【YOLO】Keras训练代码分析(迁移学习方法)
文章目录
- 0. 前言
- 1. 从零开始训练
- 2. 迁移学习方法
- 3. 训练代码解析
- 3.1 第一轮训练(冻结前N层)
- 3.2 第二轮训练(释放前N层)
0. 前言
训练自己的YOLO模型,常用的方法基于Keras和TensorFlow框架,相关方法可以参考博主另一篇博客:https://blog.csdn.net/qinchang1/article/details/89608058
本文主要介绍训练代码的一些个人理解。
1. 从零开始训练
早期看过别人的文章,例如:https://blog.csdn.net/m0_37857151/article/details/81330699
其中将train.py的代码改写了,目的是取消预加载权重,这样模型的训练就可以从零开始训练所有层参数。
但是,在本人执行训练之后,出现了一些问题。训练过程的损失曲线如下图所示:
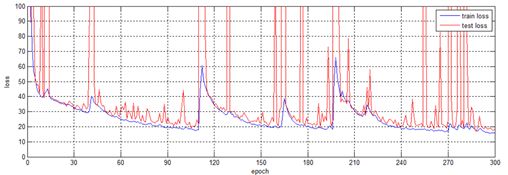
可以看到迭代过程的训练曲线特别不稳定,特别是测试损失,有时甚至突然爆炸。
其实这种现象也是可以理解的,毕竟YOLO模型里面包含的参数上百万,纯粹靠我们那没几张的小样本训练,确实很难实现稳定收敛。
2. 迁移学习方法
由于存在上述的问题,所以原训练代码中采用了迁移学习的方法,预加载官方权重,其原理如下图所示:
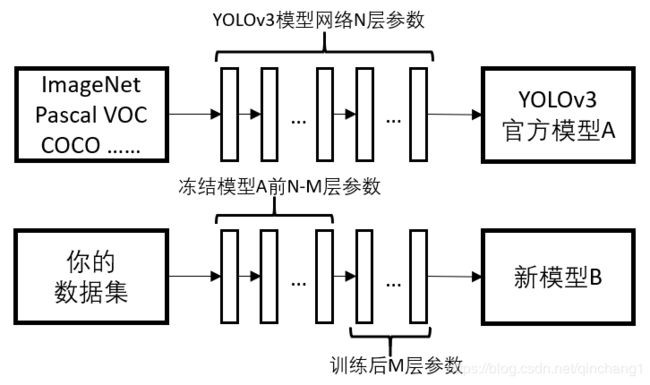
官方提供的模型,也就是那个yolo.h5(yolov3.weights),该模型是通过多个数据集上百万张图片训练而来的,因此得到的很多层参数是有再利用价值的(可能包含了某方面的检测能力)。
在训练新的检测模型时,由于数据集有限,因此可以采取迁移学习的方式,例如冻结前N-M层参数,只训练后M层参数。这样的做法可以在保证原模型的检测能力的基础上,让新的模型尽快收敛。
3. 训练代码解析
3.1 第一轮训练(冻结前N层)
原代码中,训练的代码包含了两个部分,首先第一部分:
# Train with frozen layers first, to get a stable loss.
# Adjust num epochs to your dataset. This step is enough to obtain a not bad model.
if True:
model.compile(optimizer=Adam(lr=1e-3), loss={
# use custom yolo_loss Lambda layer.
'yolo_loss': lambda y_true, y_pred: y_pred})
batch_size = 32
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=50,
initial_epoch=0,
callbacks=[logging, checkpoint])
model.save_weights(log_dir + 'trained_weights_stage_1.h5')
这部分的训练是第一轮训练,所采用的模型是冻结过后的,具体冻结了多少层,可以查看create_model()函数:
def create_model(input_shape, anchors, num_classes, load_pretrained=True, freeze_body=2,
weights_path='model_data/yolo_weights.h5'):
'''create the training model'''
K.clear_session() # get a new session
image_input = Input(shape=(None, None, 3))
h, w = input_shape
num_anchors = len(anchors)
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], \
num_anchors//3, num_classes+5)) for l in range(3)]
model_body = yolo_body(image_input, num_anchors//3, num_classes)
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
if load_pretrained:
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
print('Load weights {}.'.format(weights_path))
if freeze_body in [1, 2]:
# Freeze darknet53 body or freeze all but 3 output layers.
num = (185, len(model_body.layers)-3)[freeze_body-1] # 这里修改冻结层
for i in range(num): model_body.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(num, len(model_body.layers)))
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})(
[*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return model
YOLO采用的Darknet-53网络包含252层,本人了解到的YOLO迁移训练的冻结方式有两种:
(1)冻结前249层:因为倒数3层是3个1×1的卷积层,主要是用于最终的预测输出;
(2)冻结前185层:因为第185层,这是Darknet-53网络的最后一个残差单元。
从代码中可以看出,其采用了第(1)种方式。采用这种方式训练之后,损失曲线有了明显的改观,如下图所示:
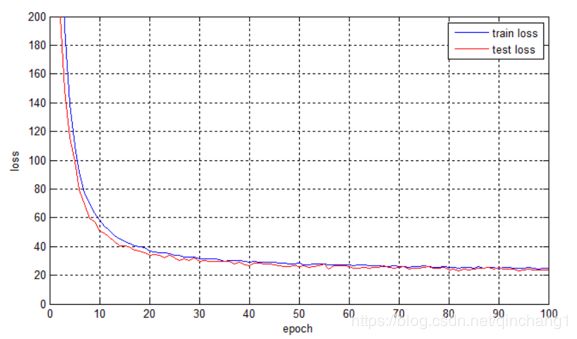
这也难怪,毕竟都冻结了249层了。但是呢,这样的方式很大程度上限制了模型的可塑性,可以说是强行将检测结果拉到你的新对象上。所以原代码中还加入了第二轮训练。
3.2 第二轮训练(释放前N层)
以下是第二轮训练的代码:
# Unfreeze and continue training, to fine-tune.
# Train longer if the result is not good.
if True:
for i in range(len(model.layers)):
model.layers[i].trainable = True
model.compile(optimizer=Adam(lr=1e-4), loss={'yolo_loss': lambda y_true, y_pred: y_pred}) # recompile to apply the change
print('Unfreeze all of the layers.')
batch_size = 10 # note that more GPU memory is required after unfreezing the body
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator_wrapper(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator_wrapper(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=200,
initial_epoch=50,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
model.save_weights(log_dir + 'trained_weights_final.h5')
从中可以看出,代码一开始就将模型的所有层释放,因此之前没有得到调整的前249层的参数也加入到了训练迭代中。
会造成什么样的结果呢?本人得到的损失曲线如下:

可以看到,第二轮释放冻结层之后,训练的损失值进一步下降,最后趋于稳定。
原代码采用这样的方式,本人的理解是:如果一开始就全参数训练,由于参数过多,迭代过程不稳定,难以收敛。因此采用迁移学习的方式,预加载官方权重文件,冻结前面大多数层的参数,从而保证训练初期的稳定收敛。当第一轮迁移学习达到瓶颈后,释放冻结层再次训练,让模型达到最终的收敛形态。【真的秒啊】
PS: 本人还试验过很多个冻结层数,上面提到的两种只是比较标准的,但不绝对。貌似只要初期冻结前50层以上,迭代过程就可以稳定收敛。
·
这里也回答了之前有些人的疑问,第二轮的训练还是比较重要的,但是第二轮训练有时候会出现问题,主要还是由于batch_size的值造成的,batch_size值越大,电脑的显存需求就越高,可能有些电脑吃不消,因此把这个值适当改小就不会报错了。
·
本人目前已完成学业,今后估计不会再做YOLO及视觉相关的研究,多半也不会更新相关的文章了,有问题的可以留言交流,感谢各位的支持O(∩_∩)O
如有错误,欢迎指正!