的越多,就会有越多的机会让老师帮我批改,我就能学的更多。正因为这样想,我每个周末哪也不去。
第一副图是我改了无数版的Order save的实现,我觉得已经相当不错了,但是今天Carsten review的时候,还是给出了修改意见,reason就是看起来很简单的single responsibility. 这个原则说起来容易实现做起来难。


两幅图比较起来,看起来我的design代码量更少,更简单。Carsten的更复杂。但这只是表象,实际上我的视线把buffer merge这个框架需要做的事情注入到了One order 模型每个节点的convert class里去了,就是那个叫convert_1o_to_s4的方法。而One order 模型比方说有200个节点,这些merge的事情就要重复做200次。而Carsten的理由很简单,就是single responsibility,convert class不应该做的事情,不应该感知到的东西,坚决不去碰。 今天我刚才按照Carsten的proposal把整个framework做了refact,结果确实是,改进后的framework代码量更少,因为所有convert class里duplicate的 buffer merge动作都提取到class外面来了,也就是第二章图里那个棕色的method。
Carsten的这个proposal我最初脑子里也曾想过,但我觉得如果放到外面,这个method要能handle任意格式的Order node数据,而且需要能检测出Creation, Deletion和Update的任意一种模式,我觉得编程复杂度过高,没法给出effort estimation。如果放到convert class内部,那么内部convert class知道自己具体是什么structure,所以structure在convert里能够写死,这样做buffer merge简单得多。因此我做POC就按照简单的实现来做,没想到最后还是被Carsten callenge了。这个refact让我总结出一条结论,如果是做框架开发,具体实现复杂度不能成为影响design的决定性因素(作为参考可以).

要获取更多Jerry的原创文章,请关注公众号"汪子熙":