《视觉SLAM-非线性优化与g2o-高翔》笔记
《视觉SLAM-非线性优化与g2o-高翔》笔记
本文是观看视频《视觉SLAM-非线性优化与g2o-高翔》整理的笔记。
1. 从滤波到优化
1.1 模型
状态变量 x x x: x = [ x 1 , x 2 , . . . , x N , y 1 , y 2 , . . . , y M ] x=[x_1, x_2, ..., x_N, \; y_1, y_2, ..., y_M] x=[x1,x2,...,xN,y1,y2,...,yM]
运动模型 f f f: x k = f ( x k − 1 , u k ) + v k x_k = f(x_{k-1}, u_k) + v_k xk=f(xk−1,uk)+vk
观测模型 g g g: z k , j = g ( x k , y j ) + n k , j z_{k,j} = g(x_k,y_j) + n_{k,j} zk,j=g(xk,yj)+nk,j
其中, x i x_i xi为位姿, y i y_i yi为路标坐标,都是未知量。 u u u为运动输入量, z z z为观测值,都是测量值。
1.2 传统EKF方法
在工作点附近计算雅可比矩阵(一阶偏导) F F F 和 G G G。
F = : δ f δ x k ∣ x ^ k − 1 v k ∼ N ( 0 , Q k ) G = : δ g δ x k ∣ x ^ k n k , j ∼ N ( 0 , R k ) F=: \frac{\delta f}{\delta x_{k}}|\hat x_{k-1} \qquad v_k \sim N(0, Q_k)\\ G=: \frac{\delta g}{\delta x_k}|\hat x_k \;\qquad n_{k,j} \sim N(0, R_k) F=:δxkδf∣x^k−1vk∼N(0,Qk)G=:δxkδg∣x^knk,j∼N(0,Rk)
step1. 预测:估计先验的均值和协方差矩阵
x ˘ k = f ( x ^ k − 1 , u k ) P ˘ k + 1 = F k P ^ k F k T + Q k \breve x_k = f(\hat x_{k-1}, u_k) \qquad \breve P_{k+1} = F_k \hat P_k F_k^T + Q_k x˘k=f(x^k−1,uk)P˘k+1=FkP^kFkT+Qk
step2. 更新:计算卡尔曼增益,并用观测模型纠正先验模型,得到后验估计
K k = P ˘ k G k T ( G k P ˘ k G k T + R k ) − 1 x ^ k = x ˘ k + K k ( z − z ^ ) P ^ k = ( i − K G k ) P ˘ k K_k = \breve P_k G_k^T (G_k \breve P_k G_k^T + R_k)^{-1} \\ \hat x_k = \breve x_k + K_k (z-\hat z) \qquad \hat P_k = (i - KG_k) \breve P_k Kk=P˘kGkT(GkP˘kGkT+Rk)−1x^k=x˘k+Kk(z−z^)P^k=(i−KGk)P˘k
EKF的问题:
线性化误差,无迭代,噪声非高斯,需要维护一个大的协方差矩阵(平方级别复杂度)。
解决思路=>使用非线性优化
1.3 非线性优化思路
| 思路 | 问题 |
|---|---|
| 1. 设定目标函数,选定初值 状态向量: x = [ x 1 , x 2 , . . . , x N , y 1 , y 2 , . . . , y M ] x=[x_1, x_2, ..., x_N, y_1, y_2, ..., y_M] x=[x1,x2,...,xN,y1,y2,...,yM] |
目标函数是什么? |
| 2. 寻找梯度,使目标函数下降 | 梯度如何计算? |
| 3. 梯度下降,迭代直到收敛 | 梯度只是局部下降,如何保证目标函数下降? |
1.4 目标函数
在视觉和激光SLAM中,运动模型差别较小,观测模型则有所差异。这里我们以观测模型为例。
观测模型: z k , j = g ( x k , y j ) + n k , j n k , j ∼ N ( 0 , Σ ) z_{k,j} = g(x_k,y_j) + n_{k,j} \qquad n_{k,j} \sim N(0, \Sigma) zk,j=g(xk,yj)+nk,jnk,j∼N(0,Σ)
误差分布: z k , j ∼ N ( g ( x k , y j ) , Σ ) z_{k,j} \sim N(g(x_k,y_j), \Sigma) zk,j∼N(g(xk,yj),Σ)
以Bayers方式理解,优化的目标是:在已知观测值 z z z的条件下,求能使 P ( x , y ∣ z ) P(x,y|z) P(x,y∣z)概率大最的 x y xy xy。即求:
( x , y ) ∗ = arg max x , y P ( x , y ∣ z ) (x,y)^*= \underset{x,y}{\arg\max} P(x,y|z) (x,y)∗=x,yargmaxP(x,y∣z)
根据贝叶斯方程,后验与似然×先验成正比。 P ( x , y ∣ z ) ∝ P ( z ∣ x , y ) P ( x , y ) P(x,y|z) \propto P(z|x,y) P(x,y) P(x,y∣z)∝P(z∣x,y)P(x,y)
则有两种方式求解 x y xy xy:
- 最大似然(MLE): ( x , y ) ∗ = arg max x , y P ( z ∣ x , y ) (x,y)^*= \underset{x,y}{\arg\max} P(z|x,y) (x,y)∗=x,yargmaxP(z∣x,y)
- 最大后验(MAP): ( x , y ) ∗ = arg max x , y P ( z ∣ x , y ) P ( x , y ) (x,y)^*= \underset{x,y}{\arg\max} P(z|x,y)P(x,y) (x,y)∗=x,yargmaxP(z∣x,y)P(x,y)
一般不知道路标的先验位置,所以用MLE多一些。
怎么求MLE呢?
我们会使用负对数简化目标函数。
这么做是因为,高斯分布函数有如下性质:取负对数后,可以分为两部分,前一部分与 z z z无关,求极值时可以不考虑;而后一部分的结构比变换之前简单了很多。
P ( z ) = − l n { 1 ( 2 π ) N d e t Σ exp [ 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ] } = 1 2 l n [ ( 2 π ) N d e t Σ ] + 1 2 [ ( x − μ ) T Σ − 1 ( x − μ ) ] P(z) = -ln \{ \; \frac{1}{{(2\pi)}^N det\Sigma} \exp[\frac{1}{2}(x-\mu)^T \Sigma^{-1} (x-\mu) ] \; \} \\ =\frac{1}{2} ln[{(2\pi)}^N det\Sigma] + \frac{1}{2} [(x-\mu)^T \Sigma^{-1} (x-\mu)] P(z)=−ln{(2π)NdetΣ1exp[21(x−μ)TΣ−1(x−μ)]}=21ln[(2π)NdetΣ]+21[(x−μ)TΣ−1(x−μ)]
对变量求极大值,相当于求负对数的极小值。则求下式即可达到最大似然:
arg max x , y P ( z ∣ x , y ) = arg min x , y − l n ( P ( z ∣ x , y ) ) = arg min x , y ( z − μ ) T Σ − 1 ( z − μ ) \begin{aligned} \underset{x,y}{\arg\max} P(z|x,y) &= \underset{x,y}{\arg\min} -ln(P(z|x,y)) \\ &= \underset{x,y}{\arg\min} (z-\mu)^T \Sigma^{-1} (z-\mu) \end{aligned} x,yargmaxP(z∣x,y)=x,yargmin−ln(P(z∣x,y))=x,yargmin(z−μ)TΣ−1(z−μ)
我们知道 z k , j ∼ N ( g ( x k , y j ) , Σ ) z_{k,j} \sim N(g(x_k,y_j), \Sigma) zk,j∼N(g(xk,yj),Σ),则有
arg max x , y P ( z ∣ x , y ) = arg min x , y [ z − g ( x , y ) ] T Σ − 1 [ z − g ( x , y ) ] = arg min x , y ( e T Σ e ) \begin{aligned} \underset{x,y}{\arg\max} P(z|x,y) &= \underset{x,y}{\arg\min} [z - g(x,y)]^T \Sigma^{-1} [z - g(x,y)]\\ &= \underset{x,y}{\arg\min} (e^T\Sigma e) \end{aligned} x,yargmaxP(z∣x,y)=x,yargmin[z−g(x,y)]TΣ−1[z−g(x,y)]=x,yargmin(eTΣe)
其中, Σ − 1 \Sigma^{-1} Σ−1是信息矩阵, Σ \Sigma Σ是噪声分布的协方差矩阵。
考虑整个系统
误差来源有二:运动模型误差,和观测模型误差。假设都符合高斯分布:
e v , k = x k − f ( x k − 1 , v k ) = v k ∼ N ( 0 , Q k ) e_{v,k}=x_k - f(x_{k-1}, v_k) = v_k \sim N(0, Q_k) ev,k=xk−f(xk−1,vk)=vk∼N(0,Qk)
e y , k , j = z k , j − g ( x k , y j ) = n k , j ∼ N ( 0 , R k ) e_{y,k,j}=z_{k,j} - g(x_k,y_j) = n_{k,j} \sim N(0, R_k) ey,k,j=zk,j−g(xk,yj)=nk,j∼N(0,Rk)
将两种误差都考虑进来,则目标函数可以定义为:
T ( x , y ) = ∑ k = 1 N e v , k T Σ v , k − 1 e v , k + ∑ k = 1 N ∑ j = 1 M e y , k , j T Σ y , k , j − 1 e y , k , j T(x,y) = \sum^{N}_{k=1} e_{v,k}^T \Sigma_{v,k}^{-1}e_{v,k} +\sum^{N}_{k=1}\sum^{M}_{j=1}e_{y,k,j}^T \Sigma_{y,k,j}^{-1}e_{y,k,j} T(x,y)=k=1∑Nev,kTΣv,k−1ev,k+k=1∑Nj=1∑Mey,k,jTΣy,k,j−1ey,k,j
其中, N N N为epoch个数, M M M为观测值个数。
若不考虑运动模型,就类似Bundle Adjustment只有观测,成为一个最小二乘问题。
1.5 计算梯度
将 x y xy xy合并记为 x x x,还是以观测误差为例: e ( x ) = z − g ( x ) e(x) = z - g(x) e(x)=z−g(x)。整体的误差项(目标函数):
E ( x ) = e ( x ) T Σ − 1 e ( x ) E(x) = e(x)^T \Sigma^{-1} e(x) E(x)=e(x)TΣ−1e(x)
给 x x x一个微小偏移量,新的误差为:
E ( x + Δ x ) = e T ( x + Δ x ) Σ − 1 e ( x + Δ x ) E(x+\Delta x) = e^T(x+\Delta x) \Sigma^{-1} e(x+\Delta x) E(x+Δx)=eT(x+Δx)Σ−1e(x+Δx)
用泰勒公式 e ( x + Δ x ) ≈ e + J Δ x e(x+\Delta x) \approx e + J \Delta x e(x+Δx)≈e+JΔx 进行一阶线性展开( e e e, J J J都是在工作点 x x x处计算的):
E ( x + Δ x ) ≈ ( e + J Δ x ) T Σ − 1 ( e + J Δ x ) = e T Σ − 1 e + 2 e T Σ − 1 J Δ x + Δ x T J T Σ − 1 J Δ x = E ( x ) + 2 e T Σ − 1 J Δ x + Δ x T J T Σ − 1 J Δ x \begin{aligned} E(x+\Delta x) &\approx (e + J \Delta x)^T \Sigma^{-1} (e + J \Delta x) \\ &=e^T\Sigma^{-1}e + 2e^T\Sigma^{-1} J \Delta x + \Delta x^T J^T\Sigma^{-1}J \Delta x \\ &=E(x) \;\;\;\; + 2e^T\Sigma^{-1} J \Delta x + \Delta x^T J^T\Sigma^{-1}J \Delta x \end{aligned} E(x+Δx)≈(e+JΔx)TΣ−1(e+JΔx)=eTΣ−1e+2eTΣ−1JΔx+ΔxTJTΣ−1JΔx=E(x)+2eTΣ−1JΔx+ΔxTJTΣ−1JΔx
则 E E E的增量:
Δ E = E ( x + Δ x ) − E ( x ) = 2 e T Σ − 1 J Δ x + Δ x T J T Σ − 1 J Δ x \begin{aligned} \Delta E &= E(x+\Delta x) - E(x)\\ &= 2e^T\Sigma^{-1} J \Delta x + \Delta x^T J^T\Sigma^{-1}J \Delta x \end{aligned} ΔE=E(x+Δx)−E(x)=2eTΣ−1JΔx+ΔxTJTΣ−1JΔx
arg min x , y ( E ) = arg min x , y ( Δ E ) \underset{x,y}{\arg\min} (E) = \underset{x,y}{\arg\min} (\Delta E) x,yargmin(E)=x,yargmin(ΔE) 。要使 Δ E \Delta E ΔE尽可能的小,解 δ Δ E / δ Δ x = 0 {\delta\Delta E} / {\delta \Delta x} = 0 δΔE/δΔx=0 即可。
δ Δ E δ Δ x = ( 2 e T Σ − 1 J ) T + 2 ( J T Σ − 1 J ) Δ x = 2 J T Σ − 1 e + 2 J T Σ − 1 J Δ x = 0 \begin{aligned} \frac{\delta\Delta E}{\delta \Delta x} &= (2e^T\Sigma^{-1} J)^T+2(J^T\Sigma^{-1}J)\Delta x\\ &= 2J^T\Sigma^{-1} e + 2 J^T\Sigma^{-1}J \Delta x = 0 \end{aligned} δΔxδΔE=(2eTΣ−1J)T+2(JTΣ−1J)Δx=2JTΣ−1e+2JTΣ−1JΔx=0
则得到以下形式的线性方程,可以解得 Δ x \Delta x Δx,该更新值可使目标函数 E E E 减小。
J T Σ − 1 J Δ x = − J T Σ − 1 e H Δ x = − b \color{red}\begin{aligned} J^T \Sigma^{-1} J \Delta x &= -J^T \Sigma^{-1} e\\ H \Delta x &= -b \end{aligned} JTΣ−1JΔxHΔx=−JTΣ−1e=−b
H = : J T Σ − 1 J H=:J^T \Sigma^{-1} J H=:JTΣ−1J,是Hessian矩阵的近似。 b = J T Σ − 1 e b = J^T\Sigma^{-1}e b=JTΣ−1e。
问题:
- 雅可比矩阵 J = Δ e / Δ x J=\Delta e/\Delta x J=Δe/Δx 怎么算?
- 怎么解 Δ x \Delta x Δx?
- 当规模小的时候可以用 Δ x = H − 1 b \Delta x = H^{-1}b Δx=H−1b
- 当方程规模大时呢?利用稀疏性。
1.6.1 雅可比矩阵 J J J 怎么算
还是以相机观测模型 z = g ( x , y ) z = g(x,y) z=g(x,y)为例:

如图,控制点的全局坐标 y y y,通过相机外参 R R R 和 t t t 转到相机坐标系,乘以相机内参 K K K,再除以距离z,得到像点坐标 u , v u,v u,v(这里没用齐次坐标,乘以 D D D取前两个值)。 最后用李代 ξ \xi ξ数表示相机的pose:
[ u v ] = [ 1 0 0 0 1 0 ] 1 z y [ f x 0 0 0 f y 0 0 0 1 ] ( R y + t ) z = D 1 z y K ( R y + t ) = 1 z y D K exp ( ξ ∧ ) y : = g ( ξ , y ) \begin{aligned} \begin{bmatrix}u\\v\end{bmatrix} &=\begin{bmatrix}1&0&0\\0&1&0\end{bmatrix} \frac{1}{z_y} \begin{bmatrix}f_x&0&0\\0&f_y&0\\0&0&1\end{bmatrix} (Ry +t) \\ z \;\;&= D \frac{1}{z_y} K(Ry+t) =\frac{1}{z_y}DK \exp(\xi^\wedge )y := g(\xi, y) \end{aligned} [uv]z=[100100]zy1⎣⎡fx000fy0001⎦⎤(Ry+t)=Dzy1K(Ry+t)=zy1DKexp(ξ∧)y:=g(ξ,y)
可以看到,误差方程 e = z − g ( ξ , y ) e = z - g(\xi, y) e=z−g(ξ,y) 包含两个自变量,相机位姿 ξ \xi ξ 和控制点坐标 y y y。
a) 误差 e e e关于pose ξ \xi ξ求导
e对于 ξ \xi ξ的模型为:
e ( ξ ) = z − g ( x , y ) = z − 1 z y D K exp ( ξ ∧ ) y \begin{aligned} e(\xi) = z - g(x,y) = z - \frac{1}{z_y}DK \exp(\xi^\wedge )y \end{aligned} e(ξ)=z−g(x,y)=z−zy1DKexp(ξ∧)y
对pose加一个扰动(定义一个广义的加法,实际是乘法):
e ( ξ ⊕ δ ξ ) = z − 1 z y D K exp [ ( ξ ⊕ δ ξ ) ∧ ] y = z − 1 z y D K exp ( δ ξ ∧ ) exp ( ξ ∧ ) y ≈ z − 1 z y D K ( 1 + δ ξ ∧ ) exp ( ξ ∧ ) y 利 用 指 数 的 泰 勒 展 开 e x p ( x ) ≈ 1 + x = z − 1 z y D K exp ( ξ ∧ ) y − 1 z y D K δ ξ ∧ exp ( ξ ∧ ) y e ( ξ ⊕ δ ξ ) = e ( ξ ) − 1 z y D K δ ξ ∧ exp ( ξ ∧ ) y \begin{aligned} e(\xi \oplus \delta \xi) & = z - \frac{1}{z_y}DK \exp[(\xi \oplus \delta \xi)^\wedge ]y \\ &= z - \frac{1}{z_y}DK {\color{Red}\exp(\delta\xi^\wedge)} \exp(\xi^\wedge )y \\ &\approx z - \frac{1}{z_y}DK {\color{Red}(1+\delta\xi^\wedge)} \exp(\xi^\wedge )y \quad 利用指数的泰勒展开exp(x)\approx1+x\\ &= z - \frac{1}{z_y}DK \exp(\xi^\wedge )y - \frac{1}{z_y}DK {\color{Red}\delta\xi^\wedge} \exp(\xi^\wedge )y\\ e(\xi \oplus \delta \xi) &= e(\xi) - \frac{1}{z_y}DK \delta\xi^\wedge \exp(\xi^\wedge )y \end{aligned} e(ξ⊕δξ)e(ξ⊕δξ)=z−zy1DKexp[(ξ⊕δξ)∧]y=z−zy1DKexp(δξ∧)exp(ξ∧)y≈z−zy1DK(1+δξ∧)exp(ξ∧)y利用指数的泰勒展开exp(x)≈1+x=z−zy1DKexp(ξ∧)y−zy1DKδξ∧exp(ξ∧)y=e(ξ)−zy1DKδξ∧exp(ξ∧)y
定义临时变量 T y = [ x , y , z ] Ty=[x, y, z] Ty=[x,y,z],则有:(详见博客推导直接法)
J ξ δ ξ = e ( ξ ⊕ δ ξ ) − e ( ξ ) = − 1 z y D K δ ξ ∧ exp ( ξ ∧ ) y J ξ δ ξ = − [ f x z 0 − f x x z 2 0 f y z − f y y z 2 ] [ I − ( T y ) ∧ ] δ ξ \begin{aligned} J_\xi \; \delta\xi &= e(\xi \oplus \delta \xi) - e(\xi) = -\frac{1}{z_y}DK {\delta\xi^\wedge} \exp(\xi^\wedge )y\\ J_\xi \; \delta\xi &= -\begin{bmatrix}\frac{f_x}{z}&0&\frac{-f_xx}{z^2} \\ 0&\frac{f_y}{z} &\frac{-f_yy}{z^2}\end{bmatrix} \begin{bmatrix}I&-(Ty)^\wedge\end{bmatrix} \delta\xi \end{aligned} JξδξJξδξ=e(ξ⊕δξ)−e(ξ)=−zy1DKδξ∧exp(ξ∧)y=−[zfx00zfyz2−fxxz2−fyy][I−(Ty)∧]δξ
以上为观测模型对相机pose的求导。pose6维,像点2维,最后求出一个2×6的 J J J矩阵。
b)误差 e e e关于3D点求导
过程类似,最后得到一个2×3的矩阵:
e ( y + δ y ) ≈ e ( y ) + J y δ y J y = − [ f x z 0 − f x x z 2 0 f y z − f y y z 2 ] R e(y+\delta y) \approx e(y) + J_y \delta y\\ J_y=- \begin{bmatrix}\frac{f_x}{z} & 0 & \frac{-f_xx}{z^2} \\ 0 & \frac{f_y}{z} & \frac{-f_yy}{z^2}\end{bmatrix}R e(y+δy)≈e(y)+JyδyJy=−[zfx00zfyz2−fxxz2−fyy]R
c)小结
对于针孔相机的观测模型 z = g ( x , y ) z = g(x,y) z=g(x,y),相机pose和空间点有微小运动时,像素的变化为:
e ( x + Δ x , y + Δ y ) ≈ e ( x , y ) + J ξ δ ξ + J y δ y e(x+\Delta x, y + \Delta y) \approx e(x,y) + J_\xi\delta\xi + J_y\delta y e(x+Δx,y+Δy)≈e(x,y)+Jξδξ+Jyδy
有耐心的话,还可以推导二阶Taylor展开式。
非线性优化SLAM:考虑所有变量和边,求解整个问题。
- 把所有相机pose和空间点放在一个state vec里面:
x = [ x 1 , x 2 , . . . , x N , 1 , x 2 , . . . , x M ] T x=[x_1, x_2, ..., x_N, _1, x_2, ..., x_M]^T x=[x1,x2,...,xN,1,x2,...,xM]T - 相机对每个控制点的观测误差: e g = z − g ( x ) e_g = z-g(x) eg=z−g(x),
每次运动的运动误差: e f = x − f ( x ) e_f=x-f(x) ef=x−f(x),
将所有误差的二次型 E = e T Σ e E = e^T\Sigma e E=eTΣe 相加,
得到目标函数 T ( x , y ) = Σ E f + Σ E g T(x,y)=\Sigma E_f + \Sigma E_g T(x,y)=ΣEf+ΣEg。 - 求 arg max x P ( x ∣ u , z ) = arg min x ( T ) \underset{x}{\arg\max}\; P(x|u,z) = \underset{x}{\arg\min} (T) xargmaxP(x∣u,z)=xargmin(T),需要解 H δ x = − b H \delta x = -b Hδx=−b。
H = ∑ ( J T Σ − 1 J ) H = \sum(\;\;\;J^T \Sigma^{-1} J) H=∑(JTΣ−1J)
b = ∑ ( − J T Σ − 1 e ) \;\;b = \sum(-J^T \Sigma^{-1} e) b=∑(−JTΣ−1e) - 更新一次 x ∗ = x ⊕ δ x x^* = x \oplus \delta x x∗=x⊕δx。(这里是广义的加号,pose不能直接相加)
以上是Gauss-Newton迭代法。
那么其他的迭代方法呢?
2 梯度下降法
给定目标函数 f ( x ) f(x) f(x),当前点 x O P x_{OP} xOP,梯度 Δ x \Delta x Δx,如何下降?
- 1 最速下降法
- 找寻最优步长 λ = arg min λ > 0 f ( x + λ x ) \lambda = \arg \min_{\lambda>0} f(x+\lambda x) λ=argminλ>0f(x+λx),下降慢
- x = x O P + λ Δ x x = x_{OP}+\lambda\Delta x x=xOP+λΔx
- 2 牛顿法 Newton
- 在工作点附近,求一阶+二阶导数(二阶导Hessian难算),可能不正定
f ( x O P + δ x ) ≈ f ( x O P ) + δ f δ x ∣ x O P δ x + 1 2 δ x T δ 2 f δ x δ x T ∣ x O P δ x = f ( x O P ) + J a c o b i a n δ x + 1 2 δ x T H e s s i a n δ x \begin{aligned} f(x_{OP}+\delta x) &\approx f(x_{OP}) + \frac{\delta f}{\delta x}|_{x_{OP}} \delta x + \frac{1}{2}\delta x^T\frac{\delta ^2 f}{\delta x \delta x^T}|_{x_{OP}}\delta x\\ & = f(x_{OP})+Jacobian\; \delta x + \frac{1}{2}\delta x^T Hessian \;\delta x\end{aligned} f(xOP+δx)≈f(xOP)+δxδf∣xOPδx+21δxTδxδxTδ2f∣xOPδx=f(xOP)+Jacobianδx+21δxTHessianδx - H δ x ∗ = − J T e H\delta x^* = -J^Te Hδx∗=−JTe
- 在工作点附近,求一阶+二阶导数(二阶导Hessian难算),可能不正定
- 3 高斯牛顿法 G-N
- 用 J T J J^TJ JTJ近似Hessian矩阵,可能半正定导致 J T J J^TJ JTJ不可逆
- J T J δ x ∗ = − J T e J^TJ\delta x^*=-J^Te JTJδx∗=−JTe
- 4 Leverberg-Marquardt法
- 引入拉格朗日乘子,在一个小的邻域范围(trusted region)中求 m i n x f ( x ) + λ ∣ ∣ x ∣ ∣ 2 min_xf(x)+\lambda||x||^2 minxf(x)+λ∣∣x∣∣2
- G-N失效,目标函数不下降时,增大 λ \lambda λ近似最速法;反之减小 λ \lambda λ近似G-N法
- ( J T J + λ I ) δ x ∗ = − J T e (J^TJ+\lambda I)\delta x^* = -J^Te (JTJ+λI)δx∗=−JTe
** 234都是二阶的方法,变量维度较高时,下降速度快。
** 非正定:当二次曲线开口向下,此时H不可逆,G-N法的 J T J J^TJ JTJ是半正定的( x T J T J x = ( J x ) 2 > 0 x^TJ^TJx=(Jx)^2 > 0 xTJTJx=(Jx)2>0),但也可能无法求逆
- 5 Dogleg法
- 在trusted region内部,用G-N
- 否则用最速,但最速的下降方向可能在region内/外部
- 在内部,使用两个梯度的混合
- 在外部,则缩小到region边界
小结
- 最速下降:计算快,收敛慢,有zig-zag现象
- Newton:收敛慢,Hessian复杂
- G-N: J T J ≈ H J^TJ\approx H JTJ≈H计算方便,可能失效
- L-M: J T J + λ I J^TJ+\lambda I JTJ+λI控制 λ \lambda λ调整收敛结果
- DogLeg:G-N与最速的混合
后三个常用,G-N最常用。
对于所有优化的问题:
- 初值敏感
- 局部可能极小
SLAM目前是个非凸问题:
- 解不唯一
- 依赖初值(前端需要提供好的匹配和初值)
3 图优化与稀疏性
一个非线性的优化问题,可以表示成图: G = V , E G={V,E} G=V,E
- V- 节点:优化变量(pose,point)
- E- 边:误差项(运动方程,观测方程)
凸优化的关键问题:当图的规模较大时(几千到几万个变量),如何求解?
H δ x ∗ = − b H\delta x^*=-b Hδx∗=−b
小规模可求逆: δ x ∗ = − H − 1 b \delta x^*=-H^{-1}b δx∗=−H−1b。但求逆的复杂度为 O ( N 3 ) O(N^3) O(N3)。
N很大的时候怎么办?利用稀疏性。
3.1 稀疏性
只有观测方程时
优化变量: x k = [ x 1 , x 2 , . . . , x N , x 1 , x 2 , . . . , x M ] k x_k=[x_1, x_2, ..., x_N, x_1, x_2, ..., x_M]_k xk=[x1,x2,...,xN,x1,x2,...,xM]k
某个约束: e j k = z j k − g ( x i , y k ) e_{jk}=z_{jk}-g(x_i,y_k) ejk=zjk−g(xi,yk)
该约束关于自变量的雅可比只有两个地方非0(如下图左)。而组成的H矩阵也只有四个地方非零(如下图右)。也就是说 H δ x = − b H\delta x=-b Hδx=−b的 H H H是稀疏的。
d e j k d x = [ 0 , 0 , . . . , d e j k d x j , . . . , d e j k d y k , . . . ] T H j k = J j k T Σ j k − 1 J j k \begin{aligned} \frac{de_{jk}}{dx} &= [0,0,...,\frac{de_{jk}}{dx_j}, ...,\frac{de_{jk}}{dy_k},...]^T \\ H_{jk} & = J^T_{jk} \Sigma^{-1}_{jk} J_{jk} \end{aligned} dxdejkHjk=[0,0,...,dxjdejk,...,dykdejk,...]T=JjkTΣjk−1Jjk


而组成的H矩阵也只有四个地方非零,如上图右。也就是说 H δ x = − b H\delta x=-b Hδx=−b的 H H H是稀疏的。
H j k = J j k T Σ j k − 1 J j k H_{jk}=J^T_{jk} \Sigma^{-1}_{jk} J_{jk} Hjk=JjkTΣjk−1Jjk
j=[1:N] 为pose个数,k=[1:M]为空间点个数。如果每个约束只有一个pose和一个point,当每个pose可以看到所有point时,矩阵形如下图:

[ H 11 H 12 H 12 T H 22 ] [ δ x 1 ∗ δ x 2 ∗ ] = [ − b 1 − b 2 ] \begin{bmatrix}H_{11}&H_{12}\\H_{12}^T&H_{22}\end{bmatrix} \begin{bmatrix}\delta x^*_1 \\ \delta x^*_2\end{bmatrix} = \begin{bmatrix} -b_1\\ -b_2\end{bmatrix} [H11H12TH12H22][δx1∗δx2∗]=[−b1−b2]
δ x 1 \delta x_1 δx1为pose部分, δ x 2 \delta x_2 δx2为point部分,一般jpose数远小于point数,形成一个箭头形的稀疏矩阵。
3.2 加速方式
a) 稀疏Schur Complement(类似消元法)
- 对上面的方程左乘 [ I − H 12 H 22 − 1 0 I ] \begin{bmatrix} I &-H_{12} H_{22}^{-1} \\ 0 & I \end{bmatrix} [I0−H12H22−1I]得到:
[ H 11 − H 12 H 22 − 1 H 12 T 0 H 12 T H 22 ] [ δ x 1 ∗ δ x 2 ∗ ] = [ − b 1 + H 12 H 22 − 1 b 2 − b 2 ] \begin{bmatrix}H_{11} - H_{12}H_{22}^{-1}H_{12}^T & 0\\ H_{12}^T & H_{22}\end{bmatrix} \begin{bmatrix}\delta x^*_1 \\ \delta x^*_2\end{bmatrix} = \begin{bmatrix} -b_1 + H_{12}H_{22}^{-1}b_2\\ -b_2\end{bmatrix} [H11−H12H22−1H12TH12T0H22][δx1∗δx2∗]=[−b1+H12H22−1b2−b2]
- 解 ( H 11 − H 12 H 22 − 1 H 12 T ) δ x 1 ∗ = − b 1 + H 12 H 22 − 1 b 2 (H_{11} - H_{12}H_{22}^{-1}H_{12}^T ) \delta x^*_1 = -b_1 + H_{12}H_{22}^{-1}b_2 (H11−H12H22−1H12T)δx1∗=−b1+H12H22−1b2 得到 δ x 1 ∗ \delta x^*_1 δx1∗( H 22 − 1 H_{22}^{-1} H22−1对角易求,pose少求逆容易)
- 解 H 12 T δ x 1 ∗ + H 22 δ x 2 ∗ = − b 2 H_{12}^T \delta x_1^* +H_{22} \delta x_2^* = -b_2 H12Tδx1∗+H22δx2∗=−b2 得到 δ x 2 ∗ \delta x^*_2 δx2∗( H 22 − 1 H_{22}^{-1} H22−1对角易解)
复杂度从 O ( N + M ) 3 O(N+M)^3 O(N+M)3 => O ( N 3 + M 3 ) O(N^3+M^3) O(N3+M3)。
当M>>N时,加速明显。
整个过程不需要求解 H − 1 H^{-1} H−1。
b) 稀疏Cholesky
Cholesky分解解方程
原始方程: A x = b Ax=b Ax=b
分解 A A A: A = U U T A=UU^T A=UUT。并设中间变量 y = U T x y = U^Tx y=UTx。则有:
A x = U U T x = U y = b Ax=UU^Tx = Uy=b Ax=UUTx=Uy=b
求解时,先解 U y = b Uy=b Uy=b,再解 U T x = y U^Tx = y UTx=y ,最终得到 x x x。
U U U是个上三角矩阵,最底下那一行只有一个变量,因此逐行求解,就很快。
Cholesky解稀疏矩阵
原始方程: H δ x ∗ = − b H \delta x^* = -b Hδx∗=−b
分块并分解 H H H为:
[ H 11 H 12 H 12 T H 22 ] = [ U 11 U 12 0 U 22 ] [ U 11 T 0 U 12 T U 22 T ] \begin{bmatrix}H_{11}&H_{12}\\H_{12}^T&H_{22}\end{bmatrix} = \begin{bmatrix}U_{11}&U_{12}\\0&U_{22}\end{bmatrix} \begin{bmatrix}U_{11}^T&0\\U_{12}^T&U_{22}^T \end{bmatrix} [H11H12TH12H22]=[U110U12U22][U11TU12T0U22T]
则可以计算U矩阵:
H 22 = U 22 U 22 T H_{22} = U_{22}U_{22}^T H22=U22U22T =》 H 22 H_{22} H22为对角块矩阵,易解 U 22 U_{22} U22
H 12 = U 12 U 22 T H_{12} = U_{12}U_{22}^T H12=U12U22T =》 U 22 U_{22} U22已知且为对角块,易解 U 12 U_{12} U12
H 11 = U 11 U 11 T + U 12 U 12 T H_{11} = U_{11}U_{11}^T + U_{12}U_{12}^T H11=U11U11T+U12U12T =》 H 11 H_{11} H11规模小,易解
那么可得:
H − 1 = [ U 11 U 11 − 1 − U 11 − T U 11 − 1 U 12 U 22 − 1 − U 22 − T U 12 T U 11 − T U 11 − 1 U 22 − T ( U 12 T U 11 − T U 11 − 1 U 12 + I ) U 22 − 1 ] H^{-1} = \begin{bmatrix} U_{11} U_{11}^{-1} & -U_{11}^{-T} U_{11}^{-1} U_{12} U_{22}^{-1} \\ -U_{22}^{-T} U_{12}^T U_{11}^{-T} U_{11}^{-1} & U_{22}^{-T} (U_{12}^T U_{11}^{-T} U_{11}^{-1} U_{12}+ I) U_{22}^{-1} \end{bmatrix} H−1=[U11U11−1−U22−TU12TU11−TU11−1−U11−TU11−1U12U22−1U22−T(U12TU11−TU11−1U12+I)U22−1]
当有运动方程时
H 11 H_{11} H11不再是对角块,但稀疏性还在,还是可以求解。
3.3 小结

后端需要做的任务:
- 定义顶点和边,每条边对应一个误差项
- 求每个误差项,求其相对于优化变量的雅可比
- 所有误差放到一起,构建增量方程
- 求解增量方程
- 更新优化变量的估计值
4 G2O
4.1 简介
General graphic Optimization 通用图优化
| g2o库提供的功能 | 用户要做的 |
|---|---|
| 多种类型图节点与边 | 构建、维护图模型 |
| 数值雅可比 | (可选)提供解析雅可比 |
| 增量方程构建&求解 | 选择求解器与下降方法 |
| 多种下降方法(G-M, L-M) | 执行优化 |
| 可视化工具 | (可选)调用 |
| 可选(自定义边,主动控制优化过程) |
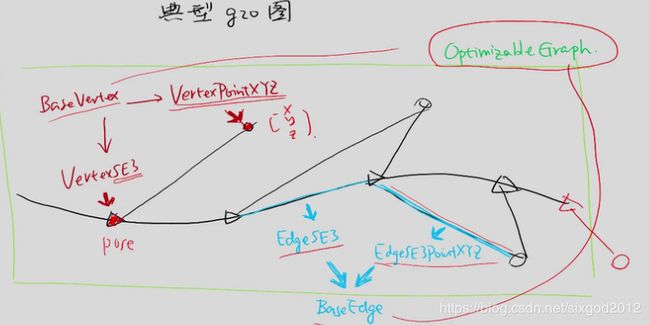
顶点:
位姿可以选VertexSE3(单目Sim3,激光SE2)
空间点可以选VertexPointXYZ
都基于基类BaseVertex
边:
pose-pose:EdgeSE3
pose-point:EdgeSE3PointXYZ
都基于基类BaseEdge
G2O的核心是一个Optimizable Graph

- Vertex可以选择fix固定住它的值,比如第一个点
- 存在多元边,如 e = z − g ( x 1 , x 2 , y 1 ) e=z-g(x_1, x_2, y_1) e=z−g(x1,x2,y1)
- 多种优化算法
- 解 H δ x = − b H\delta x=-b Hδx=−b时调用外部的库,稀疏问题可以选择一个稀疏库
4.2 使用
参考:深入理解图优化与g2o:g2o篇
大致步骤:
- 初始化
// 先构造求解器(也就是我们要维护的图)
g2o::SparseOptimizer optimizer;
// 使用Cholmod中的线性方程求解器(H dx = -b的求解器)
g2o::BlockSolver_6_3::LinearSolverType* linearSolver = new g2o::LinearSolverCholmod ();
// 6*3 的参数(单个误差项对应参数块)
g2o::BlockSolver_6_3* block_solver = new g2o::BlockSolver_6_3( linearSolver );
// L-M 下降 (定义下降方式)
g2o::OptimizationAlgorithmLevenberg* algorithm = new g2o::OptimizationAlgorithmLevenberg( block_solver );
optimizer.setAlgorithm( algorithm );
optimizer.setVerbose( false );
-
添加顶点和边
optimier.addVertex
optimier.addEdge -
开始优化
optimizer.optimize() -
读取优化结果
o[0] is undefined
* 核函数
普通误差项 E = e T Σ − 1 e E=e^T\Sigma^{-1}e E=eTΣ−1e是个二范数,随e的增长很快。
但当图中有一条错误的边,它的误差会很大,优化算法会费很大力气优化错误的边。
考虑到这点,想要使误差的增长不要那么快,引入核函数。
带核函数的误差项形式为: E = ρ ( e T Σ − 1 e ) E=\rho( \sqrt{e^T\Sigma^{-1}e}) E=ρ(eTΣ−1e)
对普通的二范数,相当于 ρ ( x ) = x 2 \rho (x) = x^2 ρ(x)=x2
Huber核:
ρ ( x ) { x 2 , ∣ x ∣ < b 2 b ∣ x ∣ − b 2 , ∣ x ∣ ≥ b \rho (x) \begin{cases} x^2 \qquad\qquad,|x|
大于边界b时变为线性增长。
* Pose Graph
只有pose没有point的图,在不关心point时可以使用,计算量小,侧重定位。
Pose Graph约束
对pose x k x_k xk和 x l x_l xl测得[未完。。。]

5 小结
- SLAM问题可以用非线性优化求解(高斯分布下对应最小二乘)
- 我们关心:优化的目标函数,误差项,梯度,下降方式
- 优化问题可以抽象成图模型
- 图优化可以用g2o求解