TensorFlow2.0 CNN,深度可分离卷积,keras_generator,resnet50迁移学习,BN层(cifar)(chapter06)
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import os
import sys
import time
import sklearn
from tensorflow import keras
import tensorflow as tf
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
2.0.0
sys.version_info(major=3, minor=7, micro=3, releaselevel=‘final’, serial=0)
matplotlib 3.0.3
numpy 1.16.2
pandas 0.24.2
sklearn 0.20.3
tensorflow 2.0.0
tensorflow_core.keras 2.2.4-tf
同样一张图片,如果用DNN训练那参数量很大,若用CNN那么参数将量级减少,CNN一般用来进行图片的训练。
卷积层:卷积核的channel为输入层的channel数,输出的channel数为卷积核数量,(深度可分离卷积的卷积核的channel为1)
BN层:对卷积层的数据标准化(6-12的cifar使用了),作用 防止梯度弥散,加快网络收敛速度,可以使用较大的学习率,可代替其他正则方式,如Dropout,L2正则化。
池化层:一般为2x2大小的filter,channel为1,输出结果的width和height相对于输入时减半,channels不变。作用:减少参数和计算量,防止过拟合
本章节包含:
最基本的CNN: 多个卷积层+DNN:(CONV - CONV - POOL) * n - Flatten - ( Dense(n) - Dense(class_num)) ; 6-5
深度可分离卷积:不同的是 CONV 的改变;6-9 减少计算次数
残差网络:6-11 残差网络描述
; 网络层数过多,loss上升,这是这是退化现象,因为存在梯度消失和梯度爆炸问题。(不是过拟合,过拟合的loss一直减少)
6-5 卷积神经网络
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all),(x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
# 数据归一化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1,1)).reshape(-1, 28, 28,1)
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1,1)).reshape(-1,28,28,1)
x_test_scaled = scaler.transform(
x_test.astype(np.float32).reshape(-1,1)).reshape(-1,28,28,1)
x_train_scaled.shape, y_train.shape
((55000, 28, 28, 1), (55000,))
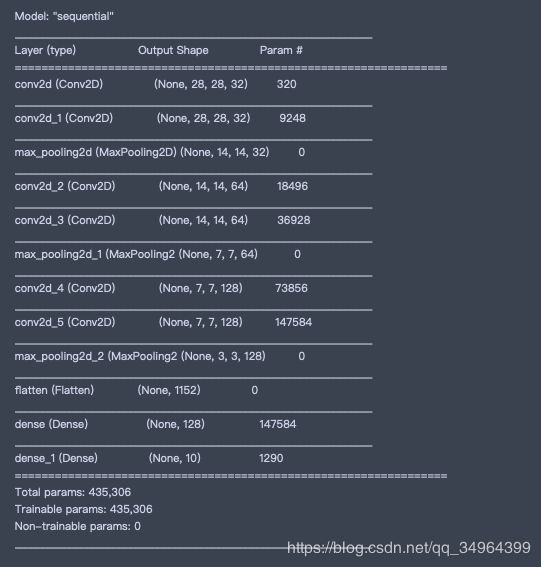
model = keras.models.Sequential()
# kernel_size : filter的size,28*28*1 1表示channel为1,因为这里是灰度图片
model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu', input_shape=(28,28,1)))
model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')) #对应层参数 9248 = (3*3*32+1)*32 每一个filter的参数为3*3*32,这个32是输入层有32个channel,在加上偏置项1,乘以32个过滤器 1
model.add(keras.layers.MaxPool2D(pool_size=2) ) # strides, If None, it will default to `pool_size`, 不需要跟Conv2D卷积核一样需要知道filters,这里是对每一个channel都做pooling,所以结果肯定是输入的channel数
model.add(keras.layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu')) # 经过pool_size=2会缩小一倍,需要filters翻倍保持原来大小
model.add(keras.layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='relu'))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='relu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation='relu'))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss='sparse_categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
model.summary()
# summary output (None,28,28,32)解读
# None: 样本数
# 28,28: 长宽
# 32: channels,由filters指定
callbacks = [
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3)
]
history = model.fit(x_train_scaled, y_train, validation_data=[x_test_scaled, y_test],
epochs=10 )
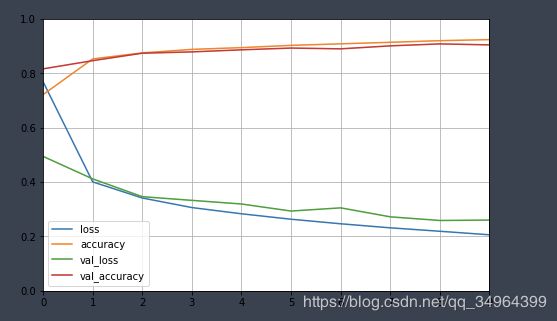
def plot_learning_curving(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curving(history)
# 此时的图形的accuracy在前2次epoch时有些低,可将Conv2D的relu激活函数替换为selu,
# selu的不同是当x<0时激活函数 a = lambda * alpha * (pow(e, z) -1), z为logits,alpha和lambda作者推导出来的
# 该函数特点:1. 存在饱和区(负无穷时,趋于-alpha * lambda) 2. 输入大于0时,激活输出对输入进行了放大
6-7 深度可分离卷积网络
调用SeparableConv2D
# 正常卷积 (12,12,3) -> filter(5,5,3) *256 = (8*8*256) 计算次数 5*5*3*8*8*256=1228800
# 深度可分离卷积,先对每个通道进行卷积后合并 (12,12,3) -> filter(5,5,1) * 3 : get (8,8,3) -> filter(1,1,3) *256 = (8,8,256) 计算次数
# 5*5*8*8*3+ 1*1*3*8*8*256 = 53952 次,说明深度可分离卷积大大减少了运行次数,
model = keras.models.Sequential()
# kernel_size : filter的size,28*28*1 1表示channel为1,因为这里是灰度图片
model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='selu', input_shape=(28,28,1)))
# 输入层为为单通道,先不需要进行深度可分离卷积
model.add(keras.layers.SeparableConv2D(filters=32, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2) )
model.add(keras.layers.SeparableConv2D(filters=64, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=64, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation='selu'))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss='sparse_categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
callbacks = [
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3)
]
history = model.fit(x_train_scaled, y_train, validation_data=[x_test_scaled, y_test],
epochs=1 )
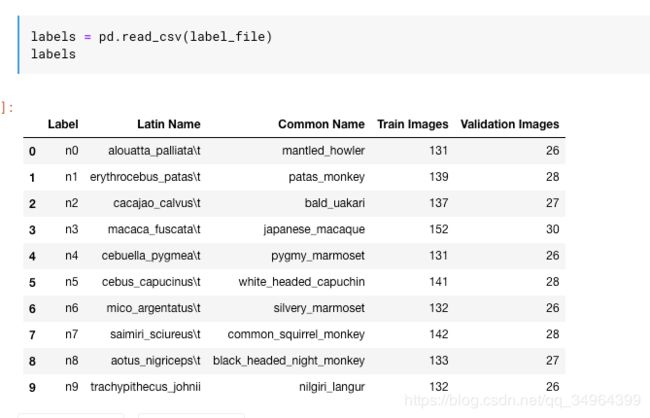
使用10-monkey数据
数据结构
6-9 keras的generator的flow_from_directory读取数据
train_dir = "../input/training/training"
valid_dir = "../input/validation/validation"
label_file = "../input/monkey_label.txt"
height = 128
width = 128
channels = 3
batch_size = 64
num_classes = 10
train_datagen = keras.preprocessing.image.ImageDataGenerator(
rescale = 1./255,
rotation_range = 40, # 将图片随机旋转的角度(-40,40)之间, 目的图片扩增
width_shift_range = 0.2, # 提升图片随机水平偏移的幅度,小数则为百分比,大于1的数则为随机平移像素
height_shift_range = 0.2,
shear_range = 0.2, # x坐标不变y坐标平移 或 y坐标不变x坐标平移
zoom_range = 0.2, # 在长或宽方向上放大
horizontal_flip = True, # 水平旋转
fill_mode = 'nearest' # 放大之后用最近的像素点填充
)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(height, width),
batch_size = batch_size,
seed = 7, # 随机度
shuffle = True,
class_mode="categorical" ) # label的标签为one_hot编码
valid_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
valid_generator = valid_datagen.flow_from_directory(valid_dir, target_size=(height, width),
batch_size = 64,
seed = 7, # 随机度
shuffle = False,
class_mode="categorical") # label的标签为one_hot编码)
train_num = train_generator.samples
valid_num = valid_generator.samples
Found 1098 images belonging to 10 classes.
Found 272 images belonging to 10 classes.
查看数据
x, y = train_generator.next()
6-10 基础模型搭建与训练
model = keras.models.Sequential()
# kernel_size : filter的size,28*28*1 1表示channel为1,因为这里是灰度图片
model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu',
input_shape=(width,height,channels)))
# 输入层为为单通道,先不需要进行深度可分离卷积
model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'))
model.add(keras.layers.MaxPool2D(pool_size=2) )
model.add(keras.layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='relu'))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='relu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation='relu'))
model.add(keras.layers.Dense(num_classes, activation="softmax"))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
epochs = 10
history = model.fit_generator(train_generator,
steps_per_epoch = train_num//batch_size,
epochs = epochs,
validation_data = valid_generator,
validation_steps = valid_num//batch_size)
6-11 resnet50进行迁徙学习
修改标准化preprocessing_function=keras.applications.resnet50.preprocess_input
height = 224
width = 224
channels = 3
batch_size = 24
num_classes = 10
train_datagen = keras.preprocessing.image.ImageDataGenerator(
preprocessing_function = keras.applications.resnet50.preprocess_input, # 归一化到(-1,1)之间
rotation_range = 40, # 将图片随机旋转的角度(-40,40)之间, 目的图片扩增
width_shift_range = 0.2, # 提升图片随机水平偏移的幅度,小数则为百分比,大于1的数则为随机平移像素
height_shift_range = 0.2,
shear_range = 0.2, # x坐标不变y坐标平移 或 y坐标不变x坐标平移
zoom_range = 0.2, # 在长或宽方向上放大
horizontal_flip = True, # 水平旋转
fill_mode = 'nearest' # 放大之后用最近的像素点填充
)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(height, width),
batch_size = batch_size,
seed = 7, # 随机度
shuffle = True,
class_mode="categorical" ) # 输出的label的标签为one_hot编码
valid_datagen = keras.preprocessing.image.ImageDataGenerator(preprocessing_function =
keras.applications.resnet50.preprocess_input)
valid_generator = valid_datagen.flow_from_directory(valid_dir, target_size=(height, width),
batch_size = 64,
seed = 7, # 随机度
shuffle = False,
class_mode="categorical") # label的标签为one_hot编码)
train_num = train_generator.samples
valid_num = valid_generator.samples
使用网上的resnet、
resnet50_fine_tune = keras.models.Sequential()
resnet50_fine_tune.add(keras.applications.ResNet50(include_top = False, # 最后一层默认是1000层,而我们的标签数为10,所以舍弃
pooling = 'avg', # 说是加了这个参数能将最后一层立体层faltten,没懂,pooling后不应该还是一个多维的矩阵吗?
weights = 'imagenet')) # 使用网上已经训练好的imagenet参数
resnet50_fine_tune.add(keras.layers.Dense(num_classes, activation='softmax'))
resnet50_fine_tune.layers[0].trainable = False # 现在网络只有2层,把前面的layer不训练,只训练最后一层,所以较快
resnet50_fine_tune.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
resnet50_fine_tune.summary()
epochs = 10
history = resnet50_fine_tune.fit_generator(train_generator, steps_per_epoch = train_num//batch_size,
epochs = epochs, validation_data = valid_generator,
validation_steps = valid_num//batch_size)
使resnet50的最后几层也能训练
resnet50 = keras.applications.ResNet50(include_top=False, pooling='avg', weights='imagenet')
resnet50.summary()
for layer in resnet50.layers[0:-5]:
layer.trainable = False
resnet50_new = keras.models.Sequential([
resnet50,
keras.layers.Dense(num_classes, activation='softmax')
])
resnet50_new.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
resnet50_new.summary()
epochs = 10
history = resnet50_new.fit_generator(train_generator, steps_per_epoch = train_num//batch_size,
epochs = epochs, validation_data = valid_generator,
validation_steps = valid_num//batch_size)
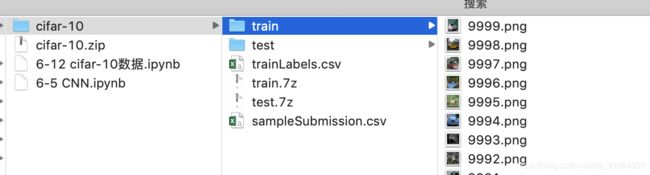
6-12 keras的generator的flow_from_dataframe的读取cifar数据
数据结构
class_names = ['airplane', 'automobile','bird', 'cat','deer','dog', 'frog', 'horse', 'ship', 'truck']
train_labels_file = './cifar-10/trainLabels.csv'
test_csv_file = './cifar-10/sampleSubmission.csv'
train_folder = "./cifar-10/train/"
test_folder = "./cifar-10/test/"
def parse_csv_file(filepath, folder):
results = []
lines = open(filepath).readlines()[1:]
for line in lines:
image_id, label = line.strip().split(",")
image_path = os.path.join(folder, image_id + '.png')
results.append((image_path, label))
return results
train_label_info = parse_csv_file(train_labels_file, train_folder)
test_csv_info = parse_csv_file(test_csv_file, test_folder)
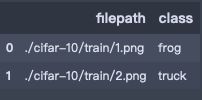
train_dfs = pd.DataFrame(train_label_info, columns=['filepath', 'class'])
test_df = pd.DataFrame(test_csv_info)
train_df = train_dfs[:45000]
valid_df = train_dfs[45000:]
train_df.head(2)
height = 32
width = 32
channels = 3
batch_size = 32
num_classes = 10
train_datagen = keras.preprocessing.image.ImageDataGenerator(
rescale = 1./255,
rotation_range = 40, # 将图片随机旋转的角度(-40,40)之间, 目的图片扩增
width_shift_range = 0.2, # 提升图片随机水平偏移的幅度,小数则为百分比,大于1的数则为随机平移像素
height_shift_range = 0.2,
shear_range = 0.2, # x坐标不变y坐标平移 或 y坐标不变x坐标平移
zoom_range = 0.2, # 在长或宽方向上放大
horizontal_flip = True, # 水平旋转
fill_mode = 'nearest' # 放大之后用最近的像素点填充
)
train_generator = train_datagen.flow_from_dataframe(train_df,
directory = "./",
x_col = 'filepath',
y_col = 'class',
classes = class_names,
target_size = (height, width),
batch_size = batch_size,
seed = 7,
shuffle = True,
class_mode = 'sparse' ) # 输出的label的标签为数字编码
valid_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
valid_generator = valid_datagen.flow_from_dataframe(valid_df,
directory = "./",
x_col = 'filepath',
y_col = 'class',
classes = class_names,
target_size = (height, width),
batch_size = batch_size,
seed = 7,
shuffle = True,
class_mode = 'sparse' ) # 输出的label的标签为数字编码
train_num = train_generator.samples
valid_num = valid_generator.samples
添加BN层可加快运行速度
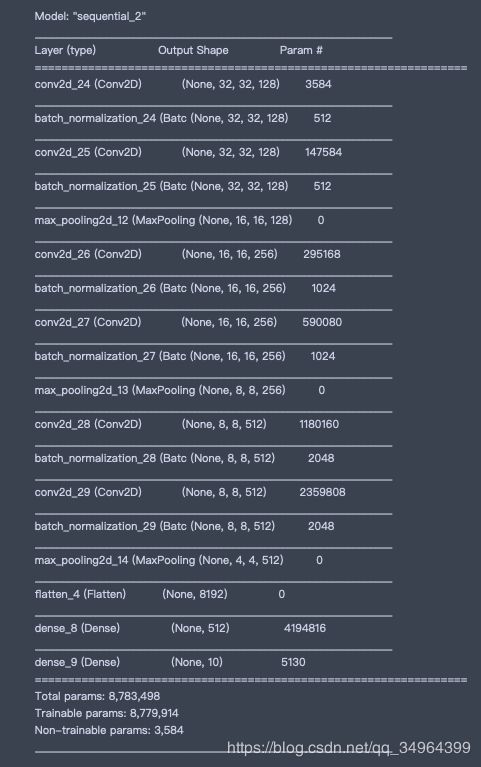
model = keras.models.Sequential([
keras.layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='relu',
input_shape=(width,height,channels)),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.MaxPool2D(pool_size=2) ,
keras.layers.Conv2D(filters=256, kernel_size=3, padding='same', activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(filters=256, kernel_size=3, padding='same', activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Conv2D(filters=512, kernel_size=3, padding='same', activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Conv2D(filters=512, kernel_size=3, padding='same', activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Flatten(),
keras.layers.Dense(512, activation='relu'),
keras.layers.Dense(num_classes, activation="softmax")])
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
epochs = 20
hostory = model.fit_generator(train_generator, steps_per_epoch=train_num// batch_size,
epochs=epochs, validation_data=valid_generator, validation_steps=valid_num//batch_size)
使用测试数据
test_datagen = keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
test_generator = valid_datagen.flow_from_dataframe(test_df,
directory = "./",
x_col = 'filepath',
y_col = 'class',
classes = class_names,
target_size = (height, width),
batch_size = batch_size,
seed = 7,
shuffle = True,
class_mode = 'sparse' ) # 输出的label的标签为数字编码
train_num = train_generator.samples
test_predict = model.predict_generator(test_genrator, workers=10, # 并行度
use_multiprocessing=True # True: 开启多个进程进行workers的并行,Flase:开启多个线程进行workers的并行
)
test_predict_class_indices = np.argmax(test_predict, axis=1)
test_predict_class_indices[:5]
test_predict_class = [class_names[index] for index in test_predict_class_indices]
# 将预测写到sample文件,进入kaggle将sampleSubmission.csv文件点击late submission 提交文件