(P6)如何用keras产生一个合适的模型【配置optimizer】
步骤
(A)首先开发一个过拟合的模型
(1)添加更多的层 --最有用
(2)让每一层变得更大
(3)训练更多的轮次
(B)抑制过拟合(没有足够数据的情况)
(1)dropout
(2)正则化
(3)图像增强
(C)再次调节超参数
(1)learning rate
(2)隐藏层单元数
(3)训练轮次
fashionminst数据集的一次尝试
首先,先用很多层和单元,看看是否过拟合
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
(train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data()
#进行归一化处理
train_image = train_image/255
test_image = test_image/255
# 将label转化为onehot的编码形式
train_label_onehot = tf.keras.utils.to_categorical(train_label)
test_label_onehot = tf.keras.utils.to_categorical(test_label)
# 在原来的基础上多加上两个隐藏层
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001),
loss='categorical_crossentropy',
metrics=['acc']
)
# 记录下训练过程,记录下测试集的 loss和 accuracy
history = model.fit(train_image, train_label_onehot,
epochs=10,
validation_data=(test_image, test_label_onehot))
# 看看过拟合在loss上面的体现
print(history.history.keys()) # 看看fit过程中有哪些keys dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])
plt.plot(history.epoch, history.history.get('loss'), label='loss')
plt.plot(history.epoch, history.history.get('val_loss'), label='val_loss')
plt.legend() # 给图像加上图例
plt.show()
# 看看过拟合在acc上面的体现
plt.plot(history.epoch, history.history.get('acc'), label='acc')
plt.plot(history.epoch, history.history.get('val_acc'), label='val_acc')
plt.legend() # 给图像加上图例
plt.show()
与上一次的模型相比,这次多增加了两个隐藏层
让我们来看看训练集和测试集的loss和accuracy
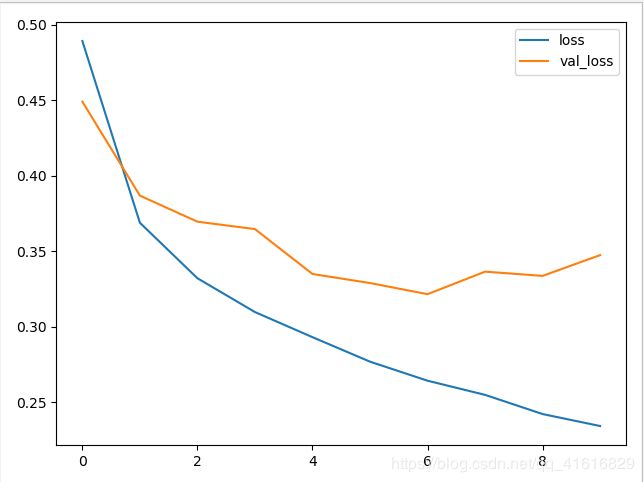
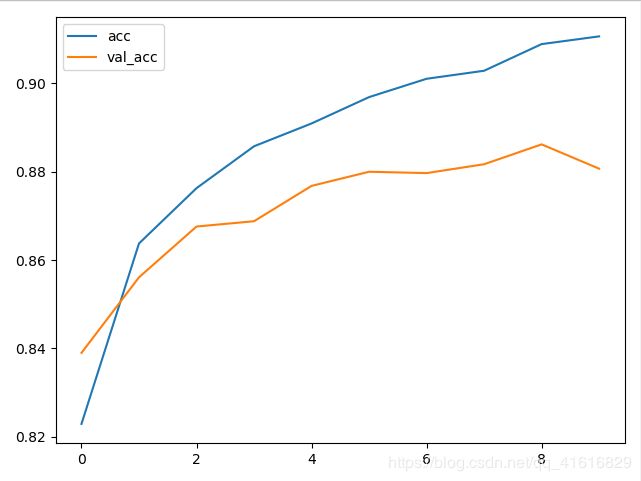
可以看到训练集上的loss一直在下降,但是测试集上的loss到了第六次以后不降反升
同样accurary,训练集一直上升,测试集到了后面也下降
这说明了过拟合了
加入3个Dropout层看看效果
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
(train_image, train_label), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data()
#进行归一化处理
train_image = train_image/255
test_image = test_image/255
# 将label转化为onehot的编码形式
train_label_onehot = tf.keras.utils.to_categorical(train_label)
test_label_onehot = tf.keras.utils.to_categorical(test_label)
# 在原来的基础上多加上两个隐藏层
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001),
loss='categorical_crossentropy',
metrics=['acc']
)
# 记录下训练过程,记录下测试集的 loss和 accuracy
history = model.fit(train_image, train_label_onehot,
epochs=10,
validation_data=(test_image, test_label_onehot))
# 看看过拟合在loss上面的体现
print(history.history.keys()) # 看看fit过程中有哪些keys
plt.plot(history.epoch, history.history.get('loss'), label='loss')
plt.plot(history.epoch, history.history.get('val_loss'), label='val_loss')
plt.legend() # 给图像加上图例
plt.show()
# 看看过拟合在acc上面的体现
plt.plot(history.epoch, history.history.get('acc'), label='acc')
plt.plot(history.epoch, history.history.get('val_acc'), label='val_acc')
plt.legend() # 给图像加上图例
plt.show()
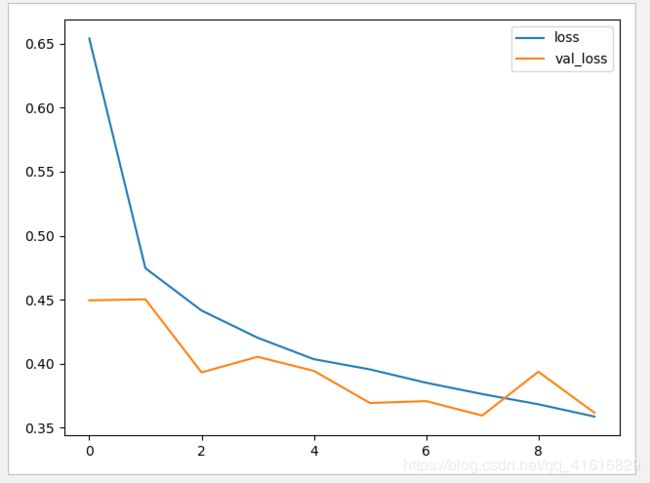

与前面的对比,可以看到很好地减少了过拟合
通过正则化的方法来减小过拟合
tf.keras.layers.Dense(128, activation='relu', kernel_regularizer=2)

就是开过改Dense()中的kernel_regularizer这个参数来控制的,用的不是很多,不做了