python3学习笔记之web抓取、request库、beautifulsoup库的使用、selenium 模块的使用
1.使用sys.argv获得从命令行输入外部参数。其返回值为一个列表。
2.python3有个关于剪切板文本的模块:pyperclip
1.pyperclip.paste()可以取得剪切板的文本
2.pyperclip.copy("")可以将字符串复制到剪切板
3.python的字符串与bytes区别:
1)在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。编码的对象是字符。
2)python3的字符串是以Unicode编码(ord()编码,chr()解码)的,意思是python3可以输出中文。
可以用
'ABC'.encode('ascii')将字符串编码为指定的bytes。
也可以用
b'ABC'.decode('ascii')将bytes解码为字符串。
4.request库的使用:
1.建立request对象:
>>> r = requests.get('https://api.github.com/events')
2.request对象所具有的属性:
1)status_code:返回的响应码
2)text:获得网页的内容以字符串内容
3)content:以字节的方式访问请求响应体
3.request对象具有的方法:
1)raise_for_status()检查文件下载是否出错,如果出错就抛出异常。
2)iter_content(100000)以迭代方式获得bytes,一般大小为100000.即是
3)
5.bs4库的使用
1)import bs4
2)创建BeautifulSoup 对象
bso=bs4.BeautifulSoup( )需要传入字符串值,或者文件对象。
3)BeautifulSoup对象所具有的方法
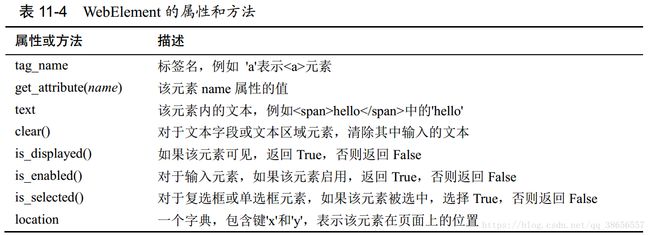
1.select(“”)方法传递给 soup.select('div > span') 所有直接在 soup.select('input[name]') 所有名为,并有一个 name 属性,其值无所谓的元素 soup.select('input[type="button"]') 所有名为,并有一个 type 属性,其值为 button 的元素 总结:传入字符串,查找元素名。之前加#号,是为找id。之前加.号,查找类属性。之间加空格,内含随意找。之间加大于,紧密来查找。之后加[],属性来查找。 2.返回的是tag对象的列表。 tag对象所具有的方法和属性为: (1)getText()方法,可以取得元素内容。 (2).attrs属性,返回属性对照的字典。 (3)get(“”)方法,返回传入属性的值。 6.selenium 模块的使用 0.wendriver的下载 1.chromedriver 下载地址:https://code.google.com/p/chromedriver/downloads/list 2.Firefox的驱动geckodriver 下载地址:https://github.com/mozilla/geckodriver/releases/ 下载解压后,将chromedriver.exe , geckodriver.exe , Iedriver.exe发到Python的安装目录,例如 D:\python 。 然后再将Python的安装目录添加到系统环境变量的Path下面。 (注意:windows安装tar.gz格式的文件的方法: 首先下载tar.gz文件,比如我准备安装python docx的库文件:python-docx-0.8.6.tar.gz,下载后是一个tar.gz文件,解压软件解压,解压后的目录里有一个setup.py文件,这时,切换到该目录,执行命令python.exe setup.py install) 1.创建WebDriver 对象 from selenium import webdriver browser = webdriver.Firefox() 【无头浏览器(即是无界面)的创建: browser = webdriver.FirefoxOptions() 2.WebDriver 对象的方法和属性 0)page_source属性:页面源代码 1)get(“”)方法,打开webdriver转到传入页面,等待加载完成返回脚本继续执行命令。(如果页面有ajax,其无法估计加载完成) (注意:import webbrowser webbrowser.open('')打开的是默认浏览器。 而webdriver对象的get打开的是指定浏览器驱动。 2)close()关闭浏览页面 3)back() 点击“返回”按钮。 forward()点击“前进”按钮 refresh()点击“刷新”按钮 4)find方法,在页面中查找元素 返回element对象。 3.element对象所具有的方法或属性 click():模拟鼠标在该元素上点击。这个方法可以用于链接跳转,选择单选按钮,点击提交按钮, 或者触发该元素被鼠标点击时发生的任何事情。 submit():在任何元素上调用 submit()方法,都等同于点击该元素所在表单的 Submit 按钮。如果提交元素不在表单中,则会返回 send_keys():向 Web 页面的文本字段发送击键,只要找到那个文本字段的或
soup.select('div') 所有名为
soup.select('#author') 带有 id 属性为 author 的元素
soup.select('.notice') 所有使用 CSS class 属性名为 notice 的元素
soup.select('div span') 所有在
browser.set_headless()
browser = webdriver.Firefox(firefox_options=browser)】
quit()点击“关闭窗口”按钮

NoSuchElementException错误。