使用Titanic 数据集,通过特征筛选的方法一步步提升决策树的预测性能
运行python机器学习及实践代码59会出错,本人经过调试对其进行改进,主要原因是因为python 的版本不同,我的是python3
源代码:
import pandas as pd
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
y = titanic['survived']#将survived属性列抽取出来赋给y作为标签值
x = titanic.drop(['row.names', 'name', 'survived'], axis=1)#将row.names,names,survived三列去掉,不作为属性特征
x.info()
x['age'].fillna(x['age'].mean(), inplace=True)#age属性列有些值缺少了,采用这一属性的其他值的平均值来进行填充
x.fillna('UNKNOWN', inplace=True)#对于其他属性值的缺少,全部用unknown来填充
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=33)
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
x_train = vec.fit_transform(x_train.to_dict(orient='record'))
x_test = vec.transform(x_test.to_dict(orient='record'))
print(len(vec.feature_names_))
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(criterion='entropy')
dt.fit(x_train, y_train)
print(dt.score(x_test, y_test))
#从sklearn导入特征筛选器
from sklearn import feature_selection
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=20)
x_train_fs = fs.fit_transform(x_train, y_train)
dt.fit(x_train_fs, y_train)
x_test_fs = fs.transform(x_test)
print(dt.score(x_test_fs, y_test))
from sklearn.model_selection import cross_val_score
import numpy as np
percentiles = range(1, 100, 2)
results = []
for i in percentiles:
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=i)
x_train_fs = fs.fit_transform(x_train, y_train)
scores = cross_val_score(dt, x_train_fs, y_train, cv=5)
results = np.append(results, scores.mean())
print(results)
opt = np.where(results == results.max())[0]
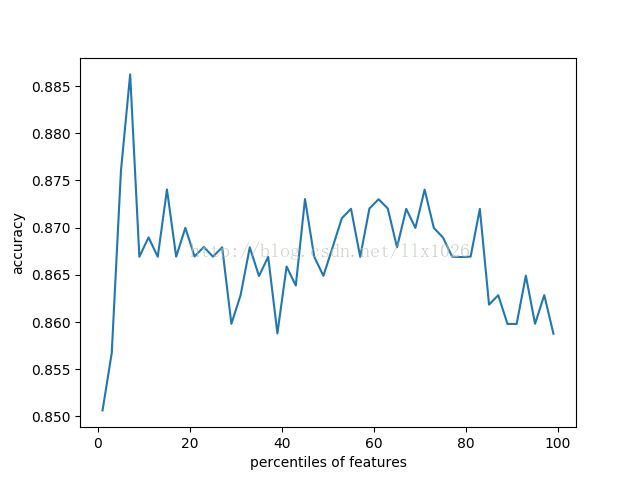
print('Optimal number of features %d'%percentiles[opt])
import pylab as pl
pl.plot(percentiles, results)
pl.xlabel('percentiles of features')
pl.ylabel('accuracy')
pl.show()
from sklearn import feature_selection
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=7)
x_train_fs = fs.fit_transform(x_train, y_train)
dt.fit(x_train_fs, y_train)
x_test_fs = fs.transform(x_test)
dt.score(x_test_fs, y_test)
Traceback (most recent call last):
File "D:/Python362/a_机器学习及实战/features_choose.py", line 51, in
print('Optimal number of features %d'%percentiles[opt])
TypeError: only integer scalar arrays can be converted to a scalar index import pandas as pd
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
y = titanic['survived']#将survived属性列抽取出来赋给y作为标签值
x = titanic.drop(['row.names', 'name', 'survived'], axis=1)#将row.names,names,survived三列去掉,不作为属性特征
x.info()
x['age'].fillna(x['age'].mean(), inplace=True)#age属性列有些值缺少了,采用这一属性的其他值的平均值来进行填充
x.fillna('UNKNOWN', inplace=True)#对于其他属性值的缺少,全部用unknown来填充
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=33)
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
x_train = vec.fit_transform(x_train.to_dict(orient='record'))
x_test = vec.transform(x_test.to_dict(orient='record'))
print(len(vec.feature_names_))
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(criterion='entropy')
dt.fit(x_train, y_train)
print(dt.score(x_test, y_test))
#从sklearn导入特征筛选器
from sklearn import feature_selection
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=20)
x_train_fs = fs.fit_transform(x_train, y_train)
dt.fit(x_train_fs, y_train)
x_test_fs = fs.transform(x_test)
print(dt.score(x_test_fs, y_test))
from sklearn.model_selection import cross_val_score
import numpy as np
percentiles = range(1, 100, 2)
results = []
for i in percentiles:
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=i)
x_train_fs = fs.fit_transform(x_train, y_train)
scores = cross_val_score(dt, x_train_fs, y_train, cv=5)
results = np.append(results, scores.mean())
print(results)
#print(results.max())
#print(results == results.max())调试所用
print(np.where(results == results.max()))#返回的是一个(array([3], dtype=int64),)元组形式的数据,我们需要的是这个results.max的索引,3正是索引,
#我们就要想办法把3提取出来,可以看出[3]是一个array也就是矩阵形式的,那么3所在的位置是一行一列,所以在下一步骤做相应的提取
opt = np.where(results == results.max())[0][0]#这一句跟源代码有出入,查看文档np.where返回的是 ndarray or tuple of ndarrays类型数据
print('Optimal number of features %d'%percentiles[opt])
import pylab as pl
pl.plot(percentiles, results)
pl.xlabel('percentiles of features')
pl.ylabel('accuracy')
pl.show()
from sklearn import feature_selection
fs = feature_selection.SelectPercentile(feature_selection.chi2, percentile=7)
x_train_fs = fs.fit_transform(x_train, y_train)
dt.fit(x_train_fs, y_train)
x_test_fs = fs.transform(x_test)
dt.score(x_test_fs, y_test)
最终定位结果如下:
RangeIndex: 1313 entries, 0 to 1312
Data columns (total 8 columns):
pclass 1313 non-null object
age 633 non-null float64
embarked 821 non-null object
home.dest 754 non-null object
room 77 non-null object
ticket 69 non-null object
boat 347 non-null object
sex 1313 non-null object
dtypes: float64(1), object(7)
memory usage: 82.1+ KB
474
0.814589665653
0.817629179331
[ 0.85063904 0.85673057 0.87602556 0.88622964 0.86691404 0.86896516
0.86691404 0.87404659 0.86692435 0.86997526 0.86694496 0.86795506
0.86692435 0.86791383 0.85981241 0.86284271 0.86791383 0.86487322
0.86690373 0.858792 0.86588332 0.86386312 0.87302618 0.86691404
0.86489384 0.86791383 0.87098536 0.87199546 0.86690373 0.87202639
0.87300557 0.87201608 0.86791383 0.87198516 0.86996496 0.87402597
0.86996496 0.86894455 0.86691404 0.86688312 0.86692435 0.87198516
0.86184292 0.86284271 0.8598021 0.8597918 0.86491445 0.85981241
0.86285302 0.85876108]
Optimal number of features 7