MapReduce中的数据倾斜简介及部分解决方案
阅读了网上别人整理写作的博客,了解了数据倾斜的一些大概情况。
查阅论文了解一下比较前沿的算法解决思路。(看了好几篇论文,找了几个有意思的解决方案和大家分享一下)
查阅Apache官方论坛,了解一些实际中的解决应用。
专业名词:data skew、partitioning skew、reduce skew、data locality
发现大概有两种优化思路,一种是在shuffle阶段做优化,使得reduce任务分配均匀,还有种就是在reduce阶段做负载均衡,让资源分配更均匀。
文章目录
- 数据倾斜简洁介绍
- 数据倾斜概述
- 数据倾斜的产生
- 1.读入数据源时就是倾斜的
- 2. 过滤导致倾斜
- 3. shuffle产生倾斜(重点解决的)
- 数据倾斜的危害
- 数据倾斜的解决思路
- 在shuffle阶段使得任务分配均匀
- Greedy-Balance load balancing approach
- sample-based algorithm
- 对reduce节点做资源负载均衡
- Dynamic Resource Allocation for MapReduce with Partitioning Skew
- SpongeFiles: mitigating data skew in mapreduce using distributed memory
- 参考
数据倾斜简洁介绍
数据倾斜概述
数据倾斜,指的是并行处理的过程中,某些分区或节点处理的数据,显著高于其他分区或节点,导致这部分的数据处理任务比其他任务要大很多,从而成为这个阶段执行最慢的部分,进而成为整个作业执行的瓶颈,甚至直接导致作业失败。
简单的讲,数据倾斜就是我们在计算数据的时候,数据的分散度不够,导致大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢。
分布式处理的理想情况:

但实际中可能会出现:

可以看出如果任务分配不均的话,分布式处理的时间并不比单机处理时间低,甚至在实际情况中还有可能分布式比单机处理更慢。
数据倾斜的产生
1.读入数据源时就是倾斜的
读入数据是计算任务的开始,但是往往这个阶段就可能已经开始出现问题了。
对于一些本身就可能倾斜的数据源,在读入阶段就可能出现个别partition执行时长过长或直接失败,如读取id分布跨度较大的mysql数据、partition分配不均的kafka数据或不可分割的压缩文件。
这些场景下,数据在读取阶段或者读取后的第一个计算阶段,就会容易执行过慢或报错。
2. 过滤导致倾斜
有些场景下,数据原本是均衡的,但是由于进行了一系列的数据剔除操作,可能在过滤掉大量数据后,造成数据的倾斜。
例如,大部分节点都被过滤掉了很多数据,只剩下少量数据,但是个别节点的数据被过滤掉的很少,保留着大部分的数据。这种情况下,一般不会OOM,但是倾斜的数据可能会随着计算逐渐累积,最终引发问题。
3. shuffle产生倾斜(重点解决的)
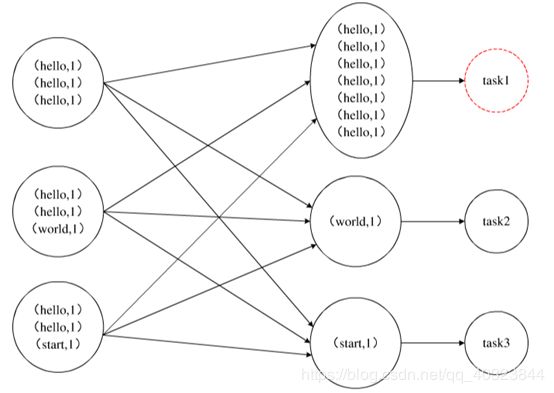
如图,是一个简单的数据倾斜示意图,在shuffle过程中对数据按照key进行重新划分后,其中一个key(hello)对应的数据量远大于其他key(world,start)的数据量,从而出现了数据倾斜。这就导致后续的处理任务中,task1的运行时间肯定远远高于其他的task2、task3的运行时间。
数据倾斜的危害
对数据倾斜概念有所理解的话,数据倾斜的危害,大家应该很容易都能想到
数据倾斜主要有三点危害:
-
任务长时间挂起,资源利用率下降
计算作业通常是分阶段进行的,阶段与阶段之间通常存在数据上的依赖关系,也就是说后一阶段需要等前一阶段执行完才能开始。
举个例子,Stage1在Stage0之后执行,假如Stage1依赖Stage0产生的数据结果,那么Stage1必须等待Stage0执行完成后才能开始,如果这时Stage0因为数据倾斜问题,导致任务执行时长过长,或者直接挂起,那么Stage1将一直处于等待状态,整个作业也就一直挂起。这个时候,资源被这个作业占据,但是却只有极少数task在执行,造成计算资源的严重浪费,利用率下降。 -
引发内存溢出,导致任务失败
数据发生倾斜时,可能导致大量数据集中在少数几个节点上,在计算执行中由于要处理的数据超出了单个节点的能力范围,最终导致内存被撑爆,报OOM异常,直接导致任务失败。 -
作业执行时间超出预期,导致后续依赖数据结果的作业出错
有时候作业与作业之间,并没有构建强依赖关系,而是通过执行时间的前后时间差来调度,当前置作业未在预期时间范围内完成执行,那么当后续作业启动时便无法读取到其所需要的最新数据,从而导致连续出错。
数据倾斜的解决思路
以下介绍了两种解决思路,主要内容源自参考的论文
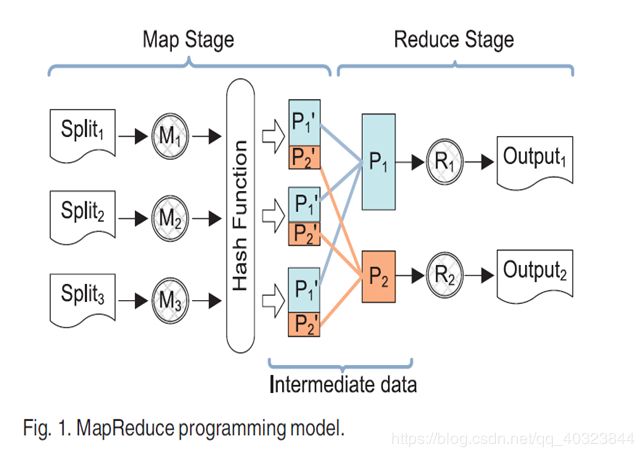
下面这图是mapreduce的编程模型,大家可以很容易想到从哪些地方下手解决数据倾斜的问题。
在shuffle阶段使得任务分配均匀
具体解决思路:
predicts the workload for individual reduce tasks based on certain statistics of keyvalue pairs, and then repartitions the workload to achieve a better balance among the reduce tasks
简单的hash function在面对不平衡的数据时会导致reduce worker任务分配不平衡,下面举例说明一个:

大家可以看出使用简单的hash function会导致任务分配不均,跟最优分配差距还是很大的。
Greedy-Balance load balancing approach
一旦读入未分配的key,便将其分配给负载最小的机器。
算法伪代码如下:

我们知道在mapreduce中,相同的key会被分配到同一reduce节点上。
简而言之,面对map阶段产生的大量key-value对,采用贪心算法,将他们分配到工作负载最小的reduce节点上。(map进行到5%左右,shuffle阶段就开始工作了)
sample-based algorithm
相对于是对于贪心算法的一个优化
我们的基于样本的算法首先收集样本,然后以观察到的key频率的顺序对样本中的key进行排序,然后选择K个最频繁的密钥。然后,遍历此列表,它将每种类型的密钥分配给当前负载最小的机器
算法伪代码:

再次拿上面那个输入案例来对比,可以看出改进版算法,能得到最优的分配。

对reduce节点做资源负载均衡
像上面介绍的这种算法通常需要采样阶段,对于平均寿命约为100秒的小型作业,这种开销可能会非常昂贵。
与其在reduce任务之间重新分配工作负载,我们通过控制分配给每个reduce任务的资源量来解决分区偏斜问题。
Dynamic Resource Allocation for MapReduce with Partitioning Skew
处理模型结构:

主要有5个模块:
Partition Size Monitor, running in the NodeManager;
Partition Size Predictor, Task Duration Estimator and Resource Allocator, running in the ApplicationMaster;
Fine-grained Container Scheduler, running in the ResourceManager.
具体处理步骤:
- each Partition Size Monitor records the size of intermediate key-value pairs produced by map tasks. Each Partition Size Monitor sends locally gathered statistics to the Application-Master
- the Partition Size Predictor performs size prediction using our proposed prediction model. After all the estimated sizes of reduce tasks are known, the Task Duration Estimator uses the reduce task performance model to predict the duration of each reduce task with specified amount of resources
Based on that, the Resource Allocator determines the amount of resources for each reduce task according to our proposed resource allocation algorithm (Section 4.3) to equalize the execution time of all reduce tasks and then sends resource requests to the ResourceManager - the ResourceManager receives Application Masters’ resource requests and schedules free containers in the cluster to corresponding ApplicationMasters.
- Once the ApplicationMaster obtains new containers from the ResourceManager, it assigns the corresponding containers to the pending tasks, and finally launches the tasks.
看似简单,但是设计细节还是很难操作的。
设计细节:
- 为了判别数据倾斜,必须开发一个运行时预测算法用来预测每个reduce任务的partition size
- 为了确保每个reduce任务的容器正确大小,开发一个将任务运行时间和资源分配相关联的性能评测模型
- 将各维度的资源( CPU, memory, disk I/O and network bandwidth.)组合分配的算法。
SpongeFiles: mitigating data skew in mapreduce using distributed memory


参考
website:
漫谈千亿级数据优化实践:数据倾斜(纯干货
数据倾斜问题-数据处理与分析过程中的杀手
paper:
Online Load Balancing for MapReduce with skewed data input
SpongeFiles: mitigating data skew in mapreduce using distributed memory. SIGMOD Conference 2014: 551-562
Dynamic Resource Allocation for MapReduce with Partitioning Skew
code:
https://issues.apache.org/jira/projects/SPARK/issues