数据库系统概论-第六章-关系数据理论
关系模式的组成:
关系模式由五部分组成,是一个五元组:
R(U, D, DOM, F)
-
关系名R是符号化的元组语义
-
U为一组属性
-
D为属性组U中的属性所来自的域
-
DOM为属性到域的映射
-
F为属性组U上的一组数据依赖
第一范式(1NF):
- 作为二维表,关系要符合一个最基本的条件:每个分量必须是不可分开的数据项。满足了这个条件的关系模式就属于第一范式(1NF)
数据依赖:
- 是一个关系内部属性与属性之间的一种约束关系
- 通过属性间值的相等与否体现出来的数据间相互联系
- 是现实世界属性间相互联系的抽象
- 是数据内在的性质
- 是语义的体现
- 数据依赖的主要类型:函数依赖 FD 多值依赖 MVD
函数依赖:
- 一对一联系:X←→Y
- 多对一联系:X→Y
- 多对多联系:不存在依赖关系
- 可从属性间的联系类型来分析属性间的函数依赖
- 若X→Y,并且Y→X, 则记为X←→Y。
若Y不函数依赖于X, 则记为X→\Y。 - X→Y,但Y⊈X则称X→Y是非平凡的函数依赖。
X→Y,但Y⊆X 则称X→Y是平凡的函数依赖。 - 若X→Y,则X称为这个函数依赖的决定因素
注:
1. 函数依赖不是指关系模式R的某个或某些关系实例满足的约束条件,而是指R的所有关系实例均要满足的约束条件。
2. 函数依赖是语义范畴的概念。只能根据数据的语义来确定函数依赖。
例如“姓名→年龄”这个函数依赖只有在不允许有同名人的条件下成立
3. 数据库设计者可以对现实世界作强制的规定。例如规定不允许同名人出现,函数依赖“姓名→年龄”成立。所插入的元组必须满足规定的函数依赖,若发现有同名人存在, 则拒绝装入该元组。
范式:
各种范式之间存在联系:

某一关系模式R为第n范式,可简记为R∈nNF
- 范式是符合某一种级别的关系模式的集合。
- 关系数据库中的关系必须满足一定的要求。满足 不同程度要求的为不同范式。
- 范式的种类:
- 第一范式(1NF)
第二范式(2NF)
第三范式(3NF)
BC范式(BCNF)
第四范式(4NF)
第五范式(5NF)
规范化:
- 一个低一级范式的关系模式,通过模式分解(schema decomposition)可以转换为若干个高一级范式的关系模式的集合,这种过程就叫规范化(normalization)
BCNF的关系模式所具有的性质:
- 所有非主属性都完全函数依赖于每个候选码
- 所有主属性都完全函数依赖于每个不包含它的候选码
- 没有任何属性完全函数依赖于非码的任何一组属性
平凡多值依赖和非平凡的多值依赖:
- 若X→→Y,而Z=Ф,即Z为空,则称X→→Y为平凡的多值依赖。
否则称X→→Y为非平凡的多值依赖。
多值依赖的性质:
(1)多值依赖具有对称性。
即若X→→Y,则X→→Z,其中Z=U-X-Y,多值依赖的对称性可以用完全二分图直观地表示出来。
(2)多值依赖具有传递性。即若X→→Y,Y→→Z, 则X→→Z -Y。
(3)函数依赖是多值依赖的特殊情况。即若X→Y,则X→→Y。
(4)若X→→Y,X→→Z,则X→→YZ。
(5)若X→→Y,X→→Z,则X→→Y∩Z。
(6)若X→→Y,X→→Z,则X→→Y-Z,X→→Z -Y。
多值依赖与函数依赖的区别:
(1)多值依赖的有效性与属性集的范围有关
l若X→→Y在U上成立,则在W(XYÍ W Í U)上一定成立;反之则不然,即X→→Y在W(W Ì U)上成立,在U上并不一定成立。
l原因:多值依赖的定义中不仅涉及属性组X和Y,而且涉及U中其余属性Z。
多值依赖的有效性与属性集的范围有关:
一般地,在R(U)上若有X→→Y在W(W Ì U)上成立,则称X→→Y为R(U)的嵌入型多值依赖。
函数依赖X→Y的有效性仅决定于X、Y这两个属性集的值只要在R(U)的任何一个关系r中,元组在X和Y上的值满足定义6.l,则函数依赖X→Y在任何属性集W(XYÍ W ÍU)上成立。
(2)若函数依赖X→Y在R (U)上成立,则对于任何Y‘ Ì Y均有X→Y’ 成立。多值依赖X→→Y若在R(U)上成立,不能断言对于任何Y’ Ì Y有X→→Y’ 成立。
4NF:
关系模式R<U,F>∈1NF,如果对于R的每个非平凡多值依赖X→→Y(Y ⊈ X),X都含有码,则R<U,F>∈4NF。
不允许有非平凡且非函数依赖的多值依赖。允许的非平凡多值依赖实际上是函数依赖
规范化小结:
规范化的基本思想:
- 在关系数据库中,对关系模式的基本要求是满足第一范式。
- 规范化程度过低的关系不一定能够很好地描述现实世界
- 可能存在插入异常、删除异常、修改复杂、数据冗余等问题
- 解决方法就是对其进行规范化,转换成高级范式。。
-
一个低一级范式的关系模式,通过模式分解可以转换为若干个高一级范式的关系模式集合,这种过程就叫关系模式的规范化。
-
关系数据库的规范化理论是数据库逻辑设计的工具。
是逐步消除数据依赖中不合适的部分,使模式中的各关系模式达到某种程度的“分离”。即采用“一事一地”的模式设计原则,让一个关系描述一个概念、一个实体或者实体间的一种联系。若多于一个概念就把它“分离”出去。因此 规范化实质上是概念的单一化。
规范化的基本步骤:
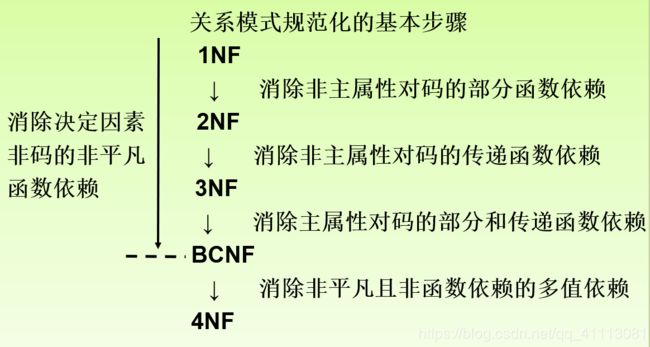
不能说规范化程度越高的关系模式就越好,必须对现实世界的实际情况和用户应用需求作进一步分析,确定一个合适的、能够反映现实世界的模式。上面的规范化步骤可以在其中任何一步终止。
Armstrong公理系统 :
设U为属性集总体,F是U上的一组函数依赖, 于是有关系模式R <U,F >。对R <U,F> 来说有以下的推理规则:
A1 自反律(reflexivity rule):若Y Í X Í U,则X →Y 为F所蕴涵。
A2 增广律(augmentation rule):若X→Y为F所蕴涵,且Z Í U,则XZ→YZ 为F所蕴涵。
A3 传递律(transitivity rule):若X→Y及Y→Z为F所蕴涵,则X→Z 为F所蕴涵。
注意:由自反律所得到的函数依赖均是平凡的函数依赖, 自反律的使用并不依赖于F。
根据A1,A2,A3这三条推理规则可以得到下面三条推理规则:
合并规则(union rule):由X→Y,X→Z,有X→YZ。
伪传递规则(pseudo transitivity rule):由X→Y,WY→Z,有XW→Z。
分解规则(decomposition rule): 由X→Y及ZÍY,有X→Z。
有效性与完备性的含义:
有效性:由F 出发根据Armstrong公理推导出来的每一个函数依赖一定在F +中
完备性:F +中的每一个函数依赖,必定可以由F出发根据Armstrong公理推导出来
如果函数依赖集F满足下列条件,则称F为一个极小函数依赖集,亦称为最小依赖集或最小覆盖。
(1)单属性化: F中任一函数依赖的右部仅含有一个属性。
(2)无冗余化: F中不存在这样的函数依赖X→A, 使得F与F-{X→A}等价。
(3)既约化: F中不存在这样的函数依赖X→A, X有真子集Z使得F-{X→A}∪{Z→A}与F等价。
模式的分解:
- 把低一级的关系模式分解为若干个高一级的关系模式的方法不是唯一的
- 只有能够保证分解后的关系模式与原关系模式等价,分解方法才有意义
- 三种模式分解等价的定义:
⒈. 分解具有无损连接性
⒉. 分解要保持函数依赖
⒊. 分解既要保持函数依赖,又要具有无损连接性
关系模式R
若R与R1、R2、…、Rn自然连接的结果相等,则称关系模式R的这个分解ρ具有无损连接性(Lossless join)
具有无损连接性的分解保证不丢失信息,无损连接性不一定能解决插入异常、删除异常、修改复杂、数据冗余等问题
- 如果一个分解具有无损连接性,则它能够保证不丢失信息
- 如果一个分解保持了函数依赖,则它可以减轻或解决各种异常情况
- 分解具有无损连接性和分解保持函数依赖是两个互相独立的标准。具有无损连接性的分解不一定能够保持函数依赖;同样,保持函数依赖的分解也不一定具有无损连接性。
若要求分解具有无损连接性,那么模式分解一定能够达到4NF
若要求分解保持函数依赖,那么模式分解一定能够达到3NF,但不一定能够达到BCNF
若要求分解既具有无损连接性,又保持函数依赖,则模式分解一定能够达到3NF,但不一定能够达到BCNF
规范化理论为数据库设计提供了理论的指南和工具,也仅仅是指南和工具
并不是规范化程度越高,模式就越好,必须结合应用环境和现实世界的具体情况合理地选择数据库模式