(2) hadoop 配置部署启动HDFS及本地模式运行MapReduce案例(使用HDFS上数据)
(1)hdfs的配置 /opt/modules/hadoop-2.5.0-cdh5.3.6/etc/hadoop/core-site.xml
添加:
(2)修改 hdfs-site.xml
(3)格式化文件系统 清空之前旧数据 如果不知道命令 可以打bin/hdfs 然后回车 就会显示所有的命令
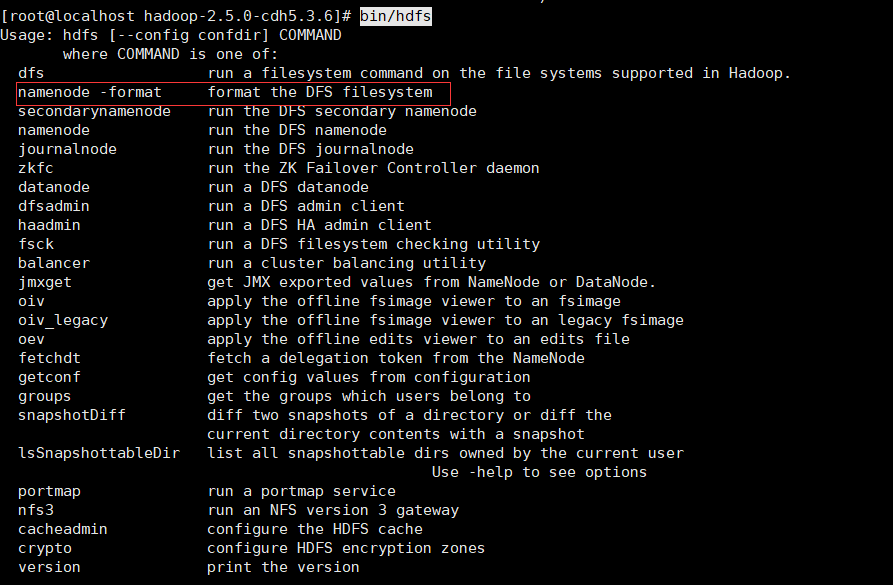
执行: bin/hdfs namenode -format
(4)启动 namenode datanode 启动脚本在sbin目录下
namenode 主节点 负责管理数据
datanode 是从节点 负责存储数据
启动namenode: sbin/hadoop-daemon.sh start namenode
启动datanode:sbin/hadoop-daemon.sh start datanode
jps 查看一下 有2个jvm进程

日志在/opt/modules/hadoop-2.5.0-cdh5.3.6/logs 中 如果有报错 查看这里的日志文件 自行搜索
(5)提供了 web访问界面
linuxIp:50070
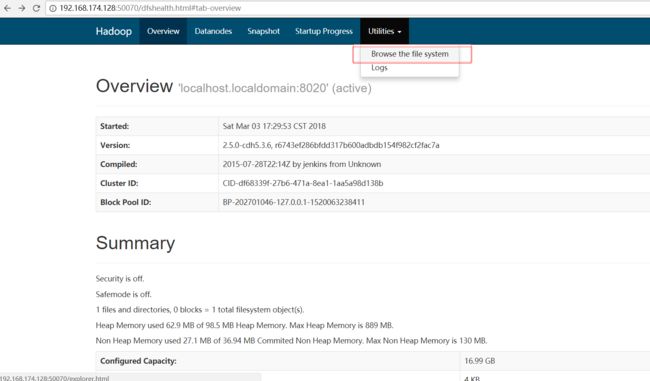
点击Browse the file system 菜单 可以查看文件系统的一些信息
(6)hdfs 创建文件夹 到/opt/modules/hadoop-2.5.0-cdh5.3.6 目录下
bin/hdfs dfs -mkdir -p /user/root
然后按照(5)中的Browse the file system菜单 查看
也可以用命令:bin/hdfs dfs -ls -R /

(7) 例子
1)执行: bin/hdfs dfs -mkdir -p /user/root/mapreduce/wordcount/input
2)把本地的已存在的一个文件(上一篇博客创建的)上传到/user/root/mapreduce/wordcount/input 下边
bin/hdfs dfs -put wcinput/wc.input /user/root/mapreduce/wordcount/input/
3)查看是否上传成功 可以用命令 也可点击(5)中说的菜单查看
bin/hdfs dfs -ls -R /
也可以读取内容
bin/hdfs dfs -cat /user/root/mapreduce/wordcount/input/wc.input
4)在运行单词统计程序 此时的输入时从hdfs文件系统中读取的 不再是本地(上一篇博客)
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount /user/root/mapreduce/wordcount/input /user/root/mapreduce/wordcount/output
执行成功按照点击步骤(5)中的菜单 进去看是否生成output
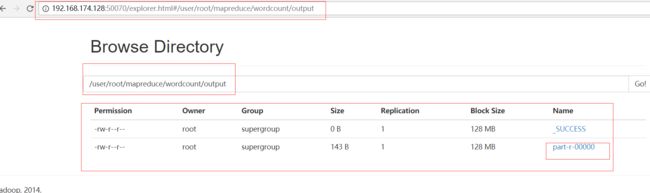
用程序读取一下结果中的内容:
bin/hdfs dfs -cat /user/root/mapreduce/wordcount/output/part-r-00000
注: hdfs有很多命令 可以通过 bin/hdfs 回车查看
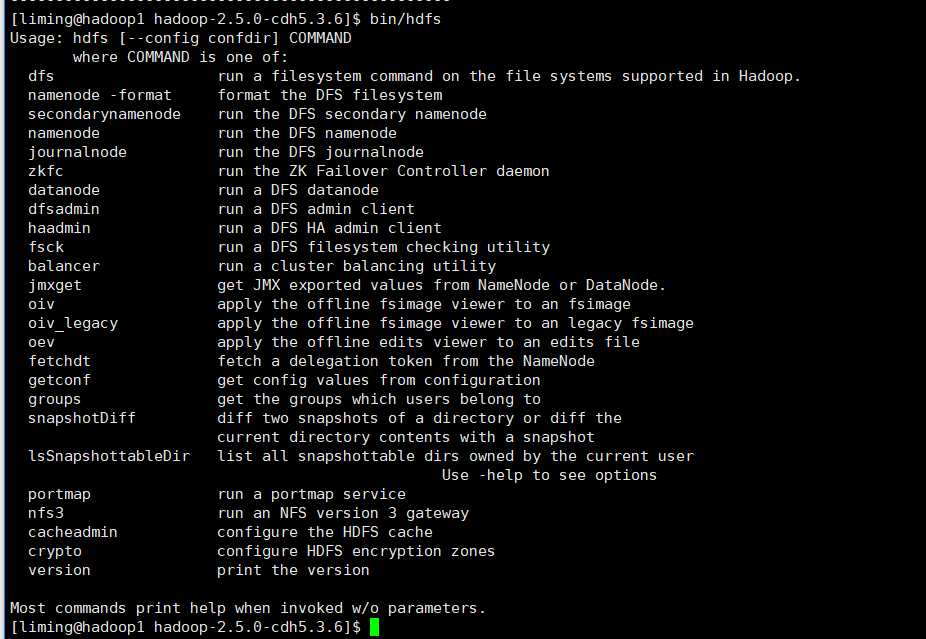
比如这里有一个dfsadmin(很重要的一个命令 dfs管理员) 接着查看bin/hdfs dfsadmin 回车
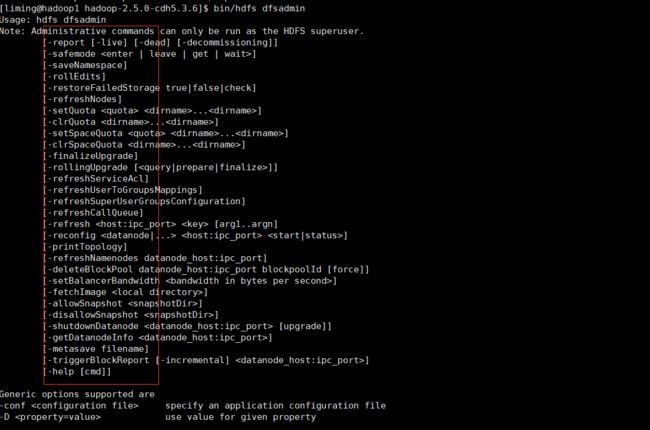
可以看到有功能 其中 -report -safemode -refresh 等 都很常用