论文笔记-DYNET: DYNAMIC CONVOLUTION FOR ACCELERATING CONVOLUTIONAL NEURAL NETWORKS
DYNET: DYNAMIC CONVOLUTION FOR ACCELERATING CONVOLUTIONAL NEURAL NETWORKS
文章出处
- 作者:Yikang Zhang, Jian Zhang, Qiang Wang, Zhao Zhong
- 机构:华为
- 来源:arxiv
- URL:https://arxiv.org/pdf/2004.10694.pdf
文章翻译
摘要
卷积操作是 CNN 的核心,是计算开销的主要来源。为了让 CNN 更高效,一些方法设计轻量的 CNN 模型,一些方法则对模型进行压缩,尽管诸如 MobileNet 和 ShuffleNet 这样的框架已经能够高效运行,作者还是发现卷积核之间存在冗余信息,为了解决这个问题,本文提出动态卷积,用于可调整地基于图像内容生成卷积核,为说明实验结果,作者将动态卷积用于多个 STOA 的 CNN。一方面,动态卷积使得模型在保持原有性能的同时降低计算开销,另一方面,模型保持计算开销不变的情况下可以取得大幅度的性能提升。为验证模型的可拓展性,DyNet 被用于分割任务,实验结果证明:模型在分割任务上保持平均 IoU 的情况下能够降低 69.3% 的 FLOPS。
引言
当前 CNN 已经在很多计算机视觉任务上获得 STOA 性能,但是 CNN 常常需要大量的计算资源来执行卷积核操作,为了让 CNN 能够用于移动端设备,当前许多研究将重心放在构造更轻量、更高效的模型上,这些方法主要分为两类:(1)设计高效模型,(2)压缩模型。
精心构造的高效网络已经取得一定的进展,但是这些网络的卷积核中仍然存在显著的相关性,引入了许多不必要的计算,且这些小网络难以压缩,传统的网络压缩其实并没有很好地解决 CNN 的荣誉计算的问题,作者从理论上对这一现象进行分析,发现这个问题是由于传统卷积操作的本质带来的。由于卷积操作的主要密度在于利用相关核提取噪声无关的特征,因此很难在不降低信息损失的情况下去压缩传统的卷积核,作者还发现,如果在输入的基础上,将几个固定的卷积核线性地融合成新的动态核,则可以在不用多个卷积核的条件下获得噪声无关的特征。
基于上述的观察分析,作者提出动态卷积用于解决之前的问题,通过基于图像内同适应性地生成卷积核。整体框架如下图所示。
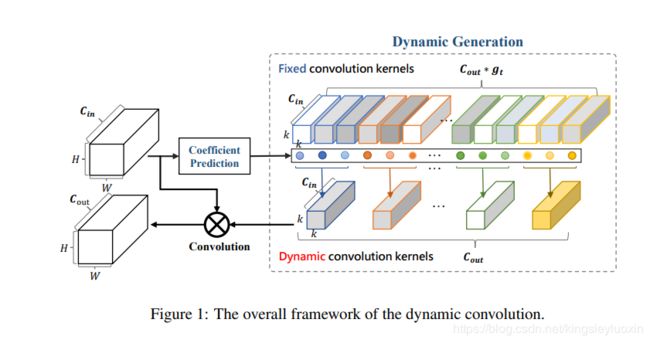
整体框架由两个模块组成:相关系数预测模块和动态生成模块。相关系数预测模块是可训练的,用于预测固定的多个卷积核之间的相关系数,动态生成模块则基于预测的相关系数生成一个动态的卷积核。
提出的方法已于实现,且可以作为任何卷积层的实现插件以减少冗余卷积,作者在多个网络上进行了测试评估,评估结果详见论文。
相关工作
(1)高效 CNN 设计
主要介绍一些相关工作:
- GoogleNet 增加网络深度,比简单堆叠卷积层的复杂度低
- SqueezeNet 利用 bottleneck 设计小网络
- Xception 和 MobileNet 使用深度层次可分离的卷积降低模型大小和计算开销
- ShuffleNet 通过滑动通道的方式降低 1x1 卷积的计算开销
- MobileNetV3 基于搜索技巧蛇口
但是这些方法还是存在冗余计算,动态卷积可以减少冗余计算,对这些网络进行弥补
(2)网络压缩
- 基于因子分解的方法使用张良分析来近似原有的卷积操作
- 基于知识蒸馏的方法利用一个较小的网络来模拟原有的更大的教师网络
- 基于剪枝的方法将冗余的链接或者卷积通道进行卷积
比起这些方法而言,DyNet 更为高效,尤其是针对本身已经非常精简高效的网络。
(3)动态卷积核
生成动态卷积核在 CV 和 NLP 任务中都已经出现。
- 通过基于之前的网络层的特征图的线性层生成卷积核,由于卷积核有大量参数,因而线性层硬件实现上并不高效。作者提出的方法仅仅预测将固定的几个核线性组合的相关系数,因此可以在硬件上进行 CNN 加速。
- NLP 领域常常用上下文信息生成输入相关的卷积滤波器,根据不同长度的输入句子,这些滤波器可以适应性地调整。这些方法也是通过线性层生成卷积操作,但是 NLP 领域的 CNN 大学和卷积核维度都要小一些,所以计算开销问题得以解决。
DyNet:CNN 中的动态卷积
(1)设计动机
深度模型中的卷积核具有天然的相关性,下图所示为深度模型的特征图之间的相关系数
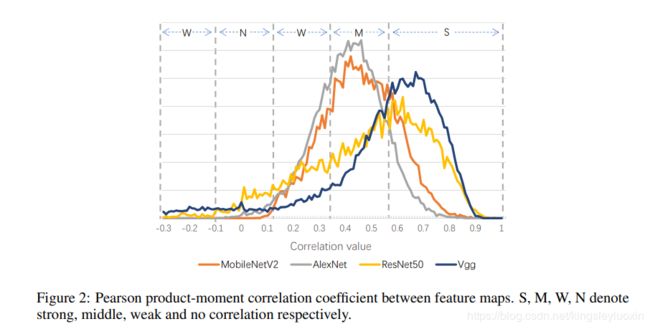
现有的工作通过压缩网络来减少这种相关,但是压缩对于 MobileNet 这样的小网络不是很容易实现,此外,这些相关其实是有必要的,因为这些相关有助于获取噪声无关的特征,以人脸识别为例,姿势或者光照条件应当是不影响识别分类结果的,因此,特征图必须随着网络层次加深而变得与噪声无关,基于附件 A 的理论分析,作者发现这个获取噪声无关的特征的过程需要多个相关的卷积核共同参与,但是如果可以将多个固定的核进行融合,则可以不需要他们的共同参与,因此本文提出动态卷积方法,学习相关系数用于将多个核融合成一个基于输入图像的动态核,动机的深入分析见论文的附录 A。
(2)动态卷积
动态卷积的目标在于学习一组核的相关系数,用于将多个固定的核融成一个动态核,图1所示框架中的 2 个主要模块详细介绍如下:
相关系数预测模块

上图所示为系数预测模块,系数预测基于输入的图像内容预测相关系数,该模块可以分解为一个全局平均池化层 GAP 和一个 有 Sigmoid 激活层的全连接层 FC,GAP 将输入的特征图聚合转换成 1x1x C i n C_{in} Cin 的向量,作为特征提取层,全连接层将该向量映射到一个 1x1xC 的向量,代表了多个动态卷积层的固定卷积核。
动态生成模块
每个动态卷积层权重为 [ C o u t × g t , C i n , k , k ] [C_{out} \times g_t,C_{in},k,k] [Cout×gt,Cin,k,k],对应到 c o u t × g t c_{out} \times g_t cout×gt 个固定核和 c o u t c_{out} cout 个动态核,其中每个核的大小为 [ C i n , k , k ] [C_{in},k,k] [Cin,k,k], g t g_t gt 代表组大小,是超参数,将固定核表示为 w t i w_t^i wti,动态和表示为 w ~ t \widetilde w_t w t,相关系数表示为 η t i \eta_t^i ηti,其中 t = 0 , . . . , C o u t , i = 0 , . . . , g t t = 0,...,C_{out},i = 0,...,g_t t=0,...,Cout,i=0,...,gt
获取相关系数之后,通过下面的式子生成动态核
w ~ t = ∑ i = 1 g t η t i ⋅ w t i \widetilde w_t=\sum_{i=1}^{g_t}{\eta_t^i \cdot w_t^i} w t=i=1∑gtηti⋅wti
训练算法
为了训练提出的动态卷积,不适合适用于基于批量的训练方案,因为每个小批量的图像输入大小不同,所以其卷积核也不一样,故在训练中基于相关系数而不是基于核来进行多个特征图的融合,见下式所示:
O ~ t = w ~ t ⊗ x = ∑ i = 1 g t η t i ⋅ w t i ⊗ x = ∑ i = 1 g t ( η t i ⋅ w t i ⊗ x ) = ∑ i = 1 g t ( η t i ⋅ ( w t i ⊗ x ) ) = ∑ i = 1 g t ( η t i ⋅ O t i ) \widetilde O_t=\widetilde w_t \otimes x \\ = \sum_{i=1}^{g_t}{\eta_t^i \cdot w_t^i} \otimes x\\ = \sum_{i=1}^{g_t}{(\eta_t^i \cdot w_t^i\otimes x)}\\ =\sum_{i=1}^{g_t}{(\eta_t^i \cdot ( w_t^i\otimes x))}\\ =\sum_{i=1}^{g_t}{(\eta_t^i \cdot O_t^i)} O t=w t⊗x=i=1∑gtηti⋅wti⊗x=i=1∑gt(ηti⋅wti⊗x)=i=1∑gt(ηti⋅(wti⊗x))=i=1∑gt(ηti⋅Oti)
x x x 表示输入, O ~ t \widetilde O_t O t 表示动态核 w ~ t \widetilde w_t w t 的输出, O t i O_t^i Oti 表示固定核 w t i w_t^i wti 的输出。