VGG网络 pytorch源码分析
《Very Deep Convolutional Networks for Large-Scale Image Recognition》
论文:https://arxiv.org/pdf/1409.1556.pdf
VGG作为一个经典的backbone,已经被大家讲烂了,很多文章里的模型图都被大家拷贝到模糊了。在看一些项目源码比如faster rcnn、ctpn时,VGG都是它们的基础网络模型来获取特征图。这里注意记录下pytorch官方的vgg实现源码。
VGG通过3x3的卷积核和2x2的最大池化层得不断叠加,来构建一个深层的网络模型(文章里也有一部分采用1x1的卷积核,但是不是我们常说的vgg16和vgg19中的)。那就会有出现一道必考题,为什么VGG使用3x3的卷积?谈论vgg肯定会问这个问题,在VGG采用最多的是7x7和11x11的卷积核,VGG的主要作用就是采用小的卷积核而增加网络深度来提高网络性能。那为什么用3x3呢,从感受野上看一个7x7的卷积层相当于三个3x3的卷积层,但是后者的参数(3*3*3=27)要比前者(7*7=49)少的多。参数少了而且每个3x3后有一个Relu函数,这样做了三次非线性变换,增加了网络深度,网络深度的增加能给提取更加复杂的图像特征。增加网络深度有什么用?

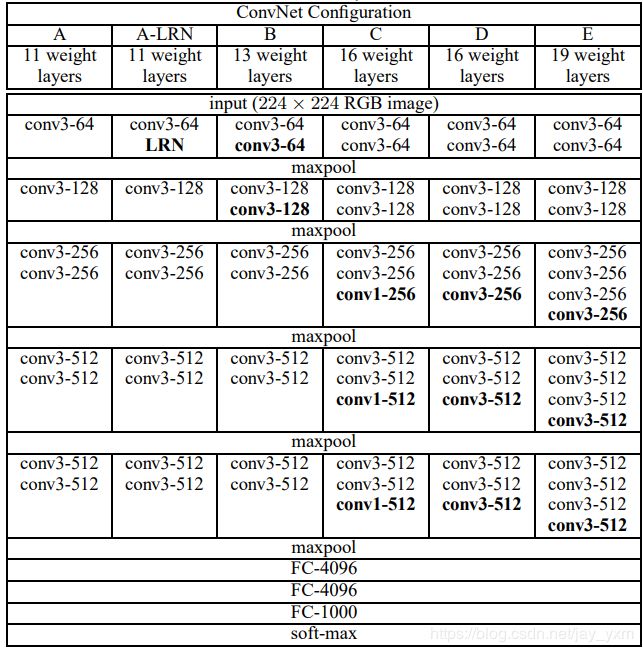
上图是论文中的结构图,D就是vgg16,E是vgg19,pytorch的vgg源码按照上面相同的结构来实现,整个结构分为5段,项目源码中喜欢用conv3_1、conv5_3等来表示某一层特征图,conv5_3就表示第5段中第三个卷积层。所有的卷积层结束以后是三个全连接层,最后是一个softmax分类层。在C中用1x1的卷积,实验表明效果不如3x3的卷积,但不是1x1没用,只是在这里没有3x3提取到更多有用的特征,其实1x1的卷积更多用来融合通道,或者增加减少通道数,比如在Inception网络中可以减少相当多参数量。

假设previous layer的大小为28*28*192,则,
a的weights大小,1*1*192*64+3*3*192*128+5*5*192*32=387072
a的输出featuremap大小,28*28*64+28*28*128+28*28*32+28*28*192=28*28*416
b的weights大小,1*1*192*64+(1*1*192*96+3*3*96*128)+(1*1*192*16+5*5*16*32)+1*1*192*32=163328
b的输出feature map大小,28*28*64+28*28*128+28*28*32+28*28*32=28*28*256
1x1卷积极大的减少了参数量
B中的LRN在LEnet中提出的一种网络层,本文中实验说它没有用,那就没有用了呗。
pytorch中网络构造方式:
features层,3x3卷积和2x2池化叠加来的
cfgs = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
#'M'表示池化层
#make_layers会根据参数cfg,来选择A B C D E哪一个模型
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)分类层,包括三个全连接层,前两个全连接层都跟了dropout,这跟原文也是相同的
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
pytorch里并没有加入softmax层,它也不是真的作为一个分类模型去使用,主要使用作为一些项目的主要网络。使用上也很方便
model = vgg16(pretrained=False)
features = list(model.features)[:30]这样就加载了预训练模型vgg16的conv5_3之前的部分。
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x这部分是一个完整前向计算,但是在features层之后,pytorch并没有采用maxpool最大池化,而是用了自适应的平均池化。
self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)初始化部分,这里比较直接简单,但在文字中对VGG的初始化就麻烦一点,作者先训练上面网络结构中的A结构,A收敛之后呢,将A的网络权重保存下来,再复用A网络的权重来初始化后面几个简单模型。复用A的网络权重,只是前四个卷积层,以及后三层全连接层,其它的都是随机初始化。随机初始化,均值是0,方差是0.01,bias是0.