HBASE双机集群HA-部署
HBASE双机HA-部署
1.1、系统环境初始化
防火墙关闭:
server iptables stop
chkconfig iptables off
selinux关闭:
用户创建:
vim yonghu.txt
hbase hdfs hive impala Impala kudu Kudu spark wxl zookeeper
#!/bin/sh
for i in `cat /root/hadoop-cdh/yonghu.txt`;
do
echo $i
useradd $i
done
免密码登录:其他用户更改root名称XXX
config-ssh-root.sh
#!/bin/sh
expect -c "
spawn ssh-keygen -t rsa
expect {
\".ssh/id_rsa): \" {send \"\r\";exp_continue }
\"Enter passphrase (empty for no passphrase): \" {send \"\r\";exp_continue }
\"Enter same passphrase again: \" {send \"\r\" }
}
expect eof
"
expect -c "
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub zk-master-la01
expect {
yes/no { send \"yes\r\"; exp_continue }
*assword* { send \"pass@word1\r\" }
}
expect {
*assword* { send \"pass@word1\r\" }
}
expect eof
"
expect -c "
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub zk-master-la02
expect {
yes/no { send \"yes\r\"; exp_continue }
*assword* { send \"pass@word1\r\" }
}
expect {
*assword* { send \"pass@word1\r\" }
}
expect eof
"
expect -c "
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub zk-la03
expect {
yes/no { send \"yes\r\"; exp_continue }
*assword* { send \"pass@word1\r\" }
}
expect {
*assword* { send \"pass@word1\r\" }
}
expect eof
"
expect -c "
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub nagios_server
expect {
yes/no { send \"yes\r\"; exp_continue }
*assword* { send \"pass@word1\r\" }
}
expect {
*assword* { send \"pass@word1\r\" }
}
expect eof
"
for slave in $(
do
#ecl=${EXPECT_CMD/remoteHost/$slave}
#echo $ecl
expect -c "
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub $slave
expect {
yes/no { send \"yes\r\"; exp_continue }
*assword* { send \"pass@word1\r\" }
}
expect {
*assword* { send \"pass@word1\r\" }
}
"
done
1.2、zookeeper安装配置:
JDK1.8配置生效
tar -zxvf jdk-8u121-linux-x64.gz -C /usr/local/
vim /home/hadoop/.bash_profile
export JAVA_HOME=/usr/local/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
source /home/hadoop/.bash_profile
zk-master-la01节点操作
tar -zxvf zookeeper-3.4.61.tar.gz –C /usr/local/
cd /usr/local/zookeeper-3.4.6/conf
配置zookeerper文件:
vim zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/data
clientPort=2181
server.1=zk-master-la01:2888:3888
server.2=zk-master-la02:2888:3888
server.3=slave-01:2888:3888
#创建data数据目录
mkdir -p /opt/zookeeper/data/
echo "1" >> /opt/zookeeper/data/myid
#scp分别传输多台节点
vim host.txt
zk-master-la01
zk-master-la02
zk-la03
slave-01
slave-02
for i in `cat /root/host.txt`;do echo $i;scp -r /usr/local/zookeeper-3.4.5-cdh5.10.0 root@$i:/usr/local/zookeeper-3.4.5-cdh5.10.0 ;done
zk-master-la02操作
#注意改下myid 2
mkdir –p /opt/zookeeper/data/
echo "2" >> /opt/zookeeper/data/myid
zk-la03操作
#注意改下myid 3
mkdir -p /opt/zookeeper/data/
echo "3" >> /opt/zookeeper/data/myid
#zk-master-la01操作
/usr/local/zookeeper-3.4.6/bin/zkServer.sh start
/usr/local/zookeeper-3.4.6/bin/zkServer.sh stop
//usr/local/zookeeper-3.4.6/bin/zkServer.sh status
#zk-master-la02操作
/usr/local/zookeeper-3.4.6/bin/zkServer.sh start
#zk-la03操作
/usr/local/zookeeper-3.4.6/bin/zkServer.sh start
1.3、部署hadoop双机HA-namenode
hadoop解压到/usr目录
tar -zxvf hadoop-2.6.0-cdh5.7.5.tar.gz -C /usr/local/
cd /usr/local/hadoop-2.6.0-cdh5.7.5/etc/hadoop
编辑修改内容如下:
vim core-site.xml
vim hdfs-site.xml
Vim mapred-site.xml
Vim yarn-site.xml
cat yarn-env.sh
#如果需要日志目录指定目录需手动更改env日志目录,默认不更改。
export JAVA_HOME=/usr/local/jdk1.8.0_121
export YARN_LOG_DIR=/var-logs/hadoop/logs
cat hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_121
export HADOOP_SSH_OPTS="-p 22"
export HADOOP_LOG_DIR=/var/hadoop/logs
export HADOOP_SECURE_DN_LOG_DIR=$HADOOP_LOG_DIR

Scp 分发节点
vim host.txt
zk-master-la01
zk-master-la02
zk-la03
slave-01
slave-02
for i in `cat /root/host.txt`;do echo $i;scp -r /usr/local/ hadoop-2.6.0-cdh5.7.5 root@$i:/usr/local/ hadoop-2.6.0-cdh5.7.5 ;done
hdfs启动命令
注意首次初始化启动命令和之后启动的命令是不同的,首次启动比较复杂,步骤不对的话就会报错,不过之后就好了
首次启动命令
1、首先启动各个节点的Zookeeper,在各个节点上执行以下命令:
bin/zkServer.sh start
2、在某一个namenode节点执行如下命令,创建命名空间
hdfs zkfc -formatZK
3、在每个journalnode节点用如下命令启动journalnode
sbin/hadoop-daemon.sh start journalnode
4、在主namenode节点用格式化namenode和journalnode目录
hdfs namenode -format ns
5、在主namenode节点启动namenode进程
sbin/hadoop-daemon.sh start namenode
6、在备namenode节点执行第一行命令,这个是把备namenode节点的目录格式化并把元数据从主namenode节点copy过来,并且这个命令不会把journalnode目录再格式化了!然后用第二个命令启动备namenode进程!
hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
7、在两个namenode节点都执行以下命令
sbin/hadoop-daemon.sh start zkfc
8、在所有datanode节点都执行以下命令启动datanode
sbin/hadoop-daemon.sh start datanode
9、在两个namenode节点都执行以下命令
yarn-daemon.sh start resourcemanager
10、在所有datanode节点都执行以下命令启动
yarn-daemon.sh start nodemanager
日常启停命令
sbin/start-dfs.sh
sbin/stop-dfs.sh
验证
首先在浏览器分别打开两个节点的namenode状态,其中一个显示active,另一个显示standby
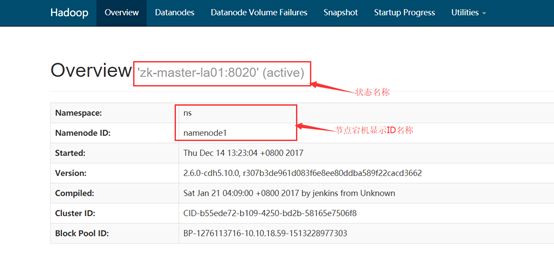

然后在active所在的namenode节点执行jps,杀掉相应的namenode进程

前面standby所对应的namenode变成active
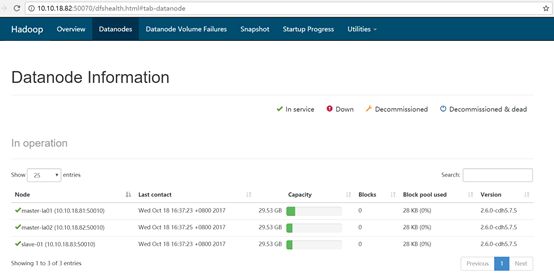
1.4、Hbase双机Hmaster安装
解压至安装目录下
tar -zxvf hbase-1.2.0-cdh5.7.5.tar.gz -C /usr/local/
chown -R hbase:hbase /usr/local/hbase-1.2.0-cdh5.7.5
编辑环境变量并使其生效
Note:这一步在 HBase 集群中的所有节点上都完成
vim /home/hadoop/.bash_profile
添加如下:
export JAVA_HOME=/usr/local/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop-2.6.0-cdh5.7.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export zk=/usr/local/zookeeper-3.4.5-cdh5.7.5
export PATH=$PATH:$zk/bin
export HBASE_HOME=/usr/local/hbase-1.2.0-cdh5.7.5
export PATH=$PATH:$HBASE_HOME/bin
最后环境变量生效:
source /home/hadoop/.bash_profile
编辑配置更改内容
vim /usr/local/hbase-1.2.0-cdh5.7.5/conf/hbase-env.sh
添加如下:
export JAVA_HOME=/usr/local/jdk1.8.0_121
export HBASE_CLASSPATH=/usr/local/hadoop-2.6.0-cdh5.7.5/etc/hadoop
export HBASE_HEAPSIZE=4000
export HBASE_LOG_DIR=/var/hadoop/hbase/logs
export HBASE_MANAGES_ZK=false
其中JAVA_HOME 和 HBASE_CLASSPATH 根据实际情况进行配置
HBASE_HEAPSIZE 的大小根据你的集群配置,默认是 1000
HBASE_LOG_DIR 是 HBase 日志存放位置
HBASE_MANAGES_ZK=false 含义为 hbase 不托管 zookeeper 的启动与关闭,因为笔者的 ZooKeeper 是独立安装的
vim /usr/local/hbase-1.2.0-cdh5.7.5/conf/hbase-site.xml
配置 regionservers
在这里列出了希望运行的全部 Regionserver ,一行写一个主机名(就像 Hadoop 中的 slaves 一样)。这里列出的 Server 会随着集群的启动而启动,集群的停止而停止。
vim regionservers
添加如下:
Zk-la03
Slave-01
Slave-02
替换 Hadoop 的 jar 包使用如下命令:
cp /usr/local/hadoop-2.6.0-cdh5.7.5/share/hadoop/common/hadoop-common-2.6.0-cdh5.7.5.jar /usr/local/hbase-1.2.0-cdh5.7.5/lib/
移除 HBase 里面的不必要 log4j 的 jar 包
cd /usr/local/hbase-1.2.0-cdh5.7.5/lib/
mv slf4j-log4j12-1.7.5.jar slf4j-log4j12-1.7.5.jar.bak
如果不移除的话,将会出现以下 warning :
![]()
分发 HBase
chown -R hbase:hbase /usr/local/hbase-1.2.0-cdh5.7.5
vim host.txt
zk-master-la01
zk-master-la02
zk-la03
slave-01
slave-02
for i in `cat /root/host.txt`;do echo $i;scp -r /usr/local/ hbase-1.2.0-cdh5.7.5 root@$i:/usr/local/hbase-1.2.0-cdh5.7.5 ;done
多台创建日志和数据目录
mkdir -p /var/hadoop/hbase/logs
chown -R hadoop:hadoop /var/hadoop/hbase/logs
chown -R hadoop:hadoop /opt/hbase/data/
chown -R hadoop:hadoop /usr/local/hbase-1.2.0-cdh5.7.5/
su hdfs
cat hadoop-fs-hbase.sh
#!/bin/sh
echo 'hdfs fs -mkdir /hbase'
/usr/local/hadoop-2.6.0-cdh5.10.0/bin/hadoop fs -mkdir /hbase
/usr/local/hadoop-2.6.0-cdh5.10.0/bin/hadoop fs -chown hbase:hbase /hbase
启动并检验 HBase
启动 HBase
友情提醒:在启动之前,笔者已经将 ZooKeeper 和 Hadoop (至少是 HDFS)给启动了。
1. 在其中一台主机上启动 Hmaster,即笔者在 master5 上,执行以下命令
start-hbase.sh

在另一台 Hmaster 的主机上,即笔者在 master52 上,执行以下命令
hbase-daemon.sh start master
![]()
查看 master-la01上的日志

在其中一个 ZooKeeper 机子上,可以查看相应的 znode 点,例如在 slave-01 上执行
zkCli.sh

查看相应进程



HDFS 上 /hbase 目录
在 master-la01 上查看启动 HBase 后在 HDFS 上产的目录。该路径是由 hbase.rootdir 属性参数所决定的
hadoop fs -ls -R /hbase
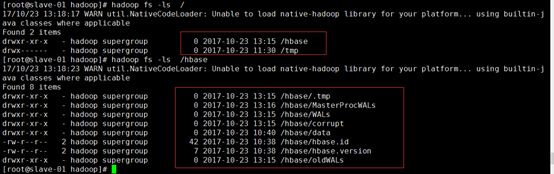
验证
在浏览器上查看具体信息
Zk-master-la01:60010

Zk-master-la02
模拟 master-la01 失效后 ,Hmaster 故障切换

补充:关闭集群
Note:在关闭之前请确保 ZooKeeper 并没有关闭!
stop-hbase.sh