IBC 2019 五篇文章阅读笔记
本文是阅读 IBC 2019上面五篇文章的阅读笔记。
目录
- 一、Comparative Analysis of Real-time Multi-view Reconstruction of a Sign Language Interpreter 手语翻译员的多视角重构的对比分析
- 1. 背景动机
- 2. 相关工作
- 3. 主要方法
- 4. 总结思考
- 5. 文词珠玉
- 二、Evaluating The Quality of Multi-Camera Video Capture and View-Point Interpolation for 6DOF AR/VR Applications 六自由度AR/VR应用中多摄像机视频获取与视点插入的质量验证
- 1. 背景动机
- 2. 主要方法
- 3. 总结思考
- 4. 文词珠玉
- 三、HIAR/VR For Various Viewing Styles in the Future of Broadcasting 未来广播中的多视角HIAR/VR模式
- 1. 背景动机
- 2. 已有工作
- 3. 目前工作和可能的研发方向
- 4. 总结思考
- 5. 文词珠玉
- 四、Lessons Learnt During One Year of Commercial Volumetric Video Production 一年的商业体视频生产带来的提高和进步
- 1. 背景动机
- 2. 系统概述
- 3. 总结思考
- 4. 文词珠玉
- 五、State-of-Art of Extended Reality in 5G Networks 5G网络中目前最好的扩展现实
- 1. 背景动机
- 2. 基于5G的扩展现实案例
- 3. 基于5G的扩展现实的技术
- 4. 基于5G的扩展现实标准
- 5. 总结感受
- 6. 文词珠玉
- 六、总结
一、Comparative Analysis of Real-time Multi-view Reconstruction of a Sign Language Interpreter 手语翻译员的多视角重构的对比分析
1. 背景动机
聋人社区对手语播报的需求非常迫切,HbbTV 2.0的启动也促使众多广播公司通过手持设备为聋人社区提供更多易获取的内容。
现有手语播报服务依赖专用演播室(背景,光线,摄像),多使用后期合成技术,将手语翻译合成进主要内容流中,花费很高。
对手语翻译员进行写实三维重构是一种解决方法,以用户为中心,使用低花费传感器,且不受环境影响。本文使用多个RGB-D传感器(Kinect V2, RealSense D435)来进行重建。
2. 相关工作
RGB-D传感器已广泛用于姿态估计、场景重建等。深度传感器有深度信息丢失或不准确的缺点,产生原因是不正确的红外模式匹配造成的许多错误,如噪声,深度值确实或闪烁。一些研究者采用双边滤波器及其变种来处理。仍有耗时过长和不准确的问题。作者用他们之前的基于Time-of-Flignt(TOF)传感器的工作来解决这个问题。
已有一些用多Kinect无缝渲染场景的工作,主要挑战是对感知到的数据做筛选、纠正和重构。本文的引文11通过给点云中的每一对近邻添加一个新点,实现了不需要预处理或过采样的实时表面细化。
引文9通过使用多台PC分散计算负载,然而实时处理的帧率较低。
3. 主要方法
主要有三个步骤:将多台放置在采集区域周围的RGB-D传感器连接起来;校准;用可实时处理大规模数据的方法来进行点云提升。
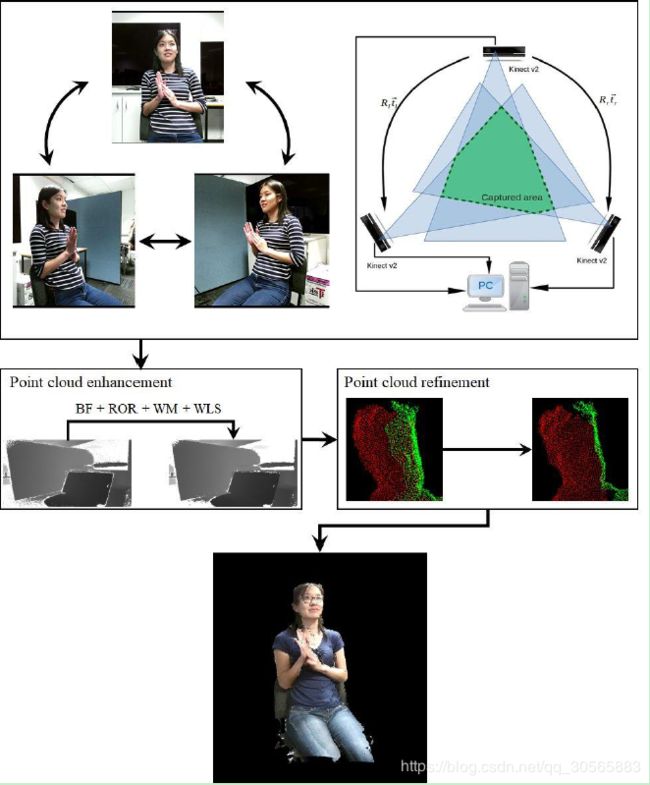
校准分两部分,RGB与D的校准;多台传感器之间的校准。
RGB与D的校准:二者不能达到像素级别的一一对应,本文用的是引文8的方法。把深度图中的点映射到三维空间中,然后再投影到RGB摄像平面中。
传感器之间的校准:本文用的是引文8和9的方法,通过使用摄像机针孔模型(camera pinhole model)来寻找传感器的内在和外在参数。
重建的主要问题为,如何对多个传感器采集到的信息做时间序列同步。相关方法主要缺陷是,不同RGB-D设备采集到的深度信息可能矛盾。
文章认为深度图的质量对模型获取和重建都很关键。ToF摄像头如Kinect V2通过衍射膜投射伪随机红外光,可能造成深度值不准确。结构传感器如RealSense D435主要缺点是因红外传感器曝光不足或曝光过度导致的深度值不准确。
因此需要用预处理去掉图像边界上的像素,可以通过采用多个滤波方法来实现(文献8)。
图像表达的准确率主要取决于点云点的数量,本文将不同传感器得到的点云进行了缝合。
文章假设任何传感器得到的深度值都可以用其他传感器采集到的数据进行估计。
4. 总结思考
主要思路是,多RGB-D传感器,RGB与D的校准和传感器校准,时间序列对齐,滤波去除噪音,点云缝合。
文章讲的RGB与D的校准方法如果是用了Kinect V2提供的标准接口,效果应该很差,我之前也用过。不知道作者具体是怎么做的。
文章没讲清楚具体重构的方法,关键的几个点也是直接引用之前的文献,一些地方也没说清楚,连实验部分都没有,作图也比较粗糙,实质内容貌似并不多,需要参考其他几篇引文来完全理解和实现。
一点启发就是用其他传感器采集到的数据去估计和代替单一传感器的数据,减小误差。
5. 文词珠玉
following the proliferation of … 随着…的激增、增殖
emerging trend 迫切需求
address the demand placed on … 满足…的需求
pervasive adj. 普遍的
facilitate v. 促进
in the literature 现有文献中
render a scene 场景渲染
lay in 是
stress the advantage of 强调…的优势
二、Evaluating The Quality of Multi-Camera Video Capture and View-Point Interpolation for 6DOF AR/VR Applications 六自由度AR/VR应用中多摄像机视频获取与视点插入的质量验证
1. 背景动机
制作六自由度视频要求视频用多台摄像机采集、实时深度估计、压缩、流播和回放。目前这些步骤都在发展中,没有现成的解决方案。
为了在发展过程中做好抉择,需要提前预测系统参数(例如摄像头间距)和深度估计算法对图像质量的影响。
本文提出了一种使用人工场景的光线追踪图像的质量估计方法。
图像做深度估计和视角合成,视角再做合成,得到的图像与光线追踪图像做对比。
通过比较光线追踪图像估计得的深度合成得的图像,和用真实深度合成得的图像,隔离模型误差与深度估计误差。
2. 主要方法
Python-Blender v2.79用于创建15x15视角区域内的光线追踪图,该图来自于位于15x15点阵上间距为3cm的摄像头(下图绿色的圈),视角区域允许观察者上下左右转动头:
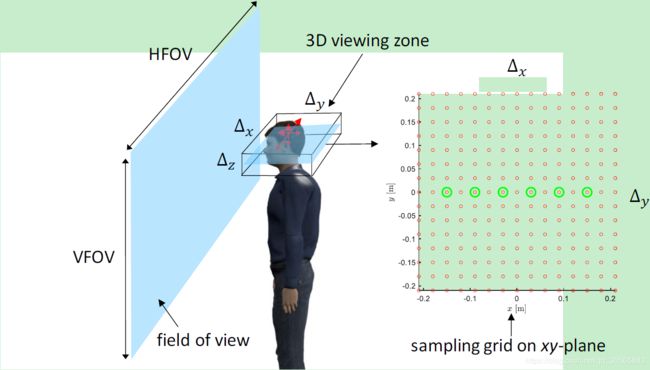
Python-Blender用于自动光线追踪15x15的图像,x和y方向的间隔都是3厘米。
捕获操作有一个关键参数是摄像机的间距(baseline),给定视区内的最小质量水平,使用光线追踪图像可以让我们找到合适的baseline。
文章研究了人物场景(用MakeHuman软件搭建)和车辆场景(使用Blender的demo),作为代表性的场景捕捉。
用客观峰值信噪比(Peak signal-to-noise ratio)来度量系统参数(摄像头间距):
P S N R ≡ 10 ⋅ l o g 10 ( 25 5 2 M S E ) PSNR\equiv10·log_{10}(\frac{255^2}{MSE}) PSNR≡10⋅log10(MSE2552)
MSE是RGB色彩通道的均方误差。PSNR在用单一数据集比较baseline时尤其有用。然后用PSNR对比合成图像与光线追踪的图像。
下图给出了整体流程:
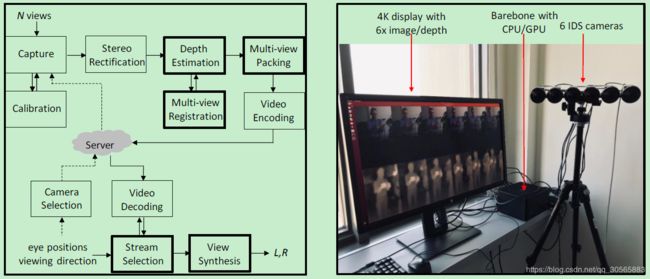
本文使用文献5和6的深度估计与误差分类方法,用双边滤波器保证深度值变化平滑。
如上图右侧图,准系统电脑为Magnus ZBOX-EN1080K,显示器播放的是4K的深度估计图和原图,6个摄像头分辨率均为640x1080。
系统同时处理6个摄像头的输入,得到6个深度图,将12张图拼接到4K帧中并编码,上述过程实时帧率为30fps。
客户端接收到的视频是一些压缩和编码过的视频,需要解压缩和解码。
流的选择在客户端完成,为左右眼各找两个距离最近的视角。
假设每个视角的model matrix M i M_i Mi已知, p = ( 0 , 0 , 0 , 1 ) t p=(0,0,0,1)^t p=(0,0,0,1)t是齐次坐标,距离判断公式为:
i n e a r e s t = a r g m i n i ( ∣ M i p − V p ∣ ) i_{nearest}=argmin_i(|M_ip-Vp|) inearest=argmini(∣Mip−Vp∣)
其中 V V V取 V l e f t V_{left} Vleft或 V r i g h t V_{right} Vright,表示左右眼视角。
文章还用了简单着色器来提高图像质量。
上述得到的两个视角用来预测每只眼的最终视图,用如下公式:
I e y e = ∣ x 2 ∣ ∣ x 1 ∣ + ∣ x 2 ∣ I 1 + ∣ x 1 ∣ ∣ x 1 ∣ + ∣ x 2 ∣ I 2 I_{eye}=\frac{|x_2|}{|x_1|+|x_2|}I_{1}+\frac{|x_1|}{|x_1|+|x_2|}I_{2} Ieye=∣x1∣+∣x2∣∣x2∣I1+∣x1∣+∣x2∣∣x1∣I2
其中 x 1 x_1 x1和 x 2 x_2 x2分别表示两个视角距离 x x x轴原点的距离。
实验部分在车辆场景和人物场景进行,用真实深度值与估计的深度值作对比。
发现摄像头间距越小,视区的PSNR值越大。摄像头间距越小,估计误差与视角合成误差都越小。
3. 总结思考
文章主要工作就是用6个甚至更多个摄像头阵列拍摄多个视频流,然后做成4K视频,压缩编码传输到用户端。
用户端是一个比较大的场景,用户直接面对,然后为用户的左右眼分别选择两个最近的视频流做合成,用户转动头(上下左右)就可以得到不同的视角,得到接近于用户直面场景的立体的效果。
实验部分,文章似乎就是用Python-Blender做建模,然后取不同视角和深度值模拟6个摄像头,再做融合去与真实的深度值做比较。数据也容易取,还避免了引入不必要误差,对做实验是很方便的。
本文的工作令我想起了接触过的HoloLens,不过HoloLens可以让用户围绕场景转一圈,还可以放大、拉近等。比本文做的效果更立体更真实,本文只能面对场景。下图很好地说明了HoloLens的特点:

启发是,Python-Blender是一种很好的工具;PSNR是一种常见的好用的指标;文章用深度值去校验立体效果,也值得参考。
一个粗浅直接的想法就是考虑往HoloLens的方向改进,以及考虑如何缩放、移动。文章没有考虑摄像头其他摆放方式下的效果和处理方法,也没有展示真实场景下的效果,后续可以做些这方面的工作。
4. 文词珠玉
ground truth 真值
under development 正在发展
ready-made adj. 现成的
enrich the applications 丰富了应用
further into the future 更进一步的未来
client device 客户端
for the live broadcast case 对现场直播这个案例来说
at initialization 初始时
systematically adv. 系统地
三、HIAR/VR For Various Viewing Styles in the Future of Broadcasting 未来广播中的多视角HIAR/VR模式
1. 背景动机
文章讨论了未来的广播媒体中要求的技术和研发策略,以及视角形式。AR/VR被认为是演播室内4K/8K发展之后的重要因素。为了发展AR/VR,文章应用了两种方法:演绎和归纳。
演绎法关注于实现AR/VR,称为“For AR/VR”,是通过利用技术创新来提高表现效果。
归纳法关注于用AR/VR做什么,称为“By AR/VR”,首先需要从科技和社会发展趋势来预期现在和未来的潜在需要,然后考虑我们应提供何种图像服务,接下来进行研发。广播媒体公司应考虑用广播内容做什么,比如联系沟通人与人等,这是高于“For AR/VR”的一层。
本文介绍了过去和现在的关于“For AR/VR”和“By AR/VR”的例子,关注未来的视觉形式,讨论了媒体在AR/VR时代的作用。
通过归纳法,文章期望AR/VR媒体能够超越时间限制,将用户连接起来,也期望在AR眼镜时代,处理多种形式的2D视频成为一种重要方法。
为了解决上述问题,文章提出一种使用球形图像和α通道(透明通道)的方法,几乎可以包含所有类型的2D视频。
为了提高图像中物体的存在,文章扩展了双目头戴式头盔和AR眼睛中的深度感知形式。
2. 已有工作
这部分主要介绍过去在AR/VR方面的研发尝试,用以指导未来的AR/VR广播媒体技术和发展策略。
“For AR/VR” 样例1 在使用头戴式显示器(Head-mounted displays,HMD)通过宽广视角观察360°全景图像时,为了让使用者察觉不到像素结构,HMD需要提供很高的空间分辨率,这导致360°全景图像需要甚至更高的空间分辨率。NHK以8K(1058ppi)空间分辨率,用OLED(有机发光二极管)开发了一种HMD原型,来捕捉分辨率30K*15K的360°图像。这一结果在ITU-R BT.2123被用做推荐讨论样例。
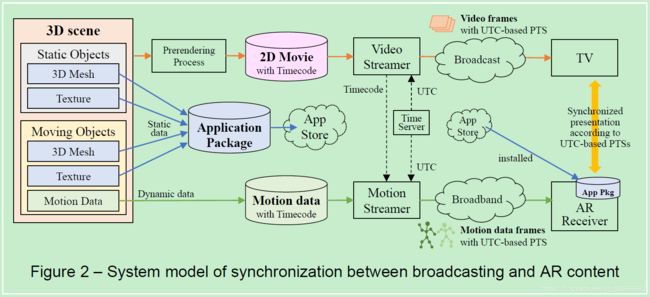
“For AR/VR” 样例2 文献3提供了一种方案,使得用户可以一边在电视上观看广播媒体节目,一边用移动设备作为第二屏幕观看三维计算图形(3DCG)内容,包含AR内容,两个屏幕的内容均已用UTC时间校准对齐。且视频使用了MMT(MPEG media transport)和UTC为基础的时间戳。
“By AR/VR” 样例1 增强电视。增强电视使得用户能感受到电视中的世界与现实世界结合了起来。有两个主要功能,一是电视图像与移动设备上的3DCG内容的帧表达同步,二是电视和移动设备之间的相对定位与定向。与上个样例相比,本样例也记录了视频回放的标记,这样除了可以用于广播电视直播,也可用于时移查看,包装媒体(package media),或数字标识等。
“By AR/VR” 样例2 360°视频传递系统,这也是一种电视节目的增强系统,使得用户可以通过移动设备看到广播节目帧之外的上下左右方向的场景,具体在文献5中。
3. 目前工作和可能的研发方向
“For AR/VR” 样例3 使用8K摄像机的高沉浸式VR产品。VR视频拍摄中,理性状态是只使用一台摄像机从而避免缝合带来的不匹配不对齐,然而没有设备能360°全景拍摄。为了减少缝合,就要求用高分辨率摄像机来实现高分辨率VR视频。文中的Table 1研究了不同的镜头和8K摄像机排列方式,在不同场景下的效果,来选择合理的设置方案。
未来AR眼镜的视觉效果 AR眼镜被视为最有可能替代智能手机的产品。与智能手机不同的是,AR眼镜具有很高的空间表达自由。AR眼镜应该有的功能包括,空间映射,空间记录,空间表达等,可以观看各种内容,也可以选择以用户为中心的坐标系(VCS,view coordinate system)或其他比较便利的坐标系。
共享空间的视觉图像服务 用户通过一些手段共享空间,虚实结合。下图很好的表达了这一愿景:
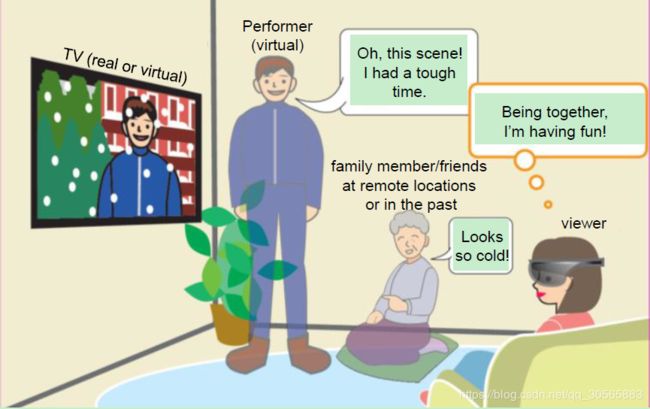
内容演示管理 虚拟电视领域将会要求更高程度的内容管理。用户的目标是优化播放体验,角色是判断者;媒体内容的目标是最大化产品关注度,角色是根据数据做决策;VROS/App的目标是优化播放,角色是状态估计与播放功能提供。通过AI手段,手工判断可以从用户层转移到VROS/App层。
“By AR/VR” 样例3 在360°全景视频中加入α通道(透明通道)。实际上各种类型的2D内容都可以被融入虚拟电视领域,如前面By AR/VR 样例2所说的。为了处理各种类型的2D内容,NHK在VCS中利用360°球形图像和α通道,利用了VP8/WebM。如果多数图像都是透明的,图像数据就可以有更高的压缩率。为了提高VCS中带有α通道的360°球形图像中物体的存在,提出一种新的距离感知形式——从用户的位置到球形图像的距离参数 d . d. d. ,该参数是与时间有关的函数。内容提供者指定 d d d的值,用户在VCS中方可使用。换言之,用户有两种感知距离的方式:通过双目头盔或AR眼镜,感知带有α通道的球形360°图像上的物体,与虚拟空间中的背景,之间的视差。360°图像上的物体与实物之间会有一个映射联系。
“By AR/VR” 样例3.1 作者开发了一个基于HoloLens的应用,该应用用红外传感器记录了每一帧时物体到HoloLens的距离,然后在回放时,该应用在相对于HoloLens的位置上播放视频。这样仿佛物体还在眼前运动一样。
“By AR/VR” 样例4 分享VR经验。在VR中,用户很难与其他人共享一个空间。文献10在用户近前(1~2m)演示AR场景,在距离用户有一段距离的地方演示360°球形图像,这样就允许其他用户共享相同的这个空间。
4. 总结思考
本文讲了AR/VR领域已经解决的一些问题和未来可能的研究方向,有一点综述、科普的性质,没有什么具体而微的内容。作者把这些问题和研究方向分为For和By,大致可以理解为理论和应用,作者期望通过一些案例研究对未来的发展提出一些指导。
主要问题包括,如何与更多平台(固定的,移动的)和媒体形式做连接、如何将虚拟和显示更好地结合、如何更好地沟通用户(虚实结合,空间共享),等等。
主要热点和工具包括,高分辨率、空间缝合、高分辨率、8K、360°球形图像、摄像头排列分布、深度值、α通道、VP8/WebM、HoloLens等等。
共享空间、虚实结合令人浮想联翩,假设有一台服务器,用于统筹处理各个用户(不论距离远近)的VR/AR眼镜以及其他摄像头看到的景象,然后进行处理合成,分别传输到各个用户的眼镜上,在服务器上完成交互。可能对传输速度要求比较高,这方面工作应该也有人在做,比较简单的交互功能应该也是可以尝试的。暂时能想到的就这些。
感觉系统性的进展,像HoloLens这样可以落地的东西,貌似还是产业界容易做出来,他们有这个需要,他们知识人才也更全面。学术界做一些具体小方向上的改进和提高比较合适,这也是学术界的长处。
这张图画的很细致生动,配色合理,也容易模仿,值得学习:
5. 文词珠玉
R&D 研究与发展(research and development)
deductive and inductive 演绎和归纳
be drawn on 关注于,聚焦于
the necessity of …的必要性
to cope with 为了处理…
enjoy a … experience 享受…的体验
broad attention 广泛关注
implicitly adv. 含蓄地
taking … into account 考虑到…
in regards to 关于
四、Lessons Learnt During One Year of Commercial Volumetric Video Production 一年的商业体视频生产带来的提高和进步
1. 背景动机
2018年6月德国波茨坦一家公司Volucap GmbH(正是本文的完成单位)成立了一个体视频(Volumetric Video)工作室,12月开始商业生产,他们的核心产品是3D人体重构(3DHBR)。该技术用新系统捕捉真人运动,然后建立动态的3D模型,可以从任意虚拟视角或增光环境下观察。
一年以来消费者对其进行了大量的测试,提出了大量要求,3DHBR系统也提升很多。本文介绍了该系统的主要流程模块,和这一年的提升。
2. 系统概述
采集系统 采集系统由一系列继承的摄像头和照明系统,来进行360°全方位采集。该公司搭建了一个圆柱形的实验室,直径为6m,高度为4m,如下图。装备有32个20MPixel的摄像头,安装在16个立体像对(stereo pair)上。依赖于以视觉为基础的方法进行采集,而非3D传感器。
220个ARRI SkyPanel(这是一种LLE柔光灯,ARRI是品牌)安装在一个扩散组织后面,满足不同的光照需求并照亮背景。现有体视频工作室多依赖于绿色背景和离散方向的直接光照,如微软的Mixed Reality Studio和8i的工作室。

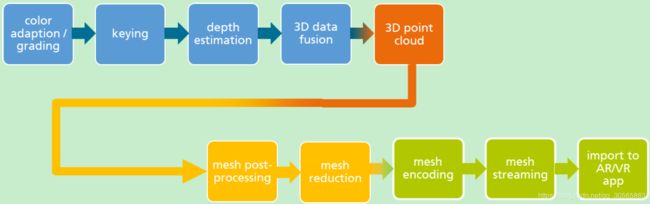
工作流程 该工作室搭建了完全自动流程来进行专业生产采集。首先是对多视角摄像头系统进行色彩校正和适应,来提供匹配的均匀的图像。然后是在前景物体上做查分键控来简化后续流程,所有摄像头都安装在均匀分布在圆柱设备上的立体像对上,这样就便于从立体基准系统上演着视角方向提取3D信息,并用IPSweep算法(文献3、4)做了立体视角匹配。
立体处理方法由一些可代替的算法结构组成,通过对应的映射使用点转化(point transfer)从左到右比较3D斑块(patches)的投影。得到的每个立体像对的深度信息被融合到每帧的公共3D点云中。然后用后续网格(mesh)处理方法把数据转换为公共的CGI(computer generated imagery)形式。
由于得到的每帧的网格仍然很复杂,考虑到目标设备的承载能力和模型对敏感区域(比如脸)的适应性,需要做网格缩减(mesh reduction)。对桌面应用,使用有60k的脸的网格;对移动设备,是20k的脸。这样就得到了一系列网格(mesh)和对应的纹理文件(texture file),每一帧都由具有自己拓扑结构的独立网格组成。这会有一些时间稳定性和相关纹理性能方面的缺陷,因此用一种网格注册(mesh registration)方法来提供相同拓扑结构的注册网格的短序列。
为了便于用户把体视频注入AR/VR应用中,发展了一种新的网格编码方案,而视频和音频是另用当前最好方法编码的,多路传输(multipleses)都传入MP4文件中。相关插件可以用Unity和Unreal处理MP4文件、编码基本流、实时提取体数据渲染来获得。主要优势是高压缩比特流可以直接从硬盘或网络中庸HTTP自适应流流动进出。
Unity和Unreal Engine是两种流行的实时渲染引擎,可以提供完整的3D场景发展环境和可以支持多数AR/VR设备与操作系统的实时渲染器。
整体流程如下:
独立处理的颜色分级 独一无二的照明系统提供了任意方向的漫射照明(diffuse lighting),因此物体的纹理就好像会很平,没有任何内部阴影。这种漫射照明提供了为后续3D模型做重照明的尽可能好的条件,从VR体验设计的角度来看。然而在以下算法步骤还需要做不同的颜色分级来处理输入数据:前景后背景分割(keying键控, i.e.);深度处理;创新的纹理分级。
在键入过程中,使用了高饱和度的分级来优化区分前景与背景。在深度处理中,使用分级是为了实现结构的最好表示,因此人像的黑色部分被分地更亮。全方位的漫射照明使得图像非常平滑,因此最后,需要第三种分级方法,来提供一个自然的皮肤色调。这个最终的分级用于把姿态反投影(back-projection)3D模型上。
为端到端流程设计的新模块 Unity和Unreal没有提供合适工具或流程来继承体视频,目前能处理好动态物体,但是临时变动的网格仍然具有挑战性。3D视频处理的结果是每一帧都有由独立拓扑结构和纹理集的独立网格组成。为了用独立拓扑结构建立网格流,那个提高相关纹理结构的时间稳定性,使用了网格正则化。
定义完关键网格的自动选择后,随后的网格结构是通过把关键帧修正到临近帧计算出来的,并且保护了近邻和拓扑结构。双向处理是用于更好地处理网格流迅速的拓扑结构变化的。一旦注册网格的偏差达到定义好的阈值,就设置新的关键网格。
然后所有纹理块都安排到一个纹理集合中,从左下角最大的块开始,为了更好地应用以块为基础的视频编码方法,首先保持块在集合中的位置,只有每个块的视频内容会改变,然后块之间的空白被修改。如下图左右两图(右图还添加了集成照明环境)。

注册好的网格流被压缩并多路传入到MP4文件中,这样就能整合入Unity和Unreal。网格用一种标准编码器(文章的图5)来编码,纹理集用在移动设备上速度更快的H.264/AVC来编码,音频信号用标准音频编码器编码。三种不同的流多路集成如MP4文件。接收端,Unity和Unreal插件将体视频插入AR/VR应用。这些插件包括信号分离器,相关解码器。我们第一批试验中,典型的移动设备的注册网格流是20Mbit/s,每个网格20k面部(faces)。桌面应用是39Mbit/s,60k。纹理分辨率都是2048x2048,25fps。
制作过程中的挑战 快速移动。记录快速的动作,甚至是物体,要求对光照条件的快速适应。一般来说这用变换度测(conversion measure)和生产时有限的时间花费是不可能实现的。Volucap使用一种可编程的光照系统,使得光照模板能够通过几个按键来载入。

给演员重新打光 为了将演员在后续自然地嵌入虚拟场景,需要有调整光照的灵活度。例如,在拍摄的时候如果不知道3D场景最终的光照强度,或者对于某些服装或动作需要有一定的光照设置。我们建立了一些简单的方法来解决这个问题(文章貌似没说怎么解决)。
跑步机 采集环境直径只有3m,如果不做修正的话会有一些动作无法采集,比如沿着一条道路跑。可以用一台跑步机来解决。

3. 总结思考
本文主要讲了该公司所设计的一个体视频采集环境的工作流程,以及遇到的一些问题和解决方法,他们的体感视频采集主要是用做AR/VR环境,可以在Unity或Unreal整合入一些背景。
从图片看,采集环境整体颜色为白色,便于后续处理,有几对黑点,应该是文章所说的16个立体像对(stereo pair),放的是摄像头。照明系统很厉害,不仅实现完全无阴影的漫射照明,而且还有可编程快速载入的光照模板,用来捕捉快速运动的对象,还具有一定光照灵活度(这部分文章没说清楚是怎么做的)。
采集流程包括:摄像头色彩校对(16x2个摄像头),色差键控(用来更好地区分前景背景之类,用了高饱和度),深度估计(IPSweep算法,文献3和4),3D数据融合,3D点云构成,网格后处理(把数据转化成CGI形式),网格缩减(适应目标设备和受感区域如脸),网格编码(音频视频分别编码,多路传输),网格流(用网格注册方法),导入AR/VR应用。
网格与CGI的关系、为什么要用网格的问题我并不明白,缺乏相关基础。网格注册(mesh registration)的具体步骤也是没领会到什么内涵。这需要进一步学习才能领会。Unity和Unreal也需要花一些功夫。
该公司对光照系统的重视程度之高,令人震惊。他们认为可快速调节的光照有利于捕捉快速移动的物体,这一点我体会并不深,可能是经验还太少,我感觉打一些额外的光可能有用,但是更应该依赖高帧率的采集来实现,所谓快速调节的光照和模板,只是加快了采集,省去了改变灯光照射的时间。加跑步机的方法,后续还需要一些工作来抠掉跑步机,其实也比较麻烦,容易引入一些误差,莫不如把拍摄环境的底盘就设计成可转动的呢。文章没说怎样在拍摄完后还能保持光照的灵活性,我认为就改变对比度之类的就可以了,就是比较简单的方法了,不知道具体作者是怎么做的。
4. 文词珠玉
overview description 整体描述
full 360 degree acquisition 360°全方位采集
be equipped with 装备着…
mount 安装
workflow 工作流程
allow for 考虑,顾忌
asset into 注入,投入
at the stage of 从…的角度看
normally 一般而言
五、State-of-Art of Extended Reality in 5G Networks 5G网络中目前最好的扩展现实
1. 背景动机
AR和VR在媒体工业界都有很大的重要性,但是市场整体对VR的接受度并没有预期高,业界的正在AR方向发力,认为AR在未来会比VR更有前景。AR在手机上的应用也比VR更广。AR的爆发一方面是由于最近移动技术的发展,另一方面是5G网络的保障。5G作为无线交流的基础设施,将能够满足扩展显示(XR)对带宽和低延迟的需求。本文涵盖了与基于5G网络的XR系统关的一些例子,建筑(architectural),协议和代码领域,及其在3GPP和MPEG标准化组织中的state-of-the-art。
所谓扩展现实指的是通过计算机技术与可穿戴设备实现的环境与人机交互的虚实结合,包括增强现实,混合现实,虚拟现实等。将XR整合入网络的话,需要考虑一些不同的领域,包括应用数据下载大小 (GBs),流沉浸式场景(10Mbps)等。
2. 基于5G的扩展现实案例
这部分主要谈3GPP考虑的一些基于5G的XR案例。
流(streaming) 典型的流媒体体验可以用场景中的6DoF的容量来提高。6DoF动作和交互可以通过改变场景中内的视角和头盔显示器与头的移动来实现。用户的情绪反应(包括面部表情,眼动,信条,生理数据等)可以通过身体传感器在观看时收集,个性化的故事线可以根据情绪类别创建。流的播放可以通过AR眼镜或室内的的某一面墙来实现。几个同时在场的用户也可以交互。本应用依赖于体视频和6DoF采集系统。
游戏 多玩家的VR游戏可以让不同地的玩家在同一空间游戏。交互和视频质量(至少60fps,8K分辨率)非常重要。玩家可以通过使用控制器或移动来改变游戏中的位置。游戏观众应该能够有两种视角:玩家视角或观众视角。观众和玩家的交互也是可以做设想的。本应用中,编码,渲染,标准传感器接口等对于多平台是有效的,低延迟是必须的。
实时3D交流 视频聊天可以通过头部3D模型来捕捉,接受方可以做一些旋转。多方VR会议支持在360°视频中与会者的混合表现,使用预先设定的会议背景。一些与会者可能覆盖在AR表演上。创建一个虚拟会议空间,参与者的替身可以移动或与其他替身交互。远程与会者使用HMD,音频是双声道或空间渲染过的。目前的3GPP标准需要被扩展以支持动态3D物体,空间音频,和6DoF框架,多设备媒体同步,以网络为基础的媒体处理功能,背景迁移,HMD替换等。
工业服务 例如远程指导。需要有AR眼镜,远程助理指导一个本地人维修工业机器。这个远程助理可以实时通过本地人的AR眼镜来观看。部分指导可以直接发到AR眼镜上。
信息收发(messaging) 目前的MMS服务可以扩展到支持3D图形信息。这是通过装备了深度摄像头采集3D图形的设备来实现的。需要制定一些关于网格、点云、深度层图的标准。
其他应用包括训练(可能是最大的市场),自动化(工程,设计,销售),位置为基础的娱乐,数字模型,3D全息展示,自驾车中的游客娱乐,医疗,数据可视化等等。
3. 基于5G的扩展现实的技术
这部分主要讲如何在体视频数据的帮助下演示3D虚拟媒体,以及XR的一般结构。
XR应用重要的一部分就是把3D沉浸式媒体和体视频演示,增强或混合入真实环境,其中关键的一步就是用场景和物体的3D表达来实现6DoF体验。目前此类内容存储和传输最相关的格式有:
PLY格式 用一系列头顶,面部或其他元素及其关联属性描述3D物体。一个PLY文件描述一个3D物体,3D物体可以是合成的也可以是从真实场景捕捉的。关联属性包括颜色,曲面法线,纹理坐标和透明度等等。
OBJ格式 是一种表示渲染器命令集的文本格式。命令分别用不同行表示,空行表示终止。每行第一个字母表示命令类型。
USD(Universal Sense Description) 由Pixar开发并已开源,目的是为视觉效果行业提供跨平台图像格式。USD提供了图像的多文件来实现场景分割和合成,其关键特点是可以平行处理场景。
gITF 2.0 一种新的场景表达标准,用JSON表达以方便网页背景合成。该标准特点是冗余较少,可以在相同场景中给不同物体提出有效的索引。
Open Scene Graph(OSG) 是一套可以提供场景图像的库,但同时也允许定制场景图像处理的扩展。
业界并没有统一的共用的文件格式,引出需要更多对齐和标准化工作。
为了捕捉3D场景和物体(包括体视频和点云数据),存在一些体态的捕捉方案提供者:
Volucap 即第四篇文章的内容和作者单位。捕捉环境直径3m,高6m,有32个高分辨率摄像机。捕捉到的数据每分钟有2TB,可以最终处理转化成3D数据。
4DView 捕捉环境直径3m,高2.4m,帧率60fps,每个视频的每分钟需要处理10小时。
微软Mixed Reality Capture 有多个部署。最近的部署在Culver City,3m直径,106个摄像头(53个RGB,53个红外),采集结果是一个包含网格信息和纹理图像的mp4文件。
Intel Studios 900平米场地,96个高分辨率摄像机。采集到的数据通过光纤光缆传输,速度达到6TB/min,用包含90个处理单元的服务器场来创建体视频数据。
8i 有多个采集环境,一个是2.5x2.2m,一个是1.5x2m的便携舞台,各装备有30个采集摄像机。一个本地处理场来创建最终的体视频流,点云,MP4流等等。
Jaunt XR-Cast 使用6个Intel real-sense来捕捉较小的区域,需要的硬件较差,分辨率也较差。
一种有前途的代表体媒体的格式是点云,由于点云有高的空间分辨率。MPEG证明了编码动态3D点云在客观和主观质量上都很好。Video-based Point Cloud Compression (V-PCC)的一种优势就是依赖于商业上可获得的2D视频编码标准和技术,VPCC因此可以方便地应用于当前的硬件。Geometry-based PCC(G-PCC)由MPEG推动,把点云存储在八叉树结构上,是一种更复杂的加工编码形式。
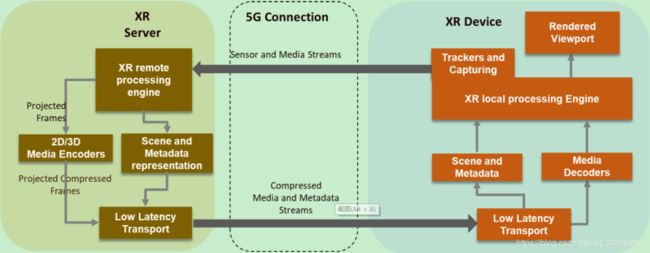
文章认为仍然需要一种新的结构来促进完全的端到端管道,下图是一种3GPP正在讨论的广义XR分布计算结构,3D渲染是其一个重要亮点,或者在用户的直接视角,或者转化为简单形式在设备中处理。渲染是基于动作姿态的本地纠正来做的。图像工作负载被分为XR服务器上的渲染负载,和设备上的简单渲染,有利于移动和脱机XR设备。该设计还需要更多讨论和分析改进。
4. 基于5G的扩展现实标准
2016年MPEG发起了“沉浸式媒体的编码表示”项目,称为MPEG-1,期望其能带来交互沉浸式媒体服务领域的变革。在此标准下发展出了一些技术和因素,包括:沉浸式媒体架构(现在的架构开始关注分布式渲染,提取媒体功能和要求,把网络化与压缩后的媒体整合入6DoF等),全向媒体格式(OMAF,最早是联合利用MPEG压缩,与存储归档文件设计,目前关注于多视角6DoF,镶边或覆盖图,以及提高视口自适应的流),通用视频编码(VVC,显著提高了高分辨率视频压缩效率,仍被期望为沉浸式媒体信号编码提供更多支持,HEVC覆盖概念被期望能提高灵活度来允许同一场景下不同物体的编码),沉浸式音频编码(IAC,支持丰富、沉浸式、高交互度的音频),点云编码(点云容易采集和渲染,MPEG提出了VPCC和GPCC可以用于压缩点云),基于网络的媒体处理(定义一个框架在网络中来描述、部署、控制媒体处理)。还有一些比如6DoF视频表示与压缩还在讨论中,传统MPEG技术和MP5文件格式、DASH流也进行了提高以支持体视频媒体存储与传输。
在3GPP(第三代移动通讯合作计划)中,有以下沉浸式服务相关标准:沉浸式音频服务(IVAS,用于口语音频、多流电视会话、VR会话、用户生成的实时或非实时流),QoE度量(QoE Metrics,用于度量设备容量与延迟),用于远程终端的沉浸式电视会话与网真(ITT4RT,用于引入沉浸式媒体来支持对话服务),5G媒体流框架(用于提供流服务包括边界计算的框架)。
最终,Khronos集团提出了一种重要的方案来统一设备功能和API,OpenXR (跨平台,便携,虚拟现实)定义了AR/VR应用的接口。OpenXR 0.90与2019年3月发布,定义了两种级别的API接口:APP和引擎使用标准接口来做继承并驱动设备,设备可以自我整合到标准驱动接口上;标准化的硬件软件相互作用以减少破碎,实行细节仍保持开发以鼓励创新。
为了支持浏览器上的沉浸式体验,网页XR设备API规范由W3C发展起来。
5. 总结感受
本文讲了许多机遇5G网络的XR系统的案例,结构,技术,实践和标准,内容比较杂,有综述和科普性质。一个直观印象就是OpenXR很重要,很关键。
谈到各类体视频采集工作室时,感觉用6台realsense搭建的Jaunt XR-Cast值得多研究一下,相比起其他的应该更好复现一些。
从文章内容来看,我感觉5G最大的作用就是在带宽和低延迟方面带来的提升,其他提升文章貌似没有讲到。
6. 文词珠玉
retain importance in 在…中保持重要性
overall market adoption 市场的整体接受度
shift towards 转向…
be foreseen as 被预见为
explosion 爆发式的发展
take into account 考虑
co-located 同位的,同地协作的
with the goal of 目的是
enable 使成为可能
with the objective to 目标是,用于
六、总结
这几篇文章都和AR/VR有关,描绘了该领域的前景和现状,以及业界关注的主要技术手段和思路。有一些公共的关键词如深度估计,3D点云,场景融合,3D模型、视频/音频编码、网格等等。但是所讲的大部分东西都不是很实在,个人难以复现,只能有一个直观的大致的印象。深度估计、3D点云、编码、网格相关方法这样的工作是比较适合个人来研究的,也是非常重要的。有一些工具比如Unity,Unreal,Python-Blender也需要学习了解。这几篇文章写作风格都不合常规,综述性质都很强,专业性也很强,个人很难写或者发表这样的文章,想具体发表相关论文还需要研究其他更加具体而微的文章和算法。现在宜抓一个小方向,如深度估计、编码/3D点云/网格的某一个小分支,去做更深入的研究。
不只Kinect V2,我也有过Intel Realsense SR300的使用经验,也玩过HoLolens和XBox上的体感游戏,和一些VR游戏,对这些文章所说的内容有过部分直接体验。VR/AR的未来在哪里,能不能像智能手机一样真正改变人们的生活,前景确实很美好,却还需要更多技术进步呀。