【Kaggle实战】泰坦尼克号生存人数预测(从零到提交到Kaggle再到模型的保存与恢复)
数据地址:https://www.kaggle.com/c/titanic/data
版本说明:python 3.6 + tensorflow 1.9
项目结构图:
【data】
1.train.csv 训练集
2.test.csv 测试集(不含预测结果)
3.gender_...csv 测试集的预测结果

【data_process.py 数据预处理 人工选择特征】
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
def trainDataProcess(filepath):
"""
训练数据预处理
:param filepath:
:return: data_train, data_target
"""
# 读训练集
data = pd.read_csv(filepath)
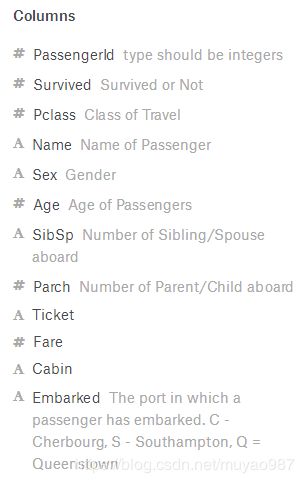
# 人工选特征 已去掉无用特征
data = data[
['Survived', # 是否获救(0/1)
'Pclass', # 客舱等级(1/2/3)
'Sex', # 性别
'Age', # 年龄
'SibSp', # 船上兄妹对象数
'Parch', # 船上爹妈儿女数
'Fare', # 船票价格
'Cabin', # 客舱号
'Embarked' # 登船口
]
]
# 空白值(NA/NaN)的处理 以及String类型字段的数值化
data['Age'] = data['Age'].fillna(data['Age'].mean()) # Age:空白值填入平均年龄
data['Cabin'] = pd.factorize(data.Cabin)[0] # Cabin:元组第0项为数值化的值
data.fillna(0, inplace=True) # 其他的空白值统统填0
data['Sex'] = [1 if x == 'male' else 0 for x in data.Sex]
# Pclass:避免出现 "2等票=1等票*2" 的线性关系 对三个票等级进行one-hot编码 加三个新字段 并删掉原字段
data['p1'] = np.array(data['Pclass'] == 1).astype(np.int32) # p1:0(非1等座) 1(是1等座)
data['p2'] = np.array(data['Pclass'] == 2).astype(np.int32) # p2:0(非2等座) 1(是2等座)
data['p3'] = np.array(data['Pclass'] == 3).astype(np.int32) # p3:0(非3等座) 1(是3等座)
del data['Pclass']
# Embarked:处理方法同上
data['e1'] = np.array(data['Embarked'] == 'S').astype(np.int32)
data['e2'] = np.array(data['Embarked'] == 'C').astype(np.int32)
data['e3'] = np.array(data['Embarked'] == 'Q').astype(np.int32)
del data['Embarked']
# print(data[['p1','Cabin']]) # 去数据用双中括号
# 预处理后的数据字段
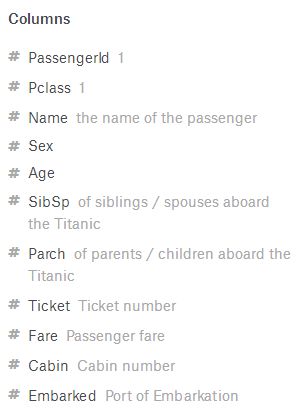
data_train = data[
[
'p1','p2','p3', # 客舱等级(1/2/3)
'Sex', # 性别
'Age', # 年龄
'SibSp', # 船上兄妹对象数
'Parch', # 船上爹妈儿女数
'Fare', # 船票价格
'Cabin', # 客舱号
'e1','e2','e3' # 登船口
]
] # 输入:891*12
data_target = data['Survived'].values.reshape(len(data),1) # 输出891*1 (列向量)
return data_train,data_target
def testDataProcess(filepath):
"""
测试数据预处理
:param filepath:
:return: data_test
"""
# 读训练集
data = pd.read_csv(filepath)
# 人工选特征 已去掉无用特征
data = data[
[
'Pclass', # 客舱等级(1/2/3)
'Sex', # 性别
'Age', # 年龄
'SibSp', # 船上兄妹对象数
'Parch', # 船上爹妈儿女数
'Fare', # 船票价格
'Cabin', # 客舱号
'Embarked' # 登船口
]
]
# 空白值(NA/NaN)的处理 以及String类型字段的数值化
data['Age'] = data['Age'].fillna(data['Age'].mean()) # Age:空白值填入平均年龄
data['Cabin'] = pd.factorize(data.Cabin)[0] # Cabin:元组第0项为数值化的值
data.fillna(0, inplace=True) # 其他的空白值统统填0
data['Sex'] = [1 if x == 'male' else 0 for x in data.Sex]
# Pclass:避免出现 "2等票=1等票*2" 的线性关系 对三个票等级进行one-hot编码 加三个新字段 并删掉原字段
data['p1'] = np.array(data['Pclass'] == 1).astype(np.int32) # p1:0(非1等座) 1(是1等座)
data['p2'] = np.array(data['Pclass'] == 2).astype(np.int32) # p2:0(非2等座) 1(是2等座)
data['p3'] = np.array(data['Pclass'] == 3).astype(np.int32) # p3:0(非3等座) 1(是3等座)
del data['Pclass']
# Embarked:处理方法同上
data['e1'] = np.array(data['Embarked'] == 'S').astype(np.int32)
data['e2'] = np.array(data['Embarked'] == 'C').astype(np.int32)
data['e3'] = np.array(data['Embarked'] == 'Q').astype(np.int32)
del data['Embarked']
# 预处理后的数据字段
data_test = data[
[
'p1','p2','p3', # 客舱等级(1/2/3)
'Sex', # 性别
'Age', # 年龄
'SibSp', # 船上兄妹对象数
'Parch', # 船上爹妈儿女数
'Fare', # 船票价格
'Cabin', # 客舱号
'e1','e2','e3' # 登船口
]
] # 输入:891*12
return data_test
【network.py 构建训练网络】
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
def network(data_train, data_target, data_test, test_lable):
"""
构建网络
:param data_train:
:param data_target:
:param data_test:
:param test_lable:
:return:
"""
x = tf.placeholder("float", shape=[None,12]) # 行数不定(可能分批放入) 故None
y = tf.placeholder("float", shape=[None,1])
weight = tf.Variable(tf.random_normal(shape=[12,1]),name='weight') # 每行输入12值 输出1值
bias = tf.Variable(tf.random_normal(shape=[1]),name='bias')
output = tf.matmul(x,weight)+bias # output = XW+b
pred = tf.cast(tf.sigmoid(output) > 0.5,
tf.float32) # 转成0/1
# 注意:logits取output 因为sigmoid_cross_entropy_with_logits里面要算sigmoid
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y, # 目标值
logits=output)) # 计算值
train_step = tf.train.GradientDescentOptimizer(0.0003).minimize(loss)
accuracy = tf.reduce_mean(tf.cast(tf.equal(pred,y),
tf.float32))
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # 变量初始化
loss_train = [] # 存每1000步的loss
train_acc = [] # 存每1000步的训练集准确率
test_acc = [] # 存每1000步的测试集准确率
for epoch in range(25000):
# 为防止过拟合,对训练顺序(数据索引)随机排序
index = np.random.permutation(len(data_target))
data_train = data_train.iloc[index]
data_target = data_target[index]
for batch in range(len(data_target)//100+1): # batch = 0~9
batch_xs = data_train[batch * 100:batch * 100 + 100] # 每批取100个数据
batch_ys = data_target[batch * 100:batch * 100 + 100]
sess.run(train_step, feed_dict={x:batch_xs,
y:batch_ys})
# 每隔1000步 算一次训练loss和acc 和测试acc
if epoch % 1000 == 0:
loss_temp = sess.run(loss, feed_dict={x:batch_xs,
y:batch_ys})
train_acc_temp = sess.run(accuracy, feed_dict={x:batch_xs,
y:batch_ys})
test_acc_temp = sess.run(accuracy, feed_dict={x:data_test,
y:test_lable})
loss_train.append(loss_temp)
train_acc.append(train_acc_temp)
test_acc.append(test_acc_temp)
print('The epoch ',epoch,
' loss = ',loss_temp,
' train_acc = ',train_acc_temp,
' test_acc = ',test_acc_temp,
'\n', end='')
return loss_train, train_acc, test_acc
【run.py 运行训练并绘制运行结果】
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from Tatanic.data_process import trainDataProcess,testDataProcess
from Tatanic.network import network
if __name__ == '__main__':
# 训练集的输入、输出
data_train, data_target = trainDataProcess('data/train.csv')
# 测试集的输入、期望输出
data_test = testDataProcess('data/test.csv')
test_lable = pd.read_csv('data/gender_submission.csv')
test_lable = np.reshape(test_lable.Survived.values.astype(np.float32),
newshape=(len(test_lable),1)) # 481*1
# 训练
loss_train, train_acc, test_acc = network(data_train=data_train,
data_target=data_target,
data_test=data_test,
test_lable=test_lable)
# 绘图
plt.figure(1)
plt.plot(loss_train, 'k-', label='train_loss')
plt.legend()
plt.title('Titanic death prediction - loss')
plt.figure(2)
plt.plot(train_acc, 'b-', label='train_acc')
plt.plot(test_acc, 'r--', label='test_acc')
plt.title('Titanic death prediction -acc')
plt.legend()
plt.show()
【运行结果及分析】
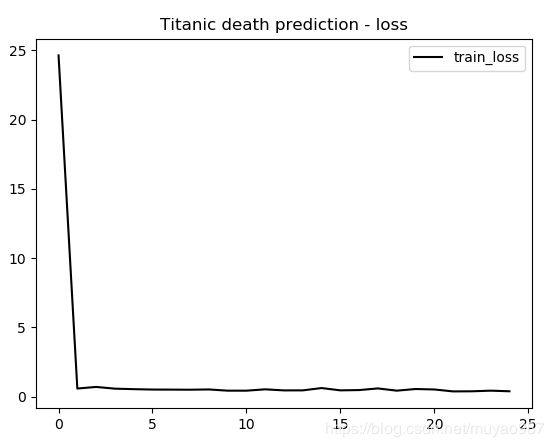
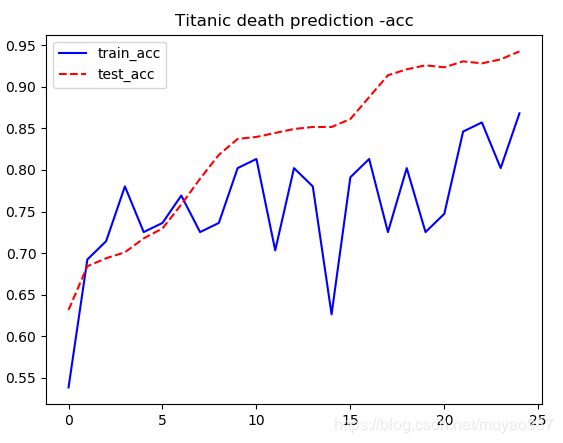
train_acc波动大,是因为电脑比较菜,batch选择的太小(100)。
【提交结果】
1.格式:提交格式是和gender_submission.csv同样的格式
2.提交:
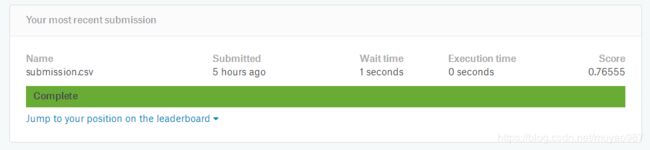
提交成功~~虽然排名有点往后,但也算是走了一遍流程了~
【模型保存恢复】
1.模型保存
...(这里是变量们的定义)
saver = tf.train.Saver()
...(模型训练过程)
saver.save(sess, "tmp/model.ckpt")2.模型恢复
restore。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
if __name__ == '__main__':
x = tf.placeholder("float", shape=[None,12])
weight = tf.Variable(tf.random_normal(shape=[12,1]),name='weight')
bias = tf.Variable(tf.random_normal(shape=[1]),name='bias')
output = tf.matmul(x, weight) + bias
pred = tf.cast(tf.sigmoid(output) > 0.5,tf.float32) # 转成0/1
saver = tf.train.Saver()
sess = tf.Session()
sess.run(tf.global_variables_initializer()) # 变量初始化
saver.restore(sess, "tmp/model.ckpt")
"""
'p1','p2','p3', # 客舱等级(1/2/3)
'Sex', # 性别
'Age', # 年龄
'SibSp', # 船上兄妹对象数
'Parch', # 船上爹妈儿女数
'Fare', # 船票价格
'Cabin', # 客舱号
'e1','e2','e3' # 登船口
"""
# 测试一个来自18岁的头等舱小姐姐
x_test = np.array([0,0,1,0,18,0,0,8,0,1,0,0]).reshape(1,12)
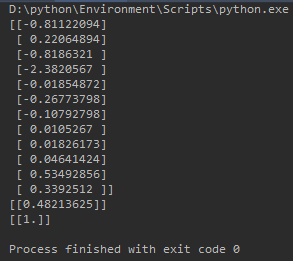
print(sess.run(weight))
print(sess.run(output, feed_dict={x: x_test}))
print(sess.run(pred, feed_dict={x: x_test}))
sess.close()测试结果:
年轻(18岁)又有钱(头等舱)的小姐姐,当然要活下来了!