决策树的基本原理--学习于实验楼
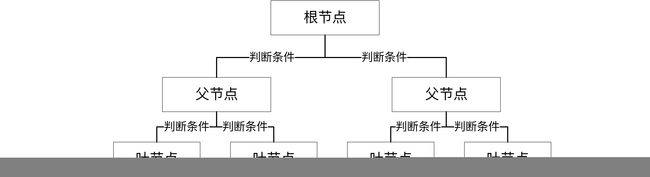
决策树是一种特殊的树形结构,一般由节点和有向边组成,其中,节点表示特征,属性,或者一个类,而有向边包含判断条件
如图所示,决策树从根节点开始延伸经过不同的判断条件后,到达不同的子节点,而上层子节点又可以作为父节点被进一步划分为下层子节点,一般情况下,我们从根节点输入数据,经过多次判断后,这些数据就会被划分到不同的类别。这就构成了一颗简单的分类决策树
决策树可以用来解决分类或者回归问题,分别称之为分类树或回归树。其中,分类树的输出是一个标量。而回归树的输出一般为一个实数
通常情况下,决策树利用损失函数最小的原则建立模型,然后利用该模型进行预测。决策树学习通常包含三个阶段:特征选择,树的生成,树的修剪。
三个阶段
特征选择
特征选择是建立决策树之前的十分重要的一步。如果是随机的选择特征,那么所建立决策树的学习效率就会大打折扣。举例:银行采用决策树来解决信用卡审批问题,判断是否向某人发放信用卡可以根据其年龄,工作单位,是否有不动产,历史信贷情况等特征决定。而选择不同的特征,后续生成的决策树就会不一致,这种不一致最终会影响到决策树的分类效率。
通常我们在选择特征的时, 会考虑到两种不同的指标,分别为:信息增益和信息增益比。这里就要谈到信息论中的另一个常见的名词:熵。
熵(Entropy)是表示随机变量不确定性的度量。简单来说:熵越大,随机变量的不确定性就越大,而特征A对于某一训练集D的信息增益g(D,A)定义为集合D的熵H(D)与特征A在给定条件下D的熵的(H|A)之差。
g(D,A)=H(D)-H(D|A)
简单来讲,每一个特征针对训练数据集的前后信息变化的影响是不一样的,信息增益越大,即代表这种影响越大,而影响越大,就表明该特征更加重要。
生成算法
决策树的生成算法最经典的就数 John Ross Quinlan 提出的 ID3 算法,这个算法的核心理论即源于上面提到的信息增益。
ID3 算法通过递归的方式建立决策树。建立时,从根节点开始,对节点计算每个独立特征的信息增益,选择信息增益最大的特征作为节点特征。接下来,对该特征施加判断条件,建立子节点。然后针对子节点再此使用信息增益进行判断,直到所有特征的信息增益很小或者没有特征时结束,这样就逐步建立一颗完整的决策树。
除了从信息增益演化而来的 ID3 算法,还有一种常见的算法叫 C4.5。C4.5 算法同样由 John Ross Quinlan 发明,但它使用了信息增益比来选择特征,这被看成是 ID3 算法的一种改进。
ID3 和 C4.5 算法简单高效,但是他俩均存在一个缺点,那就是用 “完美去造就了另一个不完美”。这两个算法从信息增益和信息增益比开始,对整个训练集进行的分类,拟合出来的模型针对该训练集的确是非常完美的。但是,这种完美就使得整体模型的复杂度较高,而对其他数据集的预测能力就降低了,也就是我们常说的过拟合而使得模型的泛化能力变弱。
当然,过拟合的问题也是可以解决的,那就是对决策树进行修剪。
决策树修剪
决策树的修剪,其实就是通过优化损失函数来去掉不必要的一些分类特征,降低模型的整体复杂度。修剪的方式,就是从树的叶节点出发,向上回缩,逐步判断。如果去掉某一特征后,整棵决策树所对应的损失函数更小,那就就将该特征及带有的分支剪掉。
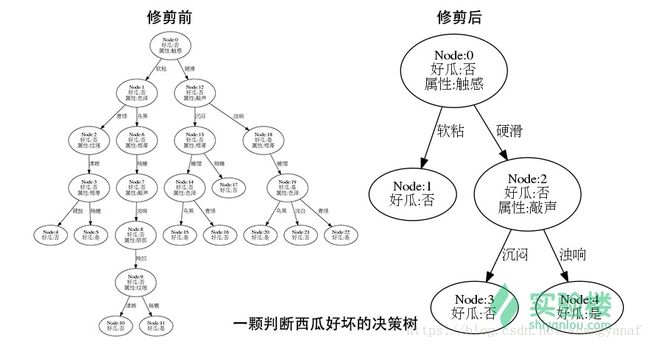
由于 ID3 和 C4.5 只能生成决策树,而修剪需要单独进行,这也就使得过程更加复杂了。1984 年,Breiman 提出了 CART 算法,使这个过程变得可以一步到位。CART 算法本身就包含了决策树的生成和修剪,并且可以同时被运用到分类树和回归树。这就是和 ID3 及 C4.5 之间的最大区别。
CART 算法在生成树的过程中,分类树采用了基尼指数(Gini Index)最小化原则,而回归树选择了平方损失函数最小化原则。基尼指数其实和前面提到的熵的概念是很相似的。简单概述区别的话,就是数值相近但不同,而基尼指数在运算过程中的速度会更快一些。
CART 算法也包含了树的修剪。CART 算法从完全生长的决策树底端剪去一些子树,使得模型更加简单。而修剪这些子树时,是每次去除一颗,逐步修剪直到根节点,从而形成一个子树序列。最后,对该子树序列进行交叉验证,再选出最优的子树作为最终决策树。