SQL分析对比Python分析
mysql -uroot -p
回车输密码 进入mysql 找数据
pip install pymysql
这是一组经过脱敏的电商数据
#导包,连接数据
import pandas as pd
from sqlalchemy import create_engine
warnings.filterwarnings('ignore')
conn=create_engine("myqsl+pymysql://root:123456@localhost:3306/demo?charset=utf8")
sql="show tables"
pd.read_sql(sql,conn) #chunksize进行SQL存储
#Talbes_in_demo
#0 order_info
#1 user_info
#数据导出数据库存储入.csv文件
sql="select * from order_info"
df=pd.read_sql(sql,conn)
df.to_csv('order_info.csv',index=False)
sql="select * from user_info"
df=pd.read_sql(sql,conn)
df.to_csv('user_info.csv',index=False)
#将数据导入到数据库中
user_info=pd.read_csv('./user_info.csv')
'''
name:表名
con:连接参数
if_exists='fail'新建 append追加
index=False
'''
#user_info
#user_info.drop(labels='Unnamed:0',axis=1,inplace=True)
user_info.to_sql('user_info',conn,index=False,chunksize=10000) #chunksize append用最佳 分组进行
order_info=pd.read_csv('./order_info.csv')
order_info.drop(labels='Unnamed:0',axis=1,inplace=True)
order_info.to_sql('order_info',conn,index=False,chunksize=10000)
查看建表语句

bigint 太大 改为int
show create table user_info\G
alter table ‘user_info’ modify ‘userid’ int primary key;
alter table ‘user_info’ modify ‘sex’ enum(‘男’,‘女’); #枚举类型 有约束作业
alter table ‘user_info’ modify ‘birth’ datetime;
修改order_info的
orderid,userid 改为int primary key -----price 改为float(32) —ispaid改为枚举(‘已支付’,‘未支付’)
统计不同月份下单的人数
- 时间列还要处理一下null值
- 月份分组
- userid去重
select * from ‘user_info’ limit 10;
select * from ‘order_info’ limit 10;
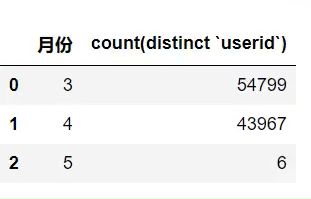
select month(‘paidtime’) as 月份,count(distinct ‘userid’) from ‘user_info’ where ‘paidtime’ is not null group by 月份;
#pandas 读取所有数据
sql="select * from order_info"
pd.read_sql(sql,conn).head()
sql="select month('paidtime') as 月份,count(distinct 'userid') from 'user_info' where 'paidtime' is not null group by 月份;"
pd.read_sql(sql,conn).head() #有索引了所以快
#B-tree B树 B+tree B+树 没有B-树 多路平衡查找树
统计用户在三月份的复购率
三月份买过了,又买了,购买次数大于1的用户/3月份已支付的用户
- order_info
- 3月份已支付用户数量
- 下单数量大于1
select count(*) from ‘order_info’; 539414
select count(distinct *) from ‘order_info’; 101534
select count(distinct ‘userid’) from order_info where ‘ispaid’=‘已支付’ and month(‘paidtime’)=3; 54799
userid每出现一次,代表下过一单
select count(‘userid’) as uc from ‘order_info’ where ‘ispaid’=‘已支付’ and month(‘paidtime’)=3 group by ‘userid’ having uc>1; 16916
合并 —>子查询
select concat(count(uc)/(select count(distinct ‘userid’) from order_info where ‘ispaid’=‘已支付’ and month(‘paidtime’)=3)*100,’%’) from (select userid,count(‘userid’) as uc from ‘order_info’ where ‘ispaid’=‘已支付’ and month(‘paidtime’)=3 group by ‘userid’ having uc>1)as tmp ;
select SUM(if(cnt>1, 1, 0)) / count(userid) 回购率
from (select userid, count(userid) cnt from order_info where date_format(paidtime, ‘%m’) = 3 group by userid) x;
#存储过程 procedure
#需要占用mysql的硬盘空间 计算资源比空间资源更加昂贵 用空间去换时间
#形成一张view 需要耗费空间 保存了结构
delimiter //
create procedure getfg()
begin
#定义局部变量 total=0
declare total int default 0;
declare a int default 0;
#select 值 into 变量 赋值
select count(distinct 'userid') into total from order_info where 'ispaid'='已支付' and month('paidtime')=3;
select count(uc) into gt2 from (select userid,count('userid') as uc from 'order_info' where 'ispaid'='已支付' and month('paidtime')=3 group by 'userid' having uc>1) as tmp;
#输出 dual表
select concat(gt2/total*100.'%') from dual;
end//
先写个delimiter// 然后复制之后的
mysql>call getfg()//
获取每个月的用户购买数量和复购率
- 月份,用户 分组
select mon as 月份, concat(sum(if(uc>1,1,0)) / count(userid)*100,’%’) as 复购率 from (select month(‘paidtime’) as mon, ‘userid’, count(‘userid’) as cnt from ‘order_info’ where ‘paidtime’ is not null group by ‘userid’, mon) as tmp group by mon;
3月回购率
上个月买过,这个又来买了一笔
3月份买过哦,4月份又来了
- 月份指定好
- 3月份购买的4月份又购买了的剩余人数 / 3月份购买的总人数
select concat (count(distinct ‘userid’) / 54799*100, ‘%’) from ‘order_info’ where month(‘paidtime’)=4 and ispaid=‘已支付’ and ‘userid’ in (select distinct ‘userid’ from ‘order_info’ where month(‘paidtime’)=3 and ispaid=‘已支付’ group by userid);
每个月的回购率
- 月份差
select m1.mon as 月份,count(m1.mon) as 总用户, count(m2.mon) as 回购用户数,concat(count(m2.mon) / count(m1.mon)*100,’%’) from
(select userid, month(‘paidtime’) as mon from ‘order_info’ where ‘paidtime’ is not null and ‘ispaid’=‘已支付’ group by mon,userid) as m1
left join
(select userid, month(‘paidtime’) as mon from ‘order_info’ where ‘paidtime’ is not null and ‘ispaid’=‘已支付’ group by mon,userid) as m2
on m1.userid=m2.userid and m1.mon=m2.mon-1 group by m1.mon;
pandas数据分析
user_info=pd.read_csv('./user_info_utf.csv')
order_info=pd.read_csv('./order_info_utff.csv')
统计不同月份下单的人数
#order_info.dropna() #all 一整行为空才删 any 某一个字段为空删
#获取时间不为空
indexs=order_info.paidtime.notnull()
new_order_info=order_info.loc[indexs]
new_order_info.head()

new_order_info['month']=new_order_info.paidtime.map(lambda item:item.split('/')[1]
#剔除重复下单 userid,month
next_new_order_info=new_order_info.loc[:,['userid','month']].drop_duplicates()
result=next_new_order_info.groupby('month').userid.count()
result
#month
#3 54799
#4 43967
#5 6
#Name:userid, dtype:int64
统计用户在三月份的复购率
total3=next_new_order_info.query("month=='3'").shape[0]
cond=next_new_order_info.query("month=='3'").groupby(by=['userid']).count()
#获取下单大于1的
indexs=cond>1
gt2=cond[indexs].shape[0]
gt2/total3 #0.3086
统计男女的消费频次
- 消费人群
select sex as 性别,avg(uc) as 频次 from (select u.userid,u.sex,count(u.userid) as uc from ‘order_info’ as o inner join (select * from ‘user_info’ where sex is not null) as u on o.userid=u.userid where ‘ispaid’=‘已支付’ group by u.sex,u.userid) as tmp group by sex;
性别 频次
男 1.8035
女 1.7829
两张建表语句:

普通索引—>联合索引—>左前缀法(当索引是单个出现的时候,最左端的字段可以使用索引)
alter talbe ‘user_info’ add index ‘union1’(‘userid’,‘sex’,‘birth’);
alter talbe ‘user_info’ add index ‘union2’(‘birth’,‘sex’,‘userid’);
alter talbe ‘user_info’ add index ‘union3’(‘sex’,‘userid’,‘birth’);
alter table ‘order_info’ add index ‘union1’(‘ispaid’,‘userid’,‘paidtime’,‘price’);
alter table ‘order_info’ add index ‘union2’(‘userid’,‘ispaid’,‘paidtime’,‘price’);
alter table ‘order_info’ add index ‘union3’(‘paidtime’,‘userid’,‘ispaid’,‘price’);
alter table ‘order_info’ add index ‘union4’(‘price’,‘userid’,‘paidtime’,‘ispaid’);
统计不同年龄的人群,平均消费金额
select age,avg(sp) from
(select age,sum(‘price’) as sp from ‘order_info’ as o inner join
(select userid,ceil(year(now())-year(‘birth’))/10) as age,birth from ‘user_info’ where ‘birth’ is not null and year(‘birth’)>1940) as u on o.userid=u.userid group by u.userid;
消费二八法则
消费TOP20% 20%的人消费了今年的80% 80%人消费了20%
消费总额
select ceil(sum(‘price’)) from ‘order_info’ where ‘ispaid’=1 and ‘paidtime’ is not null; #318503082
20%会员数量
select round(count(‘userid’)*0.2) from ‘user_info’; #20307
top20% 每个人花了多少钱
select * from (select userid,ceil(sum(‘price’)) as sp from ‘order_info’ where ‘ispaid’=1 and ‘paidtime’ is not null group by ‘userid’ order by sp desc limit 20307) as amt;
select ceil(sum(sp)) from (select userid,ceil(sum(‘price’)) as sp from ‘order_info’ where ‘ispaid’=1 and ‘paidtime’ is not null group by ‘userid’ order by sp desc limit 20307) as amt;
delimiter//
create procedure show20()
begin
#所有人总金额
declare total_price int default 0;
#TOP20%人数有多少
declare num_20 int default 0;
#TOP20一共花了多少钱
declare amt_20 int default 0;
select ceil(sum(‘price’)) into total_price from ‘order_info’ where ‘ispaid’=1 and ‘paidtime’ is not null;
select round(count(‘userid’)0.2) into num_20 from ‘user_info’;
select ceil(sum(sp)) into amt_20 from (select userid,ceil(sum(‘price’)) as sp from ‘order_info’ where ‘ispaid’=1 and ‘paidtime’ is not null group by ‘userid’ order by sp desc limit num_20) as amt;
#TOP20的人消费比例
select amt_20 as TOP20,concat(amt_20/total_price100,’%’) as rate from dual;
end//
call show20()

SQl计算数字,Excel
环比:报告比上一次增加了还是减少了
同比:今年1月和去年1月进行对比
业务专家
主从复制

主服务器有带宽,主服务器的数据修改了,多台从服务器同步数据会占用主服务器的大量带宽,就需要有一台黑洞引擎,黑洞引擎会将主服务器的各种insert update delete等操作打包成日志分发给个从服务器。