大数据入门(五)windows上搭建单机版Hadoop2.8(踩坑记录)
目录
- 安装jdk
- 1、下载jdk的包并安装
- 2、配置环境变量
- 3、验证
- Hadoop安装和配置
- 1、下载Hadoop包及安装
- 2、环境变量配置
- Hadoop的文件修改
- 1、core-site.xml
- 2、mapred-site.xml(hadoop2.8.5将mapred-site.xml.template重命名为mapred-site.xml)
- 3、hdfs-site.xml
- 4、yarn-site.xml
- 5、hadoop-env.cmd
- 启动Hadoop
- 查看状态的网址
- JDK路径带空格问题的解决方法
- 参考
系列:
大数据入门(一)环境搭建,VMware15+CentOS8.1 配置
https://blog.csdn.net/qq_34391511/article/details/104874044
大数据入门(二)Centos8,JDK 配置
https://blog.csdn.net/qq_34391511/article/details/104893587
大数据入门(三)CentOS 网络配置
https://blog.csdn.net/qq_34391511/article/details/104895498
大数据入门(四)Hadoop 集群搭建
https://blog.csdn.net/qq_34391511/article/details/104885278
大数据入门(五)windows 上搭建单机版 Hadoop2.8(踩坑记录)
https://blog.csdn.net/qq_34391511/article/details/104948319
大数据入门(六)win10 对 Hadoop hdfs 的基本操作
https://blog.csdn.net/qq_34391511/article/details/105070955
大数据入门(七)win10 上 eclipse 使用 Hadoop 的配置
https://blog.csdn.net/qq_34391511/article/details/105066667
大数据入门(八)win10 下的 wordcount
https://blog.csdn.net/qq_34391511/article/details/105073076
大数据入门(九)基于 win10 的 Hadoop,java 代码进行 hdfs 操作
https://blog.csdn.net/qq_34391511/article/details/105145380
liunx单机安装参考:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html#Standalone_Operation
安装jdk
1、下载jdk的包并安装
友情提示:jdk安装路径不要带空格!!!!
我选择的是jdk1.8;
官网上下载:
按提示安装,配置好环境变量

2、配置环境变量
新建变量:JAVA_HOME
对应的值是其安装路径
如果路径带空格,参考下面的填坑记录
新建变量:CLASSPATH
值:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
双击“path”新建添加%JAVA_HOME%\bin,完成,确定即可,注意这里不要置顶,因为带“%”的放到了环境变量path的最前面,导致“环境变量path”变成了“系统/用户变量path”。如果为了让优先级高一点,就放到前面一点就可以了。如果出现问题,解决方法可参考:win10解决环境变量变成系统/用户变量的方法
3、验证

如果失败,参考:https://jingyan.baidu.com/album/36d6ed1f602f8c1bcf4883ed.html?picindex=4
Hadoop安装和配置
1、下载Hadoop包及安装
我选择的是2.8版本的Hadoop,解压缩即可。下载:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
另外还需要下载winutils:https://github.com/steveloughran/winutils
找到相应版本,用里面的bin去替代Hadoop文件里面的bin,原因:Hadoop不支持win,需要改一下
2、环境变量配置
系统环境变量里面新建“HADOOP_HOME”;值为其路径,我的是:D:\Learning\Hadoop\hadoop-2.8.5
“系统环境变量”的“path”(位置参考jdk的环境配置)里添加:%HADOOP_HOME%\bin 、 %HADOOP_HOME%\sbin
#打开cmd:
#测试
hadoop
hadoop -version

Hadoop的文件修改
文件所在路径:D:\Learning\Hadoop\hadoop-2.8.5\etc\hadoop(注意是:etc下的hadoop),把以下内容替代掉对应的文件全部内容就行,另外需要注意core-site.xml、hdfs-site.xml这两个在修改的时候有对应路径的修改,需要提前建好文件夹,路径自己设定,如果是别的版本,不替代的话,只需要在相应的
1、core-site.xml
hadoop.tmp.dir
/D:/Learning/Hadoop/hadoop-2.8.5/workspace/tmp
dfs.name.dir
/D:/Learning/Hadoop/hadoop-2.8.5/workspace/name
fs.default.name
hdfs://localhost:9000
2、mapred-site.xml(hadoop2.8.5将mapred-site.xml.template重命名为mapred-site.xml)
mapreduce.framework.name
yarn
mapred.job.tracker
hdfs://localhost:9001
3、hdfs-site.xml
dfs.replication
1
dfs.data.dir
/D:/Learning/Hadoop/hadoop-2.8.5/workspace/data
4、yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
5、hadoop-env.cmd
修改set JAVA_HOME=这里填本机的jdk路径,如果jdk路径有空格,参考下面解决方法
启动Hadoop
#打开cmd:
#格式化hdfs
hdfs namenode -format
#到\hadoop-2.8.5\sbin目录下,如果把sbin放到环境变量里面,就不需要到sbin目录下了:
start-all.cmd
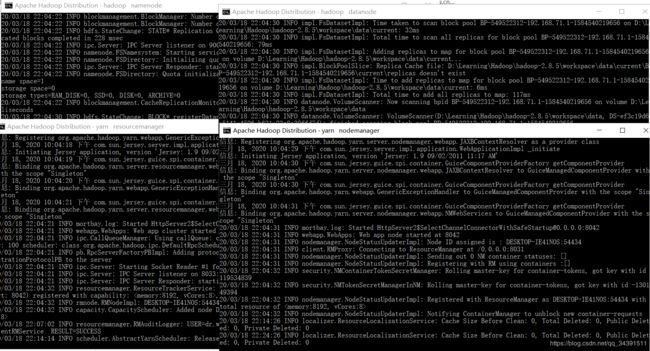
启动成功:

jps查看,每个都需要,才是成功:

下面的图,都是处于运行状态:
若有挂闪或启动失败,则可能的原因及其解决办法:
| 原因 | 解决方法 |
|---|---|
| 使用winutils的替换bin版本不匹配 | 找到合适的版本代替 |
| 前面五个文件配置错误 | 对照,自行重新修改 |
| 9000端口被占用 | 关闭9000端口运行的程序或者重启 |
| 其他 | 看挂闪文件的提示进行相应的修改 |
| 比较偏激的解决方法 | 删除格式化HDFS后在前面新建的文件夹下的内容,然后重新格式化HDFS,再重新启动即可 |
查看状态的网址
查看集群状态:http://localhost:8088
查看Hadoop状态:http://localhost:50070
stop-all.cmd关闭Hadoop
JDK路径带空格问题的解决方法
1、
java -version没有用,直接在环境变量path里面新建,添加jdk的路径:
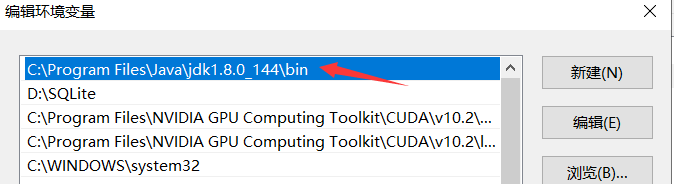
2、
按照提示,修改hadoop-env.cmd文件:
PROGRA~1是 Program Files 目录的dos文件名模式下的缩写 ,必须写成这样的形式

参考
windows上部署hadoop(单机版)
Windows环境下执行hadoop命令出现Error: JAVA_HOME is incorrectly set Please update D:\SoftWare\hadoop-2.6.0\conf\hadoop-env.cmd错误的解决办法(图文详解)
Windows下安装Hadoop2.8.5