随着大数据时代的来临,越来越大的数据量冲击着我们的系统,很多脆弱的系统在数据洪水的猛攻下早已不堪重负甚至垮掉。随着计算机硬件的飞速发展,千兆、万兆网卡,光纤,SSD硬盘,DDR4等等最新硬件的出现,计算机的硬件性能不再是我们系统优化的重要关注点,慢慢的我们发现现在的Web系统绝大多数性能的瓶颈都来自数据库。
前置系统即使你提供再多的web应用服务器,买再好的负载均衡设备,接最快的骨干线路却仍被数据库底下的性能所“坑爹”,页面动不动就卡死,查询一条数据要很久....
所以优化我们的数据库是最省钱也是最有效的方法,可以使我们的系统性能大幅度的提升,优化数据库的方法有很多,例如:采用SSD固态硬盘存储核心数据,增加数据库集群等等。下面我们要介绍的一种就是“分表”优化,这种优化相对简单,在数据库设计时期就可做到合理的规划。
分表优化简单的来讲就是将“大表”拆分成“小表”,这里的“大”有两个维度的意思:
表字段水平维度:表字段多,一个表甚至有几十个字段。
表内容垂直维度:表数据量大,几百万,几千万甚至上亿条数据。
所以分表优化会从两个方向同时进行,垂直和水平。
一般来说我们执行一条SQL语句是按以下顺序进行的:
1.客户端将SQL通过连接发送的数据库服务器。
2.数据库服务器对SQL语句进行解析并做一系列处理。
3.执行SQL语句。
4.将执行结果返回给客户端。
期间诸如updae,delete等操作会造成一定程度上的“锁”,根据引擎不同,隔离级别设置不同可能会出现“锁字段”,“锁行”,“锁表”甚至“锁据库”等等情况。
这样带来的后果就是SQL执行时间长,查询队列中等待的SQL无法继续进行,从而造成系统操作时间大幅度增加等不良后果。
应对“锁”我们就需要合理的分表了。
下面我们就先来研究“垂直分表”:
据说MySQL可以支持1000个字段,然而往往我们是用不了也不建议用这么多的,一般情况下建议字段总数不要超过30个,10-20个比较合理,再多的话在关联查询时会造成效率上的浪费。当然这也不是绝对的,可以根据项目及具体情况来执行。
以下是一张用户表,仅作为举例使用,不必去考虑其具体设计及内容合理性:
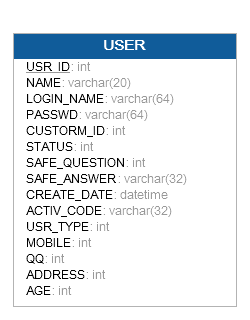
以下是建表SQL语句:
CREATE TABLE `USER` (
`USR_ID` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户编号',
`NAME` varchar(20) DEFAULT NULL COMMENT '姓名',
`LOGIN_NAME` varchar(64) NOT NULL COMMENT '登录名',
`PASSWD` varchar(64) NOT NULL COMMENT '密码',
`CUSTORM_ID` int(11) DEFAULT NULL COMMENT '客户代码',
`STATUS` int(11) DEFAULT NULL COMMENT '用户状态',
`SAFE_QUESTION` int(11) DEFAULT NULL COMMENT '安全提示问题',
`SAFE_ANSWER` varchar(32) DEFAULT NULL COMMENT '安全提示答案',
`CREATE_DATE` datetime DEFAULT NULL COMMENT '创建日期',
`ACTIV_CODE` varchar(32) DEFAULT NULL COMMENT '激活码',
`USR_TYPE` int(11) DEFAULT NULL COMMENT '用户类型',
`MOBILE` int(15) DEFAULT NULL COMMENT '手机',
`QQ` int(15) DEFAULT NULL COMMENT 'QQ',
`ADDRESS` int(150) DEFAULT NULL COMMENT '联系地址',
`AGE` int(10) DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`USR_ID`)
);
这个表内容信息丰富可以很全面的查询出所有的用户信息,既然如此我们还有必要利用分表去优化它吗?答案是肯定的,有必要!
在访问量不大的情况下把所有信息都放置到一张表中可以很容易的获取所有信息,给我们代码的开发带来了极大的便利,但是一旦用户量激增,这种表结构就会产生很严重的诟病,例如:登录和更新用户信息同时进行,很容易导致锁表,相互影响;又如修改密码和修改其他信息也会如此等等。为了应对未来这种高并发的情况我们就应该合理的去设计库表了。
首先,我们可以将用户安全相关信息提取出来,如:密码,登录名,安全提示问题,安全提示答案。将这些信息组成一个名为“PASSWD”的表,这样做的好处是:将登录及相关安全信息独立出来以供功能单一如“登录”的业务调用,这样就可以减轻一部分表的压力,登录时只到“PASSWD”查询即可完成操作,当有必要时再去查询其他信息,这样做也有另一个好处,就是可以将PASSWD的查看及修改权限固定,仅限一定的mysql用户可以操作以提升安全性。
其次,我们将用户的相关联系信息提取,如:姓名,联系地址,年龄,手机,QQ。这些信息组成一个名为“USER_INFO”的表,这样我们就可以很方便的去扩展此表的字段及信息,更利于日后的更新及维护。
最后,剩下的字段组成新的“USER”表,此表只负责存储与用户业务相关的字段,使得“USER”表能更好的贴近相关业务,这三张表通过字段“USR_ID”进行关联。
分完后的表如下:

建表SQL语句:
CREATE TABLE `USER` (
`USR_ID` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户编号',
`CUSTORM_ID` int(11) DEFAULT NULL COMMENT '客户代码',
`STATUS` int(11) DEFAULT NULL COMMENT '用户状态',
`CREATE_DATE` datetime DEFAULT NULL COMMENT '创建日期',
`ACTIV_CODE` varchar(32) DEFAULT NULL COMMENT '激活码',
`USR_TYPE` int(11) DEFAULT NULL COMMENT '用户类型',
PRIMARY KEY (`USR_ID`)
);
CREATE TABLE `PASSWD` (
`USR_ID` int(11) NOT NULL COMMENT '用户编号',
`LOGIN_NAME` varchar(64) NOT NULL COMMENT '登录名',
`PASSWD` varchar(64) NOT NULL COMMENT '密码',
`SAFE_QUESTION` int(11) DEFAULT NULL COMMENT '安全提示问题',
`SAFE_ANSWER` varchar(32) DEFAULT NULL COMMENT '安全提示答案'
);
CREATE TABLE `USER_INFO` (
`USR_ID` int(11) NOT NULL COMMENT '用户编号',
`NAME` varchar(20) DEFAULT NULL COMMENT '姓名',
`ADDRESS` int(150) DEFAULT NULL COMMENT '联系地址',
`AGE` int(10) DEFAULT NULL COMMENT '年龄',
`MOBILE` int(15) DEFAULT NULL COMMENT '手机',
`QQ` int(15) DEFAULT NULL COMMENT 'QQ'
);
当然以上分表并不是绝对的,可以根据具体情况去考虑分配方法及实现,我在这里只是提供一个思路,不必去严格要求上述分法的合理性,仁者见仁智者见智。
总结:垂直分表适合字段较多且业务关联较多的情况,将这些字段分散到不同业务相关的表中分别维护,这样不同的业务之间不会相互影响或制约。
另一种分表方式就是“水平分表”:
垂直分表应用于字段,水平分表就应用于表内容了。
我们知道一旦表内容非常多的时候查询起来就会很慢,虽然建立索引可以减少查询时间,但这毕竟不是根本解决办法。虽然MySQL没有硬性限制单表的大小,但是任何人都知道“表容量是不能无限制的增长的,这样影响性能”。
我们可以在SQL控制台输入命令“SHOW TABLE STATUS”来查看表的大小及状态。
水平分表的思路其实就是将一个内容高负荷的表拆分成一些小表以提高性能,如:论坛表结构。
众所周知一个论坛对应了很多子论坛,子论坛又对应了很多帖子,帖子又对应了很多回复,结构如:
论坛 < 子论坛 forum < 帖子 topic < 回复 reply
我们就可以forum按论坛id进行区分,如:forum_001,forum_002,forum_003....
查询时我们利用特定算法拼接表名来进行操作。
当然这是一种比较极端的做法,这种做法局限性也很强,一旦表结构修改将产生令人恐怖的修改工作量,水平分表类似于“分区分表”,我们会在接下来学习分区分表相关内容。
水平分表优先需要解决“主键”问题,当全部数据集中在同一张表中时,我们可以利用MySQL的内部机制auto_increment 很轻易的实现主键自增,但是水平分表后每一张表都各种维护一份主键生成策略,这样就会产生重复冲突的现象,所以我们分表之前首先需要解决主键的生成问题。
以下是几种解决方案:
1.设置主键起始值
加入我们已经将表水平分成了3张表,TABLE1,TABLE2,TABLE3,每张表容纳10万份数据,那么TABLE1 的主键范围就应该是1-10万,而TABLE2 主键范围则为10万1-20万,TABLE3 主键范围则为20万1-30万,依次类推。
我们在创建表的时候可以手动的指定每张表主键增长的起始值,如TABLE1 起始值为1,TABLE2 为100001,TABLE3 为200001...
建表语句则为:
CREATE TABLE `TABLE1` (
...
) AUTO_INCREMENT=1
CREATE TABLE `TABLE2` (
...
) AUTO_INCREMENT=100001
CREATE TABLE `TABLE3` (
...
) AUTO_INCREMENT=200001在建表时人为指定主键起始值的做法简单明了,维护成本小,不必额外关注主键生成问题。 但是在建表时直接声明起始值的做法有些生硬,我们可以将建表语句与主键设置语句分离,这样维护起来更加方便灵活:
CREATE TABLE `TABLE1` (
...
)
alter table `TABLE1` AUTO_INCREMENT=1
CREATE TABLE `TABLE2` (
...
)
alter table `TABLE2` AUTO_INCREMENT=100001
CREATE TABLE `TABLE3` (
...
)
alter table `TABLE3` AUTO_INCREMENT=200001sql语句的大概意思应该明白了吧,里面的错误就不必较真了。
2.利用拼接方式
这种方式下我们不必为每张表维护不同的主键ID,每张表完全可以都是从1-10万相同即可,在使用表数据时需要程序中人为加入另一个标识符,如表名:
主键:TABLE1_1001 代表TABLE1中的1001数据
主键:TABLE2_1001 代表TABLE2中的1001数据这样做的好处就是建表时全部采用相同的条件语句,不必单独维护主键异同,使用时需要在程序中动态的去判断该数据所属的表即可。
如主键ID显示可以变成1_1001,2_1001等等,将表和数据的ID分离。
3.利用外部实现
也就是在程序或一张单独的表中维护主键的值,在每次插入时取一下主键值。