Dynamic Zoom-in Network for Fast Object Detection in Large Images
Dynamic Zoom-in Network for Fast Object Detection in Large Images
Mingfei Gao1 Ruichi Yu1 Ang Li2_ Vlad I. Morariu3_ Larry S. Davis1
1University of Maryland, College Park 2DeepMind 3Adobe Research
论文地址:https://arxiv.org/abs/1711.05187
Introduction
-
背景介绍
目标检测领域常用数据集有VOC2007/2012(约500×400)和MS COCO(约600×400)等等。在经典的卷积
神经网络(CNN)检测器中,图像是 在低的分辨率下进行卷积操作,计算成本相对低。然而,实际应用中,
我们使用的图片是高分辨率的,已经超过了这些数据集。CNN检测器直接应用于这些高分辨率图像需要大量的处理时间。



-
相关解决方法
通过简化网络结构来加速检测和减少GPU内存消耗;
针对特定的网络结构定制的,不适用于新结构
将图像分割成满足内存的子图像,并对每个子图像进行检测;
计算繁琐
在向下采样的图像上使用现有的检测器;
对小目标的检测效果是不好的
-
研究思路
应用场景:不同大小的物体出现在高分辨率图像中
任务:目标检测
目标:在保持精度的同时,降低了目标检测的计算成本
-
理论基础

目标检测主流的框架:One-Stage:YOLO、SSD; Two-Stage: Faster R-CNN
处理大尺寸图像策略可以是避免处理整个图像,而是按顺序研究小区域
RL是顺序搜索策略的一种机制,其模型应用于具有一系列动作组合的序列化决策场景中
Algorithm
-
Dynamic zoom-in network
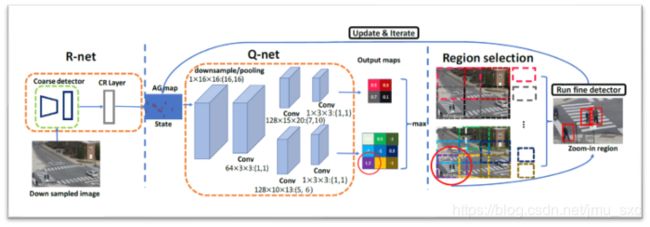
策略:coarse-to-fine ,在低分辨率下应用检测器,并使用该检测器的输出指导对高分辨率图像下目标的深入搜索
•Input: Down Sampled Image
•R-net:Coarse Detector 进行检测,利用其检测结果预测图像目标区域在高分辨率下检测的效益
•Q-net:基于R-net的输出(AG Map),输出若干个可供选择的放大区域
•选择值最大的区域,对其运行Fine Detector,之后不断迭代且对AG Map进行更新重复第三第四步,直到
AG Map值满足某个条件后,结束算法
-
a zoom-in accuracy gain regression network

R-net目标:根据粗检测结果预测特定区域的放大(精检测)精度增益
输入:低分辨率图像(1/2原图像)
Coarse detector:Faster R-CNN
输出:AG map
训练R-net:使用两个预先训练过的检测器应用在一同训练集上,得到两组图像检测结果:
low-resolution: ???,???,???{(d_i^l,p_i^l,f_i^l )} high-resolution: ???,??? {(d_j^l,p_j^l )}
d为检测边界框;p为目标物体的概率;f为对应检测的特征向量,h和l表示高分辨率和低分辨率,i,j分别表示两个检测器预测出目标
match layer:对两个检测方案配对( ??????,???IoU(d_i^l,d_j^l ) >>0.5 ),每个proposal生成一组对应关系: ???,???,??h???{(d_k^l,p_k^l,p_k^h f_k^l )}
CR Layer:估计proposal k的放大精度增益( a zoom-in accuracy gain ), CR层包含两个全连接的层,其中第一层有4096个单元,第二层只有一个输出单元。
训练CR Layer:
输入: ???,???,??h???{(d_k^l,p_k^l,p_k^h f_k^l )}

当高分辨率得分pkl![]() 比低分辨率得分pkh
比低分辨率得分pkh![]() 更接近于Groundtruth时,函数表明proposal k值得进一步放大。否则,在下采样图像上应用检测器可能会产生更高的精度,所以我们应该避免放大proposal k
更接近于Groundtruth时,函数表明proposal k值得进一步放大。否则,在下采样图像上应用检测器可能会产生更高的精度,所以我们应该避免放大proposal k
AG map:根据每个proposal的a zoom-in accuracy gain ,可以生成AG图:
-
a zoom-in Q function network

Q-net任务:AG map作为输入,找一个最可能存在物体的位置,去原图像中取相应的高分辨率图像,运行fine detector,之后进行迭代,AG Map更新,直到到底指定结束条件( AG Map的所有值之和小于0.1)
输入:AG Map
输出:Output Maps:某状态下各个action(区域)的reward
强化学习
机器学习的学习算法分为监督学习,非监督学习,强化学习。
马尔可夫决策过程(序列化决策问题):
三要素:状态(state),动作(action),奖赏(reward)
在每一动作,系统观察当前状态,评估采取不同行动的潜在回报,并选择具有最大长期回报的动作
应用: Alpha Go,Andrew Ng的直升机控制

Action.选择要在高分辨率下分析的区域,每个动作都可以用一个元组(x , y, w , h)表示
State.表示两种类型的信息:
1)待分析区域的预测精度增益
2)已经用高分辨率分析过的区域的历史(避免被多次被分析)
state这里使用AG Map作为状态表示
Cost-aware reward function.

在训练过程中,Q-net使用这个奖励函数来计算采取行动的即时奖励,保证了在有限的计算量下能保持较高的精度
a long-term reward function:
![]()
未来奖励的影响程度 : γ=0.5
在给定当前状态下,采取行动的最优reward等于其当前reward与该行动触发的下一状态下的最优reward的组合
通过Q-Net(DQN)学习一个长期的奖励函数
Loss function:

网络的参数: θi-=θi-C C = 10 γ=0.5 C是一个常数参数
DQN中的target Q网络:采样的方式计算“真实值”, target Q网络是每隔一段时间才会更新,即权重更新的比较慢
ϵ−greedy策略:它以ϵ的概率从所有的action中随机抽取一个;以1−ϵ的概率抽取最大reward 的action
Output maps:
AG Map 经过下采样、卷积后分为两个并行的通道(通过不同的卷积核),每个管道输出action – reward map,对应于具有特定大小的放大区域。值表示该action以低成本提高准确性的可能性
Region selection:
对连两个特定尺寸的若干个区域进行排序,选择最大的reward作为当前状态下的action
Run fine detector:
对被选择的区域,去原图像中取相应的高分辨率图像进行 fine detector。我们得到该区域目标的精细检测结果,然后用精检测的结果替换粗检测的结果。
Update & Iterate:
在对一个区域进行缩放并执行检测之后,AG Map中该区域内的所有值都设置为0,
以防止将来对同一区域进行缩放;不断迭代直到AG Map内的值之和小于0.1,迭代结束
Experimental
-
Window selection refinement

在refinement之前,由于采样稀疏网格的关系,windows很可能会将人切一半,导致检测性能很差。
细化局部调整窗口的位置,产生更好的结果
-
Q-net* vs. GS
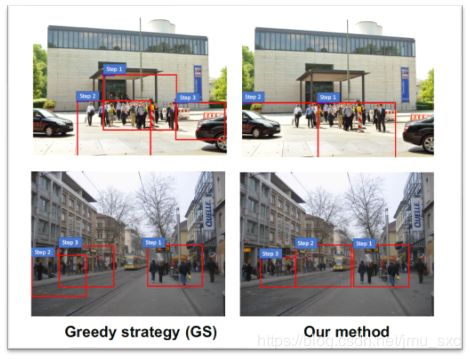
使用Q-net*与贪婪策略(GS)进行定性比较,贪婪策略的每一步选择是预测精度增益最高的区域
Q-net选择的区域在短期内似乎不是最优的,但在长期内缩放序列更好,这导致步骤更少,如第一行所示
-
R-net vs. ER

ER:检测器输出的熵(对象与无对象)是另一种测量粗检测质量的方法
ER的accuracy gain计算:
![]()
在粗检测区域足够好或者优于细检测区域,R-net给出的正面分数相对于ER较低;
而在精细检测比粗检测好得多的区域生成更高的分数
-
Detection accuracy comparisons
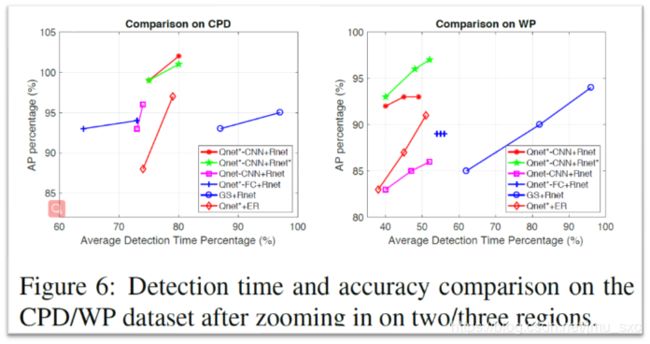
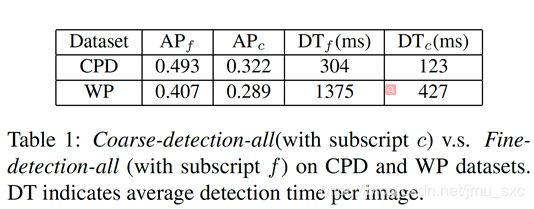
CPD:The image resolution in the CPD dataset is low (640×480)
WP:Images are rescaled to 2,000 pixels on the longer side to fit for our GPU memor
Qnet*:该方法使用Q-net进行细化,对Q-net选择的放大窗口进行局部调整
Rnet*:这是一个R-net学习使用的奖励函数,没有显式编码成本( 朗达= 0)
Qnet-FC:我们为Q-net开发了具有两个完全连接(FC)层的变体,每个输出单元表示图像上的一个采样窗口
-
Ours vs. Single-shot detectors
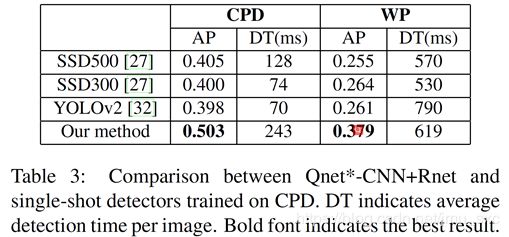
-
Detection accuracy comparisons in terms of Aperc
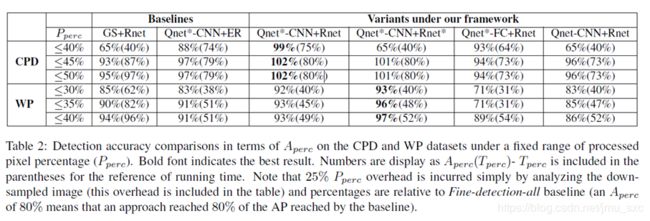
Conclusion
作者提出了一种dynamic zoom-in network,在不改变底层检测器结构的情况下,提高了对大图像的目标检测速度。
首先用R-net对图像进行降采样和处理,以预测放大区域的accuracy gain。
然后,Q-net依次选择放大奖励高的区域进行精细检测。
实验表明,该方法对加州理工学院行人检测数据集(CPD)和高分辨率行人数据集(WP)有效的