SparkOnYarn专题一SparkOnYarn环境搭建
版权声明:本文为博主原创文章,未经博主允许不得转载!!
欢迎访问:https://blog.csdn.net/qq_21439395/article/details/80678372
交流QQ: 824203453
欢迎关注B站,收看更多视频内容:https://space.bilibili.com/383891492
hadoop版本: 2.8.0 spark 版本: 2.2.0
前提:hdfs的集群环境已经搭建完毕,这里不详表。
集群环境:3台机器规模
| 192.168.8.11 hdp-01 192.168.8.12 hdp-02 192.168.8.13 hdp-03 hdp-01上安装: NameNode ResourceManager DataNode NodeManager hdp-02 hdp-03 上安装: DataNode NodeManager |
1. yarn集群环境搭建:
yarn集群中有两个角色:
主节点:Resource Manager 1台
从节点:Node Manager N台
NodeManager在物理上应该跟data node部署在一起,为什么?
hdfs上的数据存储在datanode节点上,而nodemanager,要进行运算,就需要读取datanode上的数据块,如果部署在datanode节点上,可用直接本地读取,不需要再跨网络传输,速度更快,效率更高。
ResourceManager在物理上应该独立部署在一台专门的机器上(可用部署在任意的机器)
1 修改配置文件:
yarn-site.xml
| # nodemanager给 mapreduce程序提供辅助功能,辅助shuffle |
yarn集群配置参数说明:
| yarn.nodemanager.resource.memory-mb 默认是8G yarn.nodemanager.resource.cpu-vcores 默认是8 注意:如果内存不足2G,至少配置2G,即值为2048 如果内存配置低于2G,可能会导致mapreduce任务不能正常运行。 报错如下:
原因: 在mapred-default.xml中,有默认参数配置了(MR AppMaster)内存为1.5G。
每一个mapreduce 会启动一个MR AppMaster进行。 |

2、scp这个yarn-site.xml到其他节点
| cd /root/apps/hadoop/etc/hadoop/ for i in 2 3;do scp yarn-site.xml hdp-0$i:`pwd` ;done |
yarn为每一个容器分配内存和核数:
| yarn为每一个container分配的最小的内存:1024 yarn.scheduler.minimum-allocation-mb 1024最大可分配的内存为8G: yarn.scheduler.maximum-allocation-mb 8192 最小的cores: 1个 默认的就是一个 yarn.scheduler.minimum-allocation-vcores 1 最多可分配的cores:32个 yarn.scheduler.maximum-allocation-vcores 32
|
3、启动yarn集群:
主节点:#yarn-daemon.sh start resourcemanager
从节点:#yarn-daemon.sh start nodemanager
4、脚本批量启动:
在hdp-01上,修改hadoop的slaves文件,列入要启动nodemanager的机器
然后将hdp-01到所有机器的免密登陆配置好
启动yarn集群:(注:该命令应该在resourcemanager所在的机器上执行)
# start-yarn.sh
停止:# stop-yarn.sh
验证:用jps检查yarn的进程,用web浏览器查看yarn的web控制台
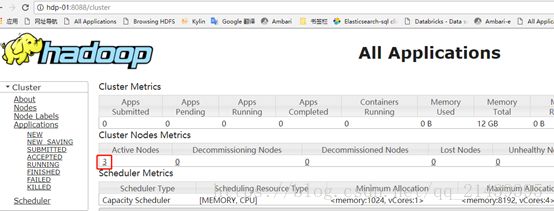
启动完成后,可以在windows上用浏览器访问resourcemanager的web端口:
http://hdp-01:8088
看resource mananger是否认出了所有的node manager节点
2. spark on yarn,yarn集群的补充配置:
补充配置一:
yarn默认情况下,只根据内存调度资源,所以sparkon yarn运行的时候,即使通过--executor-cores指定vcore个数为N,但是在yarn的资源管理页面上看到使用的vcore个数还是1. 相关配置在capacity-scheduler.xml 文件:
|
|
补充配置二:
修改所有yarn节点的yarn-site.xml,在该文件中添加如下配置
| |
如果不配置这两个选项,在spark-on-yarn的client模式下,可能会报错,错误如下:

分析原因:内存不足,导致程序被终止。
参数说明: |
配置修改完成之后,把配置文件分发到各台节点上:
| # cd /root/apps/hadoop/etc/hadoop [root@hdp-01 hadoop]# for i in 2 3 ;do scp capacity-scheduler.xml yarn-site.xml hdp-0$i:`pwd`;done |
至此,spark on yarn的yarn集群配置完成。(hdfs集群也配置完成是前提)
启动hdfs和yarn集群。
3. spark配置:
3.1. sparkonyarn 简介:
yarn是hadoop中的一个组件,是一个统一的资源调度平台。
spark on yarn,就是把spark任务提交到yarn 集群上运行。
那么提交spark任务的地方,就是客户端。所以客户端一台即可。但需要保证客户端可以正常连接到hdfs集群和yarn集群。
3.2. spark配置:
官方文档:
http://spark.apache.org/docs/latest/running-on-yarn.html
下载spark安装包,上传并解压到/root/apps目录下。
修改spark的配置文件,只需要修改conf目录下的spark-env.sh 配置文件即可。
在spark-env.sh中配置
| export JAVA_HOME=/usr/local/jdk1.8.0_131 export HADOOP_CONF_DIR=/root/apps/hadoop/etc/hadoop |
注意:该配置文件的作用,就是告知spark程序yarn在哪里。
可以使用HADOOP_CONF_DIR或者YARN_CONF_DIR,如果不配置该选项,就会报错如下:
![]()
再次强调:提交spark任务的地方,就是客户端,所以配置一台机器即可。
待HDFS和YARN正常启动后,就可以提交任务到yarn集群中。
4.启动hadoop集群
启动hdfs:start-dfs.sh
启动yarn: start-yarn.sh
yarn集群状况:


5 补充:hadoop集群其他配置文件:
core-site.xml文件:
| |
hdfs-site.xml文件:
| # namenode 存储元数据的本地目录 # datanode 存储块数据的本地目录 |
hadoop-env.sh:
| export JAVA_HOME=/usr/local/jdk |
版权声明:本文为博主原创文章,未经博主允许不得转载!!
欢迎访问:https://blog.csdn.net/qq_21439395/article/details/80678372
交流QQ: 824203453
欢迎关注B站,收看更多视频内容:https://space.bilibili.com/383891492