有趣的算法(七):3分钟看懂希尔排序(C语言实现)
我的机器学习教程「美团」算法工程师带你入门机器学习 已经开始更新了,欢迎大家订阅~
任何关于算法、编程、AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主在线答疑~此外,公众号内还有更多AI、算法、编程和大数据知识分享,以及免费的SSR节点和学习资料。其他平台(知乎/B站)也是同名「图灵的猫」,不要迷路哦~



在上一次的算法讨论中,我们一起学习了直接插入排序。它的原理就是把前i个长度的序列变成有序序列,然后循环迭代,直至整个序列都变为有序的。但是说来说去它还是一个时间复杂度为(n^2)的算法,难道就不能再进一步把时间复杂度降低一阶么?
确实,以上几种算法相对于之前的O(n^2)级别的算法真的是弱,效率可能还会差上千万倍,但是我们不妨翻看一下历史,你就会感觉每一种算法的出现都是很可贵的。
一、算法思想
希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破O(n2)的第一批算法之一。因为在1959年之前的相当长的一段时间里,各种各样的排序算法无论是怎么花样繁多,都始终无法突破O(n^2),在当时直接插入排序已经是相当优秀的了,而排序算法不可能突破O(n^2)的声音成为了当时的主流。希尔排序的出现带来了新的希望。
该方法的基本思想是:先将整个待排元素序列切割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。由于直接插入排序在元素基本有序的情况下(接近最好情况),效率是非常高的,因此希尔排序在时间效率上比前两种方法有较大提高。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率。
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
增量的选择:在每趟的排序过程都有一个增量,至少满足一个规则 增量关系 d[1] > d[2] > d[3] >..> d[t] = 1 (t趟排序);根据增量序列的选取其时间复杂度也会有变化,这个不少论文进行了研究,在此处就不再深究。本文采用增量为n/2,以此递推,每次增量为原先的1/2,直到增量为1。
希尔排序的排序效率和选择步长序列有直接关系,从length逐步减半,这还不算最快的希尔,有几个增量在实践中表现更出色,具体可以看weiss的数据结构书,同时里面有希尔排序复杂度的证明,但是涉及组合数学和数论,希尔排序是实现简单但是分析极其困难的一个算法的例子。目前最好的序列是 塞奇威克(Sedgewick)的步长序列(摘自维基百科)
- 希尔(Shell)原始步长序列:N / 2,N / 4,...,1(重复除以2)
- 希伯德(Hibbard)的步长序列:1,3,7,...,2 k - 1
- 克努特(Knuth)的步长序列:1,4,13,...,(3 k - 1)/ 2
- 塞奇威克(Sedgewick) 的步长序列:1,5,19,41,109
二、算法步骤
算法步骤可以简单分为:
- 用增量进行分组
- 对每组进行插入排序

举个例子,按步长序列 [1,3,5,...] 对数组[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ] 进行希尔排序,首先按步长为5 进行分组,每行为一个分组得到:
然后对每行分组进行排序得到:
然后再按步长为3进行分组,每行为一个分组得到:
对每行分组进行排序得到:
此时数组如下所示,可以看到,元素本身已经基本有序了,此时插入排序的效率可以达到最高
[ 10 14 13 25 23 33 27 25 59 39 65 73 45 94 82 94 ]
看起来 比直接分组排序多了些步骤,而实际上是让一些小数跳过了一些比较和交换操作,直接从后面跳到了前面,从而提高了效率。下面这个动态图形象的解释了希尔排序的过程:
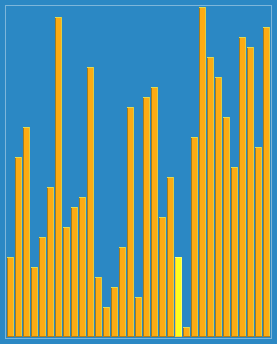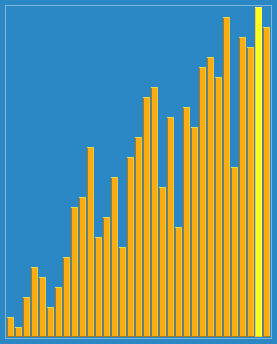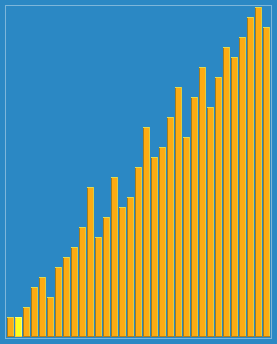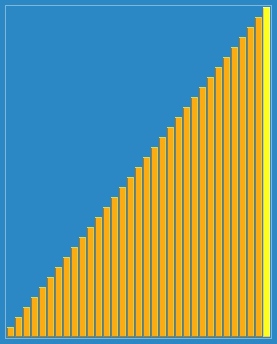
三、算法分析
希尔排序中对于增量序列的选择十分重要,直接影响到希尔排序的性能。我们上面选择的增量序列{n/2,(n/2)/2...1}(希尔增量),其最坏时间复杂度依然为O(n2),一些经过优化的增量序列如Hibbard经过复杂证明可使得最坏时间复杂度为O(n3/2)
| 排序方法 | 时间复杂度 | 空间复杂度 | 稳定性 | 复杂性 | ||
| 平均情况 | 最坏情况 | 最好情况 | ||||
| Shell 排序 | O(n3/2) | O(n^2) | O(n) | O(1) | 不稳定 | 较复杂 |
(上面这个我引用的图空间复杂度有问题,原来是O(N),我修改了,其实应该是O(1))
对于希尔排序的一个理解,我觉得知乎上有个答主说的很好,从本质上剖析了高效算法之所以高效的原因:
希尔能突破O(N^2)的界,可以用逆序数来理解,假设我们要从小到大排序,一个数组中取两个元素如果前面比后面大,则为一个逆序,容易看出排序的本质就是消除逆序数,可以证明对于随机数组,逆序数是O(N^2)的,而如果采用“交换相邻元素”的办法来消除逆序,每次正好只消除一个,因此必须执行O(N^2)的交换次数,这就是为啥冒泡、插入等算法只能到平方级别的原因,反过来,基于交换元素的排序要想突破这个下界,必须执行一些比较,交换相隔比较远的元素,使得一次交换能消除一个以上的逆序,希尔、快排、堆排等等算法都是交换比较远的元素,只不过规则各不同罢了。
四、算法实现
代码在VC++环境下编译通过
/*Shell排序数组
version: Shell插入排序
*/
#include
#include
#include
#ifndef N
#define N 100
#endif // N
int arr[N];
inline int Shell_Sort(int *arr)
{
register int i, j, k, tmp;
int incre; //选择一个增量,这里我们用简单的二分法
for(incre = N/20; incre > 0;incre /= 2)
{
for(i = incre; i < N/10; i++)
{
tmp = arr[i];
// 很明显和插排的不同就是插排这里是j = i - 1
j = i - incre;
while( j >= 0 && tmp < arr[j])
{
arr[j + incre] = arr[j];
j -= incre;
}
arr[j + incre] = tmp;
}
}
}
int main( int argc, int *argv[])
{
int i;
printf("please enter 10 numbers: \n");
for(i = 0;i < N/10;i++)
{
scanf("%d", &arr[i]);
}
Shell_Sort(arr);
printf("\n");
printf("the ordered array is: \n");
for(i = 0;i < N/10;i++)
{
printf("%4d", arr[i]);
}
} 输入:
5,13,7,26,54,8,42,33,72,41
输出:
![]()
参考文章:
排序算法系列—希尔排序
算法篇:希尔排序
知乎:希尔排序为什么那么牛