Kafka Consumer底层原理分析【Kafka系列】
虽然目前Kafka0.10版本已经重写了其API,但底层原理是类似的,所以我们可以先了解kafka0.8.x里面的提供的Consumer的实现原理与交互流程
Kafka提供了两套API给Consumer
- The SimpleConsumer API
- The high-level Consumer API
1. 低阶API
本质上是提供了一种与broker交互信息的API
剩下的处理全靠用户自己的程序,功能比较简单,但用户扩展性比较强
1) API结构
低阶API的consumer,指定查找topic某个partition的指定offset去消费
首先与broker通信,寻找到leader(不与zookeeper通信,不存在groupid),然后直接和leader通信,指定offset去消费。消费多少,从哪里开始消费,都可控(我们的例子是从0开始消费)

findLeader方法中会去调用findPartitionMetadata方法

程序运行结果:
运行过程中一直卡住没有成功消费,加入如下错误信息判断,发现error code为1
说明我们从offset 0消费offsetoutofrange了
(我们发送请求topic1 partition0的offset 0 broker回复我们offset out of range,因为kafka中已经没有offset 0 的数据了,已经过期清理掉了)

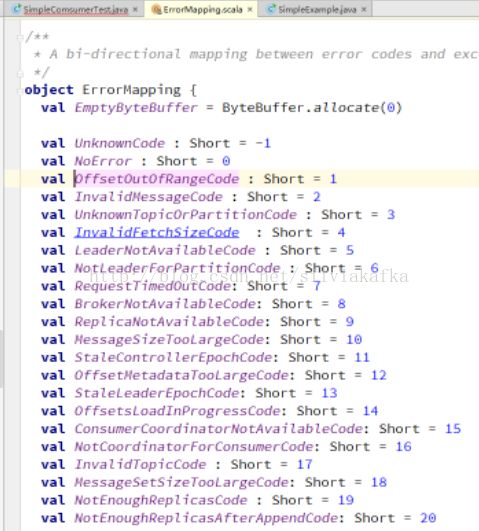
所以我们添加getLastOffset,getEarliestOffset的方法,获取该topic该partition在kafka集群中有的的最小和最大的offset



调整offset之后,可能最新的数据也过期了,于是获取到的message的size为0

查看SimpleConsumer的源码:


1) 交互过程
使用SimpleConsumer的步骤
1) 从所有活跃的broker中找出哪个是指定Topic Partition中的leader broker
2) 获取kafka中已存在的offset访问(或人工指定)
3) 构造请求
4) 发送请求查询数据
5) 获取查询结果,处理(判断获取的结果,进行相应的处理)
处理就包括:
l 处理offset不存在的情况
l 处理offset的增长
l 处理leader broker变更
(当连接的这个brokerdown掉,我们要写程序捕获异常并且写程序去切换broker,重新连接)
注意:该API是不阻塞的,SimpleConsumer传一个请求过去,不论是数据过期、新的数据还没来等,都会有一个response回来的

使用SimpleConsumer有哪些弊端呢?
l 必须在程序中跟踪offset值
l 必须找出指定Topic Partition中的lead broker
l 必须处理broker的变动
(当连接的这个brokerdown掉,我们要写程序捕获异常并且写程序去切换broker,重新连接)
l 如果多个SimpleConsumer共享消费某个topic,想要实现彼此的负载均衡,需要添加很多额外代码
(多个客户端共享某个topic,就要保证他们的消费是互斥的,不能消费到同一条数据,比如A,B,C共享topicX共4个partition,那么A就消费partition0,B消费partition1,partition2,C就消费partition3,保证其消费相互独立,并且A,B,C的消费总和是整个topicX的所有消息)
2. 高阶API
本质上是提供了一个完整的程序,内置各种功能(比如和其他consumer的负载均衡,比如处理broker变动)
用户只需要调用API即可,功能非常强大,但用户扩展性比较差
1) API
高阶消费者API必须要指定group.id,否则会报错

2) 负载均衡原理与算法
该程序,运行多个进程,他们之间是可以实现负载均衡的。前提是他们同属于一个group,拥有相同的groupid。

每个consumer都会监听zk上topic partition信息和consumer的信息
添加一个节点,他们就监听到变化,监听到变化就会调用rebanlance去重新算自己需要消费哪些partition。然后开始消费。
每个consumer都自己独立去调整自己的消费

会触发consumer rebalance的场景有如下场景:
l 条件1:有新的consumer加入
l 条件2:旧的consumer挂了
l 条件3:coordinator挂了,集群选举出新的coordinator(0.10 特有的)
l 条件4:topic的partition新加
l 条件5:consumer调用unsubscrible(),取消topic的订阅
这种负载均衡方案存在的问题
- Herd effect(羊群效应)
任何Broker或者Consumer的增减都会触发所有的Consumer的Rebalance,造成集群内大量的调整
- Split Brain
每个Consumer分别单独通过Zookeeper判断哪些Broker和Consumer 宕机了,那么不同Consumer在同一时刻从Zookeeper“看”到的View就可能不一样,这是由Zookeeper的特性决定的,这就会造成不正确的Reblance尝试。
- 调整结果不可控
所有的Consumer都并不知道其它Consumer的Rebalance是否成功,这可能会导致Kafka工作在一个不正确的状态。
为了解决这些问题,Kafka作者在0.9.x版本中开始使用中心协调器(Coordinator)。由它统一来监听zookeeper,生成rebalance命令,并且判断是否成功,不成功进行重试(后面讲解)
3) blockingQueue
consumerMap
| Topic1 |
4 |
| Topic2 |
2 |
| Topic3 |
1 |
核心创建方案就是:
Map

这个topicCountMap主要是指定消费线程数,该API底层的实现如下图:
1.会为每个topic生成对应的消费线程,我们可以叫它消费线程。它会从一个blockingQueue里面取数据。这个取的过程是阻塞的,如果queue中没有数据,就会阻塞。
2.会为每个kafka的broker生成一个fetch线程,我们可以叫它取数据线程。每个fetch thread会于kafka broker建立一个连接。fetch thread线程去拉取消息数据,最终放到对应的blockingQueue中,等待消费线程来消费。

客户端使用时:

根据topic,指定取某一个消费线程,拿出流数据,然后可以遍历该数据了,如上所述,该方法会是阻塞的,如果没有数据了,它就会阻塞在这里。
4) 关于offset
该api除了使用zk做负载均衡 还会用它记录offset。
/consumers/groupid/offsets/topic/partition/xxxx
记录消费到的offset值

上图左边为在zookeeper中没有此groupid节点的流程 右边为有的流程
groupid节点如果没有,会创建,然后offset的创建初始值会在kafka中获取,默认是获取最新的offset,也可以指定获取kafka中目前存在的最小offset,如下参数可以人工指定
//偏移量,初始化从哪个位置读
//props.put("auto.offset.reset", "smallest");
注意:此设置只有在运行初始化的时候有效,如果zookeeper中已经有值,那么这个参数是无效的,会直接去读zookeeper中的offset值。如果还想获取之前的数据,方法1手动修改zookeeper中该offset的值,方法2换一个groupid去消费,指定smallest。
在获取到offset值之后,就是去kafka中消费数据,然后在zookeeper中更新此offset的值。这些都是API底层帮我们实现了,我们上层API无感知。
5) 负载均衡小实验
创建一个partition为2的topic
创建两个groupid相同的consumer进程来消费这个topic的消息
一个producer不断的打入消息
结果:


附API使用代码
高阶API
package com.wangke.consumer;
import com.wangke.kafkaProducerConsumer.KafkaProperties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
/**
* Created by dell on 2017/8/11.
*/
public class HighConsumerTest {
private static ConsumerConfig createConsumerConfig()
{
String zkConnect = "ip:2181";
String groupId = "group2";
Properties props = new Properties();
props.put("zookeeper.connect", zkConnect);
props.put("group.id", groupId);
props.put("zookeeper.session.timeout.ms", "40000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
//偏移量,从哪个位置读
props.put("auto.offset.reset", "smallest");
return new ConsumerConfig(props);
}
public static void main(String[] args) throws InterruptedException {
ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig());
String topic = "test7";
Map topicCountMap = new HashMap();
topicCountMap.put(topic, new Integer(1));
Map>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream stream = consumerMap.get(topic).get(0);
ConsumerIterator it = stream.iterator();
int i=0;
while (it.hasNext()) {
System.out.println("receive:" + new String(it.next().message()));
i++;
if(i==10)
break;
}
consumer.shutdown();
}
}
低阶API
package com.wangke.consumer;
import kafka.api.FetchRequest;
import kafka.api.FetchRequestBuilder;
import kafka.api.PartitionOffsetRequestInfo;
import kafka.cluster.Broker;
import kafka.common.ErrorMapping;
import kafka.common.TopicAndPartition;
import kafka.javaapi.*;
import kafka.javaapi.consumer.SimpleConsumer;
import kafka.javaapi.message.ByteBufferMessageSet;
import kafka.message.Message;
import kafka.message.MessageAndOffset;
import java.nio.ByteBuffer;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
*
* @author wangke
* @date 2017/8/9
*/
public class SimpleComsumerTest {
public static void main(String[] args) throws InterruptedException {
String BROKER_CONNECT = "ip:9092";
String TOPIC = "topic";
int partitionNum = 0;
// 找到leader
Broker leaderBroker = findLeader(BROKER_CONNECT, TOPIC, partitionNum);
if(leaderBroker==null){
System.out.println("未找到leader信息");
return;
}
// 从leader消费 soTimeout bufferSize clientId
SimpleConsumer simpleConsumer = new SimpleConsumer(leaderBroker.host(), leaderBroker.port(), 20000, 10000, "mySimpleConsumer");
long startOffet = 0;
int fetchSize = 500;
long offset = startOffet;
while (true ) {
System.out.println("offset:"+offset);
// 添加fetch指定目标topic,分区,起始offset及fetchSize(字节),可以添加多个fetch
FetchRequest req = new FetchRequestBuilder().addFetch(TOPIC, partitionNum, offset, fetchSize).build();
// 拉取消息
FetchResponse fetchResponse = simpleConsumer.fetch(req);
if (fetchResponse.hasError()) {
// Something went wrong!
short code = fetchResponse.errorCode(TOPIC, partitionNum);
System.out.println("Error fetching data from the Broker:" + leaderBroker + " Reason: " + code);
if (code == ErrorMapping.OffsetOutOfRangeCode()) {
// We asked for an invalid offset. For simple case ask for
// the last element to reset
//offset = getEarliestOffset(simpleConsumer, TOPIC, partitionNum, "mySimpleConsumer");
offset = getLastOffset(simpleConsumer, TOPIC, partitionNum, "mySimpleConsumer");
continue;
}
System.out.println("Error fetching data Offset Data the Broker. Reason: " + fetchResponse.errorCode(TOPIC, partitionNum));
continue;
}
ByteBufferMessageSet messageSet = fetchResponse.messageSet(TOPIC, partitionNum);
if(messageSet.sizeInBytes() ==0){
Thread.sleep(5000);
System.out.println("数据为空");
continue;
}
for (MessageAndOffset messageAndOffset : messageSet) {
Message mess = messageAndOffset.message();
ByteBuffer payload = mess.payload();
byte[] bytes = new byte[payload.limit()];
payload.get(bytes);
String msg = new String(bytes);
offset = messageAndOffset.offset();
System.out.println("partition : " + partitionNum + ", offset : " + offset + " mess : " + msg);
}
// 继续消费下一批
offset = offset + 1;
Thread.sleep(5000);
}
}
/**
* 找到制定分区的leader broker
*
* @param brokerHosts broker地址,格式为:“host1:port1,host2:port2,host3:port3”
* @param topic topic
* @param partition 分区
* @return
*/
private static Broker findLeader(String brokerHosts, String topic, int partition) {
PartitionMetadata partitionMetadata = findPartitionMetadata(brokerHosts, topic, partition);
if(partitionMetadata==null){
System.out.println("未找到leader信息");
return null;
}
Broker leader = partitionMetadata.leader();
System.out.println(String.format("Leader tor topic %s, partition %d is %s:%d", topic, partition, leader.host(), leader.port()));
return leader;
}
/**
* 找到指定分区的元数据
*
* @param brokerHosts broker地址,格式为:“host1:port1,host2:port2,host3:port3”
* @param topic topic
* @param partition 分区
* @return 元数据
*/
private static PartitionMetadata findPartitionMetadata(String brokerHosts, String topic, int partition) {
PartitionMetadata returnMetaData = null;
for (String brokerHost : brokerHosts.split(",")) {
SimpleConsumer consumer = null;
String[] splits = brokerHost.split(":");
consumer = new SimpleConsumer(splits[0], Integer.valueOf(splits[1]), 100000, 64 * 1024, "leaderLookup");
List topics = Collections.singletonList(topic);
TopicMetadataRequest request = new TopicMetadataRequest(topics);
TopicMetadataResponse response = consumer.send(request);
List topicMetadatas = response.topicsMetadata();
for (TopicMetadata topicMetadata : topicMetadatas) {
for (PartitionMetadata PartitionMetadata : topicMetadata.partitionsMetadata()) {
if (PartitionMetadata.partitionId() == partition) {
returnMetaData = PartitionMetadata;
break;//找到元数据,程序可以退出了
}
}
}
if (consumer != null)
consumer.close();
}
return returnMetaData;
}
/*消费者消费一个topic的指定partition时,从哪里开始读数据
*kafka.api.OffsetRequest.EarliestTime()找到日志中数据的最开始头位置,从那里开始消费(hadoop-consumer中使用的应该就是这种方式)
*kafka.api.OffsetRequest.LatestTime()只消费最新的数据
*注意,不要假设0是offset的初始值
*参数:long whichTime的取值即两种:
* kafka.api.OffsetRequest.LatestTime()
* kafka.api.OffsetRequest.LatestTime()
*返回值:一个long类型的offset*/
private static long getLastOffset(SimpleConsumer consumer, String topic, int partition, String clientName) {
TopicAndPartition topicAndPartition = new TopicAndPartition(topic, partition);
Map requestInfo = new HashMap();
requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(kafka.api.OffsetRequest.LatestTime(), 1));
kafka.javaapi.OffsetRequest request = new kafka.javaapi.OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName);
OffsetResponse response = consumer.getOffsetsBefore(request);
if (response.hasError()) {
System.out.println("Error fetching data Offset Data the Broker. Reason: " + response.errorCode(topic, partition));
return 0;
}
long[] offsets = response.offsets(topic, partition);
return offsets[0];
}
private static long getEarliestOffset(SimpleConsumer consumer, String topic, int partition, String clientName) {
TopicAndPartition topicAndPartition = new TopicAndPartition(topic, partition);
Map requestInfo = new HashMap();
requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(kafka.api.OffsetRequest.EarliestTime(), 1));
kafka.javaapi.OffsetRequest request = new kafka.javaapi.OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName);
OffsetResponse response = consumer.getOffsetsBefore(request);
if (response.hasError()) {
System.out.println("Error fetching data Offset Data the Broker. Reason: " + response.errorCode(topic, partition));
return 0;
}
long[] offsets = response.offsets(topic, partition);
return offsets[0];
}
}