ElasticSearch笔记(1)elk搭建与基本操作
目录
- 一 介绍
- 1.1 目录结构
- 1.2 es安装
- 集群安装
- 1.3 kibana安装
- 插件
- 1.4 docker中安装ELK Stack
- 1.5 安装logstash并导入数据
- 二 基本概念
- 2.1文档
- 文档的元数据
- 索引
- 和数据库类比
- 2.2 分布式特性
- 2.3 节点
- Master-eligible nodes和Master Node
- Data Node & Coordinating Node
- 其他的节点类型
- 配置节点类型
- 2.3 分片
- 实践说明
- 分片的设定
- 查看集群的健康状态
- 2.4 使用说明
- kibana
- cerebro
- 三 基本操作CRUD
- 3.1 index相关
- 查看所有的index
- 查看index的mapping
- 创建一个index
- 3.2 创建文档
- 3.3 查询文档
- 3.4 Index文档
- 3.5 Update文档
- 四 BULK(批量)操作
- 五 批量读取-mget
- 六 批量查询-msearch
- 七 常见错误返回
- 参考
一 介绍
1.1 目录结构

1.2 es安装
参考:https://blog.csdn.net/msllws/article/details/102807605?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
中间报了几次错,网上都可以查到解决方案
效果
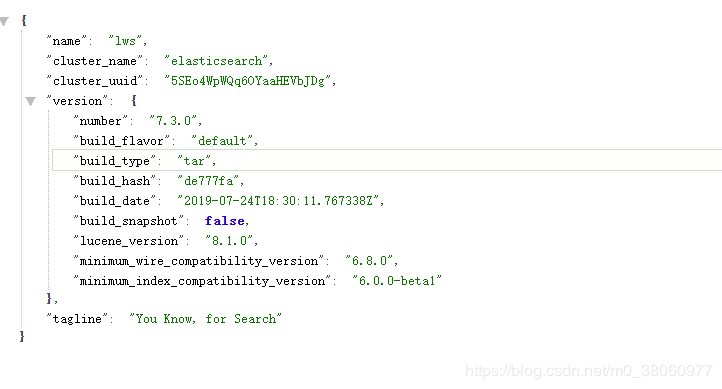
集群安装
参考:Elasticsearch 7.x 最详细安装及配置
注意:需要把之前安装时,配置文件中的配置去掉。变成默认配置
1.3 kibana安装
- 在官网下载kibana(我是用7.3版本,版本必须一致)
- 直接安装,运行(开箱即用)
可以用来执行命令

插件
1.4 docker中安装ELK Stack

- 先安装docker和docker-compose
- 去教程对应的github中找到写好的docker-compose.yml
配置文件如下:
version: '2.2'
services:
cerebro:
image: lmenezes/cerebro:0.8.3
container_name: hwc_cerebro
ports:
- "9000:9000"
command:
- -Dhosts.0.host=http://elasticsearch:9200
networks:
- hwc_es7net
kibana:
image: docker.elastic.co/kibana/kibana:7.1.0
container_name: hwc_kibana7
environment:
#- I18N_LOCALE=zh-CN
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED="true"
ports:
- "5601:5601"
networks:
- hwc_es7net
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_hot
environment:
- cluster.name=geektime-hwc
- node.name=es7_hot
- node.attr.box_type=hot
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_hot,es7_warm,es7_cold
- cluster.initial_master_nodes=es7_hot,es7_warm,es7_cold
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- hwc_es7data_hot:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- hwc_es7net
elasticsearch2:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_warm
environment:
- cluster.name=geektime-hwc
- node.name=es7_warm
- node.attr.box_type=warm
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_hot,es7_warm,es7_cold
- cluster.initial_master_nodes=es7_hot,es7_warm,es7_cold
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- hwc_es7data_warm:/usr/share/elasticsearch/data
networks:
- hwc_es7net-com
elasticsearch3:
image: docker.elastic.co/elasticsearch/elasticsearch:7.1.0
container_name: es7_cold
environment:
- cluster.name=geektime-hwc
- node.name=es7_cold
- node.attr.box_type=cold
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_hot,es7_warm,es7_cold
- cluster.initial_master_nodes=es7_hot,es7_warm,es7_cold
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- hwc_es7data_cold:/usr/share/elasticsearch/data
networks:
- hwc_es7net
volumes:
hwc_es7data_hot:
driver: local
hwc_es7data_warm:
driver: local
hwc_es7data_cold:
driver: local
networks:
hwc_es7net:
driver: bridge
这里坑太多,首先就是不能从官方镜像库下载elasticsearch镜像。配置阿里云镜像,不知道为什么还是从官方下载。后来先手动从指定库下载才解决
docker pull docker.mirrors.ustc.edu.cn/library/elasticsearch:7.1.0
1.5 安装logstash并导入数据
- 先去官网下载,版本要和前面的elasticsearch一致官网下载地址
- 网上搜索movielens项目并下载。拿到movies.csv文件
- 编写一个logstash.conf文件(
不是我写的,教程里的老师写的)
input {
file {
path => "/目录xx/movies.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
csv {
separator => ","
columns => ["id","content","genre"]
}
mutate {
split => { "genre" => "|" }
remove_field => ["path", "host","@timestamp","message"]
}
mutate {
split => ["content", "("]
add_field => { "title" => "%{[content][0]}"}
add_field => { "year" => "%{[content][1]}"}
}
mutate {
convert => {
"year" => "integer"
}
strip => ["title"]
remove_field => ["path", "host","@timestamp","message","content"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "movies"
document_id => "%{id}"
}
stdout {}
}
- 启动logsaths,导入数据
./bin/logstash -f logstash.conf
二 基本概念
2.1文档
Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位
文档会被序列化成JSON格式,保存在Elasticsearch 中
- JSON对象由字段组成,
- 每个字段都有对应的字段类型 (字符串/数值/布尔/日期/二进制/范围类型)
- 每个文档都有-个Unique ID(你可以自己指定ID 或者通过Elasticsearch自动生成)
- 一篇文档包含了一系列的字段。类似数据库表中
一条记录 - JSON文档,
格式灵活,不需要预先定义格式(字段的类型可以指定或者通过Elasticsearch自动推算\支持数组/支持嵌套)
结构和mongodb很像
文档的元数据
元数据,用于标注文档的相关信息
- _index -文档所属的索引名
- _type -文档所属的类型名
- _id- 文档唯一ld
- _ source:文档的
原始Json数据 - _all: 整合所有字段内容到该字段,已被废除
- _version: 文档的版本信息
- _ score:
相关性打分
索引
Index-索引是文档的容器,是一类文档的结合
- Index 体现了
逻辑空间的概念:每个索引都有自己的Mapping定义,用于定义包含的文档的字段名和字段类型 - Shard体现了
物理空间的概念:索引中的数据分散在Shard.上
索引的Mapping与Settings
- Mapping 定义文档
字段的类型 - Setting 定义
不同的数据分布
和数据库类比

2.2 分布式特性
Elasticsearch的分布式架构的好处
- 存储的
水平扩容 - 提高系统的
可用性, 部分节点停止服务,整个集群的服务不受影响
Elasticsearch的分布式架构
- 不同的集群通过不同的名字来区分,默认名字“elasticsearch”
- 通过配置文件修改, 或者在命令行中
-E cluster.name=xxx进行设定 - 一个集群可以有
一个或者多个节点
2.3 节点
节点是一个Elasticsearch的实例
- 每一个节点都有名字,通过
配置文件配置,或者启动时候-E node.name=node1指定 - 每一个节点在启动之后,会分配一个
UID, 保存在data目录下
Master-eligible nodes和Master Node
- 每个节点启动后,默认就是一个Master eligible节点可以设置node.master: false禁止
- Master- eligible节点可以
参加选主流程,成为Master节点 - 当第一个节点启动时候,它会将自己选举成Master节点
- 每个节点上
都保存了集群的状态,只有Master节点才能修改集群的状态信息 - 集群状态(Cluster State) ,维护了一个集群中,必要的信息(所有的
节点信息、所有的索引和其相关的Mapping与Setting信息、分片的路由信息)
Data Node & Coordinating Node
Data Node
可以保存数据的节点,叫做Data Node。负责保存分片数据。在数据扩展上起到了至关重要的作用
Coordinating Node
- 负责接受Client的请求, 将
请求分发到合适的节点,最终把结果汇集到一起 - 每个节点
默认都起到 了Coordinating Node的职责
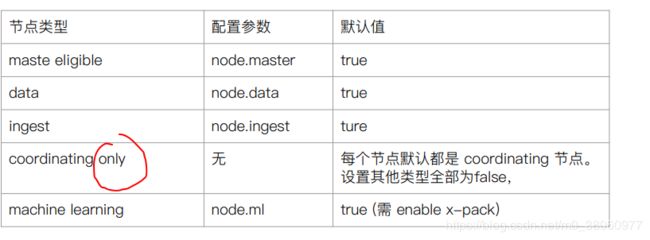
其他的节点类型
- Hot & Warm Node(hot所在的服务器性能高)
不同硬件配置的DataNode,用来实现Hot&Warm架构,降低集群部署的成本 - Machine Learning Node
负责跑机器学习的Job, 用来做异常检测 - Tribe Node
(5.3开始使用Cross Cluster Serarch) Tribe Node连接到不同的Elasticsearch 集群,
并且支持将这些集群当成一个单独的集群处理
配置节点类型
- 开发环境中一个节点可以
承担多种角色 - 生产环境中,
应该设置单一的角色的节点(dedicated node)
2.3 分片
主分片,用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上
- 一个分片是一个运行的
Lucene的实例(一种搜索引擎) - 主分片数在
索引创建时指定,后续不允许修改,除非Reindex
副本,用以解决数据高可用的问题。分片是主分片的拷贝
- 副本分片数, 可以动态题调整
- 增加副本数, 还可以在一定程度上提高服务的可用性(读取的吞吐)
实践说明
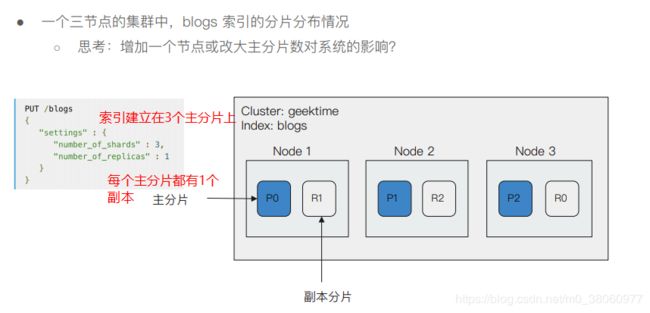
分片的设定
对于生产环境中分片的设定,需要提前做好容量规划!!!
如果分片数设置过小
- 导致后续
无法增加节点实现水平扩展 - 单个分片的数据量太大, 导致数据
重新分配耗时(前面提过reindex)
如果分片数设置过大,7.0开始,默认主分片设置成1, 解决了over-sharding的问题
- 影响搜索结果的
相关性打分,影响统计结果的准确性 - 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
查看集群的健康状态

2.4 使用说明
kibana
在dev tools 中可以使用指令

get _cluster/health
get _cat/nodes
get _cat/shards
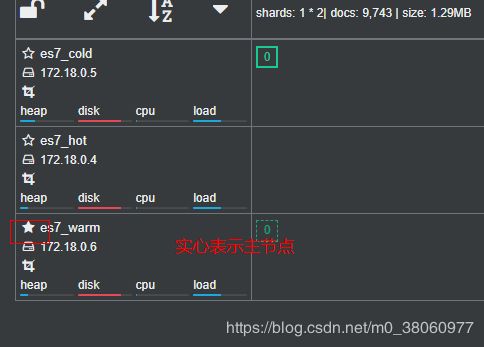
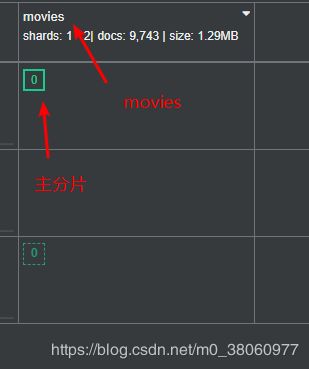
cerebro
这个界面打开比较慢
三 基本操作CRUD
3.1 index相关
查看所有的index
GET /_cat/indices?v
查看index的mapping
GET /_mapping?pretty=true
# 查看movies的index
GET movies/_mapping?pretty=true
创建一个index
PUT users2
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"age": {
"type": "long"
},
"name": {
"type": "keyword"
},
"desc": {
"type": "text"
},
"hobby": {
"type": "text"
}
}
}
}
3.2 创建文档
注意,这里第一次创建文档是,其实还没有创建过mapping。但es会自动根据字段值创建
没指定id,自动创建id
POST users/_doc
{
"user" : "Mike",
"post_date" : "2019-04-15T14:12:12",
"message" : "trying out Kibana"
}
指定id创建
此时,如果id已经存在,则会报错
POST users/_doc/1?op_type=create
{
"user" : "ZYC",
"post_date" : "2016-04-15T14:12:12",
"message" : "i have id"
}
#PUT也可以,这里的_create是关键字
put users/_create/2
{
"user" : "11dian",
"post_date" : "2016-04-15T14:12:12",
"message" : "i have id by put"
}
3.3 查询文档
找到文档,返回200
GET users/_doc/1
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"user" : "ZYC",
"post_date" : "2016-04-15T14:12:12",
"message" : "i have id"
}
}
找不到文档,返回404
GET users/_doc/100
{
"_index" : "users",
"_type" : "_doc",
"_id" : "100",
"found" : false
}

3.4 Index文档
index和create不一样的地方,如果文档不存在。则索引新的文档。否则,旧文档会被删除,新的文档被索引。版本信息+1
PUT users/_doc/1
{
"user":"zyc1"
}
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,//版本增加了
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"user" : "zyc1"
}
}
3.5 Update文档
- 不会删除原来的文档,
真正的更新 POST需要用到doc属性
POST users/_update/1/
{
"doc":{
"post_date" : "2019-05-15T14:12:12",
"message" : "trying out Elasticsearch"
}
}
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : {
"user" : "zyc1",
"post_date" : "2019-05-15T14:12:12",
"message" : "trying out Elasticsearch"
}
}
四 BULK(批量)操作
- 支持在一次请求中,对不同的index操作
- 中间某条操作失败,不会影响到其他的操作
- 返回结果包含了每一条操作的结果
- 支持 Index\Create\Update\Delete 四种操作
- 可以在URI中指定index,也可以在请求体中
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test2", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field1" : "value1_new"} }
结果
{
"took" : 317,
"errors" : true,
"items" : [
{
"index" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"delete" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"result" : "not_found",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 404
}
},
{
"create" : {
"_index" : "test2",
"_type" : "_doc",
"_id" : "3",
"status" : 409,
"error" : {
"type" : "version_conflict_engine_exception",
"reason" : "[3]: version conflict, document already exists (current version [1])",
"index_uuid" : "BsuXOUxpS_eVxmbgjF9iVQ",
"shard" : "0",
"index" : "test2"
}
}
},
{
"update" : {
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 200
}
}
]
}
五 批量读取-mget
批量操作,降低了请求次数和网络开销
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_id" : "1"
},
{
"_index" : "test",
"_id" : "2"
}
]
}
{
"docs" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : {
"field1" : "value1_new"
}
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"found" : false
}
]
}
uri中指定
GET /test/_mget
{
"docs" : [
{
"_id" : "1"
},
{
"_id" : "2"
}
]
}
六 批量查询-msearch
POST users/_msearch
{}
{"query" : {"match_all" : {}},"size":1}
{"index" : "test"}
{"query" : {"match_all" : {}},"size":2}
结果
{
"took" : 2,
"responses" : [
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "users",
"_type" : "_doc",
"_id" : "zOMveXEBcLw4fF5IGKcV",
"_score" : 1.0,
"_source" : {
"user" : "Mike",
"post_date" : "2019-04-15T14:12:12",
"message" : "trying out Kibana"
}
}
]
},
"status" : 200
},
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"field1" : "value1_new"
}
}
]
},
"status" : 200
}
]
}
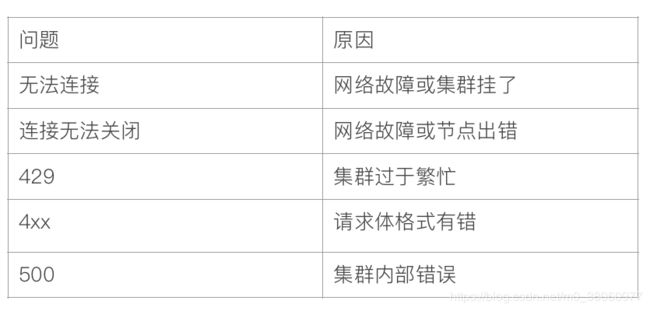
七 常见错误返回
参考
- Elasticsearch核心技术与实战