MySQL使用存储过程30秒插入百万数据!!!
来了,老弟!!!没有骗你,30秒插入了百万数据!!!
坐稳了,开车了。。。
直接写个存储过程
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 1000000
DO
INSERT INTO duplicated_user(name) VALUES ('edgar');
SET i = i + 1;
END WHILE;
END
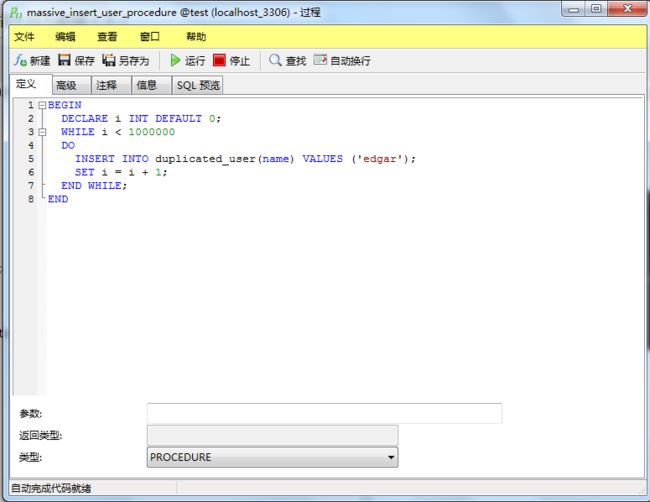
我这里直接在MySQL5.7连接器的界面写的存储过程,如果你是命令行写的话:
mysql> delimiter $$$
mysql> create procedure search()
-> BEGIN
-> DECLARE i INT DEFAULT 0;
-> WHILE i < 1000000
-> DO
-> INSERT INTO duplicated_user(name) VALUES ('edgar');
-> SET i = i + 1;
-> END WHILE;
-> END
-> $$$
mysql> delimiter;
call search();
用了22分钟才跑完。。。what???这是要翻车的节奏么!!!
不要着急,接着往下看:
我们接下来对MySQL做个优化:
- 设置 innodb_flush_log_at_trx_commit = 0 ,相对于 innodb_flush_log_at_trx_commit = 1 可以十分明显的提升导入速度;
- 修改参数 bulk_insert_buffer_size, 调大批量插入的缓存;
- 合并多条 insert 为一条.
show VARIABLES like 'innodb_flush_log_at_trx_commit';
这个参数默认为1的,我们把它设置成0。
set global innodb_flush_log_at_trx_commit = '0';
如果报以下的错误
[SQL] set global innodb_flush_log_at_trx_commit = '0';
[Err] 1193 - Unknown system variable 'innodb_flush_log_at_trx_commit'
关于innodb_flush_log_at_trx_commit这个参数详解请戳这篇博文:
MySQL中的innodb_flush_log_at_trx_commit参数
那我们直接在安装目录为my.ini的文件直接修改innodb_flush_log_at_trx_commit =0就生效了。
show VARIABLES like 'bulk_insert_buffer_size';
一般插入缓存的大小为8388608=8M,我们可以设置成16-100M,具体的看你插入的数据量。
Myisam : 对于Myisam类型的表,可以通过以下方式快速的导入大量的数据。
ALTER TABLE tblname DISABLE KEYS;loading the data ALTER TABLE tblname ENABLE KEYS; 这两个命令用来打开或者关闭Myisam表非唯一索引的更新。在导入大量的数据到一个非空的Myisam表时,通过设置这两个命令,可以提高导入的效率。对于导入大量数据到一个空的Myisam表,默认就是先导入数据然后才创建索引的,所以不用进行设置
Innodb : 对于Innodb类型的表,有以下几种方式可以提高导入的效率:
1、因为Innodb类型的表是按照主键的顺序保存的,所以将导入的数据按照主键的顺序排列,可以有效的提高导入数据的效率。如果Innodb表没有主键,那么系统会默认创建一个内部列作为主键,所以如果可以给表创建一个主键,将可以利用这个优势提高导入数据的效率。
2、在导入数据前执行SET UNIQUE_CHECKS=0,关闭唯一性校验,在导入结束后执行SET UNIQUE_CHECKS=1,恢复唯一性校验,可以提高导入的效率。
3、如果应用使用自动提交的方式,建议在导入前执行SET AUTOCOMMIT=0,关闭自动提交,导入结束后再执行SET AUTOCOMMIT=1,打开自动提交,也可以提高导入的效率。
而我创建的是Innodb类型的表
先查看下面两个参数,如果为on的话,我们需要设置它们为off
show VARIABLES like 'UNIQUE_CHECKS '
show VARIABLES like 'AUTOCOMMIT'
set session UNIQUE_CHECKS off;
set session AUTOCOMMIT off;
一顿操作后,再执行刚才那个插入100万的存储过程,好家伙,cpu占用率跳到了70%左右,30秒就把100万的数据插入完成了。