如何用 fast.ai 高效批量推断测试集?
简洁和效率,我们都要。

痛点
通过咱们之前几篇 fast.ai 深度学习框架介绍,很多读者都认识到了它的威力,并且有效加以了利用。
fast.ai 不仅语法简洁,还包裹了很多实用的数据集与预训练模型,这使得我们在研究和工作中,可以省下大量的时间。
跟着教程跑一遍,你会发现做图像、文本分类,乃至推荐系统,其实是非常简单的事情。
然而,细心的你,可能已经发现了一个问题:
fast.ai 训练数据体验很好;可做起测试集数据推断来,好像并不是那么高效。
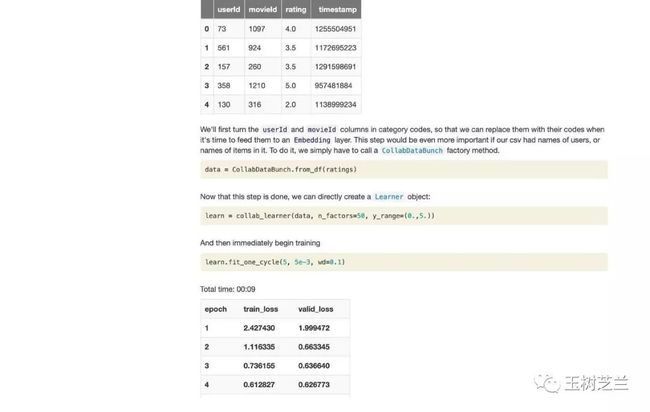
教程里面,模型训练并且验证后,推断/预测是这么做的:

如果你只是需要对单个新的数据点做推断,这确实足够了。
但是如果你要推断/预测的是一个集合,包含成千上万条数据,那么该怎么办呢?
你可能会想到,很简单,写个循环不就得了?
从道理上讲,这固然是没错的。
但是你要真是那么实践起来,就会感觉到等待的痛苦了。
因为上面这条语句,实际上效率是很低的。
这就如同你要搬家。理论上无非是把所有要搬的东西,都从A地搬到B地。
但是,你比较一下这两种方式:
方法一,把所有东西装箱打包,然后一箱箱放到车上,车开到B地后,再把箱子一一搬下来。
方法二,找到一样要搬的东西,就放到车上,车开到B地,搬下来。车开回来,再把下一样要搬的东西放上去,车开走……重复这一过程。
你见过谁家是用方法二来搬家的?
它的效率太低了!
用循环来执行 predict 函数,也是一样的。那里面包含了对输入文本的各种预处理,还得调用复杂模型来跑这一条处理后的数据,这些都需要开销/成本。
怎么办?
其实,fast.ai 提供了完整的解决方案。你可以把测试集作为整体进行输入,让模型做推断,然后返回全部的结果。根本就不需要一条条跑循环。
可是,因为这个方式,并没有显式写在教程里面,导致很多人都有类似的疑问。
这篇文章里,我就来为你展示一下,具体该怎么做,才能让 fast.ai 高效批量推断测试集数据。
为了保持简洁,我这里用的是文本分类的例子。其实,因为 fast.ai 的接口逻辑一致,你可以很方便地把它应用到图像分类等其他任务上。
划分
为了保持专注,我们这里把一个模型从训练到推断的过程,划分成两个部分。
第一部分,是读取数据、训练、验证。
第二部分,是载入训练好的模型,批量推断测试集。
我把第一部分的代码,存储到了 Github 上,你可以在我的公众号“玉树芝兰”(nkwangshuyi)后台回复“train”,查看完整的代码链接。
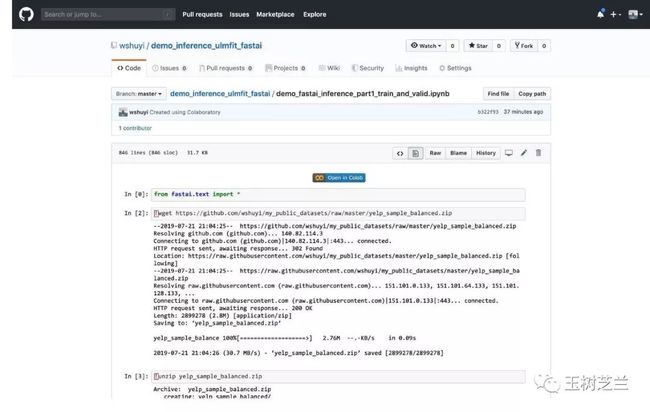
点击其中的“Open in Colab”按钮,你可以在 Google Colab 云端环境打开并且执行它,免费使用 Google 提供的高性能 GPU 。
如果你想了解其中每一条代码的具体含义,可以参考我的这篇《如何用 Python 和深度迁移学习做文本分类?》。
注意,在其中,我加入了3条额外的数据输出语句。
分别是:
data_clas.save('data_clas_export.pkl')
这一条,存储了我们的分类数据(包含训练集、验证集、测试集)及其对应的标签。注意,因为 fast.ai 的特殊假设(具体见后文“解释”部分),测试集的标签全部都是0。
也正因如此,我们需要单独存储测试集的正确标签:
with open(path/"test_labels.pkl", 'wb') as f:
pickle.dump(test.label, f)
除了上述两条之外,你还需要保留训练好的模型。
毕竟,为了训练它,我们也着实是花了一番时间的。
learn.export("model_trained.pkl")
上述 pickle 数据文件,我都存储到了 Gitlab 公共空间。后面咱们要用到。
这就是训练和存储模型的全部工作了。
第二部分,才是本文的重点。
这一部分,我们开启一个全新的 Google Colab 笔记本,读入上述三个文件,并且对测试集进行批量推断。
这个笔记本,我同样在 Github 上存储了一份。
你可以在后台回复“infer”,找到它的链接。
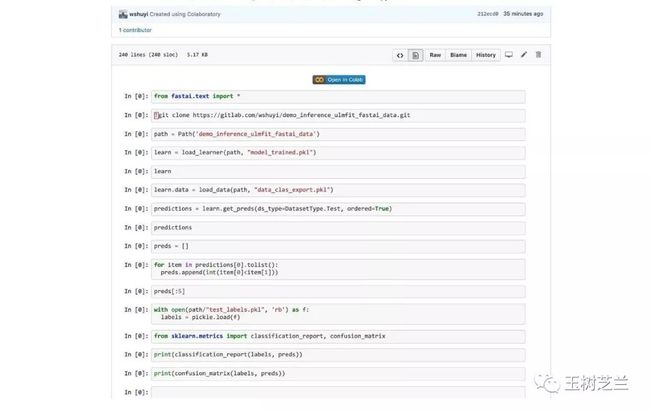
下面,我给你一一讲解每一条代码语句的作用,并且告诉你一些关键点,避免你在使用过程中,跟我一样踩坑。
代码
首先,你要读入 fast.ai 的文本处理包。
from fastai.text import *
注意这个包可不只是包含 fast.ai 的相关函数。
它把许多 Python 3 新特性工具包,例如 pathlib 等,全都包含在内。这就使得你可以少写很多 import 语句。
下面,是从 Gitlab 中下载我们之前保存的 3 个 pickle 数据文件。
!git clone https://gitlab.com/wshuyi/demo_inference_ulmfit_fastai_data.git
如果你对 pickle 数据不是很熟悉,可以参考我的这篇文章《如何用 Pandas 存取和交换数据?》。
我们设定一下数据所在目录:
path = Path('demo_inference_ulmfit_fastai_data')
下面,我们就要把训练好的模型恢复回来了。
learn = load_learner(path, "model_trained.pkl")
不过这里有个问题。
虽然 fast.ai 是高度集成的,但为了避免训练结果占用空间过大,模型和数据是分别存储的。
这时我们读取回来的,只有一个预训练模型架构。配套的数据,却还都不在里面。
我们可以通过展示学习器 learn 的内容,来看看。
learn
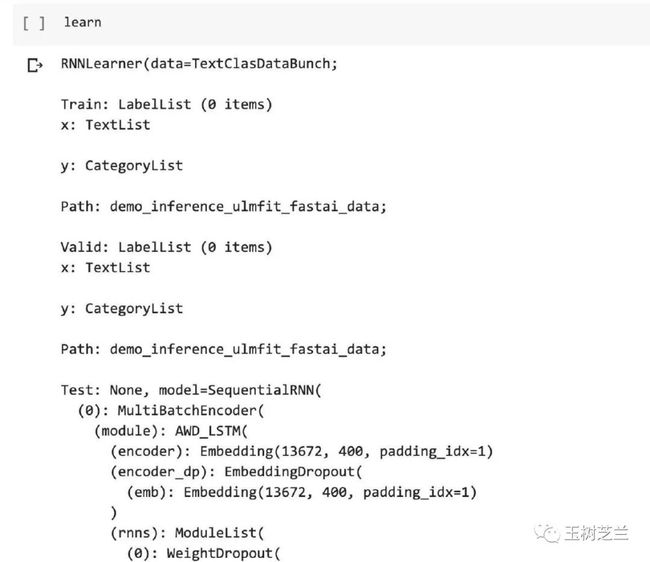
注意下方架构的数据是完整的,但是训练集、验证集、测试集的长度,都是0。
这时候,我们就需要自己读入之前存好的分类数据了。
learn.data = load_data(path, "data_clas_export.pkl")
数据、模型都在,我们可以进行测试集数据推断了。
predictions = learn.get_preds(ds_type=DatasetType.Test, ordered=True)
注意这一句里,函数用的是 get_preds 。说明我们要批量推断。
数据部分,我们指定了测试集,即 DatasetType.Test。但是默认情况下,fast.ai 是不保持测试集数据的顺序的。所以我们必须指定 ordered=True 。这样才能拿我们的预测结果,和测试集原先的标记进行比较。
测试集推断的结果,此时是这样的:
predictions

这个列表里面包含了 2 个张量(Tensor)。
千万不要以为后面那个是预测结果。不,那就是一堆0.
你要用的,是第一个张量。
它其实是个二维列表。
每一行,代表了对应两个不同分类,模型分别预测的概率结果。
当然,作为二元分类,二者加起来应该等于1.
我们想要的预测结果,是分类名称,例如0还是1.
先建立一个空的列表。
preds = []
之后,用一个循环,一一核对哪个类别的概率大,就返回哪个作为结果。
for item in predictions[0].tolist():
preds.append(int(item[0]<item[1]))
看看我们最终预测的标记结果:
preds[:5]

为了和真实的测试集标记比较,我们还要读入第三个文件。
with open(path/"test_labels.pkl", 'rb') as f:
labels = pickle.load(f)
预测结果与真实标记我们都具备了。下面该怎么评价模型的分类效果?
这时可以暂时抛开 fast.ai ,改用我们的老朋友 scikit-learn 登场。
它最大的好处,是用户界面设计得非常人性化。
我们这里调用两个模块。
from sklearn.metrics import classification_report, confusion_matrix
先来看分类报告:
print(classification_report(labels, preds))
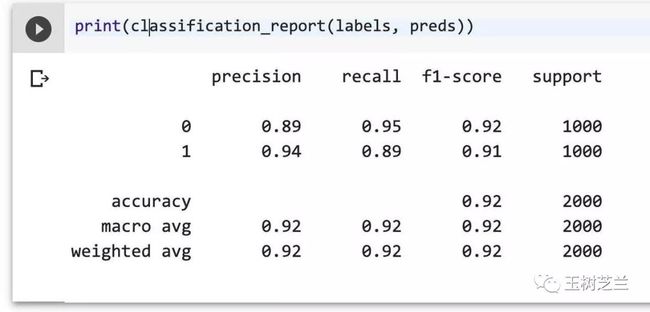
几千条数据训练下来,测试集的 f1-score 就已经达到了 0.92 ,还是很让人振奋的。
fast.ai 预置的 ULMfit 性能,已经非常强大了。
我们再来看看混淆矩阵的情况:
print(confusion_matrix(labels, preds))
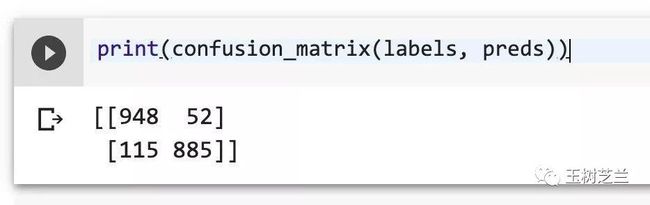
分类的错误情况,一目了然。
解释
讲到这里,你可能还有一个疑惑,以易用著称的 fast.ai ,为什么没有把测试集推断这种必要功能做得更简单和直观一些?
而且,在 fast.ai 里,测试集好像一直是个“二等公民”一般。
以文本分类模型为例。
TextDataBunch 这个读取数据的模块,有一个从 Pandas 数据框读取数据的函数,叫做 from_df。
我们来看看它的文档。

注意这里,train_df(训练集) 和 valid_df (验证集)都是必填项目,而 test_df 却是选填项目。
为什么?
因为 fast.ai 是为你参加各种学术界和业界的数据科学竞赛提供帮助的。
这些比赛里面,往往都会预先给你训练集和验证集数据。
但是测试集数据,一般都会在很晚的时候,才提供给你。即便给你,也是没有标记的。
否则,岂不是成了发高考试卷的时候,同时给你标准答案了?
看过《如何正确使用机器学习中的训练集、验证集和测试集?》一文后,再看 fast.ai 的设计,你就更容易理解一些。
你训练模型的大部分时候,都不会和测试集打交道。甚至多数场景下,你根本都没有测试集可用。
所以,fast.ai 干脆把它做成了可选项,避免混淆。
然而,这种设计初衷虽然好,却也给很多人带来烦恼。尤其是那些不参加竞赛,只是想和已有研究成果对比的人们。
大量场景下,他们都需要频繁和测试集交互。
我建议 fast.ai ,还是把这部分人的需求考虑进来吧。至少,像本文一样,写个足够简明的文档或样例,给他们使用。
小结
通过这篇文章的学习,希望你掌握了以下知识点:
如何保存在 fast.ai 中训练的模型;
如何在 fast.ai 中读取训练好的模型,以及对应的数据;
如何批量推断测试集数据;
如何用 scikit-learn 进行分类测试结果汇报。
祝深度学习愉快!
征稿
SSCI 检索期刊 Information Discovery and Delivery 要做一期《基于语言机器智能的信息发现》( “Information Discovery with Machine Intelligence for Language”) 特刊(Special Issue)。

本人是客座编辑(guest editor)之一。另外两位分别是:
我在北得克萨斯大学(University of North Texas)的同事 Dr. Alexis Palmer 教授
南京理工大学章成志教授

征稿的主题包括但不限于:
Language Modeling for Information Retrieval
Transfer Learning for Text Classification
Word and Character Representations for Cross-Lingual Analysis
Information Extraction and Knowledge Graph Building
Discourse Analysis at Sentence Level and Beyond
Synthetic Text Data for Machine Learning Purposes
User Modeling and Information Recommendation based on Text Analysis
Semantic Analysis with Machine Learning
Other applications of CL/NLP for Information Discovery
Other related topics
具体的征稿启事(Call for Paper),请查看 Emerald 期刊官网的这个链接(http://dwz.win/c2Q)。
作为本专栏的老读者,欢迎你,及你所在的团队踊跃投稿哦。
如果你不巧并不从事上述研究方向(机器学习、自然语言处理和计算语言学等),也希望你能帮个忙,转发这个消息给你身边的研究者,让他们有机会成为我们特刊的作者。
谢谢!
延伸阅读
你可能也会对以下话题感兴趣。点击链接就可以查看。
如何高效学 Python ?
《文科生数据科学上手指南》分享
如何用 Python 和 fast.ai 做图像深度迁移学习?
如何用 Python 和深度迁移学习做文本分类?
如何用 Python 和 BERT 做中文文本二元分类?
感觉有用的话,请点“在看”,并且把它转发给你身边有需要的朋友。
赞赏就是力量。

由于微信公众号外部链接的限制,文中的部分链接可能无法正确打开。如有需要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。
订阅我的微信公众号“玉树芝兰”,第一时间免费收到文章更新。别忘了加星标,以免错过新推送提示。

如果你对 Python 与数据科学感兴趣,希望能与其他热爱学习的小伙伴一起讨论切磋,答疑解惑,欢迎加入知识星球。
题图: Photo by Tim Evans on Unsplash