hadoop2提交到Yarn: Mapreduce执行过程分析
1 概述
3 怎么运行MapReduce
4 如何编写MapReduce程序
4.1 代码构成
4.2 入口类
4.2.1 参数获取
而getRemainingArgs方法会获得传入的参数,接着在main方法中会进行判断参数的个数,由于此处是WordCount计算,只需要传入文件的输入路径和输出路径即可,因此参数的个数为2,否则将退出:
4.2.2 Job定义
可见,传入的"word count"就是Job的名字。而conf被传递给了JobConf进行环境变量的获取:
4.2.3 Job提交
4.2.4 另一种运行方式
至此,我们的MapReduce的启动类要做的事情已经分析完了。
获取已经完成的Map信息,如Map的host、mapId等放入ShuffleSchedulerImpl中的Set中便于下面进行数据的拷贝传输。
线程的run方法就是进行数据的远程拷贝:
并执行其run方法,此run方法就是我们的org.apache.hadoop.mapreduce.Reducer中的run方法。
该瞅瞅MapReduce的内部运行原理了,以前只知道个皮毛,再不搞搞,不然怎么死的都不晓得。下文会以2.4版本中的WordCount这个经典例子作为分析的切入点,一步步来看里面到底是个什么情况。
2 为什么要使用MapReduce
Map/Reduce,是一种模式,适合解决并行计算的问题,比如TopN、贝叶斯分类等。注意,是并行计算,而非迭代计算,像涉及到层次聚类的问题就不太适合了。
从名字可以看出,这种模式有两个步骤,Map和Reduce。Map即数据的映射,用于把一组键值对映射成另一组新的键值对,而Reduce这个东东,以Map阶段的输出结果作为输入,对数据做化简、合并等操作。
而MapReduce是Hadoop生态系统中基于底层HDFS的一个计算框架,它的上层又可以是Hive、Pig等数据仓库框架,也可以是Mahout这样的数据挖掘工具。由于MapReduce依赖于HDFS,其运算过程中的数据等会保存到HDFS上,把对数据集的计算分发给各个节点,并将结果进行汇总,再加上各种状态汇报、心跳汇报等,其只适合做离线计算。和实时计算框架Storm、Spark等相比,速度上没有优势。旧的Hadoop生态几乎是以MapReduce为核心的,但是慢慢的发展,其
扩展性差、资源利用率低、可靠性等问题都越来越让人觉得不爽,于是才产生了
Yarn,并且二代版的Hadoop生态都是以Yarn为核心。Storm、Spark等都可以基于Yarn使用。
3 怎么运行MapReduce
明白了哪些地方可以使用这个牛叉的MapReduce框架,那该怎么用呢?Hadoop的MapReduce源码给我们提供了范例,在其
hadoop-mapreduce-examples子工程中包含了MapReduce的Java版例子。在写完类似的代码后,打包成jar,在HDFS的客户端运行:
bin/hadoop jar mapreduce_examples.jar mainClass args
即可。当然,也可以在IDE(如Eclipse)中,进行远程运行、调试程序。
至于,HadoopStreaming方式,网上有很多。我们这里只讨论Java的实现。
4 如何编写MapReduce程序
如前文所说,MapReduce中有Map和Reduce,在实现MapReduce的过程中,主要分为这两个阶段,分别以两类函数进行展现,
一个是map函数,一个是reduce函数。map函数的参数是一个键值对,其输出结果也是键值对,reduce函数以map的输出作为输入进行处理。
4.1 代码构成
实际的代码中,需要三个元素,分别是
Map、Reduce、运行任务的代码。这里的Map类是继承了org.apache.hadoop.mapreduce.Mapper,并实现其中的map方法;而Reduce类是继承了org.apache.hadoop.mapreduce.Reducer,实现其中的reduce方法。至于运行任务的代码,就是我们程序的入口。
下面是Hadoop提供的WordCount源码。
首先定义配置文件类
Configuration,此类是Hadoop各个模块的公共使用类,用于加载类路径下的各种配置文件,读写其中的配置选项。
第二步中,用到了
GenericOptionsParser类,其目的是将命令行中参数自动设置到变量conf中。
GenericOptionsParser的构造方法进去之后,会进行到
parseGeneralOptions,对传入的参数进行解析:
而getRemainingArgs方法会获得传入的参数,接着在main方法中会进行判断参数的个数,由于此处是WordCount计算,只需要传入文件的输入路径和输出路径即可,因此参数的个数为2,否则将退出:
如果在代码运行的时候传入其他的参数,比如指定reduce的个数,可以根据GenericOptionsParser的命令行格式这么写:
bin/hadoop jar MyJob.jar com.xxx.MyJobDriver -Dmapred.reduce.tasks=5
其规则是
-D加MapReduce的配置选项,当然还支持-fs等其他参数传入。当然,
默认情况下Reduce的数目为1,Map的数目也为1。
定义Job对象,其构造方法为:
可见,传入的"word count"就是Job的名字。而conf被传递给了JobConf进行环境变量的获取:
Job已经实例化了,下面就得给这个Job加点佐料才能让它按照我们的要求运行。于是依次给Job添加启动Jar包、设置Mapper类、设置合并类、设置Reducer类、设置输出键类型、设置输出值的类型。
这里有必要说下设置Jar包的这个方法setJarByClass:
它会首先判断当前Job的状态是否是运行中,接着通过class找到其所属的jar文件,将jar路径赋值给mapreduce.job.jar属性。至于寻找jar文件的方法,则是通过classloader获取类路径下的资源文件,进行循环遍历。具体实现见ClassUtil类中的findContainingJar方法。
搞完了上面的东西,紧接着就会给
mapreduce.input.fileinputformat.inputdir参数赋值,这是Job的输入路径,还有
mapreduce.input.fileinputformat.inputdir,这是Job的输出路径。具体的位置,就是我们前面main中传入的Args。
4.2.3 Job提交
万事俱备,那就运行吧。
这里调用的方法如下:
至于方法的参数
verbose,如果想在控制台打印当前的进度,则设置为true。
至于submit方法,如果当前在HDFS的配置文件中配置了
mapreduce.framework.name属性为“yarn”的话,会创建一个
YARNRunner对象来进行任务的提交。其构造方法如下:
其中,ResourceMgrDelegate实际上ResourceManager的代理类,其实现了
YarnClient接口,通过
ApplicationClientProtocol代理直接向RM提交Job,杀死Job,查看Job运行状态等操作。同时,在ResourceMgrDelegate类中会通过YarnConfiguration来读取yarn-site.xml、core-site.xml等配置文件中的配置属性。
下面就到了客户端最关键的时刻了,提交Job到集群运行。具体实现类是JobSubmitter类中的
submitJobInternal方法。这个牛气哄哄的方法写了100多行,还不算其几十行的注释。我们看它干了点啥。
Step1:
检查job的输出路径是否存在,如果存在则抛出异常。
Step2:
初始化用于存放Job相关资源的路径。注意此路径的构造方式为:
其中,
MRJobConfig.DEFAULT_MR_AM_STAGING_DIR为“/tmp/hadoop-yarn/staging”,
STAGING_CONSTANT为".staging"。
Step3:
设置客户端的host属性:
mapreduce.job.submithostname和mapreduce.job.submithostaddress。
Step4:
通过RPC,向Yarn的ResourceManager申请JobID对象。
Step5:
从HDFS的NameNode获取验证用的Token,并将其放入缓存。
Step6:
将作业文件上传到HDFS,这里如果我们前面没有对Job命名的话,默认的名称就会在这里设置成jar的名字。并且,作业默认的副本数是10,如果属性
mapreduce.client.submit.file.replication没有被设置的话。
Step7:
文件上传到HDFS之后,还要被DistributedCache进行缓存起来。这是因为计算节点收到该作业的第一个任务后,就会有DistributedCache自动将作业文件Cache到节点本地目录下,并且会对压缩文件进行解压,如:.zip,.jar,.tar等等,然后开始任务。
最后,对于同一个计算节点接下来收到的任务,
DistributedCache不会重复去下载作业文件,而是直接运行任务。如果一个作业的任务数很多,这种设计避免了在同一个节点上对用一个job的文件会下载多次,大大提高了任务运行的效率。
Step8:
对每个输入文件进行split划分。注意这只是个逻辑的划分,不是物理的。因为此处是输入文件,因此执行的是FileInputFormat类中的getSplits方法。只有非压缩的文件和几种特定压缩方式压缩后的文件才分片。分片的大小由如下几个参数决定:
mapreduce.input.fileinputformat.split.maxsize、mapreduce.input.fileinputformat.split.minsize、文件的块大小。
具体计算方式为:
Math.max(minSize, Math.min(maxSize, blockSize))
分片的大小有可能比默认块大小64M要大,当然也有可能小于它,默认情况下分片大小为当前HDFS的块大小,64M。
接下来就该正儿八经的获取分片详情了。代码如下:
Step8.1:
将bytesRemaining(剩余未分片字节数)设置为整个文件的长度。
Step8.2:
如果bytesRemaining超过分片大小splitSize一定量才会将文件分成多个InputSplit,SPLIT_SLOP(默认1.1)。接着就会执行如下方法获取block的索引,其中第二个参数是这个block在整个文件中的偏移量,在循环中会从0越来越大:
将符合条件的块的索引对应的block信息的主机节点以及文件的路径名、开始的偏移量、分片大小splitSize封装到一个InputSplit中加入List splits。
Step8.3:
bytesRemaining -= splitSize修改剩余字节大小。剩余如果bytesRemaining还不为0,表示还有未分配的数据,将剩余的数据及最后一个block加入splits。
Step8.4
如果不允许分割isSplitable==false,则将第一个block、文件目录、开始位置为0,长度为整个文件的长度封装到一个InputSplit,加入splits中;如果文件的长度==0,则splits.add(new FileSplit(path, 0, length, new String[0]))没有block,并且初始和长度都为0;
Step8.5
将输入目录下文件的个数赋值给 "mapreduce.input.num.files",方便以后校对,返回分片信息splits。
这就是getSplits获取分片的过程。当使用基于FileInputFormat实现InputFormat时,为了提高MapTask的数据本地性,应尽量使InputSplit大小与block大小相同。
如果分片大小超过bolck大小,但是InputSplit中的封装了单个block的所在主机信息啊,这样能读取多个bolck数据吗?
比如当前文件很大,1G,我们设置的最小分片是100M,最大是200M,当前块大小为64M,经过计算后的实际分片大小是100M,这个时候第二个分片中存放的也只是一个block的host信息。需要注意的是split是逻辑分片,不是物理分片,当Map任务需要的数据本地性发挥作用时,会从本机的block开始读取,超过这个block的部分可能不在本机,这就需要从别的DataNode拉数据过来,因为实际获取数据是一个输入流,这个输入流面向的是整个文件,不受split的影响,split的大小越大可能需要从别的节点拉的数据越多,从从而效率也会越慢,拉数据的多少是由getSplits方法中的splitSize决定的。所以为了更有效率,分片的大小尽量保持在一个block大小吧。
Step9:
将split信息和SplitMetaInfo都写入HDFS中。使用方法:
Step10:
对Map数目设置,上面获得到的split的个数就是实际的Map任务的数目。
Step11:
相关配置写入到job.xml中:
Step12:
通过如下代码正式提交Job到Yarn:
这里就涉及到YarnClient和RresourceManager的RPC通信了。包括获取applicationId、进行状态检查、网络通信等。
Step13:
上面通过RPC的调用,最后会返回一个JobStatus对象,它的toString方法可以在JobClient端打印运行的相关日志信息。
4.2.4 另一种运行方式
提交MapReduce任务的方式除了上述源码中给出的之外,还可以使用ToolRunner方式。具体方式为:
至此,我们的MapReduce的启动类要做的事情已经分析完了。
4.3 Map类

数据区域和索引数据区域在kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,而分割点是变化的,每次Spill之后都会更新一次。初始的分界点是0,数据的存储方向是向上增长,索引数据的存储方向是向下增长,如图所示:

这里会触发信号量,使得在MapTask类的init方法中正在等待的SpillThread线程继续运行。

4.4 Reduce类
4.4.1 Reduce介绍
创建Map类和map函数,map函数是org.apache.hadoop.mapreduce.Mapper类中的定义的,当处理每一个键值对的时候,都要调用一次map方法,用户需要覆写此方法。此外还有setup方法和cleanup方法。map方法是当map任务开始运行的时候调用一次,cleanup方法是整个map任务结束的时候运行一次。
4.3.1 Map介绍
Mapper类是一个泛型类,带有4个参数(输入的键,输入的值,输出的键,输出的值)。在这里输入的key为Object(默认是行),输入的值为Text(hadoop中的String类型),输出的key为Text(关键字)和输出的值为IntWritable(hadoop中的int类型)。以上所有hadoop数据类型和java的数据类型都很相像,除了它们是针对网络序列化而做的特殊优化。
MapReduce中的类似于IntWritable的类型还有如下几种:
BooleanWritable:标准布尔型数值、ByteWritable:单字节数值、DoubleWritable:双字节数值、FloatWritable:浮点数、IntWritable:整型数、LongWritable:长整型数、Text:使用UTF8格式存储的文本(类似java中的String)、NullWritable:当中的key或value为空时使用。
这些都是实现了WritableComparable接口:
Map任务是一类将输入记录集转换为中间格式记录集的独立任务。 Mapper类中的map方法将输入键值对(key/value pair)映射到一组中间格式的键值对集合。这种转换的中间格式记录集不需要与输入记录集的类型一致。一个给定的输入键值对可以映射成0个或多个输出键值对。
这里将输入的行进行解析分割之后,利用Context的write方法进行保存。而Context是实现了MapContext接口的一个抽象内部类。此处把解析出的每个单词作为key,将整形1作为对应的value,表示此单词出现了一次。map就是一个分的过程,reduce就是合的过程。Map任务的个数和前面的split的数目对应,作为map函数的输入。Map任务的具体执行见下一小节。
4.3.2 Map任务分析
Map任务被提交到Yarn后,被ApplicationMaster启动,任务的形式是YarnChild进程,在其中会执行MapTask的run方法。无论是MapTask还是ReduceTask都是继承的Task这个抽象类。
run方法的执行步骤有:
Step1:
判断是否有Reduce任务,如果没有的话,Map任务结束,就整个提交的作业结束;如果有的话,当Map任务完成的时候设置当前进度为66.7%,Sort完成的时候设置进度为33.3%。
Step2:
启动TaskReporter线程,用于更新当前的状态。
Step3:
初始化任务,设置任务的当前状态为RUNNING,设置输出目录等。
Step4:
判断当前是否是jobCleanup任务、jobSetup任务、taskCleanup任务及相应的处理。
Step5:
调用runNewMapper方法,执行具体的map。
Step6:
作业完成之后,调用done方法,进行任务的清理、计数器更新、任务状态更新等。
4.3.3 runNewMapper分析
下面我们来看看这个runNewMapper方法。代码如下:
此方法的主要执行流程是:
Step1:
获取配置信息类对象TaskAttemptContextImpl、自己开发的Mapper的实例mapper、用户指定的InputFormat对象 (默认是TextInputFormat)、任务对应的分片信息split。
其中TaskAttemptContextImpl类实现TaskAttemptContext接口,而TaskAttemptContext接口又继承于JobContext和Progressable接口,但是相对于JobContext增加了一些有关task的信息。通过TaskAttemptContextImpl对象可以获得很多与任务执行相关的类,比如用户定义的Mapper类,InputFormat类等。
Step2:
根据inputFormat构建一个NewTrackingRecordReader对象,这个对象中的RecordReader real是LineRecordReader,用于读取分片中的内容,传递给Mapper的map方法做处理的。
Step3:
然后创建org.apache.hadoop.mapreduce.RecordWriter对象,作为任务的输出,如果没有reducer,就设置此RecordWriter对象为NewDirectOutputCollector(taskContext, job, umbilical, reporter)直接输出到HDFS上;如果有reducer,就设置此RecordWriter对象为NewOutputCollector(taskContext, job, umbilical, reporter)作为输出。
NewOutputCollector是有reducer的作业的map的输出。这个类的主要包含的对象是MapOutputCollector collector,是利用反射工具构造出来的:
如果Reduce的个数大于1,则实例化org.apache.hadoop.mapreduce.Partitioner (默认是HashPartitioner.class),用来对mapper的输出数据进行分区,即数据要汇总到哪个reducer上,NewOutputCollector的write方法会调用collector.collect(key, value,partitioner.getPartition(key, value, partitions));否则设置分区个数为0。
Step4:
打开输入文件(构建一个LineReader对象,在这实现文件内容的具体读)并且将文件指针指向文件头。由LineRecordReader的initialize方法完成。
实际上读文件内容的是类中的LineReader对象in,该对象在initialize方法中进行了初始化,会根据输入文件的文件类型(压缩或不压缩)传入相应输入流对象。LineReader会从输入流对象中通过:
in.readLine(new Text(), 0, maxBytesToConsume(start));
方法每次读取一行放入Text对象str中,并返回读取数据的长度。
LineRecordReader.nextKeyValue()方法会设置两个对象key和value,key是一个偏移量指的是当前这行数据在输入文件中的偏移量(注意这个偏移量可不是对应单个分片内的偏移量,而是针对整个文中的偏移量),value是通过LineReader的对象in读取的一行内容:
如果没有数据可读了,这个方法会返回false,否则true。
另外,getCurrentKey()和getCurrentValue()是获取当前的key和value,调用这俩方法之前需要先调用nextKeyValue()为key和value赋新值,否则会重复。
这样就跟org.apache.hadoop.mapreduce.Mapper中的run方法关联起来了。
Step5:
执行org.apache.hadoop.mapreduce.Mapper的run方法。
Step5.1:
首先会执行setup方法,用于设定用户自定义的一些参数等,方便在下面的操作步骤中读取。参数是设置在Context中的。此对象的初始化在MapTask类中的runNewMapper方法中:
会将LineRecordReader的实例对象和NewOutputCollector的实例对象传进去,下面的nextKeyValue()、getCurrentValue()、getCurrentKey()会调用reader的相应方法,从而实现了Mapper.run方法中的nextKeyValue()不断获取key和value。
Step5.2:
循环中的map方法就是用户自定的map。map方法逻辑处理完之后,最后都会有context.write(K,V)方法用来将计算数据输出。此write方法最后调用的是NewOutputCollector.write方法,write方法会调用MapOutputBuffer.collect(key, value,partitioner.getPartition(key, value, partitions))方法,用于汇报进度、序列化数据并将其缓存等,主要是里面还有个Spill的过程,下一小节会详细介绍。
Step5.3:
当读完数据之后,会调用cleanup方法来做一些清理工作,这点我们同样可以利用,我们可以根据自己的需要重写cleanup方法。
Step6:
最后是输出流的关闭output.close(mapperContext),该方法会执行MapOutputBuffer.flush()操作会将剩余的数据也通过sortAndSpill()方法写入本地文件,并在最后调用mergeParts()方法合并所有spill文件。sortAndSpill方法在4.3.4小节中会介绍。
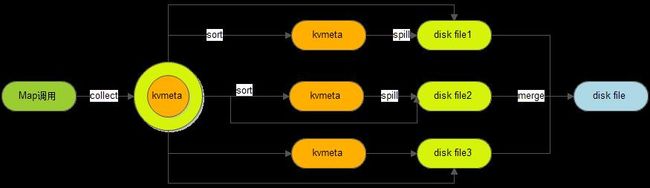
4.3.4 Spill分析
Spill的汉语意思是溢出,spill处理就是溢出写。怎么个溢出法呢?Spill过程包括输出、排序、溢写、合并等步骤,有点复杂,如图所示:
每个Map任务不断地以对的形式把数据输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
这个数据结构其实就是个字节数组,叫kvbuffer,这里面不只有数据,还放置了一些索引数据,并且给放置索引数据的区域起了一个kvmeta的别名。
kvmeta是对记录Record在kvbuffer中的索引,是个四元组,包括:value的起始位置、key的起始位置、partition值、value的长度,占用四个Int长度,kvmeta的存放指针kvindex每次都是向下跳四步,然后再向上一个坑一个坑地填充四元组的数据。比如kvindex初始位置是-4,当第一个写完之后,(kvindex+0)的位置存放value的起始位置、(kvindex+1)的位置存放key的起始位置、(kindex+2)的位置存放partition的值、(kvindex+3)的位置存放value的长度,然后kvindex跳到-8位置,等第二个和索引写完之后,kvindex跳到-32位置。
其中,kvbuffer的大小maxMemUsage的默认是100M。涉及到的变量有点多:
(1)kvstart是有效记录开始的下标;
(2)kvindex是下一个可做记录的位置;
(3)kvend在开始Spill的时候它会被赋值为kvindex的值,Spill结束时,它的值会被赋给kvstart,这时候kvstart==kvend。这就是说,如果kvstart不等于kvend,系统正在spill,否则,kvstart==kvend,系统处于普通工作状态;
(4)bufvoid,用于表明实际使用的缓冲区结尾;
(5)bufmark,用于标记记录的结尾;
(6)bufindex初始值为0,一个Int型的key写完之后,bufindex增长为4,一个Int型的value写完之后,bufindex增长为8
在kvindex和bufindex之间(包括equator节点)的那一坨数据就是未被Spill的数据。如果这部分数据所占用的空间大于等于Spill的指定百分比(默认是80%),则开始调用startSpill方法进行溢写。对应的方法为:
这里会触发信号量,使得在MapTask类的init方法中正在等待的SpillThread线程继续运行。
继续调用sortAndSpill方法,此方法负责将buf中的数据刷到磁盘。主要是根据排过序的kvmeta把每个partition的数据写到文件中,一个partition对应的数据搞完之后顺序地搞下个partition,直到把所有的partition遍历完(partiton的个数就是reduce的个数)。
Step1:
先计算写入文件的大小;
Step2:
然后获取写到本地(非HDFS)文件的文件名,会有一个编号,例如output/spill2.out;命名格式对应的代码为:
Step3:
使用快排对缓冲区kvbuffe中区间[bufstart,bufend)内的数据进行排序,先按分区编号partition进行升序,然后按照key进行升序。这样经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序;
Step4:
构建一个IFile.Writer对象将输出流传进去,输出到指定的文件当中,这个对象支持行级的压缩。
如果用户设置了Combiner(实际上是一个Reducer),则写入文件之前会对每个分区中的数据进行一次聚集操作,通过combinerRunner.combine(kvIter, combineCollector)实现,进而会执行reducer.run方法,只不过输出和正常的reducer不一样而已,这里最终会调用IFile.Writer的append方法实现本地文件的写入。
Step5:
将元数据信息写到内存索引数据结构SpillRecord中。如果内存中索引大于1MB,则写到文件名类似于output/spill2.out.index的文件中,“2”就是当前Spill的次数。
index文件中不光存储了索引数据,还存储了crc32的校验数据。index文件不一定在磁盘上创建,如果内存(默认1M空间)中能放得下就放在内存中。
out文件、index文件和partition数据文件的对应关系为:
索引文件的信息主要包括partition的元数据的偏移量、大小、压缩后的大小等。
Step6:
Spill结束的时候,会调用resetSpill方法进行重置。
也就是取kvbuffer中剩余空间的中间位置,用这个位置设置为新的分界点。
4.3.5 合并
Map任务如果输出数据量很大,可能会进行好几次Spill,out文件和Index文件会产生很多,分布在不同的磁盘上。这时候就需要merge操作把这些文件进行合并。
Merge会从所有的本地目录上扫描得到Index文件,然后把索引信息存储在一个列表里,最后根据列表来创建一个叫file.out的文件和一个叫file.out.Index的文件用来存储最终的输出和索引。
每个artition都应一个段列表,记录所有的Spill文件中对应的这个partition那段数据的文件名、起始位置、长度等等。所以首先会对artition对应的所有的segment进行合并,合并成一个segment。当这个partition对应很多个segment时,会分批地进行合并,类似于堆排序。最终的索引数据仍然输出到Index文件中。对应mergeParts方法。
4.3.6 相关配置选项
Map的东西大概的就这么多。主要是读取数据然后写入内存缓冲区,缓存区满足条件就会快排,并设置partition,然后Spill到本地文件和索引文件;如果有combiner,Spill之前也会做一次聚集操作,等数据跑完会通过归并合并所有spill文件和索引文件,如果有combiner,合并之前在满足条件后会做一次综合的聚集操作。map阶段的结果都会存储在本地中(如果有reducer的话),非HDFS。
在上面的分析,包括过程的梳理中,主要涉及到以下几种配置选项:
mapreduce.job.map.output.collector.class,默认为MapTask.MapOutputBuffer;
mapreduce.map.sort.spill.percent配置内存开始溢写的百分比值,默认为0.8;
mapreduce.task.io.sort.mb配置内存bufer的大小,默认是100mb;
map.sort.class配置排序实现类,默认为QuickSort,快速排序;
mapreduce.map.output.compress.codec配置map的输出的压缩处理程序;
mapreduce.map.output.compress配置map输出是否启用压缩,默认为false
整完了Map,接下来就是Reduce了。YarnChild.main()—>ReduceTask.run()。ReduceTask.run方法开始和MapTask类似,包括initialize()初始化,根据情况看是否调用runJobCleanupTask(),runTaskCleanupTask()等。之后进入正式的工作,主要有这么三个步骤:Copy、Sort、Reduce。
4.4.2 Copy
Copy就是从执行各个Map任务的节点获取map的输出文件。这是由ReduceTask.ReduceCopier 类来负责。ReduceCopier对象负责将Map函数的输出拷贝至Reduce所在机器。如果大小超过一定阈值就写到磁盘,否则放入内存,在远程拷贝数据的同时,Reduce Task启动了两个后台线程对内存和磁盘上的文件进行合并,防止内存使用过多和磁盘文件过多。
Step1:
首先在ReduceTask的run方法中,通过如下配置来mapreduce.job.reduce.shuffle.consumer.plugin.class装配shuffle的plugin。默认的实现是Shuffle类:
Step2:
初始化上述的plugin后,执行其run方法,得到RawKeyValueIterator的实例。
run方法的执行步骤如下:
Step2.1:
量化Reduce的事件数目:
Step2.2:
生成map的完成状态获取线程,并启动此线程:
获取已经完成的Map信息,如Map的host、mapId等放入ShuffleSchedulerImpl中的Set
Step2.3:
在Shuffle类中启动初始化Fetcher线程组,并启动:
线程的run方法就是进行数据的远程拷贝:
Step2.4:
来看下这个copyFromHost方法。主要是就是使用HttpURLConnection,实现远程数据的传输。
建立连接之后,从接收到的Stream流中读取数据。每次读取一个map文件。
上面的copyMapOutput方法中,每次读取一个mapid,根据MergeManagerImpl中的reserve函数,检查map的输出是否超过了mapreduce.reduce.memory.totalbytes配置的大小,此配置的默认值
是当前Runtime的maxMemory*mapreduce.reduce.shuffle.input.buffer.percent配置的值,Buffer.percent的默认值为0.90。
如果mapoutput超过了此配置的大小时,生成一个OnDiskMapOutput实例。在接下来的操作中,map的输出写入到local临时文件中。
如果没有超过此大小,生成一个InMemoryMapOutput实例。在接下来操作中,直接把map输出写入到内存。
最后,执行ShuffleScheduler.copySucceeded完成文件的copy,调用mapout.commit函数,更新状态或者触发merge操作。
Step2.5:
等待上面所有的拷贝完成之后,关闭相关的线程。
Step2.6:
执行最终的merge操作,由Shuffle中的MergeManager完成:
Step3:
释放资源。
Copy完毕。
4.4.3 Sort
Sort(其实相当于合并)就相当于排序工作的一个延续,它会在所有的文件都拷贝完毕后进行。使用工具类Merger归并所有的文件。经过此过程后,会产生一个合并了所有(所有并不准确)Map任务输出文件的新文件,而那些从其他各个服务器搞过来的 Map任务输出文件会删除。根据hadoop是否分布式来决定调用哪种排序方式。
在上面的4.3.2节中的Step2.4结束之后就会触发此操作。
4.4.4 Reduce
经过上面的步骤之后,回到ReduceTask中的run方法继续往下执行,调用runNewReducer。创建reducer:
并执行其run方法,此run方法就是我们的org.apache.hadoop.mapreduce.Reducer中的run方法。
while的循环条件是ReduceContext.nextKey()为真,这个方法就在ReduceContext中实现的,这个方法的目的就是处理下一个唯一的key,因为reduce方法的输入数据是分组的,所以每次都会处理一个key及这个key对应的所有value,又因为已经将所有的Map Task的输出拷贝过来而且做了排序,所以key相同的KV对都是挨着的。
nextKey方法中,又会调用nextKeyValue方法来尝试去获取下一个key值,并且如果没数据了就会返回false,如果还有数据就返回true。防止获取重复的数据就在这里做的处理。
接下来就是调用用户自定义的reduce方法了。