一、概述
如果你小时候看过神奇宝贝,或者宝可梦(Pokemon)的动画片,你可能听过一个叫宝可梦图鉴的东西。由于宝可梦种类太多,而且有不同的进化等级,你在街上遇到一个宝可梦,可能一时想不起来他的名字和相关属性,这时候你可能就需要掏出你的宠物图鉴,就像下面的小智一样:

言归正传..本文记录了自己通过基本计算机视觉技术搭建一个简版宝可梦图鉴的过程。接收用户给定的输入图像,输出对应的pokemon名称。不过本文重点在于建立一个完整的图像处理管线,选择的图像描述方法比较简单和单一(形状描述子和颜色描述子),所以模型其实并不鲁棒。待以后学习一些更高级的描述子,如SIFT,LBP,HOG,甚至CNN提取的特征等,直接替换掉本文的描述子即可。
1.1 本文流程
本文的介绍将按照以下流程展开:第二部分为数据集准备,即从pokemon database中抓取一些小精灵的样本,作为自己的数据集。第三部分构建两个图像描述子,并使用其对数据集进行Index(特征提取)。第四部分构建图像搜索接口,对输入的query图像进行特征提取和数据库搜索。第五部分以一个小霸王游戏机上的Pokemon为例,通过图像处理提取出pokemon的roi并在搜索引擎中查询。第六部分对整个流程进行总结和讨论。
二、获取Pokemon数据集
这部分是一个简单的图像爬虫任务。值得注意的是,原博客中Adrian在2014年抓取的网站早已发生物是人非...不管是图像还是网页的组织方式都发生了很大变化,14年的网站落后就算了,连妖怪也一个个长得肆意妄为...然而我的CV技术比黑白画风还要落后


爬虫部分整体还是采用ctrl+F大法在开发者模式下寻找xpath。可以先用一个header伪装自己的ip。相关准备工作如下
headers = {
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
#
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
url = "https://pokemondb.net/pokedex/national"
html = requests.get(url, headers=headers)
html.encoding = 'utf-8'
content = etree.HTML(html.text)
不过在实际获取图像url list时遇到一个问题,由于缺乏相关爬虫的经验,卡了蛮久。后来发现是chrome“开发者工具”模式下匹配到的xpath和源代码中的xpath稍微有一些不同。当时还特地截了图,记录在下面:
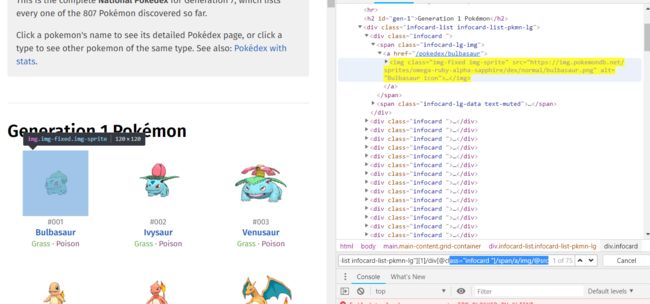
从上面两张图应该可以看出,开发者模式下的xpath为:xxx/div[@class="infocard"]/span/a/img/,理论上在后面加个@src即可获取图像url;然而源代码显示xpath为:xxx/div[@class="infocard"]/span/a/span/@data-src。事实证明应该以源代码上的xpath为准。
数据库中总共有大几百张pokemon图像。我只爬取了第一代的151张作为数据集。

三、构建图像描述子(Descriptors)

Who is that Pokemon?
上图显示了一个电视节目的场景:让小朋友根据图中的信息判断Pokemon的类别。这里给出的信息显然是形状(轮廓)。由此可见,仅仅通过形状描述子(shape descriptors)就可以一定程度上对不同种类的pokemon进行描述并区分。
常见的形状描述子有很多,如opencv提供的Hu moments,而Adrian介绍了一种更强大的算法——Zernike moments。
3.1 Zernike Moments(泽尼克矩)
3.1.1 Image Moments (图像矩)
矩的概念参考: https://blog.csdn.net/fengye2two/article/details/79113399
OpenCV中有HuMoments可以用于计算Hu矩,从而用于描述目标的结构和形状。不过Adrian介绍了一个更强大的实现——mahotas中的zernike_momentspackage。
泽尼克矩的优点:
因为泽尼克多项式的各个分量相互正交,因此矩之间不存在冗余信息。 (since the Zernike polynomials are orthogonal to each other, there is no redundancy of information between the moments.)泽尼克矩对于图像形状变化的敏感性:
①泽尼克矩对于大小(缩放)敏感。
②泽尼克矩对于平移(translation)敏感。
③泽尼克矩的幅值对于目标的旋转具有鲁棒性。(这一良好性质使得泽尼克矩可以用作shape descriptor)
前两个特点是我们要避免的。为了获取translation invariance, 我们可以将所有Pokemon提前“分割”出来,简单地分割前景然后用一个tight bounding box crop出来即可;为了获取scale invariance,我们可以将crop出的图像resize到相同的尺寸。
3.1.2 定义泽尼克描述子
一个细节是,在使用描述子对数据集进行index的过程(即对数据集中所有图像提取特征并保存到磁盘上)中,要保证描述子的参数等不变,即一致描述(consistent representation)。这句话虽然说起来简单,实际上很容易被忽略。下文中将继续涉及这个话题。
这里用了mahotas库中实现的zernike_moments。代码比较简单。练习起见,我结合了下Adrian的另一篇博客。更多关于Image search engine的内容可以见这里。代码见下方:
import cv2
import mahotas
# shape descriptor
class ZernikeMoments:
def __init__(self, radius):
'''这里的radius将被用于计算矩。该参数越大,矩计算包含的像素范围越大。该参数常常需要多次调节'''
self.radius = radius
def describe(self, image):
'''Quantify each image in terms of shape'''
return mahotas.features.zernike_moments(image, self.radius)
# color descriptor
class RGBHistogram:
def __init__(self, bins):
# 保存直方图将使用的bin数
self.bins = bins
def describe(self, img):
# 计算RGB颜色空间的3D直方图,然后normalize,以便同一张图像,不同缩放尺度对应(大致)相同的histogram
hist = cv2.calcHist(images=[img], channels=[0,1,2], mask=None, histSize=self.bins,
ranges=[0,256,0,256,0,256])
hist = cv2.normalize(hist, hist) #cv3的写法
return hist.flatten()
mahotas感觉是个满神秘的库。之前只接触过一次,是在Adrian的OpenCV教程那个使用HOG+SVM进行手写数字识别的案例分析中,通过mahotas对手写数字进行一个center_extent的预处理。
3.2 对数据集进行特征提取——Indexing
按照上面的描述,要对数据集进行index,首先要进行一些预处理。具体来说需要得到图像前景的轮廓,然后①根据轮廓进一步得到mask②根据mask得到tight bounding box。最后对这个tight box对应roi resize到同一大小。然后对resize之后的mask进行泽尼克描述,同时可以对resize之后的原图对应roi进行RGB直方图描述。再将提取出的两个向量拼接到一起即每个样本最后的特征向量。由于数据集中的图像整体很相似,可以用相同的处理方法。故下面定义几个辅助函数:
from imutils.paths import list_images
import numpy as np
import pickle
import os
import cv2
import imutils
import matplotlib.pyplot as plt
def get_roi(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
thresh = gray.copy()
thresh[thresh>0]=255 # 这样将前景从图像中分离出来,得到pokemon的mask
#为了得到bbox,我们需要先得到该mask的轮廓
#outline = np.zeros(img.shape, dtype='uint8')
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[1]
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0] # 获取面积最大的cnt
(x,y,w,h) = cv2.boundingRect(cnts)
roi = img[y:y+h, x:x+w]
roi_thresh= thresh[y:y+h, x:x+w]
return roi, roi_thresh
def thresh2mask(thresh):
## 其实可以直接根据thresh行和列的min, max确定bbox坐标...
outline = np.zeros_like(thresh, dtype='uint8')
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[1]
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0] # 获取面积最大的cnt
cv2.drawContours(outline, [cnts], -1, 255, -1)
return outline
def feature_extractor(img, debug=False):
zernike_desc = ZernikeMoments(21)
hist_desc = RGBHistogram((4, 4, 4))
# 同np.pad,作用是防止图像在边缘位置,直接thresh可能有影响
img = cv2.copyMakeBorder(img, 15,15,15,15, cv2.BORDER_CONSTANT, value=0)
roi, roi_thresh = get_roi(img) # roi为rgb图像
#roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
roi = cv2.resize(roi, (64, 64))
roi_thresh = cv2.resize(roi_thresh, (64, 64))
outline = thresh2mask(roi_thresh)
moments = zernike_desc.describe(outline)
hist = hist_desc.describe(roi)
if debug:
return (moments, hist, roi, roi_thresh, outline)
else:
return moments, hist
然后直接就可以调用函数对数据集进行index了
index = {}
index_file = './Pokemon/index/moment_features.pkl'
imgDir = "./Pokemon/Dataset/"
for imgPath in list_images(imgDir):
pokemon = os.path.basename(imgPath)[:-4] #.rstrip('.jpg')
moments, hist = feature_extractor(img)
index[pokemon] = np.concatenate((moments, hist))
with open(index_file, "wb") as f:
f.write(pickle.dumps(index))
值得注意的是这里发现了一个小问题:就是str.rstrip函数的使用。之前一直没留意,简单地当做去除最右边的特定字符串。其实不是这么简单。见下图:
print('xxx.jpg'.rstrip('.jpg'))
print('Abrmang.jpg'.rstrip(".jpg"))
print('xxxjpg.jpg'.rstrip('.jpg'))
# ========== 输出 ============
xxx
Abrman
xxx
又百度了下才发现,rstrip会从右侧删除所有指定的字符(无视顺序),即从右侧开始,只要遇到的字符是括号中的任意一个,就删除。因此会出现将图像名中的最后一个'g'误删的情况。strip和rstrip也同理。
四、构建搜索工具
本部分解决:选择合适的测度,来比较给定样本的特征向量和数据集中各个样本特征向量的差异(或者相似程度),通过排序选出距离最近的样本作为搜索结果。
在Adrian的博客中,针对形状描述子,他选择的测度是欧氏距离;针对RGB直方图,他使用chi-squared distance(常用来描述直方图之间的距离)作为测度。故我们定义一个Searcher类,来构建这部分代码:
class Searcher:
def __init__(self, index, w=0.5):
self.index = index
self.w = w
def search(self, queryFeatures):
results = {}
# 遍历所有index
for (k, features) in self.index.items():
# 对比query image的feature以及index中每个feature的距离:
# 这里将moments的欧氏距离和hist的chi-squared distance混合起来使用
d = dist.euclidean(queryFeatures[:25], features[:25]) * self.w +
self.chi2_distance(queryFeatures[25:], features[25:]) * (1-self.w)
results[k]=d
results = sorted([(v, k) for (k, v) in results.items()]) #给字典排序
return results
def chi2_distance(self, histA, histB, eps = 1e-10):
# compute the chi-squared distance
d = 0.5 * np.sum([((a - b) ** 2) / (a + b + eps) for (a, b) in zip(histA, histB)])
return d
def viz_query_results(results, imgPath='Pokemon/Dataset/'):
montageA = np.zeros((100*5, 100, 3),dtype="uint8")
montageB = np.zeros((100*5, 100, 3),dtype="uint8")
for j in range(10):
(score, pokemon) = results[j]
path = os.path.join(imgPath, pokemon+'.jpg')
img=cv2.imread(path)
assert(img is not None), "fail to read image. Check pokemon name \"{}\" and jpg name.".format(pokemon)
print("\t{}. {} : {:.3f}".format(j+1, pokemon, score))
if j < 5:
montageA[j*100: (j+1)*100, :] = cv2.resize(img,(100,100))
else:
montageB[(j - 5) * 100:((j - 5) + 1) * 100, :] = cv2.resize(img,(100,100))
plt.subplot(121);plt.imshow(montageA[...,::-1])
plt.subplot(122);plt.imshow(montageB[...,::-1])
为了直观显示搜索结果,这里定义了一个用于可视化的辅助函数。下面就用这个搜索系统来对数据库中已有的图像进行一下搜索~
queryImg = 'Pokemon/Dataset/Bellsprout.jpg'
tst_img = cv2.imread(queryImg)
#moments, hist = feature_extractor(tst_img)
queryFeatures = np.concatenate(feature_extractor(tst_img))
searcher= Searcher(index,w=0.5)
results = searcher.search(queryFeatures)
fig = plt.figure(figsize=(12,12))
viz_query_results(results)
输出:
1. Bellsprout : 0.000
2. Weepinbell : 0.113
3. Victreebel : 0.125
4. Zapdos : 0.178
5. Scyther : 0.186
6. Dodrio : 0.208
7. Abra : 0.219
8. Electabuzz : 0.220
9. Exeggutor : 0.223
10. Raichu : 0.227

注意上面的w=0.5给两种描述子相同的权重。可以看出搜索结果前几张都比较类似。后面的即使颜色差异较大,大体上都是两只脚两只手的怪物...由此可以看出我们的图像搜索引擎还是有一定效果的。
五、实际应用:获取游戏机屏幕的Pokemon ROI,并对该图像在数据库中进行搜索
在这部分中我们将通过一系列图像处理方法获取小霸王游戏机的屏幕
5.1 观察游戏机图片
观察可知,每次pokemon出现的位置都是屏幕的右上角相同区域,也就是说如果我们能获取视角合适的图像,就能根据位置估计出pokemon的roi。但是拍照的角度等会对屏幕的位置产生很大影响。因此,找出屏幕并进行预处理是后续工作的关键。为了方便可视化,这里定义了一个imshow函数,可以选择cv2模式还是matplotlib inline模式;支持单张或者多张图像(存储于list中):
def imshow(imgs, mode=None):
if mode=='plt':
%matplotlib inline
if not isinstance(imgs, list):
plt.imshow(imgs) if len(imgs.shape)==3 else plt.imshow(imgs, 'gray')
else:
for i in imgs:
plt.figure()
plt.imshow(i) if len(i.shape)==3 else plt.imshow(i, 'gray')
else:
if not isinstance(imgs, list):
cv2.imshow("show",imgs)
else:
for i, img in enumerate(imgs):
cv2.imshow("figure_"+str(i), img)
cv2.waitKey(0)
cv2.destroyAllWindows()
5.2 获取小霸王屏幕
首先有一个小技巧:Adrian给的这个游戏机原图非常大,尺寸达到了(3264 x 1228 x 3),如果直接处理原图,不仅增加了不必要的开销,可视化时也不太方便(顺便复习下cv2.namedWindow("test", cv2.WINDOW_NORMAL); cv2.resizeWindow("test", 500, 500))。而这一步我们的目标仅仅是获取小霸王屏幕对应的box坐标,因此可以对图像进行缩放,然后记下缩放比例,处理小图得到坐标之后再按照比例放大回来。
缩放之后对图像进行灰度化,加入适当模糊然后获取边缘进而得到轮廓。这里涉及一些轮廓相关的知识。一些简单的概念我整理在下面,需要详细了解请参考OpenCV-Python中文教程.
5.2.1 轮廓相关知识
①轮廓的定义:轮廓可以简单认为成连续的点连在一起的曲线,具有相同的颜色或灰度。轮廓在形状分析和物体的检测识别中很有用。
②获取轮廓:首先最好使用二值图像(阈值化或者Canny边界检测得到)。另外这个二值图中要保证查找的轮廓为白色物体而背景是黑色。然后对该二值图像使用cv2.findContours()函数,其中第二个参数为轮廓检索模式,通常使用cv2.RETR_TREE, 该参数告诉OpenCv考虑轮廓之间的层级结构关系。也可以用cv2.RETR_LIST。第三个参数为轮廓近似方式,通常设置为cv2.CHAIN_APPROX_SIMPLE。
③轮廓压缩:用于压缩OpenCV获取的轮廓,进而节省空间。由上述介绍知道,“轮廓”是连续的坐标点连在一起的曲线。然而对于简单的轮廓(如矩形)而言,为了得到其轮廓我们并不需要所有紧密相连的点,反之我们只需要四个顶点,就可以近似描述该轮廓。参考下面的Fig. 10.

④注意:获取轮廓常常要先获取图像边缘。而边缘检测子往往对噪声特别敏感。故进行边缘检测之前可以加入一定程度的模糊。这里的模糊有几种不同的类型,比如均值滤波,中值滤波,高斯滤波,双边滤波等。详细的了解见这里。其中高斯滤波和双边滤波比较常用。高斯滤波用的最多,可能是因为参数设置比较简单,通常选(3,3)大小的核。双边滤波则更为强大,可以在保留边缘的同时对图像非边缘区域进行模糊。下图展示了双边滤波的一个例子:
The Gaussian function of space makes sure that only pixels are ‘spatial neighbors’ are considered for filtering, while the Gaussian component applied in the intensity domain (a Gaussian function of intensity differences) ensures that only those pixels with intensities similar to that of the central pixel (‘intensity neighbors’) are included to compute the blurred intensity value.

5.2.2 获取屏幕的候选轮廓
对我们的小霸王游戏机进行处理,通过求边缘进而获得轮廓cnts,然后对轮廓进行排序,选出面积最大的10个轮廓作为候选轮廓:
# 第一步:读取图像,缩放并灰度化,加模糊然后获取边缘
img = cv2.imread('Pokemon/queries/query_marowak.jpg')
ratio = img.shape[0] / 300.
origImg = img.copy()
img = imutils.resize(img, height=300)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray= cv2.bilateralFilter(gray, 11, 17, 17)
edged = cv2.Canny(gray, 30, 200)
# 寻找边缘图上的contours,排序并保留面积较大的
cnts = cv2.findContours(edged.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)[1]
# The second parameter cv2.RETR_TREE tells OpenCV to compute the hierarchy (relationship) between contours.
# We could have also used the cv2.RETR_LIST option as well.
# Finally, we tell OpenCV to compress the contours to save space using cv2.CV_CHAIN_APPROX_SIMPLE.
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
screenCnt = None
imshow(edged) #注意,这一步如果用plt.imshow,可能显示的没有cv.imshow清楚
这段代码中值得注意的是使用findContours函数一般要对原图做一个备份。
为了进一步观察轮廓,下面又定义了两个辅助函数:
def viz_contour_boxes(cnts, img):
'''注意:该函数不是显示出所有物体轮廓,而是显示出轮廓的bbox'''
img = img.copy()
for cnt in cnts:
color = np.random.randint(0,255, size=(3)).tolist()
(x, y, w, h) = cv2.boundingRect(cnt)
cv2.rectangle(img, (x,y), (x+w,y+h), color, 2)
#imshow(edged)
plt.imshow(img[...,::-1])
def draw_contours(img, cnts):
%matplotlib notebook
'''通过动图可视化:每次显示出一个轮廓'''
fig = plt.figure(figsize=(5,5))
for i in range(len(cnts)):
plt.clf()
timg = img.copy() # 函数结束时这些拷贝的对象会被释放吗...
color = np.random.randint(0,255, size=(3)).tolist()
timg = cv2.drawContours(timg, [cnts[i]], -1, color, 2)
plt.imshow(timg[...,::-1])
fig.canvas.draw()
plt.pause(0.5)
轮廓的动态显示结果放在notebook上面。下面展示出对cnts对应的boundingbox的可视化结果。可以清晰的看出cnts对应几个不同的轮廓位置:

注意图中的一个细节: cv2.boundingRect接收的cnt一定是array的list。不是array!。轮廓的可视化结果见notebook中的动图。
5.2.3 找到最终的屏幕轮廓
- 从剩下的contour中捕获屏幕
接下来的任务就是从上面剩下的10个contour中找到屏幕对应的那一个(也可能是多个近似重复的)。从上面的可视化可以看出,虽然屏幕有多个类似矩形的轮廓,但是外面的轮廓实际上包含了几个小精灵的边缘,故其矩形的“程度”不是特别高。而我们要捕获的屏幕轮廓,矩形程度相对较高。因此只需要找出矩形程度最高的轮廓即可。
这里涉及轮廓近似: cv2.approxPolyDP, 即将轮廓形状近似到另外一种由更少点组成的轮廓形状,使用Douglas-Percker算法。第二个参数是epsilon,即从原始轮廓到近似轮廓的最大距离,是一个准确度参数。该参数很重要,通常由轮廓周长乘以一个较小的系数(0.1, 0.15等)来估计。该函数返回近似之后的contour(同上面的近似轮廓,即用最少的点去描述一个轮廓)。
下面的代码在一定精度下寻找只用四个点就能近似的轮廓(即矩形轮廓)。
for cnt in cnts:
peri = cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, 0.015*peri, True)
if len(approx)==4:
screenCnt = approx
break
draw_contours(img, [screenCnt])
结果:

5.3 屏幕预处理
这一部分对我们获取到的屏幕图像进行预处理,以便送入最终的图像搜索引擎。
从Fig. 13可以看出,游戏机的屏幕有一些歪斜(skewed), 同时由于视点问题,该图不是自上而下俯瞰游戏机的。这样就不能根据屏幕的相对位置获取准确的pokemon ROI。故考虑对屏幕图像进行视点转换(Perspective Warping) 。
为了进行视点变化,我们首先要确定图像的四个顶点。由上面轮廓近似返回的四个点位置是不确定的。确定四个顶点顺序的方法很简单:左上角点的x,y坐标之和最小,右下角最大;右上角的点的x,y坐标差值最大,左下角最小。
perspective transformation函数要求传入一个dst,包含形变图像的宽高信息。perspective transformation中要求的四个顶点顺序: 左上、右上、右下、左下。
5.3.1 透视变换(perspective transformation)
参考:https://blog.csdn.net/guduruyu/article/details/72518340
直接上代码:
pts = screenCnt.reshape(4,2)
rect = np.zeros((4,2), dtype='float32')
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)] #左上
rect[2] = pts[np.argmax(s)] #右下
# 注意:np.diff([1,3]) = 2, 即运算时是沿着给定轴按照: out[n] = a[n+1] - a[n] 来算的
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)] #右上
rect[3] = pts[np.argmax(diff)] #左下
# 这时候将得到的屏幕ROI缩放至原始尺寸(使用一开始保存的ratio)
rect *= ratio
tl, tr, br, bl = rect
cal_dist = lambda x, y: np.sqrt(((x[0] - y[0]) ** 2) + ((x[1] - y[1]) ** 2))
widthA = cal_dist(bl, br)
widthB = cal_dist(tl, tr)
heightA = cal_dist(tl, bl)
heightB = cal_dist(tr, br)
maxWidth = max(int(widthA), int(widthB))
maxHeight = max(int(heightA), int(heightB))
dst = np.array([
[0, 0],
[maxWidth-1, 0],
[maxWidth-1, maxHeight-1],
[0, maxHeight-1]], dtype="float32")
M = cv2.getPerspectiveTransform(rect, dst)
warp = cv2.warpPerspective(origImg, M, (maxWidth, maxHeight))

由于游戏机中Pokemon出现的位置是固定的,只需要简单的crop就可以获取右上角Pokemon的大致ROI(不一定要紧贴边界,大致位置即可。)
5.4 查询结果
这里由于我爬取的Pokemon数据集中Marowak长得和屏幕中这个差别太大,而简单的形状描述子很难取得好的效果,我把Adrian用的14年数据集中的Marowak图片进行了单独的特征提取并加入到index中。然后对屏幕图像进行类似的特征提取(也是获取轮廓进而得到一个tight outline box的二值图像,然后用描述子进行描述)得到特征向量。由于屏幕图是灰度图,在搜索时可以将w设为1(不使用RGBHistogram的特征)进行匹配。搜索结果:
1. marowak_adrian : 0.014
2. Psyduck : 0.029
3. Pidgey : 0.030
4. Kangaskhan : 0.030
5. Weedle : 0.030
6. Venusaur : 0.032
7. Jynx : 0.032
8. Cloyster : 0.032
9. Wartortle : 0.033
10. Nidoqueen : 0.033

- 错误记录:
中间有好长一段时间搜索结果不正确。后来发现是起前面定义的feature_extractor函数只适用于处理上面的数据集;而对于额外增加的数据需要使用不同的预处理方法。
另一个错误的地方是忘记把额外增加的数据进行tightly crop,导致query的和额外增加的图像scale不一样。而zernike描述子对大小敏感。所以产生了很大误差。具体的实验对比见下方。故一定要保证前一批数据和后面额外数据在提取特征时使用一致描述。
六、参考
Pokemon数据库:https://pokemondb.net/pokedex/national#gen-1
Adrian博客(Pokedex):https://www.pyimagesearch.com/2014/03/10/building-pokedex-python-getting-started-step-1-6/
Adrian博客(图像搜索引擎):
- https://www.pyimagesearch.com/2014/01/27/hobbits-and-histograms-a-how-to-guide-to-building-your-first-image-search-engine-in-python/
- https://www.pyimagesearch.com/2014/02/03/building-an-image-search-engine-defining-your-image-descriptor-step-1-of-4/
涉及到的图像处理技术:
- https://www.kancloud.cn/aollo/aolloopencv/272892
- https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_filtering/py_filtering.html
- https://blog.csdn.net/guduruyu/article/details/72518340