hadoop-hdfs-Secondary NameNode
原理
NameNode
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
元数据文件:
fsimage - 它是在NameNode启动时对整个文件系统的快照
edit logs - 它是在NameNode启动后,对文件系统的改动序列
namenode 存储对文件系统的修改 作为日志添加到本地文件系统edits文件。
当一个namenode 启动时,它会读取hdfs状态 从一个image文件中(fsimage),
然后应用edits从edits 日志文件。它写新的hdfs状态到fsimage 然后启动正常操作到一个空的edits文件。因为namenode合并fsimage和edits文件 仅仅在启动的时候,
edits文件可能会耗费大量的时间在一个繁忙的集群中。大的edits文件的另一个影响是集群NameNode下一次重启会非常耗时间
checkpoint
一是镜像备份,二是日志与镜像的定期合并。两个过程同时进行,称为checkpoint.
作用
保持文件系统最新的元数据
The secondary NameNode 会定期的合并fsimage和edits日志文件,并且限定edits日志文件大小。运行在一个不同的机器上面 而不是主NameNode上 内存要求和主NameNode同样的规则。
secondary NameNode 存储最近的checkpoint 在一个和主NameNode目录一样结构的目录。因此 check pointed image如果有必要经常准备去被主NameNode 读取
在secondary NameNode 上启动的checkpoint进程 有两个参数控制
dfs.namenode.checkpoint.period,
// to 1 hour by default, specifies the maximum delay between two consecutive checkpoints, and
dfs.namenode.checkpoint.txns
//set to 1 million by default, defines the number of uncheckpointed transactions on the NameNode which will force an urgent checkpoint, even if the checkpoint period has not been reached.Secondary NameNode 是为了辅助namenode,负责支持定期HDFS元数据的检查点
每个HDFS 集群只允许一个 Secondary NameNode
Secondary NameNode 是一个周期性唤醒的守护进程
具体时间由配置的schedule属性指定
触发定时检查点 然后回到睡眠
Secondary NameNode使用namenode协议与主namenode通信
相关配置
<property>
<name>dfs.http.addressname>
master:50070
The address and the base port where the dfs namenode web ui will listen on.If the port is 0 then the server will start on a free port.
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
slave1:50090
##主要是这里的主机名要变
##如果secondarynamenode为多个话可以设置为0.0.0.0:50090
property><property><name>fs.checkpoint.periodname>
3600
The number of seconds between two periodic checkpoints.
property>
<property>
<name>fs.checkpoint.sizename>
67108864
The size of the current edit log (in bytes) that triggers
a periodic checkpoint even if the fs.checkpoint.period hasn’t expired.
property>命令
secondarynamenode
Usage: hdfs secondarynamenode [-checkpoint [force]] | [-format] | [-geteditsize]
COMMAND_OPTION Description
-checkpoint [force] Checkpoints the SecondaryNameNode if EditLog size >= fs.checkpoint.size. If force is used, checkpoint irrespective of EditLog size.
-format Format the local storage during startup.
-geteditsize Prints the number of uncheckpointed transactions on the NameNode.
Runs the HDFS secondary namenode. See Secondary Namenode for more info.
启动:
bin/hadoop-daemons.sh --config conf/ --hosts masters start secondarynamenode
停止:
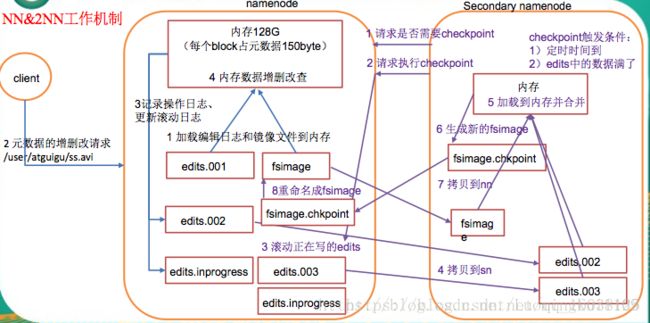
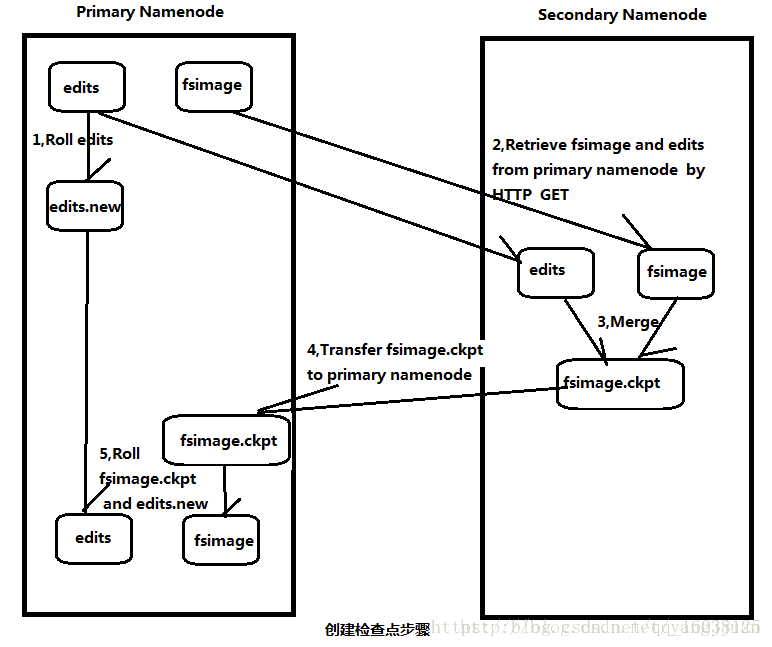
bin/hadoop-daemons.sh --config conf/ --hosts masters stop secondarynamenode日志与镜像的定期合并步骤
1.SecondaryNameNode通知NameNode准备提交edits文件,此时主节点产生edits.new
2.SecondaryNameNode通过http get方式获取NameNode的fsimage与edits文件(在SecondaryNameNode的current同级目录下可见到 temp.check-point或者previous-checkpoint目录,这些目录中存储着从namenode拷贝来的镜像文件)
3.SecondaryNameNode开始合并获取的上述两个文件,产生一个新的fsimage文件fsimage.ckpt
4.SecondaryNameNode用http post方式发送fsimage.ckpt至NameNode
5.NameNode将fsimage.ckpt与edits.new文件分别重命名为fsimage与edits,然后更新fstime,整个checkpoint过程到此结束。 在新版本的hadoop中(hadoop0.21.0),SecondaryNameNode两个作用被两个节点替换, checkpoint node与backup node. SecondaryNameNode备份由三个参数控制fs.checkpoint.period控制周期,fs.checkpoint.size控制日志文件超过多少大小时合并, dfs.http.address表示http地址,这个参数在SecondaryNameNode为单独节点时需要设置。
Checkpoint的日志信息
2011-07-19 23:59:28,435 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Number of transactions: 0 Total time for transactions(ms): 0Number of transactions batched in Syncs: 0 Number of syncs: 0 SyncTimes(ms): 02011-07-19 23:59:28,472 INFO org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: Downloaded file fsimage size 548 bytes.
2011-07-19 23:59:28,473 INFO org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: Downloaded file edits size 631 bytes.
2011-07-19 23:59:28,486 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: fsOwner=hadadm,hadgrp
2011-07-19 23:59:28,486 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: supergroup=supergroup
2011-07-19 23:59:28,486 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: isPermissionEnabled=true
2011-07-19 23:59:28,488 INFO org.apache.hadoop.hdfs.server.common.Storage: Number of files = 6
2011-07-19 23:59:28,489 INFO org.apache.hadoop.hdfs.server.common.Storage: Number of files under construction = 0
2011-07-19 23:59:28,490 INFO org.apache.hadoop.hdfs.server.common.Storage: Edits file /home/hadadm/clusterdir/tmp/dfs/namesecondary/current/edits of size 631 edits # 6 loaded in 0 seconds.
2011-07-19 23:59:28,493 INFO org.apache.hadoop.hdfs.server.common.Storage: Image file of size 831 saved in 0 seconds.
2011-07-19 23:59:28,513 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Number of transactions: 0 Total time for transactions(ms): 0Number of transactions batched in Syncs: 0 Number of syncs: 0 SyncTimes(ms): 0
2011-07-19 23:59:28,543 INFO org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: Posted URL master:50070putimage=1&port=50090&machine=10.253.74.234&token=-18:1766583108:0:1311091168000:1311087567797
2011-07-19 23:59:28,561 WARN org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode: Checkpoint done. New Image Size: 831文件结构
edits、fsimage、fstime、
VERSION文件内容:
#Tue Jul 19 22:59:27 CST 2011
namespaceID=1766583108
cTime=0
storageType=NAME_NODE
layoutVersion=-18previous.checkpoint目录内容是上一个检查点的数据,可以用来恢复数据
导入CheckPoint
如果主节点namenode挂掉了,硬盘数据需要时间恢复或者不能恢复了,现在又想立刻恢复HDFS,这个时候就可以import checkpoint。步骤如下:
准备原来机器一样的机器,包括配置和文件
创建一个空的文件夹,该文件夹就是配置文件中dfs.name.dir所指向的文件夹。
拷贝你的secondary NameNode checkpoint出来的文件,到某个文件夹,该文件夹为fs.checkpoint.dir指向的文件夹(例如:/home/hadadm/clusterdir/tmp/dfs/namesecondary)
执行命令bin/hadoop namenode –importCheckpoint
这样NameNode会读取checkpoint文件,保存到dfs.name.dir。但是如果你的dfs.name.dir包含合法的 fsimage,是会执行失败的。因为NameNode会检查fs.checkpoint.dir目录下镜像的一致性,但是不会去改动它。
一般建议给maste配置多台机器,让namesecondary与namenode不在同一台机器上值得推荐的是,你要注意备份你的dfs.name.dir和 ${hadoop.tmp.dir}/dfs/namesecondary。
缺点
因为Secondarynamenaode不是实施备份和同步,所以SNN会丢掉当前namenode的edit log数据,应该来说backupnode可以解决这个问题
Checkpoint Node
NameNode persists its namespace using two files: fsimage, which is the latest checkpoint of the namespace and edits, a journal (log) of changes to the namespace since the checkpoint. When a NameNode starts up, it merges the fsimage and edits journal to provide an up-to-date view of the file system metadata. The NameNode then overwrites fsimage with the new HDFS state and begins a new edits journal.
The Checkpoint node periodically creates checkpoints of the namespace. It downloads fsimage and edits from the active NameNode, merges them locally, and uploads the new image back to the active NameNode. The Checkpoint node usually runs on a different machine than the NameNode since its memory requirements are on the same order as the NameNode. The Checkpoint node is started by bin/hdfs namenode -checkpoint on the node specified in the configuration file.
The location of the Checkpoint (or Backup) node and its accompanying web interface are configured via the dfs.namenode.backup.address and dfs.namenode.backup.http-address configuration variables.
The start of the checkpoint process on the Checkpoint node is controlled by two configuration parameters.
dfs.namenode.checkpoint.period, set to 1 hour by default, specifies the maximum delay between two consecutive checkpoints
dfs.namenode.checkpoint.txns, set to 1 million by default, defines the number of uncheckpointed transactions on the NameNode which will force an urgent checkpoint, even if the checkpoint period has not been reached.
The Checkpoint node stores the latest checkpoint in a directory that is structured the same as the NameNode’s directory. This allows the checkpointed image to be always available for reading by the NameNode if necessary. See Import checkpoint.
Multiple checkpoint nodes may be specified in the cluster configuration file.
For command usage, see namenode.
Backup Node
BackupNode : 备份结点。这个结点的模式有点像 mysql 中的主从结点复制功能, NN 可以实时的将日志传送给 BN ,而 SNN 是每隔一段时间去 NN 下载 fsimage 和 edits 文件,而 BN 是实时的得到操作日志,然后将操作合并到 fsimage 里。在 NN 里提供了二个日志流接口: EditLogOutputStream 和 EditLogInputStream 。即当 NN 有日志时,不仅会写一份到本地 edits 的日志文件,同时会向 BN 的网络流中写一份,当流缓冲达到阀值时,将会写入到 BN 结点上, BN 收到后就会进行合并操作,这样来完成低延迟的日志复制功能。
The Backup node provides the same checkpointing functionality as the Checkpoint node, as well as maintaining an in-memory, up-to-date copy of the file system namespace that is always synchronized with the active NameNode state. Along with accepting a journal stream of file system edits from the NameNode and persisting this to disk, the Backup node also applies those edits into its own copy of the namespace in memory, thus creating a backup of the namespace.
The Backup node does not need to download fsimage and edits files from the active NameNode in order to create a checkpoint, as would be required with a Checkpoint node or Secondary NameNode, since it already has an up-to-date state of the namespace state in memory. The Backup node checkpoint process is more efficient as it only needs to save the namespace into the local fsimage file and reset edits.
As the Backup node maintains a copy of the namespace in memory, its RAM requirements are the same as the NameNode.
The NameNode supports one Backup node at a time. No Checkpoint nodes may be registered if a Backup node is in use. Using multiple Backup nodes concurrently will be supported in the future.
The Backup node is configured in the same manner as the Checkpoint node. It is started with bin/hdfs namenode -backup.
The location of the Backup (or Checkpoint) node and its accompanying web interface are configured via the dfs.namenode.backup.address and dfs.namenode.backup.http-address configuration variables.
Use of a Backup node provides the option of running the NameNode with no persistent storage, delegating all responsibility for persisting the state of the namespace to the Backup node. To do this, start the NameNode with the -importCheckpoint option, along with specifying no persistent storage directories of type edits dfs.namenode.edits.dir for the NameNode configuration.
For a complete discussion of the motivation behind the creation of the Backup node and Checkpoint node, see HADOOP-4539. For command usage, see namenode.
Import Checkpoint
The latest checkpoint can be imported to the NameNode if all other copies of the image and the edits files are lost. In order to do that one should:
Create an empty directory specified in the dfs.namenode.name.dir configuration variable;
Specify the location of the checkpoint directory in the configuration variable dfs.namenode.checkpoint.dir;
and start the NameNode with -importCheckpoint option.
The NameNode will upload the checkpoint from the dfs.namenode.checkpoint.dir directory and then save it to the NameNode directory(s) set in dfs.namenode.name.dir. The NameNode will fail if a legal image is contained in dfs.namenode.name.dir. The NameNode verifies that the image in dfs.namenode.checkpoint.dir is consistent, but does not modify it in any way.
For command usage, see namenode.
Fsimage和Edits解析
(1) 概念
namenode被格式化之后,将在/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current 目录中产生如下文件:
edits_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
① Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息。
② Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
③ seen_txid文件: seen_txid文件保存的是一个数字,就是最后一个edits_的数字
④ VERSION:记录了nameNode的相关信息
namespaceID=1660707761
clusterID=CID-ae140ab0-f35c-42e4-bace-99e391612bd5
cTime=0
storageType=NAME_NODE
blockpoolID=BP-513901284-10.211.55.103-1526360404128
layoutVersion=-63⑤ 注意:每次NameNode启动的时候都会将fsimage文件读入内存,并从00001开始到seen_txid中记录的数字依次执行每个edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将fsimage和edits文件进行了合并。
(2) oiv查看fsimage文件
① 查看oiv和oev命令
[luomk@hadoop102 current] hdfsoivapplytheofflinefsimageviewertoanfsimageoevapplytheofflineeditsviewertoaneditsfile②基本语法hdfsoiv−p文件类型−i镜像文件−o转换后文件输出路径③案例实操[luomk@hadoop102current] h d f s o i v a p p l y t h e o f f l i n e f s i m a g e v i e w e r t o a n f s i m a g e o e v a p p l y t h e o f f l i n e e d i t s v i e w e r t o a n e d i t s f i l e ② 基 本 语 法 h d f s o i v − p 文 件 类 型 − i 镜 像 文 件 − o 转 换 后 文 件 输 出 路 径 ③ 案 例 实 操 [ l u o m k @ h a d o o p 102 c u r r e n t ] pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/name/current
[luomk@hadoop102 current] hdfsoiv−pXML−ifsimage0000000000000000025−o/opt/module/hadoop−2.7.2/fsimage.xml[luomk@hadoop102current] h d f s o i v − p X M L − i f s i m a g e 0 000000000000000025 − o / o p t / m o d u l e / h a d o o p − 2.7.2 / f s i m a g e . x m l [ l u o m k @ h a d o o p 102 c u r r e n t ] cat /opt/module/hadoop-2.7.2/fsimage.xml
将显示的xml文件内容拷贝到eclipse中创建的xml文件中,并格式化。部分显示结果如下。
<inode>
<id>16386id>
<type>DIRECTORYtype>
<name>username>
<mtime>1512722284477mtime>
<permission>luomk:supergroup:rwxr-xr-xpermission>
<nsquota>-1nsquota>
<dsquota>-1dsquota>
inode>
<inode>
<id>16387id>
<type>DIRECTORYtype>
<name>luomkname>
<mtime>1512790549080mtime>
<permission>luomk:supergroup:rwxr-xr-xpermission>
<nsquota>-1nsquota>
<dsquota>-1dsquota>
inode>
<inode>
<id>16389id>
<type>FILEtype>
<name>wc.inputname>
<replication>3replication>
<mtime>1512722322219mtime>
<atime>1512722321610atime>
<perferredBlockSize>134217728perferredBlockSize>
<permission>luomk:supergroup:rw-r--r--permission>
<blocks>
<block>
<id>1073741825id>
<genstamp>1001genstamp>
<numBytes>59numBytes>
block>
blocks>
inode>
(3) oev查看edits文件
① 基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
② 案例实操
[luomk@hadoop102 current] hdfsoev−pXML−iedits0000000000000000012−0000000000000000013−o/opt/module/hadoop−2.7.2/edits.xml[luomk@hadoop102current] h d f s o e v − p X M L − i e d i t s 0 000000000000000012 − 0000000000000000013 − o / o p t / m o d u l e / h a d o o p − 2.7.2 / e d i t s . x m l [ l u o m k @ h a d o o p 102 c u r r e n t ] cat /opt/module/hadoop-2.7.2/edits.xml
将显示的xml文件内容拷贝到eclipse中创建的xml文件中,并格式化。显示结果如下。
<EDITS>
<EDITS_VERSION>-63EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENTOPCODE>
<DATA>
<TXID>129TXID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_ADDOPCODE>
<DATA>
<TXID>130TXID>
<LENGTH>0LENGTH>
<INODEID>16407INODEID>
<PATH>/hello7.txtPATH>
<REPLICATION>2REPLICATION>
<MTIME>1512943607866MTIME>
<ATIME>1512943607866ATIME>
<BLOCKSIZE>134217728BLOCKSIZE>
<CLIENT_NAME>DFSClient_NONMAPREDUCE_-1544295051_1CLIENT_NAME>
<CLIENT_MACHINE>192.168.1.5CLIENT_MACHINE>
<OVERWRITE>trueOVERWRITE>
<PERMISSION_STATUS>
<USERNAME>luomkUSERNAME>
<GROUPNAME>supergroupGROUPNAME>
<MODE>420MODE>
PERMISSION_STATUS>
<RPC_CLIENTID>908eafd4-9aec-4288-96f1-e8011d181561RPC_CLIENTID>
<RPC_CALLID>0RPC_CALLID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_ALLOCATE_BLOCK_IDOPCODE>
<DATA>
<TXID>131TXID>
<BLOCK_ID>1073741839BLOCK_ID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_SET_GENSTAMP_V2OPCODE>
<DATA>
<TXID>132TXID>
<GENSTAMPV2>1016GENSTAMPV2>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_ADD_BLOCKOPCODE>
<DATA>
<TXID>133TXID>
<PATH>/hello7.txtPATH>
<BLOCK>
<BLOCK_ID>1073741839BLOCK_ID>
<NUM_BYTES>0NUM_BYTES>
<GENSTAMP>1016GENSTAMP>
BLOCK>
<RPC_CLIENTID>RPC_CLIENTID>
<RPC_CALLID>-2RPC_CALLID>
DATA>
RECORD>
<RECORD>
<OPCODE>OP_CLOSEOPCODE>
<DATA>
<TXID>134TXID>
<LENGTH>0LENGTH>
<INODEID>0INODEID>
<PATH>/hello7.txtPATH>
<REPLICATION>2REPLICATION>
<MTIME>1512943608761MTIME>
<ATIME>1512943607866ATIME>
<BLOCKSIZE>134217728BLOCKSIZE>
<CLIENT_NAME>CLIENT_NAME>
<CLIENT_MACHINE>CLIENT_MACHINE>
<OVERWRITE>falseOVERWRITE>
<BLOCK>
<BLOCK_ID>1073741839BLOCK_ID>
<NUM_BYTES>25NUM_BYTES>
<GENSTAMP>1016GENSTAMP>
BLOCK>
<PERMISSION_STATUS>
<USERNAME>luomkUSERNAME>
<GROUPNAME>supergroupGROUPNAME>
<MODE>420MODE>
PERMISSION_STATUS>
DATA>
RECORD>
EDITS>3.checkpoint设置
在 hdfs-default.xml 配置文件中
(1) 通常情况下,SecondaryNameNode每隔一小时执行一次。
<property>
<name>dfs.namenode.checkpoint.periodname>
<value>3600value>
property>
(2) 一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txnsname>
<value>1000000value>
<description>操作动作次数description>
property>
<property>
<name>dfs.namenode.checkpoint.check.periodname>
<value>60value>
<description> 1分钟检查一次操作次数description>
property>处理NameNode故障
方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
(1) kill -9 namenode进程
(2) 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[luomk@hadoop102 hadoop-2.7.2] rm−rf/opt/module/hadoop−2.7.2/data/tmp/dfs/name/∗(3)拷贝SecondaryNameNode中数据到原NameNode存储数据目录[luomk@hadoop102dfs] r m − r f / o p t / m o d u l e / h a d o o p − 2.7.2 / d a t a / t m p / d f s / n a m e / ∗ ( 3 ) 拷 贝 S e c o n d a r y N a m e N o d e 中 数 据 到 原 N a m e N o d e 存 储 数 据 目 录 [ l u o m k @ h a d o o p 102 d f s ] scp -r luomk@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/
(4) 重新启动namenode
方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
(1) 修改hdfs-site.xml中的
<property>
<name>dfs.namenode.checkpoint.periodname>
<value>120value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/opt/module/hadoop-2.7.2/data/tmp/dfs/namevalue>
property>(2) kill -9 namenode进程
(3) 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[luomk@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*(4) 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件。
[luomk@hadoop102 dfs] scp−rluomk@hadoop104:/opt/module/hadoop−2.7.2/data/tmp/dfs/namesecondary./[luomk@hadoop102namesecondary] s c p − r l u o m k @ h a d o o p 104 : / o p t / m o d u l e / h a d o o p − 2.7.2 / d a t a / t m p / d f s / n a m e s e c o n d a r y . / [ l u o m k @ h a d o o p 102 n a m e s e c o n d a r y ] rm -rf in_use.lock
[luomk@hadoop102 dfs] pwd/opt/module/hadoop−2.7.2/data/tmp/dfs[luomk@hadoop102dfs] p w d / o p t / m o d u l e / h a d o o p − 2.7.2 / d a t a / t m p / d f s [ l u o m k @ h a d o o p 102 d f s ] ls
data name namesecondary
(5) 导入检查点数据(等待一会ctrl+c结束掉)
[luomk@hadoop102 hadoop-2.7.2] bin/hdfsnamenode−importCheckpoint(6)启动namenode[luomk@hadoop102hadoop−2.7.2] b i n / h d f s n a m e n o d e − i m p o r t C h e c k p o i n t ( 6 ) 启 动 n a m e n o d e [ l u o m k @ h a d o o p 102 h a d o o p − 2.7.2 ] sbin/hadoop-daemon.sh start namenode