Kaggle比赛经验总结之Titanic: Machine Learning from Disaster
这是个根据旅客信息判断他是否幸存的二分类问题,适合机器学习新手入门。本文记录了我大致的处理思路和步骤,然后总结了一下经验,同时有助于特征工程和pandas的学习。
我的准确率:0.80383
代码地址:点我
一,观察数据:
•PassengerID(ID)
•Survived(存活与否)
•Pclass(客舱等级,较为重要)
•Name(姓名,可提取出更多信息)
•Sex(性别,较为重要)
•Age(年龄,较为重要)
•Parch(直系亲友)
•SibSp(旁系)
•Ticket(票编号)
•Fare(票价)
•Cabin(客舱编号)
•Embarked(上船的港口编号)
我用python的pandas读入csv为df,在notebook中它长这样:
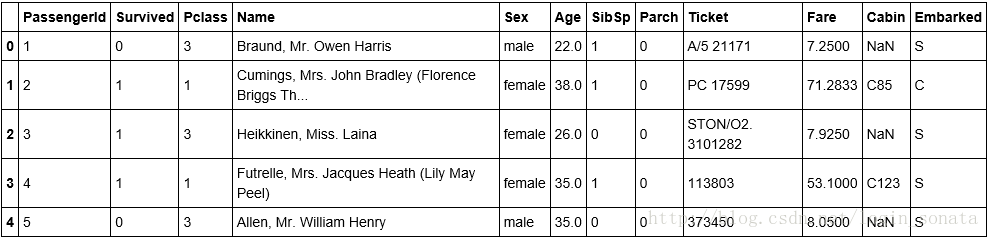
总览数据的常用命令有:
1、df.info() 可观察空值
2、df.dtypes 看类型
3、df.describe() 显示一些运算结果(mean/sum等)
4、df[‘Name’].unique() Name这一列所包含的值
二,数据预处理
1,Name
本来我是直接删掉Name这一列的,但从网上学到了从Name中提取属性,如名字中间夹的称谓:
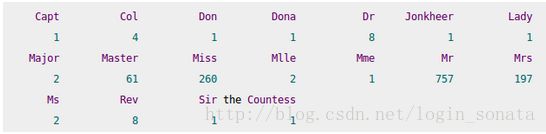
图片来自http://www.cnblogs.com/north-north/p/4358084.html。图中列出了数据中出现的所有称谓,有些是英语的,有些是法语的,我把他们进行替换,最后分为5类,再做定性属性的数值化处理,把字符串变为数值,方便用sklearn处理。用pandas的factorize方法或者get_dummies方法都行,前者直接在原列変换成数值,后者把变换后的属性作为新列。具体处理如下:
#正则匹配出名字中间的称谓
df['Title'] = df['Name'].map(lambda x: re.compile(",(.*?)\.").findall(x)[0])
#匹配的逗号后面有空格,记得去除空格,不然下一步没法替换
df['Title'] = df['Title'].map(str.strip)
#替换出5类
df['Title'][df.Title=='Jonkheer'] = 'Master'
df['Title'][df.Title.isin(['Ms','Mlle'])] = 'Miss'
df['Title'][df.Title.isin(['Mme','Dona', 'Lady', 'the Countess'])] = 'Mrs'
df['Title'][df.Title.isin(['Capt', 'Don', 'Major', 'Col', 'Sir'])] = 'Mr'
df['Title'][df.Title.isin(['Dr','Rev'])] = 'DrAndRev'
#factorize数值化
df['Title'] = pd.factorize(df.Title)[0]2,Sex
#对Sex进行数值化处理。
df['Sex'] = pd.factorize(df.Sex)[0]
#另一种数值化方法,可具体指定:
#df['Sex'] = df['Sex'].map({'female': 1, 'male': 0}).astype(int)
3,sibsp和parch
添加familysize列作为sibsp和parch的和,代表总的家庭成员数。
这种从原始数据中挖掘隐藏属性或属性组合的方法叫做派生属性。但是这些挖掘出来的特征有几个问题:
一是这些特征间具有多重共线性,可能会导致空间的不稳定;
二是高维空间本身具有稀疏性,一维正态分布有68%的值落于正负标准差之间,而在十维空间上只有0.02%;
三是过多的属性会加大计算量。所以要用到数据归约技术(降维),归约后的数据集小得多,但基本保持原始数据的完整性。
但我的做法并没有像属性组合那样生成很多新的属性,实际上我几乎没有派生,除了 familysize,所以也就没有用到降维技术(比如PCA)。
不过在后来的调试中,为了降低模型复杂度和缩小特征空间,我把sibsp和parch两列都删除了,并把familysize分为两类,一类是带了亲戚的,另一类是没带的。
df['Familysize'] = df['SibSp'] + df["Parch"]
df['Familysize'][df.Familysize==0] = 0
df['Familysize'][df.Familysize>0] = 1
4,Fare
我的做法很简单,分两类就行了,20块以下和以上。
df['Fare'][df.Fare<20] = 0
df['Fare'][df.Fare>=20] = 1
如何判断分几类呢?可以用excel的图表快速查看数据分布,也可以用python画图,比如在notebook上画散点图和简单的条形图:
import pylab as pl
%pylab inline
#散点图
pl.scatter(df.index,df['Fare'])
#条形
#pl.hist(df['Fare'],bins=100)
#pl.show()
这种简单的处理方法对于小数据来说效果非常不错,我最开始用的是从网上看来的做法:
就像直方图的bin将数据划分成几块一样,我们也可以将数值属性划分成几个bin,这是一种连续数据离散化的处理方式。
我们使用pandas.qcut()函数来离散化连续数据,它使用分位数对数据进行划分,使得每个左开右闭区间内的频数相等。具体实现是这样的:
#把fare的0转化为各自所在Pclass等级的平均数。
#先把0转为空值
df.Fare = df.Fare.map(lambda x: np.nan if x == 0 else x)
df.loc[(df.Fare.isnull())&(df.Pclass==1),'Fare']=np.median(df[df['Pclass']==1]['Fare'].dropna())
# 也可用透视表求各个类的均值,显示效果是三行,分别是123类,第二列是每类的均值。
# classmeans = df.pivot_table('Fare', index='Pclass', aggfunc='mean')
# df.Fare = df[['Fare', 'Pclass']].apply(lambda x: classmeans[x['Pclass']] if pd.isnull(x['Fare']) else x['Fare'],axis=1)
# 把train数据中的Fare离散化(先把数值转化为段,再把段转化为离散的数)
fare_bins = pd.qcut(train_df.Fare, 6, retbins=True)
#具体数字被替换成了它所在的区间
train_df['Fare_bined'] = fare_bins[0]
train_df['Fare_bined'] = pd.factorize(train_df.Fare_bined)[0]
# test的Fare依照train的标准离散化
bins = fare_bins[1]
test_df['Fare_bined'] = pd.cut(test_df.Fare,bins)
test_df['Fare_bined'] = pd.factorize(test_df.Fare_bined)[0]
插一句,如果最后训练用随机森林分类器的话只需要离散化而不需要规范化,但对于基于距离度量的分类和聚类算法,一般还需要规范化。数据规范化通过将数据压缩到一个范围内(通常是0-1或者-1-1)赋予所有属性相等的权重。比如StandardScaler将数值压缩到[-1,1]区间:
#在train集上做标准化后,用同样的标准化器去标准化test集
scaler = sklearn.preprocessing.StandardScaler().fit(train)
scaler.transform(train)
scaler.transform(test)
5,Age、Cabin和Embarked
通过之前的观察数据,发现age、cabin和embarked有空值,在特征工程中,对于空值的做法有:
•数据很多但缺失值很少时,直接删掉。
•可以赋一个代表缺失的值,比如‘U0’。因为缺失本身也可能代表着一些隐含信息。
•如果缺失值很重要,使用模型来预测缺失属性的值。
•如果该属性相对学习来说不是很重要,可以对缺失值赋均值或者众数。
对于Age的做法,我一开始是把age的空值替换为中位数。但这样太粗糙了,我认为它比较重要,所以最终方案是用别的属性去预测它,模型用随机森林:
#先删掉没有用到的列
df.drop(['PassengerId', 'Name', 'SibSp' ,'Parch','Ticket', 'Cabin','Embarked'],inplace=True, axis=1)
#把非空的Age分为两类,18岁以下和以上
df['Age'][(df.Age<18)&(df.Age.notnull())] = 0
df['Age'][(df.Age>=18)&(df.Age.notnull())] = 1
#提取训练的输入和输出,以及测试输入,然后训练模型,预测。
y_train = df['Age'][df.Age.notnull()].values
x_train = df[df.Age.notnull()].drop(['Age'],axis=1).values
x_test = df[df.Age.isnull()].drop(['Age'],axis=1).values
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier().fit(x_train,y_train)
df['Age'][df.Age.isnull()] = rfc.predict(x_test)
df.info()
对于cabin列,由于缺失太多,我选择不使用它。
对于embarked列,我一开始是用众数填充它的,但是最后的方案是抛弃掉这一列,我认为它作为特征并不明显,删掉它有助于进一步简化模型。用众数填充的实现是这样的:
# mode方法找频数最大的值(可以是字符串)
df['Embarked'][df['Embarked'].isnull()]=df.Embarked.dropna().mode().values
#这句和上边一句效果相同
#df.Embarked = df.Embarked.fillna(mode(df.Embarked) [0][0])
#get_dummies数值化
dummies_Embarked = pd.get_dummies(df.Embarked)
dummies_Embarked = dummies_Embarked.rename(columns=lambda x:'Embarked_'+str(x))
df = pd.concat([df,dummies_Embarked],axis=1)
#也可以重命名列名
df.rename(columns={'Embarked_1':'EM_1'},inplace=True)
6,Pclass
Pclass没有动,不过试过把它表示为onehot的形式(就是一个1其余0的形式),甚至全部属性都表示为onehot形式,很奇怪结果都不理想,那怎么确定factorize和get_dummies这两种转换的适用范围?这是我很疑惑的一个地方,我觉得最好用onehot,有3个优点:1,避免统计上出现问题,比如某特征的取值为{1,2,3},1和2的距离是1,1和3的距离是2,但我们不能说1与2更相似;2,使用onehot在某种程度上扩充了特征,比如性别特征扩充为男女两个特征;3,使用onehot可以产生稀疏特征,特征表达更明确且计算快,在某些场景下很有用。
最终去掉没用东西之后得到的训练集如下:
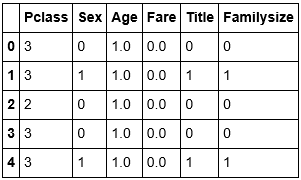
三,训练模型
1,二分类比较简单,什么模型都可以试试,我最终用了随机森林,gbdt和svm,然后用了投票分类器做了模型的集成,交叉验证参数调优什么的都没有做:
feature = pd.read_csv(r'E:\kaggle\titanicv2\cleaned_data\cleaned_train_feature.csv',header=None).values
target = pd.read_csv(r'E:\kaggle\titanicv2\cleaned_data\train_tag.csv',header=None).values
x_train, x_test, y_train, y_test = train_test_split(feature,target,test_size=0.15,random_state=None)
# 随机森林模型
rfc = RandomForestClassifier(random_state=1)
rfc.fit(x_train,y_train)
y_train_pred = rfc.predict(x_train)
y_test_pred = rfc.predict(x_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
#下边这两个正确率可以大致反映出模型是否过拟合
print('rfc/test accuracies %.4f/%.4f' % (tree_train, tree_test))
#特征选择
# feature_importance = rfc.feature_importances_
# feature_importance = 100.0 * (feature_importance / feature_importance.max())
# print(feature_importance)
#交叉验证
# cvscores = cross_validation.cross_val_score(rfc, feature, target, cv=5)
# print(cvscores.mean())
# 模型集成方法
#随机性的模型都会有个random_state来控制随机种子,所以得到一个好模型后记下这个值用来复现模型。
svmMod = svm.SVC(probability=True,random_state=1)
gbdt = GradientBoostingClassifier(random_state=1)
voting_class = VotingClassifier(estimators=[('rfc', rfc), ('gbdt', gbdt),('svm',svmMod)], voting='soft',weights=[1, 1, 1])
vote = voting_class.fit(x_train, y_train)
y_train_pred = vote.predict(x_train)
y_test_pred = vote.predict(x_test)
vote_train = accuracy_score(y_train, y_train_pred)
vote_test = accuracy_score(y_test, y_test_pred)
print('Ensemble Classifier train/test accuracies %.4f/%.4f' % (vote_train, vote_test))
#保存模型 ,参数compress=3通过压缩解决了生成一堆文件的问题
joblib.dump(vote,'E://kaggle//titanicv2//model//' + str(vote_test) + 'vote1.model',compress=3)
#读入模型
#vote = joblib.load(r'E:\kaggle\titanicv2\model\0.850746268657vote1.model')2,因为数据少,我的做法是利用模型的随机性(同时每次训练集和测试集的拆分也是随机的,因此我放弃了调参),生成多个模型,选取正确率最高的几个模型(比如7个,越多越好),用它们去分别做预测。
3,然后对这7个预测结果做一次结果的集成,对有争议的预测结果按照少数服从多数的原则修改,因为是二分类,类别较少,所以这是一种投机取巧的方法。
三,经验总结
1,特征方面的。我对于特征的处理非常粗糙,网上看别人的都是派生出很多属性,然后再属性组合生成上百种属性,目的是抓住不同特征之间的联系,比如用Age乘以class产生一个属性,甚至说对于任意两个特征,都依次生成f1*f2、f1/f2、f1+f2、f1-f2四种特征,最后训练完模型后,根据反馈进行特征选择。
那么相比于PCA,特征选择也算是一种降维的手段,但PCA是训练模型前的降维。我在知乎上看到了一个问题,说为什么预处理完后不直接PCA降维,可不可以直接替代掉特征选择这一步?以下是一些回答:
从处理方式来说,特征选择对原特征要么留,要么舍;而降维会利用到原特征的部分信息。从目的角度来说,特征选择是选取“有用”的特征,而降维是在性能和效率之间做一个折衷。这两者并不是同概念。
我觉得是如果直接PCA降维的话得到的主成分可能没有原始特征代表的意义那么直观,即使对每一个主成分都作出合理的解释也没有原始特征来的确切。这是一方面原因。还有原因就是,PCA是无监督的算法,对不同类别无差别的对待,除了降维以外,对最后的正确率没有什么保证;而特征选择可以有监督的进行,除降维之外,可以确保最后的正确率不比没降维之前差,甚至更好。
2,对于小数据集,模型尽量简单,避免过拟合。在我的最终方案里,训练集属性只有6个,我觉得甚至可以再少一些。我尝试过的十几维甚至更高维的特征最终效果都不太好。所以,尽量简化你的模型,同时减少每个属性可选值的个数。
3,数据不均衡,影响模型拟合。因为幸存者相对未幸存的人数较少,所以数据是不均衡的,可以通过重采样或者调整样本的权重,来获得均衡的训练样本。
详见:http://blog.csdn.net/login_sonata/article/details/54290402
4,在处理特征的时间花费上远大于模型的花费上,但这是值得的,因为好的数据集比好的算法更重要。我觉得对于算法的选择其实不太关键,基本就是流行的那几个,调参和集成什么的提升都是微小的,不如一个好的特征关键。希望下次能用用传说中的神器XGBOOST。
5,在网上看到一种别人的训练方式,是让不同的模型接收不同的特征。比如我派生出了上百个属性,然后我构建不同的分类器,有的接收标量,有的接收二值,因为有些分类器只在某个特征上效果好,最后集成这些模型。至于效果如何,我没试过,但这也算是一种思路。
6,关注bad case,即分错的样例。具体到本例,比如针对幸存者,我们对从原始训练集中拆分出的测试集进行预测,把预测结果和真实数据做个对比,仔细观察错误项,看到底是什么原因给它分错了,这有助于我们进一步优化特征。
7,sklearn这个包非常方便(不管是预处理还是训练),特征选择和交叉验证什么的功能都有,下面这个是非常有用的GridSearch参数调优方法,虽然这次没有用到:
#对效果最好的分类算法使用GridSearch做参数调优(来自网络,仅供参考):
def get_best_parameter():
x_train, y_train = train_data.get_process_train_data() #得到训练特征和标签
tree = DecisionTreeClassifier(criterion='entropy', max_depth=None)
param_grid = [{'criterion': ['gini', 'entropy'],'splitter': ['best', 'random'],'max_depth': [1, 5, 10, None]}]
gs = GridSearchCV(estimator=tree,param_grid=param_grid,scoring='accuracy')
gs = gs.fit(x_train, y_train)
print(gs.best_score_)
print(gs.best_params_)
bestMod = grid.best_estimator_ #返回最优模型