node.js文件读写-fs,Stream文件流
文件读写——fs
-
nodejs文档里api一大堆,该怎么选择呢?我这里挑选了几个常用的出来。
-
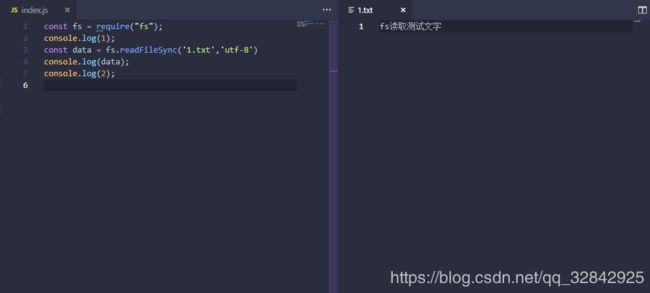
案例说明:当前目录下有index.js和1.txt两个文件
-
fs 模块提供了一些 API,用于以一种类似标准 POSIX 函数的方式与文件系统进行交互。
const fs = require('fs');
- 异步形式的最后一个参数都是完成时回调函数。 传给回调函数的参数取决于具体方法,但回调函数的第一个参数都会保留给异常。 如果操作成功完成,则第一个参数会是 null 或 undefined。
const fs = require('fs');
fs.unlink('/tmp/hello', (err) => {
if (err) throw err;
console.log('成功删除 /tmp/hello');
});
- 当使用同步操作时,任何异常都会被立即抛出,可以使用 try/catch 来处理异常,或让异常向上冒泡。
const fs = require('fs');
try {
fs.unlinkSync('/tmp/hello');
console.log('successfully deleted /tmp/hello');
} catch (err) {
// handle the error
}
异步的文件读取
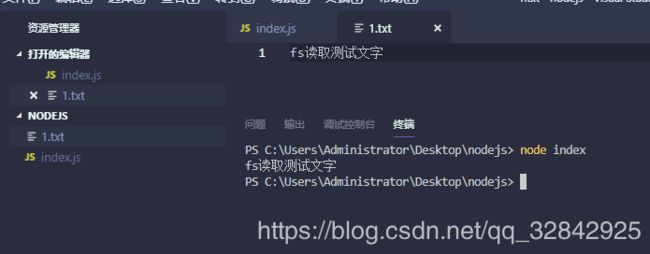
- 我们先读取一下这个文件:
const fs = require("fs");
fs.readFile("./1.txt",(err,data)=>{
console.log(data);
})

我们怎么知道它正确读取到了呢?一堆16进制的buffer.
readFile接收三个参数,必选参数:路径,可选参数:编码,必选参数:回调函数。
const fs = require("fs");
fs.readFile("./1.txt","utf-8",(err,data)=>{
console.log(data);
})
- 注意两个异步不能相干:
const fs = require("fs");
const fn = async () => {
const data = await new Promise((resovle,reject) => {
fs.readFile('1.txt','utf-8',(err,data) => {
if(err) return reject(err)
resovle(data)
})
})
console.log(data,111);
}
console.log(1);
console.log(fn(),222);
console.log(2);
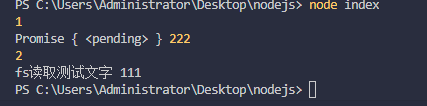
显然异步读取数据不能这样做,人家本身就是异步的,你还拿异步的去取,肯定靠天吃饭啦。
想要准确的拿数据,还是得遵守async函数的规则,乖乖在它的怀抱下等待。
同步的文件读取
- fs.readFileSync(‘路径’,‘编码’)
const fs = require("fs");
console.log(1);
const data = fs.readFileSync('1.txt','utf-8')
console.log(data);
console.log(2);
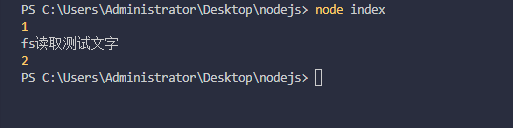
很愉快的读取到数据,因为是同步,所以后面的代码必须等待前面读取文件成功才能继续执行。如果文件非常大,所以还是乖乖异步吧!
异步的写文件
fs.writeFile(file, data[, options])
- fs.writeFile,第一个参数为路径和文件,第二个参数为写入的数据,第三个会回执消息,如果没有错误会返回null:
如果你把1.txt删了或者路径下没有这个文件的话会自动创建文件
const fs = require("fs");
console.log(1);
const data = '写入测试文字'
fs.writeFile('1.txt',data,res=>{
console.log(res,11111);
})
console.log(2);
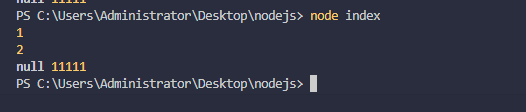
但是如果仅是这样的话,会把原来的文字覆盖。
同步的写文件
fs.writeFileSync(file, data[, options])
const fs = require("fs");
console.log(1);
const data = '写入测试文字'
fs.writeFileSync('1.txt', data, res => {
console.log(res, 11111);
})
console.log(2);

因为这个写函数如果没有对应文件会自己新建,所以想报错还真的很难!暂时没有错误示例!
open,打开文件
fs.open(path, flags[, mode], callback)
四个参数,mode是默认的:
- path
- flags
- mode
- callback
- err
- fd
- err
具体的参数:
flags 可以是:
-
‘r’ - 以读取模式打开文件。如果文件不存在则发生异常。
-
‘r+’ - 以读写模式打开文件。如果文件不存在则发生异常。
-
‘rs+’ - 以同步读写模式打开文件。命令操作系统绕过本地文件系统缓存。
这对 NFS 挂载模式下打开文件很有用,因为它可以让你跳过潜在的旧本地缓存。 它对 I/O 的性能有明显的影响,所以除非需要,否则不要使用此标志。
注意,这不会使 fs.open() 进入同步阻塞调用。 如果那是你想要的,则应该使用 fs.openSync()。
-
‘w’ - 以写入模式打开文件。文件会被创建(如果文件不存在)或截断(如果文件存在)。
-
‘wx’ - 类似 ‘w’,但如果 path 存在,则失败。
-
‘w+’ - 以读写模式打开文件。文件会被创建(如果文件不存在)或截断(如果文件存在)。
-
‘wx+’ - 类似 ‘w+’,但如果 path 存在,则失败。
-
‘a’ - 以追加模式打开文件。如果文件不存在,则会被创建。
-
‘ax’ - 类似于 ‘a’,但如果 path 存在,则失败。
-
‘a+’ - 以读取和追加模式打开文件。如果文件不存在,则会被创建。
-
‘ax+’ - 类似于 ‘a+’,但如果 path 存在,则失败。
mode 可设置文件模式(权限和 sticky 位),但只有当文件被创建时才有效。默认为 0o666,可读写。
- 该回调有两个参数 (err, fd)。
特有的标志 ‘x’(在 open(2) 中的 O_EXCL 标志)确保 path 是新创建的。 在 POSIX 操作系统中,path 会被视为存在,即使是一个链接到一个不存在的文件的符号。 该特有的标志有可能在网络文件系统中无法使用。
flags 也可以是一个数字,[open(2)] 文档中有描述; 常用的常量可从 fs.constants 获取。 在 Windows 系统中,标志会被转换为与它等同的替代者,例如,O_WRONLY 转换为 FILE_GENERIC_WRITE、或 O_EXCL|O_CREAT 转换为 CREATE_NEW,通过 CreateFileW 接受。
在 Linux 中,当文件以追加模式打开时,定位的写入不起作用。 内核会忽略位置参数,并总是附加数据到文件的末尾。
callback[err,fa]
-
失败就不说了,读取成功后,fd将是读取文件中read方法的第一个参数,这个参数代表指定的文件。
-
注意:fs.open() 某些标志的行为是与平台相关的。 因此,在 macOS 和 Linux 下用 ‘a+’ 标志打开一个目录(见下面的例子),会返回一个错误。 与此相反,在 Windows 和 FreeBSD,则会返回一个文件描述符。
// macOS 与 Linux
fs.open('' , 'a+', (err, fd) => {
// => [Error: EISDIR: illegal operation on a directory, open ]
});
// Windows 与 FreeBSD
fs.open('' , 'a+', (err, fd) => {
// => null, fs.read读文件,基于open
参数
- fd
- buffer
- offset
- length
- position
- callback
- err
- bytesRead
- buffer
- err
参数的值
-
从 fd 指定的文件中读取数据。
-
buffer 是数据将被写入到的 buffer。
-
offset 是 buffer 中开始写入的偏移量。
-
length 是一个整数,指定要读取的字节数。
position 指定从文件中开始读取的位置。 如果 position 为 null,则数据从当前文件读取位置开始读取,且文件读取位置会被更新。 如果 position 为一个整数,则文件读取位置保持不变。
回调有三个参数 (err, bytesRead, buffer)。
如果调用该方法的 util.promisify() 版本,将会返回一个包含 bytesRead 和 buffer 属性的 Promise。
例子:
- 使用read要和open结合在一起,通过open返回的fd指定文件拿到要读取的目标!
- 注意nodejs的buffer已经废弃了很多api!
var fs = require('fs');
fs.open('./1.txt', 'r', function (err, fd) {
if(err) throw err
//buf根据你的需要设定每次的读取长度
var buf = new Buffer.alloc(225);
//读取fd文件内容到buf缓存区,如果position设置为null就会从最开始的地方开始读
fs.read(fd, buf, 0, 20, null, function (err, bytesRead, buffer) {
console.log(buf.slice(0, bytesRead).toString());
console.log(buf);
});
});
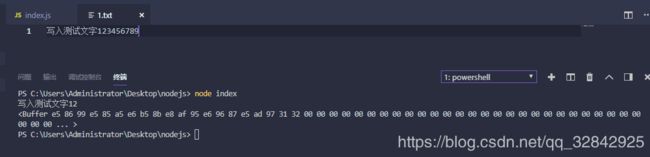
fs.write写文件,基于open
参数
- fd
- buffer
- offset
- length
- position
- callback
- err
- bytesWritten
- buffer
- err
参数的值
-
写入 buffer 到 fd 指定的文件。
-
offset 决定 buffer 中被写入的部分,length 是一个整数,指定要写入的字节数。
-
position 指向从文件开始写入数据的位置的偏移量。 如果 typeof position !== ‘number’,则数据从当前位置写入。详见 pwrite(2)。
-
回调有三个参数 (err, bytesWritten, buffer),其中 bytesWritten 指定从 buffer 写入了多少字节。
-
如果以 util.promisify() 的形式调用该方法,则会返回包含 bytesWritten 和 buffer 属性的 Promise 的对象。
-
注意,多次对同一文件使用 fs.write 且不等待回调,是不安全的。 对于这种情况,强烈推荐使用 fs.createWriteStream。
在 Linux 上,当文件以追加模式打开时,指定位置的写入是不起作用的。 内核会忽略位置参数,并总是将数据追加到文件的末尾。
例子
var fs = require('fs');
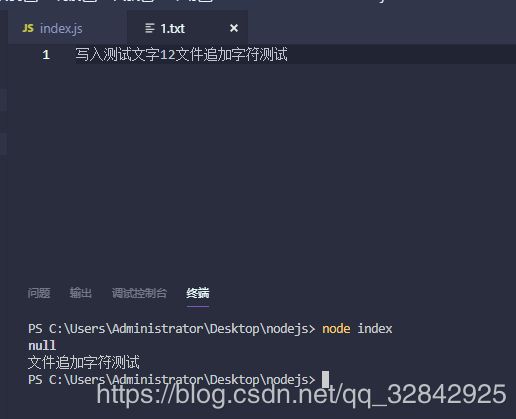
fs.open('./1.txt', 'r+', function (err, fd) {
if(err) throw err
fs.write(fd, '文件追加字符测试', 20, 'utf-8', (err, written, buffer)=>{
console.log(err);
console.log(buffer);
})
});
写入前,别眨眼:
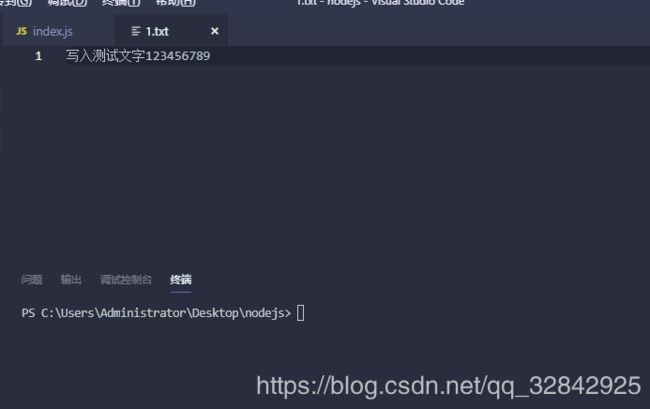
写入后的结果,写入位置20,打印err,空,打印buffer,刚才写入的字符串!
- 提升:位置和数据的写入和读取就是各位通过逻辑来控制的了!
文件流Stream
- 想象一下,如果把文件读取比作向一个池子里抽水,同步会阻塞程序,异步会等待结果,如果这个池子特别大怎么办?有三峡水库那么大怎么办?你要等到多久才能喝到抽的水?
- 因此便会有了文件流,文件流就好比你一边抽一边取,不用等池子满了再用一样方便。
- 因为流在文件读写里非常抽象,所以并不能明显确定,只能勉强通过一些特征表示;
- fs继承于Stream;
读取流例子
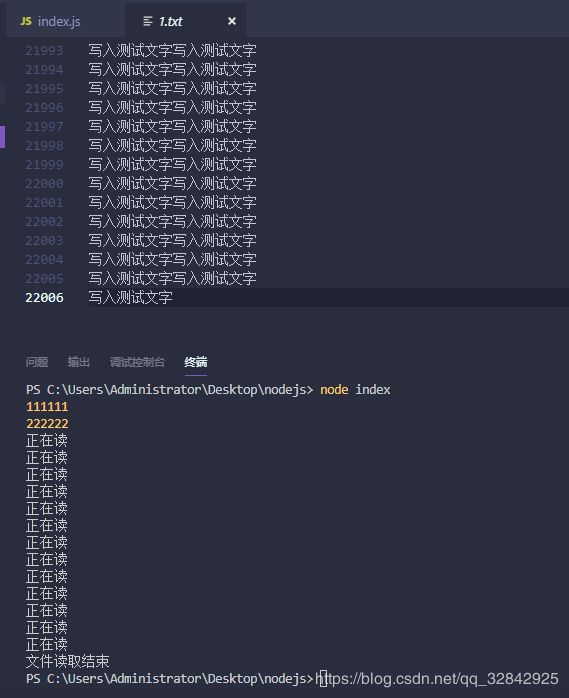
const fs = require("fs");
console.log(111111);
const read = fs.createReadStream('1.txt')
read.setEncoding('utf-8')
read.resume();//让文件流开始'流'动起来
read.on('data',data =>{//监听读取的数据,如果打印data就是文件的内容
console.log('正在读');
})
read.on('end', () => { //监听状态
console.log('文件读取结束');
})
console.log(222222);
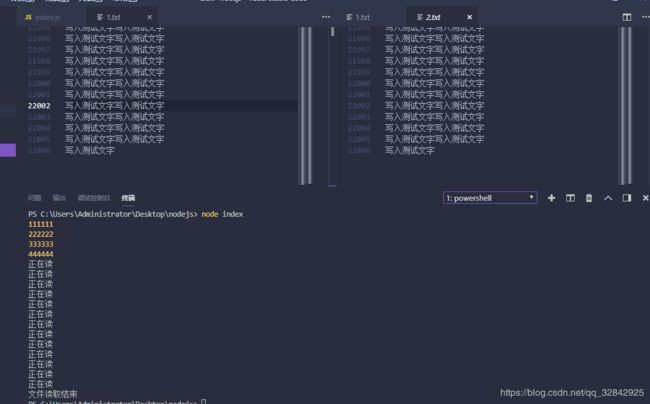
我这里准备了2万+行的数据,监听的data打印了多少次就说明被流监听了多少次,期间就可以使用多少次这个数据,用于一些超大型的数据读取还是非常有效的。
写入流
const fs = require("fs");
console.log(111111);
const read = fs.createReadStream('1.txt')
read.setEncoding('utf-8')
read.resume();//让文件流开始'流'动起来
read.on('data',data =>{
console.log('正在读');
})
read.on('end', () => { //监听状态
console.log('文件读取结束');
})
console.log(222222);
console.log(333333);
const write = fs.createWriteStream('2.txt')
read.pipe(write) //pipe就是那根水管,抽向2.txt
console.log(444444);
如果你自己测试的时候看着2.txt的行数在飞涨,会更加直观!