MySQL学习记录(五)—— 简单项目实战
数据表的导入导出
Workbench 导出之前创建的 email 数据表为 CSV 格式文件
将光标放在 email 表附近右键鼠标,选择 Table Data Export Wizard,按照弹出窗口的指示一步一步进行:
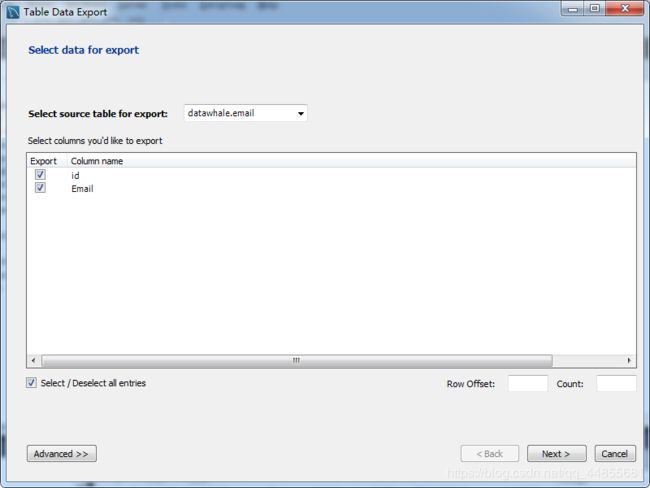
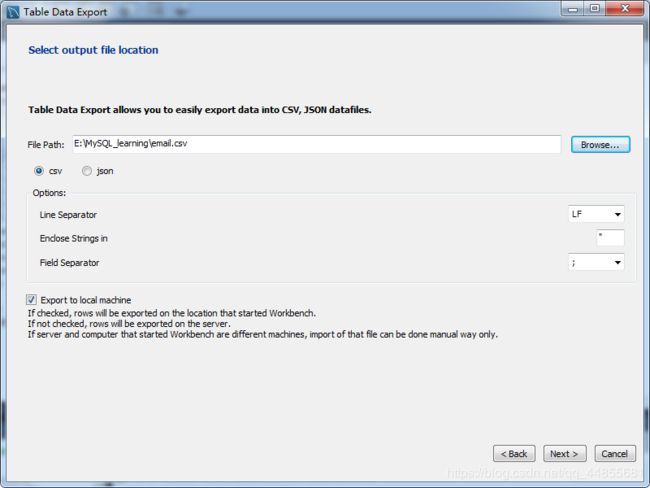
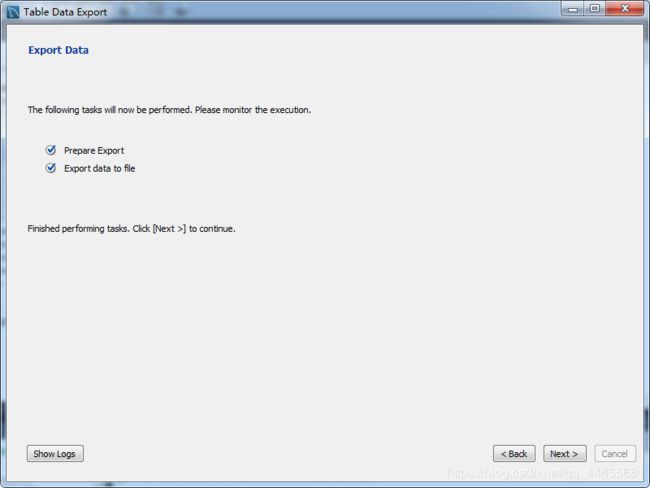
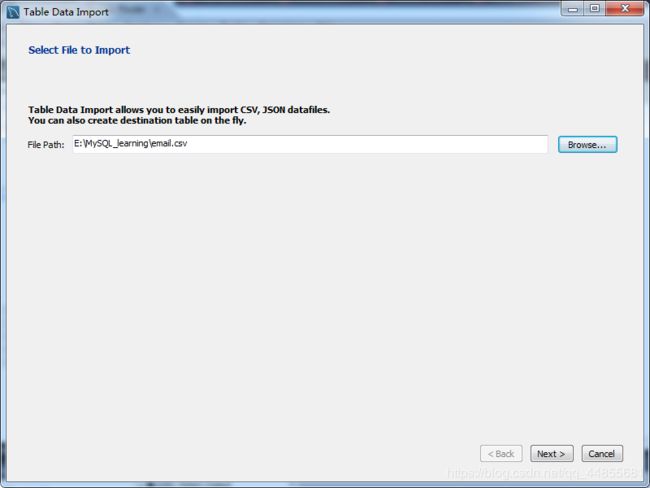
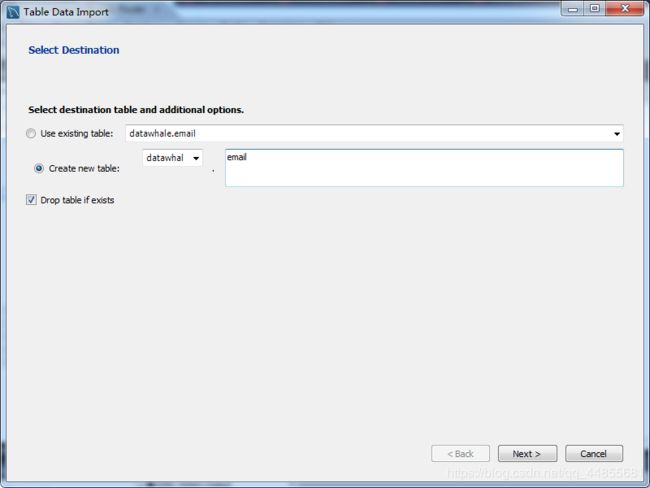
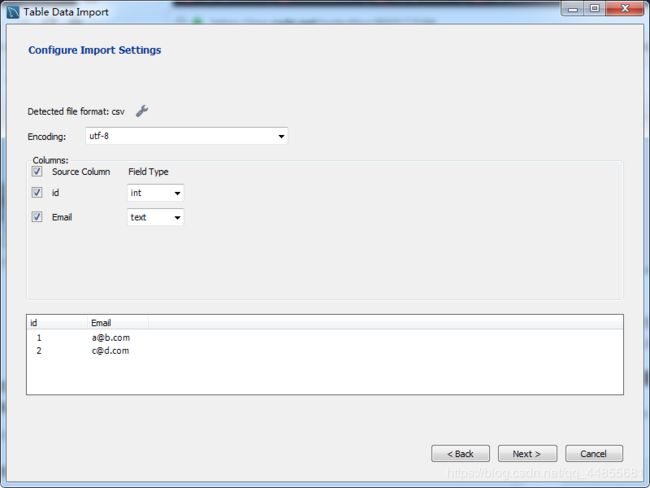
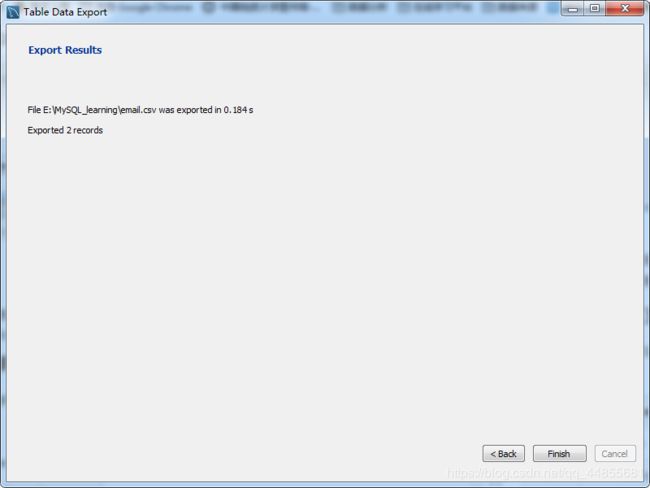 将 CSV 文件导入 MySQL:
将 CSV 文件导入 MySQL:


项目七: 各部门工资最高的员工(难度:中等)
创建Employee 表,包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
| Id | Name | Salary | DepartmentId |
|---|---|---|---|
| 1 | Joe | 70000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
创建Department 表,包含公司所有部门的信息。
| Id | Name |
|---|---|
| 1 | IT |
| 2 | Sales |
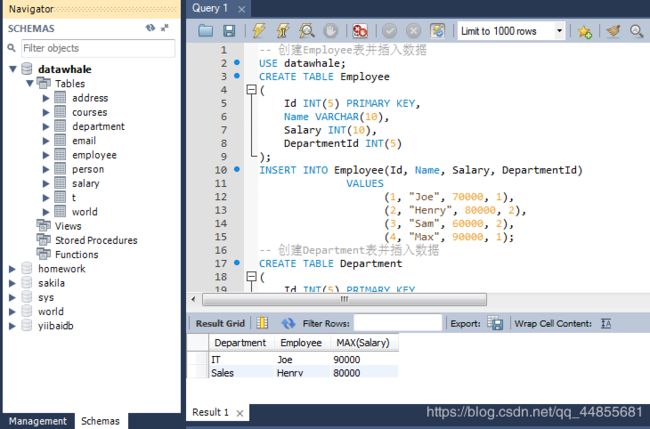
编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
| Department | Employee | Salary |
|---|---|---|
| IT | Max | 90000 |
| Sales | Henry | 80000 |
-- 创建Employee表并插入数据
USE datawhale;
CREATE TABLE Employee
(
Id INT(5) PRIMARY KEY,
Name VARCHAR(10),
Salary INT(10),
DepartmentId INT(5)
);
INSERT INTO Employee(Id, Name, Salary, DepartmentId)
VALUES
(1, "Joe", 70000, 1),
(2, "Henry", 80000, 2),
(3, "Sam", 60000, 2),
(4, "Max", 90000, 1);
-- 创建Department表并插入数据
CREATE TABLE Department
(
Id INT(5) PRIMARY KEY,
Name VARCHAR(10)
);
INSERT INTO Department(Id, Name)
VALUES
(1, "IT"),
(2, "Sales");
-- 将两个表按照部门编号进行内联结保存为新表 t ,再根据部门分组找出最高工资
CREATE TABLE t AS
SELECT d.Name Department, e.Name Employee, e.Salary
FROM Employee e INNER JOIN Department d
ON e.DepartmentId = d.Id;
SELECT Department, Employee, MAX(Salary)
FROM t
GROUP BY Department;
项目八: 换座位(难度:中等)
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。
其中纵列的 id 是连续递增的
小美想改变相邻俩学生的座位。
你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
请创建如下所示seat表:
示例:
| id | student |
|---|---|
| 1 | Abbot |
| 2 | Doris |
| 3 | Emerson |
| 4 | Green |
| 5 | Jeames |
假如数据输入的是上表,则输出结果如下:
| id | student |
|---|---|
| 1 | Doris |
| 2 | Abbot |
| 3 | Green |
| 4 | Emerson |
| 5 | Jeames |
注意:如果学生人数是奇数,则不需要改变最后一个同学的座位。
-- 创建seat表并插入数据
CREATE TABLE seat
(
id INT(10) PRIMARY KEY,
student VARCHAR(10)
);
INSERT INTO seat(id, student)
VALUES
(1, "Abbot"),
(2, "Doris"),
(3, "Emerson"),
(4, "Green"),
(5, "Jeames");
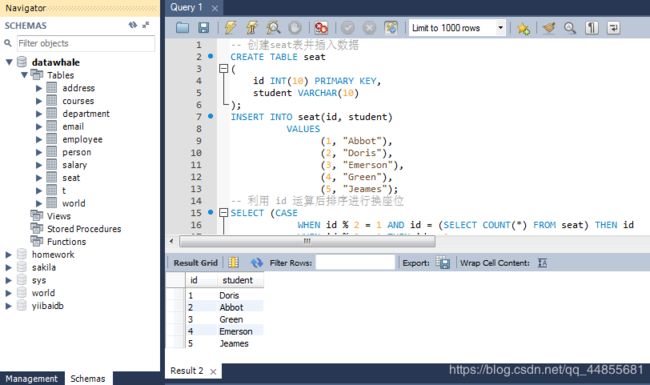
-- 利用 id 运算后排序进行换座位
SELECT (CASE
WHEN id % 2 = 1 AND id = (SELECT COUNT(*) FROM seat) THEN id
WHEN id % 2 = 1 THEN id + 1
ELSE id - 1
END) AS id,
student
FROM seat
ORDER BY id ASC;
项目九: 分数排名(难度:中等)
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
创建以下score表:
| Id | Score |
|---|---|
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
| Score | Rank |
|---|---|
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
-- 创建score表并插入数据
CREATE TABLE score
(
Id INT(10) PRIMARY KEY,
Score FLOAT(4)
);
INSERT INTO score(Id, Score)
VALUES(1, 3.50),
(2, 3.65),
(3, 4.00),
(4, 3.85),
(5, 4.00),
(6, 3.65);
-- 用内联结,条件是左表的分数小于等于右表的分数,根据id分组后,统计右表分数的个数
SELECT s1.Score, COUNT(DISTINCT s2.Score) Rank
FROM Score s1 INNER JOIN Score s2
ON s1.Score <= s2.Score
GROUP BY s1.Id
ORDER BY s1.Score DESC;
