RHCS介绍
What is RHCS?
RHCS(Red Hat Cluster Suite)红帽集群套件,它将集群系统中三大集群架构融合一体,可以给web应用、数据库应用等提供安全、稳定的运行环境,是经济廉价的集群工具集合,更确切的说,RHCS是一个功能完备的集群应用解决方案,它从应用的前端访问到后端的数据存储都提供了一个行之有效的集群架构实现,通过RHCS提供的这种解决方案,不但能保证前端应用持久、稳定的提供服务,同时也保证了后端数据存储的安全。
三种集群构架:高可用性集群、负载均衡集群、存储集群
CMAN(Cluster manager):
运行位置:
是一个分布式集群管理工具,运行在集群的各个节点上,为RHCS提供集群管理任务。
作用:
它用于管理集群成员、消息和通知。它通过监控每个节点的运行状态来了解节点成员之间的有关系。当集群中某个节点出现故障时,节点成员关系将发生改变,CMAN及时将这种改变通知底层,进而做出相应的调整。
CMAN根据每个节点的运行状态,统计出一个法定节点数,作为集群是否存活的依据。当整个集群中有多于一半的节点处于激活状态时,表示达到了法定节点数,此集群可以正常运行,当集群中有一半或少于一半的节点处于激活状态时,表示没有达到法定的节点数,此时整个集群系统将变得不可用。
依赖:
CMAN依赖于CCS,并且CMAN通过CCS读取cluster.conf文件。
CCS(Cluster configuration system)
运行位置:
CCS运行在集群的每个节点上
作用:
监控每个集群节点上的单一配置文件/etc/cluster/cluster.conf的状态。当这个文件发生任何变化时,都将些变化更新至集群中的每个节点上,时刻保持每个节点的配置文件同步。Cluster.conf是一个XML文件,其中包含集群名称,集群节点信息,集群资源和服务信息,fence设备等。
fence(栅设备)
通过栅设备可以从集群共享存储中断开一个节点,切断I/O以保证数据的完整性。当CMAN确定一个节点失败后,它在集群结构中通告这个失败的节点,fenced进程将失败的节点隔离,以保证失败节点不破坏共享数据。它可以避免因出现不可预知的情况而造成的“脑裂”(split-brain)现象。“脑裂”是指当两个节点之间的心跳线中断时,两台主机都无法获取对方的信息,此时两台主机都认为自己是主节点,于是对集群资源(共享存储,公共IP地址)进行争用,抢夺。
Fence的工作原理是:当意外原因导致主机异常或宕机时,备用机会首先调用fence设备,然后通过fence设备将异常的主机重启或从网络上隔离,释放异常主机占据的资源,当隔离操作成功后,返回信息给备用机,备用机在接到信息后,开始接管主机的服务和资源。
RHCS的Fence设备可以分为两种:内部Fence和外部Fence。内部fence有IBM RSAII卡,HP的ILO卡,以及IPMI设备等;外部FENCE设备有UPS,SAN switch ,Network switch等。
rgmanager 高可用服务管理器:
运行位置:
rgmanager运行在每个集群节点上,在服务器上对应的进程为clurgmgrd
作用:
它主要用来监督、启动、停止集群的应用、服务和资源。当一个节点的服务失败时,高可用集群服务管理进程可以将服务从这个失败节点转移至其点健康节点上,这种服务转移能力是自动动,透明的。
在RHCS集群中,高可用性服务是和一个失败转移域结合在一起的。由几个节点负责一个特定的服务的集合叫失败转移域,在失败迁移域中可以设置节点的优先级,主节点失效,服务会迁移至次节点,如果没有设置优先,集群高可用服务将在任意节点间转移。
在RHCS集群中,高可用服务包括集群服务和集群资源两方面
集群服务:
其实就是应用,如APACHE,MYSQL等
集群资源:
有IP地址,脚本,EXT3/GFS文件系统等
Conga
RHCS提供了多种集群配置和管理工具,常用有基于GUI的system-config-cluster,conga等
conga是新的基于网络的集群配置工具。它是web界面管理的,由luci和ricci组成,luci可以安装在一台独立的计算机上,也可安装在节点上,用于配置和管理集群,ricci是一个代理,安装在每个集群节点上,luci通过ricci和集群中的每个节点通信
。
拓扑
浮动IP:1.1.1.3/24
+++++++++++++++ +++++++++++++++
- web master + + web backup +
+++++++++++ +++ +++++++++++++++
web1:1.1.1.10/24 web2:1.1.1.20/24
|_________________________________|
|
++++++++++ - NFS +
++++++++++
1.1.1.1/24
友情提示:所有网卡必须hostonly模式,否则后果很严重。。。
环境检查:
- 3个服务器需要设置主机名
web1.up.com
web2.up.com
nfs.up.com - 3个服务器要在/etc/hosts文件中添加解析
192.168.122.10 web1.up.com web1
192.168.122.20 web2.up.com web2
192.168.122.30 nfs.up.com nfs (我截图的时候使用的是slave.up.com,只是名字而已) - 在3个服务器上 iptables 和 SElinux 要 Disabled, 停止并禁用 NetworkManager 。
- 在3个服务器上配置yum,需要支持光盘上的根目录 、 HighAvailability 、 ResilientStorage 、 ScalableFileSystem
部署NFS
[root@nfs ~]# mkdir /apache/
[root@nfs ~]# echo “Conga test” > /apache/index.html
[root@nfs ~]# vim /etc/exports
/apache *(ro,sync)
[root@nfs ~]# service nfs restart
分别测试web1 & web2在挂载nfs共享后,都能够正常显示, 测试后停止
httpd服务,卸载nfs
的客户端挂载
部署Conga
分别在2个HA节点(web1 & web2)上部署ricci
[root@web1 ~]# yum install ricci
[root@web1 ~]# passwd ricci
[root@web2 ~]# service ricci start
NFS作为管理节点部署luci
[root@nfs ~]# yum install luci
[root@nfs ~]# service luci start
Start luci… [ OK ]
Point your web browser to
https://nfs.up.com:8084
(or equivalent) to access luci
配置Conga
[root@nfs ~]# firefox
https://nfs.up.com:8084
用户名:root , 密码 : luci所在系统的root密码
Luci is a graphical user interface that you can use to administer the Red Hat High Availability Add-On. Note, however, that in order to use this interface effectively you need to have a good and clear understanding of the underlying concepts. Learning about cluster configuration by exploring the available features in the user interface is not recommended, as it may result in a system that is not robust enough to keep all services running when components fail.
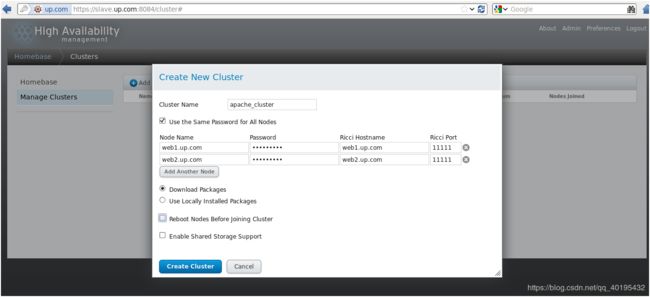
创建集群,并在集群中加入集群节点,Manage Clusters—>Create a New Cluster
Node Hostname HA集群成员的主机名,不可填写IP
Password HA集群节点的ricci密码
Download packages 部署集群时,自动安装所需软件
Reboot nodes before joining cluster 生产环境建议勾选


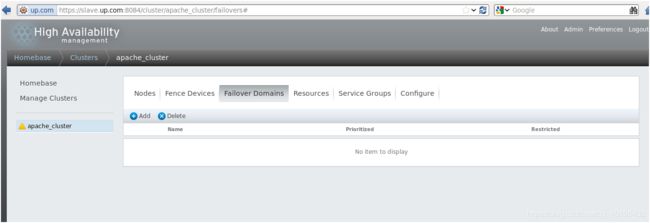
创建故障转移域,指定故障转移域中的成员,域中成员的优先级(数小优先级高)

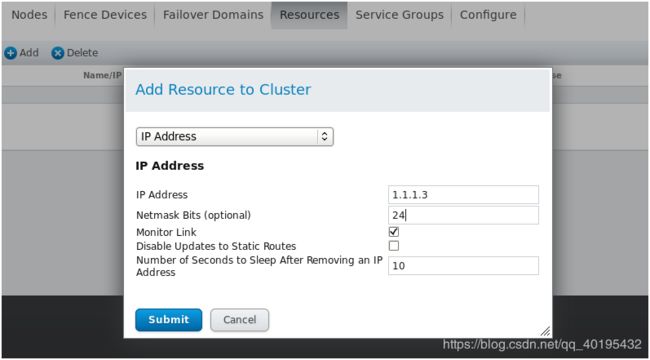
在资源池中添加浮动资源(浮动IP,nfs mount,httpd)



创建服务,指定服务运行的故障转移域,恢复策略,添加组成服务的资源


上图的Recovery Policy :
Restart:在当前节点上重新启动资源组,如果失败,将切换到资源组中的其他节点上
Restart-Disable:在当前节点上重启资源组,如果失败,将资源组禁用
Relocate:在当前节点上停止资源组,并切换到另一个可用节点,如果没有节点可用将禁用资源组
Disable:禁用资源组,需要管理员启用资源组
点击上图按钮Add Resource
选择之前定义好的资源
添加时,先添加IP,再添加nfs,最后添加httpd,在添加IP之后每次添加资源要选择 Add Child Resource


点击Add Child Resource

点击Add Child Resource

刚创建出服务时,服务状态可能是Unknown,稍等刷新页面即可
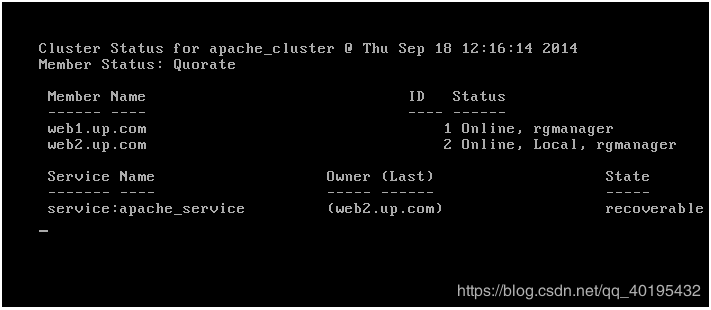
在字符界面我们也可以使用命令来查看集群状态
[root@web1 ~]# clustat -i 1
在web1上将httpd服务关闭,可以通过clustat -i 1 命令看到服务向web2切换


特别提示:
如果NetworkManager服务启动,cman可能启动不起来,需要关闭NetworkManager,此服务关闭需要使用chkconfig,如果单纯stop不管用