【SLAM论文】《使用DNN在连续驾驶场景中进行稳健车道检测的方法》学习笔记
目录
Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks
1. 摘要
2. 主要贡献
3. 算法流程
3.1 网络概述
3.2 网络设计
3.2.1 LSTM网络
3.2.2 编码-解码网络
3.2.3 网络训练
4. 结果展示
4.1 数据集
4.2 实现细节
4.3 性能比较
(1)整体性能
(2)稳健性
4.4 参数分析
致谢:本文为自己学习与参考泡泡机器人的笔记
Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks
1. 摘要
驾驶场景中的车道检测是自动汽车和高级驾驶辅助系统的重要模块。近些年已经出现了很多复杂的车道检测方法。然而,大多数方法集中于从单张图像中检测车道,这样经常导致在处理一些极端恶劣的情形时效果很差,比如大雾,标记严重损毁,车辆严重堵塞等等。实际上,车道是路上连续的线结构。本文使用连续驾驶场景中的多帧信息进行车道检测,并提出了一种结合卷积神经网络(CNN)和循环神经网络(RNN)的混合深度框架。明确来说,每一帧的信息都从一个CNN块提取出来,将具有时间序列性质的多个连续帧中的CNN特征投入RNN块中进行特征学习和车道检测。
2. 主要贡献
1.本文提出了一种结合CNN和RNN的全新混合神经网络对连续驾驶场景中多帧图像进行车道检测的稳健方法。
2.本文在两种大规模数据集上的实验表明,该方法在各种复杂驾驶情形下(如遮蔽,阴影,堵车,光照不足,车道线磨损等)性能表现超越了当前先进的方法。
3. 算法流程
3.1 网络概述
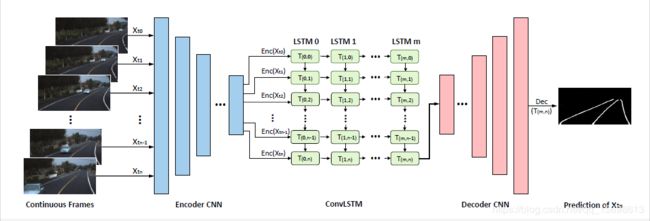
本文所提出的方法结合了CNN和RNN利用驾驶场景中大量连续帧进行车道检测。实际上,在连续的驾驶场景中,汽车摄像头捕捉到的图像是连贯的,因此一帧和其之前帧中的车道通常会重叠,使得在一个时间序列预测框架中进行车道检测成为可能。
为了将CNN和RNN整合成一个端到端的可训练的网络,本文用编码解码框架构建网络。本文提出的网络结构如图1所示。编码CNN和解码CNN是两个全卷积网络。以大量的连续帧作为输入,编码CNN对每一帧进行处理并获取以时间为顺序的特征图。然后这些特征图作为LSTM网络的输入进行车道信息预测。LSTM的输出输入到解码CNN生成车道检测的概率图,该图与输入图像有相同的大小。
3.2 网络设计
3.2.1 LSTM网络
使用LSTM网络是由于其剔除不重要信息和记忆重要特征的能力比传统RNN模型更强。本文使用了双层的LSTM,一层用于连贯的特征提取,另一层用于整合信息。本文在网络中利用卷积LSTM(ConvLSTM)。
一个通用ConvLSTM cell在时间t的激活可以公式化为:
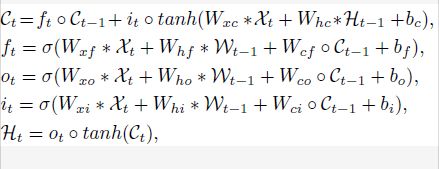
3.2.2 编码-解码网络
编码-解码框架将车道检测问题建模成一个语义分割任务。在编码部分,卷积和池化被用于图像提取和特征提取。同时在解码部分,反卷积和上采样用于理解和突出目标信息和在空域上重建它们。
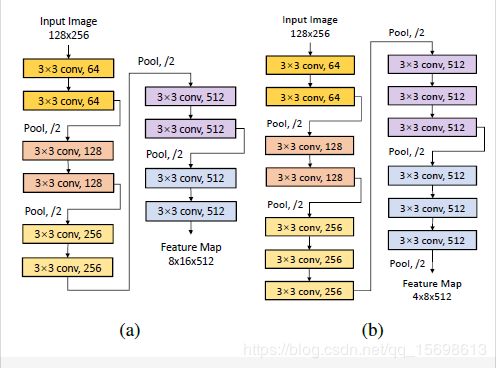
从SegNet和U-Net编码-解码结构在语义分割上的成功获得灵感 ,本文通过将ConvLSTM块嵌入这两个编码-解码网络。因此,最后的网络分别被命名为SegNet-ConvLSTM和UNet-ConvLSTM
3.2.3 网络训练
一旦端到端可训练的神经网络搭建好,就可以对其进行训练,通过反向传播过程相对真值进行预测,在反向传播过程中卷积核权重参数和ConvLSTM矩阵将会被更新。训练过程考虑到了如下四个方面。
1.本文所提出的网络使用了SegNet和U-Net在ImageNet上的预训练权重,不仅节省训练时间,而且将合适的权重传给本文网络。
2.N为用于辨识车道的输入驾驶场景连续图像的数量。所以,反向传播时,ConvLSTM的每个权重更新系数都需除以N。实验时,将N设为5作为对比。同时用实验探究了N如何影响网络性能。
3.基于加权的交叉熵构建的损失函数来解决不同的分割任务
4.为了更有效地训练本文网络,本文使用在不用训练阶段使用不同的优化器。开始,使用Adam优化器,网络训练到一个相对较高的准确率时,转而使用随机梯度下降优化器(SGD)。改变优化器时,学习率也应该相应匹配,否则学习过程将会被完全不同的学习步子所扰乱,导致收敛过快或者过慢。
4. 结果展示
4.1 数据集
基于TuSimple车道数据集和自己的车道数据集构建了一个数据集。TuSimple数据集包含了3626个图像序列。
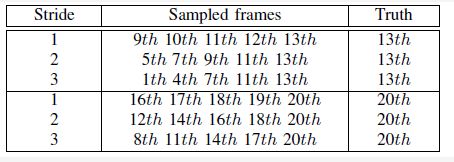
训练时,采样5张连续图像作为网络输入,并在最后一帧辨识车道。基于第13帧和第20帧的真值标签,本文构建了训练集。与此同时 ,为了本文网络充分适应不同驾驶速度的车道检测,以三种不同的步幅采样输入,即分别以1,2和3帧作为间隔。然后,对每个真值标签有三种采样方式,如表2所列。
4.2 实现细节
将用于车道检测的图像采样成256 x 128的分辨率。实验在配备Intel Core Xeon [email protected], 64GB RAM和两块GeForce GTX TITAN-X GPU的平台上运行
4.3 性能比较
(1)整体性能
a.视觉检测:一个优秀的语义分割神经网络应该将输入图像分割精确分割成不同的二部分,无论是粗分割还是细分割。
粗分割时,期望模型正确预测出图像中车道的全部数量,即应该避免两种检测错误:漏检和过度检测。细分割中,希望在粗分割结果满意的情况下,模型准确地处理细节。
b.定量分析
最简单的评估指标——Accuracy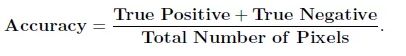
更合理的两个评估指标——Precision和recall
考虑到精确度或召回率只影响车道检测性能的一个方面,我们引入F1-measure作为一个整体评估性能。F1被定义为
c.运行时间
本文模型将序列图像作为输入,并额外增加了LSTM块,它可能增加了运行时间。表3的最后一列可以看出,本文网络处理五帧时比处理单张图像的模型会花费更多时间,比如SegNet和U-Net。
(2)稳健性
稳健性测试时,使用包含各种驾驶场景的全新数据集。Testest#2,包含728 张图像,其中有乡村,城市和高速公路场景。数据集通过数据记录仪在不同高度,前挡风玻璃的里外以及在不同的天气状况下捕捉。该测试数据集十分全面并具有挑战性,其中有些车道十分难检测到,甚至是人眼都无法辨认。
4.4 参数分析
主要有两种参数可能影响本文方法的性能。一个就是网络输入的图像帧数,另外一个为采样步幅。这两个参数共同决定了第一帧和最后一帧之间的总范围。