爬取京东评论并制作词云图
jieba库
jieba库是python的第三方中文分词库,利用jieba可以更好的实现中文分词。
jieba.cut 方法接受三个输入参数: sentence需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型。
jieba.cut_for_search 方法接受两个参数:需要分词的字符串;是否使用 HMM 模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细。
jieba支持三种分词模式:
a. 精确模式,试图将句子最精确地切开,适合文本分析;
b. 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
c. 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
2.分词更加准确的两种方法
(1)添加自定义词典
载入词典:开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径,可以按照自己定义的词典进行分词
词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码(保存为txt文件时保存类型更改为UTF-8 编码)。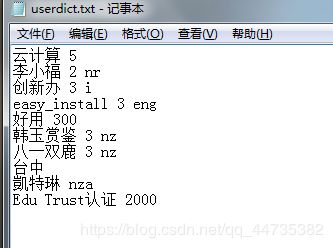
词频省略时使用自动计算的能保证分出该词的词频
(2)调整词典:
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
jieba.add_word可以 增加字典内容,比如有效解决“路明非”被分为路明和明非,将容易分错的词语可以通过此方式添加
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
import jieba
print('='*40)
print('添加自定义词典/调整词典')
print('-'*40)
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中将/出错/。
# 调整词典使 中将 变为中/将
print(jieba.suggest_freq(('中', '将'), True))
#494
print('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))
#如果/放到/post/中/将/出错/。
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台/中/」/正确/应该/不会/被/切开
print(jieba.suggest_freq('台中', True))
#69
# 调整词典使 台中 不被分词为台/中
print('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))
#「/台中/」/正确/应该/不会/被/切开
wordcloud库
1安装wordcloud库
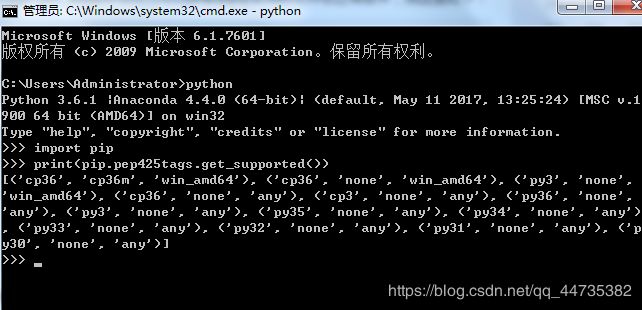
先看看所安装的python适合哪个版本,然后去https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud下载对应的wordcloud版本(本机python pip命令匹配的版本是wordcloud-1.6.0-cp36-cp36m-win_amd64.whl这个文件)
win+r 输入 cmd 打开命令窗口,输入 cd 切换到你下载到的那个文件夹,然后输入pip install wordcloud-1.6.0-cp36-cp36m-win_amd64.whl,回车即可安装。
2.wordcloud使用
wordcloud把词云当作一个对象,它可以将文本中词语出现的频率作为一个参数绘制词云,而词云的大小、颜色、形状等都是可以设定的。
主要是依据单词出现的频率来绘图,因此我们应该过滤一些词即停用表(网上下载即可)
京东爬取评论
利用requests库
打开所要研究的商品页,进入调试窗口,加载数据,找到network
复制一段评论,利用ctrl+F调出搜索框 ,粘贴搜索,找到出现的数据,点击headers可以拿到京东评论数据的接口,preview可以评论数据所对应的键(comments),其中content为用户的评论内容
import requests
import os
import json
import time
import random
from wordcloud import WordCloud, ImageColorGenerator
from os import path
#from scipy.misc import imread
import matplotlib.pyplot as plt
from matplotlib.pyplot import imread
import jieba
import numpy
COMMENT_FILE_PATH='jd_comments.txt'#文件名
d = path.dirname(__file__)# 获取当前文件路径
def spider_comment(page=0):#爬取
url='https://club.jd.com/comment/productPageComments.action?........page=%s&pageSize=10&isShadowSku=0&fold=1'%page#%s为page增加的占位符,设置page参数递增
headers={'user-agent': 'Mozilla/5.0','referer': 'https://item.jd.com/100008643290.html'}#两个请求头
try:
r = requests.get(url, headers=headers, timeout=30)
r.raise_for_status()
#r.encoding = r.apparent_encoding
#print("网页请求成功!"+r.text[:500])
#return r.text
except:
print("网页请求失败")
r_json_str = r.text[26:-2]#截取json数据字符串
r_json_obj = json.loads(r_json_str)#字符串转json对象
r_json_comments=r_json_obj['comments']#获取评价列表数据
print('某京东数据:')
for r_json_comment in r_json_comments:#遍历评论对象列表
with open(COMMENT_FILE_PATH,'a+') as file:#以追加模式写入每行评价
file.write(r_json_comment['content']+'\n')
print(r_json_comment['content'])#打印评论
def batch_spider_comment():
if os.path.exists(COMMENT_FILE_PATH):#写入文件前先清空数据
os.remove(COMMENT_FILE_PATH)
for i in range(5):#爬取100页
spider_comment(i)
time.sleep(random.random()*5)#模拟用户浏览,设置爬虫间隔,防止ip被封
return COMMENT_FILE_PATH
# 添加自己的词库分词
#def add_word(list):
#for items in list:
#jieba.add_word(items)
def jiebaclearText(text):
# my_words_list = ['供给侧'] # 在结巴的词库中添加新词
# add_word(my_words_list)
mywordlist = []
stopwords_path = 'stopwords1893.txt' # 停用词词表
seg_list = jieba.cut(text, cut_all=False)
liststr="/ ".join(seg_list)
f_stop = open(stopwords_path)
try:
f_stop_text = f_stop.read( )
f_stop_text=str(f_stop_text)
finally:
f_stop.close( )
f_stop_seg_list=f_stop_text.split('\n')
for myword in liststr.split('/'):
if not(myword.strip() in f_stop_seg_list) and len(myword.strip())>1:
mywordlist.append(myword)
return ''.join(mywordlist)
def set_background(back_coloring_path):#设置生成词云图的背景图片
back_coloring = imread(path.join(d, back_coloring_path)) # 设置背景图片
return back_coloring
def create_word_cloud(text_jieba,back_coloring):
font_path = 'D:\Documents\simkai.ttf' # 为matplotlib设置中文字体路径没
# 设置词云属性
wc = WordCloud(font_path=font_path, # 设置字体
collocations=False,#去重
background_color="white", # 背景颜色
max_words=2000, # 词云显示的最大词数
mask=back_coloring, # 设置背景图片
max_font_size=100, # 字体最大值
random_state=42,
width=1000, height=860, margin=2, # 设置图片默认的大小,但是如果使用背景图片的话,那么保存的图片大小将会按照其大小保存,margin为词语边缘距离
)
wc.generate(text_jieba)
# 生成词云, 可以用generate输入全部文本(wordcloud对中文分词支持不好,建议启用中文分词),也可以我们计算好词频后使用generate_from_frequencies函数
plt.figure()
# 以下代码显示图片
plt.imshow(wc)
plt.axis("off")
plt.show()
# 绘制词云
wc.to_file(path.join(d, imgname1)) # 保存图片,保存到该文件夹下,且为图片命名
if __name__ == '__main__':
stopwords = {}
#isCN = 1 # 默认启用中文分词
text_path =batch_spider_comment() # 设置要分析的文本路径
back_coloring_path = "heart2.jpg" # 设置背景图片路径
text = open(path.join(d, text_path)).read()
text_jieba = jiebaclearText(text)
imgname1 = "jdDefautColors.png" # 保存的图片名字1(只按照背景图片形状)
back_coloring =set_background(back_coloring_path)
create_word_cloud(text_jieba,back_coloring)
感谢:
https://blog.csdn.net/u014044812/article/details/95198791
https://blog.csdn.net/FontThrone/article/details/72782971