猫眼电影排行榜前100爬取案例学习笔记
最近在学习崔庆才老师著作的《python3 网络爬虫开发实战》,对爬取猫眼排名榜前100电影的讲解案例,产生一些小想法,结合pandas 在数据分析方面的应用,给出以下学习笔记,作为rockyliu学习爬虫成长道路上的one small step.
话不多说,先汇总本次爬取的目标:
- 1)获取猫眼排名榜前100电影
- 2)获取前100电影图片存放在本地
- 3)获取前100电影的英文名称
- 4)通过百度百科获取电影区域归属
- 5)展示前100电影的上映时间分布
- 6)展示参演频率最高的前5位演员及所参演电影
是不是感觉rockyliu有点贪,让我们拭目以待吧。
实现目标1:获取猫眼排名榜前100电影
先上效果图:

如效果图,通过爬虫代码,从猫眼电影排行榜上,获取前100的电影的相关信息(排名/电影海报地址/电影名/主演/上映时间/评分)。接下来上代码,供大家参考学习:
import requests
import re
import time
from requests.exceptions import RequestException
import pandas as pd
#先定义一个获取网站源代码的方法
def get_one_page(url):
#使用try方法,防止程序中断报错
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
# rockyliu 偏好 写出print('wrong1:获取一个网站源代码出错'),便于快速查找问题
#定义一个对源代码解析,并利用正则表达式获取想要的值,再结合pandas库,生成pandas.DataFrame数据
def parse_one_page(html):
#该处的正则表达式,可能会随着时间推移而改变,若报错,请读者自行更新哟
pattern = re.compile(
'.*?board-index.*?>(.*?).*?data-src="(.*?)".*?name.*?a.*?>(.*?).*?star.*?>(.*?).*?releasetime.*?>(.*?).*?integer.*?>(.*?).*?fraction.*?>(.*?).*? ',re.S)
items = re.findall(pattern,html)
pf = pd.DataFrame()
for item in items:
a = [item[0],item[1],item[2].strip(),item[3].strip()[3:] if len(item[3])>3 else '',item[4].strip()[5:] if len(item[4])>5 else '',item[5].strip()+item[6].strip()]
#需要注意item[5]代表评分整数,item[6]代表评分小数,因此合计评分要两者相加
pf_ = pd.DataFrame(a)
pf = pd.concat([pf,pf_.T]) #要注意pf_.T,即转置小细节,否则会报错哟
yield pf
'''通过yield函数生成一个汇总的pd.DataFrame数据(小细节,yield 只能存在函数表达式中(def balaba:),否则就会出现outside function报错 )
'''
#定义一个写入文档函数:
def write_to_file(offset):
url = 'https://maoyan.com/board/4?offset='+str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item.shape)
#如果是第一个网页,即前10电影,增加一个列表头,其他则不增加,以header = True /False 体现
if offset == 0:
item.columns = ['index','image_url','title','actor','time','score']
item.to_csv('result.csv',mode='a',encoding='gbk',index=False)
else:
item.to_csv('result.csv',mode='a',encoding='gbk',index=False,header=False)
'''
小细节,要增加encoding = 'gbk'和mode='a',相信rockyliu没有错
生成的result.csv,就存在python代码所在的文件夹内。rockyliu建议写成绝对路径:r'D:\bala\result.csv'
'''
#定义一个获取前X*10的电影函数
def get_top_movie(top=10):
# if 函数,主要为了防止出现非1-10的值
if (not isinstance(top,int)):
print('wrong2:输入值不为整数')
elif (top>10) | (top<1):
print('wrong3:输入值不在1-10内')
else:
for i in range(top):
write_to_file(offset=i*10)
time.sleep(1)
#最后一步,调用函数
get_top_movie()
通过上述代码,我们实现了目标1)获取猫眼排名榜前100电影,
实现目标2:获取前100电影图片存放在本地
先上效果图:
满屏幕的图片是不是很赞呢?立刻贴代码:
import requests
import pandas as pd
from requests.exceptions import RequestException
import time
#读取前100电影海报图片url地址
pf = pd.read_csv('result.csv',encoding='gbk')
#爬虫的报文头,headers主要就是模拟浏览器登陆,否则可能会获取不到相关图片
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
for i in range(100):
url = pf.iloc[i,1]
movie_image_name =str(i+1)+'-' + pf.iloc[i,2]
'''
小细节,str(i+1)+'-'就是为了快速辨识电影的排名.
若不加上str(),直接(i+1)+'-'会报错哟
'''
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
content = response.content
'''
小细节,如果写成response.text 不能正常写入哟。会报 'gbk' codec can't encode character '\ufffd' in position 0: illegal multibyte sequence
'movie_image\\',要记得先在代码所在文件夹中新建一个movie_image的文件夹,否则会报错的哟
'\\'多出一个'\'是因为为了转义,不要漏了哟
'''
movie_image_path = 'movie_image\\' + movie_image_name +'.jpg'
with open(movie_image_path,'wb') as f:
f.write(content)
else:
print('wrong1:获取图片错误')
print(response.status_code)
except RequestException:
print('wrong1:获取图片错误')
print(i) # 要不然,空等着程序跑,看着着急死人
time.sleep(1)
实现目标3:获取前100电影的英文名称

通过百度百科获取前100电影的外文名称和制片地区,着实不易。anyway,贴上代码跟大家一起分享:
import requests
import re
import pandas as pd
import time
from requests.exceptions import RequestException
inputfile = 'result.csv'
# 利用pandas读取前面从猫眼电影上爬取的数据
pf = pd.read_csv('result.csv',encoding='gbk')
# 新增三列,分别为 name_en - 外文名称,movie_area - 制片地址,movie_base_info- 电影基本信息
title = pf['title']
pf['name_en'] = None
pf['movie_area'] = None
pf['movie_base_info'] = None
'''
百科的搜索地址,是rockyliu浏览众多网页中找到的,官网是要进行商务合作且收费的。若读者用于商业用途,则有可能造成侵权
'''
url_ = 'http://baike.baidu.com/search/word?word='
'''
定义一个获取百度百科指定电影的网页
模块代码冷知识:爬取到的百科网页编码为ISO-8859-1,需要response.text.encode('ISO-8859-1').decode("utf-8"),进行特殊处理,否则将报错哟。各种编码问题,今后找时间跟大家讲解下
'''
def get_movie_extra(url):
try:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text.encode('ISO-8859-1').decode("utf-8")
return None
except RequestException:
return None
'''
对获取的网页内容进行关键字提取获取
利用chrome浏览器中开发者工具,可以获取当前网页内容,结合notepad++,非常非常提高对网页的分析。
从中获取关键的字符有:class="basicInfo-item name和class="basicInfo-item value,围绕这两个关键字符,给出正则表达式
鉴于name/value组合,创建一个字典,便于今后提取相关字段和值
rockyliu的正则表达式玩的还不溜,所以,需要对name和value进行二次处理。读者有好的正则表达式,欢迎在评论区回答。毕竟正则表达式的书写是一门艺术
定义函数时,最好是用到return
'''
def parse_movie_extra(html):
pattern = re.compile('(.*?) .*?(.*?)','',list_values[i],re.S).replace(' ','').replace('\n','')
dic = dict(zip(list_keys,list_values))
return dic
'''
提取title列,进行for循环,分别给出name_en/movie_area/movie_base_info的值
特别说一句,最新的pandas库,要求赋值,最好利用 .at[index,column]=value的方式,而非pf[column][index]=value
增加time.sleep(1),主要担心爬取过快,被对方封IP
增加print('已完成%d个查找'%(i+1)),便于知道当前进度,心里有数
'''
for i in range(len(title)):
url = url_+title[i]
html = get_movie_extra(url)
dict1 = parse_movie_extra(html)
pf.at[i, 'name_en'] = dict1.get('外文名',None)
pf.at[i,'movie_area'] = dict1.get('制片地区',None)
pf.at[i,'movie_base_info'] = dict1
time.sleep(1)
print('已完成%d个查找'%(i+1))
pf.to_csv('result1.csv',encoding='utf_8_sig',index=False)#
'''
本次数据格式,有gbk,有utf-8,有ISO-8859-1,用excel打开后,一直报错,网上查了资料,用encoding='utf_8_sig'utf_8_sig,完美解决。
index =False ,一定不要丢了,否则,朋友试下就知道,嘿嘿。
'''
print('完成任务')
完成目标1,2,3,4后,基本上想要的数据已经全了。接下来目标5,6,都是数据分析展示了。
目标5)展示前100电影的上映时间分布 效果图(好片于2010-2013扎堆上映)
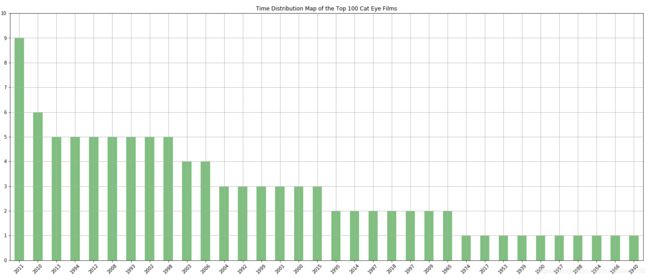
6)展示参演频率最高的前5位演员及所参演电影 效果图(哥哥是最高产的)

贴代码咯
import pandas as pd
import re
'''
读取已经添加百度百科的数据
挑选出我们需要的几个列字段,index/排名,title/名称,actor/主演,time/上映时间,name_en/外文名称,movie_area/上映地区
'''
pf = pd.read_csv('result1_1.csv')
pf = pf[['index', 'title', 'actor', 'time', 'name_en', 'movie_area']]
# 提取前四个数字,即获得相应的年份
func_time = lambda string: re.match('\d{4}',string).group()
pf['time'] = pf['time'].apply(func_time)
# 利用pandas.plot.bar展示上映年份的柱状图
pd.value_counts(pf['time']).plot.bar(figsize=(25,10),yticks=range(11),grid=True,rot=45,alpha=0.5,title='Time Distribution Map of the Top 100 Cat Eye Films',color='g')
#将主演列拆分为一个一个演员列表,用于分析
#.replace(',',',').split(','),先更换部分中文逗号,再拆分成列表
func_actor = lambda x: x.replace(',',',').split(',')
pf['actor_'] = pf['actor'].apply(func_actor)
#获取拆分出来的主演人员数量,为下一步分析做铺垫。本次分析出来,发现只有3和1
pf['actor_num'] = pf['actor_'].apply(len)
#新建列,actor_01/主演1,actor_02/主演2,actor_03/主演3
pf['actor_01'] =None
pf['actor_02'] =None
pf['actor_03'] =None
#赋值actor_01/主演1,actor_02/主演2,actor_03/主演3
for i in range(pf['actor_'].shape[0]):
if len(pf['actor_'][i])==3:
pf.at[i,'actor_01'] = pf['actor_'][i][0]
pf.at[i,'actor_02'] = pf['actor_'][i][1]
pf.at[i,'actor_03'] = pf['actor_'][i][2]
else:
pf.at[i,'actor_01'] = pf['actor_'][i][0]
'''
创建演员列表,用于分析每个演员出现的次数
isinstance(pf['actor_'][i],list)担心部分主演仅有一个,就成字符串而非列表,字符串不能直接和列表相加
'''
list_actor = []
for i in range(pf['actor_'].shape[0]):
if isinstance(pf['actor_'][i],list):
list_actor = list_actor+pf['actor_'][i]
else:
list_actor = list_actor + list(pf['actor_'][i])
#使用pd.value_counts(pd.Series),获取排名
list_actor = pd.Series(list_actor)
#创建一个空的pd.DataFrame()数据
# 新增参演电影数/movie_num,演员/actor两列
actor_top10 = pd.DataFrame()
actor_top10['movie_num'] = pd.value_counts(list_actor)[:10]
actor_top10['actor'] = pd.value_counts(list_actor)[:10].index
# 定义一个函数,用于获取参演电影名称
#actor_top10['pactor_top10_movies_list'] = None 创建列:pactor_top10_movies_list/参演电影
# 一定要用上.copy(),避免原始pf数据字段值被覆盖,或错误引用index值
def actor_top10_movies(actor_top10,pf):
actor_top10['pactor_top10_movies_list'] = None
for i in range(len(actor_top10['actor'])):
pf_ = pf[(pf['actor_01']==actor_top10['actor'][i]) | (pf['actor_02']==actor_top10['actor'][i]) |(pf['actor_03']==actor_top10['actor'][i])].copy()
actor_top10['actor_top10_movies_list'][i] = list(pf_['title'])
#调用函数
actor_top10_movies(actor_top10,pf)
#更改index值和名称
actor_top10.index=range(10)
actor_top10.index.name='order'
#打印出来,完工
print(actor_top10)
print('完工,开心!')借助演员分布的分析思路,各位读者可以对上映地区进行分布分析,欢迎在评论区展示。
此外,想知道1940年上映的电影,可以在评论区留言哟。
部分爬虫代码来自崔庆才老师的著作《python3网络爬虫开发实战》,若侵权,请联系,rockyliu将第一时间删除,谢谢。