时序数据库 TimescaleDB 和 InfluxDB 对比
时间序列数据库
顾名思义,时间序列数据库旨在存储随时间变化的数据。这可以是对时间收集的任何类型的数据。他可能是从某些系统收集的指标,实际上,所有趋势系统均是时间序列数据的示例。
对于不同类型的时间序列数据库,我该如何选择?
本文中,我们主要讨论 TimescaleDB 和 InfluxDB 两个时序数据库的区别。
InfluxDB
InfluxDB 是由 InfluxData 创建的。它是用 Go 语言编写的自定义、开源、NoSQL 的时间序列数据库。数据存储区提供了一种类似 SQL 的查询语言,称之为 InfluxQL,这使开发人员可以轻松地将其集成到其应用程序中。它还具有一种称之为 Flux 的新的自定义查询语言,该语言可以是执行某些任务变得更容易,但在采用自定义查询语言时总会有一条学习曲线。
如下是一个 Flux 查询的示例:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()
在该数据库中,每个测量结果都包含一个时间戳,以及一组与之关联的标签和一组字段。该字段表示实际测量读取值,而标签表示描述测量的原数据。字段数据类型仅限于 float, int, string 和 boolean,不重写数据就无法更改。标记值被编入索引。他们以字符串表示,无法更新。
InfluxDB 入门非常容易,因为你不必担心创建原型或索引。但是,它非常严格死板和受限,无法创建额外的索引、连续字段上的索引、事后更新原数据、强制数据验证等。
他并非没有原型。它会根据输入的数据自动创建一个基础模型。
InfluxDB 必须从头开始实施多种容错工具,例如多副本、高可用性和备份/还原,并且要对磁盘的可靠性负责。我们仅限于使用这些工具,并且其中许多功能(如 HA)仅在企业版中可用。
InfluxDB 备份工具可以进行完整或增量备份,并且可以用于时间点恢复。
InfluxDB 还提供了比 PostgreSQL 和 TimescaleDB 更好的磁盘压缩。
TimescaleDB
TimescaleDB 是一个开源的时间序列数据库,已针对支持全面 SQL 的快速提取和复杂查询进行了优化。它基于 PostgreSQL ,并且为时间序列数据提供了最好的 NoSQL 和 关系世界。
如下是一个 TimescaleDB 查询示例:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';
作为 PostgreSQL 扩展,TimescaleDB 是一个关系数据库。这使得新用户有一个较短的学习曲线,并且可以继承 pg_dump 或 pg_backup 之类的工具进行备份,还继承了高可用性的工具,相比其他时间序列数据库这是一个优势。它还支持将流复制作为主要的复制方式,可以将其用于高可用性设置中。在故障转义和备份方面,你可以使用 ClusterControl 之类的外部系统来自动执行。
在 TimescaleDB 中,每个时间序列测量值都记录在自己的行中,时间字段后面跟着任意数量的其他类型字段,包括 浮点数,整数,字符串,布尔值,数组,JSON,地理空间尺寸,日期 / 时间 / 时间戳,货币,二进制数据等。
你可以在任意字段(标准索引)或多个字段(符合索引)上或在函数等表达式上创建索引,甚至可以将索引限制为行的自己(部分索引)。这些字段中的任何一个都可用作辅助表的外键,然后改辅助表可以存储其他原数据。
这样,你需要选择一个原型,并确定系统需要哪些索引。
性能
如果我们谈论性能,那么可以查看 TimescaleDB 博客。在那里,您可以通过图表和指标对两个数据库之间的性能进行详细比较。现在让我们看看该博客中的一些最重要的信息。
You can create indexes on any field (standard indexes) or multiple fields (composite indexes), or on expressions like functions, or even limit an index to a subset of rows (partial index). Any of these fields can be used as a foreign key to secondary tables, which can then store additional metadata.
In this way, you need to choose a schema, and decide which indexes you’ll need for your system.
插入性能
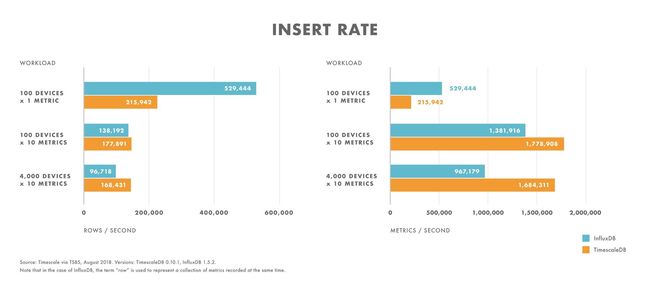
- 对于基数非常低的工作负载(例如 100 个设备),InfluxDB 的性能优于 TimescaleDB。
- 随着基数的增加,InfluxDB 插入性能下降的速度快于 TimescaleDB。
- 对于中到高基数的工作负载(例如,100 个设备发送 10 个指标),TimescaleDB 的性能要优于 InfluxDB。

读取性能
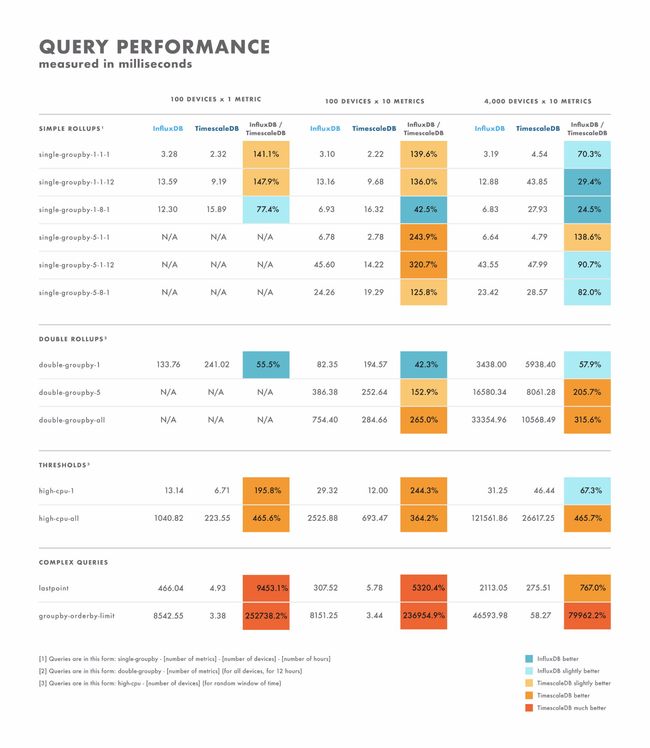
- 对于简单查询,结果相差很大:在某些情况下,一个数据库明显优于另一个数据库,而其他数据库则取决于数据集的基数。此处的差异通常在一位数到两位数的毫秒数范围内。
- 对于复杂的查询,TimescaleDB 的性能大大优于 InfluxDB,并支持范围更广的查询类型。这里的差异通常在几秒到几十秒之间。
- 考虑到这一点,正确测试的最佳方法是使用计划执行的查询进行基准测试。
稳定性
- InfluxDB 在基数高(100K +)时存在稳定性和性能问题。
总结
如果您的数据适合 InfluxDB 数据模型,并且您不希望将来发生变化,那么您应该考虑使用 InfluxDB,因为该模型更容易上手,就像大多数使用面向列方法的数据库一样,提供比 PostgreSQL 和 TimescaleDB更好的磁盘压缩。
但是,关系模型比 InfluxDB 模型具有更多的通用性,并提供更多的功能,灵活性和控制力。随着应用程序的发展,这一点尤其重要。在规划系统时,您应该考虑当前和将来的需求。
在此博客中,我们可以看到 TimescaleDB 和 InfluxDB 之间的简短比较,并且可以说 TimescaleDB作为 PostgreSQL 扩展,看起来很成熟并且功能丰富,因为它从 PostgreSQL 继承了很多东西。但是您可以根据本博客前面提到的优缺点来做出自己的决定,并确保对自己的工作负载进行基准测试。在这个新的时间序列数据库世界中祝您好运!