深度CTR之Graph Embedding:阿里电商推荐中亿级商品的Graph Embedding
介绍
阿里巴巴团队发表于KDD 2018,文章题目-《Attentional Factorization Machines:Learning the Weight of Feature Interactions via Attention Networks》。阿里的推荐系统是按照matching + ranking的两步策略,本文解决的是matching阶段的问题,即商品召回阶段的问题。
paper中说到taobao的推荐系统主要面临了3个主要问题:
- 可扩展性:十亿用户,二十亿商品的量级;
- 稀疏性:有些用户和商品之间的交互信息特别少,导致无法精确的训练推荐模型;
- 冷启动:新商品的冷启动问题,taobao上每小时会上线百万级的新商品,而用户与新商品之间没有交互信息,因此无法很好建模用户对商品偏好。
paper主要解决的是matching阶段中对应上面的3类问题。在这之前,taobao的推荐系统在召回阶段主要是使用协同过滤的方法,计算不同商品之间的相似性,来生成商品候选集合。这篇文章中主要是用Graph技术来学习商品的embedding向量,但是考虑到前人工作中Graph embedding的缺点,paper作者引入了辅助信息来学习商品向量表达,再计算商品之间的相似性。作者在构建商品Graph的时候,使用了启发式的方法,从数十亿的用户历史行为中构建商品Graph。paper中先后实验的方案为:
- Base Graph Embedding (BGE);
- Graph Embedding with Side information (GES);
- Enhanced Graph Embedding with Side information (EGES)。
最后作者也介绍了在taobao的大规模的用户和商品量级的规模下,他们也构建了graph embedding系统XTensorflow来支持算法的上线。
框架
这篇文章的思路也是受到最原始的Graph Embedding方法的启发,例如DeepWalk方法,DeepWalk方法就是先通过在graph中随机游走来生成节点的序列,然后应用Skip-gram算法来学习graph中节点的Embeddding表示。沿着这个思路,paper中也是按照两步来介绍的,1)基于用户历史行为构建图结构,2)学习图中item的embedding表示。
基于用户历史行为的 Item Graph的构建
在淘宝中,用户的历史行为都是具有时间序列特点的,例如图2(a)所示,而协同过滤算法中只考虑到商品之间的共现性,而没有将商品的序列关系纳入考虑,而在我们的item graph构建过程中,会考虑商品的序列信息,但是由于计算量和存储空间的成本高、以及用户的兴趣具有随着时间而漂移的特点,因此我们在使用用户历史行为信息时,基于以前的经验,只使用一个小时时间窗口内的历史行为item用于构建item graph,paper中也提到,对于这种一个小时的时间窗口称之为session。

当我们得到基于session的用户历史行为时,在一个session中,我们可以得到item之间的顺序关系,例如在图2(a)中的顺序关系已经反映在了图2(b)中了,而在图2(b)中,节点之间的连接权重被赋值为两个item共现的次数。但是在构建item graph时,对于下面的三类脏数据和不正常行为会过滤掉:
- 点击后停留时间太短,例如不超过1秒的;
- 三个月内购买超过1000个商品或者点击次数大于3500次的,这种过于活跃的用户,有可能是刷单等异常行为;
- 由于商家会给同一个标志码的商品不断地做一些细节上的更新,但是有可能一段时期后,同一个标志码的商品已经变得完全不一样了,对于这种情况,我们会直接去除。
Base版的Graph Embedding
基于图2(b)中的权重有向item graph,paper中使用DeepWalk的随机游走方法生成节点序列,并在序列上运行Skip-gram算法来学习节点的Embedding表示,按照节点间的权重关系将随机游走的节点转移概率定义为:

我们使用Skip-gram算法学习Embedding向量,该算法是最大化序列中两个节点的共现概率,因此我们可以关联到下面的负数似然概率的优化问题:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DErwibt8-1582962385069)(evernotecid://AFC3459F-70B1-4432-9FEA-943ED3F7E284/appyinxiangcom/22185754/ENResource/p548)]](http://img.e-com-net.com/image/info8/e2bdc6f3e77d4333af297ed72ac3b45d.jpg)
其中,w表示序列中上下文节点的窗口大小,如果假设节点之间是相互独立的,即独立性假设的情况下,可以得到下面的公式:

我们通过借鉴Word2vec中的负采样算法,那么方程(3)可以转化为下面的式子:
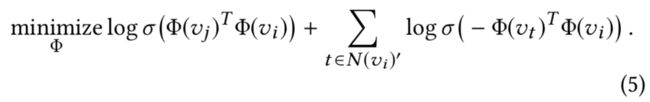
其中,
N ( v i ) ′ N(v_i)' N(vi)′
表示v_i的负样本,而 σ 表示sigmoid函数
σ ( x ) = 1 1 + e − x \sigma (x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
理论上来说,
∣ N ( v i ) ′ ∣ |N(v_i)'| ∣N(vi)′∣
越大越好,当然这也会带来更大的计算量上的负担。
加入辅助信息的Graph Embedding
虽然在基本的graph embedding方法中,通过用户的行为序列,可以学习到协同过滤方法无法学习到的高阶相似性(因为加入了点击商品的序列信息),但是对于需要冷启动的商品,由于其缺乏用户和该商品之间的交互,因此仍旧无法较好的学习其embedding表示。因此这部分使用了item的辅助信息来学习item Embedding,用于解决item的冷启动问题。
paper中举了一些例子来说明当对item加入category、shop、price等辅助信息时的作用,例如来自于优衣库(shop相同)的两件外套(category相同),那么他们的embedding表示应该比较相似。基于类似的假设,paper中提出了GES的方法,如图3所示。

在GES中,使用W表示item及其辅助信息的embedding矩阵,W_v^0表示item v的embedding,W_v^s表示item v的第s个辅助信息的embedding,如果一共有n个辅助信息的话,那么对item v来说,将会有 n+1 个向量
W v 0 , … , W v n ∈ R d W_v^0, \dots, W_v^n \in \mathbb{R}^d Wv0,…,Wvn∈Rd
其中d表示embedding向量的维度,在paper中,作者提到了经验上的结论为,把item和其辅助信息的embedding的维度设置成相同时的效果更好。
在图3中可以看到,paper中的处理方式比较common,添加一个隐层,对这n+1个embedding向量做avg pooling的聚合操作,其中,H_v就表示item v的聚合embedding表示了。这样的处理方式貌似可以较好的解决item的冷启动问题了。

加入辅助信息的增强型Graph Embedding
上面GES算法中,虽然使用了辅助信息学习到了更好的item的embedding表示,而且一定成都上缓解了item的冷启动问题,但是依然存在一些明显的问题,就是item v的所有的辅助信息对于最终的embedding表示的贡献不一定是完全相同的,但是在GES方法中是按照完全一样来计算的。对于item v,
A ∈ R ∣ V ∣ ∗ ( n + 1 ) A \in \mathbb{R}^{|V|*(n+1)} A∈R∣V∣∗(n+1)
表示权重矩阵,A_ij 表示第i个item的第j个辅助信息,而A的第一列数值A_{*0} 表示item 自身的权重。也就是说,a_v^s表示item v的第s个辅助信息的权重,而a_v^0表示item v本身的权重值,而该层组合了不同的辅助信息的加权平均网络定义如下:

paper中使用指数计算得到权重,即e^{a_v^j}代替a_v^j以确保每个辅助信息的权重贡献值大于0。
在训练样本中,对于节点v和其上下文节点u,使用
Z u ∈ R d Z_u \in \mathbb{R}^d Zu∈Rd
来表示u的embedding表示,使用y来表示其label,那么EGES的loss函数为
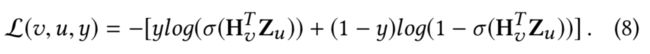
上式对Z_u求导(其实就是交叉上损失函数的求一阶导数)得到
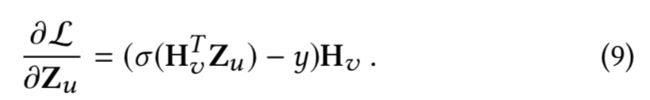
如果公式(9)再进一步对辅助信息的权重求导的话,得到

而如果公式(9)再进一步对辅助信息的embedding表示求导的话,得到
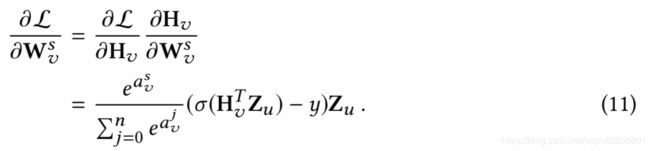
下面是EGES的伪代码,Alg1给出了EGES的整个框架,Alg2给出了权重Skip-gram算法的计算流程,Alg2的核心其实就在于根据正、负样本更新参数辅助信息权重a_v^s和辅助信息embedding表示W_v^s。


实验
离线评估
实验中使用了比较common的链接预测任务,使用的数据集为Amazon和Taobao的数据集,他们对应的节点数量、边数量、辅助信息数量、稀疏度如表1所示,两个数据集的稀疏性都非常高。其中Amazon数据集的item graph主要根据共现性来构造,而taobao数据集主要基于前面讲到的session-based的历史行为来构造的。

paper中主要实验的方法为BGE, LINE, GES, EGES,其中LINE方法是在graph embedding中捕获一阶和二阶近似。
实验结果如表2所示,结果显示,GES和EGES方法在Amazon和Taobao数据集的效果均优于BGE、LINE(1st)、LINE(2nd)方法的效果。值得注意的地方为:
- GES和EGES方法在 Taobao数据集相比于Amazon数据集上的效果提升更加明显,这可能是由于Taobao数据集的辅助信息更加丰富和有效;
- EGES方法相比于GES方法,可以使得Amazon数据集的效果提升更加明显,但是对于Taobao数据集的效果提升却不那么明显,这可能是因为GES的效果已经非常好了,所以EGES的提升也没那么显著。

在线A/B测
因为paper中学习到的item 的向量表示最终用于推荐系统中的item召回阶段,因此最终评估item embedding的方式也是推荐系统中常见的点击率评估方法,如果在召回阶段通过使用graph embedding代替传统的CF方法的召回物料质量更高的话,那么对于最终线上的ctr一定会有提升的效果的。

而从结果上来看,基于引入辅助信息的GES和EGES方法确实能够取得更好的线上点击率效果。
Case Study
可视化:paper中使用了tensorflow中自带的可视化工具进行embedding的可视化,从图7(a)中可以看到不同种类的鞋子分布在不同的簇中,而具有相似辅助信息的鞋子会更加相似;而图7(b)中进一步分析了乒乓球、羽毛球、足球这三种不同运动的鞋子,并在图中展示了乒乓球、羽毛球这两种鞋子更加相近,而足球鞋子会距离更远一些,这也更加符合中国人的特点,因为乒乓球、羽毛球更偏向于室内运动(相似性更高),而足球更偏向于室外运动。
冷启动item:对于没有user和item之间交互信息的冷启动item来说,可以使用其辅助信息向量的average pooling值来表示该冷启动item,这在之前传统的CF方法中无法实现。
EGES中的权重:图6可视化了不同item的不同类型的辅助信息的权重,从图中可以看到:
- 不同的item的辅助信息的权重大小是不同的;
- 所有的item中,Item自身embedding表示的权重是最大的;
- 除了Item自身embedding表示的权重外,Shop的embedding表示的权重是最大的,这是因为对于Taobao的用户来说,用户会为了方便性和低价的好处,更倾向于在同一店铺中购买商品。

系统部署和操作

在介绍Taobo的graph embedding学习系统之前,我们先了解下整个taobao的推荐系统,其分为在线系统和离线系统。
在线系统包括Taobao个性化平台(TPP)和排序服务平台(RSP),其在线系统的整个工作流为:
- 用户打开app后,TPP会获取用户最新的数据特征以及从离线系统中获取item候选集,然后将item候选集喂入到RSP中,排序模型会对使用深度神经网络对候选集的item进行打分和排序,并将排序结果返回给TPP,然后TPP再将排序结果展示到用户app上。
- 用户在使用过程中的行为信息会被收集下来并保存成日志数据,之后会再继续服务于离线系统。
而对于离线系统中的graph embedding的工作流如下,这里只简单说下,具体可以参考下paper原文:
- 获取到用户行为的日志数据,取最近3个月的数据构建item graph。但是在此之前需要对用户数据进行反爬虫处理(以及其他去除脏数据的数据处理方法),然后才基于用户行为取生成sessin-based的序列。
- 然后就是实现item graph方法,再基于基于ODPS平台的分布式训练来进行学习;
- 在XTF平台上,整个的日志获取、反爬处理、item graph构建、随机游走生成session序列、item to item的相似性计算和映射生成这些过程只需要在6个小时内就可以计算完成。
总结和未来展望
总结:针对稀疏性、item冷启动、大规模(十亿用户和二十亿商品)这三个问题,作者分别提出了解决方案。对于稀疏性、item冷启动问题,paper提出了将item的辅助信息融入到item graph中来学习的graph embedding,而对于大规模的数据量问题,则详细介绍了训练graph embedding所依托的阿里的各种计算平台的优势。
展望:paper中也提出了未来将要继续探索的一些领域,一是将在graph embedding中加入attention机制,以更灵活地学习到辅助信息的权重;二是将item下的用户评论中的文本信息数据加入到item graph中去学习graph embedding。