- kmp
- 1.算法分析
- 1.1 符号介绍
- 1.2 算法思想
- 1.3 算法原理
- 1.3 时间复杂度
- 2. 基本性质
- 2.1 border的传递性
- 2.2 失配树
- 2.3 循环节
- 2. 典型例题
- 2.1 字符串匹配
- 2.1.1 一维字符串匹配
- 2.1.2 二维字符串匹配
- 2.2 失配树问题(周期、循环节问题)
- 2.2.1 失配树版题
- 2.2.2 求最小border
- 2.2.3 求border数目
- 2.1 字符串匹配
- 1.算法分析
kmp
1.算法分析
1.1 符号介绍
- 周期
0 < p < |s|, s[i] = s[i + p],满足这个条件,p称为s的周期 - border
0 < r < |s|, pre(s, r) == suf(s, r),满足这个条件,称pre(s, r)是s的border - 周期和border
- 3和6都是abcabcab的周期
- abcab和ab都是abcabcab的border
- pre(s, k)是s的border <=> |s| - k是s的周期
1.2 算法思想
双指针算法优化时间复杂度,同时利用ne数组记录已经匹配成功的位置以优化时间复杂度
1.3 算法原理
ne数组含义,ne[i] == j表示以i位置结尾的区间和以j位置结尾的区间完全相等,如下图两段红色的区间。
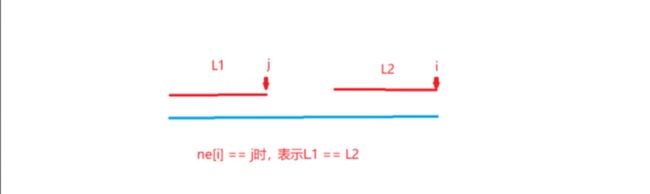
同时,可以证明ne数组匹配到的L的长度,一定是最大的,也就是说,ne[i] == j时,最长只能是L2 == L1,不可能出现两段长度大于L1的L3和L4,且满足L3 == L4
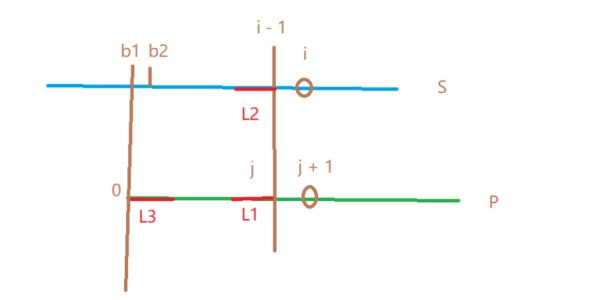
P串的0 ~ j位和S串的b1 ~ i-1位匹配成功,但P串的j+1位和S串的i位不相等,那么本来应该把P串的第0位开始和S串的b2位开始逐个匹配。但是由于L1 = L3(使用ne数组记录),L2 = L1, 所以L2 = L3,那么表明P串的0~L3位已经和S串的i-1-L2~i-1位匹配成功,那么无需逐个匹配,只需要把P串L3后面一位和S的第i位开始匹配即可,通过这样的方式优化时间复杂度。
1.ne数组的生成
对模式串进行匹配,一个指针i在前从2开始,一个指针j在后从1开始,两个指针分别向前扫描,进行模式匹配,如果匹配成功,记录ne[i] = j;匹配不成功,j向后退,j = ne[j]
2.模式匹配
一个指针i指向原串S,一个指针j指向模式串P,逐个匹配,匹配成功,则匹配下一个;匹配不成功,j往回退,j = ne[j];
1.3 时间复杂度
O(m + n)
2. 基本性质
2.1 border的传递性
弱传递性: 串s是串t的border,串t是串r的border,那么s是r的border
- aba是ababa的border
- ababa是abababa的border
- 则有传递性aba是abababa的border
更强的传递性: 串s是串r的border,串t是r的border,单|t| < |s|,则串t是串s的border
- aba是abababa的border
- ababa是abababa的border
- 则aba也是ababa的border
记 mb(s) 表示s的最长border,则:
- mb(s),mb(mb(s)),...,构成了s的所有border
- s的所有border环环相扣,被1条链串起来
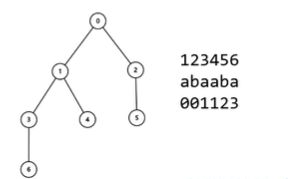
2.2 失配树
将ne[i]视为i点的父节点,那么通过ne数组可以把0~N点连成一棵树,满足性质:
- 点i的所有祖先都是前缀pre(s, i)的border
- 没有祖先关系两个点i,j没有border关系
计算ne数组可以看作:从j=fa[i-1]开始不断往上走,找第一个满足s[j+1]=s[i]的点,把i点的父亲设为j+1
2.3 循环节
定理:假设S的长度为len,则S存在最小循环节,循环节的长度L=len-next[len],子串为S[0…len-next[len]-1]。
(1)如果len可以被len - next[len]整除,则表明字符串S可以完全由循环节循环组成,循环周期T=len/L。
(2)如果不能,说明还需要再添加几个字母才能补全。需要补的个数是循环个数L-len%L=L-(len-L)%L=L-next[len]%L,L=len-next[len]。
sample:
-
s0s1s2s3s4s5 ,next[6]=3
即s0s1s2=s3s4s5
很明显可知:循环子串为s0s1s2,L=len-next[6]=3,且能被len整除。 -
s0s1s2s3s4s5s6 ,next[7]=4
此时len-next[7]=3,即L=3
由s0s1s2s3=s3s4s5s6
可知s0s1=s3s4,s2s3=s5s6
从而可知s0s1s2=s3s4s5,s0=s3=s6
即如果再添加3-4%3=2个字母(s1s2,加在原字符串的最后),那么得到的字符串就可以由s0s1s2循环3次组成
2. 典型例题
2.1 字符串匹配
2.1.1 一维字符串匹配
acwing831KMP字符串
给定一个模式串S,以及一个模板串P, 模板串P在模式串S中多次作为子串出现。
求出模板串P在模式串S中所有出现的位置的起始下标。
#include
using namespace std;
int const N = 1e6 + 10;
int n, m;
char p[N], s[N];
int ne[N];
int main()
{
cin >> n >> p + 1 >> m >> s + 1;
// 生成ne数组
for (int i = 2, j = 0; i <= n; ++i)
{
while (j && p[j + 1] != p[i]) j = ne[j]; // 对模式串进行匹配,如果没有匹配成功,j变成ne[j]的位置
if (p[j + 1] == p[i]) j++; // 匹配成功,j到后一位
ne[i] = j; // 记录匹配成功的i位和j位的对应关系
}
// 利用ne数组进行模式匹配
for (int i = 1, j = 0; i <= m; ++i)
{
while (j && p[j + 1] != s[i]) j = ne[j]; // 没匹配成功, j变成ne[j]的位置
if (p[j + 1] == s[i]) j++; // 匹配成功,j往后一位
if (j == n) // 如果完全匹配完毕
{
cout << i - n << " ";
j = ne[j]; // 寻找p在s中的下一次出现的位置,利用ne数组优化时间复杂度
}
}
return 0;
}
2.1.2 二维字符串匹配
POJ 2185 Milking Grid
在N*M字符矩阵中找出一个最小子矩阵,使其多次复制所得矩阵包含原矩阵。N<=1e4, M<=75
/*
本题要求最小子矩阵,把每行看成一个字符,求个ne数组,然后把每列看成一个字符,求ne数组
要使得子矩阵最小,那么就是要是的周期最小,即border最大,那么直接把m-ne[m]即可
答案即为(n-ne[n])*(m-ne[m])
*/
#include
#include
#include
using namespace std;
int const N = 1e5 + 10, M = 80;
char s[N][M];
int n, m, ne[N];
// 每行当成字符
bool cmp1(int i, int j) {
for (int k = 1; k <= m; ++k)
if (s[i][k] != s[j][k]) return false;
return true;
}
// 每列当成字符
bool cmp2(int i, int j) {
for (int k = 1; k <= n; ++k)
if (s[k][i] != s[k][j]) return false;
return true;
}
int main()
{
cin >> n >> m;
for (int i = 1; i <= n; ++i) cin >> s[i] + 1;
// 行做kmp
for (int i = 2, j = 0; i <= n; ++i) {
while (j && !cmp1(i, j + 1)) j = ne[j];
if (cmp1(i, j + 1)) j++;
ne[i] = j;
}
int ans = n - ne[n];
// 列做kmp
memset(ne, 0, sizeof ne);
for (int i = 2, j = 0; i <= m; ++i) {
while (j && !cmp2(i, j + 1)) j = ne[j];
if (cmp2(i, j + 1)) j++;
ne[i] = j;
}
ans = ans * (m - ne[m]);
printf("%d", ans);
return 0;
}
2.2 失配树问题(周期、循环节问题)
2.2.1 失配树版题
P5829 【模板】失配树
m组询问,每组询问给定p,q,求s的p前缀和q前缀的最长公共border的长度。
/*求p和q地最长border即为求p和q点的lca,如果lca=p||lca=q,那么lca=fa[lca]*/
#include
using namespace std;
const int N = 1e6 + 10, M = N * 2;
int f[N][22], d[N]; // f[i][j]表示从i开始,往上走2^j步到达的点,d为深度,dist为距离
int e[M], ne[M], h[N], idx;
int T, n, m, t; // t为数的深度
queue q;
char s[N];
int nex[N];
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
// 预处理:得到每个点的深度,距离,f数组
void bfs()
{
q.push(0);
d[0] = 1;
while (q.size())
{
int x = q.front();
q.pop();
for (int i = h[x]; i != -1; i = ne[i])
{
int y = e[i];
if (d[y]) continue;
d[y] = d[x] + 1; // 更新深度
// 进行dp更新
f[y][0] = x;
for (int j = 1; j <= t; ++j)
{
f[y][j] = f[f[y][j - 1]][j - 1]; // 分两段处理
}
q.push(y);
}
}
}
// 查找x和y的最近公共祖先
int lca(int x, int y)
{
if (d[x] > d[y]) swap(x, y); // 保证x的深度浅一点
for (int i = t; i >= 0; --i)
if (d[f[y][i]] >= d[x]) y = f[y][i]; // 让x和y到同一个深度
if (x == y) return x;
for (int i = t; i >= 0; --i) // 让x和y之差一步就能相遇
{
if (f[x][i] != f[y][i]) x = f[x][i], y = f[y][i];
}
return f[x][0];
}
int main()
{
cin >> s + 1;
n = strlen(s + 1);
// 求ne数组
for (int i = 2, j = 0; i <= n; ++i)
{
while (j && s[j + 1] != s[i]) j = nex[j]; // 对模式串进行匹配,如果没有匹配成功,j变成ne[j]的位置
if (s[j + 1] == s[i]) j++; // 匹配成功,j到后一位
nex[i] = j; // 记录匹配成功的i位和j位的对应关系
}
memset(h, -1, sizeof h);
t = (int)(log(n) / log(2)) + 1; // 得到树的深度
// 读入一棵树
for (int i = 1; i <= n; ++i) {
add(i, nex[i]), add(nex[i], i);
}
cin >> m;
bfs();
// 回答询问
for (int i = 1; i <= m; ++i)
{
int a, b;
scanf("%d %d", &a, &b);
int lcaa = lca(a, b);
if (lcaa == a || lcaa == b) lcaa = f[lcaa][0];
printf("%d\n", lcaa);
}
return 0;
}
2.2.2 求最小border
luogu P3435 [POI2006]OKR-Periods of Words
给定一个字符A,对于A的每个前缀pre(A, i),求最长字符串Bi,使得len(Bi) < i, 且pre(A, i)是若干Bi连接成的字符串的前缀,求出每个Bi的长度和
len(A) <= 1e6
/*
本题要求的是最短border,那么就无法使用ne数组了
我们考虑在失配树上去思考问题,最短border就是离i点最远且最接近0但不等于0的那个点
因此我们可以使用路径压缩的思路,每次找到i对应的那个最短border后,修改ne数组,使得i直接指向它的最短border
树可以不需要建出来
*/
#include
using namespace std;
int const N = 1e6 + 10;
int ne[N], n;
char s[N];
int main()
{
cin >> n >> s + 1;
// 生成ne数组
for (int i = 2, j = 0; i <= n; ++i)
{
while (j && s[j + 1] != s[i]) j = ne[j]; // 对模式串进行匹配,如果没有匹配成功,j变成ne[j]的位置
if (s[j + 1] == s[i]) j++; // 匹配成功,j到后一位
ne[i] = j; // 记录匹配成功的i位和j位的对应关系
}
long long res = 0;
for(int i = 1, j; i <= n; i++) {
j=i;
while(ne[j]) j = ne[j];
if (ne[i]!=0) ne[i] = j;//记忆化
res += (long long)i - j;
}
printf("%lld\n", res);
return 0;
}
2.2.3 求border数目
在求ne数组的同时,我们可以一起把border数组求出来
P2375[NOI 2014]动物园
给定长度为N的字符串s,对每一个前缀pre(s, i),求出长度不超过一半的border数量.N<=1e6
/*本题要求求出每个前缀pre(s, i),长度小于i/2得border得数目,记dep[x]长度为x时的border数目,那么我们可以在
求ne数组时就把dep数组求出来(dep数组其实就是每个点的深度)。那么我们可以通过倍增的方法从i开始往上跳,找到第一个深度小于i/2的位置,然后把对应的cnt[i]乘到答案即可*/
#include
using namespace std;
typedef long long LL;
int const N = 1e6 + 10, MOD = 1e9 + 7;
int ne[N], f[20][N], n, t, dep[N];
char s[N];
int main()
{
freopen("in.txt", "r", stdin);
freopen("out.txt", "w", stdout);
cin >> t;
while (t--)
{
scanf("%s", s + 1);
n = strlen(s + 1);
dep[1] = 1;
// kmp求ne数组,求dep数组
for (int i = 2, j = 0; i <= n; ++i) {
while (j && s[i] != s[j + 1]) j = ne[j];
if (s[i] == s[j + 1]) j++;
ne[i] = j;
f[0][i] = ne[i];
if (!ne[i]) dep[i] = 1;
else dep[i] = dep[ne[i]] + 1;
}
// 初始化倍增数组
for (int j = 1; j < 20; ++j)
for (int i = 1; i <= n; ++i)
f[j][i] = f[j - 1][f[j - 1][i]];
// 从i点往上跳,跳到第一个<=i/2的位置
LL ans = 1;
for (int i = 2; i <= n; ++i) {
int tt = i;
for (int j = 19; j >= 0; --j) {
if (f[j][tt] * 2 > i) tt = f[j][tt];
}
ans = ans * dep[tt] % MOD;
}
printf("%lld\n", ans);
}
return 0;
}
/*本题还可以做两边kmp,第一遍求出每个点的深度dep数组,然后第二次做kmp时,用ne数组暴力往上跳,
直到跳到<=i/2的位置,这样做是线性的(记x[i]为i/2的border的位置,那么x[i]<=x[i-1]+1,因此j是递减的,可以保证这个算法是O(n)的)*/
#include
using namespace std;
typedef long long LL;
int const N = 1e6 + 10, MOD = 1e9 + 7;
int ne[N], n, t, dep[N];
char s[N];
int main()
{
freopen("in.txt", "r", stdin);
freopen("out.txt", "w", stdout);
cin >> t;
while (t--)
{
scanf("%s", s + 1);
n = strlen(s + 1);
dep[1] = 1;
// kmp求ne数组,求dep数组
for (int i = 2, j = 0; i <= n; ++i) {
while (j && s[i] != s[j + 1]) j = ne[j];
if (s[i] == s[j + 1]) j++;
ne[i] = j;
if (!ne[i]) dep[i] = 1;
else dep[i] = dep[ne[i]] + 1;
}
LL ans = 1;
// 记x[i]为i/2的border的位置,那么x[i]<=x[i-1]+1
for (int i = 2, j = 0; i <= n; ++i) {
while (j && s[i] != s[j + 1]) j = ne[j];
if (s[i] == s[j + 1]) j++;
while ((j << 1) > i) j = ne[j]; // 因此j是递减的,可以保证这个算法是O(n)的
ans = ans * (dep[j] + 1) % MOD;
}
printf("%lld\n", ans);
}
return 0;
}