目标检测Anchor-free分支:基于关键点的目标检测(最新网络全面超越YOLOv3)
目标检测领域最近有个较新的方向:基于关键点进行目标物体检测。该策略的代表算法为:CornerNet和CenterNet。由于本人工作特性,对网络的实时性要求比较高,因此多用YoLov3及其变体。而就在今天下午得知,基于CornerNet改进的CornerNet-Squeeze网络居然在实时性和精度上都超越了YoLov3,我还是蛮激动的,故趁此机会学习下该类检测算法的原理。
cornerNer论文链接:https://arxiv.org/pdf/1808.01244.pdf
github:https://github.com/umich-vl/CornerNet
CenterNet论文链接:https://arxiv.org/abs/1904.08189
github:https://github.com/Duankaiwen/CenterNet
CornerNe-Lite论文链接: https://arxiv.org/abs/1904.08900
github: https://github.com/princeton-vl/CornerNet-Lite
所谓基于关键点进行目标检测,其实就是使用one-stage网络将目标边界框检测为一对关键点(即边界框的左上角和右下角)。通过将目标检测为成对关键点,就可消除现有的one-stage检测网络中对一组anchors的需要,这个最近火热的anchor-free也是不谋而合。接下来,先简单介绍下CornetNet和CenterNet这两个基于特征点的目标检测网络。最后对CornerNet-Squeeze做个简单介绍!
1.CornerNet 【ECCV2018】
CornerNet网络的整体思路是,首先通过Hourglass Network网络进行特征提取,紧接着将网络得到的特征输入到两个模块:Top-left Corner pooling和Bottom-right Corner pooling提取关键点的特征,对于每个Corner Pooling模块都会进行目标框的左上角关键点和右下角关键点的类别分类(Heatmaps),并找到每个目标的一对关键点(Embeddings),以及减少基于坐标回算目标目标位置时的偏置(offsets)。网络的整体结构图如下:
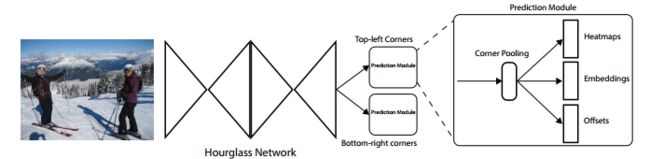
很显然,CornerNet的核心是四个部分:
-
两个Corner Pooling
下图展示的是Top-left corner pooling的示意图,为了使得关键点的特征能够表征左上角和右下角关键点所包含的目标区域的特征,作者提出了如下所示的corner pooling的策略,比如下图所示,为求左上角关键点特征,需要求当前关键点同一行中的左边区域的最大值,和同一列中的下面区域的最大值,并将两个最大值相加才是当前位置的左上角关键点特征。

-
Heatmaps模块
通过Heatmaps模块,网络会预测每一个关键点所属于的类别,该过程中使用的损失函数如下:
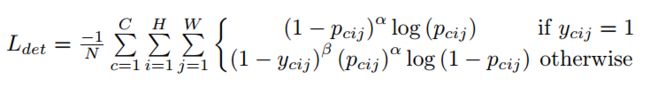
上述公式是针对角点预测(headmaps)的损失函数,整体上是改良版的focal loss。几个参数的含义:pcij表示预测的heatmaps在第c个通道(类别c)的(i,j)位置的值,ycij表示对应位置的ground truth,N表示目标的数量。ycij=1时候的损失函数容易理解,就是focal loss,α参数用来控制难易分类样本的损失权重;ycij等于其他值时表示(i,j)点不是类别c的目标角点,照理说此时ycij应该是0(大部分算法都是这样处理的),但是这里ycij不是0,而是用基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的ycij值接近1,这部分通过β参数控制权重,这是和focal loss的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近ground truth的误检角点组成的预测框仍会和ground truth有较大的重叠面积,如下图所示所示。
图中,红色实线框是ground truth;橘色圆圈是根据ground truth的左上角角点、右下角角点和设定的半径值画出来的,半径是根据圆圈内的角点组成的框和ground truth的IOU值大于0.7而设定的,圆圈内的点的数值是以圆心往外呈二维的高斯分布;白色虚线是一个预测框,可以看出这个预测框的两个角点和ground truth并不重合,但是该预测框基本框住了目标,因此是有用的预测框,所以要有一定权重的损失返回,这就是为什么要对不同负样本点的损失函数采取不同权重值的原因。

- Embeddings模块
在Headmaps模块中对关键点类别的预测是没办法知道哪两个关键点能够构成一个目标,因此如何找到一个目标的两个关键点就是模块embedding做的工作。
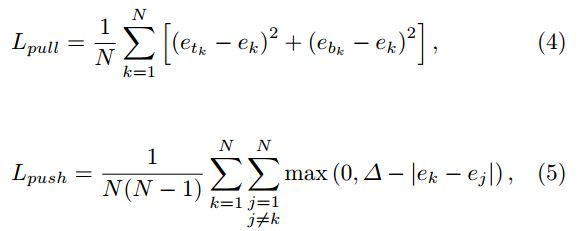
embedding这部分的训练是通过两个损失函数实现的,etk表示属于k类目标的左上角角点的embedding vector,ebk表示属于k类目标的右下角关键点的embedding vector,ek表示etk和ebk的均值。公式4用来缩小属于同一个目标(k类目标)的两个关键点的embedding vector(etk和ebk)距离。公式5用来扩大不属于同一个目标的两个角点的embedding vector距离。
- Offsets模块
该模块主要用于弥补由于网络降采样得到的特征图,在反算关键点原始位置时的精度丢失。如下公式所示,由于向下取整,所以会导致精度丢失,而作者利用L1损失来减少这种精度损失。
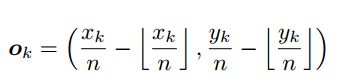
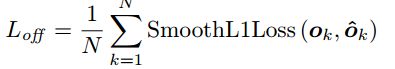
最终,如下图所示,上半支路的网络结果如下所示,网络最终是由两条支路组成的。

2.CenterNet【CVPR092109】
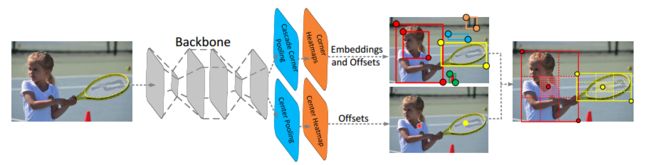
CenterNet网络主要是基于CornerNet网络存在的问题,而提出的基于关键点目标检测的网络。其实现了目前为止在one-stage系类算法中最高的MAP。CenterNet的作者发现,CornerNet是通过检测物体的左上角点和右下角点来确定目标,但在此过程中CornetNet使用corner pooling仅仅能够提取到目标边缘的特征,而导致CornetNet会产生很多的误检。基于此,CenterNet利用关键点三元组即中心点、左上角关键点和右下角关键点三个关键点而不是两个点来确定一个目标,使得网络能够获取到目标内部的特征。而CornerNet在论文中也说道了,约束其网络性能最重要的部分是关键点的提取,因此CenterNet提出了Center Pooling和cascade corner Pooling用来更好的提取本文提出的三个关键点。
-
三元组预测
如下图所示,网络通过 cascade corner pooling得到左上角,右下角的关键点类别。并通过center pooling得到中心点的关键点类别。随后通过 offsets 将三个关键点位置尽可能精确的映射到输入图片的对应位置,最后通过 embedings 判断三个点是否属于同一个目标。
在预测中心点特征时,对每个预测框定义一个中心区域,通过判断每个目标框的中心区域是否含有中心点,若有则保留,并且此时预测框的 confidence 为中心点,左上角关键点和右下角关键点的confidence的平均,若无则去除。而很显然,对于每个预测框的中心区域,我们需要其和预测框的大小进行适应,因为中心区面积过小会使得小尺度的错误预测框无法被去除,而中心区过大会导致大尺度的错误预测框无法被去除。因此作者提出如下策略:

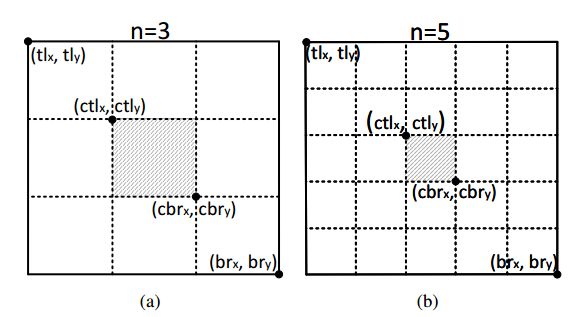
如上图所示,当预测框的尺寸较大时,我们得到的中心区域面积也会变小,而与之对应的,当预测框的尺寸较小时,中心区域的面积也会变大。 -
Center Pooling
作者基于Corner Pooling的系列思想,提出了Center Pooling的思想,使得网络提取到的中心点特征能够更好的表征目标物体。

一个物体的中心并不一定含有很强的,易于区分于其他类别的语义信息。例如,一个人的头部含有很强的,易于区分于其他类别的语义信息,但是其中心往往位于人的中部。我们提出了center pooling 来丰富中心点特征。上图为该方法原理,center pooling提取中心点水平方向和垂直方向的最大值并相加,以此给中心点提供所处位置以外的信息。这一操作使中心点有机会获得更易于区分于其他类别的语义信息。Center pooling 可通过不同方向上的 corner pooling 的组合实现。一个水平方向上的取最大值操作可由 left pooling 和 right pooling通过串联实现,同理,一个垂直方向上的取最大值操作可由 top pooling 和 bottom pooling通过串联实现,如图6所示。

- cascade corner Pooling
作者基于Corner Pooling的系列思想,提出了cascade corner Pooling的思想,使得网络提取到的中心点特征能够更好的表征目标物体。
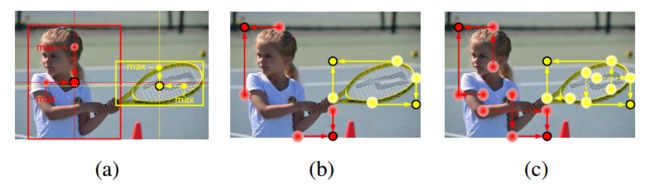
一般情况下角点位于物体外部,所处位置并不含有关联物体的语义信息,这为角点的检测带来了困难。上图(b) 为传统做法,称为 corner pooling。它提取物体边界最大值并相加,该方法只能提供关联物体边缘语义信息,对于更加丰富的物体内部语义信息则很难提取到。上图©为cascade corner pooling 原理,它首先提取物体边界最大值,然后在边界最大值处继续向内部(图中沿虚线方向)提取提最大值,并与边界最大值相加,以此给角点特征提供更加丰富的关联物体语义信息。Cascade corner pooling 也可通过不同方向上的 corner pooling 的组合实现,如图8 所示,图8展示了cascade left corner pooling 原理。

最终,CenterNet在CornerNet的基础上增加了中心点的预测,以及修改了关键点特征的提取方式,大大减小了网络的误检,并且实现了one-stage系列算法中的最好效果。
3.CornetNet-Lite
普林斯顿大学在4月19号提出了两种更高效的基于关键点的目标检测算法,分别为:CornetNet-Saccade和CornetNet-Squeeze,若将两种策略结合则称为CornerNet-Lite。

如上图所示,CornerNet-Squeeze专注于速度,但其在性能和速度上都超越了YOLOv3,而CornerNet-Saccade专注于精度。
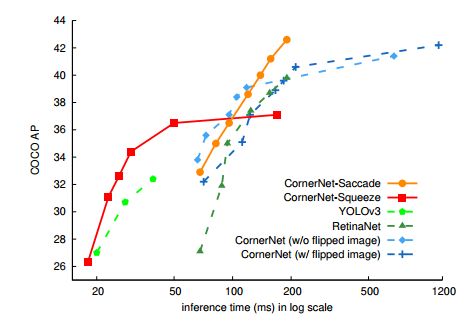
如上图所示,我们发现CornetNet-Saccade和CornetNet-Squeeze确实很优秀。
以下是Cver对这两个网络的介绍,个人感觉写的很好,我就不造轮子了:

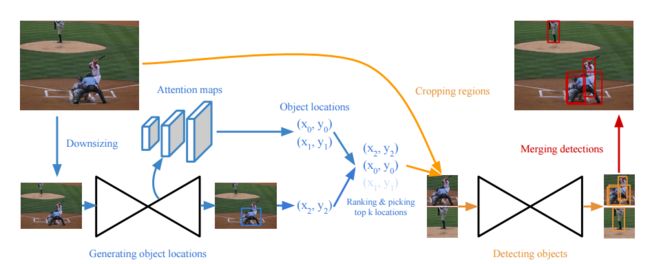

最终我最感兴趣的网络CornerNet-Squeeze和YOLOv3进行对比,达到了如下图所示的效果。
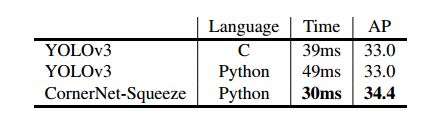
然而,就在我学习并总结这篇文章的过程中,我发现CornerNet-Squeeze是基于CornerNet改进的,但正如上文中介绍CenterNet的时候提到过的CornerNet所具有的那些弊端,我总觉得CornerNet-Squeeze在误检的部分不一定会很优秀,所以接下来就是看源码阶段了,希望CornerNet-Squeeze能够不负我望哈~
参考文献:
https://mp.weixin.qq.com/s/lk268kc55Lgz1d_21zg26A
https://blog.csdn.net/u014380165/article/details/83032273
https://mp.weixin.qq.com/s/xy1WWl2rNvGAXnqIJCy-Mg