关系型数据库架构介绍及主流应用场景
前言
做为目前主流的模型数据库类型,关系型数据库的架构随着业务规模的增长做出相应的变化,本章我们来学习关系型数据库架构的变化以及主流的应用场景。
关系型数据库架构
随着业务规模增大,数据库存储的数据量和承载的业务压力也不断增加,数据库的架构需要随之变化,为上层应用提供稳定和高效的数据服务。
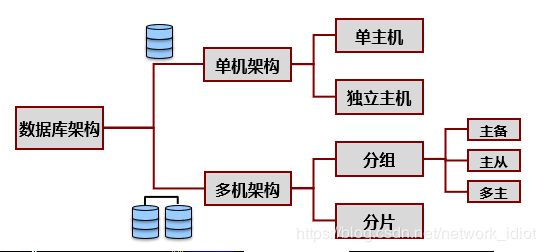
上图所示的数据库架构中单机与多机的区别是按照主机数量进行区分,这里的主机指的是数据库服务器。单机架构就是指单个数据库主机,在单机架构中又分为了单主机和独立主机,所谓的单主机指的是应用和数据库都放在一个主机上,这对主机的性能负担过重,因此有了独立主机,将应用和数据库分开,数据库就放在专门的数据库服务器上,应用就放在专门的应用型服务器上。
多机架构是通过增加服务器数量来提升整个数据库服务的可用性和服务能力,多级架构分为了分组和分片,分组指的是对每个服务器区分角色,这里分为了主备、主从、多主结构。不管是主备、主从还是多主结构本质上都是多个数据库结构相同,储存数据相同的服务器之间进行数据同步。而分片结构则是将数据按照算法分摊在各个节点上,每个节点维护自己的数据库数据。
单机架构
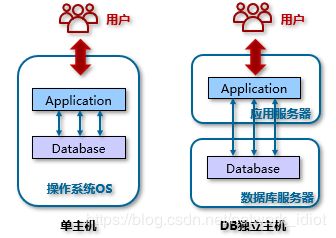
为了避免应用服务和数据库服务对资源的竞争,单机架构也从早期的单主机模式发展到数据库独立主机模式,把应用和数据服务分开。应用服务可以增加服务器数量,进行负载均衡,增大系统并发能力。
| 优点 | 部署集中,运维方便。 | 一个数据库即一个主机,对单机结构服务器进行维护很方便,但同样出现故障也很麻烦。 |
|---|---|---|
| 缺点 | 可扩展性 | 数据库单机架构扩展性只有纵向扩展(Scale-up)。通过增加硬件配置来提升性能,但单台主机的硬件可配置的资源会遇到上限。 |
| 存在单点故障 | 扩容的时候往往需要停机扩容,服务停止。硬件故障导致整个服务不可用,甚至数据丢失。单机会遇到性能瓶颈。 |
早期互联网的LAMP(Linux,Apache,Mysql,PHP)架构的服务器就是最典型的单机架构的使用。
单主机和独立主机的区别
多机架构
分组架构:主备
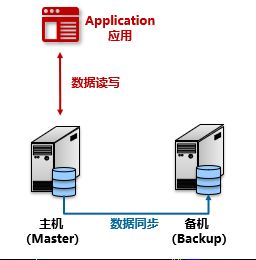
在主备架构中数据的读写都在一台设备上进行,这台设备叫做主机(Master),而另外一台设备被称为备机(Backup),备机在正常情况下不会被使用,只会进行主备直接数据的同步,当主机出现故障后,备机将替代主机的作用进行数据读写。同一时间内只有一台设备能够对外提供服务。
| 优点 | 应用不需要针对数据库故障来增加开发量。相对单机架构提升了数据容错性。解决了单点故障情况。 |
|---|---|
| 缺点 | 资源的浪费,备机和主机同等配置,但长期范围内基本上资源限制,无法利用。性能压力依旧在一台设备上,无法解决性能的瓶颈,当出现故障时主备机切换需要一定的人工干预或者监控。 |
分组架构:主从
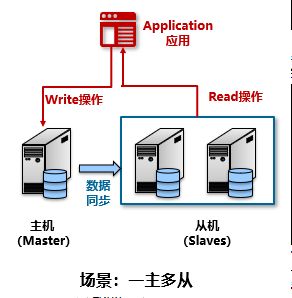
在主从结构中,主机依旧只能有一台,但是从机可以有多台,根据业务需求进行横向的扩展。应用在主机上进行写入、修改、删除操作,把查询请求分配到从机上,而从机与主机之间要进行数据的同步。
| 优点 | 提升资源利用率,适合读多写少的应用场景。在大并发读的使用场景,可以使用负载均衡在多个主机间进行平衡。从机的扩展性比较灵活,扩容操作不会影响到业务进行。 |
|---|---|
| 缺点 | 延迟问题,数据同步到从机数据库时会有延迟,所以应用必须能够容忍短暂的不一致性。对于一致性要求非常高的场景是不适合的。写操作的性能压力还是集中在主机上。主机出现故障,需要实现主从切换,人工干预需要响应时间,自动切换复杂度较高。 |
使用读写分离方式,应用开发模式有时也需要进行调整:应用开发过程中药注意区分读写操作,读操作提交到主机,写操作提交到从机,近年来,不同的数据库产品都出现了中间件来支持读写分离,数据库中间件起到路由功能,会识别读请求和写请求,分别把读写操作分配到读库和写库上。如开源的mycat,vitness等。读多写少是相对而言,许多互联网应用场景是读的事务量远远大于写的事务量,读操作往往先成为性能瓶颈。另外写库出现故障期间,读库仍然可以对外提供服务,表现出“只读”服务,根据从机的数量可以分为一主一从和一主多从。从机数量越多,虽然能够提升数据库读的并发访问量,但是从机之间的数据一致性问题也会带来比较多问题。主机出现故障,自动切换就要解决多台从机如何选举出新主机的问题。对一致性要求不高的应用:如互联网行业的社交网络应用,对一致性要求高的场景:与金融,计费相关的应用。
分组架构:多主
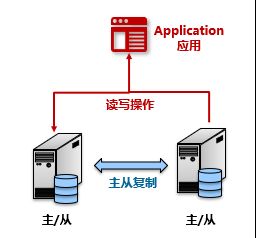
多主架构,也称为双活,多活架构,在多主架构中,每一台设备都不再区分从设备,都互为主从。每台设备都能对上提供服务。
| 优点 | 资源利用率较高的同时降低了单点故障的风险。 |
|---|---|
| 缺点 | 双主机都接受写数据,要实现数据双向同步。双向复制同样会带来延迟问题,极端情况下有可能数据丢失。数据库数量增加会导致数据同步问题变得极为复杂,实际应用中多见双机模式。 |
互为主从模式下的数据同步机制更为复杂,所以数据延迟、丢失都由可能存在,所以对于一致性要求非常高的场景,不适合使用这种架构。
共享存储多活架构
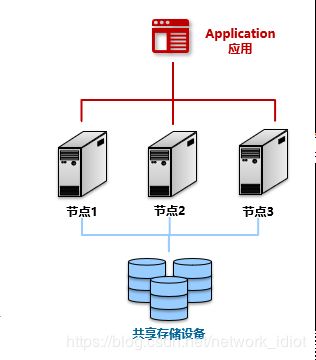
共享存储的多活架构(Shared Disk)是一种特殊的多主架构。数据库服务器共享数据存储,而多个服务器实现均衡负载。它解决了多主结构中的数据一致性问题,所有节点共享一个储存设备,因此不会出现数据不一致的问题。
| 优点 | 多个计算服务器提供高可用服务,提供了高级别的可用性。可伸缩性,避免了服务器集群的单点故障问题。比较方便的横向扩展能够增加整体系统并行处理能力。 |
|---|---|
| 缺点 | 实现技术难度大。当存储器接口带宽达到饱和的时候,增加节点并不能获得更高的性能,存储IO容易成为整个系统的性能瓶颈。 |
shared disk较为成功的案例目前,有Oracle的RAC(Real Application Cluster)产品, 微软的SQL Server Failover Cluster
分片(Sharding)架构
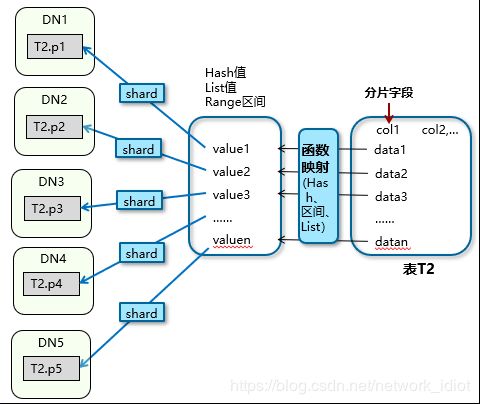
分片架构主要表现形式就是水平数据分片架构,把数据分散在多个节点上的分片方案,每一个分片包括数据库的一部分,称为一个shard。多个节点都拥有相同的数据库结构,但不同分片的数据之间没有交集,所有分区数据的并集构成数据总体。
| 优点 | 数据分散在集群内的各个节点上,所有节点可以独立性工作。 |
|---|
GaussDB 100可以支持,单机,主备,主从的架构部署方式,分布式版本支持分片架构的部署方式。目前正在计划开发共享存储多活的架构。
无共享(Share-Nothing)架构
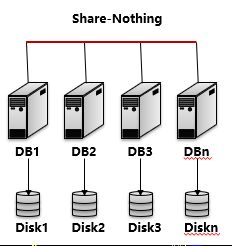
无共享架构非常类似共享式储存多活架构,主不过不再使用共享的储存,而是每个节点使用维护各自的独立CPU/内存/储存,不存在共享资源。各节点(处理单元)处理自己本地的数据,处理结果可以向上层汇总或者通过通信协议在节点间流转。节点是相互独立的,扩展能力强。整个集群拥有强大的并行处理能力。
可以说明一下,在硬件发展到当前时代,一个节点或一个物理主机上可以部署多个处理单元,所以Shared-Nothing的最小单元可能不是物理节点,而是逻辑上的虚拟处理单元。比如一个物理主机具有4核CPU,部署的时候可以部署4个数据库实例,也就相当于拥有4个处理单元。
MPP架构 (Massively Parallel Processing)
大规模并行处理(Massively Parallel Processing)是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
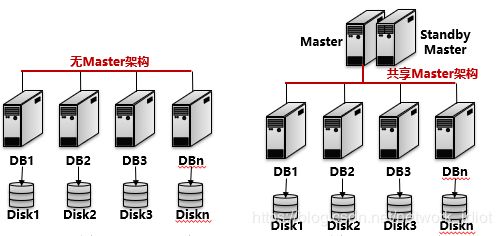
分为了两种架构
| 无Master架构 | 所有节点都对等,可以通过任意的节点查询和写入数据,不存在性能瓶颈以及单点故障问题,可以进行横向扩展。 |
|---|---|
| 共享Master架构 | Master对外提供服务,任务由各个节点并行计算处理,结果上交给Master。 |
常见的MPP产品
| 无共享Master | Vertica,Teradata。 |
|---|---|
| 共享Master | Greenplum,Netezza。 |
Teradata,Netezza是软硬件一体机,GaussDB 200,Greeplum,Vertica是软件版MPP数据库
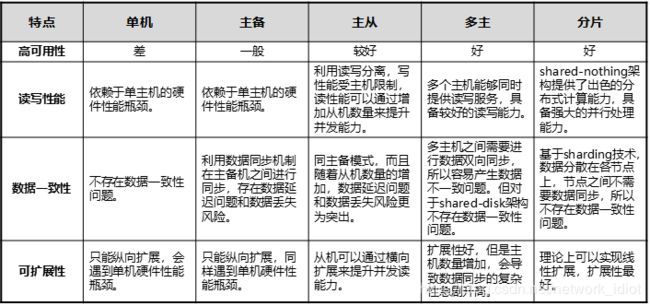
数据库架构特点对比
关系型数据库主流应用场景
联机事务处理 (OnLine Transaction Processing)
OLTP是传统关系数据库的主要应用,面向基本的,日常的事务处理,例如银行储蓄业务的存取交易,转账交易等。业务量大,但是单个业务需要处理的数据量小,类似银行中的每日流水,都是些基本的信息赠,删,改,查操作。
特点:
大吞吐量:大量的短在线事务(插入、更新、删除),非常快速的查询处理。高并发,(准)实时响应。
典型的OLTP应用场景
零售系统、金融交易系统、火车机票销售系统、秒杀活动等。
事务
而所谓的数据库事务是数据库执行过程中的一个基本逻辑单位,数据库系统要确保一个事务中的所有操作都成功完成且结果永久保存在数据库中。且一个事务中的操作要么都执行,要么都不执行。
例如:某人要在商店使用电子货币购买100元的东西,当中至少包括两个操作,他的账户上少100元,而商铺账户上多100元,这是一个事务,两个操作,而数据库要保证该两个操作都成功且结果保存,不然就有可能发生用户账户没扣成功,反而商铺账户上凭空多出来100元。
但在现实情况下,失败的风险很高。在一个数据库事务的执行过程中,有可能会遇上事务操作失败、数据库系统/操作系统出错,甚至是存储介质出错等情况。这便需要DBMS对一个执行失败的事务执行恢复操作,将其数据库状态恢复到一致状态(数据的一致性得到保证的状态)。为了实现将数据库状态恢复到一致状态的功能,DBMS通常需要维护事务日志以追踪事务中所有影响数据库数据的操作。
联机分析处理 (OnLine Analytical Processing)
OLAP是指对数据的查询和分析操作,通常对大量的历史数据查询和分析。涉及到的历史周期比较长,数据量大,在不同层级上的汇总,聚合操作使得事务处理操作比较复杂。数据处理方面聚焦于数据的聚合,汇总,分组计算,窗口计算等“分析型”数据加工和操作。从多维度去使用和分析数据。
典型的OLAP场景
报表系统,CRM系统。金融风险预测预警系统、反洗钱系统。数据集市,数据仓库。
| 报表系统 | 是产生固定周期报表的,或者上报固定格式报表数据的平台或系统,如日报,周报,月报,月报,为经营决策提供电子化报表数据。 |
|---|---|
| CRM系统 | 客户关系管理系统,维护客户,对客户相关信息进行存储,客户行为进行分析, 对客户进行响应,挽留和市场活动管理等综合性业务系统平台。 |
| 数据集市 | 就一般是面向一个组织中某个部门级别需求的应用需要,比如信用卡部门的分析需求。 |
| 数据仓库 | 是面向企业级别的构建整个企业分析处理环境而产生的分析类平台系统。 |
数据库性能衡量指标
TPC(Transaction Processing Performance Council,事务处理性能委员会)
职责是制定商务应用基准测试标准(Benchmark)的规范、性能和价格度量,并管理测试结果的发布。制定的是标准规范而不是代码,任何厂家依据规范最优地构造自己系统进行评测。推出了很多基准测试标准,其中针对OLTP和OLAP分别有两个规范。
TPC-C规范
面向OLTP系统,主要包括两个指标:
流量指标 tpmC(tpm – transactions per minuete, 即每分钟测试系统处理的事务数量)。
性价比指标 Price(测试系统价格)/tmpC。
TPC-H规范
面向OLAP类系统
流量指标:qphH – Query per hour,即每小时处理的复杂查询数量。需要考虑测试数据集合大小,分为不同的测试数据集,指定了22个查询语句,可以根据产品微调。测试场景:数据加载,Power能力测试和Througput测试。
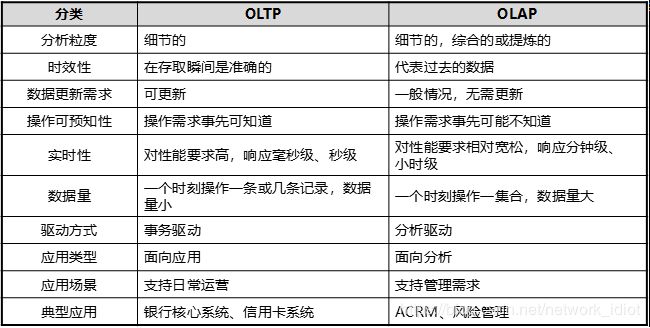
OLTP和OLAP对比分析