系列
redis数据淘汰原理
redis过期数据删除策略
redis server事件模型
redis cluster mget 引发的讨论
redis 3.x windows 集群搭建
redis 命令执行过程
redis string底层数据结构
redis list底层数据结构
redis hash底层数据结构
redis set底层数据结构
redis zset底层数据结构
redis 客户端管理
redis 主从同步-slave端
redis 主从同步-master端
redis 主从超时检测
redis aof持久化
redis rdb持久化
redis 数据恢复过程
redis TTL实现原理
redis cluster集群建立
redis cluster集群选主
redis数据存储结构
redis的内部整体的存储结构就是一个大的hashmap,内部实现是数组实现hash,冲突通过挂链去实现,然后每个dictEntry就是一个key/value对象。dictEntry的key指向set key value命令中的key对应的对象,dictEntry的v指向set key value命令中的value对应的对象。
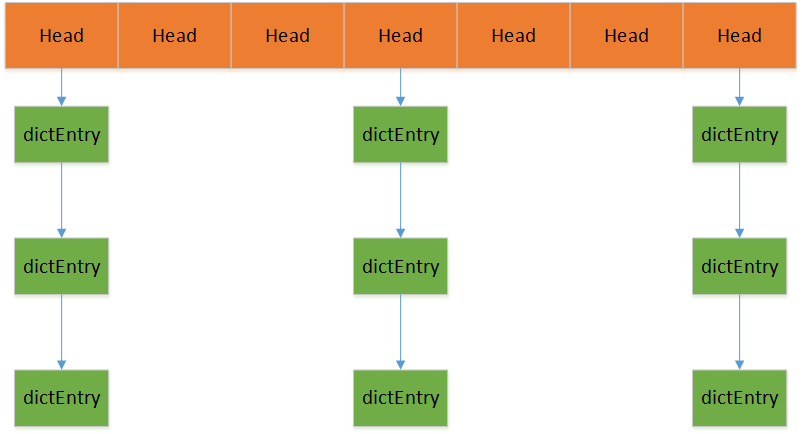
dictEntry 内部包含数据存储的key和v变量,同时包含一个dictEntry的next指针连接落入同一个hash桶的对象。dictEntry当中的key和v的指针指向的是redisObject。
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
redisObject是redis server存储最原子数据的数据结构,其中的void *ptr会指向真正的存储数据结构,我们set key value中的key和value其实由ptr指向真正保存的位置。
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
// 引用计数
int refcount;
// 指向实际值的指针
void *ptr;
} robj;
redis string类型转换
我们可能以为redis在内部存储string都是用sds的数据结构实现的,其实在整个redis的数据存储过程中为了提高性能,内部做了很多优化。整体选择顺序应该是:
整数,存储字符串长度小于21且能够转化为整数的字符串。
EmbeddedString,存储字符串长度小于39的字符串(REDIS_ENCODING_EMBSTR_SIZE_LIMIT)。
SDS,剩余情况使用sds进行存储。
embstr和sds的区别在于内存的申请和回收
embstr的创建只需分配一次内存,而raw为两次(一次为sds分配对象,另一次为redisObject分配对象,embstr省去了第一次)。相对地,释放内存的次数也由两次变为一次。
embstr的redisObject和sds放在一起,更好地利用缓存带来的优势
缺点:redis并未提供任何修改embstr的方式,即embstr是只读的形式。对embstr的修改实际上是先转换为raw再进行修改。
string编码转换源码分析
通过redis 内部的命令映射表我们找到set对应的处理函数为setCommand,相当于这个是处理set命令的入口函数,关注下tryObjectEncoding,内部对其实对Object进行转换。
/* SET key value [NX] [XX] [EX ] [PX ] */
void setCommand(redisClient *c) {
int j;
robj *expire = NULL;
int unit = UNIT_SECONDS;
int flags = REDIS_SET_NO_FLAGS;
// 设置选项参数
for (j = 3; j < c->argc; j++) {
char *a = c->argv[j]->ptr;
robj *next = (j == c->argc-1) ? NULL : c->argv[j+1];
if ((a[0] == 'n' || a[0] == 'N') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0') {
flags |= REDIS_SET_NX;
} else if ((a[0] == 'x' || a[0] == 'X') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0') {
flags |= REDIS_SET_XX;
} else if ((a[0] == 'e' || a[0] == 'E') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0' && next) {
unit = UNIT_SECONDS;
expire = next;
j++;
} else if ((a[0] == 'p' || a[0] == 'P') &&
(a[1] == 'x' || a[1] == 'X') && a[2] == '\0' && next) {
unit = UNIT_MILLISECONDS;
expire = next;
j++;
} else {
addReply(c,shared.syntaxerr);
return;
}
}
// 尝试对值对象进行编码
c->argv[2] = tryObjectEncoding(c->argv[2]);
setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);
}
整个尝试编码转换的逻辑过程通过代码的注释应该是比较清楚了,过程如下:
- 只对长度小于或等于 21 字节,并且可以被解释为整数的字符串进行编码,使用整数存储
- 尝试将 RAW 编码的字符串编码为 EMBSTR 编码,使用EMBSTR 编码
- 这个对象没办法进行编码,尝试从 SDS 中移除所有空余空间,使用SDS编码
/* Try to encode a string object in order to save space */
// 尝试对字符串对象进行编码,以节约内存。
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
redisAssertWithInfo(NULL,o,o->type == REDIS_STRING);
// 只在字符串的编码为 RAW 或者 EMBSTR 时尝试进行编码
if (!sdsEncodedObject(o)) return o;
// 不对共享对象进行编码
if (o->refcount > 1) return o;
// 对字符串进行检查
// 只对长度小于或等于 21 字节,并且可以被解释为整数的字符串进行编码
len = sdslen(s);
if (len <= 21 && string2l(s,len,&value)) {
if (server.maxmemory == 0 &&
value >= 0 &&
value < REDIS_SHARED_INTEGERS)
{
decrRefCount(o);
incrRefCount(shared.integers[value]);
return shared.integers[value];
} else {
if (o->encoding == REDIS_ENCODING_RAW) sdsfree(o->ptr);
o->encoding = REDIS_ENCODING_INT;
o->ptr = (void*) value;
return o;
}
}
// 尝试将 RAW 编码的字符串编码为 EMBSTR 编码
if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
if (o->encoding == REDIS_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
decrRefCount(o);
return emb;
}
// 这个对象没办法进行编码,尝试从 SDS 中移除所有空余空间
if (o->encoding == REDIS_ENCODING_RAW &&
sdsavail(s) > len/10)
{
o->ptr = sdsRemoveFreeSpace(o->ptr);
}
/* Return the original object. */
return o;
}
redis sds的介绍
在C语言中,字符串可以用'\0'结尾的char数组标示。这种简单的字符串表示,在大多数情况下都能满足要求,但是不能高效的计算length和append数据。所以Redis自己实现了SDS(简单动态字符串)的抽象类型。
SDS的数据结构如下,len表示sdshdr中数据的长度,free表示sdshdr中剩余的空间,buf表示实际存储数据的空间。
sdslen的函数有一个细节需要我们注意,那就是通过(s-(sizeof(struct sdshdr)))来计算偏移量,之所以需要这么计算是因为sds的指针指向的是char buf[]位置,所以我们需要访问sdshdr的首地址的时候需要减去偏移量。
/*
* 保存字符串对象的结构
*/
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
};
/*
* 返回 sds 实际保存的字符串的长度
*
* T = O(1)
*/
static inline size_t sdslen(const sds s) {
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->len;
}
/*
* 返回 sds 可用空间的长度
*
* T = O(1)
*/
static inline size_t sdsavail(const sds s) {
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->free;
}
sds对象创建
在创建sds对象的时候,我们上面提到过的涉及两次内存分配的过程,从下面的代码可以看出来:
- sds对象创建sdsnewlen分配了一次内存。
- robj对象的创建又分配了一次内存。
整个sds对象的创建其实就是分配内存并初始化len和free字段。
/* Create a string object with encoding REDIS_ENCODING_RAW, that is a plain
* string object where o->ptr points to a proper sds string. */
// 创建一个 REDIS_ENCODING_RAW 编码的字符对象
// 对象的指针指向一个 sds 结构
robj *createRawStringObject(char *ptr, size_t len) {
return createObject(REDIS_STRING, sdsnewlen(ptr,len));
}
/*
* 根据给定的初始化字符串 init 和字符串长度 initlen
* 创建一个新的 sds
*
* 参数
* init :初始化字符串指针
* initlen :初始化字符串的长度
*
* 返回值
* sds :创建成功返回 sdshdr 相对应的 sds
* 创建失败返回 NULL
*
* 复杂度
* T = O(N)
*/
sds sdsnewlen(const void *init, size_t initlen) {
struct sdshdr *sh;
// 根据是否有初始化内容,选择适当的内存分配方式
// T = O(N)
if (init) {
// zmalloc 不初始化所分配的内存
sh = zmalloc(sizeof(struct sdshdr)+initlen+1);
} else {
// zcalloc 将分配的内存全部初始化为 0
sh = zcalloc(sizeof(struct sdshdr)+initlen+1);
}
// 内存分配失败,返回
if (sh == NULL) return NULL;
// 设置初始化长度
sh->len = initlen;
// 新 sds 不预留任何空间
sh->free = 0;
// 如果有指定初始化内容,将它们复制到 sdshdr 的 buf 中
// T = O(N)
if (initlen && init)
memcpy(sh->buf, init, initlen);
// 以 \0 结尾
sh->buf[initlen] = '\0';
// 返回 buf 部分,而不是整个 sdshdr
return (char*)sh->buf;
}
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = REDIS_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution). */
o->lru = LRU_CLOCK();
return o;
}
sds内存扩容
当字符串长度小于SDS_MAX_PREALLOC (1024*1024),那么就以2倍的速度扩容,当字符串长度大于SDS_MAX_PREALLOC,那么就以+SDS_MAX_PREALLOC的速度扩容。
/*
* 对 sds 中 buf 的长度进行扩展,确保在函数执行之后,
* buf 至少会有 addlen + 1 长度的空余空间
* (额外的 1 字节是为 \0 准备的)
*
* 返回值
* sds :扩展成功返回扩展后的 sds
* 扩展失败返回 NULL
*
* 复杂度
* T = O(N)
*/
sds sdsMakeRoomFor(sds s, size_t addlen) {
struct sdshdr *sh, *newsh;
// 获取 s 目前的空余空间长度
size_t free = sdsavail(s);
size_t len, newlen;
// s 目前的空余空间已经足够,无须再进行扩展,直接返回
if (free >= addlen) return s;
// 获取 s 目前已占用空间的长度
len = sdslen(s);
sh = (void*) (s-(sizeof(struct sdshdr)));
// s 最少需要的长度
newlen = (len+addlen);
// 根据新长度,为 s 分配新空间所需的大小
if (newlen < SDS_MAX_PREALLOC)
// 如果新长度小于 SDS_MAX_PREALLOC
// 那么为它分配两倍于所需长度的空间
newlen *= 2;
else
// 否则,分配长度为目前长度加上 SDS_MAX_PREALLOC
newlen += SDS_MAX_PREALLOC;
// T = O(N)
newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1);
// 内存不足,分配失败,返回
if (newsh == NULL) return NULL;
// 更新 sds 的空余长度
newsh->free = newlen - len;
// 返回 sds
return newsh->buf;
}
sds内存缩容
释放内存的过程中修改len和free字段,并不释放实际占用内存。
/*
* 在不释放 SDS 的字符串空间的情况下,
* 重置 SDS 所保存的字符串为空字符串。
*
* 复杂度
* T = O(1)
*/
void sdsclear(sds s) {
// 取出 sdshdr
struct sdshdr *sh = (void*) (s-(sizeof(struct sdshdr)));
// 重新计算属性
sh->free += sh->len;
sh->len = 0;
// 将结束符放到最前面(相当于惰性地删除 buf中的内容)
sh->buf[0] = '\0';
}