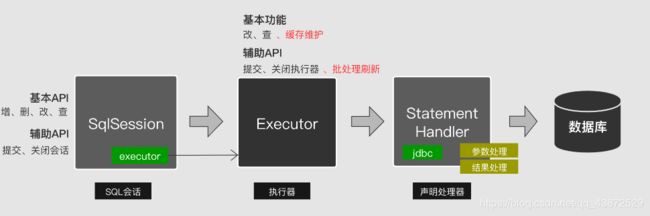
深入MyBatis源码解析执行过程
MyBatis深入分析
- 1、分析JDBC执行过程
- 2、分析MyBatis执行过程
- 2.1、SqlSession会话层分析
- 2.1.1、创建会话
- 2.1.2、获取映射
- 2.1.3、执行SQL
- 2.2、Executor执行器层分析
- 2.2.1、执行流程
- 2.2.2、一级缓存
- 2.2.3、二级缓存
- 2.3、StatementHandler层分析
1、分析JDBC执行过程

public class JdbcTest {
public static final String URL = "";
public static final String USERNAME = "";
public static final String PASSWORD = "";
private Connection connection;
public void test() throws SQLException{
//获得连接
connection = DriverManager.getConnection(URL,USERNAME,PASSWORD);
//定义sql
String sql = "SELECT * FROM users WHERE `name`=?";
//预编译sql
PreparedStatement sqlTest = connection.prepareStatement(sql);
//执行sql
sqlTest.setString(1,"test");
sqlTest.execute();
//获取结果
ResultSet resultSet = sqlTest.getResultSet();
//关闭连接
sqlTest.close();
connection.close();
}
通过以上代码简单演示了一条SQL语句在JDBC的执行流程,其中,statement通常采用
的是prepareStatement对象,因为它不仅效率更高,而且还可以防止SQL注入,其原因可参考另一篇博客https://blog.csdn.net/qq_43872529/article/details/107056367。
值得注意的是,在JDBC4.0之前,在连接数据库前通常需要执行语句Class.forName("com.mysql.jdbc.Driver)来加载MySQL数据库相关驱动;而在JDBC4.0之后则可以直接获取连接,因为它使用了SPI(Service Provide Interface)服务提供扩展机制实现驱动的加载,在DriverManager类中通过JDK的工具类 java.util.ServiceLoader进行服务发现。

2、分析MyBatis执行过程
//demoTest.java
public class demoTest{
private Configuration configuration;
private SqlSessionFactory factory;
public void test() throws SQLException{
//初始化操作
SqlSessionFactoryBuilder factoryBuilder = new SqlSessionFactoryBuilder();
factory = factoryBuilder.build(demoTest.class.getResourceAsStream("/mybatis-config.xml");
//创建sql会话
SqlSession sqlSession = factory.openSession(ExecutorType.SIMPLE, true);
//获取映射
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//执行sql
mapper.selectById(10);
}
}
//UserMapper.java
public interface UserMapper {
@Select({"select * from users where id=#{1}"})
User selectById(Integer id);
}
通过以上代码简单演示了如何通过Mapper映射获取并执行SQL语句。那么接下来就针对执行过程进行详细分析。
2.1、SqlSession会话层分析
2.1.1、创建会话
创建会话时可以选择具体的执行器类别 ExecutorType ,选择过程如下图所示:(关于不同执行器之间的区别在后续章节会继续介绍)

然后通过newExecutor方法根据 ExecutorType 选择具体的执行器,如果创建会话时未指定执行器,那么它会使用默认执行器(在配置文件中指定),如果未设置默认的执行器,那么它将使用simpleExecutor。其中newExecutor方法的具体实现如下图所示:
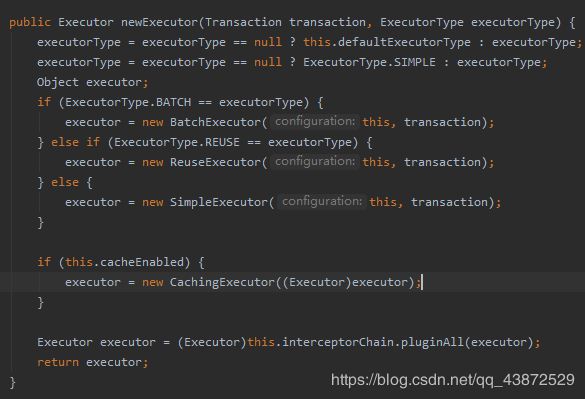
其中,事务 transaction 通过事务工厂 transactionFactory 的 newTransaction 方法进行创建。又因为cacheEnabled在未指定的情况下为true(构建configuration时确定),所以最终返回的executor属于CachingExecutor对象。
当执行器 executor 构造好之后,再通过 new DefaultSqlSession(this.configuration, executor, autoCommit)创建DefaultSqlSession 对象,而 DefaultSqlSession 类又是SqlSession接口的实现,所以创建的对象实际上是SqlSession的实例,也说明创建了一次会话。
2.1.2、获取映射
获取映射采用了代理的设计模式,使得通过getMapper方法代理之后的UserMapper类的对象可以使用SqlSession类中的功能。这个代理过程稍微有点绕,但通过debug调试的话也可以清晰地了解其流程,因为实现该流程的代码比较简洁。M我画了一个简易流程图表示其代理过程。(方框内的表示该类中的方法)

其中代理的最主要环节集中在 MapperProxyFactory.class 中,首先通过newInstance(SqlSession sqlSession)方法将传入的sqlSession封装在MapperProxy中并生成实例对象mapperProxy(MapperProxy 实现了InvocationHandler接口)。然后调用newInstance(MapperProxy方法,并传入参数mapperProxy,再通过Proxy类中的newProxyInstance方法完成最后的代理过程,使得mapper成为代理类的对象。具体的代码如下所示:
public T newInstance(SqlSession sqlSession) {
MapperProxy<T> mapperProxy = new MapperProxy(sqlSession,
this.mapperInterface, this.methodCache);
return this.newInstance(mapperProxy);
}
protected T newInstance(MapperProxy<T> mapperProxy) {
return Proxy.newProxyInstance(this.mapperInterface.getClassLoader(),
new Class[]{this.mapperInterface}, mapperProxy);
}
在Debug模式下按 alt+F8 ,输入对象的名称可以得到其完整的结构。mapper对象的结构如下所示:

从图中可以看出,mapper已经转变成代理对象,映射体系也已通过mapperInterface构成。而映射的建立过程则主要发生在 MapperAnnotationBuilder 类中,通过parse方法建立映射和完成配置,其中,SQL语句和参数配置的解析通过 parseStatement 方法完成。
//MapperAnnotationBuilder.class
public void parse() { //该方法从MapperRegistry类的addMapper方法中进入
String resource = this.type.toString();
if (!this.configuration.isResourceLoaded(resource)) {
this.loadXmlResource(); //加载xml资源
this.configuration.addLoadedResource(resource); //添加加载资源
this.assistant.setCurrentNamespace(this.type.getName()); //设置当前命名空间
this.parseCache(); //解析缓存
this.parseCacheRef(); //解析缓存引用
Method[] methods = this.type.getMethods();
Method[] var3 = methods;
int var4 = methods.length;
for(int var5 = 0; var5 < var4; ++var5) {
Method method = var3[var5];
try {
if (!method.isBridge()) {
this.parseStatement(method); //解析方法中的sql注解语句
}
} catch (IncompleteElementException var8) {
this.configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
this.parsePendingMethods();
}
2.1.3、执行SQL
调用 UserMapper 的方法将触发代理对象中 InvocationHandlerd对象 的 invoke 方法(在MapperProxy类中),然后通过 invoke 方法中的mapperMethod.execute(this.sqlSession, args)执行对应的SQL语句,不过在此之前需要先构造mapperMethod,获得SqlCommand,因为它包含了具体的SQL语句name和执行类型type。具体的execute方法执行过程如下所示:
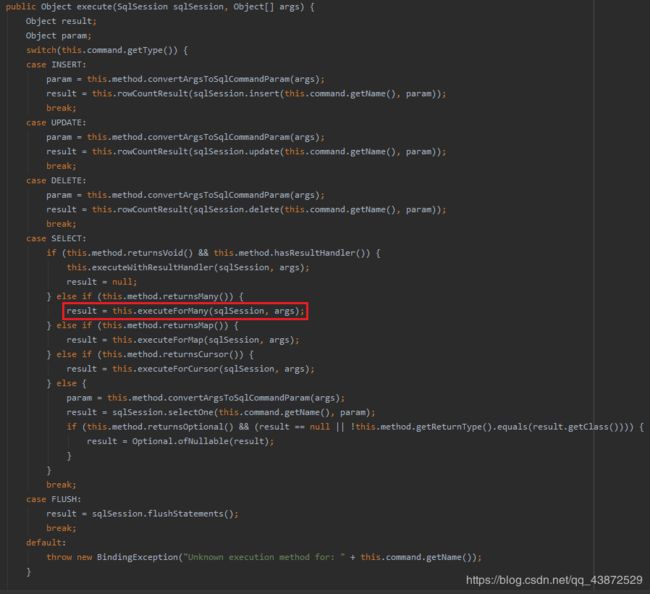
其中的 excuteForMany 方法实现如下:

从以上代码可以看出,增删改查和刷新最终都是由SqlSession对象来完成,而SqlSession对象的方法实现都在 DefaultSqlSession 类中,如下所示:
/** DefaultSqlSession.class **/
//修改
public int update(String statement, Object parameter) {
int var4;
try {
this.dirty = true;
MappedStatement ms = this.configuration.getMappedStatement(statement);
//通过执行器executor执行update操作
var4 = this.executor.update(ms, this.wrapCollection(parameter));
} catch (Exception var8) {
throw ExceptionFactory.wrapException("Error updating database. Cause: " + var8, var8);
} finally {
ErrorContext.instance().reset();
}
return var4;
}
//删除
public int delete(String statement, Object parameter) {
//转到update方法中实现删除操作
return this.update(statement, parameter);
}
//插入
public int insert(String statement, Object parameter) {
//转到update方法中实现插入操作
return this.update(statement, parameter);
}
//查找
public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
MappedStatement ms = this.configuration.getMappedStatement(statement);
//通过执行器executor执行query操作
this.executor.query(ms, this.wrapCollection(parameter), rowBounds, handler);
} catch (Exception var9) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + var9, var9);
} finally {
ErrorContext.instance().reset();
}
}
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
List var5;
try {
MappedStatement ms = this.configuration.getMappedStatement(statement);
//通过执行器executor执行query操作(默认没有结果集处理)
var5 = this.executor.query(ms, this.wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception var9) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + var9, var9);
} finally {
ErrorContext.instance().reset();
}
return var5;
}
//会话提交
public void commit(boolean force) {
try {
//通过执行器executor执行commit操作
this.executor.commit(this.isCommitOrRollbackRequired(force));
this.dirty = false;
} catch (Exception var6) {
throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + var6, var6);
} finally {
ErrorContext.instance().reset();
}
}
//会话关闭
public void close() {
try {
//通过执行器executor执行close操作
this.executor.close(this.isCommitOrRollbackRequired(false));
this.closeCursors();
this.dirty = false;
} finally {
ErrorContext.instance().reset();
}
}
//刷新
public List<BatchResult> flushStatements() {
List var1;
try {
//通过执行器executor执行flushStatements操作
var1 = this.executor.flushStatements();
} catch (Exception var5) {
throw ExceptionFactory.wrapException("Error flushing statements. Cause: " + var5, var5);
} finally {
ErrorContext.instance().reset();
}
return var1;
}
其中,插入和删除的方法实现都需要依赖修改方法,并且最终都是使用Executor执行器中的update();而查找方法的实现则是使用Executor执行器中的query();刷新以及会话提交和关闭方法则对应Executor执行器中的flushStatements()、commit()和close()。所以无论执行哪个方法,都会转到Executor执行器中执行对应的方法。
注意,在执行增删改查的方法时,都传入了一个参数:statement,然后通过 this.configuration.getMappedStatement(statement) 语句获取一个 MappedStatement类的对象,并作为参数转交给Executor执行器。该类在MyBatis的缓存机制中起到了重要作用,具体内容会在之后进行详细介绍。
2.2、Executor执行器层分析

通过会话层的分析,执行查询和修改的任务转到Executor执行器中,并通过装饰器模式将执行器封装成CachingExecutor对象,再通过其delegate属性指向BaseExecutor。这种构造方法是为了进一步扩展功能,在 BaseExecutor 中实现一级缓存逻辑的基础上,再在 CachingExecutor 中实现二级缓存逻辑。因为一级缓存是会话级缓存,为了能够让不同会话间共享缓存,使用二级缓存逻辑来实现应用级缓存的功能。
2.2.1、执行流程
从上图中可以很清晰地看出执行器层主要的执行逻辑,现在通过具体的代码进行分析,为了避免篇幅过长,分析的对象主要选择为查询query和修改update。
/** CachingExeuctor.class **/
// 查询
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
/** 获取二级缓存功能 **/
Cache cache = ms.getCache();
if (cache != null) {
this.flushCacheIfRequired(ms); //指定条件下清除二级缓存
if (ms.isUseCache() && resultHandler == null) {
this.ensureNoOutParams(ms, boundSql);
//从事务缓存管理器中获取缓存数据
List<E> list = (List)this.tcm.getObject(cache, key);
if (list == null) {
//如果没有获得二级缓存数据,即通过BaseExecutor执行查询过程
list = this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//获取的数据存放到事务缓存管理器中
this.tcm.putObject(cache, key, list);
}
return list; //返回数据
}
}
//如果未开启二级缓存功能,直接通过BaseExecutor执行查询过程
return this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
// 更新
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
//如果sql语句不是select类型,flushCache默认为true
this.flushCacheIfRequired(ms);
//通过BaseExecutor执行更新过程
return this.delegate.update(ms, parameterObject);
}
即执行查询和修改的任务从CachingExecutor转到BaseExecutor中。
/** BaseExecutor.class **/
// 查询
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (this.closed) {
throw new ExecutorException("Executor was closed.");
} else {
if (this.queryStack == 0 && ms.isFlushCacheRequired()) {
this.clearLocalCache(); //指定条件下清除一级缓存
}
List list;
try {
++this.queryStack;
//从缓存区localCache中获取数据
list = resultHandler == null ? (List)this.localCache.getObject(key) : null;
if (list != null) {
//如果获得一级缓存数据,则处理对应的参数
this.handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//如果没有获得一级缓存数据,即从数据库中查询(跳转到queryFromDatabase方法中)
list = this.queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
--this.queryStack;
}
/** 省略部分代码... **/
}
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// 在一级缓存区中预添加数据,其值为占位符
this.localCache.putObject(key, ExecutionPlaceholder.EXECUTION_PLACEHOLDER);
List list;
try {
//通过子类实现的doQuery方法实现修改过程
list = this.doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
//清除预添加的数据
this.localCache.removeObject(key);
}
//将实际查询的结果添加到一级缓存区中
this.localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
//如果statement处理器类型为callableStatement,即需要设置出参
this.localOutputParameterCache.putObject(key, parameter);
}
return list;
}
// 修改
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (this.closed) {
throw new ExecutorException("Executor was closed.");
} else {
this.clearLocalCache(); //清理一级缓存
//通过子类实现的doUpdate方法实现修改过程
return this.doUpdate(ms, parameter);
}
}
即执行查询和修改的任务从BaseExecutor转到其子类执行器中,而该子类执行器是通过executorType指定的,现以ReuseExecutor为例进行分析。
/** ReuseExecutor.class **/
// 查询
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this.wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
Statement stmt = this.prepareStatement(handler, ms.getStatementLog());
//通过StatementHandler对象处理查询过程
return handler.query(stmt, resultHandler);
}
// 修改
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, (ResultHandler)null, (BoundSql)null);
Statement stmt = this.prepareStatement(handler, ms.getStatementLog());
//通过StatementHandler对象处理修改过程
return handler.update(stmt);
}
从以上代码可以看出,Executor执行器层的主要的功能是为了实现一级缓存和二级缓存的功能,其中还包括嵌套子查询和延时加载等功能,它的查询和修改过程最后都交给了StatementHandler 对象,通过它与数据库进行交互并且进行参数处理和结果集处理等操作。
2.2.2、一级缓存
虽然按照执行流程来说,二级缓存的执行在一级缓存之前,但是相对来说一级缓存更加简单,所以先介绍一级缓存。
从执行流程分析的过程中可以发现,在 BaseExecutor 类中,关于缓存的存取操作都发生在localCache上,说明它是一级缓存中的缓存区管理者,而 localCache 是 PerpetualCache 类的对象,且该类的结构如下所示:
public class PerpetualCache implements Cache {
private final String id;
private Map<Object, Object> cache = new HashMap();
public int getSize() {
return this.cache.size();
}
public void putObject(Object key, Object value) {
this.cache.put(key, value);
}
public Object getObject(Object key) {
return this.cache.get(key);
}
public Object removeObject(Object key) {
return this.cache.remove(key);
}
public void clear() {
this.cache.clear();
}
}
根据 PerpetualCache 类的结构可以看出, localCache 中的属性 cache表示的是一级缓存的缓存区,而且由HashMap构成。通过调用 localCache 中的方法,对实际的缓存区cache 进行操作。其查询的过程如下图所示:
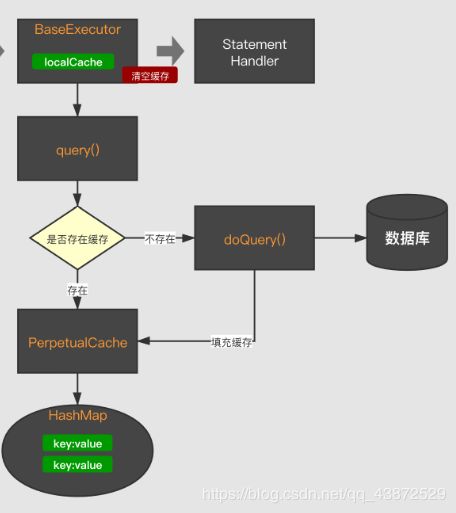
2.2.3、二级缓存
在此前曾讲到过MappedStatement类的对象作为参数从会话层转交到执行器层,并且在CachingExecutor类中需要通过它进行二级缓存功能的获取,即Cache cache = ms.getCache()语句。
那么MappedStatement类中如何生成对应的cache呢?之前是通过Configuration获取ID(String类型)为statement的实例,所以它肯定存在一个添加数据的过程。通过Debug调试发现,在MapperBuilderAssistant.class中有相关步骤:
/** MapperBuilderAssistant.class **/
public MappedStatement addMappedStatement(String id, SqlSource sqlSource, StatementType statementType, SqlCommandType sqlCommandType, Integer fetchSize, Integer timeout, String parameterMap, Class<?> parameterType, String resultMap, Class<?> resultType, ResultSetType resultSetType, boolean flushCache, boolean useCache, boolean resultOrdered, KeyGenerator keyGenerator, String keyProperty, String keyColumn, String databaseId, LanguageDriver lang, String resultSets) {
if (this.unresolvedCacheRef) {
throw new IncompleteElementException("Cache-ref not yet resolved");
} else {
id = this.applyCurrentNamespace(id, false);
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
//构造一个内部类Builder对象statementBuilder
/*关键*/org.apache.ibatis.mapping.MappedStatement.Builder statementBuilder = (new org.apache.ibatis.mapping.MappedStatement.Builder(this.configuration, id, sqlSource, sqlCommandType)).resource(this.resource).fetchSize(fetchSize).timeout(timeout).statementType(statementType).keyGenerator(keyGenerator).keyProperty(keyProperty).keyColumn(keyColumn).databaseId(databaseId).lang(lang).resultOrdered(resultOrdered).resultSets(resultSets).resultMaps(this.getStatementResultMaps(resultMap, resultType, id)).resultSetType(resultSetType).flushCacheRequired((Boolean)this.valueOrDefault(flushCache, !isSelect)).useCache((Boolean)this.valueOrDefault(useCache, isSelect)).cache(this.currentCache);
ParameterMap statementParameterMap = this.getStatementParameterMap(parameterMap, parameterType, id);
if (statementParameterMap != null) {
statementBuilder.parameterMap(statementParameterMap);
}
MappedStatement statement = statementBuilder.build();
//通过Configuration添加生成的MappedStatement对象
this.configuration.addMappedStatement(statement);
return statement;
}
}
/** Configuration.class **/
public void addMappedStatement(MappedStatement ms) {
//通过ID值添加对应的数据
this.mappedStatements.put(ms.getId(), ms);
}
MappedStatement对象添加的过程清楚了,那现在需要找到生成cache的地方。请继续查看以上代码,在关键的那一行末尾处,使用了cache方法,即 cache(this.currentCache):
public MappedStatement.Builder cache(Cache cache) {
this.mappedStatement.cache = cache;
return this;
}
说明它将 MapperBuilderAssistant 类中的 currentCache 属性值添加到 MappedStatement 对象的cache属性中,所以我们获取的cache正是来自于 currentCache ,那么接下来找到它生成的方法:
/** MapperBuilderAssistant.class **/
public Cache useNewCache(Class<? extends Cache> typeClass, Class<? extends Cache> evictionClass, Long flushInterval, Integer size, boolean readWrite, boolean blocking, Properties props) {
//通过CacheBuilder创建Cache对象
Cache cache = (new CacheBuilder(this.currentNamespace)).implementation((Class)this.valueOrDefault(typeClass, PerpetualCache.class)).addDecorator((Class)this.valueOrDefault(evictionClass, LruCache.class)).clearInterval(flushInterval).size(size).readWrite(readWrite).blocking(blocking).properties(props).build();
//将cache添加到Configuration中
this.configuration.addCache(cache);
//将Cache对象赋值给属性currentCache
this.currentCache = cache;
return cache;
}
需要先了解的是,useNewCache 方法的调用发生在解析映射注解的过程中,即在MapperAnnotationBuilder 类中的 parseCache 方法,它的主要作用是根据Mapper类中的
@CacheNamespace() 获取参数并构建二级缓存对象cache,如果没有声明缓存空间,则表示不开启二级缓存功能。
扩展:还有以下两种情况不会开启二级缓存功能:
- 设置Configuration类中的属性CacheEnabled为false:因为设置为false将不会构造CachingExecutor,所以不执行二级缓存的功能。(全局设置)
- 设置MappedStatement类中的属性useCache为false:因为设置为false将不会继续执行缓存区的存取操作,详细请看CachingExecutor类中的query方法。(局部设置)
根据以上代码,通过CacheBuilder创建Cache对象的过程中,使用了 implementation、addDecorator、clearInterval、size、readWrite、blocking、properties这七个方法来设置相应属性值,然后通过build方法生成cache对象,该过程采用了装饰器模式以及责任链模式。
public Cache build() {
//设置默认的缓存处理方式,具体实现见下一块代码
this.setDefaultImplementations();
//构建基类缓存对象cache
Cache cache = this.newBaseCacheInstance(this.implementation, this.id);
//设置与implementation相关的cache属性
this.setCacheProperties((Cache)cache);
if (PerpetualCache.class.equals(cache.getClass())) {
Iterator var2 = this.decorators.iterator();
while(var2.hasNext()) {
//逐一获取装饰器
Class<? extends Cache> decorator = (Class)var2.next();
//装饰缓存对象cache
cache = this.newCacheDecoratorInstance(decorator, (Cache)cache);
//设置与decorator相关的cache属性
this.setCacheProperties((Cache)cache);
}
//继续装饰缓存对象cache,具体实现见下一块代码
cache = this.setStandardDecorators((Cache)cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
//如果cache没有被LoggingCache装饰则通过它进行装饰
cache = new LoggingCache((Cache)cache);
}
return (Cache)cache;
}
private void setDefaultImplementations() {
if (this.implementation == null) {
this.implementation = PerpetualCache.class;
if (this.decorators.isEmpty()) {
this.decorators.add(LruCache.class);
}
}
}
private Cache setStandardDecorators(Cache cache) {
try {
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (this.size != null && metaCache.hasSetter("size")) {
//给PerpetualCache类中的cache属性设置size大小
metaCache.setValue("size", this.size);
}
if (this.clearInterval != null) { //过期清理
cache = new ScheduledCache((Cache)cache);
((ScheduledCache)cache).setClearInterval(this.clearInterval);
}
if (this.readWrite) { //实现序列化操作
cache = new SerializedCache((Cache)cache);
}
//通过日志记录命中率
Cache cache = new LoggingCache((Cache)cache);
//实现线程同步
cache = new SynchronizedCache(cache);
if (this.blocking) { //防止缓存穿透
cache = new BlockingCache((Cache)cache);
}
return (Cache)cache;
} catch (Exception var3) {
throw new CacheException("Error building standard cache decorators. Cause: " + var3, var3);
}
}
经过装饰之后,二级缓存的模型如下图所示:
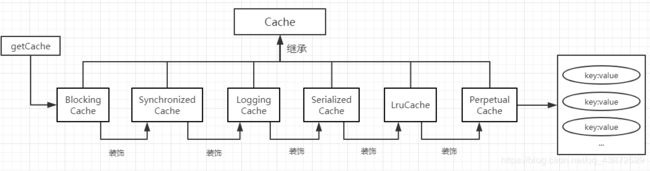
需要注意的是,默认情况下缓存的属性readWrite为false,所以不会通过BlokingCache再进行装饰。
另一个注意点是,不同会话通过同一个Mapper映射文件创建后,其MappedStatement中的cache是一致的,即二级缓存空间是一致的。因为在配置和相关映射文件被解析的过程中,会根据映射文件中二级缓存的开启情况来决定是否生成对应的唯一缓存空间。同样我们可以发现,一个映射文件对应一个缓存空间。
获取二级缓存对象之后需要与缓存区进行交互,进行相关数据的存取和清除等,二级缓存的缓存管理有两个重要概念:TransactionalCacheManager 和 TransactionalCache
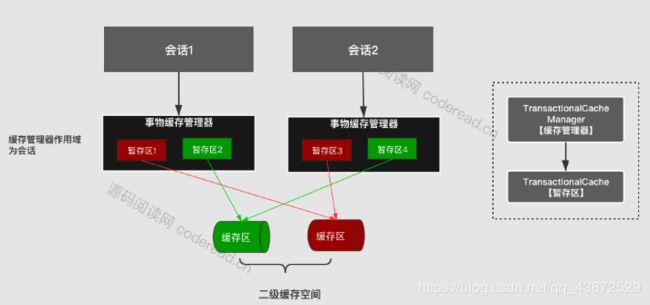
如上图所示,TransactionalCacheManager即事物缓存管理器,一次会话对应一个事物缓存管理器;TransactionalCache即暂存区,因为一次会话可以获取不同的映射文件,所以一个事物管理器对应一个或多个暂存区。
public class TransactionalCacheManager {
//事物缓存管理器通过HashMap对象transactionalCaches对应一个或多个暂存区
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap();
public void clear(Cache cache) {
this.getTransactionalCache(cache).clear();
}
public Object getObject(Cache cache, CacheKey key) {
return this.getTransactionalCache(cache).getObject(key);
}
public void putObject(Cache cache, CacheKey key, Object value) {
this.getTransactionalCache(cache).putObject(key, value);
}
private TransactionalCache getTransactionalCache(Cache cache) {
/**
* 若没有对应key为cache实例的TransactionalCache对象,则执行以下过程
* 即添加数据
* 并返回该TransactionalCache对象
*/
/**
* 若存在对应key为cache实例的TransactionalCache对象,则直接返回
*/
return (TransactionalCache)this.transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
}
/** 省略部分代码 **/
}
所以经过 TransactionalCacheManager 对象的putObject和getObject等操作,都需要进入TransactionalCache中进行相关逻辑的处理。
/** TransactionalCache.class **/
public class TransactionalCache implements Cache {
private static final Log log = LogFactory.getLog(TransactionalCache.class);
private final Cache delegate; //装饰了二级缓存空间
private boolean clearOnCommit; //缓存清除标志
private final Map<Object, Object> entriesToAddOnCommit; //具体的暂存空间
private final Set<Object> entriesMissedInCache; //与缓存穿透相关
public Object getObject(Object key) {
//获取缓存数据
Object object = this.delegate.getObject(key);
if (object == null) {
this.entriesMissedInCache.add(key);
}
//当清除标志为false时才返回object
return this.clearOnCommit ? null : object;
}
public void putObject(Object key, Object object) {
//将数据存放到暂存空间中
this.entriesToAddOnCommit.put(key, object);
}
public void clear() {
this.clearOnCommit = true; //设置清除标志为true
this.entriesToAddOnCommit.clear(); //清空暂存空间的数据
}
public void commit() {
if (this.clearOnCommit) {
//如果清除标志为true则清空缓存空间的数据
this.delegate.clear();
}
this.flushPendingEntries(); //刷新暂存空间的数据
this.reset(); //重置暂存区
}
private void flushPendingEntries() {
Iterator var1 = this.entriesToAddOnCommit.entrySet().iterator();
//遍历暂存空间,将暂存数据转到缓存空间中
while(var1.hasNext()) {
Entry<Object, Object> entry = (Entry)var1.next();
this.delegate.putObject(entry.getKey(), entry.getValue());
}
var1 = this.entriesMissedInCache.iterator();
//将未查找到的数据以null值存放到缓存空间中
while(var1.hasNext()) {
Object entry = var1.next();
if (!this.entriesToAddOnCommit.containsKey(entry)) {
this.delegate.putObject(entry, (Object)null);
}
}
}
/** 省略部分代码 **/
}
从TransactionalCache类的实现代码中可以看出,当 putObject 时只是暂时将数据存放在暂存空间中,只有通过执行commit提交之后才会将数据转到二级缓存空间中。
2.3、StatementHandler层分析
通过执行器层的分析,数据的查询和修改操作都发生在StatementHandler层中,与数据库直接进行交互。现在仍以 ReuseExecutor 为例开始进行分析,选择其中的 doQuery 方法:
/** ReuseExecutor.class **/
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
//获取配置信息configuration
Configuration configuration = ms.getConfiguration();
//通过配置生成StatementHandler处理器对象handler
StatementHandler handler = configuration.newStatementHandler(this.wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//为需要处理的SQL语句设置相关参数,即Statement对象stmt
Statement stmt = this.prepareStatement(handler, ms.getStatementLog());
//通过处理器handler执行query操作
return handler.query(stmt, resultHandler);
}
- 创建处理器对象handler的过程如下:
/** Configuration.class **/
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//通过RoutingStatementHandler来选择具体的处理器对象,如下所示
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
//如果存在拦截器则装饰StatementHandler对象
StatementHandler statementHandler = (StatementHandler)this.interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
/** RoutingStatementHandler.class **/
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//通过StatementType来选择具体的处理器
//默认情况下使用的是PreparedStatementHandler
switch(ms.getStatementType()) {
case STATEMENT:
this.delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
this.delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
this.delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
结构如下图所示:

- 为需要处理的SQL语句设置相关参数的过程如下:
/** ReuseExecutor.class **/
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
//获取handler对象需要处理的SQL语句
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql();
Statement stmt;
//从statementMap中查询是否有sql对应的处理对象
if (this.hasStatementFor(sql)) {
//如果存在则直接获取处理对象stmt
stmt = this.getStatement(sql);
this.applyTransactionTimeout(stmt);
} else {
//如果不存在即先获取连接,然后设置相应的处理参数
Connection connection = this.getConnection(statementLog);
stmt = handler.prepare(connection, this.transaction.getTimeout());
//并将该处理对象stmt存放到statementMap中
this.putStatement(sql, stmt);
}
//处理sql参数映射
handler.parameterize(stmt);
return stmt;
}
- 通过处理器handler执行query操作的过程如下:
/** PreparedStatementHandler.class **/
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement)statement;
ps.execute(); //执行处理
//返回处理后的结果集
return this.resultSetHandler.handleResultSets(ps);
}
值得注意的是, ps 是一个代理类对象,实际调用 execute 方法是在 ClientPreparedStatement 类中,而具体的方法实现较复杂,这里不作描述。该方法得到一个 ResultSetImpl 对象,即通过数据库查询到的数据,然后在调用 handleResultSets 方法处理结果集时使用的也正是该对象。
本文的主要分析思路是按照MyBatis的执行过程进行的,从SqlSession到Executor,再到StatementHandler,总体分析了查询和修改的操作是怎么一步一步往下进行的,在分析的过程中涉及了较多代码,其中也包括了我的一些观点和看法,较为详细地解释了具体的步骤,而为了避免篇幅过于冗长,就没有进行太多的扩展介绍,所以有些地方可能会使读者产生疑惑和不解,在此还请希望各位读者小伙伴们能够见谅。